Eu estava querendo dedicar algum tempo para implementar alguma DLL ou algo que eu pudesse usar do Caché e finalmente tive uma pequena ideia, se você está interessado em poder produzir mensagens que são enviadas para o Kafka rapidamente, você é no lugar certo ;-)
Antes de lhe entregar a ficha com o que vamos ver, vou fazer um resumo para que você decida se tem interesse em ler o artigo.
Neste artigo vamos focar "apenas" na parte de produzir mensagens e enviá-las para Kafka:
Se você precisar escrever a Arquitetura de Dados de sua organização e mapear para o IRIS da InterSystems, considere o seguinte Diagrama de Arquitetura de Dados e referências à documentação da íris entre sistemas, consulte:
O InterSystems IRIS tem um bom conector para fazer Hadoop usando Spark. Mas o mercado oferece outra alternativa excelente para o acesso ao Big Data Hadoop, o Apache Hive. Veja as diferenças:
Esta é uma visão bastante pessoal da história antes do Caché.
Não tem o objetivo de competir com os excelentes livros de Mike Kadow discutidos em um artigo anterior.
Temos uma história diferente e, portanto, isso visa criar uma perspectiva diferente do passado.
Toda a história começou em 1966 no MGH (Mass.General Hospital) em um PDP-7 Ser. # 103com 8 K de memória (palavras de 18 bits) [hoje = 18 K byte] como um sistema sobressalente.
"Número de série 103 - estava localizado no porão do agora demolido Edifício Thayer,atualmente [2014] o site do Cox Cancer Center no MGH. ""Neil Papparlardo e Curt Marble sob a orientação de Octo Barnett desenvolveram e lançaramo software inicial nesta máquina. "
Recentemente eu recebi o desafio de criar um método de autenticação segura para autorizar acesso a alguns dados, mas infelizmente eu não tinha nenhuma experiência com essas configurações de segurança e senti que me faltava, alguns conceitos básicos para compreender melhor a documentação oficial.
Depois de estudar e conseguir entregar as classes que me pediram para desenvolver, eu gostaria de compartilhar um pouco do meu novo conhecimento, que me ajudou seguir os tópicos da documentação.
Estou planejando implementar a Inteligência de Negócio (BI) com base nos dados de minhas instâncias. Qual é a melhor maneira de configurar meus bancos de dados e ambiente para usar o DeepSee?
Este é um exemplo de codificação funcionando no IRIS 2020.1 e no Caché 2018.1.3
Ele não será sincronizado com as novas versões
E também NÃO é atendido pelo Suporte da InterSystems!
Globais no Caché / Ensemble / IRIS são normalmente invisíveis ao acessar o SQL
Este exemplo mostra como contornar esse limite.
O mesmo serviço com a possibilidade de receber várias consultas SQL diferentes e sempre entregar o resultado independente de quantas colunas distintas tenham essas diferentes consultas. Aqui demonstro como pode ser possível montar esse tipo de serviço utilizando o Service Bus da Intersystems.
Possível cenário (Desconsiderar o uso de um BI):
Vamos pensar em um painel real time onde iremos fornecer as informações de consumo de um material por região para o setor de compras e teremos as informações do nome do produto, fabricante e quantidade por exemplo.
Neste artigo, quero revisar as extensões do VS Code que uso para trabalhar com a InterSystems e que facilitam muito meu trabalho. Tenho certeza de que este artigo será útil para quem está apenas começando a jornada de aprendizado das tecnologias da InterSystems. No entanto, também espero que este artigo seja útil para desenvolvedores com vários anos de experiências e abra novas possibilidades de uso do VS Code para desenvolvimento.
O OpenAPI-Client Gen acaba de ser lançado, este é um aplicativo para criar um cliente de produção de interoperabilidade IRIS a partir da especificação Swagger 2.0.
Em vez da ferramenta existente ^%REST que cria um aplicativo REST do lado do servidor, o OpenAPI-Client Gen cria um modelo de cliente de produção de interoperabilidade REST completo.
Houve alguns artigos muito úteis na comunidade que mostram como usar o Grafana com IRIS (ou Cache/Ensemble) usando um banco de dados intermediário.
Mas eu queria chegar diretamente às estruturas IRIS. Em particular, eu queria acessar os dados do monitor de histórico do cache que podem ser acessados por SQL, conforme descrito aqui
De acordo com o relatório Global Fraud and Identity Report 2020 da Experian, as fraudes no setor financeiro globalmente ultrapassaram a marca de US$ 42 bilhões em 2020, com destaque para fraudes de identidade, bancárias, em cartões de crédito e débito, em empréstimos e em aplicativos móveis bancários. A pandemia do COVID-19 impulsionou o crescimento de fraudes relacionadas à saúde, como fraudes em benefícios de seguro-saúde e em programas de ajuda financeira do governo.
Este artigo e os próximos dois artigos da série são um guia do usuário para desenvolvedores ou administradores de sistema que precisam usar o framework OAuth 2.0 (chamado de OAUTH para simplificar) em suas aplicações baseadas no produto InterSystems.
As consultas utilizando intervalo de datas estão muito lentas para você? O desempenho do SQL te desanima? Eu tenho um estranho truque que pode te ajudar! (Desenvolvedores de SQL odeiam isso!)*
Incrível esse legado! Esse é um dos motivos principais do sucesso da Intersystems.
Fiz um teste simples essa semana e não é que deu certo? Qual linguagem tem essa capacidade? Qual banco de dados pode-se ter Globais e Tabelas SQL? Isso sem falar na velocidade! Será covardia o BachMark entre MS-SQL e Caché. Qual o sistema que vc pode instalar em seu notebook e apresentar resultados como se estivesse em um Servidor?
IRIS External Table é um projeto de código aberto da comunidade InterSystems, que permite usar arquivos armazenados no sistema de arquivos local e armazenamento de objetos em nuvem, como o AWS S3, como tabelas SQL.
Esta postagem tem como objetivo guiá-lo através dos novos recursos JSON que introduzimos no Caché 2016.1.JSON surgiu para um formato de serialização usado em muitos lugares.A web começou, mas hoje é utilizada em todos os lugares.Temos muito o que abordar, então vamos começar.
Nesta série de artigos de três partes, é mostrado como você pode usar o IAM para simplesmente adicionar segurança, de acordo com os padrões do OAuth 2.0, a um serviço não autenticado anteriormente implantado no IRIS.
Na primeira parte, foram fornecidos alguns conhecimentos sobre o OAuth 2.0, juntamente com algumas definições e configurações iniciais do IRIS e IAM, para facilitar a compreensão de todo o processo de proteção dos seus serviços.
Desde o Caché 2017, o mecanismo SQL inclui um novo conjunto de estatísticas. Ele registra o número de vezes que uma consulta é executada e o tempo que leva para executá-la.
Recentemente, eu queria obter uma lista de todas as consultas em cache e seus textos. Veja como fazer isso. Primeiro, crie um procedimento SQL retornando texto de consulta de cache a partir de um nome de rotina de consulta em cache:
A taxa de precisão é uma medida de nossos resultados de previsão e é uma medida de quantas das amostras positivas previstas são realmente positivas. A taxa de recall é para nossa amostra original e mostra quantos exemplos positivos na amostra foram previstos corretamente. Precisão = Previsto corretamente / Tudo Se quisermos ser capazes de recuperar o máximo de conteúdo possível, essa é a busca da "razão de recall", ou seja, A / (A + C), quanto maior, melhor.
 Por visualizações
Por visualizações.png)
 Open Exchange app
Open Exchange app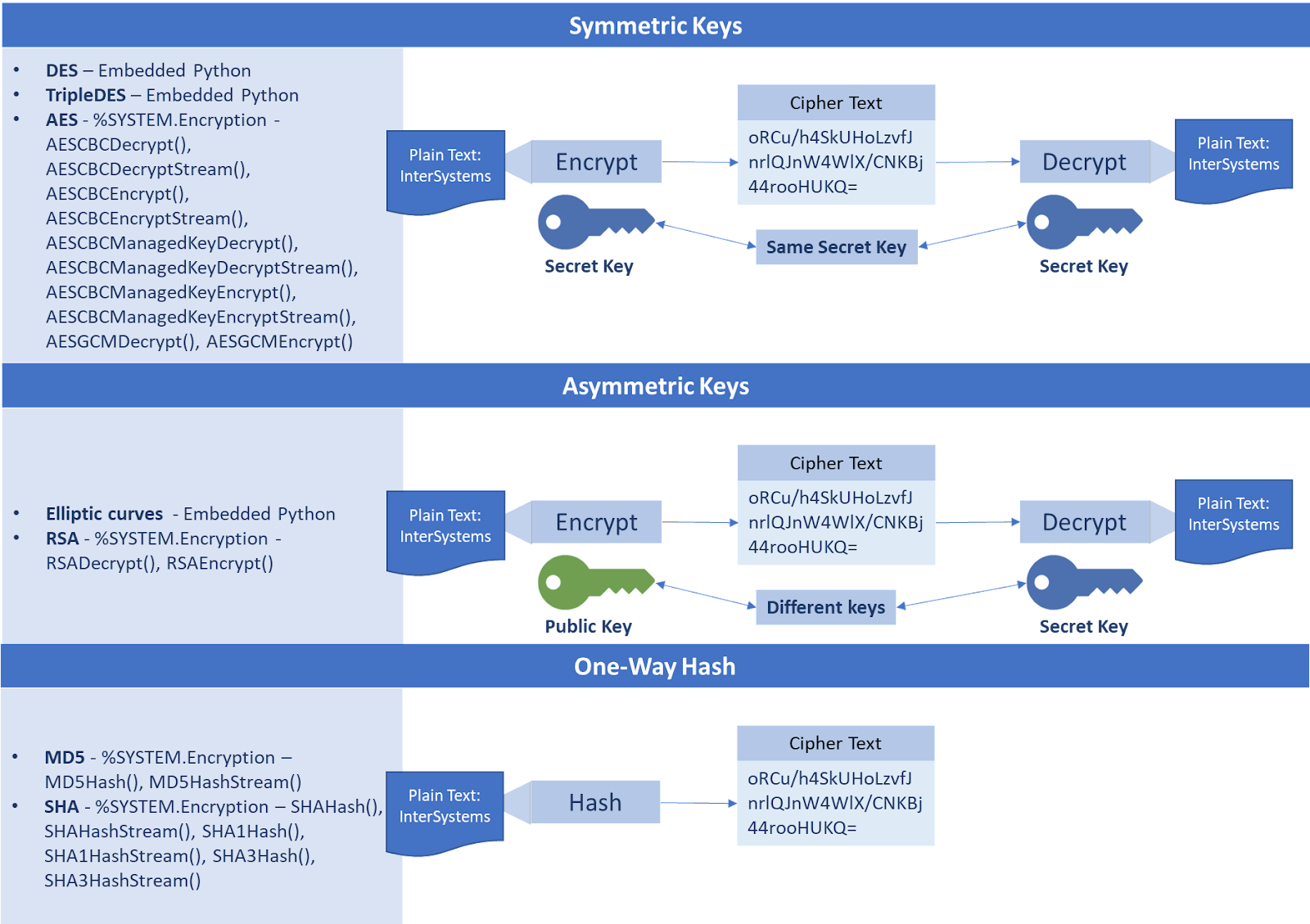


.png)