Por visualizações
Por visualizações
 Open Exchange app
Open Exchange appNeste artigo iremos construir uma configuração IRIS de alta disponibilidade utilizando implantações Kubernetes com armazenamento persistente distribuído substituindo o "tradicional" espelhamento IRIS. Esta implantação será capaz de tolerar falhas relacionadas a infraestrutura como falhas em nós, armazenamento e de Zonas de Disponibilidade. A abordagem descrita reduz muito a complexidade da implantação em detrimento um objetivo de tempo de recuperação (RTO) ligeiramente estendido.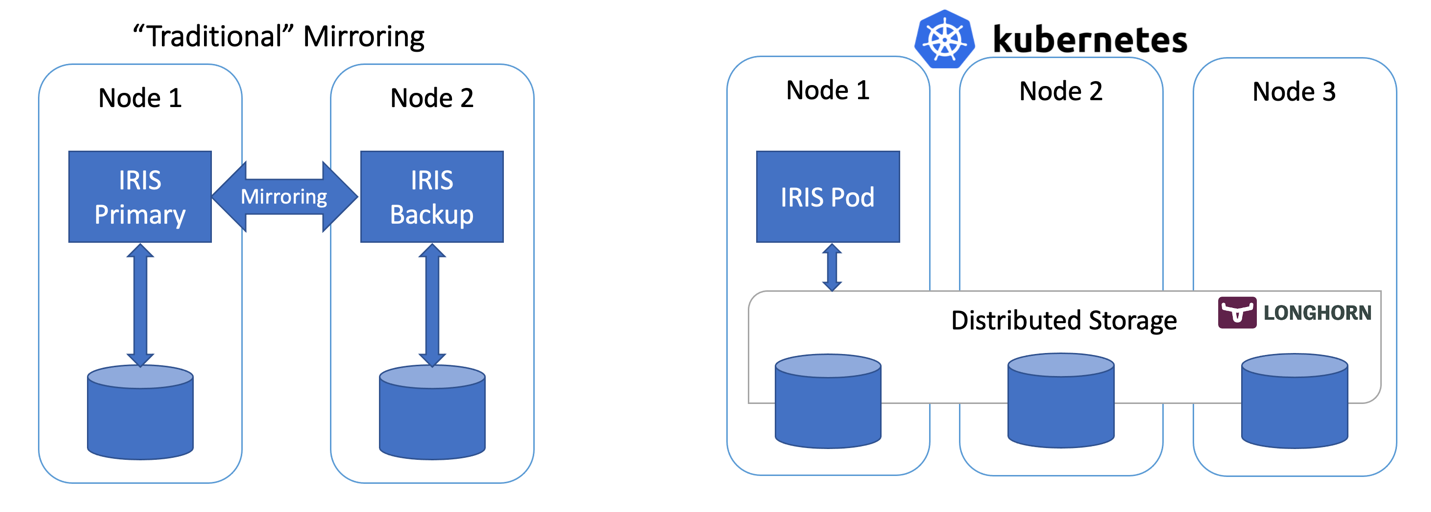

InterSystems Developer Community é uma comunidade de 23,546 desenvolvedores incríveis
Somos um local onde os programadores do InterSystems IRIS aprendem e compartilham, permanecem atualizados, crescem juntos e se divertem!



.png)
.png)