Projeto 1 - Integração utilizando SOAP Inbound Adapter
A idéia deste novo conjunto de postagens é apresentar uma série de integrações utilizando o InterSystems IRIS. Vamos ver integrações REST, SOAP, utilizando adaptadores ODBC, Arquivos e outros.
Você provavelmente já ouviu falar muito sobre LLMs (Large Language Models) e o desenvolvimento associado de aplicações RAG (Retrieval Augmented Generation) no último ano. Bem, nesta série de artigos explicaremos os fundamentos de cada termo usado e veremos como desenvolver uma aplicação RAG simples.
O FHIR (Fast Healthcare Interoperability Resources) é o padrão mais utilizado pelo mercado para interoperar e armazenar dados em saúde. Trata-se de um padrão que mapeia dezenas de recursos de dados (Pacientes, Observações, Medicações, Diagnósticos, Alergias, Vacinas, Faturamento, Provedores de Saúde, Atendimentos, dentre outros) e seus relacionamentos (Medicações do Paciente, por exemplo). O acesso a todas estas estruturas de dados se dá pelo uso de APIs REST em formato JSON ou XML. A princípio, a maioria dos fornecedores de soluções FHIR, não disponibiliza acesso aos dados no formato SQL.
Recentemente estive investigando uma situação incômoda enquanto editava classes ou rotinas ObjectScript no VSCode. O que acontecia era que, como estava escrevendo as linhas de código na minha classe (por exemplo: a adição de um novo método, mudança da assinatura de classe ou de um bloco de código) isso ocasionava uma rápida revisão da sintaxe, reformatação e compilação - e inevitavelmente (já que eu estava apenas na metade da escrita), isso gerava erros de compilação.
Desenvolvimento de frontend pode ser uma tarefa muito difícil, especialmente para desenvolvedores focados em backend. Mais cedo na minha carreira, as linhas entre frontend e backend eram borradas, e se experava de todos que conseguissem manejar ambos. CSS em particular era um desafio constante, parecia uma missão impossível.
Vamos montar nossa próxima integração utilizando uma aplicação REST. Para tal vamos utilizar um BS que chamará o BP do nosso serviço demo (ver Primeira Integração). Vamos reaproveitar o serviço que então poderá ser chamado via SOAP ou REST. Teremos então dois BS que irão chamar o mesmo BP. A imagem abaixo ilustra essa arquitetura:
Nesse artigo, demonstrarei os seguintes passos para criar seu próprio chatbot utilizando spaCy (spaCy é uma biblioteca de software de código aberto para o processamento avançado de linguagem natural, escrita nas linguagens de programação Python e Cython):
Passo 1: Instalar as livrarias necessárias
Passo 2: Criar o arquivo de padrões e respostas
Passo 3: Treinar o modelo
Passo 4: Criar uma aplicação ChatBot baseada no modelo treinado
Vamos montar nossa próxima integração utilizando o adaptador SQL Inbound Adapter. Este adaptador permite acessar uma tabela externa ao IRIS e consumir seus registros.
Bem-vindo à terceira e última publicação de nossos artigos dedicados ao desenvolvimento de aplicações RAG baseadas em modelos LLM. Neste último artigo, veremos, com base em nosso pequeno projeto de exemplo, como podemos encontrar o contexto mais adequado para a pergunta que queremos enviar ao nosso modelo LLM e para isso utilizaremos a funcionalidade de busca vetorial incluída no IRIS.
Incluo esse post para ajudar os usuários de WebTerminal que atualizaram à versão IRIS 2024.2 -- (Build 247U) Tue Jul 16 2024 09:52:30 EDT -- liberada recentemente, ou estão considerando fazê-lo.
Eu recentemente participei no "mão na massa" fantasticamente organizado pelo @Patrick Jamieson no qual uma aplicação Angular foi configurada junto com um servidor IRIS FHIR seguindo os protocolos definidos pelo SMART On FHIR e eu o achei muito interessante, então decidi desenvolver a minha própria aplicação Angular e então usar o que aprendi e publicar na comunidade.
SMART On FHIR
Vamos ver o que o Google nos conta sobre o SMART On FHIR:
Montando as integrações para esta série de postagens, vi que precisava me aprofundar um pouco mais na questão do componente CALL do BP. Assim montei este novo documento mostrando algumas informações importantes deste componente.
Vamos montar nossa próxima integração utilizando o adaptador SOAP Outbound Adapter. Este adaptador permite acessar um serviço SOAP externo e consumir este serviço.
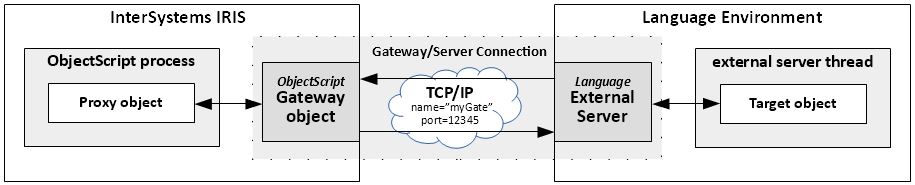
Se vocês gostam de Java e têm um ecossistema Java ativo no trabalho e precisam incorporar IRIS, isso não é um problema. A Gateway de Linguagem Externa de Java fará isso sem complicações, ou quase. Essa gateway serve como ponte entre Java e ObjectScript no IRIS. Vocês podem criar objetos de classes Java no IRIS e chamar seus métodos. Só precisam de um arquivo JAR para fazer isso.
Olá. Vamos montar nossa próxima integração utilizando o adaptador SOAP Inbound Adapter chamando um BP que chamará um BO que utilizará o REST Outbound Adapter.
Isso pode ser conseguido usando o procedimento CSV() da classe %SQL.Util.Procedures . Abaixo está o exemplo de uso do código. (Assumindo que o arquivo test.csv está em c:\temp.)
 Ano
Ano Open Exchange app
Open Exchange app.png)
.png)