Modelos lLM e Aplicações RAG Passo-a-passo - Parte III - Buscando e injetando contexto
Bem-vindo à terceira e última publicação de nossos artigos dedicados ao desenvolvimento de aplicações RAG baseadas em modelos LLM. Neste último artigo, veremos, com base em nosso pequeno projeto de exemplo, como podemos encontrar o contexto mais adequado para a pergunta que queremos enviar ao nosso modelo LLM e para isso utilizaremos a funcionalidade de busca vetorial incluída no IRIS.

Pesquisas vetoriais
Um elemento-chave de qualquer aplicação RAG é o mecanismo de busca vetorial, que permite pesquisar dentro de uma tabela com registros desse tipo aqueles mais semelhantes ao vetor de referência. Para isso, é necessário primeiro gerar o embedding da pergunta que será passada para o LLM. Vamos dar uma olhada em nosso projeto de exemplo para ver como geramos esse embedding e o usamos para lançar a consulta ao nosso banco de dados IRIS:
model = sentence_transformers.SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
question = model.encode("¿Qué medicamento puede tomar mi hijo de 2 años para bajar la fiebre?", normalize_embeddings=True)
array = np.array(question)
formatted_array = np.vectorize('{:.12f}'.format)(array)
parameterQuery = []
parameterQuery.append(str(','.join(formatted_array)))
cursorIRIS.execute("SELECT distinct(Document) FROM (SELECT VECTOR_DOT_PRODUCT(VectorizedPhrase, TO_VECTOR(?, DECIMAL)) AS similarity, Document FROM LLMRAG.DOCUMENTCHUNK) WHERE similarity > 0.6", parameterQuery)
similarityRows = cursorIRIS.fetchall()Como você pode ver, instanciamos o modelo gerador de embedding e vetorizamos a pergunta que vamos enviar ao nosso LLM. Em seguida, lançamos uma consulta à nossa tabela de dados LLMRAG.DOCUMENTCHUNK procurando aqueles vetores cuja similaridade exceda 0.6 (este valor é totalmente baseado nos critérios do desenvolvedor do produto).
Como você pode ver, o comando usado para a pesquisa é VECTOR_DOT_PRODUCT, mas não é a única opção, vamos dar uma olhada nas duas opções que temos para pesquisas de similaridade.
Produto Escalar (VECTOR_DOT_PRODUCT)
Essa operação algébrica não é mais do que a soma dos produtos de cada par de elementos que ocupam a mesma posição em seus respectivos vetores, representada da seguinte forma:
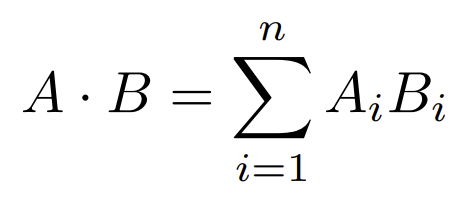
A InterSystems recomenda o uso deste método quando os vetores com os quais se trabalha são unitários, ou seja, seu módulo é 1. Para aqueles que não estão familiarizados com álgebra, o módulo é calculado da seguinte forma:

Similaridade de Cosseno (VECTOR_COSINE)
Este cálculo representa o produto escalar dos vetores dividido pelo produto de seus comprimentos e sua fórmula é a seguinte:
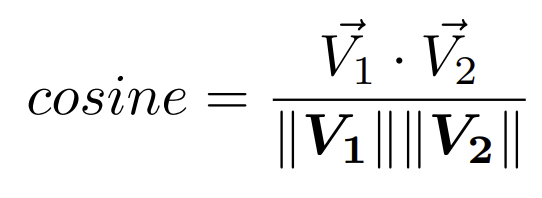
Em ambos os casos, quanto mais próximo o resultado estiver de 1, maior será a similaridade entre os vetores.
Injeção de contexto
Com a consulta acima, obteremos os textos relacionados à pergunta que enviaremos ao LLM. Em nosso caso, não vamos enviar o texto que vetorizamos, pois é mais interessante enviar o documento inteiro com a bula do medicamento, pois o modelo LLM será capaz de montar uma resposta muito mais completa com o documento inteiro. Vamos dar uma olhada em nosso código para ver como estamos fazendo isso:
for similarityRow in similarityRows:
for doc in docs_before_split:
if similarityRow[0] == doc.metadata['source'].upper():
context = context +"".join(doc.page_content)
prompt = hub.pull("rlm/rag-prompt")
rag_chain = (
{"context": lambda x: context, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("¿Qué medicamento puede tomar mi hijo de 2 años para bajar la fiebre?")Começamos com um laço for que percorrerá todos os registros vetorizados que são similares à pergunta realizada. Como em nosso exemplo, temos os documentos armazenados na memória a partir da etapa anterior de corte e vetorização, reutilizamos-o no segundo laço para extrair o texto diretamente. O ideal seria acessar o documento que teríamos armazenado em nosso sistema sem a necessidade de usar esse segundo laço for.
Uma vez que o texto dos documentos que formarão o contexto da pergunta tenha sido armazenado em uma variável, o próximo passo será informar o LLM sobre o contexto da pergunta que vamos passar a ele. Uma vez que o contexto tenha sido passado, só precisamos enviar nossa pergunta ao modelo. Neste caso, queremos saber quais medicamentos podemos dar ao nosso filho de 2 anos para baixar a febre. Vamos olhar as respostas sem contexto e com contexto:
Sem contexto:
A febre em crianças pequenas pode ser preocupante, mas é importante administrá-la adequadamente. Para uma criança de 2 anos, os medicamentos para reduzir a febre mais comumente recomendados são paracetamol (acetaminofeno) e ibuprofeno.
Com contexto:
Dalsy suspensão oral 40 mg/ml, contendo ibuprofeno, pode ser usado em crianças a partir dos 3 meses de idade para aliviar a febre. A dose recomendada para crianças de 2 anos de idade depende do seu peso e deve ser administrada por prescrição médica. Por exemplo, para uma criança com 10 kg, a dose recomendada é de 1,8 a 2,4 ml por dose, com uma dose diária máxima de 7,2 ml (288 mg). Consulte sempre o seu médico antes de administrar qualquer medicamento a uma criança.
Como você pode ver, quando não temos contexto, a resposta é bastante genérica, enquanto com o contexto apropriado, a resposta é muito mais direta e indica que deve sempre estar sob prescrição médica.
Conclusões
Nesta série de artigos, apresentamos os fundamentos do desenvolvimento de aplicativos RAG. Como você pode ver, os conceitos básicos são bastante simples, mas, como sabemos, o diabo está sempre nos detalhes. Para cada projeto, as seguintes decisões precisam ser tomadas:
- Qual modelo LLM usar? Serviço on-premise ou online?
- Qual modelo de embedding devemos usar? Funciona corretamente para a linguagem que vamos usar? Precisamos lematizar os textos que vamos vetorizar?
- Como vamos dividir nossos documentos para o contexto? Por parágrafo? Por comprimento de texto? Com sobreposições?
- Nosso contexto é baseado apenas em documentos não estruturados ou temos diferentes fontes de dados?
- Precisamos reordenar os resultados da busca vetorial com a qual extraímos o contexto? E se sim, qual modelo aplicamos?
- ...
O desenvolvimento de aplicações RAG envolve mais esforço na validação dos resultados do que no desenvolvimento técnico real da aplicação. Você deve ter certeza absoluta de que sua aplicação não fornece respostas erradas ou imprecisas, pois isso pode ter consequências graves, não apenas legais, mas também em termos de confiança.