Usando o Python no InterSystems IRIS – Calculando uma Regressão Linear Simples
Usando o Python no InterSystems IRIS – Calculando uma Regressão Linear Simples
Olá,
Neste artigo vamos ver como usar o python para calcular uma regressão linear simples no Iris.
A regressão linear simples é um modelo estatístico que tem como objetivo apontar como será o comportamento de uma variável dependente (y) em relação a uma variável independente (x), ou seja, a regressão linear simples é uma maneira de verificar a relação entre duas variáveis.
A regressão linear simples pode ser utilizada, por exemplo, para prever o volume de vendas baseado no investimento em propaganda, ou o valor de um imóvel baseado no seu tamanho em m2, ou o consumo de combustível baseado na velocidade média de um carro.
A regressão linear nos dá como resposta informações que podem ajudar a entender o modelo: o coeficiente angular, o R2 e o intercepto, que explicamos a seguir:
Coeficiente Angular: É uma medida que indica o quanto a variável dependente (y) muda para cada unidade de incremento na variável independente (x). Se for negativo, o coeficiente angular indica que as variáveis são inversamente proporcionais, ou seja, quando uma aumenta a outra diminui. Se for positivo o coeficiente angular aponta que as variáveis são proporcionais, ou seja, aumentam ou diminuem proporcionalmente. Se for zero não há relação linear entre as variáveis. Por exemplo, um coeficiente angular de valor 2 nos diz que cada aumento de 1 em x causará um aumento de 2 em y.
R2 ou Coeficiente de Determinação: É uma métrica usada para avaliar a qualidade de um modelo de regressão, que tem valores entre zero e um. Quanto mais próximo de um, melhor o modelo explica os dados. Quanto mais próximo de zero, o modelo não explica os dados. Um R2 de 0,96 nos diz que 96% dos elementos da amostra podem ser explicados pela relação entre as variáveis.
Intercepto: É o valor onde a linha do gráfico da regressão cruza o eixo Y. Ele representa o valor de y quando x é igual a zero. É o valor de y quando x não causa influência.
Em python existe a biblioteca scikit-learn que tem a classe LinearRegression, que implementa o cálculo de regressão linear tanto simples (quando temos uma variável independente) quanto múltipla (quando temos múltiplas variáveis independentes).
Vamos em frente. Primeiro precisamos carregar as seguintes bibliotecas no nosso ambiente:
- sklearn.linear_model,
- joblib
- pandas
- numpy
- json
- matplotlib
- matplotlib.pyplot
Para maiores detalhes de como importar essas bibliotecas veja o artigo anterior: https://pt.community.intersystems.com/post/usando-o-python-no-intersystems-iris-%E2%80%93-exportando-dados-para-o-excel
Uma vez instaladas as bibliotecas que vamos precisar no nosso método vamos ao código:
Class Python.Estatistica [ Abstract ]
{
ClassMethod CalcularRegressaoLinear(modelo As %String, xValores As %ListOfDataTypes, yValores As %ListOfDataTypes, estimativa As %Float) As %String [ Language = python ]
{
import json
import joblib
import pandas as pd
from sklearn.linear_model import LinearRegression
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
matplotlib.use("Agg")
# Converte listas IRIS para listas Python
x_valores = list(xValores) # variavel independente
y_valores = list(yValores) # variavel dependente
# Cria dataframe Pandas com os dados
df = pd.DataFrame({'x': x_valores, 'y': y_valores})
# Reformatando x1 para uma matriz 2D exigida pelo scikit-learn
X = df[['x']]
y = df['y']
# Inicializa e ajusta o modelo de regressão linear
model = LinearRegression()
model.fit(X, y)
# Extrai os coeficientes da regressão
coeficiente_angular = model.coef_[0]
intercepto = model.intercept_
r_quadrado = model.score(X, y)
# Salva o modelo treinado em um arquivo para uso posterior
joblib.dump(model, 'c:\\temp\\' + modelo + '.pkl')
# Previsão para a linha de regressão
x_pred = np.linspace(df['x'].min(), df['x'].max(), 100).reshape(-1, 1) # Valores para a linha de regressão
y_pred = model.predict(x_pred)
# Geração do gráfico
plt.figure(figsize=(8, 6))
plt.scatter(x_valores, y_valores, color='blue', label='Dados Originais')
plt.plot(x_pred, y_pred, color='red', label='Linha da Regressão')
plt.scatter(0, intercepto, color="purple", zorder=5, label="Ponto do intercepto")
plt.title('Regressão Linear')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
# Salvando o gráfico como imagem
caminho_arquivo = 'c:\\temp\\' + modelo + '.png'
plt.savefig(caminho_arquivo, dpi=300, bbox_inches='tight')
plt.close()
# Faz uma previsão opcional, se estimativa for fornecido (maior que zero)
if estimativa > 0:
# Prepara o valor de entrada como uma matriz 2D exigida pelo scikit-learn
X_novo = [[estimativa]]
# Faz a previsão com o modelo treinado
previsao = model.predict(X_novo)[0]
else:
previsao = None
# Formata os resultados em JSON
resultado = {
'coeficiente_angular': coeficiente_angular,
'intercepto': intercepto,
'r_quadrado': r_quadrado,
'estimativa': previsao
}
return json.dumps(resultado)
}
}
Nosso código começa carregando as bibliotecas que serão utilizadas. Depois trata a entrada recebida (listas do Iris) transformando em listas python e depois em um dataframe pandas.
Na sequência o código cria o modelo utilizando as variáveis de entrada fornecidas e recupera os parâmetros da regressão (coeficiente angular, inrtercepto e R2).
O código então utiliza a joblib para salvar em um arquivo do sistema operacional o model para uso posterior (vamos ver mais à frente).
Então o código calcula os dados parapresentação da linha de regressão no gráfico e gera um arquivo de imagem com o gráfico da regressão.
Se o parâmetro de previsão opcional tiver sido fornecido o código calcula o valor previsto (y) para o valor informado de entrada (x).
Por fim o código apresenta os dados da regressão e o valor previsto em uma string JSON. O código está bem comentado, apresentando passo a passo o que está acontecendo.
Vamos ver o nosso método em funcionamento. Primeiro vamos simular uma fábrica de sorvetes que quer estimar a quantidade de picolés que irá vender baseado na temperatura do dia. Vamos montar a chamada do nosso método:
Set xValues = ##class(%ListOfDataTypes).%New()
Set yValues = ##class(%ListOfDataTypes).%New()
//Popula a lista de valores para temperatura
Do xValues.Insert(6)
Do xValues.Insert(9)
Do xValues.Insert(12)
Do xValues.Insert(15)
Do xValues.Insert(18)
Do xValues.Insert(21)
Do xValues.Insert(24)
Do xValues.Insert(27)
Do xValues.Insert(30)
Do xValues.Insert(33)
Do xValues.Insert(36)
Do xValues.Insert(39)
Do xValues.Insert(42)
Do xValues.Insert(45)
//Popula a lista de valores para picolés vendidos
Do yValues.Insert(5)
Do yValues.Insert(10)
Do yValues.Insert(25)
Do yValues.Insert(50)
Do yValues.Insert(65)
Do yValues.Insert(90)
Do yValues.Insert(115)
Do yValues.Insert(145)
Do yValues.Insert(180)
Do yValues.Insert(220)
Do yValues.Insert(265)
Do yValues.Insert(310)
Do yValues.Insert(360)
Do yValues.Insert(400)
Temos então a seguinte relação temperatura->picolés vendidos:
|
Temperatura |
Picolés Vendidos |
|
6 |
5 |
|
9 |
10 |
|
12 |
25 |
|
15 |
50 |
|
18 |
65 |
|
21 |
90 |
|
24 |
115 |
|
27 |
145 |
|
30 |
180 |
|
33 |
220 |
|
36 |
265 |
|
39 |
310 |
|
42 |
360 |
|
45 |
400 |
Agora chamamos nosso método passando os parâmetros informados:
Set resultado = ##class(Python.Estatistica).CalcularRegressaoLinear("regressao_linear_venda_picole", xValues, yValues, 0)
Veja a tela com a chamada do método:
.png)
A chamada do método tem os seguintes parâmetros:
- Lista de valores independentes (temperaturas)
- Lista de valores dependentes (picolés vendidos)
- Nome do arquivo onde será gravado o modelo de dados (.PKL) e imagem do gráfico (.PNG) no diretório c:\temp local (se o ambiente for Windows. Caso não seja troque este local no código do método)
- Valor da variável independente para calcular uma previsão baseada no modelo que será criado (opcional)
Como resposta teremos uma string JSON com as seguintes informações:
{"coeficiente_angular": 10.35164835164835, "intercepto": -103.96703296703294, "r_quadrado": 0.9616620066324209, "estimativa": null}
Entendendo então a resposta:
- coeficiente_angular sendo positivo informa que a relação entre temperatura e picolés vendidos é proporcional, ou seja, se a temperatura aumenta, o número de picolés vendidos aumenta também.
- intercepto informa o valor para y quando x não o afeta. No nosso caso o valor apresentado não faz sentido, pois a venda de picolés só pode chegar a zero, nunca será negativa. Matematicamente ele é coerente, mas não é real. Assim assumimos, neste caso, o zero como sendo o valor de referência. Podemos forçar o modelo a travar o intercepto em zero, mas para nosso exemplo vamos apresentar o valor calculado.
- r_quadrado aponta que o modelo está ajustado aos dados. Cerca de 96% dos valores podem ser explicados pelo modelo com os dados fornecidos.
- estimativa é null pois não passamos nenhum valor para cálculo de uma estimativa. Se tivéssemos passado aqui algum valor de temperatura seria devolvida a previsão de venda de picolés com aquela temperatura informada.
Abrindo o gráfico gerado do nosso modelo podemos observar o comportamento dos dados em relação a linha da regressão:

Veja que o gráfico mostra que à medida que a temperatura aumenta a venda de picolés também aumenta, comprovando a relação entre as variáveis. Os pontos em azul são os valores que nós fornecemos para o cálculo e eles se apresentam dispostos ao longo da reta da regressão, mostrando a boa relação entre as variáveis. Não vemos nenhum ponto ou conjunto de pontos destacados da reta.
Como salvamos o modelo gerado podemos utilizá-lo para realizar novas previsões baseadas nos dados que o modelo recebeu para treinamento. Para isso vamos implementar um segundo método na nossa classe:
ClassMethod Prever(modelo As %String, estimativa As %Float) As %String [ Language = python ]
{
import json
import joblib
# Carrega o modelo salvo
model = joblib.load('c:\\temp\\' + modelo + '.pkl')
# Prepara o valor de entrada como uma matriz 2D
X_novo = [[estimativa]]
# Faz a previsão com o modelo armazenado
previsao = model.predict(X_novo)[0]
# Retorna o resultado como JSON
resultado = {
'previsao': previsao
}
return json.dumps(resultado)
}
Este segundo método recebe o nome do modelo e um valor de entrada, carrega o modelo de dados que foi salvo anteriormente, calcula o valor previsto para o valor de entrada e apresenta uma string JSON de saída. Vamos fazer alguns testes:

Chamamos nosso método Prever passando o nome do modelo que criamos no passo anterior, e agora passamos um valor de temperatura para que seja previsto a quantidade de picolés que serão vendidos. Para este modelo, com os dados fornecidos de treinamento, a previsão é que serão vendidos 413 picolés se a temperatura chegar a 50 graus, e 517 se a temperatura chegar a 60 graus.
Agora vamos imaginar que um pesquisador queira ver a relação entre óbitos causados por uma doença versus pessoas vacinadas em uma população. Podemos utilizar nossa classe para realizar este estudo. Primeiro vamos criar as listas X e Y com o número de pessoas vacinadas e o número de óbitos:
Set xValues = ##class(%ListOfDataTypes).%New()
Set yValues = ##class(%ListOfDataTypes).%New()
Do xValues.Insert(100)
Do xValues.Insert(200)
Do xValues.Insert(300)
Do xValues.Insert(400)
Do xValues.Insert(500)
Do xValues.Insert(600)
Do xValues.Insert(700)
Do xValues.Insert(800)
Do xValues.Insert(900)
Do xValues.Insert(1000)
Do yValues.Insert(90)
Do yValues.Insert(85)
Do yValues.Insert(70)
Do yValues.Insert(65)
Do yValues.Insert(50)
Do yValues.Insert(45)
Do yValues.Insert(35)
Do yValues.Insert(30)
Do yValues.Insert(20)
Do yValues.Insert(15)
Então temos a seguinte relação entre os valores:
|
Pessoas Vacinadas |
Óbitos |
|
100 |
90 |
|
200 |
85 |
|
300 |
70 |
|
400 |
65 |
|
500 |
50 |
|
600 |
45 |
|
700 |
35 |
|
800 |
30 |
|
900 |
20 |
|
1000 |
15 |
Chamando nosso método CalcularRegressaoLinear teremos a seguinte resposta:

Conforme a tela acima, recebemos com resposta do nosso método as seguintes informações:
|
Parâmetro |
Valor |
|
coeficiente_angular |
-0.08636363636363634 |
|
intercepto |
97.99999999999999 |
|
r_quadrado |
0.9888965995836225 |
O coeficiente angular negativo nos informa que as variáveis são inversamente proporcionais, ou seja, se uma aumenta a outra diminui.
O intercepto neste caso faz sentido pois temos uma quantidade de óbitos se a população não foi vacinada.
O r_quadrado nos diz que os valores informados são bem explicados pelo modelo em 98% do total.
Podemos ver o gráfico da regressão:

Note que neste exemplo, à medida que o número de vacinados aumenta, o número de óbitos diminui. É a relação inversa entre vacinados e óbitos apresentada pelo parâmetro coeficiente_angular. Nosso intercepto neste modelo faz sentido, e os valores estão bem dispostos ao longo da linha da regressão. Mais uma vez podemos pedir a previsão de dados baseado no modelo armazenado:
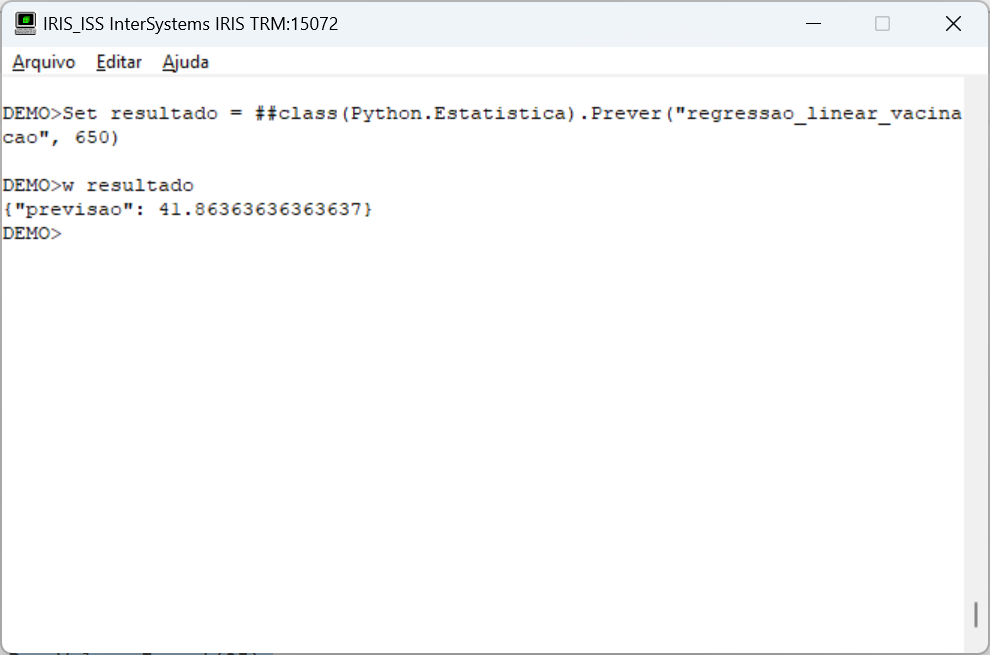
Pedimos ao método Prever para nos devolver a quantidade de óbitos se a população tivesse 650 vacinados. E o resultado foi 41 óbitos.
Este é só um exemplo simples de uso de bibliotecas para estatística que podemos lançar mão nos códigos, agora que o Iris tem integração com o python.
Até a próxima!
Comments
Muito bom Júlio Esquerdo !
acabei de reproduzir o código e testei .
100% ok 👍