Modelos LLM e Aplicações RAG Passo a Passo - Parte I
Você provavelmente já ouviu falar muito sobre LLMs (Large Language Models) e o desenvolvimento associado de aplicações RAG (Retrieval Augmented Generation) no último ano. Bem, nesta série de artigos explicaremos os fundamentos de cada termo usado e veremos como desenvolver uma aplicação RAG simples.
O que é um LLM?
Modelos LLM fazem parte do que conhecemos como IA generativa e sua fundação é a vetorização de enormes quantidades de textos. Por meio dessa vetorização, obteremos um espaço vetorial (desculpe a redundância) em que palavras ou termos relacionados estarão mais próximos uns dos outros do que palavras menos relacionadas
.png)
Embora a maneira mais simples de visualizá-lo seja um gráfico 3D como o da imagem anterior, o número de dimensões pode ser tão grande quanto desejado; quanto maiores as dimensões, maior a precisão nas relações entre termos e palavras e maior o consumo de recursos do mesmo
Esses modelos são treinados com conjuntos de dados massivos que permitem que eles tenham informações suficientes para serem capazes de gerar textos relacionados ao pedido feito a eles, mas... como o modelo sabe quais termos estão relacionados à pergunta feita? Muito simples, pela chamada "similaridade" entre vetores, isso não é mais do que um cálculo matemático que nos permite elucidar a distância entre dois vetores. Os cálculos mais comuns são:
Através desse tipo de cálculo, o LLM será capaz de montar uma resposta coerente com base em termos próximos à pergunta feita em relação ao seu contexto.
Tudo isso é muito bom, mas esses LLMs têm uma limitação quando se trata de sua aplicação para usos específicos, já que as informações com as quais foram treinados costumam ser bastante "gerais". Se quisermos que um modelo LLM se adapte às necessidades específicas do nosso negócio, teremos duas opções:
Fine-tuning
O fine-tuning é uma técnica que permite o re treinamento de modelos LLM com dados relacionados a um tópico específico (linguagem procedimental, terminologia médica, etc.). Usando essa técnica, podemos ter modelos mais adequados às nossas necessidades sem precisar treinar um modelo do zero.
A principal desvantagem dessa técnica é que ainda precisamos fornecer ao LLM uma enorme quantidade de informações para tal re treinamento e, às vezes, isso pode ficar "aquém" das expectativas de um determinado negócio.
Retrieval Augmented Generation
RAG é uma técnica que permite que o LLM inclua o contexto necessário para responder a uma determinada pergunta sem precisar treinar ou re treinar o modelo especificamente com a informação relevante.
Como incluímos o contexto necessário em nosso LLM? É muito simples: ao enviar a pergunta para o modelo, diremos explicitamente que ele deve levar em conta a informação relevante que anexamos para responder à consulta feita, e para isso, usaremos bancos de dados vetoriais dos quais podemos extrair o contexto relacionado à pergunta submetida.
Qual é a melhor opção para o meu problema, Fine tuning ou RAG?
Ambas as opções têm suas vantagens e desvantagens. Por um lado, o Fine tuning permite que você inclua todas as informações relacionadas ao problema que deseja resolver dentro do modelo LLM, sem precisar de tecnologias de terceiros como um banco de dados vetorial para armazenar contextos. Por outro lado, ele te prende ao modelo re treinado, e se ele não atender às expectativas do modelo, migrar para um novo pode ser bastante tedioso.
Por outro lado, o RAG precisa de recursos como buscas vetoriais para poder saber qual é o contexto mais exato para a pergunta que estamos passando para nosso LLM. Esse contexto deve ser armazenado em um banco de dados vetorial no qual realizaremos consultas posteriormente para extrair dita informação. A principal vantagem (além de dizer explicitamente ao LLM para usar o contexto que fornecemos) é que não estamos presos ao modelo LLM, podendo trocá-lo por outro mais adequado às nossas necessidades.
Como apresentamos no início do artigo, vamos nos concentrar no desenvolvimento de um exemplo de aplicação em RAG (sem grandes pretensões, apenas para demonstrar como você pode começar).
Arquitetura de um Projeto RAG
Vamos dar uma breve olhada em qual arquitetura seria necessária para um projeto RAG:
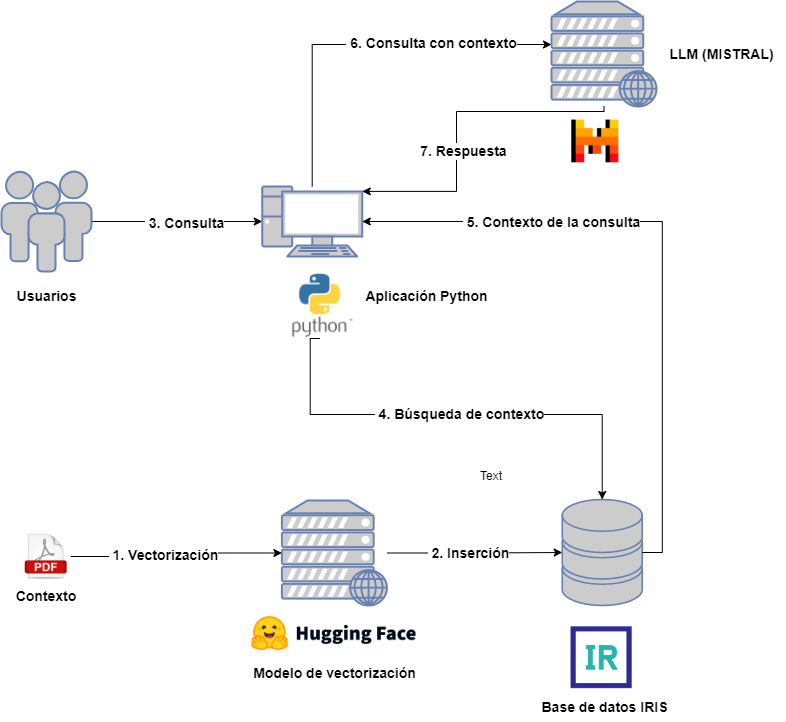
Por um lado, teremos os seguintes atores:
- Usuários: que interagirão com o LLM enviando consultas.
- Contexto: Fornecido antecipadamente para ser incluído nas consultas do usuário.
- Modelo de vetorização: para vetorizar os diferentes documentos associados ao contexto.
- Banco de dados vetorial: neste caso será o IRIS e armazenará as diferentes partes vetorizadas dos documentos de contexto.
- LLM: Modelo LLM que receberá as consultas, para este exemplo escolhemos o MISTRAL.
- Aplicação Python: destinada a consultar o banco de dados vetorial para extração de contexto e sua inclusão na consulta LLM.
Para não complicar demais o diagrama, omiti a aplicação responsável por capturar os documentos do contexto, sua divisão e posterior vetorização e inserção. Na aplicação associada você pode consultar esta etapa, bem como a seguinte relacionada à consulta para extração, mas não se preocupe, veremos isso com mais detalhes nos próximos artigos.
Associado a este artigo você tem o projeto que usaremos como referência para explicar cada etapa em detalhe. Este projeto está containerizado no Docker e você pode encontrar uma aplicação Python usando Jupyter Notebook e uma instância do IRIS. Você precisará de uma conta no MISTRAL AI para incluir a API Key que permite lançar consultas.
.png)
No próximo artigo veremos como registrar nosso contexto em um banco de dados vetorial. Fique ligado!
Comments
Obrigado @Heloisa Paiva !