Vamos montar nossa próxima integração utilizando o adaptador SQL Inbound Adapter. Este adaptador permite acessar uma tabela externa ao IRIS e consumir seus registros.
O mesmo serviço com a possibilidade de receber várias consultas SQL diferentes e sempre entregar o resultado independente de quantas colunas distintas tenham essas diferentes consultas. Aqui demonstro como pode ser possível montar esse tipo de serviço utilizando o Service Bus da Intersystems.
Possível cenário (Desconsiderar o uso de um BI):
Vamos pensar em um painel real time onde iremos fornecer as informações de consumo de um material por região para o setor de compras e teremos as informações do nome do produto, fabricante e quantidade por exemplo.
O FHIR (Fast Healthcare Interoperability Resources) é o padrão mais utilizado pelo mercado para interoperar e armazenar dados em saúde. Trata-se de um padrão que mapeia dezenas de recursos de dados (Pacientes, Observações, Medicações, Diagnósticos, Alergias, Vacinas, Faturamento, Provedores de Saúde, Atendimentos, dentre outros) e seus relacionamentos (Medicações do Paciente, por exemplo). O acesso a todas estas estruturas de dados se dá pelo uso de APIs REST em formato JSON ou XML. A princípio, a maioria dos fornecedores de soluções FHIR, não disponibiliza acesso aos dados no formato SQL.
DNA Similarity and Classification é uma API REST utilizando a tecnologia InterSystems Vector Search para investigar semelhanças genéticas e classificar eficientemente sequências de DNA. Este é um aplicativo que utiliza técnicas de inteligência artificial, como aprendizado de máquina, aprimorado por recursos de pesquisa vetorial, para classificar famílias genéticas e identificar DNAs semelhantes conhecidos a partir de um DNA de entrada desconhecido.
Em alguns dos últimos artigos, eu falei sobre tipos entre IRIS e Python, e ficou claro que não é tão fácil acessar objetos de um lado pelo outro.
Por sorte, o trabalho já foi feito para criar o SQLAlchemy-iris (clique no link para ver na Open Exchange), o que faz tudo muito mais fácil para o Python acessar os objetos do IRIS, e eu vou mostrar como começar.
Desde o Caché 2017, o mecanismo SQL inclui um novo conjunto de estatísticas. Ele registra o número de vezes que uma consulta é executada e o tempo que leva para executá-la.
Apache Superset é uma plataforma moderna de exploração e visualização de dados. O Superset pode substituir ou trazer ganhos para as ferramentas proprietárias de business intelligence para muitas equipes. O Superset integra-se bem com uma variedade de fontes de dados.
E agora é possível usar também com o InterSystems IRIS.
Uma demo online está disponível e usa IRIS Cloud SQL como sua fonte de dados.
Recentemente, eu queria obter uma lista de todas as consultas em cache e seus textos. Veja como fazer isso. Primeiro, crie um procedimento SQL retornando texto de consulta de cache a partir de um nome de rotina de consulta em cache:
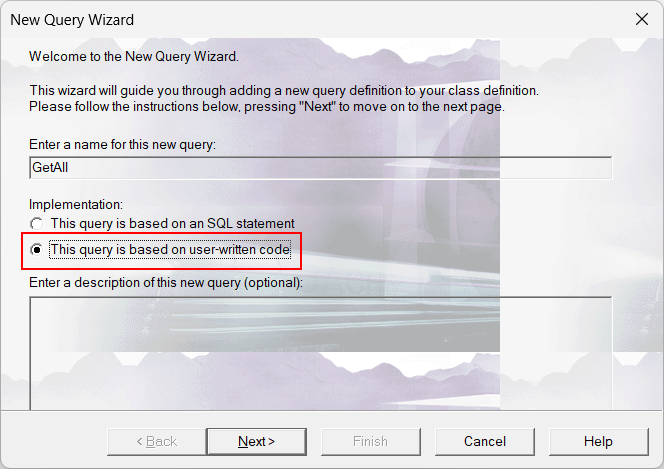
Eu criei uma classe que gera código para query customizada a partir de uma global qualquer em um determinado namespace, fazendo com que a global responda ao padrão SQL imediatamente.
Esse artigo tem a intenção de ser um simples tutorial sobre como criar conexões ODBC e trabalhar com elas, já que eu achei o assunto um pouco confuso quando estava começando, mas tive pessoas incríveis que pegaram minha mão e me guiaram para conseguir, e eu acredito que todos merecem esse tipo de ajuda também.
Vou dividir cada pequena parte em seções, então sinta-se à vontade para pular para a que sentir necessidade, apesar de eu recomendar ler o texto na íntegra.
Como você sabe, o IRIS da InterSystems além de globais, objetos, documentos e modelos de dados XML também suporta relacional onde o SQL é esperado como uma linguagem para lidar com os dados.
E como em outros DBMS relacionais, o InterSystems IRIS possui seu próprio dialeto.
Começo esta postagem para dar suporte a uma folha de dicas SQL e convido você a compartilhar seus favoritos - atualizarei o conteúdo com os comentários recebidos.
Com o InterSystems IRIS 2022.2, apresentamos o armazenamento colunar como uma nova opção para a persistência das suas tabelas SQL do IRIS que pode otimizar suas consultas analíticas por ordem de magnitude. O recurso está marcado como experimental em 2022.2 e 2022.3, mas se tornará um recurso de produção totalmente compatível no próximo lançamento de 2023.1.
A documentação do produto e este vídeo introdutório já descrevem as diferenças entre o armazenamento em linhas, que ainda é o padrão no IRIS e é usado pela nossa base de clientes, e o armazenamento de tabela colunar, além de fornecer orientações de alta qualidade para a escolha do layout de armazenamento adequado para seu caso de uso. Neste artigo, vamos falar sobre esse tema e compartilhar algumas recomendações com base nos princípios de modelagem do setor, testes internos e feedback dos participantes do Programa de Acesso Antecipado.
Isso pode ser conseguido usando o procedimento CSV() da classe %SQL.Util.Procedures . Abaixo está o exemplo de uso do código. (Assumindo que o arquivo test.csv está em c:\temp.)
As consultas utilizando intervalo de datas estão muito lentas para você? O desempenho do SQL te desanima? Eu tenho um estranho truque que pode te ajudar! (Desenvolvedores de SQL odeiam isso!)*
A personalização direta de procedimentos armazenados com ObjectScript tem sido útil para acessar o armazenamento NoSQL e as mensagens externas pela integração, para apresentar a saída em um formato tabular.
Uma VIEW em SQL é basicamente uma instrução SQL preparada. Deve ser executado e montado como qualquer outra consulta SQL. VIEW MATERIALIZADA significa que o conteúdo é coletado antes das mãos e pode ser recuperado com bastante rapidez. Eu vi o conceito primeiro com meu concorrente favorito chamado O * e eles fizeram muito barulho sobre isso.
{ favorite: because I could win every benchmark against them }
Introdução: Quando o IRISTEMP Armazena Dados Demais
Então, você verificou seu servidor e viu que o IRISTEMP está crescendo demais. Não precisa entrar em pânico. Vamos investigar o problema antes que seu armazenamento acabe.
Passo 1: Confirmar o Problema de Crescimento do IRISTEMP
Antes de assumir que o IRISTEMP é o problema, vamos verificar seu tamanho real.
Temos um delicioso conjunto de dados com receitas escritas por vários usuários do Reddit, porém, a maioria das informações é texto livre, como o título ou a descrição de um post.
De acordo com o relatório OWASP Top Ten de 2021, um documento de referência na área de segurança de aplicações web, as injeções SQL ocupam a terceira posição entre os riscos mais críticos. Este relatório, disponível em OWASP Top 10: Injection, destaca a gravidade dessa ameaça e a necessidade de implementar medidas de proteção eficazes.
Uma injeção SQL ocorre quando um atacante malicioso consegue inserir código SQL não autorizado em uma consulta enviada a um banco de dados. Esse código, disfarçado nas entradas do usuário, pode então ser executado pelo banco de dados, causando ações indesejáveis como o roubo de dados confidenciais, a modificação ou a exclusão de informações sensíveis, ou ainda a interrupção do funcionamento da aplicação.
Esse é um tutorial simples da forma mais rápida que eu achei para criar uma base de dados de exemplo para quaisquer razões, como realizar testes, fazer exemplos para tutoriais, etc.
Criando um namespace
Abra o terminal
Escreva o comando "D $SYSTEM.SQL.Shell()"
Escreva"CREATE DATABASE " e o nome desejado para o namespace.
Agora você tem um namespace novo de uma forma muito mais rápida que criando pelo Portal de Administração - que é claro que oferece muito mais opções de configuração.
 Por likes
Por likes.png)
 Open Exchange app
Open Exchange app.png)
 }
}.png)