Carregue um conjunto de dados de receitas com Foreign Tables e analise-o usando LLMs com Embedded Python (Langchain + OpenAI)
Temos um delicioso conjunto de dados com receitas escritas por vários usuários do Reddit, porém, a maioria das informações é texto livre, como o título ou a descrição de um post. Vamos descobrir como carregar o conjunto de dados facilmente, extrair algumas características e analisá-las usando recursos do modelo de linguagem grande da OpenAI no Embedded Python e no framework Langchain.
Carregando o conjunto de dados
Primeiro de tudo, precisamos carregar o conjunto de dados ou podemos só nos conectar a ele?
Há diferentes maneiras de alcançar isso: por exemplo, é possível usar o CSV Record Mapper em uma produção de interoperabilidade ou até em aplicativos legais do OpenExchange, como csvgen.
Vamos usar o Foreign Tables. Um recurso bastante útil para projetar dados armazenados fisicamente em outro lugar no IRIS SQL. Podemos usar isso para ter uma primeira visão dos arquivos do conjunto de dados.
Criamos um Foreign Server:
CREATE FOREIGN SERVER dataset FOREIGN DATA WRAPPER CSV HOST '/app/data/'
E, em seguida, uma Foreign Table que se conecta ao arquivo CSV:
CREATE FOREIGN TABLE dataset.Recipes (
CREATEDDATE DATE,
NUMCOMMENTS INTEGER,
TITLE VARCHAR,
USERNAME VARCHAR,
COMMENT VARCHAR,
NUMCHAR INTEGER
) SERVER dataset FILE 'Recipes.csv' USING
{
"from": {
"file": {
"skip": 1
}
}
}
É isso, imediatamente podemos executar consultas SQL em "dataset.Recipes":
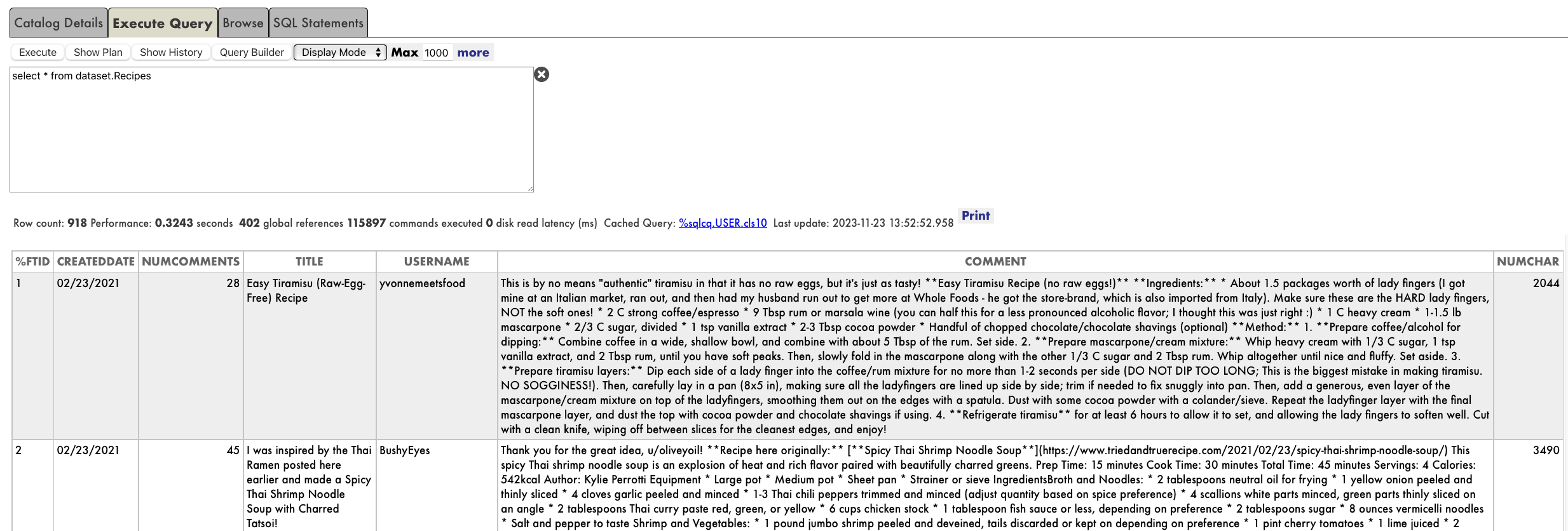
## Quais dados são necessários? O conjunto de dados é interessante e estamos com fome. No entanto, se quisermos decidir uma receita para cozinhar, será preciso mais algumas informações que possamos usar para análise.
Vamos trabalhar com duas classes persistentes (tabelas):
- yummy.data.Recipe: uma classe que contém o título e a descrição da receita e algumas outras propriedades que queremos extrair e analisar, por exemplo, Score, Difficulty, Ingredients, CuisineType, PreparationTime (nota, dificuldade, ingredientes, tipo de culinária, tempo de preparo)
- yummy.data.RecipeHistory: uma classe simples para registrar o que estamos fazendo com a receita
Podemos agora carregar nossas tabelas "yummy.data*" com o conteúdo do conjunto de dados:
do ##class(yummy.Utils).LoadDataset()
Parece bom, mas ainda precisamos descobrir como vamos gerar os dados para os campos Score, Difficulty, Ingredients, PreparationTime e CuisineType.
## Analise as receitas Queremos processar cada título e descrição de receita e:
- Extrair informações como Difficulty, Ingredients, CuisineType etc.
- Criar nossa própria nota com base em nossos critérios para que possamos decidir o que queremos cozinhar.
Vamos usar o seguinte:
- yummy.analysis.Analysis - uma estrutura de análise genérica que podemos reutilizar para desenvolver mais análises.
- yummy.analysis.SimpleOpenAI - uma análise que usar o Embedded Python + framework Langchain + modelo LLM da OpenAI.
LLM (modelos de linguagem grande) são realmente uma ótima ferramenta para processar linguagem natural.
LangChain está pronto para uso no Python, então podemos usá-lo diretamente no InterSystems IRIS usando o Embedded Python.
A classe "SimpleOpenAI" completa fica assim:
/// Análise simples da OpenAI para receitas
Class yummy.analysis.SimpleOpenAI Extends Analysis
{
Property CuisineType As %String;
Property PreparationTime As %Integer;
Property Difficulty As %String;
Property Ingredients As %String;
/// Execute
/// Você pode tentar isto a partir de um terminal:
/// set a = ##class(yummy.analysis.SimpleOpenAI).%New(##class(yummy.data.Recipe).%OpenId(8))
/// do a.Run()
/// zwrite a
Method Run()
{
try {
do ..RunPythonAnalysis()
set reasons = ""
// meus tipos de culinária favoritos
if "spanish,french,portuguese,italian,korean,japanese"[..CuisineType {
set ..Score = ..Score + 2
set reasons = reasons_$lb("It seems to be a "_..CuisineType_" recipe!")
}
// não quero passar o dia todo cozinhando :)
if (+..PreparationTime < 120) {
set ..Score = ..Score + 1
set reasons = reasons_$lb("You don't need too much time to prepare it")
}
// bônus para ingredientes favoritos!
set favIngredients = $listbuild("kimchi", "truffle", "squid")
for i=1:1:$listlength(favIngredients) {
set favIngred = $listget(favIngredients, i)
if ..Ingredients[favIngred {
set ..Score = ..Score + 1
set reasons = reasons_$lb("Favourite ingredient found: "_favIngred)
}
}
set ..Reason = $listtostring(reasons, ". ")
} catch ex {
throw ex
}
}
/// Atualize a receita com o resultado da análise
Method UpdateRecipe()
{
try {
// chame a implementação de classe mãe primeiro
do ##super()
// adicione resultados de análises da OpenAI específicos
set ..Recipe.Ingredients = ..Ingredients
set ..Recipe.PreparationTime = ..PreparationTime
set ..Recipe.Difficulty = ..Difficulty
set ..Recipe.CuisineType = ..CuisineType
} catch ex {
throw ex
}
}
/// Execute a análise usando o embedded Python + Langchain
/// do ##class(yummy.analysis.SimpleOpenAI).%New(##class(yummy.data.Recipe).%OpenId(8)).RunPythonAnalysis(1)
Method RunPythonAnalysis(debug As %Boolean = 0) [ Language = python ]
{
# load OpenAI APIKEY from env
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv('/app/.env')
# account for deprecation of LLM model
import datetime
current_date = datetime.datetime.now().date()
# date after which the model should be set to "gpt-3.5-turbo"
target_date = datetime.date(2024, 6, 12)
# set the model depending on the current date
if current_date > target_date:
llm_model = "gpt-3.5-turbo"
else:
llm_model = "gpt-3.5-turbo-0301"
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
from langchain.output_parsers import ResponseSchema
from langchain.output_parsers import ResponseSchema
# init llm model
llm = ChatOpenAI(temperature=0.0, model=llm_model)
# prepare the responses we need
cuisine_type_schema = ResponseSchema(
name="cuisine_type",
description="What is the cuisine type for the recipe? \
Answer in 1 word max in lowercase"
)
preparation_time_schema = ResponseSchema(
name="preparation_time",
description="How much time in minutes do I need to prepare the recipe?\
Anwer with an integer number, or null if unknown",
type="integer",
)
difficulty_schema = ResponseSchema(
name="difficulty",
description="How difficult is this recipe?\
Answer with one of these values: easy, normal, hard, very-hard"
)
ingredients_schema = ResponseSchema(
name="ingredients",
description="Give me a comma separated list of ingredients in lowercase or empty if unknown"
)
response_schemas = [cuisine_type_schema, preparation_time_schema, difficulty_schema, ingredients_schema]
# get format instructions from responses
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()
analysis_template = """\
Interprete and evaluate a recipe which title is: {title}
and the description is: {description}
{format_instructions}
"""
prompt = ChatPromptTemplate.from_template(template=analysis_template)
messages = prompt.format_messages(title=self.Recipe.Title, description=self.Recipe.Description, format_instructions=format_instructions)
response = llm(messages)
if debug:
print("======ACTUAL PROMPT")
print(messages[0].content)
print("======RESPONSE")
print(response.content)
# populate analysis with results
output_dict = output_parser.parse(response.content)
self.CuisineType = output_dict['cuisine_type']
self.Difficulty = output_dict['difficulty']
self.Ingredients = output_dict['ingredients']
if type(output_dict['preparation_time']) == int:
self.PreparationTime = output_dict['preparation_time']
return 1
}
}
O método "RunPythonAnalysis" é onde tudo relacionado a OpenAI acontece :). Você pode executá-lo diretamente no terminal para uma receita específica:
do ##class(yummy.analysis.SimpleOpenAI).%New(##class(yummy.data.Recipe).%OpenId(12)).RunPythonAnalysis(1)
Vamos obter uma saída assim:
USER>do ##class(yummy.analysis.SimpleOpenAI).%New(##class(yummy.data.Recipe).%OpenId(12)).RunPythonAnalysis(1)
======ACTUAL PROMPT
Interprete and evaluate a recipe which title is: Folded Sushi - Alaska Roll
and the description is: Craving for some sushi but don't have a sushi roller? Try this easy version instead. It's super easy yet equally delicious!
[Video Recipe](https://www.youtube.com/watch?v=1LJPS1lOHSM)
# Ingredients
Serving Size: \~5 sandwiches
* 1 cup of sushi rice
* 3/4 cups + 2 1/2 tbsp of water
* A small piece of konbu (kelp)
* 2 tbsp of rice vinegar
* 1 tbsp of sugar
* 1 tsp of salt
* 2 avocado
* 6 imitation crab sticks
* 2 tbsp of Japanese mayo
* 1/2 lb of salmon
# Recipe
* Place 1 cup of sushi rice into a mixing bowl and wash the rice at least 2 times or until the water becomes clear. Then transfer the rice into the rice cooker and add a small piece of kelp along with 3/4 cups plus 2 1/2 tbsp of water. Cook according to your rice cookers instruction.
* Combine 2 tbsp rice vinegar, 1 tbsp sugar, and 1 tsp salt in a medium bowl. Mix until everything is well combined.
* After the rice is cooked, remove the kelp and immediately scoop all the rice into the medium bowl with the vinegar and mix it well using the rice spatula. Make sure to use the cut motion to mix the rice to avoid mashing them. After thats done, cover it with a kitchen towel and let it cool down to room temperature.
* Cut the top of 1 avocado, then slice into the center of the avocado and rotate it along your knife. Then take each half of the avocado and twist. Afterward, take the side with the pit and carefully chop into the pit and twist to remove it. Then, using your hand, remove the peel. Repeat these steps with the other avocado. Dont forget to clean up your work station to give yourself more space. Then, place each half of the avocado facing down and thinly slice them. Once theyre sliced, slowly spread them out. Once thats done, set it aside.
* Remove the wrapper from each crab stick. Then, using your hand, peel the crab sticks vertically to get strings of crab sticks. Once all the crab sticks are peeled, rotate them sideways and chop them into small pieces, then place them in a bowl along with 2 tbsp of Japanese mayo and mix until everything is well mixed.
* Place a sharp knife at an angle and thinly slice against the grain. The thickness of the cut depends on your preference. Just make sure that all the pieces are similar in thickness.
* Grab a piece of seaweed wrap. Using a kitchen scissor, start cutting at the halfway point of seaweed wrap and cut until youre a little bit past the center of the piece. Rotate the piece vertically and start building. Dip your hand in some water to help with the sushi rice. Take a handful of sushi rice and spread it around the upper left hand quadrant of the seaweed wrap. Then carefully place a couple slices of salmon on the top right quadrant. Then place a couple slices of avocado on the bottom right quadrant. And finish it off with a couple of tsp of crab salad on the bottom left quadrant. Then, fold the top right quadrant into the bottom right quadrant, then continue by folding it into the bottom left quadrant. Well finish off the folding by folding the top left quadrant onto the rest of the sandwich. Afterward, place a piece of plastic wrap on top, cut it half, add a couple pieces of ginger and wasabi, and there you have it.
A saída deve ser um fragmento de código markdown formatado no seguinte esquema, incluindo o "```json" e "```" à esquerda e à direita:
json
{
"cuisine_type": string // What is the cuisine type for the recipe? Answer in 1 word max in lowercase
"preparation_time": integer // How much time in minutes do I need to prepare the recipe? Anwer with an integer number, or null if unknown
"difficulty": string // How difficult is this recipe? Answer with one of these values: easy, normal, hard, very-hard
"ingredients": string // Give me a comma separated list of ingredients in lowercase or empty if unknown
}
======RESPONSE
json
{
"cuisine_type": "japanese",
"preparation_time": 30,
"difficulty": "easy",
"ingredients": "sushi rice, water, konbu, rice vinegar, sugar, salt, avocado, imitation crab sticks, japanese mayo, salmon"
}
Tudo bem. Parece que nosso prompt da OpenAI é capaz de retornar algumas informações úteis. Vamos executar toda a classe da análise no terminal:
set a = ##class(yummy.analysis.SimpleOpenAI).%New(##class(yummy.data.Recipe).%OpenId(12))
do a.Run()
zwrite a
USER>zwrite a
a=37@yummy.analysis.SimpleOpenAI ; <OREF>
+----------------- general information ---------------
| oref value: 37
| class name: yummy.analysis.SimpleOpenAI
| reference count: 2
+----------------- attribute values ------------------
| CuisineType = "japanese"
| Difficulty = "easy"
| Ingredients = "sushi rice, water, konbu, rice vinegar, sugar, salt, avocado, imitation crab sticks, japanese mayo, salmon"
| PreparationTime = 30
| Reason = "It seems to be a japanese recipe!. You don't need too much time to prepare it"
| Score = 3
+----------------- swizzled references ---------------
| i%Recipe = ""
| r%Recipe = "30@yummy.data.Recipe"
+-----------------------------------------------------
## Analisando todas as receitas! Naturalmente, você gostaria de executar a análise em todas as receitas que carregamos.
Você pode analisar uma variedade de IDs de receitas desta forma:
USER>do ##class(yummy.Utils).AnalyzeRange(1,10)
> Recipe 1 (1.755185s)
> Recipe 2 (2.559526s)
> Recipe 3 (1.556895s)
> Recipe 4 (1.720246s)
> Recipe 5 (1.689123s)
> Recipe 6 (2.404745s)
> Recipe 7 (1.538208s)
> Recipe 8 (1.33001s)
> Recipe 9 (1.49972s)
> Recipe 10 (1.425612s)
Depois disso, verifique novamente sua tabela de receitas e confira os resultados
select * from yummy_data.Recipe
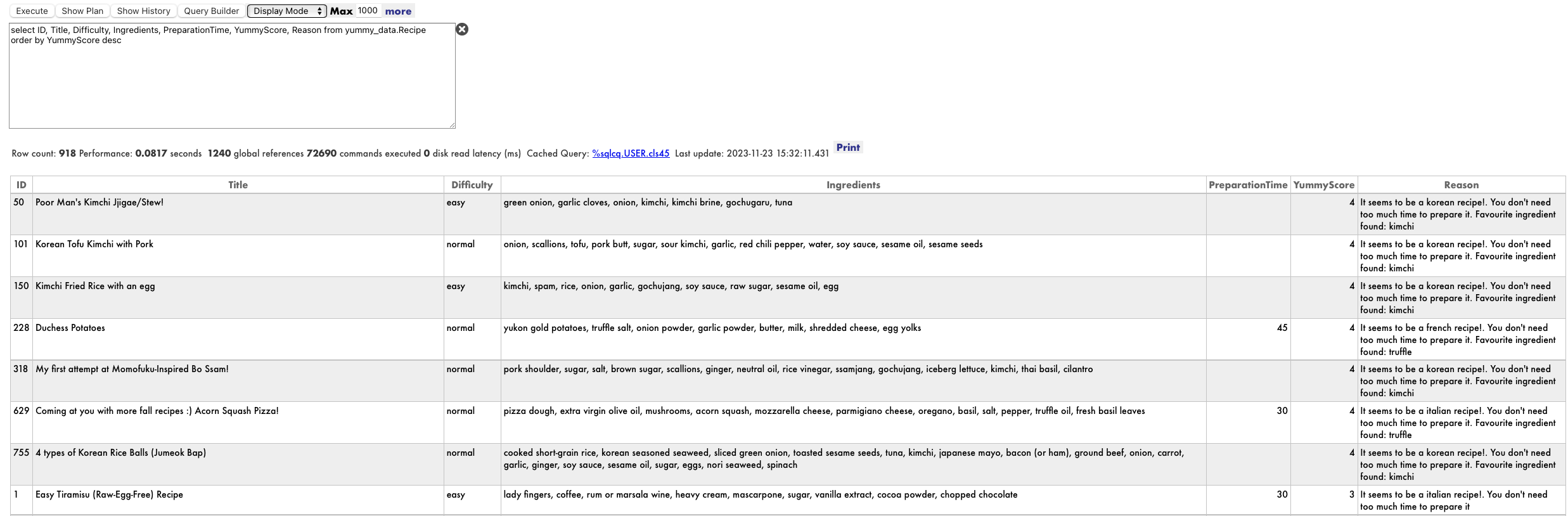
Acho que eu poderia tentar a pizza de abóbora ou o tofu com kimchi coreano e porco :). Vou precisar conferir novamente em casa de qualquer forma :)
Observações finais
Encontre o exemplo completo em https://github.com/isc-afuentes/recipe-inspector
Com esse exemplo simples, aprendemos a usar as técnicas de LLM para adicionar recursos ou analisar partes dos seus dados no InterSystems IRIS.
Com esse ponto de partida, você pode pensar em:
- Usar a BI do InterSystems para explorar e navegar pelos seus dados usando cubos e painéis.
- Criar um webapp e fornecer IU (por exemplo, Angular). Para isso, você pode aproveitar pacotes como RESTForms2 para gerar automaticamente as APIs REST para suas classes persistentes.
- Armazenar as receitas independentemente de gostar delas e, depois, tentar determinar se uma nova receita gostará de você? Você pode tentar uma abordagem com o IntegratedML ou até mesmo um LLM, fornecendo alguns dados de exemplo e criando um caso de uso de RAG (Geração Aumentada de Recuperação).
O que mais você pode tentar? Me diga o que você acha!