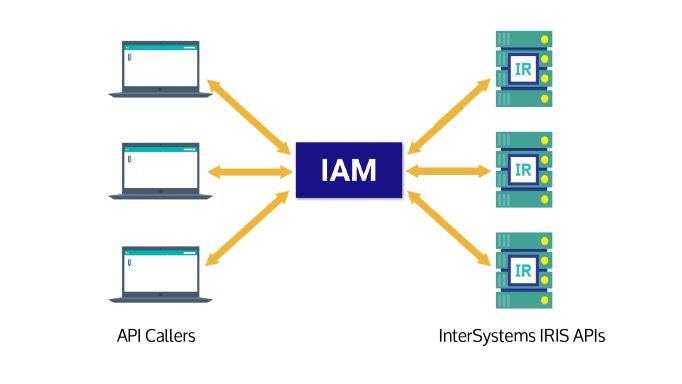
Com o meu conhecimento básico sobre o contêiner Docker e a API REST, queria tentar usar o InterSystems API Manager pela primeira vez para controlar APIs e microsserviços. Concluí esse curso online usando minha instância IRIS local como host (SO Windows) e o IAM em execução em uma VM Linux (convidado).
Olá, desenvolvedores. No momento, estou realizando uma demonstração sobre o desenvolvimento de uma IU front-end fazendo análise de dados e configurando um teste de desempenho com grandes objetos de dados. Portanto, o uso do utilitário Populate pode me ajudar a gerar automaticamente alguns dados de amostra com que eu possa brincar.
Neste post, gostaria de compartilhar minha experiência ao usar o utilitário Populate, incluindo o parâmetro POPSPEC.
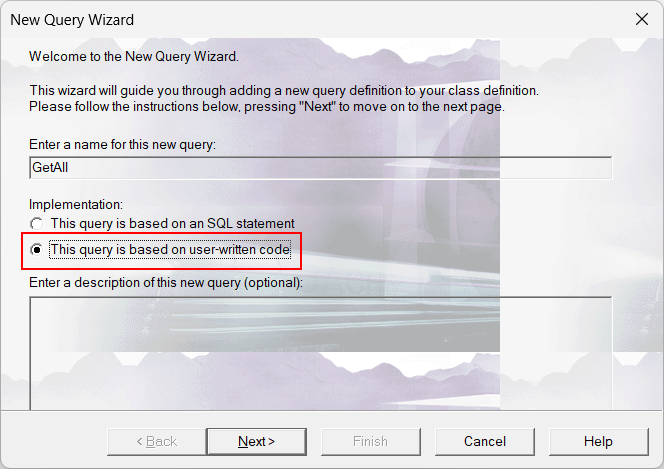
Quando você compila rotinas ou classes no terminal, os resultados da compilação são exibidos na tela, portanto, mesmo que ocorra um erro, é fácil verificar.Se você deseja obter apenas informações de erro, precisa planejar um pouco.
O seguinte descreve como obter informações de erro do resultado da compilação em lote de rotinas/classes.
Eu estava tentando encontrar uma solução para conceder aos clientes acesso anônimo a determinados endpoints de API e também proteger outros endpoints na minha API REST. No entanto, ao definir um Web App, você só pode proteger o aplicativo inteiro, e não partes específicas.
Outro dia, vi um artigo sobre o uso do pacote %ZEN ao trabalhar com JSON e decidi escrever um artigo descrevendo uma abordagem mais moderna. Recentemente, houve uma grande mudança no uso de %ZEN.Auxiliary.* para as classes JSON dedicadas. Isso permitiu o trabalho mais orgânico com JSONs.
Portanto, há basicamente 3 classes principais para trabalhar com o JSON:
%Library.DynamicObject - oferece uma maneira simples e eficiente de encapsular e trabalhar com documentos JSON padrão. Além disso, há outra possibilidade além de escrever o código habitual para criar a instância de uma classe desta maneira
set obj = ##class(%Library.DynamicObject).%New()
É possível usar a seguinte sintaxe
set obj = {}
%Library.DynamicArray - oferece uma maneira simples e eficiente de encapsular e trabalhar com arrays JSON padrão. Com arrays, é possível usar a mesma abordagem com objetos, ou seja, você pode criar uma instância da classe
set array = ##class(%DynamicArray).%New()
Ou fazer isso usando colchetes []
set array = []
%JSON.Adaptor é uma maneira de mapear objetos do ObjectScript (registrado, serial ou persistente) para entidades dinâmicas ou texto JSON.
De acordo com o Databricks, Apache Parquet é um formato de dados de código aberto orientado por colunas que é projetado para o armazenamento e recuperação de dados eficiente. Ele fornece esquemas eficientes de compactação e codificação de dados com um desempenho aprimorado para lidar com dados complexos em massa. O Apache Parquet foi criado para ser um formato de troca comum para ambas as cargas de trabalho em lote e interativas. É semelhante a outros formatos de arquivo de armazenamento colunar disponíveis no Hadoop, especificamente, RCFile e ORC.
A personalização direta de procedimentos armazenados com ObjectScript tem sido útil para acessar o armazenamento NoSQL e as mensagens externas pela integração, para apresentar a saída em um formato tabular.
Palavras-chave: ChatGPT, COS, Tabelas de consulta, IRIS, IA
Objetivo
Aqui está outra pequena observação antes de seguirmos para a jornada de automação assistida por GPT-4. Confira abaixo algumas "ajudinhas" que o ChatGPT já oferece, em várias áreas, durante as tarefas diárias.
Saiba também quais são as possíveis lacunas, riscos e armadilhas da automação assistida por LLMs, caso você explore esse caminho. Também adoraria ouvir os casos de uso e as experiências de outras pessoas nesse campo.
Os modelos de linguagem grande estão causando alguns fenômenos nos últimos meses. É claro que eu também estava testando o ChatGPT no final de semana passado, para sondar se ele poderia ser um complemento para alguns chatbots de IA "tradicionais" baseados em BERT que eu estava inventando, ou simplesmente os eliminaria.
Como todos vocês sabem, o mundo da inteligência artificial já está aqui, e todos querem usá-la em seu benefício próprio.
Há várias plataformas que oferecem serviços de inteligência artificial gratuitos, por assinatura ou particulares. No entanto, a que se destaca pelo grande "alvoroço" que fez no mundo da computação é a Open AI, sobretudo devido aos seus serviços mais renomados: ChatGPT e DALL-E.
Neste artigo, vamos analisar as complexidades da configuração de tabelas e gráficos para melhorar a legibilidade dos dados.
O Logi oferece um conjunto rico de ferramentas de visualização de dados. Você pode encontrar de tudo, desde uma ampla variedade de modelos de gráficos até estilos CSS personalizados. Entender a variedade de configurações e opções pode ser bastante difícil. Primeiro, vamos criar um gráfico e uma tabela com as configurações padrão e dar um visual apresentável a eles usando o InterSystems Reports (com tecnologia do Logi Report).
Você sabia que pode obter dados JSON diretamente das suas tabelas SQL?
Vou apresentar duas funções SQL úteis que são usadas para recuperar dados JSON de consultas SQL - JSON_ARRAY e JSON_OBJECT. Você pode usar essas funções na instrução SELECT com outros tipos de itens select, e elas podem ser especificadas em outros locais onde uma função SQL pode ser usada, como em uma cláusula WHERE
Em meus artigos anteriores, descrevi minha Extensão de Linha de Comando para NativeAPI. É claro que isso também está disponível para qualquer outro pacote NativeAPI. Portanto, criei este exemplo em Python como uma demonstração.
Neste breve artigo, quero apresentar um exemplo de uso que vários de vocês que trabalham com o IRIS como back-end para seus web applications devem ter enfrentado mais de uma vez: como enviar um arquivo do front-end para o servidor.
Em geral, a maneira mais simples que encontrei de realizar essa tarefa é transformar o arquivo do front-end para o formato Base64 e fazer uma chamada POST para o servidor anexando o Base64 obtido a uma mensagem JSON onde é indicado o nome do arquivo em um parâmetro e os dados codificados em outro. Algo parecido com isto:
WIN SQL é o editor usado pela maioria dos usuários. No entanto, não é possível fazer o download de grandes quantidades de dados usando o winsql . Então, escrevi um tutorial sobre como fazer a conexão com um novo editor baseado em Java chamado Squirrel SQL, que permite fazer o download ou exportar dados facilmente em excel ou qualquer outro formato. Também incluí um programa de conexão JDBC do Java para se conectar com um banco de dados do IRIS, particularmente um servidor de espelhamento/tolerante a falhas.
A plataforma InterSystems IRIS solucionou um problema importante em um plano de negócio da empresa de distribuição de alimentos Fresh Market. A empresa estava enfrentando um problema de estoque, que muitas vezes levava à perda de vendas e insatisfação do cliente. A empresa estava sofrendo com a falta de informações precisas e atualizadas em seu sistema de gerenciamento de estoque, o que levava a erros na previsão de demanda.
Aqui está o terceiro artico dedicado aos truques úteis que podemos encontrar pela comunidade. Dessa vez, gostaria de colocar em evidência modelos (templates) úteis que ajudarão os iniciantes (mas não somente os iniciantes) a começar a utilizar a tecnologia muito mais rápido. Aqui estão:
Temos um delicioso conjunto de dados com receitas escritas por vários usuários do Reddit, porém, a maioria das informações é texto livre, como o título ou a descrição de um post.
 Por visualizações
Por visualizações Open Exchange app
Open Exchange app.png)