Usando Python no InterSystems Iris
Olá,
Neste artigo vamos ver o uso do python como linguagem de programação no InterSystems Iris. Para tal vamos usar como referência a versão Community 2025.1 que está disponível para ser baixada em https://download.intersystems.com mediante o login no ambiente. Para maiores informações sobre o download e instalação do Iris veja o link da comunidade https://community.intersystems.com/post/how-download-and-install-intersystems-iris
Uma vez instalado o íris agora precisamos ter o python disponível no nosso ambiente. Temos vários tutoriais explicando a instalação e configuração do python no Iris. Uma boa fonte de referência é o link da documentação oficial da InterSystems em https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=AFL_epython
Uma vez instalado e configurado o python no Iris podemos fazer um primeiro teste: abrir o shell do python via terminal do Iris. Para isso vamos abrir uma janela de terminal do Iris e executar o comando Do $$SYSTEM.Python.Shell():
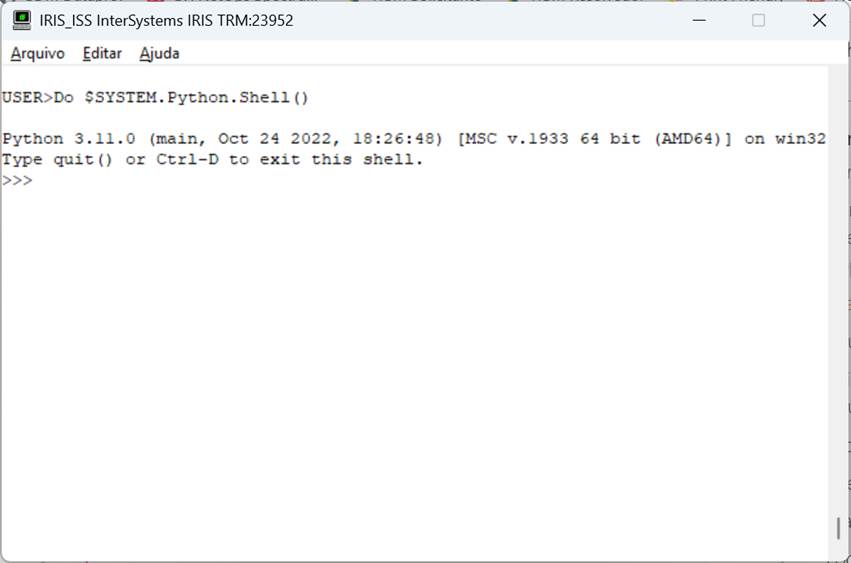
Fig. 1 – Tela do shell python no Iris
Se você estiver com seu ambiente configurado corretamente você verá a tela acima. A partir daí podemos então executar comandos, como por exemplo, ver a versão do python. Para isso vamos usar o módulo sys:
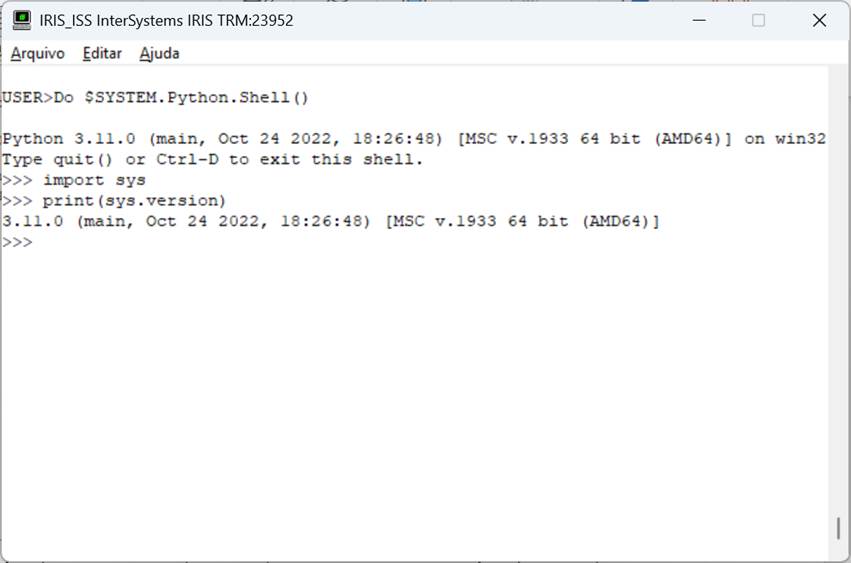
Fig. 2 – Tela do shell python no Iris
Pronto. Temos o Iris e o python prontos para trabalhar. Agora podemos criar, por exemplo, uma classe Iris e nela programar alguns métodos utilizando python. Vamos ver um exemplo:
Class Demo.Pessoa Extends %Persistent
{
Property nome As %String;
Method MeuNome() [ Language = objectscript ]
{
write ..nome
}
Method MeuNomePython() [ Language = python ]
{
print(self.nome)
}
}
A classe acima te uma propriedade (nome) e dois métodos, um em objectscript e outro em python, apenas para comparação. Chamando estes métodos temos o resultado na tela abaixo:
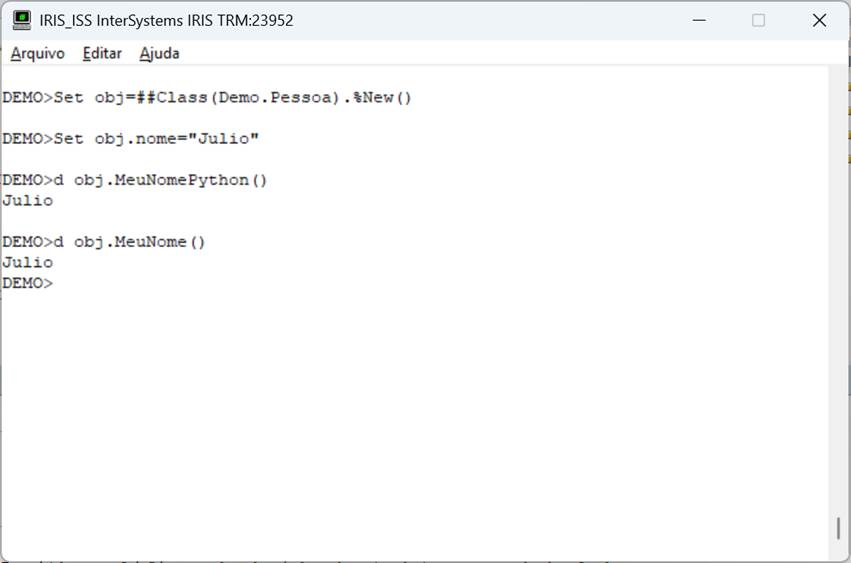
Fig. 3 – Chamada de método no Iris
Veja então que podemos ter na mesma classe métodos codificados em objectscript e em python. E de um deles podemos chamar o outro. Veja o exemplo a seguir. Vamos criar um novo método GetChave e do método MeuNomePython vamos fazer uma chamada e recuperar a informação:
Method MeuNomePython() [ Language = python ]
{
chave=self.GetChave()
print(self.nome)
print(chave)
}
Method GetChave() As %Integer [ Language = objectscript ]
{
Return $Get(^Chave)
}
Vamos criar uma global com o valor que desejamos que seja recuperado:
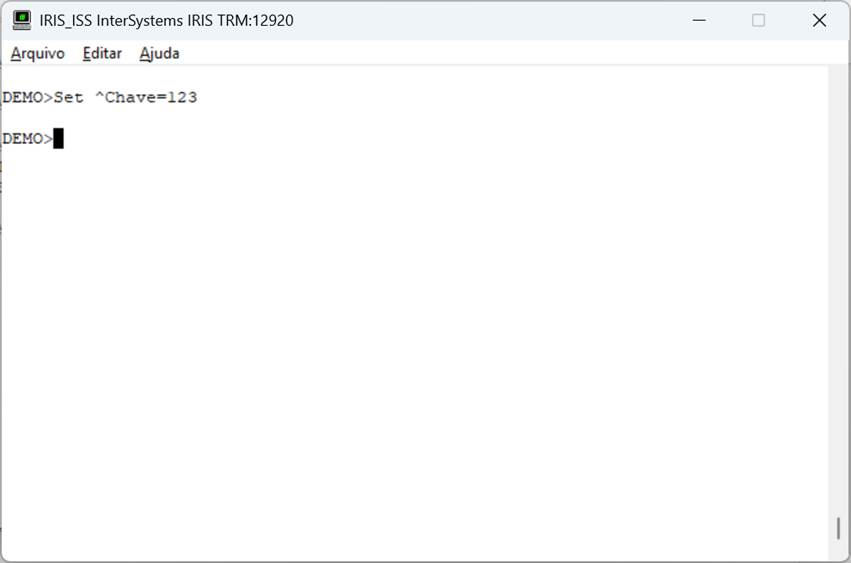
Fig. 4 – Criação de global no Iris
Pronto. Com a global criada vamos agora chamar o nosso método:
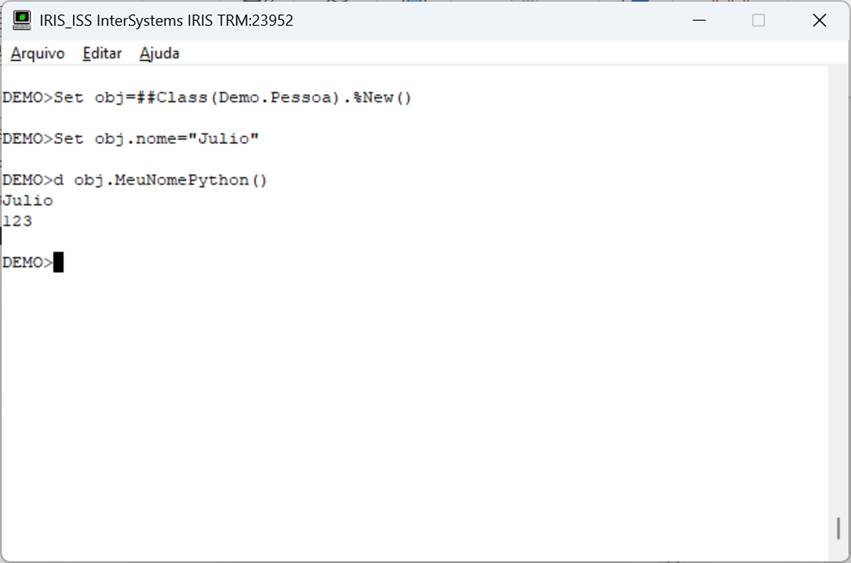
Fig. 5 – Chamada de método no Iris
Veja que agora nosso método em python faz uma chamada a outro método, este codificado em objectscript. O inverso também é válido.
Python tem diversas bibliotecas úteis, como por exemplo:
- iris – Permite interação com o banco de dados e ambiente Iris
- matplot – Visualização de dados e criação de gráficos
- numpy - Provê suporte a arrays e estrutura de dados
- scikit-learn – Permite criar e implementar models de aprendizado de máquina
- pandas – É utilizada para manipulação e análise de dados
Uma outra funcionalidade presente no Iris com python é a possibilidade de acessar dados via SQL, ou seja, podemos ter os dados armazenados em tabelas no Iris e código em python consumindo estes dados. Vamos ver um exemplo de código que lê uma tabela Iris e gera um arquivo XLS utilizando a biblioteca iris e pandas:
ClassMethod tabela() As %Status [ Language = python ]
{
import iris
import pandas as pd
rs = iris.sql.exec("select * from demo.alunos")
df = rs.dataframe()
# Salvar o DataFrame como um arquivo XLS
caminho_arquivo = 'c:\\temp\\dados.xlsx'
df.to_excel(caminho_arquivo, index=False)
return True
}
Como visto, utilizamos no código as bibliotecas iris e pandas. Então criamos um recordset (rs) com o comando SQL desejado e depois disso um dataframe pandas (df) a partir deste recordset. A partir do dataframe exportamos os dados da tabela para um arquivo Excel no caminho especificado (df.to_excel). Veja que com pouquíssimas linhas montamos um código extremamente útil. Aqui o uso das bibliotecas python foi fundamental. Elas já nos forneceram o suporte ao dataframe (pandas) e a partir daí a sua manipulação (to_excel). Executando nosso código temos então a tabela excel gerada a partir dos dados da tabela:
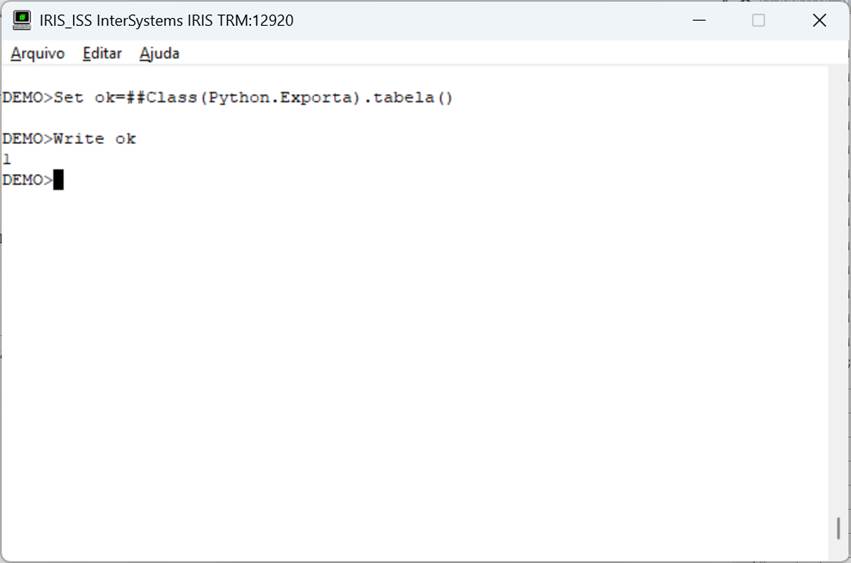
Fig. 6 – Chamada de método no Iris
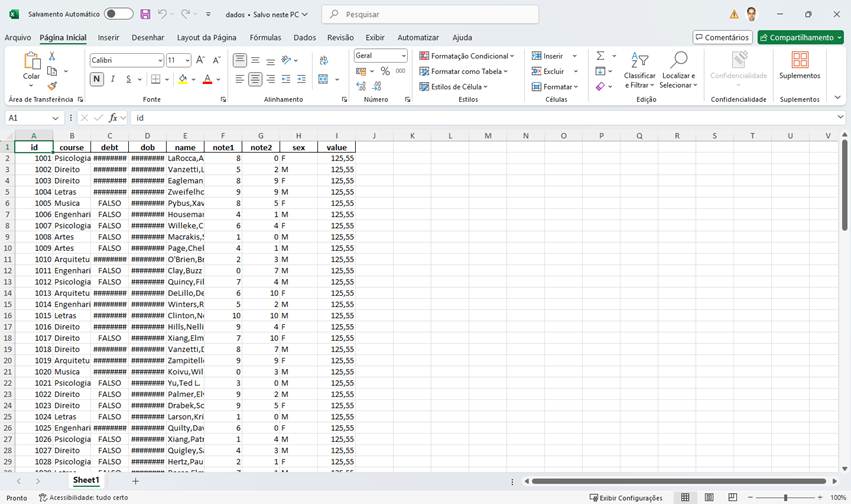
Fig. 7 – Planilha gerada pelo método
Python tem diversas bibliotecas prontas para uso, com diversas funcionalidades, assim como muito código em comunidades que podem ser utilizados nas aplicações.
Uma delas, que mencionamos acima, é a scikit-learn, que permite o uso de diversos mecanismos de regressão, permitindo a criação de métodos de predição baseado em informações, como por exemplo, uma regressão linear. Podemos ver um exemplo de código de regressão abaixo:
ClassMethod CalcularRegressaoLinear() As %String [ Language = python ]
{
import iris
import json
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
matplotlib.use("Agg")
rs = iris.sql.exec("select venda as x, temperatura as y from estat.fabrica")
df = rs.dataframe()
print(df)
# Reformatando x1 para uma matriz 2D exigida pelo scikit-learn
X = df[['x']]
y = df['y']
# Inicializa e ajusta o modelo de regressão linear
model = LinearRegression()
model.fit(X, y)
# Extrai os coeficientes da regressão
coeficiente_angular = model.coef_[0]
intercepto = model.intercept_
r_quadrado = model.score(X, y)
# Calcula Y_pred baseado no X
Y_pred = model.predict(X)
# Calcula MAE
MAE = mean_absolute_error(y, Y_pred)
# Previsão para a linha de regressão
x_pred = np.linspace(df['x'].min(), df['x'].max(), 100).reshape(-1, 1)
y_pred = model.predict(x_pred)
# Geração do gráfico de regressão
plt.figure(figsize=(8, 6))
plt.scatter(df['x'], df['y'], color='blue', label='Dados Originais')
plt.plot(df['x'], df['y'], color='black', label='Linha dos Dados Originais')
plt.scatter(df['x'], Y_pred, color='green', label='Dados Previstos')
plt.plot(x_pred, y_pred, color='red', label='Linha da Regressão')
plt.scatter(0, intercepto, color="purple", zorder=5, label="Ponto do intercepto")
plt.title('Regressão Linear')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
# Salvando o gráfico como imagem
caminho_arquivo = 'c:\\temp\\RegressaoLinear.png'
plt.savefig(caminho_arquivo, dpi=300, bbox_inches='tight')
plt.close()
# Formata os resultados em JSON
resultado = {
'coeficiente_angular': coeficiente_angular,
'intercepto': intercepto,
'r_quadrado': r_quadrado,
'MAE': MAE
}
return json.dumps(resultado)
}
O código lê uma tabela em Iris via SQL, cria um dataframe pandas baseado nos dados da tabela e calcula uma regressão linear, gerando um gráfico com a reta da regressão, além de trazer indicadores da regressão. Tudo isso a partir da biblioteca scikit-learn.
O artigo da comunidade https://pt.community.intersystems.com/post/usando-o-python-no-intersystems-iris-%E2%80%93-calculando-uma-regress%C3%A3o-linear-simples traz mais informações sobre o uso do scikit-learn para calcular regressão linear.
O Iris também permite o armazenamento dados vetoriais, o que abre inúmeras possibilidades. A biblioteca langchain_iris traz mecanismos que auxiliam no armazenamento e recuperação de informações em base de dados vetoriais.
O código a seguir pega um arquivo PDF e gera uma base de dados vetorial com os embeddings gerados para futura recuperação de dados:
ClassMethod Ingest(collectionName As %String, filePath As %String) As %String [ Language = python ]
{
import json
from langchain_iris import IRISVector
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import PyPDFLoader
try:
apiKey = <chatgpt_api_key>
loader = PyPDFLoader(filePath)
splits = loader.load_and_split()
vectorstore = IRISVector.from_documents(
documents=splits,
embedding=OpenAIEmbeddings(openai_api_key=apiKey),
dimension=1536,
collection_name=collectionName,
)
return json.dumps({"status": True})
except Exception as err:
return json.dumps({"error": str(err)})
}
Ao ler o arquivo PDF, o mesmo é “quebrado” em pedaços (splits) e esses pedaços são armazenados na forma de embeddings no Iris. Embeddings são vetores que representam aquele split.
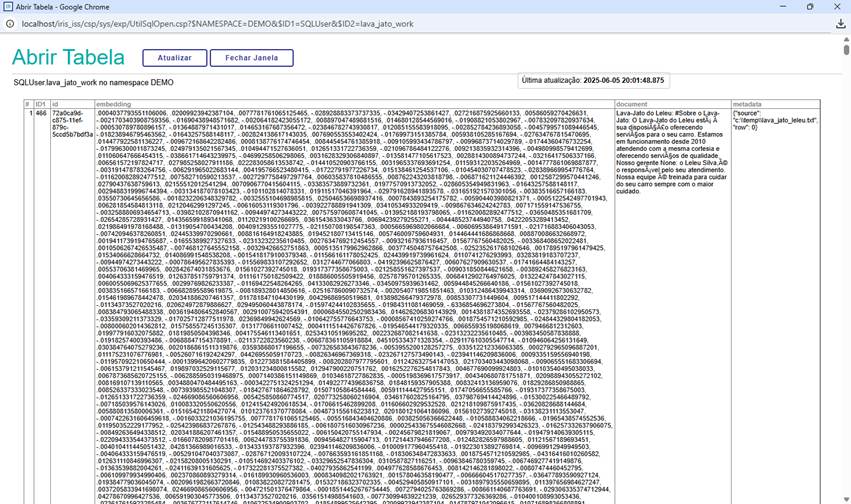
Fig. 8 – Tabela com coluna do tipo vetor no Iris
Uma vez feita a ingestão do arquivo podemos agora recuperar informações e passar para a LLM gerar um texto de retorno baseado em uma pergunta formulada. A pergunta é convertida em vetores e é feita a busca no banco de dados. Os dados recuperados são então enviados a LLM que formata uma resposta. No exemplo usamos o ChatGPT:
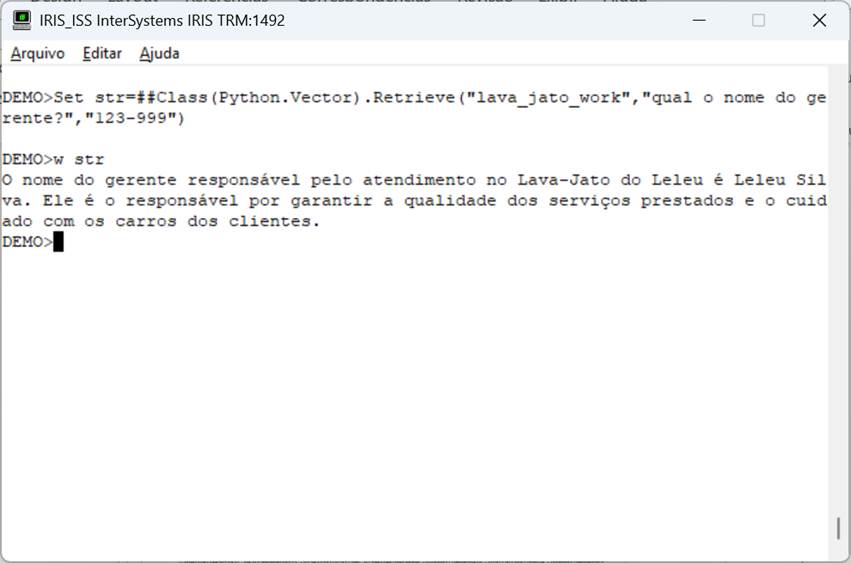
Fig.9 – Chamada de método no Iris
Abaixo o código da busca realizada:
ClassMethod Retrieve(collectionName As %String, question As %String, sessionId As %String = "") [ Language = python ]
{
import json
import iris
from langchain_iris import IRISVector
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.chains import create_history_aware_retriever
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
try:
apiKey = <chatgpt_api_key>
model = "gpt-3.5-turbo"
llm = ChatOpenAI(model= model, temperature=0, api_key=apiKey)
embeddings = OpenAIEmbeddings(openai_api_key=apiKey)
vectorstore = IRISVector(
embedding_function=OpenAIEmbeddings(openai_api_key=apiKey),
dimension=1536,
collection_name=collectionName,
)
retriever = vectorstore.as_retriever()
contextualize_q_system_prompt = """Dado um histórico de bate-papo e a última pergunta do usuário \
que pode fazer referência ao contexto no histórico do bate-papo, formule uma pergunta independente \
que pode ser entendido sem o histórico de bate-papo. NÃO responda à pergunta, \
apenas reformule-o se necessário e devolva-o como está."""
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
history_aware_retriever = create_history_aware_retriever(
llm, retriever, contextualize_q_prompt
)
qa_system_prompt = """
Você é um assistente inteligente que responde perguntas com base em dados recuperados de uma base. Dependendo da natureza dos dados, você deve escolher o melhor formato de resposta:
1. **Texto:** Se os dados contêm principalmente informações descritivas ou narrativas, responda em formato de texto.
2. **Tabela:** Se os dados contêm informações estruturadas (ex: listas, valores, métricas, comparações diretas), responda em formato HTML com o seguinte estilo:
- Bordas de 1px sólidas e de cor #dddddd.
- O cabeçalho deve ter um fundo cinza escuro (#2C3E50) e texto em branco.
- As células devem ter padding de 8px.
- As linhas pares devem ter um fundo cinza claro (#f9f9f9).
- As linhas devem mudar de cor ao passar o mouse sobre elas, usando a cor #f1f1f1.
- O texto nas células deve estar centralizado.
3. **Lista:** Se os dados contêm informações estruturadas (ex: listas, valores, métricas, comparações diretas), responda em formato HTML com o seguinte estilo:
- Bordas de 1px sólidas e de cor #dddddd.
- O cabeçalho deve ter um fundo cinza escuro (#2C3E50) e texto em branco.
- As células devem ter padding de 8px.
- As linhas pares devem ter um fundo cinza claro (#f9f9f9).
- As linhas devem mudar de cor ao passar o mouse sobre elas, usando a cor #f1f1f1.
- O texto nas células deve estar centralizado.
4. **Gráfico:** Se os dados contêm informações que são mais bem visualizadas em um gráfico (ex: tendências, distribuições, comparações entre categorias), gere um gráfico apropriado. Inclua um título, rótulos de eixo e uma legenda quando necessário. Responda utilizando um link do quickchart.io.
Contexto: {context}
Pergunta: {input}
"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)
def get_session_history(sessionId: str) -> BaseChatMessageHistory:
rs = iris.sql.exec("SELECT * FROM (SELECT TOP 5 pergunta, resposta, ID FROM Vector.ChatHistory WHERE sessionId = ? ORDER BY ID DESC) SUB ORDER BY ID ASC", sessionId)
history = ChatMessageHistory()
for row in rs:
history.add_user_message(row[0])
history.add_ai_message(row[1])
return history
def save_session_history(sessionId: str, pergunta: str, resposta: str):
iris.sql.exec("INSERT INTO Vector.ChatHistory (sessionId, pergunta, resposta) VALUES (?, ?, ?) ", sessionId, pergunta, resposta)
conversational_rag_chain = RunnableWithMessageHistory(
rag_chain,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history",
output_messages_key="answer",
)
ai_msg_1 = conversational_rag_chain.invoke(
{"input": question, "chat_history": get_session_history(sessionId).messages},
config={
"configurable": {"session_id": sessionId}
},
)
save_session_history(sessionId, question, str(ai_msg_1['answer']))
return str(ai_msg_1['answer'])
except Exception as err:
return str(err)
}
Aqui neste código entram vários aspectos que devem ser considerados neste tipo de código como o contexto da conversa, o prompt da LLM, embeddings e pesquisa vetorial.
E podemos ainda ter uma interface para realizar as chamadasao método, o que dá uma aparência mais sofisticada para a consulta. No exemplo temos uma página web acessando uma api REST que chama o método de consulta:
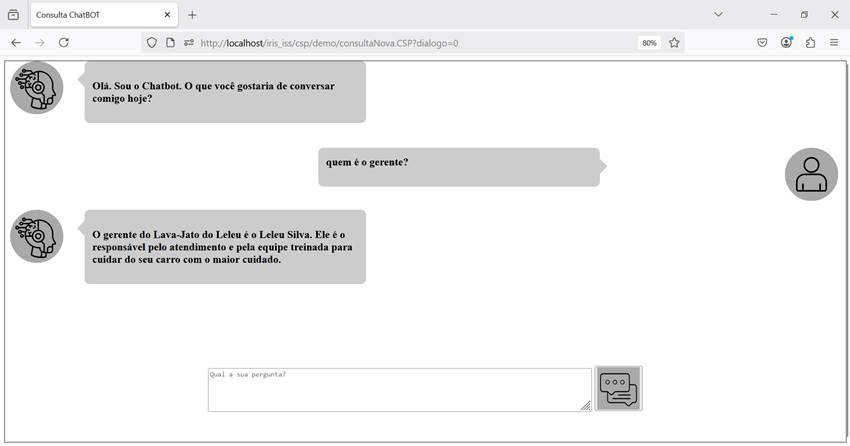
Fig. 10 – Tela de aplicação web chamando API REST no Iris
Estes são exemplos de uso do python no Iris. Mas o universo de bibliotecas disponíveis é muito maior. Podemos utilizar bibliotecas de reconhecimento de imagem, OCR, biometria, estatística e muito mais.