Oi Comunidade,
Assista a este vídeo para saber mais sobre o AI Co-Pilot, que simplifica a codificação DTL e oferece assistência personalizada, o que o torna acessível a usuários com diferentes níveis de conhecimento técnico:
⏯ Acelere a codificação DTL com o serviço AI Cloud@ Global Summit 2024
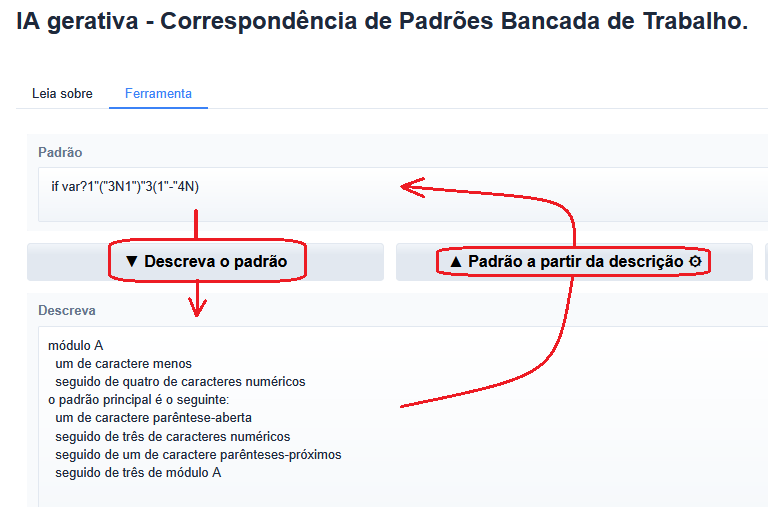
.png)