Utilizando o Gateway SQL com Python, Vector Search e Interoperabilidade no InterSystems Iris - Parte 2 – Python e Vector Search
Utilizando o Gateway SQL com Python, Vector Search e Interoperabilidade no InterSystems Iris
Parte 2 – Python e Vector Search
Uma vez que temos acesso aos dados da nossa tabela externa podemos utilizar tudo que o Iris tem de excelente com estes dados. Vamos, por exemplo, ler os dados da nossa tabela externa e gerar uma regressão polinomial com eles.
Para mais informações sobre o uso do python com o Iris veja a documentação disponível em https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=AFL_epython
Vamos agora então consumir os dados do banco externo para calcular uma regressão polinomial. Para isso vamos através de um código em python executar um SQL que lerá nossa tabela do MySQL e transformará ela em um dataframe pandas:
ClassMethod CalcularRegressaoPolinomialODBC() As %String [ Language = python ]
{
import iris
import json
import pandas as pd
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
matplotlib.use("Agg")
# Define Grau 2 para a regressão
grau = 2
# Recupera dados da tabela remota via ODBC
rs = iris.sql.exec("select venda as x, temperatura as y from estat.fabrica")
df = rs.dataframe()
# Reformatando x para uma matriz 2D exigida pelo scikit-learn
X = df[['x']]
y = df['y']
# Transformação para incluir termos polinomiais
poly = PolynomialFeatures(degree=grau)
X_poly = poly.fit_transform(X)
# Inicializa e ajusta o modelo de regressão polinomial
model = LinearRegression()
model.fit(X_poly, y)
# Extrai os coeficientes do modelo ajustado
coeficientes = model.coef_.tolist() # Coeficientes polinomiais
intercepto = model.intercept_ # Intercepto
r_quadrado = model.score(X_poly, y) # R Quadrado
# Previsão para a curva de regressão
x_pred = np.linspace(df['x'].min(), df['x'].max(), 100).reshape(-1, 1) # Valores para a curva de regressão
x_pred_poly = poly.transform(x_pred) # Transformando para base polinomial
y_pred = model.predict(x_pred_poly)
# Calcula Y_pred baseado no X
Y_pred = model.predict(X_poly)
# Calcula MAE
MAE = mean_absolute_error(y, Y_pred)
# Geração do gráfico da Regressão
plt.figure(figsize=(8, 6))
plt.scatter(df['x'], df['y'], color='blue', label='Dados Originais')
plt.plot(df['x'], df['y'], color='black', label='Linha dos Dados Originais')
plt.scatter(df['x'], Y_pred, color='green', label='Dados Previstos')
plt.plot(x_pred, y_pred, color='red', label='Curva da Regressão Polinomial')
plt.title(f'Regressão Polinomial (Grau {grau})')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
# Salvando o gráfico como imagem
caminho_arquivo = 'c:\\temp\\RegressaoPolinomialODBC.png'
plt.savefig(caminho_arquivo, dpi=300, bbox_inches='tight')
plt.close()
resultado = {
'coeficientes': coeficientes,
'intercepto': intercepto,
'r_quadrado': r_quadrado,
'MAE': MAE
}
return json.dumps(resultado)
}
A primeira ação que realizamos no código é a leitura os dados da nossa tabela externa via SQL e então os transformamos em um dataframe Pandas. Sempre lembrando que os dados estão fisicamente armazenados no MySQL e são acessados via ODBC através do Gateway SQL configurado no Iris. Com isso podemos utilizar as bibliotecas do python para cálculo e gráfico, conforme vemos no código.
Executando nossa rotina temos as informações do modelo gerado:
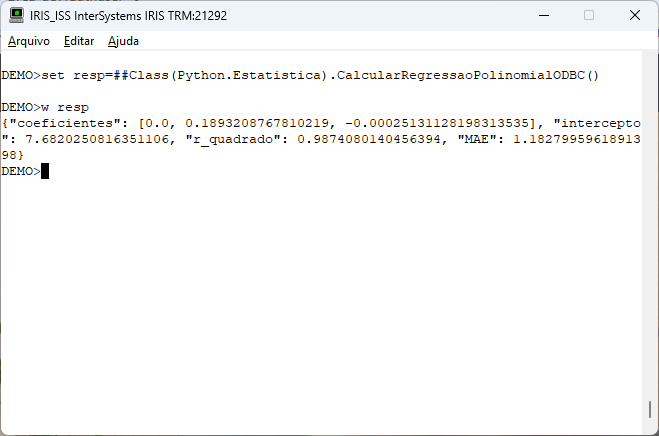
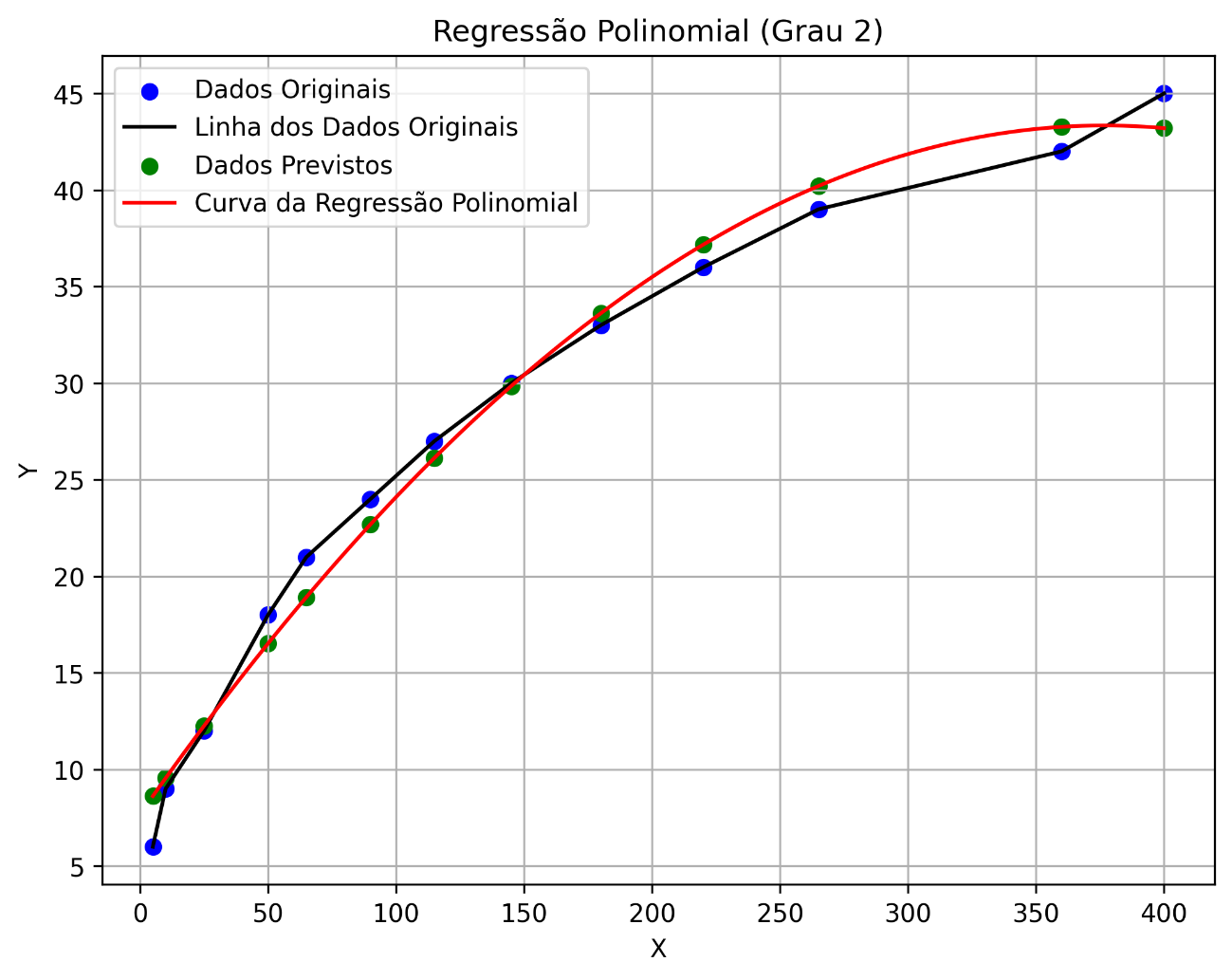
Nossa rotina também gera um gráfico que nos dá um suporte visual para a regressão polinomial. Vamos ver como o gráfico ficou:
Outra ação que podemos realizar com os dados que agora estão disponíveis é o uso do Vector Search e RAG com o uso de uma LLM. Para isso vamos vetorizar o modelo da nossa tabela e a partir daí pedir algumas informações a LLM.
Para mais informações sobre o uso de Vector Search no Iris veja o texto disponível em https://www.intersystems.com/vectorsearch/
Primeiro vamos vetorizar o modelo da nossa tabela. Abaixo o código com o qual realizamos esta tarefa:
ClassMethod IngestRelacional() As %String [ Language = python ]
{
import json
from langchain_iris import IRISVector
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
import iris
try:
apiKey = iris.cls("Vector.Util").apikey()
collectionName = "odbc_work"
metadados_tabelas = [
"Tabela: estat.fabrica; Colunas: chave(INT), venda(INT), temperatura(INT)"
]
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2048, chunk_overlap=0)
documents=text_splitter.create_documents(metadados_tabelas)
# Vetorizar as definições das tabelas
vectorstore = IRISVector.from_documents(
documents=documents,
embedding=OpenAIEmbeddings(openai_api_key=apiKey),
dimension=1536,
collection_name=collectionName
)
return json.dumps({"status": True})
except Exception as err:
return json.dumps({"error": str(err)})
}
Note que não passamos para o código de ingest o conteúdo da tabela, e sim seu modelo. Desta forma a LLM é capaz de, ao receber as colunas e suas propriedades, definir um SQL de acordo com nossa solicitação.
Este código de ingest cria a tabela odbc_work que será utilizada para fazer a busca por similaridade no modelo da tabela, e a seguir solicitar a LLM que devolva um SQL. Para isso criamos uma API KEY na OpenAI e utilizamos o langchain_iris como biblioteca python. Para mais detalhes sobre o langchain_iris veja o link https://github.com/caretdev/langchain-iris
Após realizar o ingest da definição da nossa tabela teremos a tabela odbc_work gerada:
Agora vamos a nossa terceira parte que é o acesso de uma API REST que vai consumir os dados que estão vetorizados para montar um RAG.
Até logo!