Limpar filtro
Artigo
Cristiano Silva · Jun. 7, 2023
Você já deve ter ouvido falar que, a partir das versões IRIS e HealthShare HealthConnect 2023.2, o Apache Server interno será removido da instalação padrão, então será necessário ter um servidor de aplicativos externo como Apache Server ou NGINX.
Neste artigo, procederei à instalação de um HealthShare HealthConnect 2023.1 para que funcione com um servidor Apache pré-instalado. Para isso usarei uma máquina virtual na qual instalei um Ubuntu 22.04.
Instalando Apache Server
Como indicamos, devemos instalar previamente nosso servidor Apache e o faremos seguindo as etapas indicadas em seu próprio site.
sudo apt update
sudo apt install apache2
Com o servidor Apache instalado, vamos prosseguir com a instalação do HealthConnect.
Instalando HealthConnect
Vamos revisar o que a documentação oficial da InterSystems nos diz. Se você consultar a documentação, ela nos informa como descompactar o arquivo que baixamos do WRC. No meu caso, terei que fazer alguns ajustes, pois tenho o instalador do HealthConnect em uma pasta compartilhada com minha máquina virtual.
mkdir /tmp/iriskit
chmod og+rx /tmp/iriskit
umask 022
gunzip -c /mnt/hgfs/shared/HealthConnect-2023.1.0.229.0-lnxubuntu2204x64.tar.gz | ( cd /tmp/iriskit ; tar xf - )
Vamos revisar o que estamos fazendo com esses comandos:
Criamos o diretório onde vamos descompactar nossa fonte HealthConnect.
Damos permissões de leitura e execução do diretório criado tanto ao proprietário do arquivo quanto a todos os usuários do grupo do proprietário para poder descompactar o arquivo no diretório indicado.
Damos permissões de leitura, gravação e execução em todos os arquivos e diretórios que serão criados.
Descompactamos o arquivo gz e acessando o caminho onde o descompactamos, descompactamos o arquivo tar.
Vamos ver como ficou nosso diretório temporário.
Perfeito, aqui temos o código do nosso HealthShare HealthConnect. Próximo passo, crie um usuário que será o dono da instalação do HealthConnect, vamos chamá-lo de irisusr e a partir do nosso diretório temporário executaremos o comando de instalação:
sudo useradd irisusr
sudo sh irisinstall
Ao executar a instalação, veremos uma série de opções que teremos que configurar com os valores que desejamos. Neste caso vamos realizar uma instalação PERSONALIZADA para poder configurar o WebGateway com o servidor web Apache
Continuando...
Neste ponto devemos indicar que queremos configurar o Web Gateway com o Apache Web Server já implantado em nosso servidor e continuar definindo seu caminho de instalação.
Configuração do Apache Server
A instalação configurará automaticamente o Web Gateway para funcionar com o servidor Apache e nossa instância APACHETEST do HealthConnect. Neste exemplo, sendo Ubuntu 22.0.4, o arquivo de configuração do Apache está localizado no caminho /etc/apache2/apache2.conf , para outras distribuições Linux você pode consultar a documentação.
Se abrirmos o arquivo apache2.conf e rolar até o final dele, podemos verificar as alterações introduzidas pela instalação do Web Gateway:
Esta configuración está redirigiendo todas las llamadas que reciba el puerto 80 (puerto en el que Apache Server escucha por defecto) con la ruta /csp a nuestro Web Gateway, el cual a su vez enviará la llamada a nuestra instancia de HealthConnect. Por defecto el parámetro CSPFileTypes está configurada únicamente para redireccionar los archivos de tipo "csp cls zen cxw", para poder trabajar con el portal de gestión sin inconveniente lo hemos modificado para aceptar todos los tipos "*". El cambio de CSPFileTypes exige reiniciar Apache Server.
Esta configuração está redirecionando todas as chamadas recebidas pela porta 80 (a porta padrão do Apache Server) com a rota /csp para nosso Web Gateway, que por sua vez enviará a chamada para nossa instância HealthConnect. Por padrão, o parâmetro CSPFileTypes é configurado apenas para redirecionar arquivos do tipo "csp cls zen cxw", para trabalhar com o portal de gerenciamento sem nenhum problema, modificaremos para aceitar todos os tipos "*". Alterar os CSPFileTypes requer uma reinicialização do Servidor Apache.
Acceso ao Portal de Gerenciamento do Sistema
Muito bem, temos nosso Apache escutando na porta 80, nosso Web Gateway configurado e a instância HealthConnect iniciada. Vamos testar o acesso ao Portal de Derenciamento do Sistema usando a porta 80 do Apache.
No meu caso, a URL de acesso será http://192.168.31.214/csp/sys/%25CSP.Portal.Home.zen, como a porta 80 é a porta padrão, não será necessário incluí-la na URL.
Aquí tenemos nuestro portal de gestión plenamente operativo. Introduzcamos el usuario y la contraseña que definimos durante la instalación y abramos la configuración del Web Gateway desde la opción System Administrator --> Configuration --> Web Gateway Management. Esta vez el usuario de acceso será CSPSystem. Recordemos que el Web Gateway está configurado para funcionar con el Apache Web Server que hemos instalado previamente.
Aqui temos nosso portal de gestão totalmente operacional. Vamos inserir o nome de usuário e a senha que definimos durante a instalação e abrir a configuração do Web Gateway na opção System Administrator --> Configuration --> Web Gateway Management. Desta vez o usuário de acesso será o CSPSystem. Lembre-se de que o Web Gateway está configurado para funcionar com o Apache Web Server que instalamos anteriormente.
Vamos acessar a opção Server Access para verificar a configuração da nossa instância HealthConnect no Web Gateway:
Temos nossa instância. Vamos verificar como o Web Gateway gerencia as chamadas recebidas do servidor Apache abrindo a opção Application Access.
Vamos ver o que ele faz com URLs começando com /csp
Aí está nossa instância configurada por padrão para receber as chamadas que chegam ao nosso Servidor Apache.
Já temos nossa instância do HealthShare HealthConnect configurada para funcionar com um servidor Apache externo e o Web Gateway. Se você tiver alguma dúvida ou sugestão, sinta-se à vontade para nos enviar um comentário.
Artigo
Heloisa Paiva · Abr. 1
Frequentemente, clientes, fornecedores ou equipes internas me pedem para explicar o planejamento de capacidade de CPU para _para grandes bancos de dados de produção_ rodando no VMware vSphere.
Em resumo, existem algumas práticas recomendadas simples a seguir para dimensionar a CPU para grandes bancos de dados de produção:
- Planeje um vCPU por núcleo de CPU físico.
- Considere o NUMA e, idealmente, dimensione as VMs para manter a CPU e a memória locais para um nó NUMA.
- Dimensione as máquinas virtuais corretamente. Adicione vCPUs apenas quando necessário.
Geralmente, isso leva a algumas perguntas comuns:
- Devido ao hyper-threading, o VMware me permite criar VMs com o dobro do número de CPUs físicas. Isso não dobra a capacidade? Não devo criar VMs com o máximo de CPUs possível?
- O que é um nó NUMA? Devo me preocupar com o NUMA?
- As VMs devem ser dimensionadas corretamente, mas como sei quando estão?
Respondo a estas perguntas com exemplos abaixo. Mas também lembre-se, as melhores práticas não são imutáveis. Às vezes, você precisa fazer concessões. Por exemplo, é provável que grandes VMs de banco de dados de produção NÃO caibam em um nó NUMA e, como veremos, isso está OK. As melhores práticas são diretrizes que você terá que avaliar e validar para seus aplicativos e ambiente.~
Embora eu esteja escrevendo isso com exemplos para bancos de dados rodando em plataformas de dados InterSystems, os conceitos e regras se aplicam geralmente ao planejamento de capacidade e desempenho para qualquer VM grande (Monstro).
Para melhores práticas de virtualização e mais posts sobre planejamento de desempenho e capacidade;
[Uma lista de outros posts na série de Plataformas de Dados InterSystems e desempenho está aqui.](https://community.intersystems.com/post/capacity-planning-and-performance-series-index)
#VMs Monstruosas
Este post é principalmente sobre a implantação de _VMs Monstruosas _, às vezes chamadas de _VMs Largas_. Os requisitos de recursos de CPU de bancos de dados de alta transação significam que eles são frequentemente implantados em VMs Monstruosas.
> Uma VM monstruosa é uma VM com mais CPUs virtuais ou memória do que um nó NUMA físico.
# Arquitetura de CPU e NUMA
A arquitetura de processador Intel atual possui arquitetura de Memória de Acesso Não Uniforme (NUMA). Por exemplo, os servidores que estou usando para executar testes para este post têm:
- Dois sockets de CPU, cada um com um processador de 12 núcleos (Intel E5-2680 v3).
- 256 GB de memória (16 x 16GB RDIMM)
Cada processador de 12 núcleos tem sua própria memória local (128 GB de RDIMMs e cache local) e também pode acessar a memória em outros processadores no mesmo host. Os pacotes de 12 núcleos de CPU, cache de CPU e 128 GB de memória RDIMM são um nó NUMA. Para acessar a memória em outro processador, os nós NUMA são conectados por uma interconexão rápida.
Processos em execução em um processador que acessam a memória RDIMM e Cache local têm menor latência do que atravessar a interconexão para acessar a memória remota em outro processador. O acesso através da interconexão aumenta a latência, então o desempenho não é uniforme. O mesmo design se aplica a servidores com mais de dois sockets. Um servidor Intel de quatro sockets tem quatro nós NUMA.
O ESXi entende o NUMA físico e o agendador de CPU do ESXi é projetado para otimizar o desempenho em sistemas NUMA. Uma das maneiras pelas quais o ESXi maximiza o desempenho é criar localidade de dados em um nó NUMA físico. Em nosso exemplo, se você tiver uma VM com 12 vCPUs e menos de 128 GB de memória, o ESXi atribuirá essa VM para ser executada em um dos nós NUMA físicos. O que leva à regra;
> Se possível, dimensione as VMs para manter a CPU e a memória locais em um nó NUMA.
Se você precisar de uma VM Monstruosa maior que um nó NUMA, está OK, o ESXi faz um trabalho muito bom calculando e gerenciando automaticamente os requisitos. Por exemplo, o ESXi criará nós NUMA virtuais (vNUMA) que agendam de forma inteligente nos nós NUMA físicos para um desempenho ideal. A estrutura vNUMA é exposta ao sistema operacional. Por exemplo, se você tiver um servidor host com dois processadores de 12 núcleos e uma VM com 16 vCPUs, o ESXi pode usar oito núcleos físicos em cada um dos dois processadores para agendar vCPUs da VM, o sistema operacional (Linux ou Windows) verá dois nós NUMA.
Também é importante dimensionar corretamente suas VMs e não alocar mais recursos do que o necessário, pois isso pode levar a recursos desperdiçados e perda de desempenho. Além de ajudar a dimensionar para NUMA, é mais eficiente e resultará em melhor desempenho ter uma VM de 12 vCPUs com alta (mas segura) utilização de CPU do que uma VM de 24 vCPUs com utilização de CPU de VM baixa ou mediana, especialmente se houver outras VMs neste host precisando ser agendadas e competindo por recursos. Isso também reforça a regra;
> Dimensione as máquinas virtuais corretamente.
__Nota:__ Existem diferenças entre as implementações NUMA da Intel e da AMD. A AMD tem múltiplos nós NUMA por processador. Já faz um tempo desde que vi processadores AMD em um servidor de cliente, mas se você os tiver, revise o layout NUMA como parte do seu planejamento.
## VMs Largas e Licenciamento
Para o melhor agendamento NUMA, configure VMs largas;
Correção Junho de 2017: Configure VMs com 1 vCPU por socket.
Por exemplo, por padrão, uma VM com 24 vCPUs deve ser configurada como 24 sockets de CPU, cada um com um núcleo.
>Siga as regras de melhores práticas do VMware..
Consulte [este post nos blogs do VMware para exemplos. ](https://blogs.vmware.com/performance/2017/03/virtual-machine-vcpu-and-vnuma-rightsizing-rules-of-thumb.html)
O post do blog do VMware entra em detalhes, mas o autor, Mark Achtemichuk, recomenda as seguintes regras práticas:
- Embora existam muitas configurações avançadas de vNUMA, apenas em casos raros elas precisam ser alteradas dos padrões.
- Sempre configure a contagem de vCPU da máquina virtual para ser refletida como Núcleos por Socket, até que você exceda a contagem de núcleos físicos de um único nó NUMA físico.
- Quando você precisar configurar mais vCPUs do que há núcleos físicos no nó NUMA, divida uniformemente a contagem de vCPU pelo número mínimo de nós NUMA.
- Não atribua um número ímpar de vCPUs quando o tamanho da sua máquina virtual exceder um nó NUMA físico.
- Não habilite o Hot Add de vCPU a menos que você esteja OK com o vNUMA sendo desabilitado.
- Não crie uma VM maior que o número total de núcleos físicos do seu host.t.
O licenciamento do Caché conta núcleos, então isso não é um problema, no entanto, para software ou bancos de dados diferentes do Caché, especificar que uma VM tem 24 sockets pode fazer diferença para o licenciamento de software, então você deve verificar com os fornecedores.
# Hyper-threading e o agendador de CPU
Hyper-threading (HT) frequentemente surge em discussões, e ouço: "hyper-threading dobra o número de núcleos de CPU". O que, obviamente, no nível físico, não pode acontecer — você tem tantos núcleos físicos quanto possui. O Hyper-threading deve ser habilitado e aumentará o desempenho do sistema. A expectativa é talvez um aumento de 20% ou mais no desempenho do aplicativo, mas a quantidade real depende do aplicativo e da carga de trabalho. Mas certamente não o dobro.
Como postei no [post de melhores práticas do VMware](https://community.intersystems.com/post/intersystems-data-platforms-and-performance-%E2%80%93-part-9-cach%C3%A9-vmware-best-practice-guide), um bom ponto de partida para dimensionar _grandes VMs de banco de dados de produção_ ié assumir que o vCPU tem dedicação total de núcleo físico no servidor — basicamente ignore o hyper-threading ao planejar a capacidade. Por exemplo;
> Para um servidor host de 24 núcleos, planeje um total de até 24 vCPUs para VMs de banco de dados de produção, sabendo que pode haver folga disponível.
Após dedicar tempo monitorando o desempenho da aplicação, do sistema operacional e do VMware durante os horários de pico de processamento, você pode decidir se uma consolidação de VMs mais alta é possível. Na postagem de melhores práticas, eu estabeleci a regra como;
> Um CPU físico (inclui hyper-threading) = Um vCPU (inclui hyper-threading).
## Por que o Hyper-threading não dobra o CPU
O HT em processadores Intel Xeon é uma forma de criar dois CPUs _lógicos _ CPUsem um núcleo físico. O sistema operacional pode agendar eficientemente nos dois processadores lógicos — se um processo ou thread em um processador lógico estiver esperando, por exemplo, por E/S, os recursos do CPU físico podem ser usados pelo outro processador lógico Apenas um processador lógico pode estar progredindo em qualquer ponto no tempo, então, embora o núcleo físico seja utilizado de forma mais eficiente, _o desempenho não é dobrado_.
Com o HT habilitado na BIOS do host, ao criar uma VM, você pode configurar um vCPU por processador lógico HT. Por exemplo, em um servidor de 24 núcleos físicos com HT habilitado, você pode criar uma VM com até 48 vCPUs. O agendador de CPU do ESXi otimizará o processamento executando os processos das VMs em núcleos físicos separados primeiro (enquanto ainda considera o NUMA). Eu exploro mais adiante na postagem se alocar mais vCPUs do que núcleos físicos em uma VM de banco de dados "Monster" ajuda no escalonamento.
### Co-stop e agendamento de CPU
Após monitorar o desempenho do host e da aplicação, você pode decidir que algum sobrecomprometimento dos recursos de CPU do host é possível. Se esta é uma boa ideia dependerá muito das aplicações e cargas de trabalho. Uma compreensão do agendador e uma métrica chave para monitorar podem ajudá-lo a ter certeza de que você não está sobrecomprometendo os recursos do host.
Às vezes ouço; para que uma VM progrida, deve haver o mesmo número de CPUs lógicos livres que vCPUs na VM. Por exemplo, uma VM de 12 vCPUs deve 'esperar' que 12 CPUs lógicos estejam 'disponíveis' antes que a execução progrida. No entanto, deve-se notar que, no ESXi após a versão 3, este não é o caso. O ESXi usa co-agendamento relaxado para CPU para melhor desempenho da aplicação.
Como múltiplos threads ou processos cooperativos frequentemente se sincronizam uns com os outros, não agendá-los juntos pode aumentar a latência em suas operações. Por exemplo, um thread esperando para ser agendado por outro thread em um loop de espera ocupada (spin loop). Para melhor desempenho, o ESXi tenta agendar o máximo possível de vCPUs irmãs juntas. Mas o agendador de CPU pode agendar vCPUs de forma flexível quando há múltiplas VMs competindo por recursos de CPU em um ambiente consolidado. Se houver muita diferença de tempo, enquanto algumas vCPUs progridem e outras irmãs não (a diferença de tempo é chamada de skew), então a vCPU líder decidirá se interrompe a si mesma (co-stop). Observe que são as vCPUs que fazem co-stop (ou co-start), não a VM inteira. Isso funciona muito bem mesmo quando há algum sobrecomprometimento de recursos, no entanto, como você esperaria; muito sobrecomprometimento de recursos de CPU inevitavelmente impactará o desempenho. Mostro um exemplo de sobrecomprometimento e co-stop mais adiante no Exemplo 2.
Lembre-se que não é uma corrida direta por recursos de CPU entre VMs; o trabalho do agendador de CPU do ESXi é garantir que políticas como shares de CPU, reservas e limites sejam seguidas, maximizando a utilização da CPU e garantindo justiça, throughput, responsividade e escalabilidade. Uma discussão sobre o uso de reservas e shares para priorizar cargas de trabalho de produção está além do escopo desta postagem e depende da sua aplicação e mix de cargas de trabalho. Posso revisitar isso em um momento posterior se encontrar alguma recomendação específica do Caché. Existem muitos fatores que entram em jogo com o agendador de CPU, esta seção apenas arranha a superfície. Para um mergulho profundo, consulte o white paper da VMware e outros links nas referências no final da postagem.
# Exemplos
Para ilustrar as diferentes configurações de vCPU, executei uma série de benchmarks usando um aplicativo de Sistema de Informação Hospitalar baseado em navegador com alta taxa de transações. Um conceito semelhante ao benchmark de banco de dados DVD Store desenvolvido pela VMware.
Os scripts para o benchmark são criados com base em observações e métricas de implementações hospitalares reais e incluem fluxos de trabalho, transações e componentes de alto uso que utilizam os maiores recursos do sistema. VMs de driver em outros hosts simulam sessões web (usuários) executando scripts com dados de entrada aleatórios em taxas de transação de fluxo de trabalho definidas. Um benchmark com uma taxa de 1x é a linha de base. As taxas podem ser aumentadas e diminuídas em incrementos.
Juntamente com as métricas do banco de dados e do sistema operacional, uma boa métrica para avaliar o desempenho da VM do banco de dados do benchmark é o tempo de resposta do componente (que também pode ser uma transação) medido no servidor. Um exemplo de um componente é parte de uma tela do usuário final. Um aumento no tempo de resposta do componente significa que os usuários começariam a ver uma mudança para pior no tempo de resposta do aplicativo. Um sistema de banco de dados com bom desempenho deve fornecer alto desempenho _consistente_ para os usuários finais. Nos gráficos a seguir, estou medindo em relação ao desempenho consistente do teste e uma indicação da experiência do usuário final, calculando a média do tempo de resposta dos 10 componentes de alto uso mais lentos. O tempo de resposta médio do componente deve ser inferior a um segundo, uma tela de usuário pode ser composta por um componente, ou telas complexas podem ter muitos componentes.
> Lembre-se de que você sempre está dimensionando para a carga de trabalho máxima, mais um buffer para picos inesperados de atividade. Geralmente, busco uma utilização média de 80% da CPU no pico.
Uma lista completa do hardware e software do benchmark está no final da postagem.
## Exemplo 1. Dimensionamento correto - VM "monstro" única por host
É possível criar uma VM de banco de dados dimensionada para usar todos os núcleos físicos de um servidor host, por exemplo, uma VM de 24 vCPUs em um host de 24 núcleos físicos. Em vez de executar o servidor "bare-metal" em um espelho de banco de dados Caché para alta disponibilidade (HA) ou introduzir a complicação do clustering de failover do sistema operacional, a VM do banco de dados é incluída em um cluster vSphere para gerenciamento e HA, por exemplo, DRS e VMware HA.
Tenho visto clientes seguirem o pensamento da velha guarda e dimensionarem uma VM de banco de dados primária para a capacidade esperada no final da vida útil de cinco anos do hardware, mas como sabemos acima, é melhor dimensionar corretamente; você obterá melhor desempenho e consolidação se suas VMs não forem superdimensionadas e o gerenciamento de HA será mais fácil; pense em Tetris se houver manutenção ou falha do host e a VM monstro do banco de dados tiver que migrar ou reiniciar em outro host. Se a taxa de transações for prevista para aumentar significativamente, os vCPUs podem ser adicionados antecipadamente durante a manutenção planejada.
> Observação, a opção de 'adicionar a quente' (hot add) de CPU desativa o vNUMA, portanto, não a use para VMs monstro.
Considere o seguinte gráfico mostrando uma série de testes no host de 24 núcleos. A taxa de transações 3x é o ponto ideal e a meta de planejamento de capacidade para este sistema de 24 núcleos.
- Uma única VM está sendo executada no host.
- Quatro tamanhos de VM foram usados para mostrar o desempenho em 12, 24, 36 e 48 vCPUs.
- Taxas de transação (1x, 2x, 3x, 4x, 5x) foram executadas para cada tamanho de VM (se possível).
- O desempenho/experiência do usuário é mostrado como o tempo de resposta do componente (barras).
- Utilização média da CPU% na VM convidada (linhas).
- A utilização da CPU do host atingiu 100% (linha tracejada vermelha) na taxa de 4x para todos os tamanhos de VM.

Há muita coisa acontecendo neste gráfico, mas podemos nos concentrar em algumas coisas interessantes.
- A VM com 24 vCPUs (laranja) escalou suavemente para a taxa de transação alvo de 3x. Com a taxa de 3x, a VM convidada está com uma média de 76% de CPU (picos foram em torno de 91%). A utilização da CPU do host não é muito maior do que a da VM convidada. O tempo de resposta do componente é praticamente plano até 3x, então os usuários estão satisfeitos. Quanto à nossa taxa de transação alvo — esta _VM está dimensionada corretamente_.
Então, chega de dimensionamento correto, e quanto a aumentar as vCPUs, o que significa usar hyper threads? É possível dobrar o desempenho e a escalabilidade? A resposta curta é _Não!_
Neste caso, a resposta pode ser vista observando o tempo de resposta do componente a partir de 4x. Embora o desempenho seja "melhor" com mais núcleos lógicos (vCPUs) alocados, ele ainda não é plano e consistente como era até 3x. Os usuários relatarão tempos de resposta mais lentos em 4x, independentemente de quantas vCPUs forem alocadas. Lembre-se que em 4x o _host _ já está no limite, com 100% de utilização da CPU, conforme relatado pelo vSphere. Em contagens de vCPU mais altas, mesmo que as métricas de CPU do convidado (vmstat) estejam relatando menos de 100% de utilização, esse não é o caso para os recursos físicos. Lembre-se que o sistema operacional convidado não sabe que está virtualizado e está apenas relatando os recursos apresentados a ele. Observe também que o sistema operacional convidado não vê threads HT, todas as vCPUs são apresentadas como núcleos físicos.
O ponto é que os processos do banco de dados (existem mais de 200 processos Caché na taxa de transação 3x) estão muito ocupados e fazem um uso muito eficiente dos processadores, não há muita folga para os processadores lógicos agendarem mais trabalho ou consolidarem mais VMs neste host. Por exemplo, grande parte do processamento do Caché está ocorrendo na memória, então não há muita espera por IO. Portanto, embora você possa alocar mais vCPUs do que núcleos físicos, não há muito a ganhar porque o host já está 100% utilizado.
Caché é muito bom em lidar com altas cargas de trabalho. Mesmo quando o host e a VM estão com 100% de utilização da CPU, o aplicativo ainda está em execução e a taxa de transações ainda está aumentando — o escalonamento não é linear e, como podemos ver, os tempos de resposta estão ficando mais longos e a experiência do usuário sofrerá — mas o aplicativo não "cai de um penhasco" e, embora não seja um bom lugar para se estar, os usuários ainda podem trabalhar. Se você tiver um aplicativo que não é tão sensível aos tempos de resposta, é bom saber que você pode empurrar até o limite, e além, e o Caché ainda funciona com segurança.
> Lembre-se de que você não deseja executar sua VM de banco de dados ou seu host com 100% de utilização da CPU. Você precisa de capacidade para picos inesperados e crescimento na VM, e o hipervisor ESXi precisa de recursos para todas as atividades de rede, armazenamento e outras que realiza.
Eu sempre planejo para picos de 80% de utilização da CPU. Mesmo assim, dimensionar a vCPU apenas até o número de núcleos físicos deixa alguma folga para o hipervisor ESXi em threads lógicos, mesmo em situações extremas.
>Se você estiver executando uma solução hiperconvergente (HCI), você DEVE também considerar os requisitos de CPU do HCI no nível do host. Veja minha [postagem anterior sobre HCI ](https://community.intersystems.com/post/intersystems-data-platforms-and-performance-%E2%80%93-part-8-hyper-converged-infrastructure-capacity "previous post on HCI") para mais detalhes. O dimensionamento básico da CPU de VMs implantadas em HCI é o mesmo que o de outras VMs.
Lembre-se, você deve validar e testar tudo em seu próprio ambiente e com seus aplicativos.
##Exemplo 2. Recursos supercomprometidos
Tenho visto sites de clientes relatando desempenho "lento" do aplicativo enquanto o sistema operacional convidado relata que há recursos de CPU de sobra.
Lembre-se de que o sistema operacional convidado não sabe que está virtualizado. Infelizmente, as métricas do convidado, por exemplo, conforme relatado pelo vmstat (por exemplo, em pButtons) podem ser enganosas, você também deve obter métricas de nível de host e métricas ESXi (por exemplo `esxtop`) para realmente entender a saúde e a capacidade do sistema.
Como você pode ver no gráfico acima, quando o host está relatando 100% de utilização, a VM convidada pode estar relatando uma utilização menor. A VM de 36 vCPU (vermelha) está relatando 80% de utilização média da CPU na taxa de 4x, enquanto o host está relatando 100%. Mesmo uma VM dimensionada corretamente pode ser privada de recursos, se, por exemplo, após a entrada em produção, outras VMs forem migradas para o host ou os recursos forem supercomprometidos por meio de regras DRS mal configuradas.
Para mostrar as principais métricas, para esta série de testes, configurei o seguinte:
- Duas VMs de banco de dados em execução no host.
- - uma de 24 vCPU em execução a uma taxa de transação constante de 2x (não mostrada no gráfico).
- -uma de 24 vCPU em execução a 1x, 2x, 3x (essas métricas são mostradas no gráfico).
Com outro banco de dados usando recursos; na taxa de 3x, o sistema operacional convidado (RHEL 7) vmstat está relatando apenas 86% de utilização média da CPU e a fila de execução tem uma média de apenas 25. No entanto, os usuários deste sistema estarão reclamando alto, pois o tempo de resposta do componente disparou à medida que os processos são desacelerados.
Como mostrado no gráfico a seguir, Co-stop e Tempo de Preparo contam a história de por que o desempenho do usuário é tão ruim. As métricas de Tempo de Preparo (`%RDY`) e CoStop (`%CoStop`) mostram que os recursos da CPU estão massivamente supercomprometidos na taxa alvo de 3x. Isso realmente não deveria ser uma surpresa, já que o _host_ está executando 2x (outra VM) _e_ a taxa de 3x desta VM de banco de dados.

O gráfico mostra que o tempo de espera (Ready time) aumenta quando a carga total da CPU no host aumenta.
> Tempo de espera (Ready time) é o tempo em que uma VM está pronta para executar, mas não pode porque os recursos da CPU não estão disponíveis.
O co-stop também aumenta. Não há CPUs lógicas livres suficientes para permitir que a VM do banco de dados avance (como detalhei na seção HT acima). O resultado final é que o processamento é atrasado devido à contenção por recursos físicos da CPU.
Eu vi exatamente essa situação em um site de cliente onde nossa visão de suporte de pButtons e vmstat mostrava apenas o sistema operacional virtualizado. Enquanto o vmstat reportava folga de CPU, a experiência de desempenho do usuário era terrível.
A lição aqui é que só quando as métricas do ESXi e uma visão em nível de host foram disponibilizadas é que o problema real foi diagnosticado; recursos de CPU supercomprometidos causados por escassez geral de recursos de CPU do cluster e, para piorar a situação, regras DRS ruins fazendo com que VMs de banco de dados de alta transação migrassem juntas e sobrecarregassem os recursos do host.
## Exemplo 3. Recursos supercomprometidos
Neste exemplo, usei uma VM de banco de dados de linha de base de 24 vCPUs executando a uma taxa de transação 3x, e depois duas VMs de banco de dados de 24 vCPUs a uma taxa de transação constante de 3x.
A utilização média da CPU da linha de base (veja o Exemplo 1 acima) foi de 76% para a VM e 85% para o host. Uma única VM de banco de dados de 24 vCPUs está usando todos os 24 processadores físicos. Executar duas VMs de 24 vCPUs significa que as VMs estão competindo por recursos e estão usando todas as 48 threads de execução lógicas no servidor.

Lembrando que o host não estava 100% utilizado com uma única VM, ainda podemos ver uma queda significativa no throughput e no desempenho, pois duas VMs de 24 vCPUs muito ocupadas tentam usar os 24 núcleos físicos no host (mesmo com HT). Embora o Caché seja muito eficiente ao usar os recursos de CPU disponíveis, ainda há uma queda de 16% no throughput do banco de dados por VM e, mais importante, um aumento de mais de 50% no tempo de resposta do componente (usuário).
## Resumo
Meu objetivo com este post é responder às perguntas comuns. Veja a seção de referência abaixo para um mergulho mais profundo nos recursos de CPU do host e no agendador de CPU do VMware.
Embora existam muitos níveis de ajustes e detalhes técnicos do ESXi para extrair a última gota de desempenho do seu sistema, as regras básicas são bastante simples.
Para _grandes bancos de dados de produção_ :
- Planeje um vCPU por núcleo de CPU físico.
- Considere o NUMA e, idealmente, dimensione as VMs para manter a CPU e a memória locais em um nó NUMA.
- Dimensione corretamente as máquinas virtuais. Adicione vCPUs somente quando necessário.
Se você deseja consolidar VMs, lembre-se de que grandes bancos de dados são muito ocupados e utilizarão intensamente as CPUs (físicas e lógicas) em horários de pico. Não as superinscreva até que seu monitoramento indique que é seguro.
## Referências
- [Blog da VMware - Quando Supercomprometer vCPU:pCPU para VMs Monstruosas](https://blogs.vmware.com/vsphere/2014/02/overcommit-vcpupcpu-monster-vms.html)
- [Introdução à Série de Mergulho Profundo em NUMA 2016](http://frankdenneman.nl/2016/07/06/introduction-2016-numa-deep-dive-series)
- [O Agendador de CPU no VMware vSphere 5.1](http://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/techpaper/vmware-vsphere-cpu-sched-performance-white-paper.pdf)
## Testes
Executei os exemplos neste post em um cluster vSphere composto por dois processadores Dell R730 conectados a um array all-flash. Durante os exemplos, não houve gargalos na rede ou no armazenamento.
- Caché 2016.2.1.803.0
PowerEdge R730
- 2x Intel(R) Xeon(R) CPU E5-2680 v3 @ 2.50GHz
- 16x 16GB RDIMM, 2133 MT/s, Dual Rank, x4 Data Width
- SAS 12Gbps HBA External Controller
- HyperThreading (HT) on
PowerVault MD3420, 12G SAS, 2U-24 drive
- 24x 24 960GB Solid State Drive SAS Read Intensive MLC 12Gbps 2.5in Hot-plug Drive, PX04SR
- 2 Controller, 12G SAS, 2U MD34xx, 8G Cache
VMware ESXi 6.0.0 build-2494585
- As VMs estão configuradas para as melhores práticas; VMXNET3, PVSCSI, etc.
RHEL 7
- Páginas grandes (Large pages)
A taxa de linha de base 1x teve uma média de 700.000 glorefs/segundo (acessos ao banco de dados/segundo). A taxa 5x teve uma média de mais de 3.000.000 glorefs/segundo para 24 vCPUs. Os testes foram permitidos a serem executados até que o desempenho constante fosse alcançado e, em seguida, amostras de 15 minutos foram coletadas e calculadas a média.
> Estes exemplos são apenas para mostrar a teoria, você DEVE validar com sua própria aplicação!
Artigo
Danusa Calixto · Ago. 11, 2022
Olá, comunidade,
Este é o terceiro artigo da série sobre a inicialização de instâncias da IRIS com Docker. Desta vez, focaremos no **E**nterprise **C**ache **P**rotocol (ECP).
De maneira bastante simplificada, o ECP permite configurar algumas instâncias da IRIS como servidores de aplicação e outras como servidores de dados. As informações técnicas detalhadas podem ser encontradas na documentação oficial.
O objetivo deste artigo é descrever o seguinte:
* Como programar a inicialização de um servidor de dados e como programar a inicialização de um ou mais servidores de aplicação.
* Como estabelecer uma conexão criptografada entre os nós com Docker.
Para fazer isso, geralmente, usamos algumas das ferramentas já abordadas nos artigos anteriores sobre Web Gateway e espelhamento (*Mirror*), que descrevem instrumentos como OpenSSL, envsubst e Config-API.
## Requisitos
O ECP não está disponível com a versão da Comunidade da IRIS. Portanto, é necessário o acesso à Central de Suporte (WRC) para fazer o download de uma licença de contêiner e conectar ao registro containers.intersystems.com.
## Preparando o sistema
O sistema precisa compartilhar alguns arquivos locais com os contêineres. É necessário criar determinados usuários e grupos para evitar o erro "acesso negado".
```bash
sudo useradd --uid 51773 --user-group irisowner
sudo useradd --uid 52773 --user-group irisuser
sudo groupmod --gid 51773 irisowner
sudo groupmod --gid 52773 irisuser
```
Se você ainda não tem a licença "iris.key", faça o download na WRC e adicione ao diretório do início.
## Recupere o repositório de amostra
Todos os arquivos necessários estão disponíveis em um repositório público, exceto a licença "iris.key", então comece por clonar:
```bash
git clone https://github.com/lscalese/ecp-with-docker.git
cd ecp-with-docker
```
## Certificados SSL
Para criptografar as comunicações entre os servidores de aplicação e o servidor de dados, precisamos de certificados SSL.
Um script pronto para uso ("gen-certificates.sh") está disponível. No entanto, fique à vontade para modificá-lo, para a consistência das configurações do certificado com sua localização, empresa etc.
Execute:
```bash
sh ./gen-certificates.sh
```
Os certificados gerados estão agora no diretório "./certificates".
| Arquivo | Contêiner | Descrição |
| ------------------------------ | ----------------------------------------- | ------------------------------------------------------------- |
| ./certificates/CA_Server.cer | Servidor de aplicação e servidor de dados | Certificado do servidor da autoridade |
| ./certificates/app_server.cer | Servidor de aplicação | Certificado para a instância do servidor de aplicação da IRIS |
| ./certificates/app_server.key | Servidor de aplicação | Chave privada relacionada |
| ./certificates/data_server.cer | Servidor de dados | Certificado para a instância do servidor de dados da IRIS |
| ./certificates/data_server.key | Servidor de dados | Chave privada relacionada |
## Construa a imagem
Primeiro, faça login no registro docker da InterSystems. A imagem de base será baixada do registro durante a construção:
```bash
docker login -u="YourWRCLogin" -p="YourICRToken" containers.intersystems.com
```
Se você não sabe seu token, faça login em https://containers.intersystems.com/ com a conta da WRC.
Durante essa construção, adicionaremos alguns utilitários de software à imagem de base da IRIS:
* **gettext-base**: permitirá substituir as variáveis do ambiente nos arquivos de configuração com o comando "envsubst".
* **iputils-arping**: é necessário se quisermos espelhar o servidor de dados.
* **ZPM**: gerente de pacotes ObjectScript.
[Dockerfile](https://github.com/lscalese/ecp-with-docker/blob/master/Dockerfile):
```
ARG IMAGE=containers.intersystems.com/intersystems/iris:2022.2.0.281.0
# Não é necessário fazer o download da imagem do WRC. Ela será extraída do ICR no momento da construção.
FROM $IMAGE
USER root
# Installe iputils-arping para ter um comando de arping. É necessário para configurar o IP Virtual.
# Baixe a última versão do ZPM (incluso somente na edição da comunidade).
RUN apt-get update && apt-get install iputils-arping gettext-base && \
rm -rf /var/lib/apt/lists/*
USER ${ISC_PACKAGE_MGRUSER}
WORKDIR /home/irisowner/demo
RUN --mount=type=bind,src=.,dst=. \
iris start IRIS && \
iris session IRIS < iris.script && \
iris stop IRIS quietly
```
Não há nada especial neste Dockerfile, exceto a última linha. Ela configura a instância do servidor de dados da IRIS para aceitar até 3 servidores de aplicação. Atenção: essa configuração exige a reinicialização da IRIS. Atribuímos o valor deste parâmetro durante a construção para evitar a reinicialização do script depois.
Inicie a construção:
```bash
docker-compose build –no-cache
```
## Arquivo de configuração
Para a configuração das instâncias da IRIS (servidores de aplicação e dados), usamos o formato de arquivo SON config-api. Você verá que esses arquivos contêm variáveis de ambiente "${variable_name}". Os valores são definidos nas seções do "ambiente" do arquivo "docker-compose.yml" que veremos ainda neste documento. Essas variáveis serão substituídas logo antes do carregamento dos arquivos usando o utilitário "envsubst".
### Servidor de dados
Para o servidor de dados, vamos:
* Permitir o serviço ECP e definir a lista de clientes autorizados (servidores de aplicação).
* Criar a configuração "SSL %ECPServer" necessária para a criptografia de comunicações.
* Criar uma base de dados "myappdata". Ela será usada como uma base de dados remota dos servidores de aplicação.
(data-serer.json)[https://github.com/lscalese/ecp-with-docker/blob/master/config-files/data-server.json]
```json
{
"Security.Services" : {
"%Service_ECP" : {
"Enabled" : true,
"ClientSystems":"${CLIENT_SYSTEMS}",
"AutheEnabled":"1024"
}
},
"Security.SSLConfigs": {
"%ECPServer": {
"CAFile": "${CA_ROOT}",
"CertificateFile": "${CA_SERVER}",
"Name": "%ECPServer",
"PrivateKeyFile": "${CA_PRIVATE_KEY}",
"Type": "1",
"VerifyPeer": 3
}
},
"Security.System": {
"SSLECPServer":1
},
"SYS.Databases":{
"/usr/irissys/mgr/myappdata/" : {}
},
"Databases":{
"myappdata" : {
"Directory" : "/usr/irissys/mgr/myappdata/"
}
}
}
```
Esse arquivo de configuração é carregado na inicialização do contêiner do servidor de dados pelo script "init_datasrv.sh". Todos os servidores de aplicação conectados ao servidor de dados precisam ser confiáveis. Esse script validará automaticamente todas as conexões dentro de 100 segundos para limitar as ações manuais no portal de administração. É claro que isso pode ser melhorado para aprimorar a segurança.
### Servidor de aplicação
Para os servidores de aplicação, vamos:
* Ativar o serviço ECP.
* Criar a configuração do SLL "%ECPClient" necessária para a criptografia da comunicação.
* Configurar as informações da conexão para o servidor de dados.
* Criar a configuração da base de dados remota "myappdata".
* Criar um mapeamento global "demo.*" no espaço de nome "USER" para a base de dados "myappdata". Isso permitirá o teste da operação do ECP mais tarde.
[app-server.json](https://github.com/lscalese/ecp-with-docker/blob/master/config-files/app-server.json):
```json
{
"Security.Services" : {
"%Service_ECP" : {
"Enabled" : true
}
},
"Security.SSLConfigs": {
"%ECPClient": {
"CAFile": "${CA_ROOT}",
"CertificateFile": "${CA_CLIENT}",
"Name": "%ECPClient",
"PrivateKeyFile": "${CA_PRIVATE_KEY}",
"Type": "0"
}
},
"ECPServers" : {
"${DATASERVER_NAME}" : {
"Name" : "${DATASERVER_NAME}",
"Address" : "${DATASERVER_IP}",
"Port" : "${DATASERVER_PORT}",
"SSLConfig" : "1"
}
},
"Databases": {
"myappdata" : {
"Directory" : "/usr/irissys/mgr/myappdata/",
"Name" : "${REMOTE_DB_NAME}",
"Server" : "${DATASERVER_NAME}"
}
},
"MapGlobals":{
"USER": [{
"Name" : "demo.*",
"Database" : "myappdata"
}]
}
}
```
O arquivo de configuração é carregado na inicialização de um contêiner do servidor de aplicação pelo script "[init_appsrv.sh](https://github.com/lscalese/ecp-with-docker/blob/master/init_appsrv.sh)".
## Inicializando os contêineres
Agora, podemos inicializar os contêineres:
* 2 servidores de aplicação.
* 1 servidor de dados.
Para fazer isso execute:
docker-compose up –scale ecp-demo-app-server=2
Veja mais detalhes no arquivo [docker-compose](https://github.com/lscalese/ecp-with-docker/blob/master/docker-compose.yml):
```
# As variáveis são definidas no arquivo .env
# para mostrar o arquivo docker-compose revolvido, execute
# docker-compose config
version: '3.7'
services:
ecp-demo-data-server:
build: .
image: ecp-demo
container_name: ecp-demo-data-server
hostname: data-server
networks:
app_net:
environment:
# Lista dos clientes ECP permitidos (servidor de aplicação).
- CLIENT_SYSTEMS=ecp-with-docker_ecp-demo-app-server_1;ecp-with-docker_ecp-demo-app-server_2;ecp-with-docker_ecp-demo-app-server_3
# Path authority server certificate
- CA_ROOT=/certificates/CA_Server.cer
# Path to data server certificate
- CA_SERVER=/certificates/data_server.cer
# Path to private key of the data server certificate
- CA_PRIVATE_KEY=/certificates/data_server.key
# Path to Config-API file to initiliaze this IRIS instance
- IRIS_CONFIGAPI_FILE=/home/irisowner/demo/data-server.json
ports:
- "81:52773"
volumes:
# Script após o início - inicialização do servidor de dados.
- ./init_datasrv.sh:/home/irisowner/demo/init_datasrv.sh
# Montar certificados (ver gen-certificates.sh para gerar certificados)
- ./certificates/app_server.cer:/certificates/data_server.cer
- ./certificates/app_server.key:/certificates/data_server.key
- ./certificates/CA_Server.cer:/certificates/CA_Server.cer
# Montar arquivo de configuração
- ./config-files/data-server.json:/home/irisowner/demo/data-server.json
# Licença da IRIS
- ~/iris.key:/usr/irissys/mgr/iris.key
command: -a /home/irisowner/demo/init_datasrv.sh
ecp-demo-app-server:
image: ecp-demo
networks:
app_net:
environment:
# Nome do host ou ID do servidor de dados.
- DATASERVER_IP=data-server
- DATASERVER_NAME=data-server
- DATASERVER_PORT=1972
# Caminho do certificado do servidor de autoridade
- CA_ROOT=/certificates/CA_Server.cer
- CA_CLIENT=/certificates/app_server.cer
- CA_PRIVATE_KEY=/certificates/app_server.key
- IRIS_CONFIGAPI_FILE=/home/irisowner/demo/app-server.json
ports:
- 52773
volumes:
# Após o início do script - inicialização do servidor de aplicação.
- ./init_appsrv.sh:/home/irisowner/demo/init_appsrv.sh
# Montar certificados
- ./certificates/CA_Server.cer:/certificates/CA_Server.cer
# Caminho para a chave privada do certificado do servidor de dados
- ./certificates/app_server.cer:/certificates/app_server.cer
# Caminho para a chave privada do certificado do servidor de dados
- ./certificates/app_server.key:/certificates/app_server.key
# Caminho para o arquivo Config-API inicializar a instância da IRIS
- ./config-files/app-server.json:/home/irisowner/demo/app-server.json
# Licença da IRIS
- ~/iris.key:/usr/irissys/mgr/iris.key
command: -a /home/irisowner/demo/init_appsrv.sh
networks:
app_net:
ipam:
driver: default
config:
# A variável APP_NET_SUBNET é definida no arquivo .env
- subnet: "${APP_NET_SUBNET}"
```
## Vamos testar!
### Acesso ao portal de administração do servidor de dados
Os contêineres foram inicializados. Vamos conferir o status do servidor de dados.
A porta 52773 é mapeada para a porta local 81, então você pode acessar por este endereço: [http://localhost:81/csp/sys/utilhome.csp](http://localhost:81/csp/sys/utilhome.csp)
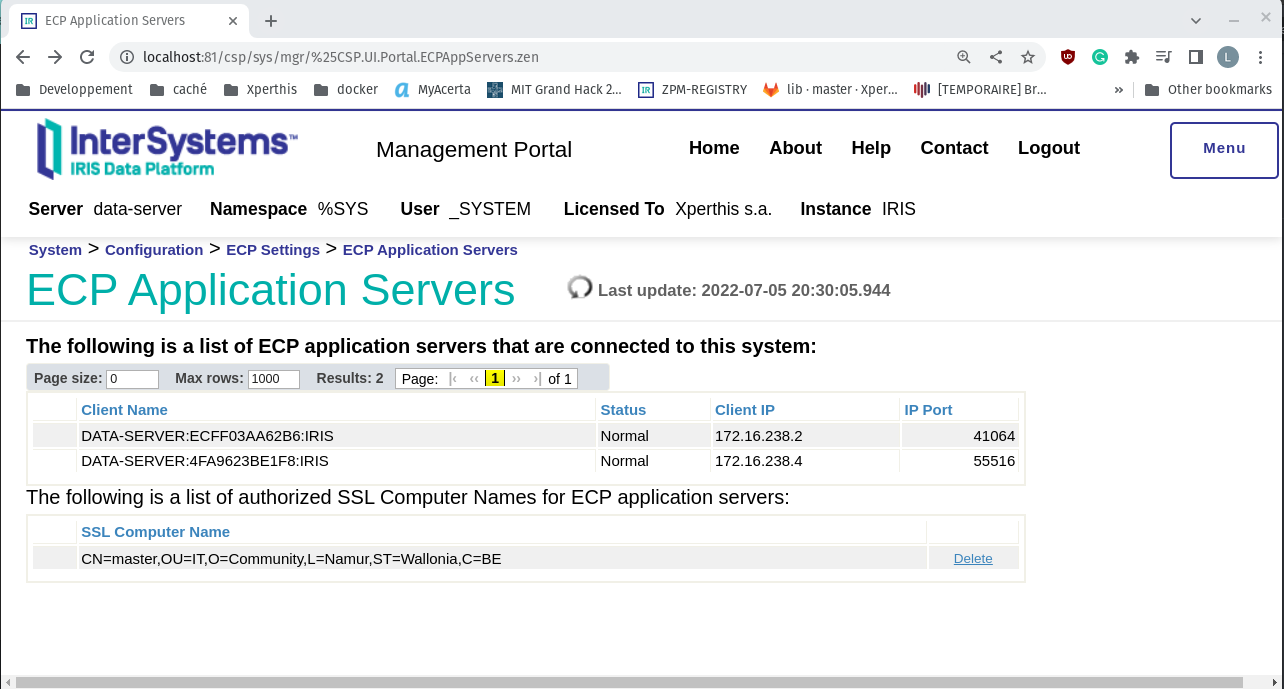
Entre com o login e a senha padrão e acesse System -> Configuration -> ECP Params. Clique em "ECP Application Servers". Se tudo estiver funcionando, você verá 2 servidores de aplicação com o status "Normal". A estrutura do nome do cliente é "nome do servidor de dados":"hostname do servidor de aplicação":"nome da instância IRIS". No nosso caso, não configuramos os hostnames do servidor de aplicação, então temos hostnames gerados.
### Acessando o portal de administração dos servidores de aplicação
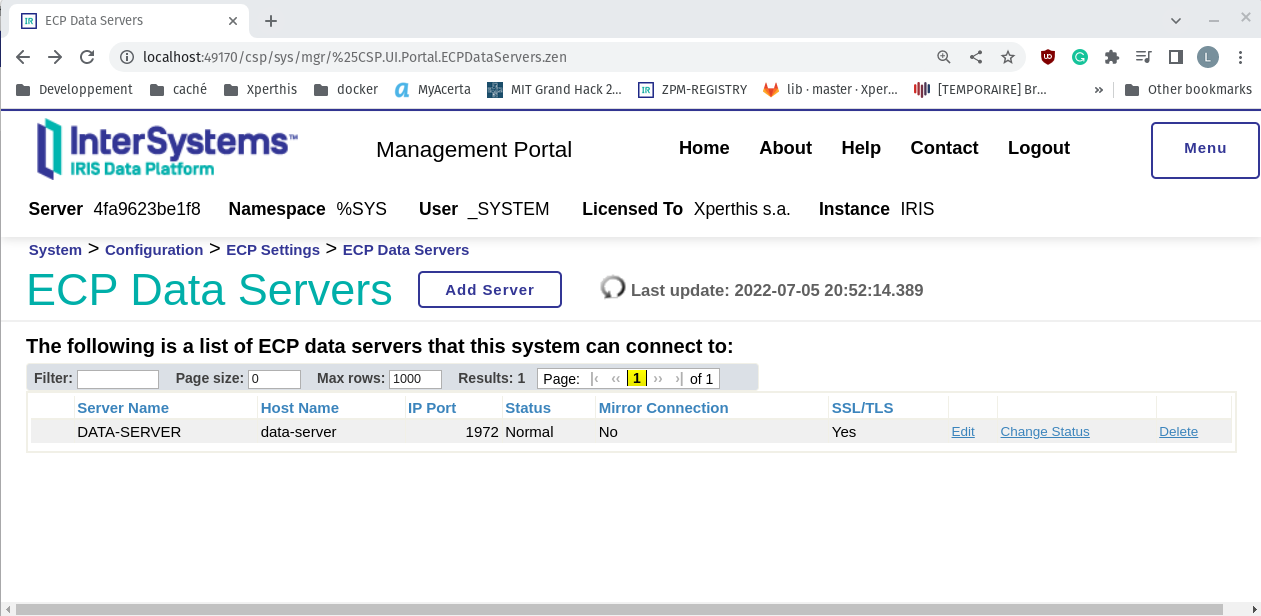
Para se conectar ao portal de administração dos servidores de aplicação, primeiro, você precisa ter o número da porta. Já que usamos a opção "--scale", não conseguimos definir as portas no arquivo docker-compose. Então, precisamos recuperá-las com o comando `docker ps`:
```
docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a1844f38939f ecp-demo "/tini -- /iris-main…" 25 minutes ago Up 25 minutes (unhealthy) 1972/tcp, 2188/tcp, 53773/tcp, 54773/tcp, 0.0.0.0:81->52773/tcp, :::81->52773/tcp ecp-demo-data-server
4fa9623be1f8 ecp-demo "/tini -- /iris-main…" 25 minutes ago Up 25 minutes (unhealthy) 1972/tcp, 2188/tcp, 53773/tcp, 54773/tcp, 0.0.0.0:49170->52773/tcp, :::49170->52773/tcp ecp-with-docker_ecp-demo-app-server_1
ecff03aa62b6 ecp-demo "/tini -- /iris-main…" 25 minutes ago Up 25 minutes (unhealthy) 1972/tcp, 2188/tcp, 53773/tcp, 54773/tcp, 0.0.0.0:49169->52773/tcp, :::49169->52773/tcp ecp-with-docker_ecp-demo-app-server_2
```
Neste exemplo, as portas são:
* 49170 para o primeiro servidor de aplicação http://localhost:49170/csp/sys/utilhome.csp
* 49169 para o segundo servidor de aplicação http://localhost:49169/csp/sys/utilhome.csp
### Teste de leitura/escrita na base de dados remota
Vamos realizar alguns testes de leitura/escrita no terminal.
Abra um terminal IRIS no primeiro servidor de aplicação:
```
docker exec -it ecp-with-docker_ecp-demo-app-server_1 iris session iris
Set ^demo.ecp=$zdt($h,3,1) _ “ write from the first application server.”
```
Agora, abra um terminal no segundo servidor de aplicação:
```
docker exec -it ecp-with-docker_ecp-demo-app-server_2 iris session iris
Set ^demo.ecp(2)=$zdt($h,3,1) _ " write from the second application server."
zwrite ^demo.ecp
```
Você deverá ver as respostas dos dois servidores:
```
^demo.ecp(1)="2022-07-05 23:05:10 write from the first application server."
^demo.ecp(2)="2022-07-05 23:07:44 write from the second application server."
```
Por fim, abra um terminal IRIS no servidor de dados e realize a leitura do global demo.ecp:
```
docker exec -it ecp-demo-data-server iris session iris
zwrite ^["^^/usr/irissys/mgr/myappdata/"]demo.ecp
^["^^/usr/irissys/mgr/myappdata/"]demo.ecp(1)="2022-07-05 23:05:10 write from the first application server."
^["^^/usr/irissys/mgr/myappdata/"]demo.ecp(2)="2022-07-05 23:07:44 write from the second application server."
```
Isso é tudo por hoje. Espero que tenha gostado deste artigo. Não hesite em deixar seus comentários.
Artigo
Yuri Marx · Abr. 10, 2022
O InterSystems HealthShare é uma plataforma integrada de serviços digitais capaz de conectar dados, serviços e processos de negócio em saúde para entregar uma operação harmoniosa baseada em Repositório Eletrônico de Saúde centralizado, HL7, FHIR e outros conhecidos padrões de mercado. Estes serviços digitais permitem:
A troca de dados e documentos clínicos e do negócio na forma de mensagens entre os envolvidos e sistemas internos e externos;
Um repositório corporativo centralizado (unificando dados de todos os centros e unidades de atendimento) de pacientes, fornecedores, profissionais de saúde e unidades de atendimento para consulta e registro centralizado;
A Gestão de consentimentos no acesso aos dados dos pacientes (ótimo para atender à LGPD);
Um Visualizador clínico com o prontuário eletrônico, resultados de exames, histórico de atendimento e demais informações de forma unificada (os dados residentes em cada unidade de atendimento no visualizador);
A disponibilização de API e Barramento SOA para integração e interoperabilidade com terceiros, aplicações internas e externas;
O uso de padrões e terminologia reconhecidos no mercado, especialmente HL7 e FHIR; e
A segurança avançada, com suporte à criptografia, auditoria e gestão de autorização e autenticação de usuários.
Não importa qual o ERP ou Sistema de Gestão Hospitalar que as unidades de saúde utilizam, toda a rede passa a operar orquestrada pelo HealthShare, potencializando as capacidades de gestão, governança e operação de dados, serviços e processos de negócio de toda a rede.
Os problemas a serem resolvidos
As unidades de saúde possuem sistemas de gestão clínica e bancos de dados locais em cada unidade. Além disto, estes sistemas apresentam problemas de interoperabilidade com os demais sistemas da unidade, com grande impacto na qualidade dos dados necessários à operação e ao atendimento dos pacientes, evidenciando os seguintes problemas:
O profissional de saúde não conhece todo o histórico clínico do paciente e não possui acesso aos exames e imagens realizados em outras unidades de saúde onde o paciente esteve. Daí, se originam dois grandes problemas, o primeiro é o custo e a perda de tempo de requisitar novos exames e imagens, o segundo é realizar um diagóstico com menos dados do que seria possível.
O paciente acaba por repetir exames de forma desnecessária, ampliando o tempo de atendimento ou internação, elevando seus custos e muitas vezes seu sofrimento, além de não ter todo o seu histórico de saúde considerado.
O plano de saúde ou o governo gastam dinheiro a mais com novos exames e maior tempo de atendimento e internação, com reflexos no valor do plano de saúde e nos custos de saúde para a Sociedade.
A operação da unidade de saúde se torna mais morosa e deficiente em dados essenciais à qualidade e agilidade no atendimento.
A boa avaliação dos programas de prevenção e combate às doenças é afetada em razão da falta de bom indicadores baseados em dados com qualidade e variedade.
A operação em rede ocorre de forma parcial, muito mais física do que digital, assim cada unidade da rede não consegue oferecer de forma plena todos os dados da operação e do paciente para auxiliar as demais unidades da rede.
Os desafios
A operação em rede é uma realidade, novas aquisições e fusões ocorrem todos os anos. As redes passam a operar com diferentes sistemas de gestão clínica e administrativa/financeira e dezenas de parceiros, incluindo planos de saúde, sistemas de governo, fornecedores, parceiros clínicos, laboratórios, muitos sem qualquer padrão de interoperabilidade na troca de dados. Os dados do paciente estão fragmentados em diferentes unidades, sob diferentes sistemas e ambientes operacionais.
O desafio, indispensável, é conectar os diferentes sistemas internos e externos de todas as unidades da rede de atendimento, dos planos de saúde, do governo, dos laboratórios e demais parceiros para harmonizar e agilizar os processos de atendimento clínico e da operação de negócio de todos os envolvidos para assim atender melhor aos pacientes, reduzir custos e reduzir falhas na operação. É necessário ter:
Um motor informatizado de coleta, transformação e enriquecimento de dados que permita ingerir dados em diferentes formatos e protocolos e unificá-los para consulta e processamento de forma padronizada (FHIR/HL7) e com a qualidade necessária para o melhor diagnóstico.
Um barramento de dados clínicos e da operação que entregue os dados no formato e na periodicidade requeridos por cada sistema interno ou externo às unidades, sejam próprios ou de parceiros.
Um visualizador clínico capaz de unificar todos os dados clínicos, de procedimentos e de histórico do paciente captados em quaisquer das unidades de atendimento, e até mesmo residentes nos parceiros, para permitir ao profissional de saúde ter uma visão 360º e de timeline do paciente, sempre entregando ao paciente a gestão de consentimento no acesso a estes dados.
Um ambiente de análise e exploração científica dos dados de atendimento para acompanhar o desempenho das ações e programas em saúde estabelecidos nas unidades e na rede de atendimento (programas de controle de infecção, eficiência de novos procedimentos e medicamentos, saúde preventiva, dentre outros), sempre respeitando os consentimentos e a privacidade dos pacientes.
Um repositório clínico unificado capaz de reduzir duplicidades de dados, qualificar os dados do cadastro do paciente e dos atendimentos para entregar o melhor cadastro possível aos profissionais e gestores em saúde.
Este desafio não é possível para sistemas de gestão clínica e administrativa/financeira em específico, pois cada unidade possui seus próprios sistemas, assim como os planos de saúde e o governo, restando estabelecer um mecanismo de intermediação e unificação que todos podem consumir:
Adaptado de: http://www.intersystems.com/https:/cdn.intersystems.psdops.com/1d/f7/eefd49e348c2a311b9d6f053a82f/healthshare-managed-connections.pdf
Cenários de Uso e Resposta do HealthShare
Cenário de Uso
Com o HealthShare
Diferentes Unidades de Saúde utilizam Tasy, TrakCare e Cerner, cada um com seu modelo de dados, mas elas precisam entregar ao médico em qualquer uma destas unidades um Visualizador com todos os dados do paciente, dos exames de laboratório e de imagem e do histórico de medicações registrados em cada uma destas unidades, de forma unificada
O Health Connect utiliza adaptadores de conexão de dados e fluxos automatizados e de coleta, transformação, padronização e armazenamento unificado no Patient Index para entregar a visão unificada para o Médico no Visualizador do Unified Care Record ou no Visualizador da escolha da Rede (que irá consumir a API com os dados unificados e renderizar suas próprias visões)
A rede precisa lidar com diferentes tabelas de referência e codificação de exames e medicamentos dos laboratórios e fornecedores e realizar o DePara automatizado na visão final
O Health Connect realiza o DePara e o Visualizador Clínico apresenta na codificação utilizada pelo Hospital
A Rede de Atendimento precisa integrar com um novo sistema de laboratório e uma das unidades da rede irá alterar seu Sistema de Gestão Clínica, mas isto não pode afetar o Visualizador Clínico do Médico
O Health Connect cria uma nova conexão de dados com os novos sistemas e armazena no MPI (Patient Index) e no UCR (Unified Care Record), sem que o Visualizador seja afetado, uma vez que o dado é consumido deste repositório e não de cada sistema diretamente em cada hospital
Em razão da LGPD (Lei de Geral de Proteção de Dados) é necessário gerir o consentimento de acesso aos dados dos pacientes
O UCR utiliza seu motor de gestão de consentimentos para retornar ao médico e aos sistemas conectados apenas os dados que o paciente der consentimento o que os parceiros/rede puderem acessar em razão da base legal estabelecida
O Gestor da Rede precisa de diversos indicadores de atendimento, na verdade um BI (Business Intelligence) para explorar e analisar desempenho dos atendimentos
O Health Insight entrega diversos painéis de análise dos atendimentos e permite ao usuário com permissão criar e compartilhar novos painéis de análise de indicadores
O médico e a família do paciente querem ser notificados imediatamente sobre resultados de exames e de imagens
O UCR possui um motor de notificação por e-mail, caixa de entrada, dentre outras notificações customizáveis, sempre que novos exames, procedimentos ou dados chegam
A Rede de Atendimento criou um Área de Ciência de Dados e precisa de um Data Lake, ferramentas de Análise e de IA para realizar seu trabalho
O HealthShare conta com o Health Insight (BI), repositório com todos dados de atendimento e do paciente disponíveis para consumo e com um motor de AutoML e de execução de IA com Python
A Rede Atendimento precisa de identificar de forma precisa, inequívoca e unificada um paciente que deu entrada na emergência, mesmo que tenha apresentado um novo número de convênio ou de número social
O MPI do HealthShare possui mecanismos e regras que analisam os dados fornecidos e retornam o percentual de chance de ser um determinado paciente na existente na base de dados, evitando duplicar o paciente e assim não ter acesso a todo o histórico em quaisquer das unidades da rede
Estes são apenas alguns cenários, mas vários outros cenários são possíveis quando se conta com um intermediador e unificador de dados em saúde que entregue serviços de barramento de dados, BI, IA, mensageria baseada em padrões, Gestor de Consentimentos e Repositório Multimodelo com MPI para os dados do paciente e dos atendimentos.
Saiba mais em: https://www.intersystems.com/br/plataforma-de-interoperabilidade
Bom dia Yuri, não consegui abrir a página de referencia (https://www.intersystems.com/de/resources/detail/healthshare-managed-connections/).
Poderia verificar e corrigir?
Obrigada! Corrigido!
Artigo
Danusa Calixto · Set. 7, 2022
Olá! Meu nome é Sergei Sarkisian e crio o front-end do Angular há mais de 7 anos trabalhando na InterSystems. Como o Angular é um framework bastante popular, ele é geralmente escolhido pelos nossos desenvolvedores, clientes e parceiros como parte da pilha para seus aplicativos.
Quero começar uma série de artigos sobre diferentes aspectos do Angular: conceitos, instruções, práticas recomendadas, tópicos avançados e muito mais. Essa série será destinada às pessoas que já estão familiarizadas com o Angular e não abordará conceitos básicos. Como ainda estou no processo de planejamento dos artigos, queria começar destacando alguns recursos importantes da versão mais recente do Angular.
## Formulários com tipos estritos
Provavelmente, esse é um dos recursos mais desejados do Angular nos últimos anos. Com o Angular 14, os desenvolvedores agora podem usar toda a funcionalidade de verificação de tipos estritos do TypeScript com os formulários reativos do Angular.
A classe FormControl é agora genérica e assume o tipo do valor que detém.
```typescript
/* Antes do Angular 14 */
const untypedControl = new FormControl(true);
untypedControl.setValue(100); // o valor está definido, sem erros
// Agora
const strictlyTypedControl = new FormControl(true);
strictlyTypedControl.setValue(100); // você receberá a mensagem de erro de verificação de tipo aqui
// Também no Angular 14
const strictlyTypedControl = new FormControl(true);
strictlyTypedControl.setValue(100); // você receberá a mensagem de erro de verificação de tipo aqui
```
Como você pode ver, o primeiro e o último exemplos são quase iguais, mas têm resultados diferentes. Isso ocorre porque, no Angular 14, a nova classe FormControl deduz tipos do valor inicial informado pelo desenvolvedor. Portanto, se o valor `true` foi fornecido, o Angular define o tipo `boolean | null` para FormControl. O valor anulável é necessário para o método `.reset()`, que anula os valores se nenhum for fornecido.
Uma classe FormControl antiga e sem tipo foi convertida para `UntypedFormControl` (isso também se aplica para `UntypedFormGroup`, `UntypedFormArray` e `UntypedFormBuilder`), que é basicamente um codinome para `FormControl`. Se você estiver fazendo upgrade de uma versão anterior do Angular, todas as menções à classe `FormControl` serão substituídas pela classe `UntypedFormControl` pela CLI do Angular.
As classes sem tipo* são usadas com metas específicas:
1. Fazer seu app funcionar da mesma maneira como era antes da transição da versão anterior (lembre-se de que o novo FormControl deduzirá o tipo a partir do valor inicial).
2. Verificar se todos os usos de `FormControl` são desejados. Portanto, você precisará mudar qualquer UntypedFormControl para `FormControl` por conta própria.
3. Dar aos desenvolvedores mais flexibilidade (abordaremos isso abaixo).
Lembra-se de que, se o valor inicial for `null`, você precisará especificar explicitamente o tipo FormControl. Além disso, o TypeScript tem um bug que exige que você faça o mesmo se o valor inicial for `false`.
Para o grupo do formulário, você também pode definir a interface e transmitir essa interface como um tipo para FormGroup. Nesse caso, TypeScript deduzirá todos os tipos dentro de FormGroup.
```typescript
interface LoginForm {
email: FormControl;
password?: FormControl;
}
const login = new FormGroup({
email: new FormControl('', {nonNullable: true}),
password: new FormControl('', {nonNullable: true}),
});
```
O método `.group()` do FormBuilder agora tem um atributo genérico que pode aceitar sua interface predefinida, como no exemplo acima, em que criamos manualmente o FormGroup:
```typescript
interface LoginForm {
email: FormControl;
password?: FormControl;
}
const fb = new FormBuilder();
const login = fb.group({
email: '',
password: '',
});
```
Como nossa interface só tem tipos primitivos não anuláveis, ela pode ser simplificada com a nova propriedade `nonNullable` do FormBuilder (que contém a instância da classe `NonNullableFormBuilder`, também criada diretamente):
```typescript
const fb = new FormBuilder();
const login = fb.nonNullable.group({
email: '',
password: '',
});
```
❗ Se você usar o FormBuilder nonNullable ou definir a opção nonNullable no FormControl, quando chamar o método `.reset()`, ele usará o valor inicial do FormControl como um valor de redefinição.
Além disso, também é muito importante observar que todas as propriedades em `this.form.value` serão marcadas como opcionais. Desta forma:
```typescript
const fb = new FormBuilder();
const login = fb.nonNullable.group({
email: '',
password: '',
});
// login.value
// {
// email?: string;
// password?: string;
// }
```
Isso ocorre porque, quando você desativa qualquer FormControl dentro do FormGroup, o valor desse FormControl será excluído do `form.value`
```typescript
const fb = new FormBuilder();
const login = fb.nonNullable.group({
email: '',
password: '',
});
login.get('email').disable();
console.log(login.value);
// {
// password: ''
// }
```
Para obter todo o objeto do formulário, você precisa usar o método `.getRawValue()`:
```typescript
const fb = new FormBuilder();
const login = fb.nonNullable.group({
email: '',
password: '',
});
login.get('email').disable();
console.log(login.getRawValue());
// {
// email: '',
// password: ''
// }
```
Vantagens de formulários com tipos estritos:
1. Qualquer propriedade e método que retorna valores do FormControl / FormGroup é agora estritamente tipado. Por exemplo: `value`, `getRawValue()`, `valueChanges`.
2. Qualquer método de mudança do valor do FormControl é agora seguro para os tipos: `setValue()`, `patchValue()`, `updateValue()`
3. Os FormControls têm agora tipos estritos. Isso também se aplica ao método `.get()` do FormGroup. Isso evitará que você acesse FormControls inexistentes no momento da compilação.
### Nova classe FormRecord
A desvantagem da nova classe `FormGroup` é que ela perdeu sua natureza dinâmica. Após a definição, você não poderá adicionar ou remover FormControls dela rapidamente.
Para resolver esse problema, o Angular apresenta uma nova classe — `FormRecord`. `FormRecord` é praticamente igual ao `FormGroup`, mas é dinâmico e todos os seus FormControls devem ter o mesmo tipo.
```typescript
folders: new FormRecord({
home: new FormControl(true, { nonNullable: true }),
music: new FormControl(false, { nonNullable: true })
});
// Adicione o novo FormContol ao grupo
this.foldersForm.get('folders').addControl('videos', new FormControl(false, { nonNullable: true }));
// Isso gerará um erro de compilação, já que o controle tem um tipo diferente
this.foldersForm.get('folders').addControl('books', new FormControl('Some string', { nonNullable: true }));
```
Como você pode ver, há uma outra limitação — todos os FormControls precisam ter o mesmo tipo. Se você realmente precisar de um FormGroup dinâmico e heterogêneo, deverá usar a classe`UntypedFormGroup` para definir seu formulário.
## Componentes sem módulos (individuais)
Apesar de ainda ser considerado experimental, esse é um recurso interessante. Ele permite definir componentes, diretivas e pipes sem incluí-los em qualquer módulo.
O conceito ainda não está totalmente pronto, mas já conseguimos desenvolver um aplicativo sem ngModules.
Para definir um componente individual, você precisa usar a nova propriedade `standalone` no decorator Component/Pipe/Directive:
```typescript
@Component({
selector: 'app-table',
standalone: true,
templateUrl: './table.component.html'
})
export class TableComponent {
}
```
Nesse caso, o componente não pode ser declarado em qualquer NgModule. No entanto, ele pode ser importado em NgModules e outros componentes individuais.
Cada componente/pipe/diretiva individual agora tem um mecanismo para importar as dependências diretamente no decorator:
```typescript
@Component({
standalone: true,
selector: 'photo-gallery',
// um módulo existente é importado diretamente em um componente individual
// CommonModule é importado diretamente para usar diretivas padrão do Angular como *ngIf
// o componente individual declarado acima também é importado diretamente
imports: [CommonModule, MatButtonModule, TableComponent],
template: `
...
Next Page
`,
})
export class PhotoGalleryComponent {
}
```
Como mencionei acima, você pode importar componentes individuais em qualquer ngModule existente. Não é mais necessário importar todo o sharedModule. Podemos importar somente o que é realmente necessário. Essa também é uma boa estratégia para começar a usar novos componentes individuais:
```typescript
@NgModule({
declarations: [AppComponent],
imports: [BrowserModule, HttpClientModule, TableComponent], // import our standalone TableComponent
bootstrap: [AppComponent]
})
export class AppModule {}
```
Você pode criar um componente individual com a CLI do Angular ao digitar:
```bash
ng g component --standalone user
```
### Aplicativo Bootstrap sem módulos
Se você quiser se livrar de todos os ngModules do seu aplicativo, você precisa usar o bootstrap de maneira diferente. O Angular tem uma nova função para isso que você precisa chamar no arquivo main.ts:
```typescript
bootstrapApplication(AppComponent);
```
O segundo parâmetro dessa função permitirá definir os fornecedores necessários em todo o app. Como a maioria dos fornecedores geralmente existe em módulos, o Angular (por enquanto) exige o uso de uma nova função de extração `importProvidersFrom` para eles:
```typescript
bootstrapApplication(AppComponent, { providers: [importProvidersFrom(HttpClientModule)] });
```
### Rota de componente individual de lazy load:
O Angular tem uma nova função `loadComponent` de rota de lazy loading, que serve exatamente para o carregamento de componentes individuais:
```typescript
{
path: 'home',
loadComponent: () => import('./home/home.component').then(m => m.HomeComponent)
}
```
Agora, `loadChildren` não só permite o lazy load de ngModule, mas também carrega rotas filhas diretamente do arquivo de rotas:
```typescript
{
path: 'home',
loadChildren: () => import('./home/home.routes').then(c => c.HomeRoutes)
}
```
### Algumas observações no momento da redação do artigo
- O recurso de componentes individuais ainda está em fase experimental. Ela receberá melhorias no futuro com a migração para Vite builder em vez de Webpack, ferramentas otimizadas, tempos de desenvolvimento mais rápidos, arquitetura de app mais robusta, testes mais fáceis e muito mais. Por enquanto, várias dessas coisas estão faltando, então não recebemos o pacote completo, mas pelo menos podemos começar a desenvolver nossos apps com o novo paradigma do Angular em mente.
- Os IDEs e ferramentas do Angular ainda não estão totalmente prontos para analisar estatisticamente novas entidades individuais. Já que é necessário importar todas as dependências em cada entidade individual, se você deixar algo passar, o compilador pode também não perceber e falhar no tempo de execução. Isso melhorará com o tempo, mas agora as importações exigem maior atenção dos desenvolvedores.
- Não há importações globais no Angular no momento (como em Vue, por exemplo), então você precisa importar cada uma das dependências em todas as entidades individuais. Espero que isso seja solucionado em uma versão futura, já que o principal objetivo desse recurso a meu ver seja reduzir o boilerplate e facilitar as coisas.
#
Isso é tudo por hoje. Até mais!
Anúncio
Jose-Tomas Salvador · Nov. 3, 2020
Desta vez, quero falar sobre algo não específico do InterSystems IRIS, mas que acho importante se você deseja trabalhar com Docker e seu servidor no trabalho é um PC ou laptop com Windows 10 Pro ou Enterprise.
Como você provavelmente sabe, a tecnologia de contêineres vem basicamente do mundo Linux e, hoje em dia, está em hosts Linux onde apresenta potencial máximo. Quem usa o Windows normalmente vê que tanto a Microsoft quanto o Docker têm feito esforços importantes nos últimos anos que nos permitem rodar contêineres baseados em imagens Linux em nosso sistema Windows de uma maneira muito fácil... mas é algo que não é suportado para sistemas em produção e, este é o grande problema, não é confiável se quisermos manter os dados persistentes fora dos contêineres, no sistema host... principalmente devido às grandes diferenças entre os sistemas de arquivos Windows e Linux. No final, o próprio _Docker para Windows usa uma pequena máquina virtual Linux (_MobiLinux_) para executar os contêineres... ele faz isso de forma transparente para o usuário do Windows... e funciona perfeitamente bem se, como eu disse, você não exigir que seus bancos de dados sobrevivam mais do que o contêiner...
Bem... vamos direto ao ponto... o ponto é que muitas vezes, para evitar problemas e simplificar, precisamos de um sistema Linux completo e, se nosso servidor for baseado em Windows, a única maneira de fazê-lo é por meio de uma máquina virtual. Pelo menos até o WSL2 no Windows ser lançado, mas isso será uma outra história e com certeza levará um pouco de tempo para se tornar robusto o suficiente.
Neste artigo, vou lhe dizer, passo a passo, como instalar um ambiente onde você poderá trabalhar, se precisar, com contêineres Docker em um sistema Ubuntu em seu servidor Windows. Vamos lá...
1. Habilite o Hyper-V
Se você ainda não o habilitou, vá em adicionar `Recursos do Windows` e habilite o Hyper-V. Você precisará reiniciar (os textos da imagem estão em espanhol pois esse é o meu espaço de trabalho atual. Espero que junto com as instruções ajudem a "descriptografá-la" se você não conhece a língua de Dom Quixote 😉)
.png)
2. Crie uma máquina virtual Ubuntu no Hyper-V
Não acho que haja uma maneira mais fácil de criar uma máquina virtual (VM). Basta abrir a janela do `Gerenciador Hyper-V`, ir para a opção Criação Rápida...(logo acima na tela) e criar sua máquina virtual usando qualquer uma das versões do Ubuntu já oferecidas (você pode baixar um arquivo _ISO _de qualquer outro Linux e assim criar a VM com uma distro diferente). No meu caso, escolhi a última versão disponível do Ubuntu: 19.10. Enfim, tudo que você verá aqui é válido para o dia 18/04. Em 15 ou 20 minutos, dependendo do que a imagem leva para baixar, você terá sua nova VM criada e pronta.
Importante: Deixe a opção de Switch padrão como é oferecida. Isso garantirá que você tenha acesso à Internet tanto no host quanto na máquina virtual.
3. Crie uma sub-rede local
Um dos problemas no uso de máquinas virtuais que encontrei com frequência tem a ver com configuração de rede... às vezes funciona, outras não, ou funciona se eu estiver conectado com Wi-Fi, mas não por cabo ou o oposto, ou se eu estabelecer uma VPN no host Windows, perco o acesso à Internet na VM, ou a comunicação entre a VM (Linux) e o host (Windows) quebra... enfim... é uma loucura! Faz com que eu não confie no meu ambiente quando uso meu laptop para desenvolvimento, pequenas e rápidas demonstrações ou para apresentações, onde provavelmente o acesso à Internet não é tão importante quanto ter certeza de que as comunicações entre meu host e minhas VMs funcionam em uma forma confiável.
Com uma sub-rede local ad-hoc, compartilhada entre seu host Windows e suas máquinas virtuais, você resolve. Para permitir que eles se comuniquem entre si, você usa essa sub-rede e é isso. Você só precisa atribuir IPs específicos ao seu host e às suas VMs e tudo pronto.
É muito fácil fazer isso com essas etapas. Basta ir em Gerenciador de Comutador virtual... que você encontrará em seu `Gerenciador Hyper-V`:
.png)
Uma vez lá, vá até a opção _Novo Comutador Virtual __ _(será como uma nova placa de rede para a VM):
.png)
Certifique-se de defini-la como uma _Rede Interna _, escolha o nome que queremos e deixe as outras opções como padrão
.png)
Agora, se formos ao _`Painel de Controle do Windows > Central de Rede e Compartilhamento`_, veremos que já temos lá o switch que acabamos de criar:
.png)
4. Configure a sub-rede local compartilhada pelo host e as máquinas virtuais
Neste ponto, você pode concluir a configuração de sua nova rede local. Para fazer isso, coloque o cursor sobre a conexão _Meu Novo Comutador LOCAL_, clique e vá em Propriedades, e de lá para o protocolo IPv4 para atribuir um endereço IP fixo:
.png)
Importante: O IP que você atribuir aqui será o IP do seu host (Windows) nesta sub-rede local.
5. Conecte e configure sua nova rede local para sua máquina virtual
Agora volte ao seu `Gerenciador Hyper-V`. Se sua VM estiver em execução, pare-a. Depois de parado, vá para sua configuração e adicione o novo switch virtual interno:
.png)
_(Nota – Na imagem você pode ver outro switch, o Comutador INTERNO Hyper-V. É para outra sub-rede que eu tenho. Mas não é necessário para você nesta configuração) _
Depois de clicar em Adicionar, você só terá que selecionar o switch que você criou anteriormente:
.png)
Bem, uma vez feito isso, clique em Aplicar, Aceitar... e você está pronto! Você pode iniciar e entrar novamente em sua máquina virtual para finalizar a configuração da conexão interna. Para fazer isso, assim que a VM iniciar, clique no ícone de rede (à direita) e você verá que tem 2 redes: _eth0 _e _eth1_. O _eth1_ aparece como desconectado... por agora:
.png)
Vá para a configuração da Ethernet (eht1) e atribua um IP fixo para esta sub-rede local, por exemplo: _155.100.101.1_, e a máscara de sub-rede:_ 255.255.255.0_
.png)
e isso é tudo. Aqui você tem sua máquina virtual, identificada com o IP 155.100.101.1 compartilhando a mesma sub-rede com seu host.
7. Permitir acesso ao Windows 10 de sua máquina virtual
Você provavelmente descobrirá que o Windows 10 não permite por padrão a conexão de outro servidor e, para o seu sistema Windows, a VM que você acabou de criar é exatamente isso, um servidor externo e potencialmente perigoso... então você terá que adicionar uma regra no Firewall para poder se conectar ao seu host a partir dessas máquinas virtuais. Como? Muito fácil, basta procurar pelo `Firewall do Windows Defender` no seu `Painel de Controle do Windows`, ir em Configuração Avançada e criar uma nova *Regra de Entrada*:
.png)
Você pode definir uma porta ou um ou vários intervalos nelas... (também pode definir a regra para todas as portas)...
.png)
A ação que queremos é _Permitir Conexão_...
.png)
Para _todos os tipos de redes_...
.png)
Dê um nome à sua regra...
.png)
E **importante**, imediatamente depois disso, abra novamente as propriedades de sua regra recém-criada e *limite o escopo da aplicação*, para aplicar apenas nas conexões dentro de sua sub-rede local...
.png)
8. PRONTO. Instale o Docker e qualquer outra aplicação em sua nova máquina virtual Ubuntu
Depois de passar por todo o processo de instalação e ter sua nova VM pronta e atualizada, com acesso à internet, etc. você pode instalar as aplicações que desejar... Docker é o mínimo, essa foi a ideia para começar, você também pode instalar seu cliente VPN se precisar de uma conexão com a rede de sua empresa, VS Code, Eclipse+Atelier,...
Especificamente, para instalar o Docker, em sua VM, você pode seguir as instruções que encontrará aqui: [https://docs.docker.com/install/linux/docker-ce/ubuntu/](https://docs.docker.com/install/linux/docker-ce/ubuntu/)
Certifique-se de que o tempo de execução do Docker está funcionando, baixe alguma imagem de teste, etc... e é isso.
Com isso... _**Está tudo pronto!**_, agora você poderá ter contêineres rodando sem limitações (além da capacidade do seu hardware) em sua VM Ubuntu, aos quais você poderá se conectar a partir de seu host Windows 10, de um navegador ou aplicativo e vice-versa, de seu Ubuntu VM para seu host Windows 10. Tudo isso usando seus endereços IP configurados em sua sub-rede local compartilhada, que funcionará independente se você tem uma VPN estabelecida ou não, se você acessa à Internet através de seu adaptador Wi-Fi ou via cabo ethernet.
Ah... um último conselho. Se você deseja trocar arquivos entre o Windows 10 e suas máquinas virtuais, uma opção muito útil e simples é usar o [WinSCP](https://winscp.net/eng/download.php). É gratuito e funciona muito bem.
Bem, com certeza existem outras configurações... mas esta é a que utilizo e provou ser a mais confiável. Espero que você também ache útil. Se eu evitei qualquer dor de cabeça, este artigo terá valido a pena.
Boa codificação!
Artigo
Danusa Calixto · Set. 20, 2022
# Apache Web Gateway com Docker
Olá, comunidade.
Neste artigo, vamos configurar programaticamente um Apache Web Gateway com Docker usando:
* Protocolo HTTPS.
* TLS\SSL para proteger a comunicação entre o Web Gateway e a instância IRIS.
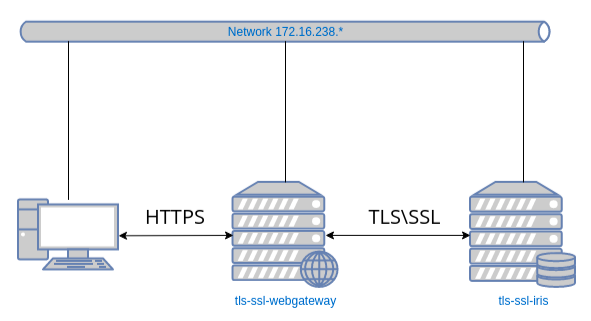
Usaremos duas imagens: uma para o Web Gateway e a segunda para a instância IRIS.
Todos os arquivos necessários estão disponíveis neste [repositório do GitHub](https://github.com/lscalese/docker-webgateway-sample).
Vamos começar com um git clone:
```bash
git clone https://github.com/lscalese/docker-webgateway-sample.git
cd docker-webgateway-sample
```
## Prepare seu sistema
Para evitar problemas com permissões, seu sistema precisa de um usuário e um grupo:
* www-data
* irisowner
É necessário compartilhar arquivos de certificados com os contêineres. Se não estiverem no seu sistema, basta executar:
```bash
sudo useradd --uid 51773 --user-group irisowner
sudo groupmod --gid 51773 irisowner
sudo useradd –user-group www-data
```
## Gere certificados
Nesta amostra, usaremos três certificados:
1. Uso do servidor Web HTTPS.
2. Criptografia TLS\SSL no cliente do Web Gateway.
3. Criptografia TLS\SSL na instância IRIS.
Um script pronto para uso está disponível para gerá-los.
No entanto, você deve personalizar o sujeito do certificado. Basta editar o arquivo [gen-certificates.sh](https://github.com/lscalese/docker-webgateway-sample/blob/master/gen-certificates.sh).
Esta é a estrutura do argumento `subj` do OpenSSL:
1. **C**: Código do país
2. **ST**: Estado
3. **L**: Local
4. **O**: Organização
5. **OU**: Unidade de organização
6. **CN**: Nome comum (basicamente, o nome do domínio ou do host)
Fique à vontade para mudar esses valores.
```bash
# sudo é necessário devido a chown, chgrp, chmod ...
sudo ./gen-certificates.sh
```
Se estiver tudo certo, você verá dois novos diretórios `./certificates/` e `~/webgateway-apache-certificates/` com certificados:
| Arquivo | Contêiner | Descrição |
| ------------------------------------------------------ | --------------- | ---------------------------------------------------------------------------------------------------- |
| ./certificates/CA_Server.cer | webgateway,iris | Certificado do servidor da autoridade |
| ./certificates/iris_server.cer | iris | Certificado para a instância IRIS (usado para a criptografia de comunicação do espelho e webgateway) |
| ./certificates/iris_server.key | iris | Chave privada relacionada |
| ~/webgateway-apache-certificates/apache_webgateway.cer | webgateway | Certificado para o servidor da Web Apache |
| ~/webgateway-apache-certificates/apache_webgateway.key | webgateway | Chave privada relacionada |
| ./certificates/webgateway_client.cer | webgateway | Certificado para criptografar a comunicação entre o webgateway e IRIS |
| ./certificates/webgateway_client.key | webgateway | Chave privada relacionada |
Considere que, se houver certificados autoassinados, os navegadores da Web mostrarão alertas de segurança. Obviamente, se você tiver um certificado entregue por uma autoridade certificada, você pode usá-lo em vez de um autoassinado (especialmente para o certificado do servidor Apache).
## Arquivos de configuração do Web Gateway
Observe os arquivos de configuração.
### CSP.INI
Você pode ver um arquivo CSP.INI no diretório `webgateway-config-files`.
Ele será empurrado para dentro da imagem, mas o conteúdo pode ser modificado no ambiente de execução. Considere o arquivo como um modelo.
Na amostra, os seguintes parâmetros serão substituídos na inicialização do contêiner:
* Ip_Address
* TCP_Port
* System_Manager
Consulte [startUpScript.sh](https://github.com/lscalese/docker-webgateway-sample/blob/master/startUpScript.sh) para ver mais detalhes. Basicamente, a substituição é realizada com a linha de comando `sed`.
Além disso, esse arquivo contém a configuração SSL\TLS para proteger a comunicação com a instância IRIS:
```
SSLCC_Certificate_File=/opt/webgateway/bin/webgateway_client.cer
SSLCC_Certificate_Key_File=/opt/webgateway/bin/webgateway_client.key
SSLCC_CA_Certificate_File=/opt/webgateway/bin/CA_Server.cer
```
Essas linhas são importantes. Precisamos garantir que os arquivos dos certificados estarão disponíveis para o contêiner.
Faremos isso mais tarde no arquivo `docker-compose` com um volume.
### 000-default.conf
Esse é um arquivo de configuração do Apache. Ele permite o uso do protocolo HTTPS e redireciona chamadas HTTP para HTTPS.
Os arquivos de certificado e chave privada são configurados neste arquivo:
```
SSLCertificateFile /etc/apache2/certificate/apache_webgateway.cer
SSLCertificateKeyFile /etc/apache2/certificate/apache_webgateway.key
```
## Instância IRIS
Para nossa instância IRIS, configuramos somente o requisito mínimo para permitir a comunicação SSL\TLS com o Web Gateway. Isso envolve:
1. Configuração SSL `%SuperServer`.
2. Permitir a configuração de segurança SSLSuperServer.
3. Restringir a lista de IPs que podem usar o serviço Web Gateway.
Para facilitar a configuração, config-api é usado com um arquivo de configuração JSON simples.
```json
{
"Security.SSLConfigs": {
"%SuperServer": {
"CAFile": "/usr/irissys/mgr/CA_Server.cer",
"CertificateFile": "/usr/irissys/mgr/iris_server.cer",
"Name": "%SuperServer",
"PrivateKeyFile": "/usr/irissys/mgr/iris_server.key",
"Type": "1",
"VerifyPeer": 3
}
},
"Security.System": {
"SSLSuperServer":1
},
"Security.Services": {
"%Service_WebGateway": {
"ClientSystems": "172.16.238.50;127.0.0.1;172.16.238.20"
}
}
}
```
Nenhuma ação é necessária. A configuração será carregada automaticamente durante a inicialização do contêiner.
## Imagem tls-ssl-webgateway
### dockerfile
```
ARG IMAGEWEBGTW=containers.intersystems.com/intersystems/webgateway:2021.1.0.215.0
FROM ${IMAGEWEBGTW}
ADD webgateway-config-files /webgateway-config-files
ADD buildWebGateway.sh /
ADD startUpScript.sh /
RUN chmod +x buildWebGateway.sh startUpScript.sh && /buildWebGateway.sh
ENTRYPOINT ["/startUpScript.sh"]
```
Por padrão, o ponto de entrada é `/startWebGateway`, mas precisamos realizar algumas operações antes de iniciar o webserver. Lembre-se de que nosso arquivo CSP.ini é um `modelo`, e precisamos mudar alguns parâmetros (IP, porta, gerente de sistemas) na inicialização. `startUpScript.sh` realizará essas mudanças e executará o script de ponto de entrada inicial `/startWebGateway`.
## Inicializando os contêineres
### arquivo docker-compose
Antes de iniciar os contêineres, o arquivo `docker-compose.yml` precisa ser modificado:
* `**SYSTEM_MANAGER**` precisa ser definido com o IP autorizado para ter acesso ao **Gerenciamento do Web Gateway** https://localhost/csp/bin/Systems/Module.cxw Basicamente, é seu endereço IP (pode ser uma lista separada por vírgulas).
* `**IRIS_WEBAPPS**` precisa ser definido com a lista dos seus aplicativos CSP. A lista é separada por espaços, por exemplo: `IRIS_WEBAPPS=/csp/sys /swagger-ui`. Por padrão, apenas `/csp/sys` é exposto.
* As portas 80 e 443 são mapeadas. Adapte a outras portas se elas já estão em uso no seu sistema.
```
version: '3.6'
services:
webgateway:
image: tls-ssl-webgateway
container_name: tls-ssl-webgateway
networks:
app_net:
ipv4_address: 172.16.238.50
ports:
# mude a porta local já em uso no seu sistema.
- "80:80"
- "443:443"
environment:
- IRIS_HOST=172.16.238.20
- IRIS_PORT=1972
# Troque pela lista de endereços IP permitidos para abrir o gerente de sistema de CSP
# https://localhost/csp/bin/Systems/Module.cxw
# veja o arquivo .env para definir a variável de ambiente.
- "SYSTEM_MANAGER=${LOCAL_IP}"
# a lista de web apps
# /csp permite que o webgateway redirecione todas as solicitações que começam com /csp à instância iris
# Você pode especificar uma lista separada por um espaço : "IRIS_WEBAPPS=/csp /api /isc /swagger-ui"
- "IRIS_WEBAPPS=/csp/sys"
volumes:
# Monte os arquivos dos certificados.
- ./volume-apache/webgateway_client.cer:/opt/webgateway/bin/webgateway_client.cer
- ./volume-apache/webgateway_client.key:/opt/webgateway/bin/webgateway_client.key
- ./volume-apache/CA_Server.cer:/opt/webgateway/bin/CA_Server.cer
- ./volume-apache/apache_webgateway.cer:/etc/apache2/certificate/apache_webgateway.cer
- ./volume-apache/apache_webgateway.key:/etc/apache2/certificate/apache_webgateway.key
hostname: webgateway
command: ["--ssl"]
iris:
image: intersystemsdc/iris-community:latest
container_name: tls-ssl-iris
networks:
app_net:
ipv4_address: 172.16.238.20
volumes:
- ./iris-config-files:/opt/config-files
# Monte os arquivos dos certificados.
- ./volume-iris/CA_Server.cer:/usr/irissys/mgr/CA_Server.cer
- ./volume-iris/iris_server.cer:/usr/irissys/mgr/iris_server.cer
- ./volume-iris/iris_server.key:/usr/irissys/mgr/iris_server.key
hostname: iris
# Carregue o arquivo de configuração IRIS ./iris-config-files/iris-config.json
command: ["-a","sh /opt/config-files/configureIris.sh"]
networks:
app_net:
ipam:
driver: default
config:
- subnet: "172.16.238.0/24"
```
Compile e comece:
```bash
docker-compose up -d --build
```
Os contêineres `tls-ssl-iris e tls-ssl-webgateway devem ser inicializados.`
## Teste o acesso a Web
### Página padrão do Apache
Abra a página [http://localhost](http://localhost). Você será automaticamente redirecionado para [https://localhost](https://localhost).
Os navegadores mostram alertas de segurança. Esse é o comportamento padrão com um certificado autoassinado, aceite o risco e continue.
### Página de gerenciamento do Web Gateway
Abra [https://localhost/csp/bin/Systems/Module.cxw](https://localhost/csp/bin/Systems/Module.cxw) e teste a conexão com o servidor. 
### Portal de gerenciamento
Abra [https://localhost/csp/sys/utilhome.csp](https://localhost/csp/sys/utilhome.csp)
Ótimo! A amostra do Web Gateway está funcionando!
## Espelho IRIS com Web Gateway
No artigo anterior, criamos um ambiente de espelho, mas faltava o Web Gateway. Agora, podemos aprimorar isso.
Um novo repositório [iris-miroring-with-webgateway](https://github.com/lscalese/iris-mirroring-with-webgateway) está disponível, incluindo o Web Gateway e mais algumas melhorias:
1. Os certificados não são mais gerados na hora, mas em um processo separado.
2. Os endereços IP são substituídos pelas variáveis de ambiente nos arquivos de configuração docker-compose e JSON. As variáveis são definidas no arquivo '.env'.
3. O repositório pode ser usado como modelo.
Veja o arquivo [README.md](https://github.com/lscalese/iris-mirroring-with-webgateway) do repositório para a execução em um ambiente como este:

Artigo
Heloisa Paiva · Jun. 10
##Introdução
[MonLBL](https://docs.intersystems.com/iris20251/csp/docbook/Doc.View.cls?KEY=GCM_monlbl) é uma ferramenta para analisar o desempenho da execução de código ObjectScript linha por linha. [`codemonitor.MonLBL`](https://github.com/lscalese/iris-monlbl-example/blob/master/src/dc/codemonitor/MonLBL.cls) é um wrapper baseado no pacote [`%Monitor.System.LineByLine`](https://docs.intersystems.com/iris20251/csp/documatic/%25CSP.Documatic.cls?LIBRARY=%25SYS&PRIVATE=1&CLASSNAME=%25Monitor.System.LineByLine)do InterSystems IRIS, projetado para coletar métricas precisas sobre a execução de rotinas, classes ou páginas CSP.
O wrapper e todos os exemplos apresentados neste artigo estão disponíveis no seguinte repositório do GitHub: [iris-monlbl-example](https://github.com/lscalese/iris-monlbl-example)
## Funcionalidades
A ferramenta permite a coleta de diversos tipos de métricas:
- **RtnLine**: Número de execuções da linha
- **GloRef**: Número de referências a globais geradas pela linha
- **Time**: Tempo de execução da linha
- **TotalTime**: Tempo de execução total, incluindo sub-rotinas chamadas
Todas as métricas são exportadas para arquivos CSV.
Além das métricas linha a linha, `dc.codemonitor.MonLBL` coleta estatísticas de globais:
- Tempo total de execução
- Número total de linhas executadas
- Número total de referências a globais
-T empo de CPU do sistema e do usuário
* O tempo de CPU do usuário corresponde ao tempo gasto pelo processador executando o código da aplicação.
* O tempo de CPU do sistema corresponde ao tempo gasto pelo processador executando operações do sistema operacional (chamadas de sistema, gerenciamento de memória, E/S).
-Tempo de leitura do disco.
## Pré-requisitos
Para monitorar o código com MonLBL:
1. Obtenha a classe `dc.codemonitor.MonLBL` (disponível [aqui](https://github.com/lscalese/iris-monlbl-example/blob/master/src/dc/codemonitor/MonLBL.cls))
2. As rotinas ou classes a serem analisadas devem ser compiladas com as flags "ck".
## ⚠️ Aviso Importante
O uso do monitoramento linha a linha impacta o desempenho do servidor. É importante seguir estas recomendações:
- Use esta ferramenta apenas em um conjunto limitado de código e processos (idealmente para execução única em um terminal).
- Evite usá-la em um servidor de produção (mas, às vezes, é necessário).
- Prefira usar esta ferramenta em um ambiente de desenvolvimento ou teste.
Essas precauções são essenciais para evitar problemas de desempenho que possam afetar usuários ou sistemas de produção. Observe que o código monitorado é executado aproximadamente 15-20% mais lentamente do que o código não monitorado.
## Uso
### Exemplo Básico
```objectscript
// Cria uma instância de MonLBL
Set mon = ##class(dc.codemonitor.MonLBL).%New()
//Define as rotinas a serem monitoradas
Set mon.routines = $ListBuild("User.MyClass.1")
// Começa o monitoramento
Do mon.startMonitoring()
// Código a analisar
// ...
// Para o monitoramento e gera resultados
Do mon.stopMonitoring()
```
**Nota**: O monitoramento iniciado aqui é válido apenas para o processo atual. Outros processos que executam o mesmo código não serão incluídos nas medições.
### Opções de Configuração
O wrapper oferece várias opções configuráveis:
- **directory**:Diretório onde os arquivos CSV serão exportados (o padrão é o diretório Temp do IRIS).
- **autoCompile**: Recompila automaticamente as rotinas com as flags "ck" se necessário.
- **metrics**: Lista personalizável de métricas a serem coletadas.
- **decimalPointIsComma**: Usa uma vírgula como separador decimal para melhor compatibilidade com o Excel (dependendo do seu ambiente local).
- **metricsEnabled**:Habilita ou desabilita a coleta de métricas linha a linha.
## Exemplo de Uso Avançado
Aqui está um exemplo mais completo (disponível na classe `dc.codemonitor.Example`):
```objectscript
ClassMethod MonitorGenerateNumber(parameters As %DynamicObject) As %Status
{
Set sc = $$$OK
Try {
// Exibe parâmetros recebidos
Write "* Parameters:", !
Set formatter = ##class(%JSON.Formatter).%New()
Do formatter.Format(parameters)
Write !
// Cria e configura o monitor
Set monitor = ##class(dc.codemonitor.MonLBL).%New()
// AVISO: Em produção, defina o autoCompile para $$$NO
// e manualmente compile o código a monitorar
Set monitor.autoCompile = $$$YES
Set monitor.metricsEnabled = $$$YES
Set monitor.directory = ##class(%File).NormalizeDirectory(##class(%SYS.System).TempDirectory())
Set monitor.decimalPointIsComma = $$$YES
// Configure a rotina para o monitor (formato "int" da classe)
// Para achar o nome exato da rotina, use o comando:
// Do $SYSTEM.OBJ.Compile("dc.codemonitor.DoSomething","ck")
// A linha "Compiling routine XXX" deve exibir o nome da rotina
Set monitor.routines = $ListBuild("dc.codemonitor.DoSomething.1")
// Comece a monitorar
$$$TOE(sc, monitor.startMonitoring())
// Execute o código a monitorar com tratamento de erro
Try {
Do ##class(dc.codemonitor.DoSomething).GenerateNumber(parameters.Number)
// Importante: Sempre pare o monitoramento
Do monitor.stopMonitoring()
}
Catch ex {
// Pare o monitoramento mesmo em caso de erro
Do monitor.stopMonitoring()
Throw ex
}
}
Catch ex {
Set sc = ex.AsStatus()
Do $SYSTEM.Status.DisplayError(sc)
}
Return sc
}
```
Este exemplo demonstra várias melhores práticas importantes:
- Uso de um bloco Try/Catch para tratamento de erros.
- Interrupção sistemática do monitoramento, mesmo em caso de erro.
- Configuração completa do monitor.
## Exemplo com Páginas CSP
O MonLBL também permite o monitoramento de páginas CSP. Aqui está um exemplo (também disponível na classe`dc.codemonitor.ExampleCsp`):
```objectscript
ClassMethod MonitorCSP(parameters As %DynamicObject = {{}}) As %Status
{
Set sc = $$$OK
Try {
// Exibe parâmetros recebidos
Write "* Parameters:", !
Set formatter = ##class(%JSON.Formatter).%New()
Do formatter.Format(parameters)
Write !
// Cria e configura o monitor
Set monitor = ##class(dc.codemonitor.MonLBL).%New()
Set monitor.autoCompile = $$$YES
Set monitor.metricsEnabled = $$$YES
Set monitor.directory = ##class(%File).NormalizeDirectory(##class(%SYS.System).TempDirectory())
Set monitor.decimalPointIsComma = $$$YES
// Para monitorar uma página CSP, use a rotina gerada
// Exemplo: /csp/user/menu.csp --> classe: csp.menu --> rotina: csp.menu.1
Set monitor.routines = $ListBuild("csp.menu.1")
// Páginas CSP necessitam de objetos %session, %request, e %response
// Crie esses objetos com os parâmetros necessários
Set %request = ##class(%CSP.Request).%New()
// Configure os parâmetros de requisição se necessário
// Set %request.Data("", 1) =
Set %request.CgiEnvs("SERVER_NAME") = "localhost"
Set %request.URL = "/csp/user/menu.csp"
Set %session = ##class(%CSP.Session).%New(1234)
// Configure os dados da sessão se necessário
// Set %session.Data("", 1) =
Set %response = ##class(%CSP.Response).%New()
// Comece o monitoramento
$$$TOE(sc, monitor.startMonitoring())
Try {
// Para evitar a exibição do conteúdo da página CSP no terminal,
// use a classe IORedirect para redirecionar sa saída para nula
// (requere instalação via zpm "install io-redirect")
Do ##class(IORedirect.Redirect).ToNull()
// Chame a página CSP via seu método OnPage
Do ##class(csp.menu).OnPage()
// Restaure a saída padrão
Do ##class(IORedirect.Redirect).RestoreIO()
// Pare o monitoramento
Do monitor.stopMonitoring()
}
Catch ex {
// Sempre restaure a saída e pare o monitoramento no caso de erro
Do ##class(IORedirect.Redirect).RestoreIO()
Do monitor.stopMonitoring()
Throw ex
}
}
Catch ex {
Set sc = ex.AsStatus()
Do $SYSTEM.Status.DisplayError(sc)
}
Return sc
}
```
Pontos chave para monitorar páginas CSP:
1. **Identificação da Rotina**: Uma página CSP é compilada em uma classe e uma rotina. Por exemplo`/csp/user/menu.csp` gera a classe `csp.menu` e a rotina `csp.menu.1`.
2. **Ambiente CSP **:É necessário criar objetos de contexto CSP (%request, %session, %response) para que a página seja executada corretamente.
3. **Redirecionamento de Saída:**: Para evitar a exibição de conteúdo HTML no terminal, você pode usar a ferramenta IORedirect (disponível no [OpenExchange](https://openexchange.intersystems.com/package/IO-Redirect) via `zpm "install io-redirect"`).
4. **Chamada da Página**: A execução é feita através do método `OnPage()` da classe gerada.
##Exemplo de Saída
Aqui está um exemplo da saída obtida ao executar o método `MonitorGenerateNumber`:
```
USER>d ##class(dc.codemonitor.Example).MonitorGenerateNumber({"number":"100"})
* Parameters:
{
"number":"100"
}
* Metrics are exported to /usr/irissys/mgr/Temp/dc.codemonitor.DoSomething.1.csv
* Perf results:
{
"startDateTime":"2025-05-07 18:45:42",
"systemCPUTime":0,
"userCPUTime":0,
"timing":0.000205,
"lines":19,
"gloRefs":14,
"diskReadInMs":"0"
}
```
Nesta saída, podemos observar:
1.Exibição dos parâmetros de entrada.
2. Confirmação de que as métricas foram exportadas para um arquivo CSV.
3.Um resumo do desempenho global em formato JSON, incluindo:
- Data e hora de início
- Tempo de CPU do sistema e do usuário
- Tempo total de execução
- Número de linhas executadas
- Número de referências a globais
- Tempo de leitura do disco
## Interpretando os Resultados CSV
Após a execução, arquivos CSV (um por rotina na lista de rotinas $ListBuild) são gerados no diretório configurado. Esses arquivos contêm:
-Número da linha
-Métricas coletadas para cada linha
- Código-fonte da linha (nota: se você não compilou com a flag "k", o código-fonte não estará disponível no arquivo CSV)
Aqui está um exemplo do conteúdo de um arquivo CSV exportado: (dc.codemonitor.DoSomething.1.csv):
| Line | RtnLine | GloRef | Time | TotalTime | Code |
|------|---------|--------|------|-----------|------|
| 1 | 0 | 0 | 0 | 0 | ` ;dc.codemonitor.DoSomething.1` |
| 2 | 0 | 0 | 0 | 0 | ` ;Generated for class dc.codemonitor.DoSomething...` |
| 3 | 0 | 0 | 0 | 0 | ` ;;59595738;dc.codemonitor.DoSomething` |
| 4 | 0 | 0 | 0 | 0 | ` ;` |
| 5 | 0 | 0 | 0 | 0 | `GenerateNumber(n=1000000) methodimpl {` |
| 6 | 1 | 0 | 0.000005 | 0.000005 | ` For i=1:1:n {` |
| 7 | 100 | 0 | 0.000019 | 0.000019 | ` Set number = $Random(100000)` |
| 8 | 100 | 0 | 0.000015 | 0.000015 | ` Set isOdd = number # 2` |
| 9 | 100 | 0 | 0.000013 | 0.000013 | ` }` |
| 10 | 1 | 0 | 0.000003 | 0.000003 | ` Return }` |
Nesta tabela, podemos analisar:
- **RtnLine**: Indica quantas vezes cada linha foi executada (aqui, as linhas 6 e 10 foram executadas uma vez)
- **GloRef**: Mostra as referências globais geradas por cada linha
- **Time**: Apresenta o tempo de execução específico de cada linha
- **TotalTime**: Exibe o tempo total, incluindo chamadas para outras rotinas
Esses dados podem ser facilmente importados para uma planilha para uma análise aprofundada. As linhas que mais consomem recursos em termos de tempo ou acesso a dados podem, assim, ser facilmente identificadas.
### Observação sobre a Eficiência do Cache
A eficiência do cache do banco de dados (buffer global) pode mascarar problemas reais de desempenho. Durante a análise, o acesso aos dados pode parecer rápido devido a esse cache, mas pode ser muito mais lento em certas condições de uso no mundo real.
Em sistemas de desenvolvimento, você pode limpar o cache entre as medições com o seguinte comando:
```objectscript
Do ClearBuffers^|"%SYS"|GLOBUFF()
```
⚠️ **ATENÇÃO**: Tenha cuidado com este comando, pois ele se aplica a todo o sistema. Nunca o utilize em um ambiente de produção, já que pode impactar o desempenho de todas as aplicações em execução.
## Conclusão
O monitoramento linha a linha é uma ferramenta valiosa para analisar o desempenho do código ObjectScript. Ao identificar precisamente as linhas de código que consomem mais recursos, ele permite que os desenvolvedores economizem um tempo significativo na análise de gargalos de desempenho.
Anúncio
Guillaume Rongier · Set. 1, 2021
# 1. Demonstração Integrated ML
Este repositório é uma demonstração do IntegratedML e Python Incorporado.
- [1. Demonstração do Integrated ML](#1-integrated-ml-demonstration)
- [2. Construindo a Demonstração](#2-building-the-demo)
- [2.1. Arquitetura](#21-architecture)
- [2.2. Construindo o contêiner nginx](#22-building-the-nginx-container)
- [3. Executando a demonstração](#3-running-the-demo)
- [4. Back-end Python](#4-python-back-end)
- [4.1. Python Incorporado](#41-embedded-python)
- [4.1.1. Configurando o contêiner](#411-setting-up-the-container)
- [4.1.2. Utilizando o Python Incorporado](#412-using-embedded-python)
- [4.1.3. Comparação Lado a Lado](#413-side-by-side-comparaison)
- [4.2. Disponibilizando o Servidor](#42-launching-the-server)
- [5. IntegratedML](#5-integratedml)
- [5.1. Explorando ambos datasets](#51-exploring-both-datasets)
- [5.2. Gerenciando Modelos](#52-managing-models)
- [5.2.1. Criando um Modelo](#521-creating-a-model)
- [5.2.2. Treinando um Modelo](#522-training-a-model)
- [5.2.3. Validando um Modelo](#523-validating-a-model)
- [5.2.4. Realizando Previsões](#524-making-predictions)
- [6. Utilizando o COS](#6-using-cos)
- [7. Maior detalhamento com o DataRobot](#7-more-explainability-with-datarobot)
- [8. Conclusão](#8-conclusion)
# 2. Criando a Demonstração
Para criar a demonstração você deve apenas executar o seguinte comando:
````
docker compose up
````
## 2.1. Arquitetura
Dois contêineres serão criados: um com o IRIS e um com o servidor nginx.
A imagem do IRIS utilizada já contêm o Python Incorporado. Após contruído, o contêiner irá executar um servidor wsgi com a API Flask.
Estamos utilizando o pacote csvgen da Comunidade para importar o dataset titanic para o IRIS. Para o dataset de noshowutilizamos outro método customizado (o método de classe `Load()` da classe `Util.Loader`). PAra que o contêiner teha acesso aos arquivos csv nós associamos o diretório local `iris/` ao diretório `/opt/irisapp/` do contêiner.
## 2.2. Construindo o contêiner nginx
Para construir nosso contêiner nginx o docker utiliza uma construção multiestágio. Inicialmente ele cria um contêiner com nó, então ele instala o npm e copia todos nossos arquivos para o contêiner. Depois disto ele constrói o projeto com o comando `ng build` e o arquivo de saída é copiado para um novo contêiner que possui apenas o nginx.
Graças a esta manobra nós obtemos um contêiner bem leve que não contém todas a bibliotecas e ferramentas utilizadas para criar páginas web.
Você consegue verificar os detalhes desta construção multiestágio no arquivo `angular/Dockerfile`. Nós também configuramos os parâmetros de nosso servidor nginx graças ao arquivo `angular/nginx.default.conf`.
# 3. Executando a Demonstração
Apenas acesse o endereço: http://localhost:8080/ e é isso! Aproveitem!
# 4. Back-end Python
O back-end é baseado no Python Flask. Nós utilizamos o Python Incorporado para realizar as chamadas às classes do IRIS e executar consultas a partir do Python.
## 4.1. Python Incorporado
### 4.1.1. Configurando o contêiner
Precisamos inicialmente explicitar no dockerfile duas variáveis de ambiente que o Python Incorporado irá utilizar:
````dockerfile
ENV IRISUSERNAME "SuperUser"
ENV IRISPASSWORD $IRIS_PASSWORD
````
Com uma configuração no arquivo docker-compose do $IRIS_PASSWORD como esta:
````yaml
iris:
build:
args:
- IRIS_PASSWORD=${IRIS_PASSWORD:-SYS}
````
(A senha transferida é a que está configurada em sua máquina local ou, se a mesma não estiver definida, será por padrão a "SYS")
### 4.1.2. Utilizando o Python Incorporado
Para utilizar o Python Incorporado nós utilizamos `irispython` como interpretador python e fazemos:
```python
import iris
```
Bem no começo do arquivo.
Iremos então poder executar métodos como:
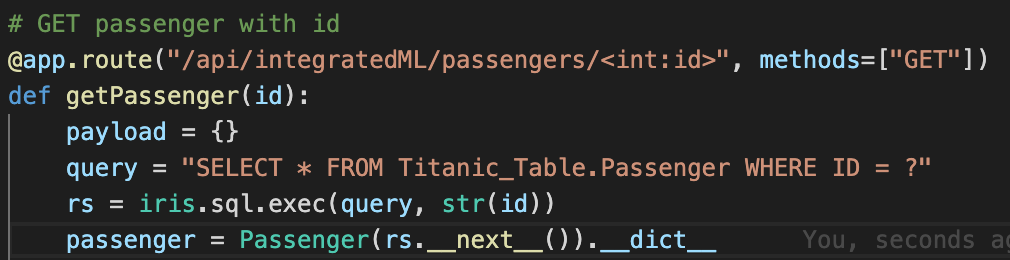
Como você pode ver, de forma a recuperar um paciente pelo ID nós apenas executamos uma consulta e utilizamos seu resultado.
Também podemos utilizar diretamente os objetos IRIS:
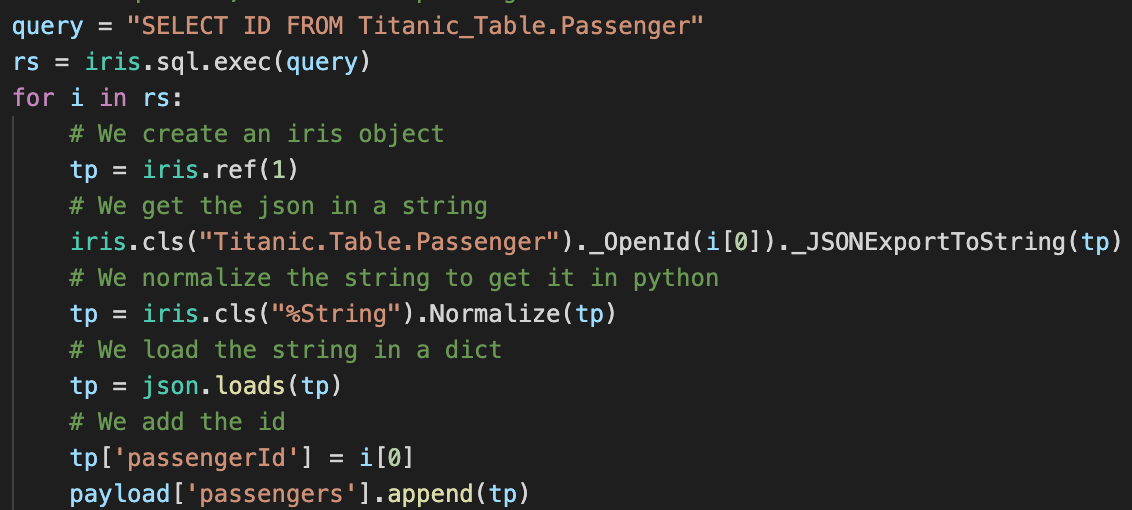
Aqui nós utilizamos uma consulta SQL para recuperar todos os IDs da tabela e então recuperamos cada passageiro da tabela com o método `%OpenId()` da classe Titanic.Table.Passenger` (notem que como o `%` é um caractere ilegal in Python utilizamos o `_` em substituição).
Graças ao Flask impleentamos todas nossas rotas e métodos desta forma.
### 4.1.3. Comparação Lado a Lado
Nesta imagem você tem uma comparação lado a lado entre uma implementação **Flask** e uma implementação **ObjectScript**.
Como você pode verificar, existem várias similaridades.
## 4.2. Disponibilizando o Servidor
Para disponibilizar o servidor utilizamos `gunicorn` com `irispython`.
Adicionamos a seguinte linha no arquivo docker-compose:
````yaml
iris:
command: -a "sh /opt/irisapp/flask_server_start.sh"
````
Esta alteração irá executar (graças a flag `-a`) , depois que o contêiner for iniciado, o seguinte script:
````bash
#!/bin/bash
cd ${FLASK_PATH}
${PYTHON_PATH} /usr/irissys/bin/gunicorn --bind "0.0.0.0:8080" wsgi:app -w 4 2>&1
exit 1
````
Com as variáveis de ambiente definidas no Dockerfile desta forma:
````dockerfile
ENV PYTHON_PATH=/usr/irissys/bin/irispython
ENV FLASK_PATH=/opt/irisapp/python/flask
````
Iremos então ter acesso ao back-end Flask através da porta local `4040`, devido a termos associado a porta 8080 do contêiner a ela.
# 5. IntegratedML
## 5.1. Explorando ambos datasets
Para ambos datasets você tera um acesso a um CRUD completo, lhe permitindo modificar como quiser as tabelas gravadas.
Para trocar de um dataset para outro você pode clicar no botão localizado na parte superior, à direita.
## 5.2. Gerenciando Modelos
### 5.2.1. Criando um Modelo
Uma vez que você descobriu o modelo, você pode agora criar um modelo para prever o valor que você quiser.
Acionando o menu lateral `Model Manager`, no item `Model List` você terá acesso a seguinte página (aqui, no caso do dataset NoShow):
Você pode escolher qual valor você quer prever, o nome do seu modelo e quais variáveis você quer utilizar para realizar a previsão.
No menu lateral você pode selecionar `See SQL queries?` para visualizar como os modelos são gerenciados no IRIS.
Depois de criar um modelo você deverá ver o seguinte:
Como vocês podem observar, a criação de um modelo necessita apenas de uma consulta SQL. As informações que você possui são todas as informações que você pode recuperar do IRIS.
Na coluna `actions` você pode deletar ou remover um modelo. Remover o modelo irá remover todos os treinamentos (e validações) exceto a última.
### 5.2.2. Treinando o Modelo
Na próxima aba você poderá treinar seus modelos.
Você poderá escolher entre 3 provedores. InterSystems' `AutoML`, `H2O`, uma solução de código aberto, e `DataRobot`, onde você consegue um período de 14 dias de teste grátis se você se registrar no site deles.
Você pode selecionar o percentual do dataset que você deseja utilizar para treinar seu modelo. Como o treinamento pode ser demorado em casos de grandes datasets, para propósito de demonstrações é possível utilizar um dataset menor.
Aqui nós treinamos um modelo usando o dataset Titanic completo:
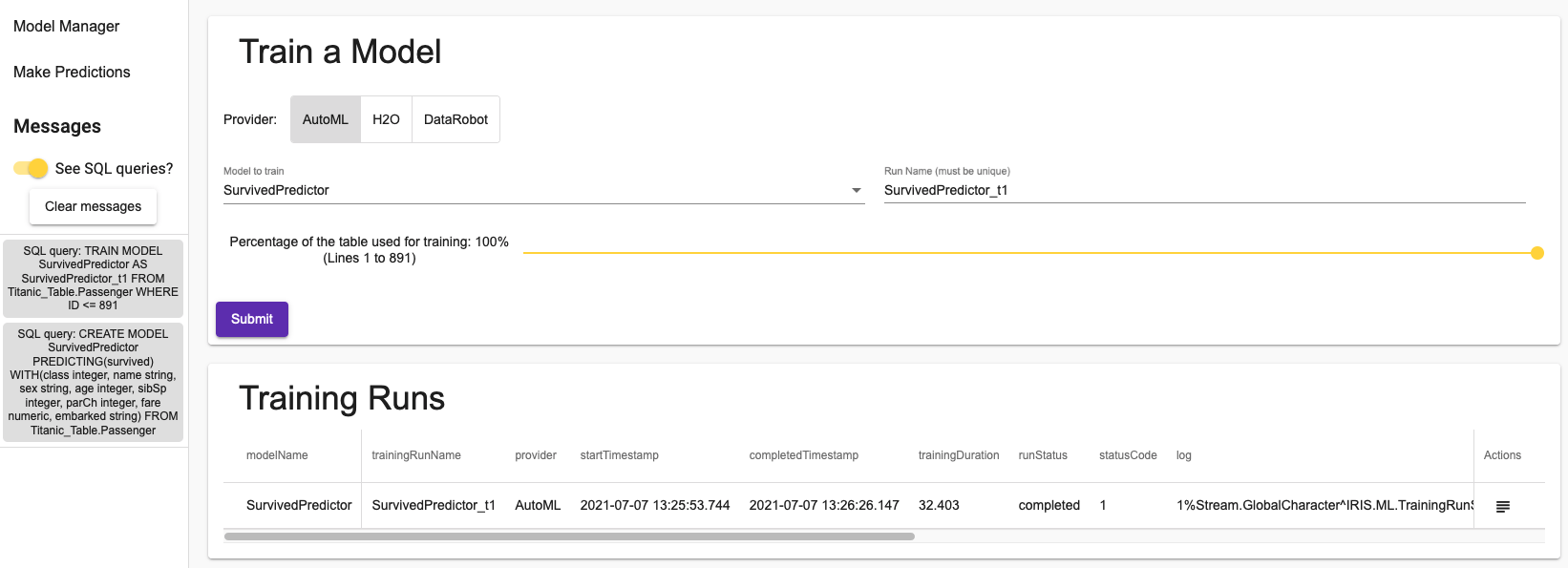
O botão na coluna `actions` irá permitir que você verifique o log. Para o AutoML você verá o que o algoritmo fez de fato: como ele preparou os dados e como ele escolheu qual modelo utilizar.
Para treinar um modelo é necessária apenas uma consulta SQL, como você pode verificar na seção de mensagens do menu lateral.
Tenha em mente que nessas duas abas você verá apenas os modelos referentes ao dataset que você está utilizando no momento.
### 5.2.3. Validando um Modelo
Finalmente você pode validar um modelo na aba final. Clicando na execução da validação irá abrir uma janela de pop-up. Lá você poderá escolher o percentual do dataset que será utilizado para a validação.
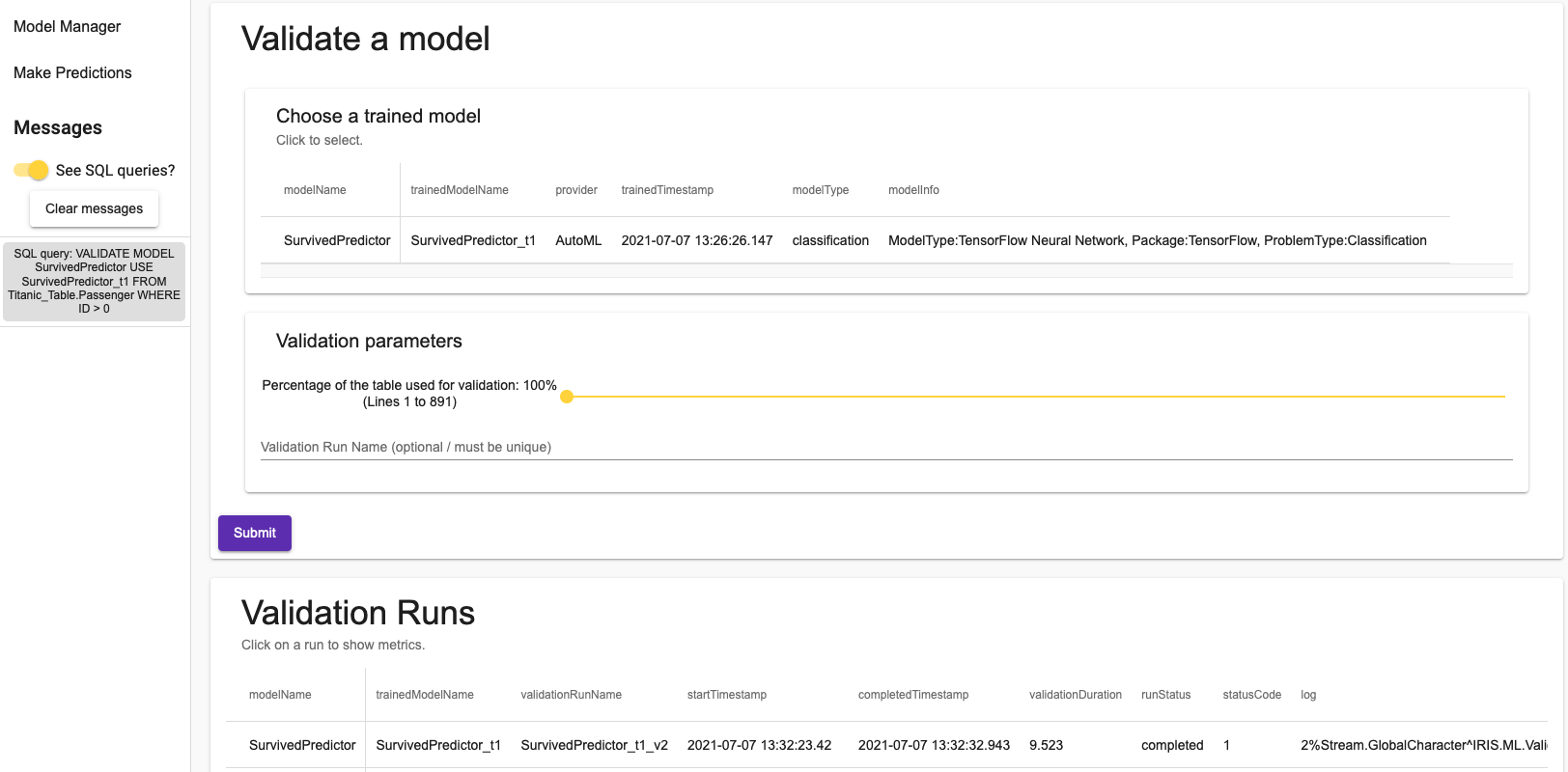
Mais uma vez, é necessária apenas uma consulta SQL.
### 5.2.4. Realizando Previsões
No menu `Make Predictions`, na última aba, você pode realizar previsões utilizando seu recente modelo treinado.
Você precisa apenas buscar um passageiro / paciente e selecioná-lo, selecionar um dos modelos treinados e delecionar a opção prever.
No caso de um modelo de classificação (como neste exemplo, para prever a sobrevivência), a previsão estará associada com a probabilidade de estar na classe prevista.
No caso da Sra. Fatima Masselmani, o modelo previu corretamente que ela sobreviveu, com uma probabilidade de 73%. Logo abaixo desta predição você pode visualizar os dados utilizados pelo modelo:
Mais uma vez, foi necessária apenas uma consulta para recuperar a predição e uma para a probabilidade.
# 6. Utilizando o COS
A demonstração disponibiliza duas APIs. Nós utilizamos a API Flask com o Python Incorporado porém um serviço REST em COS também foi configurado na construção do contêiner.
Pressionando o botão na parte superior direita **"Switch to COS API"**, você poderá utilizar este serviço.
Note como nada se altera, ambas as APIs são equivalentes e funcionam da mesma forma.
# 7. Maior detalhamento com o DataRobot
Se você quiser um maior detalhamento (mais do que o log pode lhe oferecer), sugerimos que você utiliza o provedor DataRobot.
Para isso você precisará acessar o endereço de sua instância DataRobot e procurar por `Developer Tools` para conseguir seu token. Ao treinar o modelo a página solicitará seu token.
Uma vez que o treinamento iniciar você poderá acessar sua instância DataRobot para saber muito mais sobre seu dataset e seus modelos
:
Aqui podemos ver que os campos `sex` e `name` de cada passageiro foram os valores mais importantes utilizados na predição da sobrevivência. Nós podemos também visualizar que o campo `fare` contém informações fora do padrão.
Uma vez que os modelos estiverem treinados você poderá acessar **vários** detalhes, aqui está um exemplo:
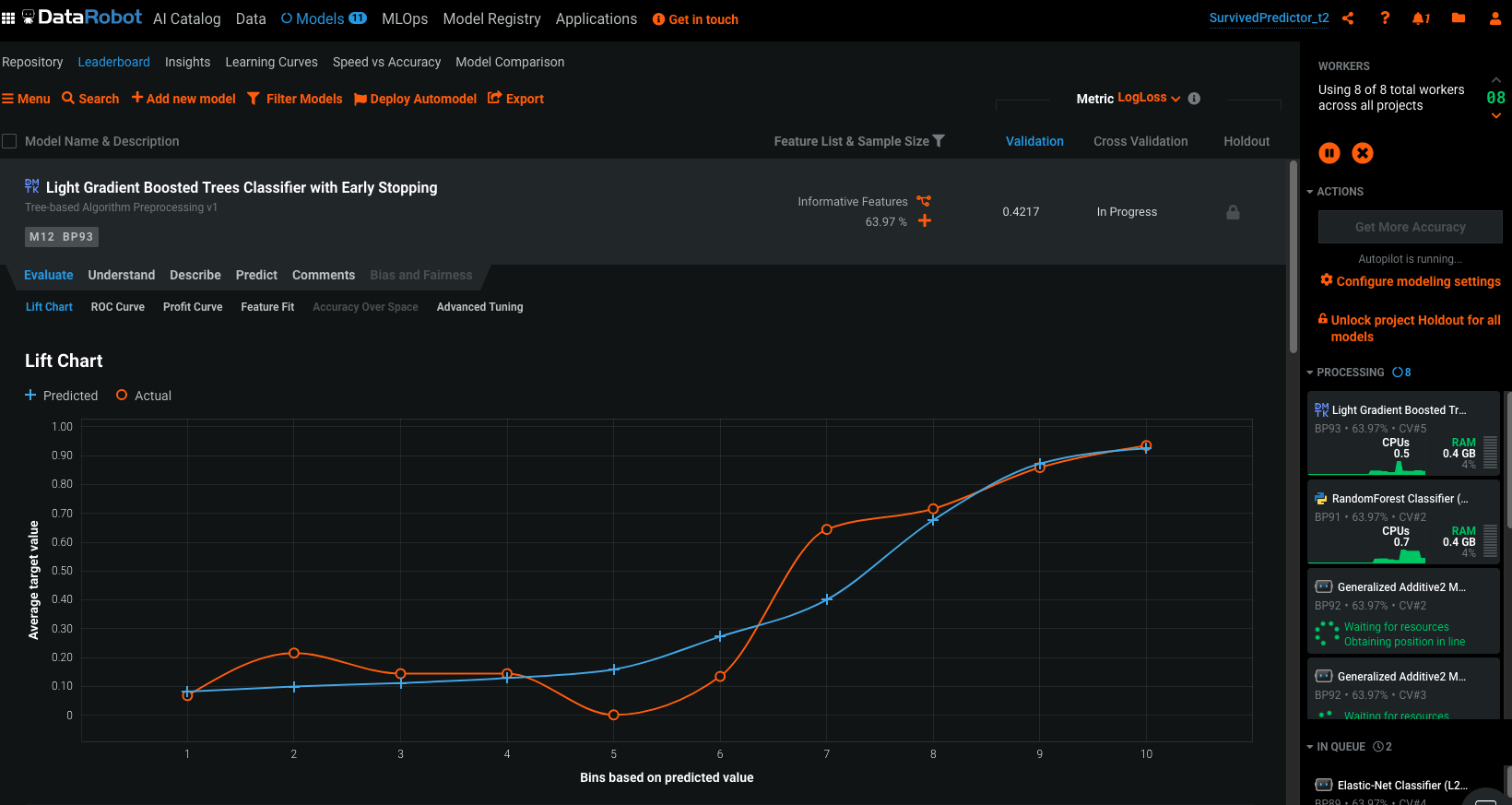
# 8. Conclusão
Através desta demonstração nós pudemos observar como é fácil criar, treinar e validar um modelo, bem como predizer valores através de poucas consultas SQL.
Conseguimos fazer isto utilizando uma API RESTful com Python Flask, utilizando Python Incorporado e também fizemos um comparativo utilizando uma API COS.
O front-end foi desenvolvido em Angular.
Artigo
David Loveluck · Dez. 9, 2020
Desde o Caché 2017, o mecanismo SQL inclui um novo conjunto de estatísticas. Ele registra o número de vezes que uma consulta é executada e o tempo que leva para executá-la.
Esta é uma mina de ouro para qualquer pessoa que está monitorando e tentando otimizar o desempenho de uma aplicação que inclui muitas instruções SQL, mas que não é tão fácil de acessar os dados como algumas pessoas desejam.
Este artigo e o código de exemplo associado explicam como usar essas informações e como extrair rotineiramente um resumo de estatísticas diárias e manter um registro histórico de desempenho do SQL de sua aplicação.
O que está registrado?
Toda vez que uma instrução SQL é executada, o tempo gasto é registrado. Esse registro é muito leve e você não pode desativá-lo. Para minimizar o custo, as estatísticas são mantidas na memória e gravadas no disco periodicamente. Os dados incluem o número de vezes que uma consulta foi executada no dia e a média e o tempo total gasto.
Os dados não são gravados no disco imediatamente, e depois de gravados, as estatísticas são atualizadas pela tarefa "Atualizar estatísticas de consulta SQL" que geralmente é programada para se executada a cada hora. Essa tarefa pode ser executada manualmente, mas se você quiser ver as estatísticas em tempo real enquanto testa uma consulta, todo o processo requer um pouco de paciência.
Aviso: No InterSystems IRIS 2019 e anteriores, essas estatísticas não são coletadas para SQL embutido em classes ou rotinas que foram implantadas usando o mecanismo %Studio.Project:Deploy. Nada quebrará com o código de exemplo, mas pode enganar você (me enganou) fazendo-o pensar que tudo estava OK porque nada parecia tão custoso.
Como você vê as informações?
Você pode ver a lista de consultas no portal de gerenciamento. Vá para a página SQL e clique na aba ‘Instruções SQL’. É ótimo para uma nova consulta que você está executando e examinando, mas se houver milhares de consultas em execução, pode-se tornar incontrolável.
A alternativa é usar o SQL para pesquisar as consultas. As informações são armazenadas em tabelas no esquema INFORMATION_SCHEMA. Este esquema tem várias tabelas e incluí alguns exemplos de consultas SQL no final deste artigo.
Quando as estatísticas são removidas?
Os dados de uma consulta são removidos sempre que ela é recompilada. Portanto, para consultas dinâmicas, isso pode significar quando as consultas em cache são limpas. Para SQL embutido, isso significa quando a classe ou rotina em que o SQL está embutido é recompilado.
Em um site ativo, é razoável esperar que as estatísticas sejam mantidas por mais de um dia, mas as tabelas que contêm as estatísticas não podem ser usadas como uma fonte de referência para relatórios ou análises de longo prazo.
Como você pode resumir as informações?
Recomendo extrair os dados todas as noites em tabelas permanentes que são mais fáceis de trabalhar ao gerar os relatórios de desempenho. Há uma chance de que algumas informações sejam perdidas se as classes forem compiladas durante o dia, mas é improvável que isso faça alguma diferença real em sua análise de consultas lentas.
O código a seguir é um exemplo de como você pode extrair as estatísticas em um resumo diário para cada consulta. Inclui três classes curtas:
* Uma tarefa que deve ser executada todas as noites. * DRL.MonitorSQL é a classe principal que extrai e armazena os dados das tabelas INFORMATION_SCHEMA.
A terceira classe DRL.MonitorSQLText é uma otimização que armazena o texto da consulta (potencialmente longo) uma vez e armazena apenas o hash da consulta nas estatísticas de cada dia.
Notas sobre o exemplo
A tarefa é extraída do dia anterior e, portanto, deve ser agendada logo após a meia-noite.
Você pode exportar mais dados históricos, se houver. Para extrair os últimos 120 dias
Faça ##class(DRL.MonitorSQL).Capture($h-120,$h-1)
O código de exemplo lê o ^rIndex global diretamente porque as versões mais antigas das estatísticas não expunham a Data ao SQL.
A variação, incluí loops em todos os namespaces na instância, mas isso nem sempre é apropriado.
Como consultar os dados extraídos
Uma vez que os dados são extraídos, você pode encontrar as consultas mais pesadas executando
SELECT top 20
S.RunDate,S.RoutineName,S.TotalHits,S.SumpTIme,S.Hash,t.QueryText
from DRL.MonitorSQL S
left join DRL.MonitorSQLText T on S.Hash=T.Hash
where RunDate='08/25/2019'
order by SumpTime desc
Além disso, se você escolher o hash para uma consulta custosa, poderá ver o histórico dessa consulta com
SELECT S.RunDate,S.RoutineName,S.TotalHits,S.SumpTIme,S.Hash,t.QueryText
from DRL.MonitorSQL S
left join DRL.MonitorSQLText T on S.Hash=T.Hash
where S.Hash='CgOlfRw7pGL4tYbiijYznQ84kmQ='
order by RunDate
No início deste ano, obtive dados de um site ativo e examinei as consultas mais custosas. Uma consulta demorava em média menos de 6 segundos, mas estava sendo chamada 14.000 vezes por dia, totalizando quase 24 horas decorridas todos os dias. Efetivamente, um núcleo estava totalmente ocupado com esta única consulta. Pior ainda, a segunda consulta que leva uma hora foi uma variação da primeira.
Data de Execução
Nome da Rotina
Visitas Totais
Tempo Total
Hash
Texto da Consulta (abreviado)
16/03/2019
14.576
85.094
5xDSguu4PvK04se2pPiOexeh6aE=
DECLARE C CURSOR FOR SELECT * INTO :%col(1) , :%col(2) , :%col(3) , :%col(4) …
16/03/2019
15.552
3.326
rCQX+CKPwFR9zOplmtMhxVnQxyw=
DECLARE C CURSOR FOR SELECT * INTO :%col(1) , :%col(2) , :%col(3) , :%col(4) , …
16/03/2019
16.892
597
yW3catzQzC0KE9euvIJ+o4mDwKc=
DECLARE C CURSOR FOR SELECT * INTO :%col(1) , :%col(2) , :%col(3) , :%col(4) , :%col(5) , :%col(6) , :%col(7) ,
16/03/2019
16.664
436
giShyiqNR3K6pZEt7RWAcen55rs=
DECLARE C CURSOR FOR SELECT * , TKGROUP INTO :%col(1) , :%col(2) , :%col(3) , ..
16/03/2019
74.550
342
4ZClMPqMfyje4m9Wed0NJzxz9qw=
DECLARE C CURSOR FOR SELECT …
Tabela 1: Resultados reais do site do cliente
Tabelas no esquema INFORMATION_SCHEMA
Assim como as estatísticas, as tabelas neste esquema controlam onde as consultas, colunas, índices etc. são usados. Normalmente, a instrução SQL é a tabela inicial e é juntada em algo como “Statements.Hash=OtherTable.Statement”.
A consulta equivalente para acessar essas tabelas diretamente para encontrar as consultas mais custosas para um dia seria…
SELECT DS.Day,Loc.Location,DS.StatCount,DS.StatTotal,S.Statement,S.Hash
FROM INFORMATION_SCHEMA.STATEMENT_DAILY_STATS DS
left join INFORMATION_SCHEMA.STATEMENTS S
on S.Hash=DS.Statement
left join INFORMATION_SCHEMA.STATEMENT_LOCATIONS Loc
on S.Hash=Loc.Statement
where Day='08/26/2019'
order by DS.stattotal desc
Esteja você pensando em configurar um processo mais sistemático ou não, recomendo que todos com uma grande aplicação que usa SQL executem essa consulta hoje.
Se uma consulta específica parecer custosa, você pode obter o histórico executando
SELECT DS.Day, Loc.Location, DS.StatCount, DS.StatTotal, S.Statement, S.Hash
FROM INFORMATION_SCHEMA.STATEMENT_DAILY_STATS DS
left join INFORMATION_SCHEMA.STATEMENTS S
on S.Hash=DS.Statement
left join INFORMATION_SCHEMA.STATEMENT_LOCATION Loc
on S.Hash=Loc.Statement
where S.Hash='jDqCKaksff/4up7Ob0UXlkT2xKY='
order by DS.Day
Exemplo de código para extrair estatísticas diariamente
Isenção de responsabilidade padrão - este exemplo é apenas para ilustração. Não há suporte ou garantia de funcionamento.
Class DRL.MonitorSQLTask Extends %SYS.Task.Definition{Parameter TaskName = "SQL Statistics Summary";Method OnTask() As %Status{ set tSC=$$$OK TRY { do ##class(DRL.MonitorSQL).Run() } CATCH exp { set tSC=$SYSTEM.Status.Error("Error in SQL Monitor Summary Task") } quit tSC }}
Class DRL.MonitorSQLText Extends %Persistent{/// Hash do texto da consultaProperty Hash As %String;
/// texto de consulta para hashProperty QueryText As %String(MAXLEN = 9999);Index IndHash On Hash [ IdKey, Unique ];}
/// Resumo das estatísticas de consulta SQL de custo muito baixo coletadas no Caché 2017.1 e posterior. /// Consulte a documentação sobre "Detalhes da instrução SQL" para obter informações sobre os dados de origem. /// Os dados são armazenados por data e hora para dar suporte a consultas ao longo do tempo. /// Normalmente executado para resumir os dados da consulta SQL do dia anterior.Class DRL.MonitorSQL Extends %Persistent{/// RunDate e RunTime identificam exclusivamente uma execuçãoProperty RunDate As %Date;/// Horário em que a captura foi iniciada/// RunDate e RunTime identificam exclusivamente uma execuçãoProperty RunTime As %Time;/// Contagem do total de acessos para o período Property TotalHits As %Integer;/// Soma de pTimeProperty SumPTime As %Numeric(SCALE = 4);/// Rotina onde o SQL é encontradoProperty RoutineName As %String(MAXLEN = 1024);/// Hash do texto da consultaProperty Hash As %String;Property Variance As %Numeric(SCALE = 4);/// Namespace onde as consultas são executadasProperty Namespace As %String;/// A execução padrão processará os dados dos dias anteriores para um único dia./// Outras combinações de intervalo de datas podem ser obtidas usando o método de captura.ClassMethod Run(){ //Cada execução é identificada pela data / hora de início para manter os itens relacionados juntos set h=$h-1 do ..Capture(+h,+h)}/// Captura estatísticas históricas para um intervalo de datasClassMethod Capture(dfrom, dto){ set oldstatsvalue=$system.SQL.SetSQLStatsJob(-1) set currNS=$znspace set tSC=##class(%SYS.Namespace).ListAll(.nsArray) set ns="" set time=$piece($h,",",2) kill ^||TMP.MonitorSQL do { set ns=$o(nsArray(ns)) quit:ns="" use 0 write !,"processing namespace ",ns zn ns for dateh=dfrom:1:dto { set hash="" set purgedun=0 do { set hash=$order(^rINDEXSQL("sqlidx",1,hash)) continue:hash="" set stats=$get(^rINDEXSQL("sqlidx",1,hash,"stat",dateh)) continue:stats="" set ^||TMP.MonitorSQL(dateh,ns,hash)=stats &SQL(SELECT Location into :tLocation FROM INFORMATION_SCHEMA.STATEMENT_LOCATIONS WHERE Statement=:hash) if SQLCODE'=0 set Location="" set ^||TMP.MonitorSQL(dateh,ns,hash,"Location")=tLocation &SQL(SELECT Statement INTO :Statement FROM INFORMATION_SCHEMA.STATEMENTS WHERE Hash=:hash) if SQLCODE'=0 set Statement="" set ^||TMP.MonitorSQL(dateh,ns,hash,"QueryText")=Statement } while hash'="" } } while ns'="" zn currNS set dateh="" do { set dateh=$o(^||TMP.MonitorSQL(dateh)) quit:dateh="" set ns="" do { set ns=$o(^||TMP.MonitorSQL(dateh,ns)) quit:ns="" set hash="" do { set hash=$o(^||TMP.MonitorSQL(dateh,ns,hash)) quit:hash="" set stats=$g(^||TMP.MonitorSQL(dateh,ns,hash)) continue:stats="" // No loop, pela primeira vez, exclua todas as estatísticas do dia para que seja executável novamente // Mas se executarmos por um dia após os dados brutos terem sido eliminados, isso destruirá tudo // então faça aqui, onde já sabemos que há resultados para inserir em seu lugar. if purgedun=0 { &SQL(DELETE FROM websys.MonitorSQL WHERE RunDate=:dateh ) set purgedun=1 } set tObj=##class(DRL.MonitorSQL).%New() set tObj.Namespace=ns set tObj.RunDate=dateh set tObj.RunTime=time set tObj.Hash=hash set tObj.TotalHits=$listget(stats,1) set tObj.SumPTime=$listget(stats,2) set tObj.Variance=$listget(stats,3) set tObj.Variance=$listget(stats,3) set queryText=^||TMP.MonitorSQL(dateh,ns,hash,"QueryText") set tObj.RoutineName=^||TMP.MonitorSQL(dateh,ns,hash,"Location") &SQL(Select ID into :TextID from DRL.MonitorSQLText where Hash=:hash) if SQLCODE'=0 { set textref=##class(DRL.MonitorSQLText).%New() set textref.Hash=tObj.Hash set textref.QueryText=queryText set sc=textref.%Save() } set tSc=tObj.%Save() //evite duplicar o texto da consulta em cada registro porque pode ser muito longo. Use uma tabela de pesquisa //com chave no hash. Se não existir, adicione.. if $$$ISERR(tSc) do $system.OBJ.DisplayError(tSc) if $$$ISERR(tSc) do $system.OBJ.DisplayError(tSc) } while hash'="" } while ns'="" } while dateh'="" do $system.SQL.SetSQLStatsJob(0)}Query Export(RunDateH1 As %Date, RunDateH2 As %Date) As %SQLQuery{SELECT S.Hash,RoutineName,RunDate,RunTime,SumPTime,TotalHits,Variance,RoutineName,T.QueryText FROM DRL.MonitorSQL S LEFT JOIN DRL.MonitorSQLText T on S.Hash=T.Hash WHERE RunDate>=:RunDateH1 AND RunDate<=:RunDateH2}}
Artigo
Henry Pereira · jan 7, 2021
**Tempo** **estimado de leitura**: 6 minutos
Olá a todos,
Fui apresentado ao TDD há quase 9 anos e imediatamente me apaixonei por ele.
Hoje em dia se tornou muito popular, mas, infelizmente, vejo que muitas empresas não o utilizam. Além disso, muitos desenvolvedores nem sabem o que é exatamente ou como usá-lo, principalmente iniciantes.
#### Visão Geral
Meu objetivo com este artigo é mostrar como usar TDD com %UnitTest. Vou mostrar meu fluxo de trabalho e explicar como usar o [cosFaker](https://github.com/henryhamon/cosfaker), um dos meus primeiros projetos, que criei usando o Caché e recentemente carreguei no [OpenExchange](https://openexchange.intersystems.com/package/CosFaker).
Então, aperte o cinto e vamos lá.
#### O que é TDD?
O Desenvolvimento Guiado por Testes (TDD) pode ser definido como uma prática de programação que instrui os desenvolvedores a escrever um novo código apenas se um teste automatizado falhar.
Existem toneladas de artigos, palestras, apresentações, seja o que for, sobre suas vantagens e todas estão corretas.
Seu código já nasce testado, você garante que seu sistema realmente atenda aos requisitos definidos para ele, evitando o excesso de engenharia, e você tem um feedback constante.
Então, por que não usar o TDD? Qual é o problema com o TDD? A resposta é simples: o Custo! Isso custa muito!
Como você precisa escrever mais linhas de código com TDD, é um processo lento. Mas com o TDD você tem um custo final para criar um produto AGORA, sem ter que adicioná-lo no futuro.
Se você executar os testes o tempo todo, encontrará os erros antecipadamente, reduzindo assim o custo de sua correção.
Portanto, meu conselho: Simplesmente Faça!
#### Configuração
A InterSystems tem uma documentação e tutorial sobre como usar o %UnitTest, [que você pode ler aqui. ](https://irisdocs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=TUNT)
Eu uso o vscode para desenvolver. Desta forma, crio uma pasta separada para testes. Eu adiciono o caminho para código do meu projeto ao UnitTestRoot e quando executo testes, passo o nome da subpasta de teste. E eu sempre passo no qualificador loadudl
Set ^UnitTestRoot = "~/code"
Do ##class(%UnitTest.Manager).RunTest("myPack","/loadudl")
#### Passos
Provavelmente você já ouviu falar sobre o famoso ciclo TDD: vermelho ➡ verde ➡ refatorar. Você escreve um teste que falha, você escreve um código de produção simples para fazê-lo passar e refatora o código de produção.
Então, vamos sujar as mãos e criar uma classe para fazer cálculos matemáticos e outra para testá-la. A última classe deve estender de %UnitTest.TestCase.
Agora vamos criar um ClassMethod para retornar um quadrado de um número inteiro:
Class Production.Math
{
ClassMethod Square(pValue As %Integer) As %Integer
{
}
}
E teste o que acontecerá se passarmos 2. Deve retornar 4.
Class TDD.Math Extends %UnitTest.TestCase
{
Method TestSquare()
{
Do $$$AssertEquals(##class(Production.Math).Square(2), 4)
}
}
Se você executar:
Do ##class(%UnitTest.Manager).RunTest("TDD","/loadudl")
o teste irá Falhar

Vermelho! O próximo passo é torná-lo Verde.
Para fazer funcionar, vamos retornar 4 como resultado da execução do nosso método Square.
Class Production.Math
{
ClassMethod Square(pValue As %Integer) As %Integer
{
Quit 4
}
}
e executar novamente nosso teste.

Provavelmente você não está muito satisfeito com esta solução, porque ela funciona para apenas um cenário. Ótimo! Vamos dar o próximo passo. Vamos criar outro cenário de teste, agora enviando um número negativo.
Class TDD.Math Extends %UnitTest.TestCase
{
Method TestSquare()
{
Do $$$AssertEquals(##class(Production.Math).Square(2), 4)
}
Method TestSquareNegativeNumber()
{
Do $$$AssertEquals(##class(Production.Math).Square(-3), 9)
}
}
Quando executamos o teste:

ele Falhará novamente, então vamos refatorar o código de produção:
Class Production.Math
{
ClassMethod Square(pValue As %Integer) As %Integer
{
Quit pValue * pValue
}
}
e executar novamente nossos testes:

Agora tudo funciona bem... Esse é o ciclo do TDD, em pequenos passos.
Você deve estar se perguntando: por que devo seguir esses passos? Por que eu tenho que ver o teste falhar?
Trabalhei em equipes que escreveram o código de produção e só depois escrevi os testes. Mas eu prefiro seguir estes passos de bebê pelos seguintes motivos:
Tio Bob (Robert C. Martin) disse que escrever testes depois de escrever o código não é TDD e, em vez disso, é chamado de “perda de tempo”.
Outro detalhe, quando vejo o teste falhar, e depois vejo passar, estou testando o teste.
Seu teste também é um código; e pode conter erros também. E a maneira de testá-lo é garantir que ele falhe e seja aprovado quando for necessário. Desta forma, você "testou o teste".
#### cosFaker
Para escrever bons testes, você pode precisar gerar dados de teste primeiro. Uma maneira de fazer isso é gerar um despejo (dump) de dados e usá-lo em seus testes.
Outra maneira é usar o [cosFaker ](https://openexchange.intersystems.com/package/CosFaker)para gerar facilmente dados falsos quando você precisar deles.
Basta fazer o download do arquivo xml, em seguida vá para o Portal de Gerenciamento -> System Explorer -> Classes -> Import. Selecione o arquivo xml a ser importado ou arraste o arquivo no Studio.
Você também pode importá-lo usando o Terminal
Do $system.OBJ.Load("yourpath/cosFaker.vX.X.X.xml","ck")
##### Localização
O cosFaker adicionará arquivos de localidades na pasta da aplicação CSP padrão. Por enquanto, existem apenas dois idiomas: Inglês e Português do Brasil (minha língua nativa).
O idioma dos dados é escolhido de acordo com a configuração do seu Caché.
A localização do cosFaker é um processo contínuo, se você quiser ajudar, não hesite em criar um provedor localizado para sua própria localidade e enviar um Pull Request.
Com o cosFaker você pode gerar palavras aleatórias, parágrafos, números de telefone, nomes, endereços, e-mails, preços, nomes de produtos, datas, códigos de cores hexadecimais... etc.
Todos os métodos são agrupados por assunto nas classes, ou seja, para gerar uma Latitude você chama o método Latitude na classe Address
Write ##class(cosFaker.Address).Latitude()
-37.6806
Você também pode gerar Json para seus testes
Write ##class(cosFaker.JSON).GetDataJSONFromJSON("{ip:'ipv4',created_at:'date.backward 40',login:'username', text: 'words 3'}")
{
"created_at":"2019-03-08",
"ip":"95.226.124.187",
"login":"john46",
"text":"temporibus fugit deserunt"
}
Aqui está uma lista completa das classes e métodos do **cosFaker**:
* **cosFaker.Address**
* StreetSuffix
* StreetPrefix
* PostCode
* StreetName
* Latitude
* _Output:_ -54.7274
* Longitude
* _Output:_ -43.9504
* Capital( Location = “” )
* State( FullName = 0 )
* City( State = “” )
* Country( Abrev = 0 )
* SecondaryAddress
* BuildingNumber
* **cosFaker.App**
* FunctionName( Group= “”, Separator = “” )
* AppAction( Group= “” )
* AppType
* **cosFaker.Coffee**
* BlendName
* _Output:_ Cascara Cake
* Variety
* _Output:_ Mundo Novo
* Notes
* _Output:_ crisp, slick, nutella, potato defect!, red apple
* Origin
* _Output:_ Rulindo, Rwanda
* **cosFaker.Color**
* Hexadecimal
* _Output:_ #A50BD7
* RGB
* _Output:_ 189,180,195
* Name
* **cosFaker.Commerce**
* ProductName
* Product
* PromotionCode
* Color
* Department
* Price( Min = 0, Max = 1000, Dec = 2, Symbol = “” )
* _Output:_ 556.88
* CNPJ( Pretty = 1 )
* CNPJ is the Brazilian National Registry of Legal Entities
* _Output:_ 44.383.315/0001-30
* **cosFaker.Company**
* Name
* Profession
* Industry
* **cosFaker.Dates**
* Forward( Days = 365, Format = 3 )
* Backward( Days = 365, Format = 3 )
* **cosFaker.DragonBall**
* Character
* _Output:_ Gogeta
* **cosFaker.File**
* Extension
* _Output:_ txt
* MimeType
* _Output:_ application/font-woff
* Filename( Dir = “”, Name = “”, Ext = “”, DirectorySeparator = “/” )
* _Output:_ repellat.architecto.aut/aliquid.gif
* **cosFaker.Finance**
* Amount( Min = 0, Max = 10000, Dec = 2, Separator= “,”, Symbol = “” )
* _Output:_ 3949,18
* CreditCard( Type = “” )
* _Output:_ 3476-581511-6349
* BitcoinAddress( Min = 24, Max = 34 )
* _Output:_ 1WoR6fYvsE8gNXkBkeXvNqGECPUZ
* **cosFaker.Game**
* MortalKombat
* _Output:_ Raiden
* StreetFighter
* _Output:_ Akuma
* Card( Abrev = 0 )
* _Output:_ 5 of Diamonds
* **cosFaker.Internet**
* UserName( FirstName = “”, LastName = “” )
* Email( FirstName = “”, LastName = “”, Provider = “” )
* Protocol
* _Output:_ http
* DomainWord
* DomainName
* Url
* Avatar( Size = “” )
* _Output:_ http://www.avatarpro.biz/avatar?s=150
* Slug( Words = “”, Glue = “” )
* IPV4
* _Output:_ 226.7.213.228
* IPV6
* _Output:_ 0532:0b70:35f6:00fd:041f:5655:74c8:83fe
* MAC
* _Output:_ 73:B0:82:D0:BC:70
* **cosFaker.JSON**
* GetDataOBJFromJSON( Json = “” // String de modelo JSON para criar dados )
* _Parameter Example_: "{dates:'5 date'}"
* _Output_: {"dates":["2019-02-19","2019-12-21","2018-07-02","2017-05-25","2016-08-14"]}
* **cosFaker.Job**
* Title
* Field
* Skills
* **cosFaker.Lorem**
* Word
* Words( Num = “” )
* Sentence( WordCount = “”, Min = 3, Max = 10 )
* _Output:_ Sapiente et accusamus reiciendis iure qui est.
* Sentences( SentenceCount = “”, Separator = “” )
* Paragraph( SentenceCount = “” )
* Paragraphs( ParagraphCount = “”, Separator = “” )
* Lines( LineCount = “” )
* Text( Times = 1 )
* Hipster( ParagraphCount = “”, Separator = “” )
* **cosFaker.Name**
* FirstName( Gender = “” )
* LastName
* FullName( Gender = “” )
* Suffix
* **cosFaker.Person**
* cpf( Pretty = 1 )
* CPF is the Brazilian Social Security Number
* _Output:_ 469.655.208-09
* **cosFaker.Phone**
* PhoneNumber( Area = 1 )
* _Output:_ (36) 9560-9757
* CellPhone( Area = 1 )
* _Output:_ (77) 94497-9538
* AreaCode
* _Output:_ 17
* **cosFaker.Pokemon**
* Pokemon( EvolvesFrom = “” )
* _Output:_ Kingdra
* **cosFaker.StarWars**
* Characters
* _Output:_ Darth Vader
* Droids
* _Output:_ C-3PO
* Planets
* _Output:_ Takodana
* Quotes
* _Output:_ Only at the end do you realize the power of the Dark Side.
* Species
* _Output:_ Hutt
* Vehicles
* _Output:_ ATT Battle Tank
* WookieWords
* _Output:_ nng
* WookieSentence( SentenceCount = “” )
* _Output:_ ruh ga ru hnn-rowr mumwa ru ru mumwa.
* **cosFaker.UFC**
* Category
* _Output:_ Middleweight
* Fighter( Category = “”, Country = “”, WithISOCountry = 0 )
* _Output:_ Dmitry Poberezhets
* Featherweight( Country = “” )
* _Output:_ Yair Rodriguez
* Middleweight( Country = “” )
* _Output:_ Elias Theodorou
* Welterweight( Country = “” )
* _Output:_ Charlie Ward
* Lightweight( Country = “” )
* _Output:_ Tae Hyun Bang
* Bantamweight( Country = “” )
* _Output:_ Alejandro Pérez
* Flyweight( Country = “” )
* _Output:_ Ben Nguyen
* Heavyweight( Country = “” )
* _Output:_ Francis Ngannou
* LightHeavyweight( Country = “” )
* _Output:_ Paul Craig
* Nickname( Fighter = “” )
* _Output:_ Abacus
Vamos criar uma classe para o usuário com um método que retorna seu nome de usuário, que será FirstName concatenado com LastName.
Class Production.User Extends %RegisteredObject
{
Property FirstName As %String;
Property LastName As %String;
Method Username() As %String
{
}
}
Class TDD.User Extends %UnitTest.TestCase
{
Method TestUsername()
{
Set firstName = ##class(cosFaker.Name).FirstName(),
lastName = ##class(cosFaker.Name).LastName(),
user = ##class(Production.User).%New(),
user.FirstName = firstName,
user.LastName = lastName
Do $$$AssertEquals(user.Username(), firstName _ "." _ lastName)
}
}

Refatorando:
Class Production.User Extends %RegisteredObject
{
Property FirstName As %String;
Property LastName As %String;
Method Username() As %String
{
Quit ..FirstName _ "." _ ..LastName
}
}

Agora vamos adicionar uma data de expiração da conta e validá-la.
Class Production.User Extends %RegisteredObject
{
Property FirstName As %String;
Property LastName As %String;
Property AccountExpires As %Date;
Method Username() As %String
{
Quit ..FirstName _ "." _ ..LastName
}
Method Expired() As %Boolean
{
}
}
Class TDD.User Extends %UnitTest.TestCase
{
Method TestUsername()
{
Set firstName = ##class(cosFaker.Name).FirstName(),
lastName = ##class(cosFaker.Name).LastName(),
user = ##class(Production.User).%New(),
user.FirstName = firstName,
user.LastName = lastName
Do $$$AssertEquals(user.Username(), firstName _ "." _ lastName)
}
Method TestWhenIsNotExpired() As %Status
{
Set user = ##class(Production.User).%New(),
user.AccountExpires = ##class(cosFaker.Dates).Forward(40)
Do $$$AssertNotTrue(user.Expired())
}
}

Refatorando:
Method Expired() As %Boolean
{
Quit ($system.SQL.DATEDIFF("dd", ..AccountExpires, +$Horolog) > 0)
}

Agora vamos testar quando a conta expirou:
Method TestWhenIsExpired() As %Status
{
Set user = ##class(Production.User).%New(),
user.AccountExpires = ##class(cosFaker.Dates).Backward(40)
Do $$$AssertTrue(user.Expired())
}

E tudo está verde...
Eu sei que esses são exemplos bobos, mas dessa forma você verá a simplicidade não apenas no código, mas também no design da classe.
#### Conclusão
Neste artigo, você aprendeu um pouco sobre Desenvolvimento Guiado por Testes e como usar a classe %UnitTest.
Também cobrimos o cosFaker e como gerar dados falsos para seus testes.
Há muito mais para aprender sobre testes e TDD, como usar essas práticas com código legado, testes de integração, testes de aceitação (ATDD), bdd, etc...
Se você quiser saber mais sobre isso, recomendo fortemente 2 livros:
[Test Driven Development Teste e design no mundo real com Ruby - Mauricio Aniche](https://www.amazon.com/Test-driven-development-Teste-design-Portuguese-ebook/dp/B01B6MSVBK/ref=sr_1_3?qid=1553909895&refinements=p_27%3AMauricio+Aniche&s=digital-text&sr=1-3&text=Mauricio+Aniche), realmente não sei se este livro tem versão em inglês. Existem edições para Java, C #, Ruby e PHP. Este livro me surpreendeu com sua grandiosidade.
E, claro, o livro de Kent Beck [Test Driven Development by Example](https://www.amazon.com.br/Test-Driven-Development-Kent-Beck/dp/0321146530/ref=pd_sbs_14_2/131-5080621-0921627?_encoding=UTF8&pd_rd_i=0321146530&pd_rd_r=23604a58-528d-11e9-8a77-f188713467c0&pd_rd_w=TSR2y&pd_rd_wg=JBqE6&pf_rd_p=80c6065d-57d3-41bf-b15e-ee01dd80424f&pf_rd_r=CJ3QPX0H0P6H0EMNFZYJ&psc=1&refRID=CJ3QPX0H0P6H0EMNFZYJ)
Sinta-se à vontade para deixar comentários ou perguntas.
Isso é tudo, pessoal Parabéns @Henry.HamonPereira pelo excelente artigo!
Artigo
José Pereira · Jul. 6, 2023
Este projeto é um experimento em usar as APIs da OpenAI para responder prompts de usuários no domínio de saúde usando recursos FHIR e codificação em Python.
## Ideia do projeto
IA generativas, como os modelos de LLM disponíveis na [OpenAI](https://platform.openai.com/docs/models), vem demonstrando impressionante capacidade para compreender e responder à questões de alto nível.
Elas podem inclusive [usar linguagens de programação para criar códigos baseado em instruções contidas nos prompts](https://platform.openai.com/examples?category=code) - e tenho que confessar que a ideia de ter meu trabalho automatizado me causa um pouco de ansiedade. Mas pelo o que tenho visto até agora, parece que isso é algo sobre o qual as pessoas serão obrigadas a se acostumar, gostando ou não. Então, decidi fazer alguns experimentos.
A ideia principal por traz desse projeto veio quando li [este artigo](https://the-decoder.com/chatgpt-programs-ar-app-using-only-natural-language-chatarkit/) sobre o [projeto ChatARKit](https://github.com/trzy/ChatARKit). Este projeto usa as APIs da OpenAI para interpretar comandos de voz para renderizar objetos 3D em vídeos exibidos em smartphones - um projeto muito interessante. E parece que este é um assunto de interesse, já que encontrei um [artigo recente](https://dl.acm.org/doi/pdf/10.1145/3581791.3597296) seguindo a mesma ideia.
O que mais me deixou curioso sobre este artigo foi o uso do ChatGPT para **programar** uma aplicação de AR. Como o repositório do github está publicamente disponível, procurei nele e achei [como o autor usou o ChatGPT para gerar código](https://github.com/trzy/ChatARKit/blob/master/iOS/ChatARKit/ChatARKit/Engine/ChatGPT.swift). Depois, descobri que este tipo de técnica é chamada de *engenharia de prompt* - [aqui está um artigo da Wikipedia sobre este assunto](https://en.wikipedia.org/wiki/Prompt_engineering), ou então estes dois outros mais práticos: [1](https://microsoft.github.io/prompt-engineering/) e [2](https://learn.microsoft.com/en-us/azure/cognitive-services/openai/concepts/advanced-prompt-engineering?pivots=programming-language-chat-completions).
Assim, pensei - e se eu tentasse algo similar, mas usando FHIR e Python? Isto foi o que veio à mente:
Fig.1 - Ideia básica do projeto
Seus principais elementos são:
- Um módulo para tratar da engenharia de prompt, o qual irá instruir o modelo de IA usar FHIR e Python
- Um módulo de integração com as APIs da OpenAI
- Um interpretador Python para executar o código gerado
- Um servidor FHIR para responder às consultas geradas pelo modelo de IA
A ideia básica é usar a [API Completion da OpenAI](https://platform.openai.com/docs/api-reference/completions) para solicitar à IA dividir o prompt do usuário como um conjunto de consultas FHIR. Então, o modelo de IA cria um script Python para manipular os recursos FHIR retornados pelo servidor FHIR no InterSystems IRIS for Health.
Se este simples esquema funcionar, usuários poderiam obter respostas à perguntas as quais ainda não são suportadas pelo modelo analítico das aplicações. Posteriormente, estas questões respondidas pelo modelo de IA, poderiam ser analisadas de forma a descobrir novas necessidades dos usuários.
Outra vantagem deste esquema é o fato de que não há necessidade de exportar dados e esquemas para APIs externas. Por exemplo, perguntas sobre pacientes podem ser realizadas sem a necessidade de enviar dados desses pacientes ou esquemas do banco de dados para um servidor de IA. Como o modelo de AI usa somente elementos publicamente disponíveis - FHIR e Python nesse caso, não há necessidade de publicação de dados internos.
No entanto, este mesmo esquema também nos remete à algumas dúvidas, tais como:
- Como guiar o modelo de IA à usar FHIR e Python de acordo com as necessidades dos usuários?
- As respostas geradas pelo modelo de IA são corretas?
- Como lidar com problemas de segurança que a execução de código Python gerado externamente?
Desta forma, de forma a construir algum suporte à essas dúvidas, realizei algumas alterações sobre o esquema pensado inicialmente:
Fig.2 - Ideia depois de refinamento
Agora, alguns novos elementos foram adicionados:
- Um analisador de código Python para localizar problemas de segurança
- Um módulo para registro de eventos (logs) para análise posterior.
- Uma API REST para futuras integrações
Assim, este projeto tem por objetivo ser uma prova de conceito o qual pode suportar experimentos para obter informações para tentar responder às questões como as propostas anteriormente.
Nas próximas seções, você verá como usar o projeto, alguns resultados obtidos tentando responder às questões mencionadas acima e, algumas conclusões.
Espero que você goste do projeto e o julgue útil. E sua colaboração com o projeto é mais que bem vinda!
## Usando o projeto
Para usar o projeto, abra um terminal IRIS e execute o seguinte:
```objectscript
ZN "USER"
Do ##class(fhirgenerativeai.FHIRGenerativeAIService).RunInTerminal("")
```
Por exemplo, as seguintes questões foram usadas para testar o projeto:
1. How many patients are in the dataset?
2. What is the average age of patients?
3. Give me all conditions (code and name) removing duplications. Present the result in a table format. (Don't use pandas)
4. How many patients has the condition viral sinusitis (code 444814009)?
5. What is the prevalence of viral sinusitis (code 444814009) in the patient population? For patients with the same condition multiple times, consider just one hit to your calculations.
6. Among patients with viral sinusitis (code 444814009), what is the distribution of gender groups?
Você encontra exemplos de saídas para essas questões [aqui](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/misc/tests-accuacy).
> OBS: mantive as questões em inglês para caso você tente usa-las no projeto, os resultados sejam o mais parecido possível. Mas nada impede de você tentar traduzi-las antes de enviar para a API da OpenAI.
> Por favor, observe que ao tentar repetir essas perguntas em seu sistema as respostas podem variar, mesmo para as mesmas perguntas. Isso se deve à natureza estocástica dos modelos de LLM.
Estas questões foram sugeridas pelo ChatGPT. Foi solicitado que tais questões fossem criadas de uma forma na qual o nível de complexidade fosse sendo aumentado. Com exceção da terceira questão, que foi elaborada pelo autor.
## Engenharia de prompt
O prompt usado pelo projeto pode ser encontrado [aqui](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/src/fhirgenerativeai/PromptService.cls) no método `GetSystemTemplate()`.
Ele segue os princípios de engenharia de prompt onde, primeiro é atribuído um papel ao modelo de IA, e após isso, uma série de restrições e instruções. O objetivo de cada uma de suas seções estão comentadas, assim é possível entender como o prompt funciona.
Observe o uso de um tipo de definição de interface, quando o modelo é instruído à assumir a existência de uma função chamada `CallFHIR()` para interagir com FHIR, ao invés de deixar o modelo declarar funções para tal. Isto foi inspirado pelo projeto ChatARKit, onde o autor define um conjunto de funções que abstraem a complexidade de uso de uma biblioteca de AR.
Aqui, usei esta técnica para evitar que o modelo crie código para realizar chamadas HTTP de forma direta.
Um achado interessante aqui foi sobre forçar o modelo de IA à retornar sua resposta em formato XML. Como é esperado que um código Python seja retornado, formatei-o em XML para uso do bloco CDATA.
Apesar de ter sido claro no prompt para que a resposta também seja no formato XML, o modelo de IA só passou a seguir à esta instrução após também enviar o prompt do usuário formato em XML. É possível verifica isso no método `FormatUserPrompt()` na mesma classe referenciada acima.
## Analisador de código Python
Este módulo usa a [biblioteca bandit](https://bandit.readthedocs.io/en/latest/) para procurar por problemas de segurança no código Python gerado.
Esta biblioteca gera a AST do programa Python e o testa com relação à problemas de segurança comuns. Os tipos de problemas detectados estão nos seguintes links:
- [Test plugins](https://bandit.readthedocs.io/en/latest/plugins/index.html#complete-test-plugin-listing)
- [Calls blacklist](https://bandit.readthedocs.io/en/latest/blacklists/blacklist_calls.html)
- [Imports blacklist](https://bandit.readthedocs.io/en/latest/blacklists/blacklist_imports.html)
Cada código Python retornado pelo modelo de IA é testado para verificar se há problemas de segurança. Caso algo esteja errado, a execução é cancelada e um evento de erro é registrado.
## Registro de eventos
Todos os eventos do sistema são registrados para análise posterior na tabela [LogTable](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/src/fhirgenerativeai/LogTable.cls).
Cada execução para responder à uma pergunta possui em ID de sessão. Este ID pode ser encontrado na coluna 'SessionID' na tabela e usado para recuperar todos os eventos associados a ele, passando-o para o método `RunInTerminal("", )`. Por exemplo:
```objectscript
Do ##class(fhirgenerativeai.FHIRGenerativeAIService).RunInTerminal("", "asdfghjk12345678")
```
Também é possível recuperar todos os eventos usando este SQL:
```sql
SELECT *
FROM fhirgenerativeai.LogTable
order by id desc
```
## Testes
Alguns testes foram executados para conseguir informações para medir o desempenho do modelo de IA.
Cada testes foi repetido 15 vezes e suas saídas estão armazenadas [neste](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/misc/tests-accuacy) e [neste](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/misc/tests-security) diretórios.
> Por favor, observe que ao tentar repetir essas perguntas em seu sistema as respostas podem variar, mesmo para as mesmas perguntas. Isso se deve à natureza estocástica dos modelos de LLM.
### Taxa de acertos
Nos testes da questão número 1, foram obtidos `14 resultados 6`, e `1 erro`. O valor correto é `6`. Então, houve `100%` de acertos, mas um percentual de falhas de execução de `6%`.
SQL usado para validar os resultados do teste para a questão número 1:
```sql
SELECT
count(*)
FROM HSFHIR_X0001_S.Patient
```
Nos testes da questão número 2, foram obtidos `3 resultados 52`, `6 resultados 52.5` e `6 erros`. O valor correto - considerando idades com valores decimais, é `52.5`. Desta forma, considerei ambos os valores corretos já que essa pequena diferença de valores seja provavelmente devido à ambiguidades no prompt - ele não menciona nada sobre permitir ou não idades com valores decimais. Assim, houve `100%` de acerto, mas com uma taxa de erros de execução de `40%`.
SQL usado para validar os resultados do teste para a questão número 2:
```sql
SELECT
birthdate, DATEDIFF(yy,birthdate,current_date), avg(DATEDIFF(yy,birthdate,current_date))
FROM HSFHIR_X0001_S.Patient
```
Nos testes da questão número 3, foram obtidos `3 erros` e `12 tabelas com 23 linhas`. Os valores das tabelas não ficaram nas mesmas posições e formato, porém novamente atribuí esse comportamento à limitações no prompt. Desta forma, houve `100%` de acerto, porém com uma taxa de falha de execução de `20%`.
SQL usado para validar os resultados do teste para a questão número 3:
```sql
SELECT
code, count(*)
FROM HSFHIR_X0001_S.Condition
group by code
```
Nos testes da questão número 4, foram obtidos `2 erros`, `12 resultados 7` e `1 resultado 4`. O valor correto é `4`. Então, foram `7%` acertos, e uma taxa de erros de execução de `13%`.
SQL usado para validar os resultados do teste para a questão número 4:
```sql
SELECT
p.Key patient, count(c._id) qtde_conditions, list(c.code) conditions
FROM HSFHIR_X0001_S.Patient p
join HSFHIR_X0001_S.Condition c on c.patient = p.key
where code like '%444814009%'
group by p.Key
```
Nos testes da questão número 5, foram obtidos `11 erros`, `3 resultados 4` e `1 resultado 0.6`. O valor correto é `4`. Então, houve `75%` de acertos, e uma taxa de erros de execução de `73%`.
O SQL usado para validar os resultados da questão número 5 foi o mesmo usado na questão número 4.
Nos testes da questão número 6, foram obtidos `12 erros` e `3 resultados {female: 4, male: 2, other: 0}`. O valor correto é `{female: 3, male: 1, other: 0}`. Desta forma, houve `0%` de acertos, e uma taxa de erros de execução de `80%`.
SQL usado para validar os resultados do teste para a questão número 6:
```sql
SELECT
p.gender, count(distinct p._id) qty_patients, list(p.key) patients, list(c.code) conditions
FROM HSFHIR_X0001_S.Patient p
join HSFHIR_X0001_S.Condition c on c.patient = p.key
where code like '%444814009%'
group by p.gender
```
Resumindo os resultados:
| Número do teste | Taxa de acertos| Taca de erros de execução|
|-----------------|----------------|--------------------------|
| 1 | 100% | 6% |
| 2 | 100% | 40% |
| 3 | 100% | 20% |
| 4 | 7% | 13% |
| 5 | 75 % | 73% |
| 6 | 0% | 80% |
### Segurança
Como se pode observar nos códigos gerados no [diretório de testes](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/misc/tests-accuacy), aparentemente nenhum problema de segurança foi gerado pelo modelo de IA - e esse foi o mesmo resultado que o analisador de código encontrou, nenhum problema de segurança.
Então, de forma a testar se o analisador de código era capaz de detectar problemas de segurança, o [módulo que executa os códigos Python](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/src/fhirgenerativeai/PythonService.cls) tem uma propriedade chamada `CodeInjection` , onde códigos maliciosos podem ser injetados para serem testados.
Desta forma, os seguintes códigos maliciosos foram injetados para o teste de segurança:
1. Teste de segurança número 1:
```python
print(eval("os.chmod('%s', 0o777)" % 'test.txt'))
```
Este código tenta acessar o sistema de arquivos do SO e alterar as permissões de um arquivo. Isto é claramente um código não esperado para o propósito do projeto, assim tendo que ser bloqueado.
2. Teste de segurança número 2:
```python
import requests
url = "https://postman-echo.com/get"
params = {"arg": "value"}
response = requests.get(url, params=params)
data = response.json()
print(data)
```
Este código tenta realizar uma requisição HTTP para um endereço externo - uma API do Postman neste caso. Se o código for executado, informações locais poderiam ser facilmente vazadas.
Como pode ser observado no [diretório para os testes de segurança](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/misc/tests-security), o analisador de códigos foi bem sucedido em encontrar os problemas de segurança.
## Conclusões
No que diz respeito à taxa de acertos, o modelo de IA obteve resultados corretos para as questões de baixa complexidade, mas começou a falhar conforme essa complexidade aumentou. O mesmo foi observado para taxa de falhas na execução. Assim, quanto mais complexas são as questões, mais o modelo de IA gera código com falha de execução e com maior probabilidade de levar a resultados com valores incorretos.
Isto significa que melhorias devem ser realizadas no prompt. Por exemplo, no [código da questão 6](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/misc/tests-accuacy/6/1688265739062.txt), o erro foi pesquisar apenas os recursos Patient e ignorar os códigos dos recursos Conditions associados. Este tipo de análise é necessária para guiar as mudanças necessárias no prompt.
No geral, o desempenho do modelo de IA nos testes mostra que ainda é necessário melhorias antes de que este seja considerado apto à responder perguntas analíticas.
Isto é devido à natureza estocástica dos modelos de IA. Quero dizer, no projeto ChartARKit citado anteriormente, se o modelo de IA renderizar um objeto 3D não exatamente no lugar requisitado mas próximo a ele, provavelmente o usuário não irá ligar muito. Infelizmente, o mesmo não pode ser dito para perguntas analíticas, nesse caso as respostas devem ser exatas.
Entretanto, é importante ressaltar que não estou dizendo que os modelos de IA são incapazes de realizarem tal tarefa. O que estou dizendo é que a maneira como o modelo de IA foi utilizado nesse projeto precisa de melhorias.
Importante também notar que este projeto não usou técnicas mais avançadas de IAs generativas, como [Langchain](https://python.langchain.com/docs/get_started/introduction.html) e [AutoGPT](https://autogpt.net/autogpt-installation-and-features/). Aqui um abordagem mais "pura" foi utilizada; talvez o uso ferramentas mais sofisticadas podem levar a resultados melhores.
Com relação à segurança, o analisador de código foi capaz de detectar todos os problemas de segurança testados.
Entretanto, isto não significa que o código gerado pelo modelo de IA é 100% seguro. Além disso, permitir a execução de código Python gerado externamente pode ser perigoso, sem sobra de dúvidas. Nem mesmo é possível afirmar com 100% de segurança que o sistema que está entregando o código Python é realmente o servidor da OpenAI...
Uma melhor saída para evitar problemas de segurança poderia ser o uso de outra linguagem de programação menos poderosa que Python, ou até mesmo criar uma "linguagem" própria e solicitar ao modelo de IA que a use, como pode ser visto [neste exemplo simples](https://platform.openai.com/examples/default-text-to-command).
Finalmente, é importante observar que aspectos como desempenho de execução de código, não foram considerados nesse projeto e provavelmente seria também um bom assunto para trabalhos futuros.
Assim, espero que você tenha achado esse projeto interessante e útil.
>**Aviso: Este é um projeto experimental. Ele envia dados para APIs da OpenAI e executa código gerado pelo modelo de IA no seu sistema. Então, não o use sobre dados sensíveis e/ou sistemas em produção. Observe também que chamadas para APIs da OpenAI são cobradas. Use este projeto sobre risco próprio. Ele não é um projeto pronto para ser usado em produção.**
muito bom!!! parabéns!!!
Artigo
Heloisa Paiva · Abr. 30
Olá Comunidade,
Gostaria de apresentar meu último pacote OpenAPI-Suite. Este é um conjunto de ferramentas para gerar código ObjectScript a partir de uma especificação OpenAPI versão 3.0.. IEm resumo, estes pacotes permitem:
Gerar classes de servidor. É bem parecido com o código gerado por ^%REST mas o valor adicionado é o suporte à versão 3.0.
Gerar classes de cliente HTTP.
Gerar classes de produção de cliente (business services, business operation, business process, Ens.Request, Ens.Response).
Uma interface web para gerar e baixar o código ou gerar e compilar diretamente no servidor.
Converter especificações das versões 1.x, 2.x para a versão 3.0.
Visão Geral
O OpenAPI Suite é dividido em vários pacotes e utiliza diferentes bibliotecas da comunidade de desenvolvedores e também serviços REST públicos. Você pode ver no esquema abaixo todos os pacotes que foram desenvolvidos, e as bibliotecas e serviços web utilizados:
Observação: Em caso de problemas ao usar serviços REST públicos, é possível iniciar uma instância Docker do serviço de conversão e validação.
O que cada pacote faz?
O OpenAPI Suite foi projetado em diferentes pacotes para facilitar a manutenção, melhoria e extensão futura. Cada pacote tem um papel. Vamos dar uma olhada!
openapi-common-lib
Isto contém todo o código comum aos outros pacotes. Por exemplo openapi-client-gen e openapi-server-gen aceitam a seguinte entrada para uma especificação OpenAPI:
URL
Caminho de arquivo
%Stream.Object
%DynamicObject
Formato YAML
Formato JSON
OpenAPI versão1.x, 2.x, 3.0.x.
No entanto, apenas uma especificação 3.0.x em um %DynamicObject pode ser processada. O código para a transformação está localizado neste pacote. Ele também contém várias utilidades.
swagger-converter-cli
É uma dependência do openapi-common-lib. Este é um cliente HTTP que utiliza o serviço REST públicoconverter.swagger.iopara converter OpenAPI versão 1.x ou 2.x para a versão 3.0.
swagger-validator-cli
É também uma dependência do openapi-common-lib, mesmo que seu nome seja "validator", ele não é usado para validar a especificação. O converter.swagger.iofornece o serviço "parse" que permite simplificar a estrutura de uma especificação OpenAPI. Por exemplo: criar uma definição para uma "nested object definition" e substituí-la por um "$ref". Isso reduz o número de casos a serem tratados no algoritmo de geração de código.
openapi-client-gen
Este pacote é dedicado à geração de código do lado do cliente para ajudar os desenvolvedores a consumir serviços REST.
Ele inclui um cliente HTTP simples ou um cliente de Produção(business services, process, operation, Production classes). Originalmente criado para suportar OpenAPI 2.x, foi completamente refatorado para suportar a versão 3.x.
openapi-server-gen
O oposto do openapi-client-gen, é dedicado à geração de código do lado do servidor. Não há interesse na versão 2.0 da especificação porque o ^%RESTexiste, mas o objetivo deste pacote é o suporte à versão 3.0.
openapi-suite
Ele reúne todos os pacotes acima e fornece uma API REST para:
Gerar o código e compilar o código na instância IRIS.
Gerar código sem compilar para download apenas.
Uma interface web também é fornecida para consumir esta API REST e, assim, explorar as funcionalidades do OpenAPI Suite.
E as bibliotecas?
Aqui estão algumas das bibliotecas existentes no DC que foram úteis neste desenvolvimento:
objectscript-openapi-definition
Uma biblioteca útil para gerar classes de modelo a partir de uma especificação OpenAPI. Esta é uma parte muito importante deste projeto e eu também sou um contribuidor.
ssl-client
Permite criar configurações SSL. Usado principalmente para criar um nome de configuração "DefaultSSL" para requisições HTTPS.
yaml-utils
No caso de especificação em formato YAML, esta biblioteca é usada para converter para o formato JSON. Essencial neste projeto. A propósito, foi desenvolvida inicialmente para testar a especificação YAML com a versão 1 do openapi-client-gen.
io-redirect
Esta é uma das minhas bibliotecas. Ela permite redirecionar a saída de "write" para um stream, arquivo, global ou variável string. É usada pelo serviço REST para manter um rastreamento dos logs. É inspirada nesta postagem da comunidade.
Instalação IPM
Para instalar a suíte, seu melhor amigo é oIPM (zpm). Existem muitos pacotes e dependências, e usar o IPM é definitivamente conveniente.
zpm "install openapi-suite"
; opcional
; zpm "install swagger-ui"
Instalação Docker
Não há nada de especial, este projeto utiliza o intersystems-iris-dev-template.
git clone git@github.com:lscalese/openapi-suite.git
cd openapi-suite
docker-compose up -d
Se você tiver um erro ao iniciar o Iris, talvez seja um problema de permissão no arquivo iris-main.log.
Você pode tentar:
touch iris-main.log && chmod 777 iris-main.log
Observação: Adicionar permissão de leitura e escrita (RW) para o usuário irisowner deve ser suficiente.
Como Usar
O OpenAPI-Suite fornece uma interface web para "Gerar e baixar" ou "Gerar e instalar" código.
A interface está disponível em http://localhost:52796/openapisuite/ui/index.csp (*adapte com o seu número de porta, se necessário).
É muito simples, preencha o formulário:
Nome do pacote da aplicação: este é o pacote usado para as classes geradas. Deve ser um nome de pacote inexistente.
Selecione o que você deseja gerar: Cliente HTTP, Produção Cliente ou Servidor REST.
Selecione o namespace onde o código será gerado. Isso faz sentido apenas se você clicar em "Install On Server"; caso contrário, este campo será ignorado.
Nome da Aplicação Web é opcional e está disponível apenas se você selecionar "Servidor REST" para gerar. Deixe vazio se você não quiser criar uma Aplicação Web relacionada à classe de despacho REST gerada.
O campo Especificação OpenAPI pode ser uma URL apontando para a especificação ou uma cópia/cola da própria especificação (neste caso, a especificação deve estar em formato JSON).
Se você clicar no botão "Download Only", o código será gerado e retornado em um arquivo XML, e então as classes serão excluídas do servidor. O namespace usado para armazenar temporariamente as classes geradas é o namespace onde o OpenAPI-Suite está instalado (por padrão IRISAPP se você usar uma instalação Docker).
No entanto, se você clicar no botão "Install On Server", o código será gerado e compilado, e o servidor retornará uma mensagem JSON com o status da geração/compilação do código e também os logs.
Por padrão, este recurso está desabilitado. Para habilitá-lo, basta abrir um terminal IRIS e:
Set ^openapisuite.config("web","enable-install-onserver") = 1
Explore a API REST do OpenAPI-Suite
O formulário CSP utiliza serviços REST disponíveis emhttp://localhost:52796/openapisuite.
Abra o swagger-ui http://localhost:52796/swagger-ui/index.html e explore http://localhost:52796/openapisuite/_spec
Este é o primeiro passo para criar uma aplicação front-end mais avançada com o framework Angular.
Gere código programaticamente
Claro, não é obrigatório usar a interface do usuário. Nesta seção, veremos como gerar o código programaticamente e como usar os serviços gerados.
Todos os trechos de código também estão disponíveis na classe dc.openapi.suite.samples.PetStore.
cliente HTTP
Set features("simpleHttpClientOnly") = 1
Set sc = ##class(dc.openapi.client.Spec).generateApp("petstoreclient", "https://petstore3.swagger.io/api/v3/openapi.json", .features)
O primeiro argumento é o pacote onde as classes serão geradas, portanto, certifique-se de passar um nome de pacote válido. O segundo argumento pode ser uma URL apontando para a especificação, um nome de arquivo, um stream ou um %DynamicObject. "features" é um array, atualmente apenas os seguintes subscritos estão disponíveis:
simpleHttpClientOnly: se for 1, apenas um cliente HTTP simples será gerado; caso contrário, uma produção também será gerada (comportamento padrão).
compile: se for 0, o código gerado não será compilado. Isso pode ser útil se você quiser gerar código apenas para fins de exportação. Por padrão, compile = 1.
Abaixo está um exemplo de como usar o serviço "addPet" com o cliente HTTP recém-gerado:
Set messageRequest = ##class(petstoreclient.requests.addPet).%New()
Set messageRequest.%ContentType = "application/json"
Do messageRequest.PetNewObject().%JSONImport({"id":456,"name":"Mittens","photoUrls":["https://static.wikia.nocookie.net/disney/images/c/cb/Profile_-_Mittens.jpg/revision/latest?cb=20200709180903"],"status":"available"})
Set httpClient = ##class(petstoreclient.HttpClient).%New("https://petstore3.swagger.io/api/v3","DefaultSSL")
; MessageResponse será uma instância de petstoreclient.responses.addPet
Set sc = httpClient.addPet(messageRequest, .messageResponse)
If $$$ISERR(sc) Do $SYSTEM.Status.DisplayError(sc) Quit sc
Write !,"Http Status code : ", messageResponse.httpStatusCode,!
Do messageResponse.Pet.%JSONExport()
Click to show generated classes.
Class petstoreclient.HttpClient Extends %RegisteredObject [ ProcedureBlock ]
{
Parameter SERVER = "https://petstore3.swagger.io/api/v3";
Parameter SSLCONFIGURATION = "DefaultSSL";
Property HttpRequest [ InitialExpression = {##class(%Net.HttpRequest).%New()} ];
Property SSLConfiguration As %String [ InitialExpression = {..#SSLCONFIGURATION} ];
Property Server As %String [ InitialExpression = {..#SERVER} ];
Property URLComponents [ MultiDimensional ];
Method %OnNew(Server As %String, SSLConfiguration As %String) As %Status
{
Set:$Data(Server) ..Server = Server
Set:$Data(SSLConfiguration) ..SSLConfiguration = SSLConfiguration
Quit ..InitializeHttpRequestObject()
}
Method InitializeHttpRequestObject() As %Status
{
Set ..HttpRequest = ##class(%Net.HttpRequest).%New()
Do ##class(%Net.URLParser).Decompose(..Server, .components)
Set:$Data(components("host"), host) ..HttpRequest.Server = host
Set:$Data(components("port"), port) ..HttpRequest.Port = port
Set:$$$LOWER($Get(components("scheme")))="https" ..HttpRequest.Https = $$$YES, ..HttpRequest.SSLConfiguration = ..SSLConfiguration
Merge:$Data(components) ..URLComponents = components
Quit $$$OK
}
/// Implementar operationId : addPet
/// post /pet
Method addPet(requestMessage As petstoreclient.requests.addPet, Output responseMessage As petstoreclient.responses.addPet = {##class(petstoreclient.responses.addPet).%New()}) As %Status
{
Set sc = $$$OK
$$$QuitOnError(requestMessage.LoadHttpRequestObject(..HttpRequest))
$$$QuitOnError(..HttpRequest.Send("POST", $Get(..URLComponents("path")) _ requestMessage.%URL))
$$$QuitOnError(responseMessage.LoadFromResponse(..HttpRequest.HttpResponse, "addPet"))
Quit sc
}
...
}
Class petstoreclient.requests.addPet Extends %RegisteredObject [ ProcedureBlock ]
{
Parameter METHOD = "post";
Parameter URL = "/pet";
Property %Consume As %String;
Property %ContentType As %String;
Property %URL As %String [ InitialExpression = {..#URL} ];
/// Use essa propriedade para conteúdo do corpo com content-type = application/json.<br/>
/// Use essa propriedade para conteúdo do corpo com content-type = application/xml.<br/>
/// Use essa propriedade para conteúdo do corpo com content-type = application/x-www-form-urlencoded.
Property Pet As petstoreclient.model.Pet;
/// Carregue %Net.HttpRequest com esse objeto de propriedade
Method LoadHttpRequestObject(ByRef httpRequest As %Net.HttpRequest) As %Status
{
Set sc = $$$OK
Set httpRequest.ContentType = ..%ContentType
Do httpRequest.SetHeader("accept", ..%Consume)
If $Piece($$$LOWER(..%ContentType),";",1) = "application/json" Do ..Pet.%JSONExportToStream(httpRequest.EntityBody)
If $Piece($$$LOWER(..%ContentType),";",1) = "application/xml" Do ..Pet.XMLExportToStream(httpRequest.EntityBody)
If $Piece($$$LOWER(..%ContentType),";",1) = "application/x-www-form-urlencoded" {
; Para implementar. Não há código gerado neste caso.
$$$ThrowStatus($$$ERROR($$$NotImplemented))
}
Quit sc
}
}
Class petstoreclient.responses.addPet Extends petstoreclient.responses.GenericResponse [ ProcedureBlock ]
{
/// http status code = 200 content-type = application/xml
/// http status code = 200 content-type = application/json
///
Property Pet As petstoreclient.model.Pet;
/// Implementar operationId : addPet
/// post /pet
Method LoadFromResponse(httpResponse As %Net.HttpResponse, caller As %String = "") As %Status
{
Set sc = $$$OK
Do ##super(httpResponse, caller)
If $$$LOWER($Piece(httpResponse.ContentType,";",1))="application/xml",httpResponse.StatusCode = "200" {
$$$ThrowStatus($$$ERROR($$$NotImplemented))
}
If $$$LOWER($Piece(httpResponse.ContentType,";",1))="application/json",httpResponse.StatusCode = "200" {
Set ..Pet = ##class(petstoreclient.model.Pet).%New()
Do ..Pet.%JSONImport(httpResponse.Data)
Return sc
}
Quit sc
}
}
Produção de cliente HTTP
Set sc = ##class(dc.openapi.client.Spec).generateApp("petstoreproduction", "https://petstore3.swagger.io/api/v3/openapi.json")
O primeiro argumento é o nome do pacote. Se você testar a geração de código de um cliente HTTP simples e de uma produção de cliente, certifique-se de usar um nome de pacote diferente. O segundo e o terceiro seguem as mesmas regras do cliente HTTP.
Antes de testar, inicie a produção através do portal de gerenciamento usando este comando:
Do ##class(Ens.Director).StartProduction("petstoreproduction.Production")
Abaixo está um exemplo de como usar o serviço "addPet", mas desta vez com a produção gerada:
Set messageRequest = ##class(petstoreproduction.requests.addPet).%New()
Set messageRequest.%ContentType = "application/json"
Do messageRequest.PetNewObject().%JSONImport({"id":123,"name":"Kitty Galore","photoUrls":["https://www.tippett.com/wp-content/uploads/2017/01/ca2DC049.130.1264.jpg"],"status":"pending"})
; MessageResponse será uma instâncoa de petstoreclient.responses.addPet
Set sc = ##class(petstoreproduction.Utils).invokeHostSync("petstoreproduction.bp.SyncProcess", messageRequest, "petstoreproduction.bs.ProxyService", , .messageResponse)
Write !, "Take a look in visual trace (management portal)"
If $$$ISERR(sc) Do $SYSTEM.Status.DisplayError(sc)
Write !,"Http Status code : ", messageResponse.httpStatusCode,!
Do messageResponse.Pet.%JSONExport()
Agora, você pode abrir o rastreamento visual para ver os detalhes:
As classes geradas nos pacotes model, requests e responses são bem semelhantes ao código gerado para um cliente HTTP simples. As classes do pacote requests herdam de Ens.Request, e as classes do pacote responses herdam de Ens.Response. A implementação padrão da operação de negócio é muito simples, veja este trecho de código:
Class petstoreproduction.bo.Operation Extends Ens.BusinessOperation [ ProcedureBlock ]
{
Parameter ADAPTER = "EnsLib.HTTP.OutboundAdapter";
Property Adapter As EnsLib.HTTP.OutboundAdapter;
/// Implementar operationId : addPet
/// post /pet
Method addPet(requestMessage As petstoreproduction.requests.addPet, Output responseMessage As petstoreproduction.responses.addPet) As %Status
{
Set sc = $$$OK, pHttpRequestIn = ##class(%Net.HttpRequest).%New(), responseMessage = ##class(petstoreproduction.responses.addPet).%New()
$$$QuitOnError(requestMessage.LoadHttpRequestObject(pHttpRequestIn))
$$$QuitOnError(..Adapter.SendFormDataArray(.pHttpResponse, "post", pHttpRequestIn, , , ..Adapter.URL_requestMessage.%URL))
$$$QuitOnError(responseMessage.LoadFromResponse(pHttpResponse, "addPet"))
Quit sc
}
...
}
}
Serviço REST HTTP do lado do servidor
Set sc = ##class(dc.openapi.server.ServerAppGenerator).Generate("petstoreserver", "https://petstore3.swagger.io/api/v3/openapi.json", "/petstore/api")
O primeiro argumento é o nome do pacote para gerar as classes. O segundo segue as mesmas regras do cliente HTTP. O terceiro argumento não é obrigatório, mas se presente, uma aplicação web será criada com o nome fornecido (tenha cuidado ao fornecer um nome de aplicação web válido).
A classe petstoreserver.disp (dispatch, despacho, %CSP.REST class) parece um código gerado por ^%REST, realizando muitas verificações para aceitar ou rejeitar a requisição e chamando a implementação do ClassMethod de serviço correspondente em petstoreserver.impl. A principal diferença é o argumento passado para o método de implementação, que é um objeto petstoreserver.requests. Exemplo:
Class petstoreserver.disp Extends %CSP.REST [ ProcedureBlock ]
{
Parameter CHARSET = "utf-8";
Parameter CONVERTINPUTSTREAM = 1;
Parameter IgnoreWrites = 1;
Parameter SpecificationClass = "petstoreserver.Spec";
/// Processar request post /pet
ClassMethod addPet() As %Status
{
Set sc = $$$OK
Try{
Set acceptedMedia = $ListFromString("application/json,application/xml,application/x-www-form-urlencoded")
If '$ListFind(acceptedMedia,$$$LOWER(%request.ContentType)) {
Do ##class(%REST.Impl).%ReportRESTError(..#HTTP415UNSUPPORTEDMEDIATYPE,$$$ERROR($$$RESTContentType,%request.ContentType)) Quit
}
Do ##class(%REST.Impl).%SetContentType($Get(%request.CgiEnvs("HTTP_ACCEPT")))
If '##class(%REST.Impl).%CheckAccepts("application/xml,application/json") Do ##class(%REST.Impl).%ReportRESTError(..#HTTP406NOTACCEPTABLE,$$$ERROR($$$RESTBadAccepts)) Quit
If '$isobject(%request.Content) Do ##class(%REST.Impl).%ReportRESTError(..#HTTP400BADREQUEST,$$$ERROR($$$RESTRequired,"body")) Quit
Set requestMessage = ##class(petstoreserver.requests.addPet).%New()
Do requestMessage.LoadFromRequest(%request)
Set scValidateRequest = requestMessage.RequestValidate()
If $$$ISERR(scValidateRequest) Do ##class(%REST.Impl).%ReportRESTError(..#HTTP400BADREQUEST,$$$ERROR(5001,"Invalid requestMessage object.")) Quit
Set response = ##class(petstoreserver.impl).addPet(requestMessage)
Do ##class(petstoreserver.impl).%WriteResponse(response)
} Catch(ex) {
Do ##class(%REST.Impl).%ReportRESTError(..#HTTP500INTERNALSERVERERROR,ex.AsStatus(),$parameter("petstoreserver.impl","ExposeServerExceptions"))
}
Quit sc
}
...
}
Como você pode ver, a classe de despacho chama “LoadFromRequest” e “RequestValidate” antes de invocar o método de implementação. Esses métodos possuem uma implementação padrão, mas o gerador de código não consegue cobrir todos os casos. Atualmente, os casos mais comuns são tratados automaticamente como parâmetros em "query" (consulta), "headers" (cabeçalhos), "path" (caminho) e no corpo (body) com os tipos de conteúdo “application/json”, “application/octet-stream” ou “multipart/form-data”. O desenvolvedor precisa verificar a implementação para checar/completar se necessário (por padrão, o gerador de código define $$$ThrowStatus($$$ERROR($$$NotImplemented)) para casos não suportados).
Exemplo de classe de requisição:
Class petstoreserver.requests.addPet Extends %RegisteredObject [ ProcedureBlock ]
{
Parameter METHOD = "post";
Parameter URL = "/pet";
Property %Consume As %String;
Property %ContentType As %String;
Property %URL As %String [ InitialExpression = {..#URL} ];
/// Use essa propriedade para conteúdo de corpo com content-type = application/json.<br/>
/// Use essa propriedade para conteúdo de corpo com content-type = application/xml.<br/>
/// Use essa propriedade para conteúdo de corpo com content-type = application/x-www-form-urlencoded.
Property Pet As petstoreserver.model.Pet;
/// Carregue propriedades de objeto do objeto %CSP.Request.
Method LoadFromRequest(request As %CSP.Request = {%request}) As %Status
{
Set sc = $$$OK
Set ..%ContentType = $Piece(request.ContentType, ";", 1)
If ..%ContentType = "application/json"{
Do ..PetNewObject().%JSONImport(request.Content)
}
If ..%ContentType = "application/xml" {
; A implementar. Não há geração de código ainda para este caso.
$$$ThrowStatus($$$ERROR($$$NotImplemented))
}
If ..%ContentType = "application/x-www-form-urlencoded" {
; A implementar. Não há geração de código ainda para este caso.
$$$ThrowStatus($$$ERROR($$$NotImplemented))
}
Quit sc
}
/// Carregue propriedades de objeto do objeto %CSP.Request.
Method RequestValidate() As %Status
{
Set sc = $$$OK
$$$QuitOnError(..%ValidateObject())
If ''$ListFind($ListFromString("application/json,application/xml,application/x-www-form-urlencoded"), ..%ContentType) {
Quit:..Pet="" $$$ERROR(5659, "Pet")
}
If $IsObject(..Pet) $$$QuitOnError(..Pet.%ValidateObject())
Quit sc
}
}
Assim como no uso de ^%REST, a classe "petstoreserver.impl" contém todos os métodos relacionados aos serviços que o desenvolvedor precisa implementar.
Class petstoreserver.impl Extends %REST.Impl [ ProcedureBlock ]
{
Parameter ExposeServerExceptions = 1;
/// Implementação do serviço para post /pet
ClassMethod addPet(messageRequest As petstoreserver.requests.addPet) As %Status
{
; Implemente seu serviço aqui
; Retorne {}
$$$ThrowStatus($$$ERROR($$$NotImplemented))
}
...
}
Breve descrição dos pacotes gerados:
Nome do Pacote \ Nome da Classe
Tipo
Descrição
petstoreclient.model
petstoreproduction.model
Client-side e server-side
Ele contém todos os modelos. Essas classes estendem %JSON.Adaptor para facilitar o carregamento de objetos a partir de JSON.
Se uma produção for gerada, essas classes também estenderão %Persistent.
petstoreclient.requests
petstoreproduction.requests
Client-side e server-side
Objeto usado para inicializar facilmente %Net.HttpRequest. Existe uma classe por operação definida na especificação.
Se a produção for gerada, essas classes estenderão Ens.Request.
Nota: A implementação desta classe é diferente se for gerada para propósitos do lado do servidor ou do lado do cliente. No caso do lado do cliente, todas as classes contêm um método "LoadHttpRequestObject" permitindo carregar um "%Net.HttpRequest" a partir das propriedades desta classe.
Se as classes forem geradas para propósitos do lado do servidor, cada classe contém um método "LoadFromRequest" para carregar a instância a partir do objeto "%request".
petstoreclient.responses
petstoreproduction.responses
Client-side e server-side
É o oposto de petstoreclient.requests. Ele permite manipular a resposta de um %Net.HttpRequest.
Se a produção for gerada, essas classes estenderão Ens.Response.
petstoreclient.HttpClient
Client-side
Contém todos os métodos para executar requisições HTTP; existe um método por operação definida na especificação OpenAPI.
petstoreproduction. bo.Operation
Client-side
A classe de Operação possui um método por operação definida na especificação OpenAPI.
petstoreproduction.bp
Client-side
Dois processos de negócio padrão são definidos: síncrono e assíncrono.
petstoreproduction.bs
Client-side
Contém todos os serviços de negócio vazios para implementar.
petstoreproduction.Production
Client-side
Configuração de produção.
petstoreserver.disp
Server-side
Classe de despacho %CSP.REST.
petstoreserver.Spec
Server-side
Esta classe contém a especificação OpenAPI em um bloco XData.
petstoreserver.impl
Server-side
Ele contém todos os métodos vazios relacionados às operações definidas na especificação OpenAPI. Esta é a classe (que estende %REST.Impl) onde os desenvolvedores precisam implementar os serviços.
Status de desenvolvimento
O OpenAPI-Suite ainda é um produto muito novo e precisa ser mais testado e então aprimorado. O suporte ao OpenAPI 3 é parcial, mais possibilidades poderiam ser suportadas.
Os testes foram realizados com a especificação públicahttps://petstore3.swagger.io/api/v3/openapi.json e outras duas relativamente simples. Obviamente, isso não é suficiente para cobrir todos os casos. Se você tiver alguma especificação para compartilhar, ficaria feliz em usá-las para meus testes.
Acredito que a base do projeto é boa e ele pode evoluir facilmente, por exemplo, ser estendido para suportar AsyncAPI.
Não hesite em deixar feedback.
Espero que você goste desta aplicação e que ela mereça seu apoio para o concurso de ferramentas para desenvolvedores.
Obrigado por ler.