Demonstração Fullstack do IntegratedML e Python Incorporado.
1. Demonstração Integrated ML
Este repositório é uma demonstração do IntegratedML e Python Incorporado.

- 1. Demonstração do Integrated ML
- 2. Construindo a Demonstração
- 3. Executando a demonstração
- 4. Back-end Python
- 5. IntegratedML
- 6. Utilizando o COS
- 7. Maior detalhamento com o DataRobot
- 8. Conclusão
2. Criando a Demonstração
Para criar a demonstração você deve apenas executar o seguinte comando:
docker compose up
2.1. Arquitetura
Dois contêineres serão criados: um com o IRIS e um com o servidor nginx.
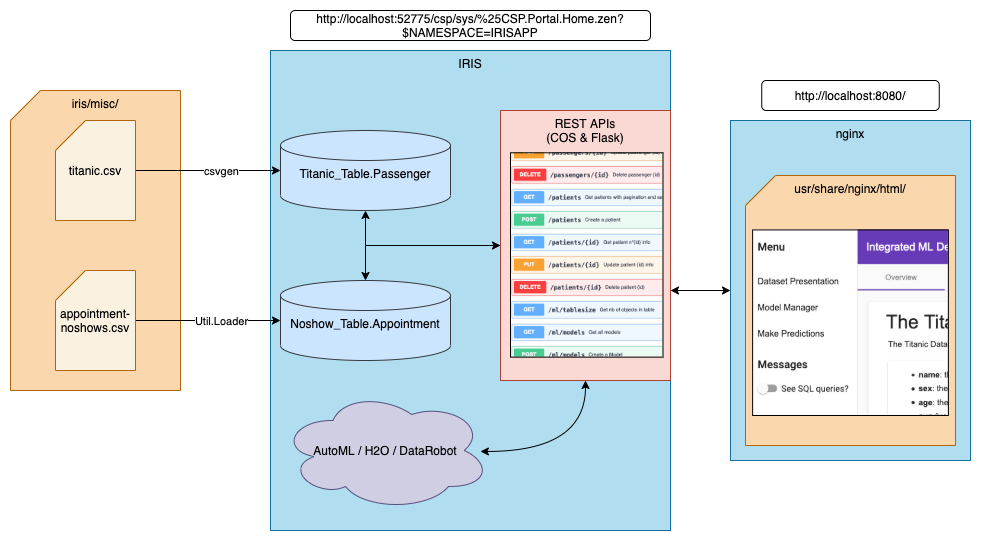
A imagem do IRIS utilizada já contêm o Python Incorporado. Após contruído, o contêiner irá executar um servidor wsgi com a API Flask.
Estamos utilizando o pacote csvgen da Comunidade para importar o dataset titanic para o IRIS. Para o dataset de noshowutilizamos outro método customizado (o método de classe Load() da classe Util.Loader). PAra que o contêiner teha acesso aos arquivos csv nós associamos o diretório local iris/ ao diretório /opt/irisapp/ do contêiner.
2.2. Construindo o contêiner nginx
Para construir nosso contêiner nginx o docker utiliza uma construção multiestágio. Inicialmente ele cria um contêiner com nó, então ele instala o npm e copia todos nossos arquivos para o contêiner. Depois disto ele constrói o projeto com o comando ng build e o arquivo de saída é copiado para um novo contêiner que possui apenas o nginx.
Graças a esta manobra nós obtemos um contêiner bem leve que não contém todas a bibliotecas e ferramentas utilizadas para criar páginas web.
Você consegue verificar os detalhes desta construção multiestágio no arquivo angular/Dockerfile. Nós também configuramos os parâmetros de nosso servidor nginx graças ao arquivo angular/nginx.default.conf.
3. Executando a Demonstração
Apenas acesse o endereço: http://localhost:8080/ e é isso! Aproveitem!
4. Back-end Python
O back-end é baseado no Python Flask. Nós utilizamos o Python Incorporado para realizar as chamadas às classes do IRIS e executar consultas a partir do Python.
4.1. Python Incorporado
4.1.1. Configurando o contêiner
Precisamos inicialmente explicitar no dockerfile duas variáveis de ambiente que o Python Incorporado irá utilizar:
ENV IRISUSERNAME "SuperUser"
ENV IRISPASSWORD $IRIS_PASSWORD
Com uma configuração no arquivo docker-compose do $IRIS_PASSWORD como esta:
iris:
build:
args:
- IRIS_PASSWORD=${IRIS_PASSWORD:-SYS}
(A senha transferida é a que está configurada em sua máquina local ou, se a mesma não estiver definida, será por padrão a "SYS")
4.1.2. Utilizando o Python Incorporado
Para utilizar o Python Incorporado nós utilizamos irispython como interpretador python e fazemos:
import iris
Bem no começo do arquivo.
Iremos então poder executar métodos como:
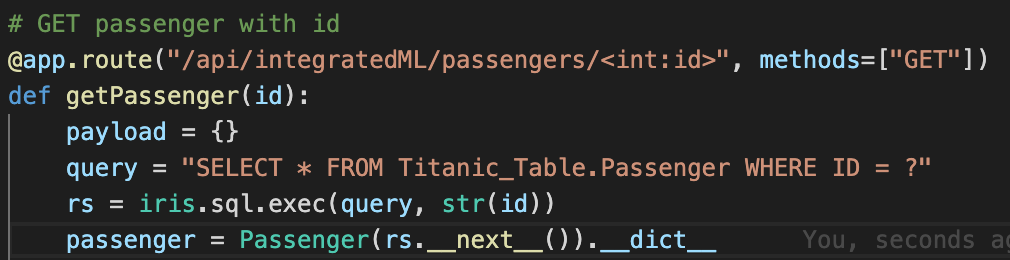
Como você pode ver, de forma a recuperar um paciente pelo ID nós apenas executamos uma consulta e utilizamos seu resultado.
Também podemos utilizar diretamente os objetos IRIS:
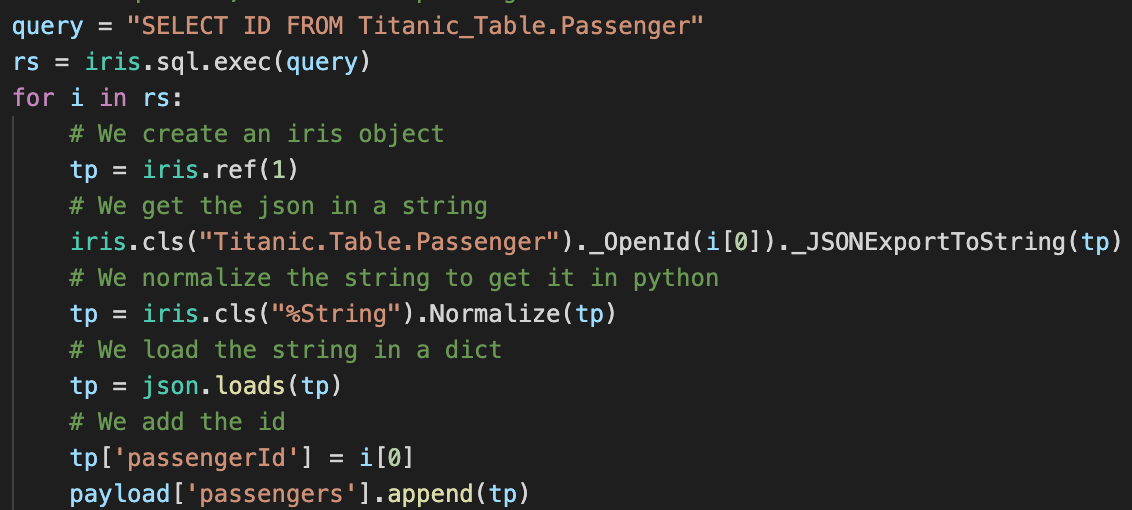
Aqui nós utilizamos uma consulta SQL para recuperar todos os IDs da tabela e então recuperamos cada passageiro da tabela com o método %OpenId() da classe Titanic.Table.Passenger(notem que como o%é um caractere ilegal in Python utilizamos o_` em substituição).
Graças ao Flask impleentamos todas nossas rotas e métodos desta forma.
4.1.3. Comparação Lado a Lado
Nesta imagem você tem uma comparação lado a lado entre uma implementação Flask e uma implementação ObjectScript.
Como você pode verificar, existem várias similaridades.
4.2. Disponibilizando o Servidor
Para disponibilizar o servidor utilizamos gunicorn com irispython.
Adicionamos a seguinte linha no arquivo docker-compose:
iris:
command: -a "sh /opt/irisapp/flask_server_start.sh"
Esta alteração irá executar (graças a flag -a) , depois que o contêiner for iniciado, o seguinte script:
#!/bin/bash
cd ${FLASK_PATH}
${PYTHON_PATH} /usr/irissys/bin/gunicorn --bind "0.0.0.0:8080" wsgi:app -w 4 2>&1
exit 1
Com as variáveis de ambiente definidas no Dockerfile desta forma:
ENV PYTHON_PATH=/usr/irissys/bin/irispython
ENV FLASK_PATH=/opt/irisapp/python/flask
Iremos então ter acesso ao back-end Flask através da porta local 4040, devido a termos associado a porta 8080 do contêiner a ela.
5. IntegratedML
5.1. Explorando ambos datasets
Para ambos datasets você tera um acesso a um CRUD completo, lhe permitindo modificar como quiser as tabelas gravadas.
Para trocar de um dataset para outro você pode clicar no botão localizado na parte superior, à direita.
5.2. Gerenciando Modelos
5.2.1. Criando um Modelo
Uma vez que você descobriu o modelo, você pode agora criar um modelo para prever o valor que você quiser.
Acionando o menu lateral Model Manager, no item Model List você terá acesso a seguinte página (aqui, no caso do dataset NoShow):
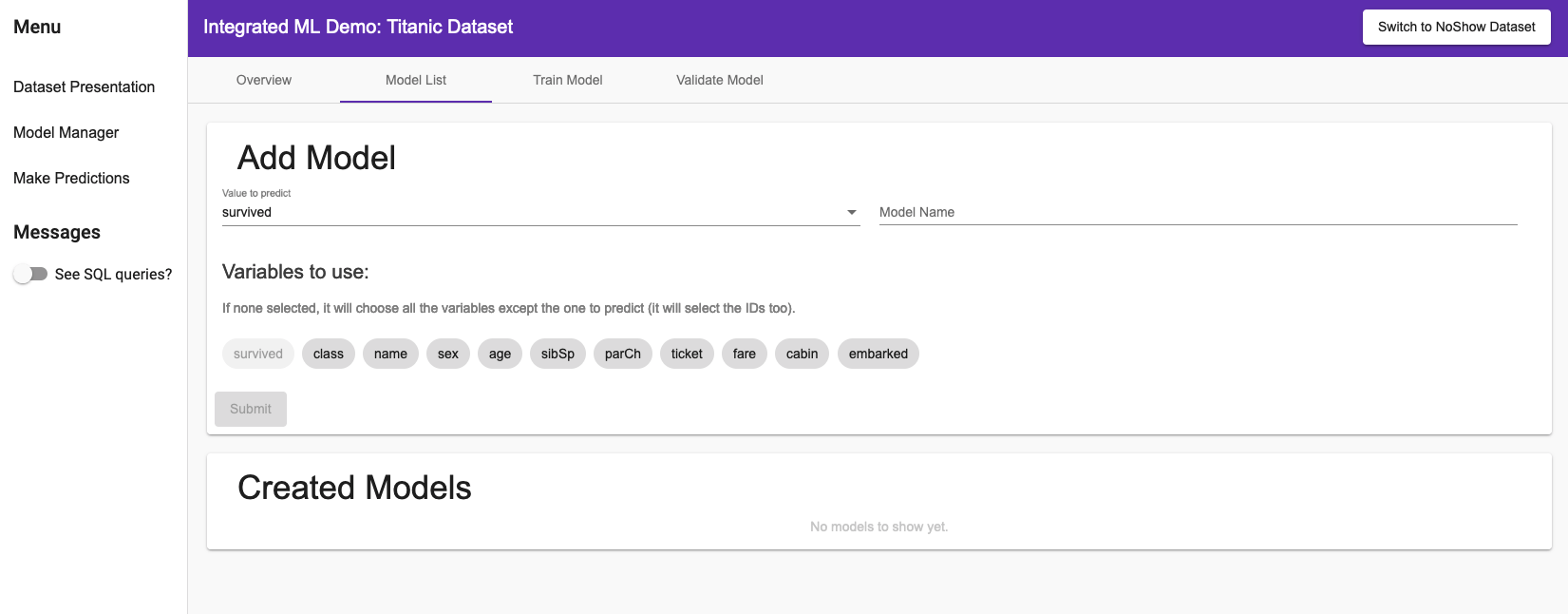
Você pode escolher qual valor você quer prever, o nome do seu modelo e quais variáveis você quer utilizar para realizar a previsão.
No menu lateral você pode selecionar See SQL queries? para visualizar como os modelos são gerenciados no IRIS.
Depois de criar um modelo você deverá ver o seguinte:
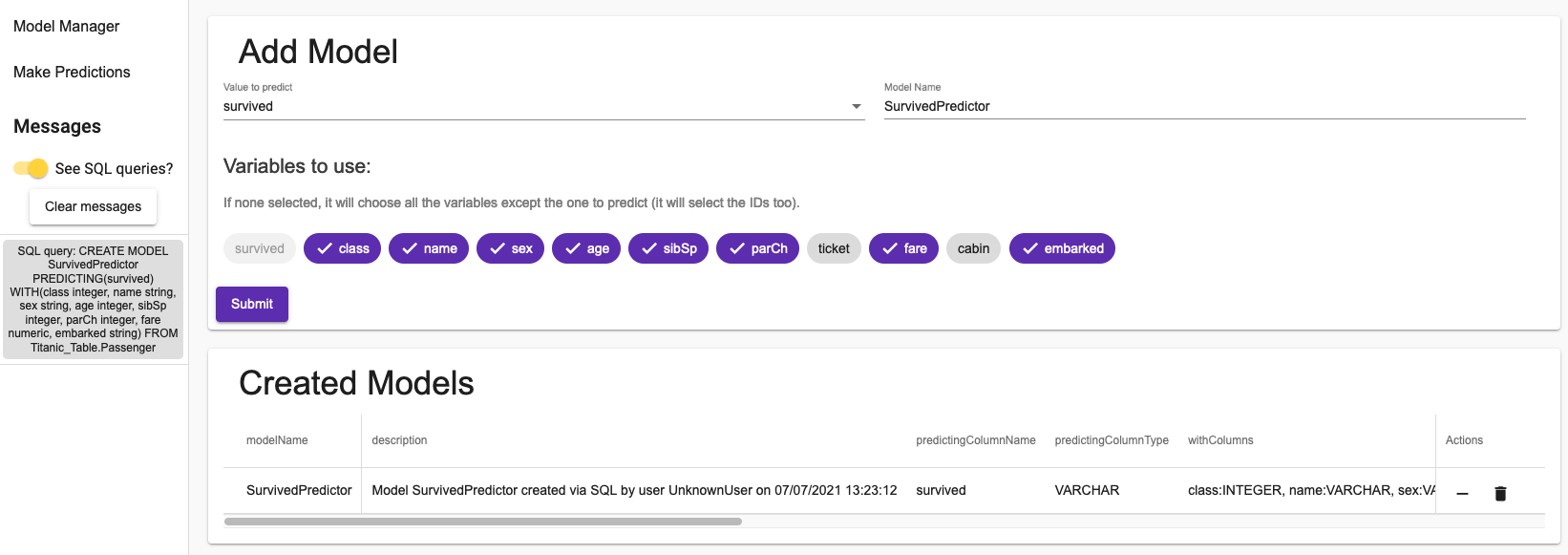
Como vocês podem observar, a criação de um modelo necessita apenas de uma consulta SQL. As informações que você possui são todas as informações que você pode recuperar do IRIS.
Na coluna actions você pode deletar ou remover um modelo. Remover o modelo irá remover todos os treinamentos (e validações) exceto a última.
5.2.2. Treinando o Modelo
Na próxima aba você poderá treinar seus modelos.
Você poderá escolher entre 3 provedores. InterSystems' AutoML, H2O, uma solução de código aberto, e DataRobot, onde você consegue um período de 14 dias de teste grátis se você se registrar no site deles.
Você pode selecionar o percentual do dataset que você deseja utilizar para treinar seu modelo. Como o treinamento pode ser demorado em casos de grandes datasets, para propósito de demonstrações é possível utilizar um dataset menor.
Aqui nós treinamos um modelo usando o dataset Titanic completo:
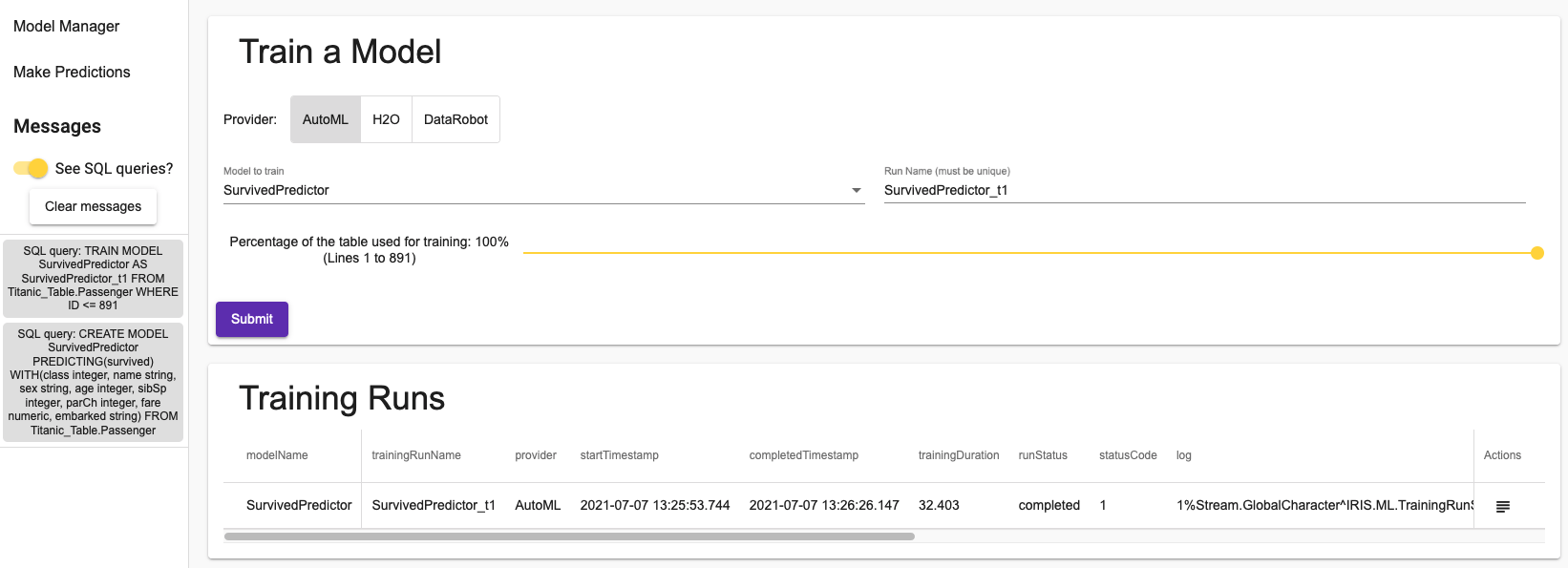
O botão na coluna actions irá permitir que você verifique o log. Para o AutoML você verá o que o algoritmo fez de fato: como ele preparou os dados e como ele escolheu qual modelo utilizar.
Para treinar um modelo é necessária apenas uma consulta SQL, como você pode verificar na seção de mensagens do menu lateral.
Tenha em mente que nessas duas abas você verá apenas os modelos referentes ao dataset que você está utilizando no momento.
5.2.3. Validando um Modelo
Finalmente você pode validar um modelo na aba final. Clicando na execução da validação irá abrir uma janela de pop-up. Lá você poderá escolher o percentual do dataset que será utilizado para a validação.
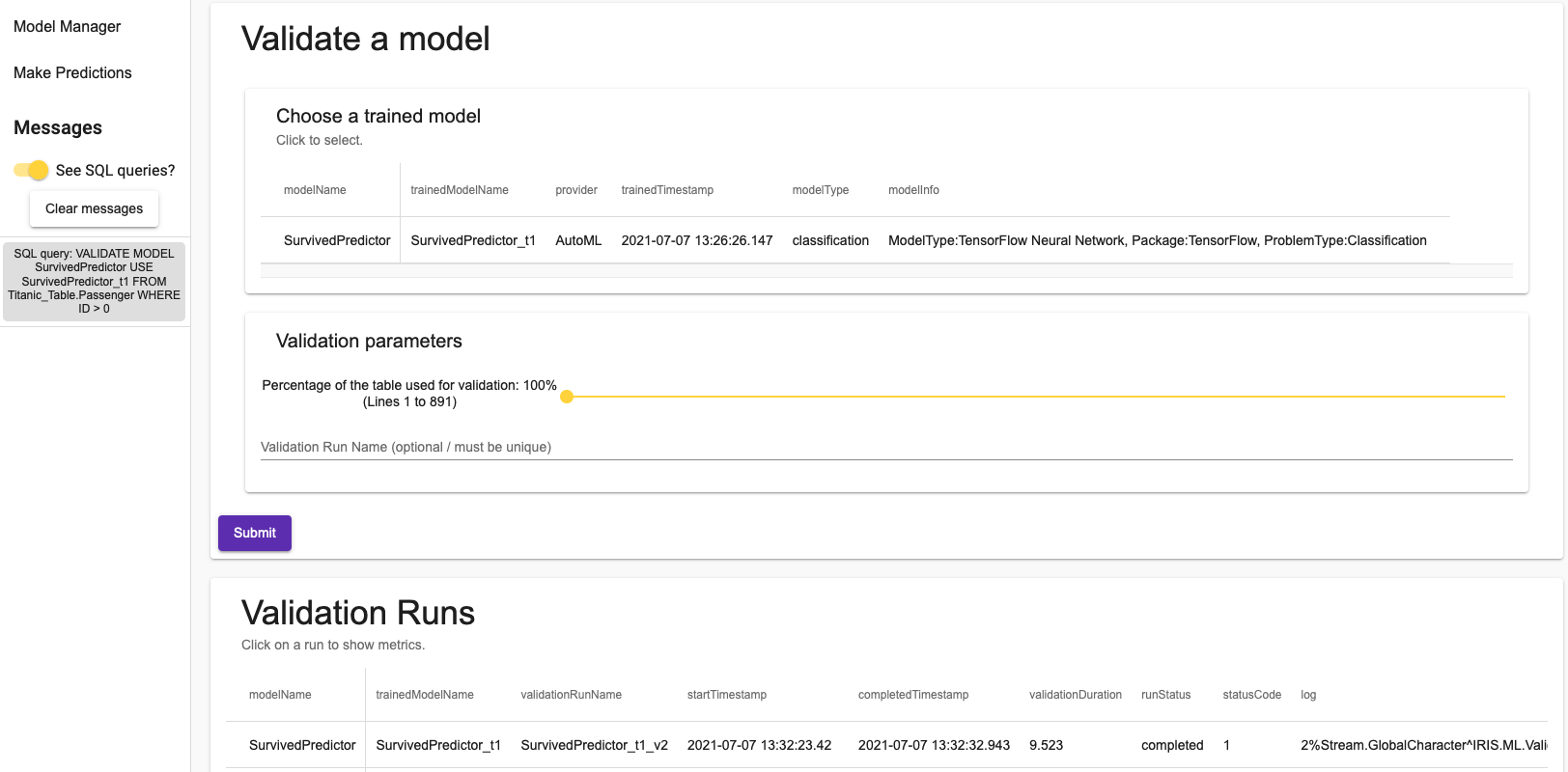
Mais uma vez, é necessária apenas uma consulta SQL.
5.2.4. Realizando Previsões
No menu Make Predictions, na última aba, você pode realizar previsões utilizando seu recente modelo treinado.
Você precisa apenas buscar um passageiro / paciente e selecioná-lo, selecionar um dos modelos treinados e delecionar a opção prever.
No caso de um modelo de classificação (como neste exemplo, para prever a sobrevivência), a previsão estará associada com a probabilidade de estar na classe prevista.
No caso da Sra. Fatima Masselmani, o modelo previu corretamente que ela sobreviveu, com uma probabilidade de 73%. Logo abaixo desta predição você pode visualizar os dados utilizados pelo modelo:
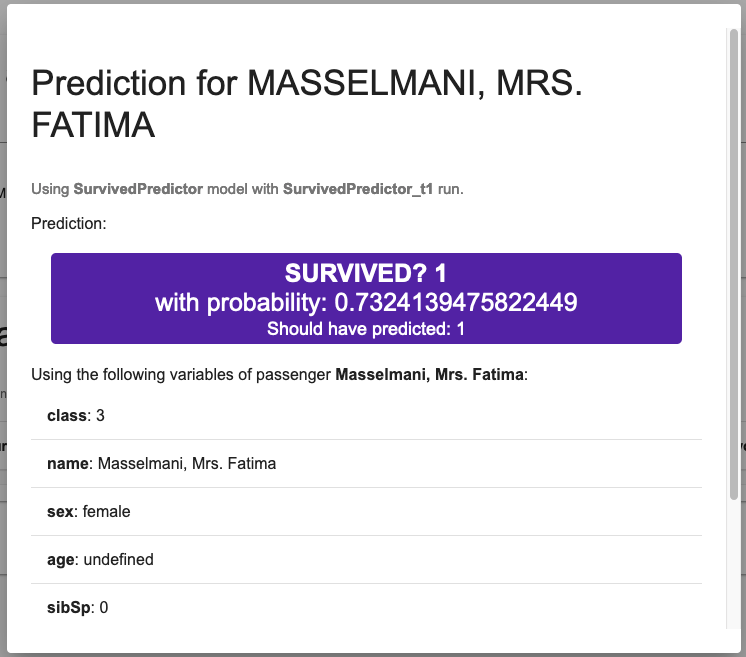
Mais uma vez, foi necessária apenas uma consulta para recuperar a predição e uma para a probabilidade.
6. Utilizando o COS
A demonstração disponibiliza duas APIs. Nós utilizamos a API Flask com o Python Incorporado porém um serviço REST em COS também foi configurado na construção do contêiner.
Pressionando o botão na parte superior direita "Switch to COS API", você poderá utilizar este serviço.
Note como nada se altera, ambas as APIs são equivalentes e funcionam da mesma forma.
7. Maior detalhamento com o DataRobot
Se você quiser um maior detalhamento (mais do que o log pode lhe oferecer), sugerimos que você utiliza o provedor DataRobot.
Para isso você precisará acessar o endereço de sua instância DataRobot e procurar por Developer Tools para conseguir seu token. Ao treinar o modelo a página solicitará seu token.
Uma vez que o treinamento iniciar você poderá acessar sua instância DataRobot para saber muito mais sobre seu dataset e seus modelos :
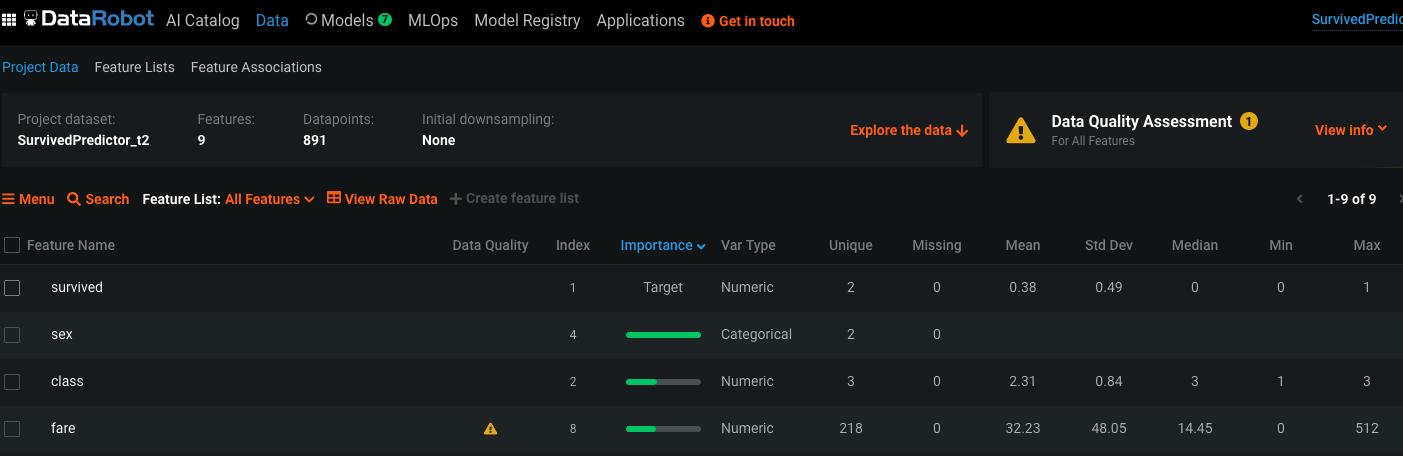
Aqui podemos ver que os campos sex e name de cada passageiro foram os valores mais importantes utilizados na predição da sobrevivência. Nós podemos também visualizar que o campo fare contém informações fora do padrão.
Uma vez que os modelos estiverem treinados você poderá acessar vários detalhes, aqui está um exemplo:
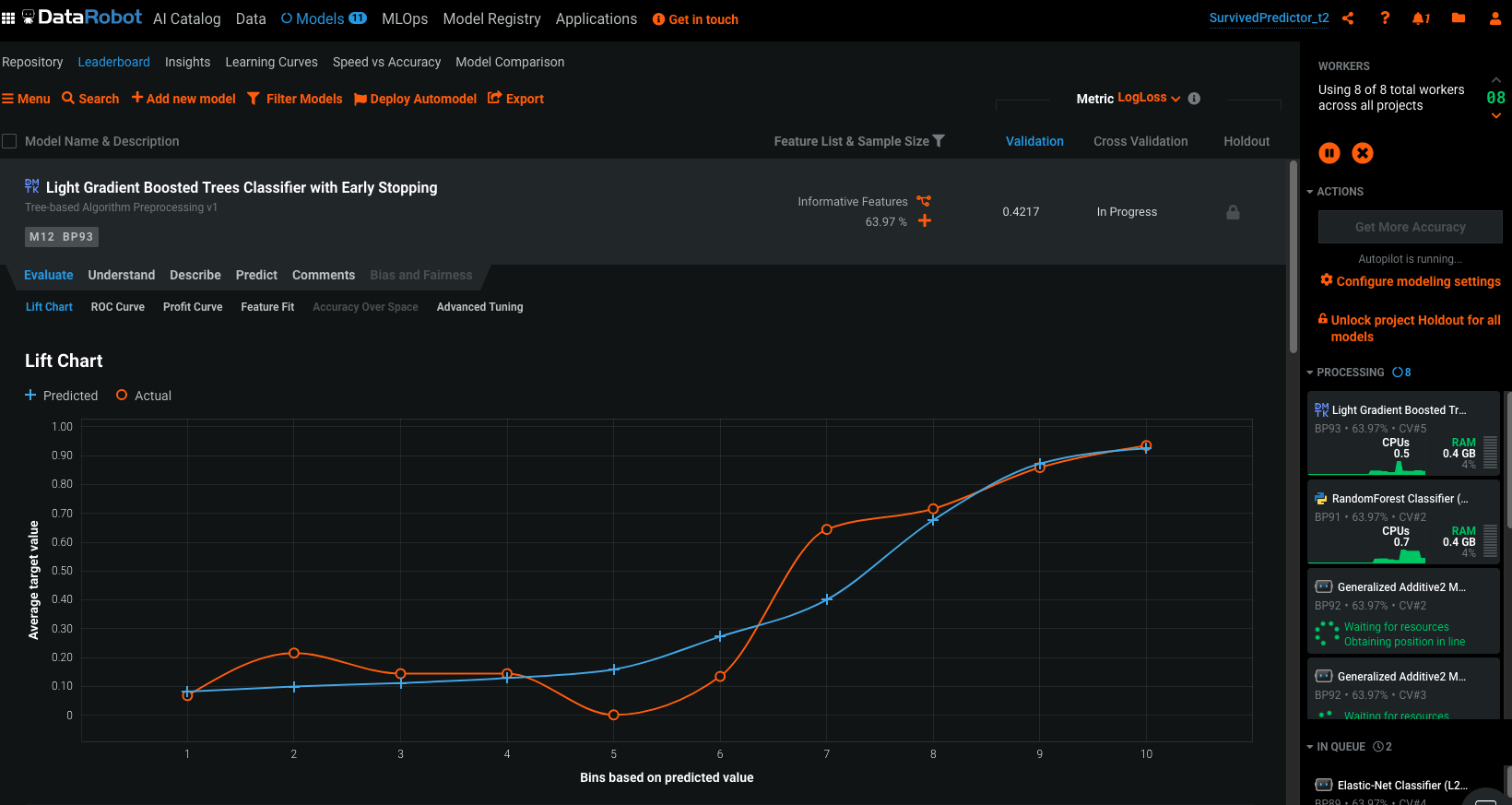
8. Conclusão
Através desta demonstração nós pudemos observar como é fácil criar, treinar e validar um modelo, bem como predizer valores através de poucas consultas SQL.
Conseguimos fazer isto utilizando uma API RESTful com Python Flask, utilizando Python Incorporado e também fizemos um comparativo utilizando uma API COS.
O front-end foi desenvolvido em Angular.