Um experimento usando IA generativa e FHIR
Este projeto é um experimento em usar as APIs da OpenAI para responder prompts de usuários no domínio de saúde usando recursos FHIR e codificação em Python.
Ideia do projeto
IA generativas, como os modelos de LLM disponíveis na OpenAI, vem demonstrando impressionante capacidade para compreender e responder à questões de alto nível.
Elas podem inclusive usar linguagens de programação para criar códigos baseado em instruções contidas nos prompts - e tenho que confessar que a ideia de ter meu trabalho automatizado me causa um pouco de ansiedade. Mas pelo o que tenho visto até agora, parece que isso é algo sobre o qual as pessoas serão obrigadas a se acostumar, gostando ou não. Então, decidi fazer alguns experimentos.
A ideia principal por traz desse projeto veio quando li este artigo sobre o projeto ChatARKit. Este projeto usa as APIs da OpenAI para interpretar comandos de voz para renderizar objetos 3D em vídeos exibidos em smartphones - um projeto muito interessante. E parece que este é um assunto de interesse, já que encontrei um artigo recente seguindo a mesma ideia.
O que mais me deixou curioso sobre este artigo foi o uso do ChatGPT para programar uma aplicação de AR. Como o repositório do github está publicamente disponível, procurei nele e achei como o autor usou o ChatGPT para gerar código. Depois, descobri que este tipo de técnica é chamada de engenharia de prompt - aqui está um artigo da Wikipedia sobre este assunto, ou então estes dois outros mais práticos: 1 e 2.
Assim, pensei - e se eu tentasse algo similar, mas usando FHIR e Python? Isto foi o que veio à mente:
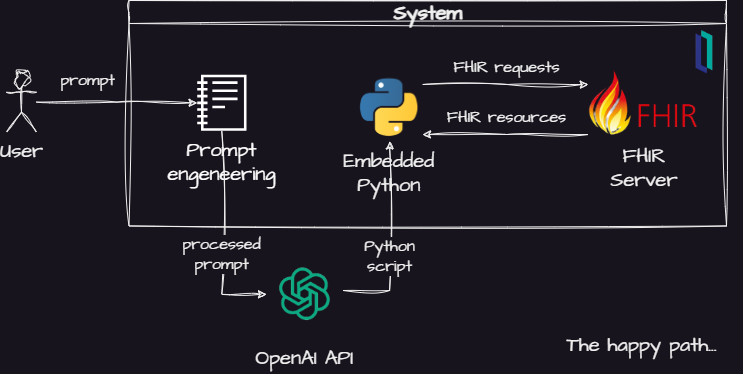
Seus principais elementos são:
- Um módulo para tratar da engenharia de prompt, o qual irá instruir o modelo de IA usar FHIR e Python
- Um módulo de integração com as APIs da OpenAI
- Um interpretador Python para executar o código gerado
- Um servidor FHIR para responder às consultas geradas pelo modelo de IA
A ideia básica é usar a API Completion da OpenAI para solicitar à IA dividir o prompt do usuário como um conjunto de consultas FHIR. Então, o modelo de IA cria um script Python para manipular os recursos FHIR retornados pelo servidor FHIR no InterSystems IRIS for Health.
Se este simples esquema funcionar, usuários poderiam obter respostas à perguntas as quais ainda não são suportadas pelo modelo analítico das aplicações. Posteriormente, estas questões respondidas pelo modelo de IA, poderiam ser analisadas de forma a descobrir novas necessidades dos usuários.
Outra vantagem deste esquema é o fato de que não há necessidade de exportar dados e esquemas para APIs externas. Por exemplo, perguntas sobre pacientes podem ser realizadas sem a necessidade de enviar dados desses pacientes ou esquemas do banco de dados para um servidor de IA. Como o modelo de AI usa somente elementos publicamente disponíveis - FHIR e Python nesse caso, não há necessidade de publicação de dados internos.
No entanto, este mesmo esquema também nos remete à algumas dúvidas, tais como:
- Como guiar o modelo de IA à usar FHIR e Python de acordo com as necessidades dos usuários?
- As respostas geradas pelo modelo de IA são corretas?
- Como lidar com problemas de segurança que a execução de código Python gerado externamente?
Desta forma, de forma a construir algum suporte à essas dúvidas, realizei algumas alterações sobre o esquema pensado inicialmente:
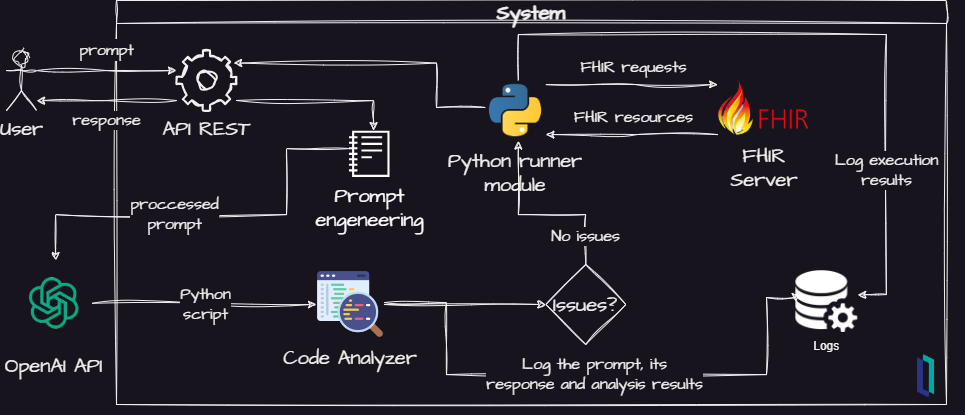
Agora, alguns novos elementos foram adicionados:
- Um analisador de código Python para localizar problemas de segurança
- Um módulo para registro de eventos (logs) para análise posterior.
- Uma API REST para futuras integrações
Assim, este projeto tem por objetivo ser uma prova de conceito o qual pode suportar experimentos para obter informações para tentar responder às questões como as propostas anteriormente.
Nas próximas seções, você verá como usar o projeto, alguns resultados obtidos tentando responder às questões mencionadas acima e, algumas conclusões.
Espero que você goste do projeto e o julgue útil. E sua colaboração com o projeto é mais que bem vinda!
Usando o projeto
Para usar o projeto, abra um terminal IRIS e execute o seguinte:
ZN "USER"
Do ##class(fhirgenerativeai.FHIRGenerativeAIService).RunInTerminal("<sua pergunta>")
Por exemplo, as seguintes questões foram usadas para testar o projeto:
- How many patients are in the dataset?
- What is the average age of patients?
- Give me all conditions (code and name) removing duplications. Present the result in a table format. (Don't use pandas)
- How many patients has the condition viral sinusitis (code 444814009)?
- What is the prevalence of viral sinusitis (code 444814009) in the patient population? For patients with the same condition multiple times, consider just one hit to your calculations.
- Among patients with viral sinusitis (code 444814009), what is the distribution of gender groups?
Você encontra exemplos de saídas para essas questões aqui.
OBS: mantive as questões em inglês para caso você tente usa-las no projeto, os resultados sejam o mais parecido possível. Mas nada impede de você tentar traduzi-las antes de enviar para a API da OpenAI.
Por favor, observe que ao tentar repetir essas perguntas em seu sistema as respostas podem variar, mesmo para as mesmas perguntas. Isso se deve à natureza estocástica dos modelos de LLM.
Estas questões foram sugeridas pelo ChatGPT. Foi solicitado que tais questões fossem criadas de uma forma na qual o nível de complexidade fosse sendo aumentado. Com exceção da terceira questão, que foi elaborada pelo autor.
Engenharia de prompt
O prompt usado pelo projeto pode ser encontrado aqui no método GetSystemTemplate().
Ele segue os princípios de engenharia de prompt onde, primeiro é atribuído um papel ao modelo de IA, e após isso, uma série de restrições e instruções. O objetivo de cada uma de suas seções estão comentadas, assim é possível entender como o prompt funciona.
Observe o uso de um tipo de definição de interface, quando o modelo é instruído à assumir a existência de uma função chamada CallFHIR() para interagir com FHIR, ao invés de deixar o modelo declarar funções para tal. Isto foi inspirado pelo projeto ChatARKit, onde o autor define um conjunto de funções que abstraem a complexidade de uso de uma biblioteca de AR.
Aqui, usei esta técnica para evitar que o modelo crie código para realizar chamadas HTTP de forma direta.
Um achado interessante aqui foi sobre forçar o modelo de IA à retornar sua resposta em formato XML. Como é esperado que um código Python seja retornado, formatei-o em XML para uso do bloco CDATA.
Apesar de ter sido claro no prompt para que a resposta também seja no formato XML, o modelo de IA só passou a seguir à esta instrução após também enviar o prompt do usuário formato em XML. É possível verifica isso no método FormatUserPrompt() na mesma classe referenciada acima.
Analisador de código Python
Este módulo usa a biblioteca bandit para procurar por problemas de segurança no código Python gerado.
Esta biblioteca gera a AST do programa Python e o testa com relação à problemas de segurança comuns. Os tipos de problemas detectados estão nos seguintes links:
Cada código Python retornado pelo modelo de IA é testado para verificar se há problemas de segurança. Caso algo esteja errado, a execução é cancelada e um evento de erro é registrado.
Registro de eventos
Todos os eventos do sistema são registrados para análise posterior na tabela LogTable.
Cada execução para responder à uma pergunta possui em ID de sessão. Este ID pode ser encontrado na coluna 'SessionID' na tabela e usado para recuperar todos os eventos associados a ele, passando-o para o método RunInTerminal("", . Por exemplo:
Do ##class(fhirgenerativeai.FHIRGenerativeAIService).RunInTerminal("", "asdfghjk12345678")
Também é possível recuperar todos os eventos usando este SQL:
SELECT *
FROM fhirgenerativeai.LogTable
order by id desc
Testes
Alguns testes foram executados para conseguir informações para medir o desempenho do modelo de IA.
Cada testes foi repetido 15 vezes e suas saídas estão armazenadas neste e neste diretórios.
Por favor, observe que ao tentar repetir essas perguntas em seu sistema as respostas podem variar, mesmo para as mesmas perguntas. Isso se deve à natureza estocástica dos modelos de LLM.
Taxa de acertos
Nos testes da questão número 1, foram obtidos 14 resultados 6, e 1 erro. O valor correto é 6. Então, houve 100% de acertos, mas um percentual de falhas de execução de 6%.
SQL usado para validar os resultados do teste para a questão número 1:
SELECT
count(*)
FROM HSFHIR_X0001_S.Patient
Nos testes da questão número 2, foram obtidos 3 resultados 52, 6 resultados 52.5 e 6 erros. O valor correto - considerando idades com valores decimais, é 52.5. Desta forma, considerei ambos os valores corretos já que essa pequena diferença de valores seja provavelmente devido à ambiguidades no prompt - ele não menciona nada sobre permitir ou não idades com valores decimais. Assim, houve 100% de acerto, mas com uma taxa de erros de execução de 40%.
SQL usado para validar os resultados do teste para a questão número 2:
SELECT
birthdate, DATEDIFF(yy,birthdate,current_date), avg(DATEDIFF(yy,birthdate,current_date))
FROM HSFHIR_X0001_S.Patient
Nos testes da questão número 3, foram obtidos 3 erros e 12 tabelas com 23 linhas. Os valores das tabelas não ficaram nas mesmas posições e formato, porém novamente atribuí esse comportamento à limitações no prompt. Desta forma, houve 100% de acerto, porém com uma taxa de falha de execução de 20%.
SQL usado para validar os resultados do teste para a questão número 3:
SELECT
code, count(*)
FROM HSFHIR_X0001_S.Condition
group by code
Nos testes da questão número 4, foram obtidos 2 erros, 12 resultados 7 e 1 resultado 4. O valor correto é 4. Então, foram 7% acertos, e uma taxa de erros de execução de 13%.
SQL usado para validar os resultados do teste para a questão número 4:
SELECT
p.Key patient, count(c._id) qtde_conditions, list(c.code) conditions
FROM HSFHIR_X0001_S.Patient p
join HSFHIR_X0001_S.Condition c on c.patient = p.key
where code like '%444814009%'
group by p.Key
Nos testes da questão número 5, foram obtidos 11 erros, 3 resultados 4 e 1 resultado 0.6. O valor correto é 4. Então, houve 75% de acertos, e uma taxa de erros de execução de 73%.
O SQL usado para validar os resultados da questão número 5 foi o mesmo usado na questão número 4.
Nos testes da questão número 6, foram obtidos 12 erros e 3 resultados {female: 4, male: 2, other: 0}. O valor correto é {female: 3, male: 1, other: 0}. Desta forma, houve 0% de acertos, e uma taxa de erros de execução de 80%.
SQL usado para validar os resultados do teste para a questão número 6:
SELECT
p.gender, count(distinct p._id) qty_patients, list(p.key) patients, list(c.code) conditions
FROM HSFHIR_X0001_S.Patient p
join HSFHIR_X0001_S.Condition c on c.patient = p.key
where code like '%444814009%'
group by p.gender
Resumindo os resultados:
| Número do teste | Taxa de acertos | Taca de erros de execução |
|---|---|---|
| 1 | 100% | 6% |
| 2 | 100% | 40% |
| 3 | 100% | 20% |
| 4 | 7% | 13% |
| 5 | 75 % | 73% |
| 6 | 0% | 80% |
Segurança
Como se pode observar nos códigos gerados no diretório de testes, aparentemente nenhum problema de segurança foi gerado pelo modelo de IA - e esse foi o mesmo resultado que o analisador de código encontrou, nenhum problema de segurança.
Então, de forma a testar se o analisador de código era capaz de detectar problemas de segurança, o módulo que executa os códigos Python tem uma propriedade chamada CodeInjection , onde códigos maliciosos podem ser injetados para serem testados.
Desta forma, os seguintes códigos maliciosos foram injetados para o teste de segurança:
- Teste de segurança número 1:
print(eval("os.chmod('%s', 0o777)" % 'test.txt'))
Este código tenta acessar o sistema de arquivos do SO e alterar as permissões de um arquivo. Isto é claramente um código não esperado para o propósito do projeto, assim tendo que ser bloqueado.
- Teste de segurança número 2:
import requests
url = "https://postman-echo.com/get"
params = {"arg": "value"}
response = requests.get(url, params=params)
data = response.json()
print(data)
Este código tenta realizar uma requisição HTTP para um endereço externo - uma API do Postman neste caso. Se o código for executado, informações locais poderiam ser facilmente vazadas.
Como pode ser observado no diretório para os testes de segurança, o analisador de códigos foi bem sucedido em encontrar os problemas de segurança.
Conclusões
No que diz respeito à taxa de acertos, o modelo de IA obteve resultados corretos para as questões de baixa complexidade, mas começou a falhar conforme essa complexidade aumentou. O mesmo foi observado para taxa de falhas na execução. Assim, quanto mais complexas são as questões, mais o modelo de IA gera código com falha de execução e com maior probabilidade de levar a resultados com valores incorretos.
Isto significa que melhorias devem ser realizadas no prompt. Por exemplo, no código da questão 6, o erro foi pesquisar apenas os recursos Patient e ignorar os códigos dos recursos Conditions associados. Este tipo de análise é necessária para guiar as mudanças necessárias no prompt.
No geral, o desempenho do modelo de IA nos testes mostra que ainda é necessário melhorias antes de que este seja considerado apto à responder perguntas analíticas.
Isto é devido à natureza estocástica dos modelos de IA. Quero dizer, no projeto ChartARKit citado anteriormente, se o modelo de IA renderizar um objeto 3D não exatamente no lugar requisitado mas próximo a ele, provavelmente o usuário não irá ligar muito. Infelizmente, o mesmo não pode ser dito para perguntas analíticas, nesse caso as respostas devem ser exatas.
Entretanto, é importante ressaltar que não estou dizendo que os modelos de IA são incapazes de realizarem tal tarefa. O que estou dizendo é que a maneira como o modelo de IA foi utilizado nesse projeto precisa de melhorias.
Importante também notar que este projeto não usou técnicas mais avançadas de IAs generativas, como Langchain e AutoGPT. Aqui um abordagem mais "pura" foi utilizada; talvez o uso ferramentas mais sofisticadas podem levar a resultados melhores.
Com relação à segurança, o analisador de código foi capaz de detectar todos os problemas de segurança testados.
Entretanto, isto não significa que o código gerado pelo modelo de IA é 100% seguro. Além disso, permitir a execução de código Python gerado externamente pode ser perigoso, sem sobra de dúvidas. Nem mesmo é possível afirmar com 100% de segurança que o sistema que está entregando o código Python é realmente o servidor da OpenAI...
Uma melhor saída para evitar problemas de segurança poderia ser o uso de outra linguagem de programação menos poderosa que Python, ou até mesmo criar uma "linguagem" própria e solicitar ao modelo de IA que a use, como pode ser visto neste exemplo simples.
Finalmente, é importante observar que aspectos como desempenho de execução de código, não foram considerados nesse projeto e provavelmente seria também um bom assunto para trabalhos futuros.
Assim, espero que você tenha achado esse projeto interessante e útil.
Aviso: Este é um projeto experimental. Ele envia dados para APIs da OpenAI e executa código gerado pelo modelo de IA no seu sistema. Então, não o use sobre dados sensíveis e/ou sistemas em produção. Observe também que chamadas para APIs da OpenAI são cobradas. Use este projeto sobre risco próprio. Ele não é um projeto pronto para ser usado em produção.
Comments
muito bom!!! parabéns!!!