Limpar filtro
Artigo
Heloisa Paiva · Maio 8
Migrar de Oracle, MSSQL ou outros sistemas de banco de dados puramente relacionais para um InterSystems IRIS multimodel é uma decisão estratégica que requer planejamento e execução cuidadosos. Embora essa transição ofereça benefícios significativos, incluindo desempenho aprimorado, escalabilidade e suporte para arquiteturas modernas, ela também apresenta desafios. Neste artigo, destacarei algumas das considerações relacionadas à codificação para garantir uma migração bem-sucedida. Deixarei tudo o que está conectado a uma migração real de estruturas e dados fora do escopo deste artigo.
Primeiramente, ao considerar migrar para um sistema de banco de dados diferente, você precisa entender sua lógica de negócios, seja ela do lado da aplicação (servidor de aplicação) ou do servidor de banco de dados. Basicamente, onde você tem suas instruções SQL que potencialmente precisará reescrever?
Quando a lógica da sua aplicação depende fortemente de SQL executado diretamente no código da aplicação (em vez de dentro de stored procedures ou triggers no banco de dados), migrar de um banco de dados relacional para o InterSystems IRIS requer um exame cuidadoso das suas instruções SQL. Vamos analisar alguns dos fatores mais importantes nos quais você precisa pensar.
Diferenças de dialeto SQL. O IRIS SQL oferece suporte ao padrão SQL-92. Isso não significa que alguns recursos mais modernos não estejam implementados. Significa apenas que você precisa verificar previamente. Por exemplo, as funções de janela apareceram no SQL:2003, mas você ainda pode escrevê-las no IRIS:
--window function
select id, rating
from (select a.id,
r.rating,
avg(r.rating) over () as avg_rating
from SQLUSER.Actor a join SQLUser.Review r on a.id = r.Reviews) as sub
where rating > avg_rating
Ao mesmo tempo, novos tipos de dados complexos, como XML, JSON, Arrays e tipos de dados geográficos, não são suportados. Então, a seguinte consulta:
SELECT a.id,
a.firstname,
ARRAY_AGG(r.rating) AS ratings
FROM SQLUSER.Actor a LEFT JOIN SQLUser.Review r ON a.id = r.Reviews
GROUP BY a.firstname
retornará um erro: ERROR #5540: SQLCODE: -359 Message: User defined SQL function 'SQLUSER.ARRAY_AGG' does not exist
Mas não é o fim do mundo. Existem muitas funções integradas que permitirão que você reescreva as consultas para obter o resultado esperado.
2. Funções integradas. Diferentes SGBDs (Sistemas de Gerenciamento de Banco de Dados) possuem diferentes funções integradas. Portanto, você precisa entender como elas correspondem às disponíveis no IRIS. Aqui estão vários exemplos do que estou falando, funções usadas no Oracle e seus equivalentes no IRIS:
Oracle
IRIS
NVL
ISNULL(field, default_value)
substr
$extract(field, start_pos, end_pos)
instr
$find(field, text_to_find)
concat
{fn CONCAT(string1,string2)}
Quando sua lógica SQL primária reside dentro de um banco de dados (por exemplo, stored procedures, triggers, views), migrar para o InterSystems IRIS requer uma abordagem diferente. Aqui estão algumas das considerações:
Migração de Objetos de Banco de Dados
Todas as Stored Procedures precisam ser reescritas usando ObjectScript. Este também pode ser um bom momento para mudar para o modelo de objetos, já que você obterá uma tabela de qualquer maneira ao criar uma classe. No entanto, trabalhar com classes permitirá que você escreva métodos (que podem ser chamados como stored procedures) e use todo o poder do paradigma orientado a objetos.
Triggers, Índices e Views são todos suportados pelo IRIS. Você pode até deixar suas Views como estão se as colunas da tabela permanecerem as mesmas, caso não usem nenhuma das funções/sintaxes não suportadas (veja o ponto anterior).
A Migração de Definições também é significativa e pode apresentar alguns desafios. Primeiro, você deve corresponder cuidadosamente os tipos de dados do seu DB anterior ao IRIS, especialmente se estiver usando novos tipos complexos. Além disso, tendo mais flexibilidade com os índices, você pode querer redefini-los de forma diferente.
Aqui estão algumas coisas que você precisa considerar ao decidir migrar para o InterSystems IRIS a partir de um banco de dados relacional diferente. É uma decisão estratégica que pode desbloquear benefícios significativos, incluindo escalabilidade, desempenho e eficiência aprimorados. No entanto, um planejamento cuidadoso é crucial para garantir uma transição perfeita e para abordar as necessidades de compatibilidade, transformação de dados e refatoração de aplicativos.
Artigo
Angelo Bruno Braga · Jun. 30, 2021
Olá Desenvolvedores,
Nesta postagem nós gostaríamos de falar com vocês como tirar o máximo proveito da Comunidade de Desenvolvedores para aprender o máximo que você puder com os experts da tecnologia InterSystems!
Prestem atenção nestes passos para se tornar um usuário avançado de nossa comunidade!
Siga os membros que você se interessa
Você pode seguir qualquer membro da Comunidade que publica conteúdos que você gosta ou se interessa. Para isso, clique no botão "Seguir" na barra lateral direita de qualquer membro e você será notificado por e-mail sempre que este membro publicar uma postagem (artigo/pergunta/anúncio ,etc.) na Comunidade.
Você também pode selecionar no menu superior a opção "Membros" e procurar por uma pessoa específica ou membros com mais visualizações, maior quantidade de likes... e começar a segui-los.
Siga as tags que você tem interesse
Todas as tags utilizadas para descrever as postagens na Comunidade podem ser encontradas na seção "Tags" na página inicial da Comunidade de Desenvolvedores:
Na Árvore de Tags da Comunidade de Desenvolvedores, você poderá encontrar tópicos que você tenha interesse e então seguir as tags relacionadas a eles. Para isso, selecione a tag e clique no botão "Seguir" próxima a ela. Quando você segue qualquer uma das tags, voC~e recebe um e-mail com todas as postagens que utilizam esta tag.
Tags que sugerimos: Melhores Práticas | Dicas e Truques | Iniciante | Tutorial.
Siga as postagem que você se interessar
Seguindo uma postagem, você receberá (por e-mail) todas as atualizações feitas nesta postagem como: novos comentários, se uma segunda parte dela for publicada, ou qualquer outra atividade relacionada a postagem que você esteja seguindo.
Para seguir uma postagem você precisa apenas clicar no ícone de sino abaixo de cada postagem:
-> Como fico sabendo quais membros, tags e postagens que estou seguindo?
Para saber quais membros, tags e postagens que você segue você precisa apenas ir para sua conta, no canto superior direito:
e então selecionar "Inscrições" no menu lateral esquerdo:
E na parte de baixo desta página você poderá ver e customizar suas inscrições através das três abas - cada uma mostrando os membros, tags e postagens que você está seguindo no momento. Por exemplo, no print de tela abaixo você pode verificar que o usuário está seguindo um membro da comunidade e duas tag:
Nota: Se você quiser seguir mambros ou tags em diferentes idiomas você precisa alterar as configurações de sua inscrição para o idioma desejado.
Adicionar postagens aos seus favoritos
Adicione a postagem que você gostar aos favoritos para que você possa acessá-la de forma mais rápida e fácil no futuro.
Se você gostar de uma postagem (artigo, pergunta ou anúncio) e gostaria de ler ele mais tarde ou guardá-lo, você pode adicioná-lo aos favoritos. Desta forma você consegue acessar a postagem de forma fácil e rápida e pode ler e reler ele quando você quiser.
Para adicionar uma postagem aos seus favoritos você precisa apenas clicar no ícone de estrela abaixo de cada postagem:
Para ver todos os seus favoritos, vá para sua conta e então para "Favoritos", no menu lateral a esquerda:
Espero que tenham gostado !
Usem todas as funcionalidades da Comunidade de Desenvolvedores que podem ajudá-lo a se tornar mais um expert nas tecnologias da InterSystems.
E é claro, vocês são muito bem vindos para nos enviar novas formas e dicas de como aprender as Tecnologias InterSystems através da Comunidade de Desenvolvedores nos comentários desta postagem.
Artigo
Danusa Calixto · Set. 14, 2022
O [SDK Nativo para Python](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=BPYNAT_about) da InterSystems é uma interface leve de APIs do InterSystems IRIS que antes estavam disponíveis somente por ObjectScript.
Estou especialmente interessado na capacidade de chamar métodos ObjectScript ou class methods, para ser preciso. Funciona muito bem, mas, por padrão, as chamadas só são compatíveis com argumentos escalares: strings, booleanos, inteiros e floats.
No entanto, se você quiser:
- Transmitir ou retornar estruturas, como dicionários ou listas
- Transmitir ou retornar streams
Você precisará escrever glue code ou usar este [projeto](https://github.com/eduard93/edpy) (instalação com `pip install edpy`). O pacote `edpy` fornece uma simples assinatura:
```python
call(iris, class_name, method_name, args)
```
que permite chamar qualquer método ObjectScript e receber resultados de volta. Faça a importação assim:
```python
from edpy import iris
```
`call` aceita 4 argumentos obrigatórios:
- `iris` — uma referência a um [objeto IRIS](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=BPYNAT_refapi#BPYNAT_refapi_class-iris) estabelecido
- `class_name` — classe IRIS para chamar
- `method_name` — método IRIS para chamar
- `args` — lista de 0 ou mais argumentos
## Argumentos
Cada argumento pode ser um destes:
- string (qualquer comprimento, se for maior do que `$$$MaxStringLength` or 3641144 símbolos, é automaticamente convertida em um stream)
- booleano
- inteiro
- float
- dict (convertido em um objeto dinâmico)
- lista ou tupla (convertidas em array dinâmica)
os argumentos dicionário, lista e tupla podem conter recursivamente outros dicionários, listas e tuplas (enquanto houver memória).
## Valor de retorno
Em retorno, esperamos um objeto/array dinâmico ou um stream/string JSON. Nesse caso, edpy primeiro converteria em uma string em Python e, se possível, interpretaria como um dicionário ou uma lista em Python. Caso contrário, o resultado seria retornado ao autor da chamada da mesma maneira.
É basicamente isso, mas veja alguns exemplos de métodos ObjectScript e como chamá-los usando essa função em Python.
## Exemplo 1: Pong
```objectscript
ClassMethod Test(arg1, arg2, arg3) As %DynamicArray
{
return [(arg1), (arg2), (arg3)]
}
```
Chame com:
```
>>> iris.call(iris_native, "User.Py", "Test", [1, 1.2, "ABC"])
[1, 1.2, 'ABC']
```
Nenhuma surpresa aqui. Os argumentos são colocados de volta em uma array e retornados ao autor da chamada.
## Exemplo 2: Propriedades
```objectscript
ClassMethod Test2(arg As %DynamicObject) As %String
{
return arg.Prop
}
```
Chame desta maneira:
```
>>> iris.call(iris_native, "User.Py", "Test2", [{"Prop":123}])
123
```
Agora para uma invocação mais incorporada:
```
>>> iris.call(iris_native, "User.Py", "Test2", [{"Prop":{"Prop2":123}}])
{'Prop2': 123}
```
Se uma propriedade for muito longa, também não tem problema — os streams serão usados para enviá-la ao IRIS e/ou de volta:
```
ret = iris.call(iris_native, "User.Py", "Test2", [{"Prop":"A" * 10000000}])
>>> len(ret)
10000000
```
Se você precisar de streams garantidos no lado do InterSystems IRIS, você pode usar [%Get](https://docs.intersystems.com/irislatest/csp/documatic/%25CSP.Documatic.cls?&LIBRARY=%25SYS&CLASSNAME=%25Library.DynamicObject#%25Get):
```objectscript
set stream = arg.%Get("Prop",,"stream")
```
Se o stream for codificado em base64, você pode decodificá-lo com:
```objectscript
set stream = arg.%Get("Prop",,"stream
Artigo
Danusa Calixto · Jul. 28, 2022
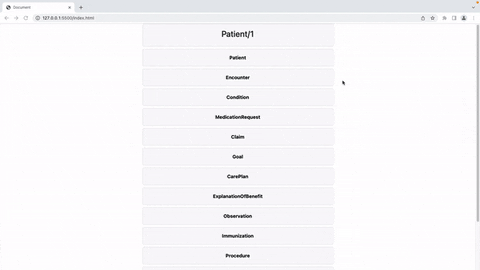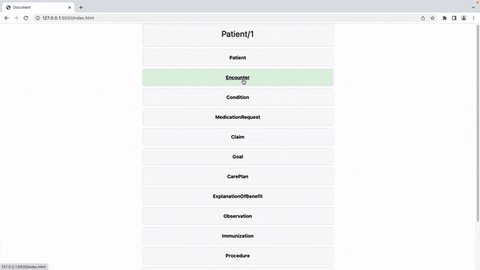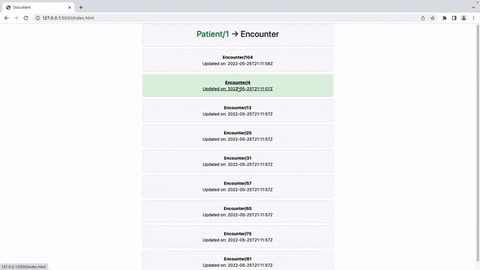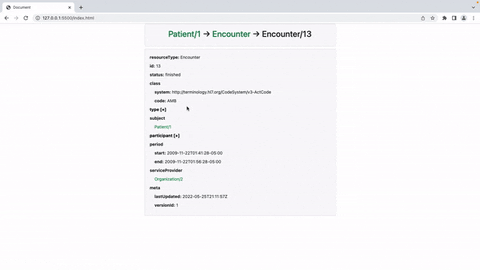
Oi pessoal!
Só queria compartilhar aqui um post rápido sobre meu projeto para o Grand Prix :)
O FHIR Patient Viewer é uma ferramenta de renderização reativa de página única construída no Vue.js que exibe de maneira amigável os dados retornados de uma chamada /Patient/{id}/$everything feita para um servidor FHIR da InterSystems. No readme, incluí 3 coisas principais: 1. Uma demonstração em vídeo conectando o FHIR Patient Viewer a um servidor sandbox IRIS FHIR (a maneira mais rápida de testá-lo); 2. Um segundo vídeo mostrando como eu usaria o FHIR Patient Viewer em um ambiente de produção (usando um backend personalizado para lidar com as chamadas da API, escrito em PHP/Laravel no meu exemplo, mas transferível para outras linguagens/frameworks); e 3. instruções para modificar os componentes, criar sua própria versão da ferramenta e construir seus próprios arquivos dist.
Obrigado a todos! Qualidade incrível nos projetos do concurso!
Dan
Artigo
Larissa Prussak · Maio 23
Depois que implementamos um novo container baseado em containers.intersystems.com/intersystems/irishealth:2023.1 esta semana, percebemos que nosso FHIR Repository começou a responder com um Erro 500. Isso aconteceu devido a violações de PROTECT no novo namespace e banco de dados HSSYSLOCALTEMP utilizado por essa versão dos componentes FHIR do IRIS for Health.
A solução para isso é adicionar a permissão "%DB_HSSYSLOCALTEMP" nas Aplicações Web que processam as requisições FHIR.
Você pode automatizar essa configuração executando o seguinte método de classe nos namespace(s) onde essas Aplicações Web estão definidas:
do ##class(HS.HealthConnect.FHIRServer.Upgrade.MethodsV6).AddLOCALTEMPRoleToCSP()
No nosso caso, isso não foi suficiente. Parte do nosso código customizado precisa acessar o token JWT Bearer enviado pelo cliente, o qual antes era obtido através do elemento AdditionalInfo "USER:OAuthToken", que não está mais presente na build 2023.6.1.809, conforme descrito em:
https://docs.intersystems.com/upgrade/results?product=ifh&versionFrom=20...
Contornamos esse problema adicionando a seguinte lógica para buscar o token diretamente do cache de tokens:
> ` $$$ThrowOnError(##class(HS.HC.Util.InfoCache).GetTokenInfo(pInteropRequest.Request.AdditionalInfo.GetAt("USER:TokenId"), .pTokenInfo))
> set OAuthToken = pTokenInfo("token_string")`
Artigo
Cristiano Silva · Maio 5, 2023
Apache Superset é uma plataforma moderna de exploração e visualização de dados. O Superset pode substituir ou trazer ganhos para as ferramentas proprietárias de business intelligence para muitas equipes. O Superset integra-se bem com uma variedade de fontes de dados.
E agora é possível usar também com o InterSystems IRIS.
Uma demo online está disponível e usa IRIS Cloud SQL como sua fonte de dados.
Apache Superset fornece vários exemplos, que foram carregados com sucesso no IRIS sem problemas, e exibidos em dashboards de exemplo.
O suporte para IRIS é implementado como um pacote Python chamado superset-iris, que pode ser instalado no Superset manualmente.
Superset usa SQLAlchemy como um mecanismo de banco de dados, portanto, o pacote superset-iris usa sqlalchemy-iris.
Quando o pacote é instalado no ambiente Superset, é possível selecionar o InterSystems IRIS na lista de bancos de dados suportados.
Para conectar ao IRIS, é necessário uma URI do SQLAlchemy no formato iris://{login}:{password}@{hostname}:{port}/{namespace}
Clique em Test Connect para verificar se o servidor está disponível. Clique em Connect, para terminar de adicionar o banco de dados.
No mesmo formulário de edição do banco de dados, na aba Avançado, e no bloco Segurança, opção chamada Permitir uploads de arquivos para o banco de dados, permitirá fazer o upload de arquivos CSV e construir tabelas no IRIS com base nele.
SQL Lab, permite executar Consultas SQL
Além de coletar e exibir informações sobre esquemas e tabelas existentes, visualizar tabelas e oferecer a construção de uma consulta SQL simples com todas as colunas.
Para testar localmente clone o repositório
git clone https://github.com/caretdev/superset-iris.git superset-iris
cd superset-iris
Inicie o Superset com o Docker-Compose
docker-compose pull
docker-compose up -d
Durante a inicialização os dados de exemplo são importados para o IRIS, pode demorar um pouco, espere até terminar, execute o comando:
docker-compose logs -f superset-init
Quando o comando acima terminar, acesse http://localhost:8088/dashboard/list/. Os Dashboards estão disponíveis sem necessidade de autorização. Para acessar o SQL Lab utilize admin/admin como login e senha.
Por favor vote no concurso
Artigo
Vinicius Maranhao Ribeiro de Castro · Maio 11, 2021
Introdução
Suponha que você desenvolveu uma nova aplicação utilizando a parte de Interoperabilidade do InterSystems IRIS e você tem certeza de que será um sucesso! No entanto, você ainda não tem um número concreto de quantas pessoas irão utilizá-la. Além disso, pode haver dias específicos em que há mais pessoas utilizando sua aplicação e dias em que quase ninguém irá acessar. Deste modo, você necessita de que sua aplicação seja escalável!
O Kubernetes já nos ajuda bastante nesta tarefa com um componente chamado Horizontal Pod Autoscaler, que permite escalar horizontalmente uma aplicação baseado em uma métrica específica. Através do componente “Metrics Server” do próprio Kubernetes, é possível obter métricas como utilização de CPU ou de memória. Mas, e se você necessitar escalar sua aplicação utilizando outra métrica, como por exemplo o tamanho da fila de todos os “Business Hosts” presentes em uma determinada Produção da Interoperabilidade do IRIS? Por se tratar de uma métrica customizada, será necessário desenvolver um serviço que irá expor essa métrica customizada para o Kubernetes.
Nesta série de artigos, veremos em mais detalhes como funciona o processo de escalonamento horizontal do Kubernetes. Na parte 1, será abordado o funcionamento do componente responsável pelo escalonamento horizontal do Kubernetes e a criação e exposição de uma métrica customizada do IRIS no formato esperado pelo Prometheus. Já na parte 2, abordaremos como configurar o Prometheus para ler essa métrica e como configurar o prometheus-adapter para expor essa métrica ao Kubernetes.
O projeto utilizado para este artigo está totalmente disponível no GitHub em:
https://github.com/vmrcastro/iris-autoscale
Kubernetes - Horizontal Pod Autoscaler
Como mencionado na Introdução, o Horizontal Pod Autoscaler é um recurso do Kubernetes que permite escalar horizontalmente aplicações baseado no valor de uma métrica específica. No exemplo abaixo, é exibido um arquivo yaml contendo a definição de um Horizontal Pod Autoscaler:
kind: HorizontalPodAutoscalerapiVersion: autoscaling/v2beta1metadata: name: iris-autoscalespec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: iris-autoscale # autoscale between 1 and 5 replicas minReplicas: 1 maxReplicas: 5 metrics: # use a "Pods" metric - type: Pods pods: metricName: queue_size # target queue size of 10 targetAverageValue: 10
Observe que nele definimos o que queremos escalar horizontalmente, neste caso o Deployment denominado “iris-autoscale”, qual é o valor mínimo e máximo de réplicas de IRIS que desejamos que executem simultaneamente, a quem essa métrica se refere (no nosso caso será PODs), qual é a métrica que utilizaremos como balizadora (“queue_size” neste exemplo) e qual é o valor médio dessa métrica que utilizaremos como alvo.
O funcionamento simplificado do Horizontal Pod Autoscaler segue o seguinte diagrama:
Fonte: https://learnk8s.io/autoscaling-apps-kubernetes
A cada 15 segundos, o Horizontal Pod Autoscaler busca o valor da métrica configurada, calcula a quantidade de réplicas da aplicação que devem estar rodando baseado na métrica obtida dessa busca e no valor alvo configurado no Horizontal Pod Autoscaler e, se necessário, adiciona ou remove réplicas da aplicação.
O cálculo da quantidade de réplicas que devem estar rodando é realizado através da seguinte fórmula:
X = N * (c/t)
onde X é a quantidade de réplicas que devem estar rodando, N é o número atual de réplicas em execução, c é o valor atual da métrica e t é o valor alvo da métrica.
No entanto, esse é o funcionamento simplificado. Na verdade, o Horizontal Pod Autoscaler não busca diretamente na aplicação o valor da métrica configurada. Ao invés disso, o Horizontal Pod Autoscaler busca esses valores no “Metrics Registry”, um outro componente do Kubernetes cuja função principal é fornecer uma interface padrão para todas as métricas que serão expostas para diversos clientes – no nosso caso, o Horizontal Pod Autoscaler.
Fonte: https://learnk8s.io/autoscaling-apps-kubernetes
O “Metrics Registry” possui 3 APIs distintas: Resource Metrics API, Custom Metrics API e a External Metric API. No nosso caso, utilizaremos a Custom Metrics API, que é destinada para métricas associadas a um objeto do Kubernetes mas não é nenhuma daquelas métricas de CPU e memória já “fornecidas por padrão” no Kubernetes.
Portanto, será necessário expor nossa métrica customizada para a Custom Metrics API do Metrics Registry. Para isso, necessitaremos 2 componentes: o “metric API server”, que irá efetivamente expor essa métrica customizada e o “metric collector”, responsável por coletar as métricas de cada um dos PODs que estão executando a aplicação e fornecê-las ao “metric API server”.
Fonte: https://learnk8s.io/autoscaling-apps-kubernetes
Há diversas formas de implementar o “metric collector” e o “metric API server”. Neste artigo, utilizaremos o Prometheus como “metric collector” e o Prometheus Adapter como “metric API server” para aproveitar a facilidade que o InterSystems IRIS fornece para criar e expor uma métrica ao Prometheus.
InterSystems IRIS – Criando uma métrica customizada
O InterSystems IRIS já expõe, por padrão, uma série de métricas de monitoramento no padrão conhecido pelo Prometheus. Essas métricas são comumente utilizadas por uma outra grande ferramenta que a InterSystems disponibiliza para monitoramento de instâncias do InterSystems IRIS, o InterSystems SAM (sigla para System Alerting and Monitoring). Neste artigo, não utilizaremos o SAM por enquanto, mas se você quiser saber mais, a documentação deste produto está disponível em:
https://docs.intersystems.com/sam/csp/docbook/DocBook.UI.Page.cls?KEY=ASAM
A lista completa de métricas disponíveis por padrão em uma instância do IRIS pode ser encontrada neste endereço:
https://irisdocs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=GCM_rest#GCM_rest_metrics_table
Caso você possua uma instância de IRIS rodando, você pode enviar uma requisição REST diretamente para o endpoint de exposição dessas métricas e analisar a resposta. Para isso, basta executar:
curl http://<IP_do_IRIS>:<Porta_WebServer_IRIS>/api/monitor/metrics
Esta requisição acima será exatamente a requisição que o Prometheus ficará enviando às instâncias do IRIS de tempos em tempos para monitorá-las.
Como não há nenhuma métrica relacionada ao tamanho da fila de uma Produção da Interoperabilidade do IRIS, iremos criar uma métrica que denominaremos “queue_size” seguindo as instruções da documentação disponível em:
https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=GCM_rest#GCM_rest_metrics_application
Como vocês podem perceber, é muito simples criar e expor uma nova métrica no IRIS. Basta criar uma classe que estende a classe “%SYS.Monitor.SAM.Abstract”, definindo um nome no parâmetro “PRODUCT” para o prefixo das métricas que serão criadas e implementar o método “GetSensors()” para definir o nome e valor das métricas atráves da chamada para o método “SetSensor()”. Esta foi a classe desenvolvida para criarmos e expormos a métrica “queue_size”:
Class CustomMetric.QueueMetric Extends %SYS.Monitor.SAM.Abstract
{
Parameter PRODUCT = "queue";
/// Collect metrics from the specified sensors
Method GetSensors() As %Status
{
&sql(SELECT SUM("Count") INTO :queuesize FROM EnsPortal.Queues_EnumerateQueues())
If (SQLCODE<0 || SQLCODE=100) {
Return $$$ERROR($$$SQLError, $System.SQL.SQLCODE(SQLCODE))
}
do ..SetSensor("size",queuesize)
Return $$$OK
}
}
Com essa classe compilada, basta executar no Terminal do IRIS:
%SYS>set status = ##class(SYS.Monitor.SAM.Config).AddApplicationClass("CustomMetric.QueueMetric", "AUTOSCALE")
%SYS>w status
status=1
e editar a Web Application /api/monitor adicionando a Application Role necessária para acessar essa classe. Feito isso, é possível enviar uma nova requisição
curl http://<IP_do_IRIS>:<Porta_WebServer_IRIS>/api/monitor/metrics
e verificar que a métrica “queue_size” está sendo exibida.
Conclusão
Nesta primeira parte, abordamos com mais detalhes o funcionamento e a definição do Horizontal Pod Autoscaler, componente do Kubernetes responsável por promover o escalonamento horizontal de entidades do Kubernetes (no nosso caso PODs) de maneira automática. Além disso, abordamos a criação de uma métrica customizada no IRIS e a sua disponibilização em um formato padrão do Prometheus.
No próximo artigo da série, veremos como configurar o Prometheus para ler essa métrica customizada e como configurar o prometheus-adapter para expô-la ao Kubernetes.
Referencias
https://learnk8s.io/autoscaling-apps-kubernetes
https://prometheus.io/docs/introduction/first_steps/
https://prometheus.io/docs/prometheus/latest/configuration/configuration/
https://github.com/kubernetes-sigs/prometheus-adapter/blob/master/docs/config-walkthrough.md
https://github.com/kubernetes-sigs/prometheus-adapter/blob/master/docs/walkthrough.md
https://github.com/prometheus/prometheus/blob/release-2.26/documentation/examples/prometheus-kubernetes.yml
Anúncio
Mike Morrissey · Mar. 29, 2021
Caro Cliente de HealthShare:
Esta postagem é parte do processo de comunidação de Alertas do HealthShare HS2021-03. A mesma informação foi divulgada através de:
E-mails para clientes HealthShare
Na página de Alertas e Recomendações dos Produtos
Na Página de Distribuição de Documentos InterSystems no WRC
Alerta
Produtos & Versões Afetadas
Categoria de Risco & Pontuação
HS2021-03 -01: Problema em Potencial de Integridade de Dados na Aplicação dos Arquivos de Journal em Espelhamento
Este problema afeta todos os produtos HealthShare e versões que suportam o espelhamento:
HealthShare Unified Care Record/Information Exchange, Health Insight, e Patient Index versão 15.02 e versões recentes
HealthShare Personal Community versão 12.0 e versões recentes
HealthShare Provider Directory 2019.2, 2020.1 e 2020.2
HealthShare Health Connect e versões HSAP que suportam espelhamento.
2-Risco Baixo (Segurança Clínica)
1-Risco Muito Baixo (Privacidade)
1-Risco Muito Baixo (Segurança)
2-Low Risk (Operations)
Se você tiver alguma dúvida sobre este comunicado, entre em contato com support@intersystems.com e faça referência ao alerta “HealthShare Alert HS2021-03”.
Anúncio
Rochael Ribeiro · Jun. 7, 2021
Desenvolvedores
O InterSystems FHIR Accelerator contest acabou!!! Agora é hora de anunciar os ganhadores!!!!!
Muitos aplausos vai para esses desenvolvedores e seus aplicativos:
🏆 Experts Nomination - os vencedores foram determinados por um júri especialmente selecionado:
🥇 1st lugar e $4,000 vai para FHIR Data Studio Connector project by @Dmitry.Maslennikov
🥈 2nd lugar e $2,000 vai para FHIR Simple Demo Application project by @Marcello.Correa
🥉 3rd lugar e $1,000 vai para iris-on-fhir project by @Henrique.GonçalvesDias and @José.Pereira
🏆 Community Nomination - o aplicativo que recebeu o maior número de votos no total:
🥇 1st lugar e $1,000 vai para iris-on-fhir project by @Henrique.GonçalvesDias and @José.Pereira
🥈 2nd lugar e $500 vai para FHIR Data Studio Connector project by @Dmitry.Maslennikov
🥉 3rd lugar e $250 vai para FHIR Simple Demo Application project by @Marcello.Correa
Parabéns a todos os vencedores!
Obrigado a todos por sua atenção ao concurso e pelo esforço que você dedica a ele!
Artigo
Yuri Marx · jan 16, 2021
Oi Comunidade InterSystems!
A linguagem ObjectScript do InterSystems IRIS possui a capacidade de estender classes utilizando um recurso muito interessante chamado XData.
Trata-se de uma seção em sua classe que pode ser utilizada para criar definições personalizadas a serem utilizadas dentro da própria classe e também externamente.
Para criar uma ou mais definições de XData para sua classe é muito fácil, veja o exemplo:
Class dc.Sample.Person Extends (%Persistent, %JSON.Adaptor, %Populate)
{
Property Name As %VarString;
Property Title As %String;
Property Company As %String;
Property Phone As %VarString;
Property DOB As %Date(MAXVAL = "$piece($horolog, "","", 1)");
/// Index for property DOB
Index DOBIndex On DOB;
ClassMethod AddTestData(amount As %Integer = 10)
{
d ..Populate(amount)
}
/// Documentation for Person
XData PersonDocHtml [ MimeType = text/html ]
{
<h1>This is the Person class</h1>
}
XData PersonDocMarkdown [ MimeType = text/markdown ]
{
<h1>This is the Person class</h1>
}
Veja que logo após as definições dos métodos, basta adicionar uma ou mais seções XData com três seções: XData NomeSecaoXData [MimeType = TipodeMimeType]. O conteúdo então é colocado entre {}.
Todos os elementos XData são armazenados na classe persistente %Dictionary.XDataDefinition. Isto significa que é possível recuperar as definições utilizando linguagem SQL, internamente ou externamente, veja o exemplo:
ClassMethod Generate()
{
Set qry = "SELECT * FROM %Dictionary.XDataDefinition WHERE MimeType IN ('text/markdown','text/html')"
Set stm = ##class(%SQL.Statement).%New()
Set qStatus = stm.%Prepare(qry)
If qStatus'=1 {Write "%Prepare failed:" Do $System.Status.DisplayError(qStatus) Quit}
Set rset = stm.%Execute()
While rset.%Next() {
Write "Row count ",rset.%ROWCOUNT,!
Write rset.parent
Write ": ",rset.Description,!!
}
Write !,"End of data"
Write !,"Total row count=",rset.%ROWCOUNT
}
}
Neste exemplo, todos os elementos XData com Mime Type markdown e html são recuperados e então tem o nome da classe onde se encontra o XData e a descrição do XData. Caso queira recuperar conteúdo, basta obter a propriedade Data.
Trata-se de uma funcionalidade muito interessante, pois podemos catalogar a documentação de todas as classes de uma aplicação e ter o fácil acesso a elas. Fantástico!
Artigo
José Hélington Pires da Cruz · Mar. 31, 2021
Por padrão, o InterSystems IRIS expõe seus endpoints usando http, mas pode ser necessário executar https em seu ambiente de desenvolvimento e / ou obter acesso público à Internet para seu aplicativo. Você pode comprar ou obter um certificado e configurar um gateway, gastando muitas horas ou usando um ótimo serviço público chamado ngrok. Siga os passos:
1 - Execute seu aplicativo, usarei o template FHIR como amostra, veja:
1.1 baixe o aplicativo: git clone https://github.com/intersystems-community/iris-fhir-template.git
1.2 vá para o diretório do aplicativo: cd iris-fhir-template
1.3 execute o aplicativo: docker-compose up -d
1.4 obter acesso ao endpoint do postman ou outro cliente api: http: // localhost: 32783 / fhir / r4 / Patient / 1
2 - Você pode ver que o nó de extremidade roda apenas localhost e usando http. Agora usamos o ngrok para resolver isso:
2.1 - Acesse https://ngrok.com/, crie uma conta grátis e faça o login no ngrok. Você pode ver muitas opções, incluindo o uso de ngrok em seus arquivos yml.
2.2 - No ngrok, vá para Configuração e instalação (https://dashboard.ngrok.com/get-started/setup) e baixe o ngrok específico para o seu sistema operacional.
2.3 - Descompacte o arquivo no caminho raiz do seu aplicativo (ou qualquer caminho, como a pasta de seus aplicativos).
2.4 - Autentique seu cliente no servidor ngrok usando as instruções em Autenticação> Seu Authtoken (https://dashboard.ngrok.com/auth/your-authtoken). No meu caso (windows) eu executei:
ngrok.exe authtoken 1iCGsc8NEmHTjfe43wmqavSHT2y_7T.........
2.5 - Ngrok salve seu authtoken em seu diretório home, para que nas próximas vezes não será necessário autenticar novamente, apenas use o serviço. 2.6 - Agora, você precisa saber sua porta http, no meu caso é 32783 (http: // localhost: 32783). Corre:
ngrok.exe http 32783
2.7 - Você pode ver o seu endereço https ou http público para o seu endpoint:
2.8 - Teste seu novo endpoint no carteiro ou em qualquer cliente de descanso, no meu caso https://9ec669d2221b.ngrok.io/fhir/r4/Patient/1.
2.9 - Ngrok oferece muitos outros cenários de caso de uso (webhook, ssh, etc), consulte: https://dashboard.ngrok.com/get-started/tutorials.
Anúncio
Angelo Bruno Braga · Jul. 7, 2021
Olá Comunidade,
Enfrentando complexidades arquiteturais desnecessárias? Muitas situações complexas para lidar? Se você tem enfrentado estes tipos de problemas, você está precisando de uma simplificação de sua arquitetura.
Não perca o webinar em inglês sob demanda por @Jeff.Fried ou leia seu blog recente para descobrir os recursos InterSystems que podem te ajudar a simplificar sua arquitetura de dados.
Quer saber mais? Visite nossa landing page para descobrir mais sobre os diferentes caminhos que você pode adotar para simplificar sua arquitetura de dados com a InterSystems.
Detalhes abaixo.
Porque utilizar múltiplos repositórios de dados quando você pode utilizar apenas um?
Conforme condições econômicas mais otimistas emergem depois da pandemia, organizações necessitarão de uma visão única e em tempo real dos dados de forma precisa e confiável, de forma que seja possível a entrega de valor aos clientes, a redução de risco e a reação rápida a novas oportunidades e desafios.
Alcançar estes objetivos entretanto, está longe de ser uma tarefa fácil de ser realizada. Um desafio comum que costumamos ouvir de nossos clientes é que através dos anos eles acabam por acumular múltiplas e diversas tecnologias para gerenciar as distintas cargas de trabalho e diferentes tipos de dados. Esta situação faz com que eles acabem por enfrentar uma complexidade arquitetural desnecessária, problemas de latência, bem como o desafio de lidar com muitas outras situações complexas derivadas desta situação. Este é o tipo de situação que precisa de uma simplificação arquitetural.
Para explicar melhor esta situação, nosso Diretor de Gerenciamento de Produtos, @Jeff.Fried palestrou no recente evento da IASA (Sociedade Irlandesa de Computação) sobre os diferentes métodos que podem ser utilizados para simplificar sua arquitetura de dados. Os caminhos para que sejam alcançados custos reduzidos, aumento de performance e uma maior e melhor segurança incluem:
Adoção de uma base de dados multi-modelo
Implantação de uma plataforma de dados translítica
Capitalização do processo de machine learning integrado à base de dados
Se você perdeu o webinar ao vivo você pode ouvir agora sob demanda do próprio Jeff sobre os prós e contras e as tendências que podem ajudá-lo a entender o que é possível ser alcançado com o uso de bases de dados multi-modelo e multi-workload, ouvindo seu webinar em inglês sob demanda ou lendo sua recente postagem no blog.
Quer debater a respeito?
Por favor sinta-se a vontade para compartilhar seus pensamentos nos comentários desta postagem. Fiquem ligados!
➡️ Landing page
➡️ Webinar em inglês sob demanda
➡️ Postagem no Blog
Artigo
Henrique Dias · Out. 21, 2021
Fala pessoal, beleza?
Como vocês exercitam sua criatividade? Como testam novas ideias?
Ao longo dos anos sempre pensei em criar coisas novas, modificar as existentes, experimentar, testar, quebrar (sempre acontece ), construir de novo, recomeçar.
Os concursos promovidos pela InterSystems são uma excelente fonte de motivação, obviamente os prêmios chamam muito a atenção e isso você não pode negar. Mas, não apenas prêmios, eles também nos dão um desafio criativo, uma oportunidade para criar, reimaginar, testar, experimentar. E a beleza de tudo isso é que você é livre para fazer o que quiser!
Vejo essas oportunidades como uma chance de criar meu próprio What if? (Aquela série onde a Marvel libera os autores para reimaginarem as histórias a vontade) e tenho tido a sorte de contar com um autor que embarca comigo nessas ideias Valeu @José.Pereira
No último concurso sobre Interoperabilidade, criei o Message Viewer e nesse concurso atual de Interoperabilidade eu trago novamente o Message Viewer, mas dessa vez com o nosso próprio Visual Trace!
Quem já trabalha com a tecnologia da InterSystems e conhece a parte de integração (Ensemble/Interoperability), sabe que o Visual Trace está lá há muito tempo, daquele mesmo jeitinho e não tem nenhum problema.
Ele funciona, exibe o diagrama de sequência da sua mensagem, mostra os detalhes, traz as informações, XML, etc. Mas... só porque ele funciona, não posso reimaginar? Tentar trazer uma nova perspectiva e talvez incentivar uma pequena mudança?
Steve Rogers está aí como exemplo, Capitão América, garoto propaganda Marvel e nem por isso eles deixaram de imaginar Peggy Carter como a Capitã da vez 😂
Então vamos falar um pouco sobre a nossa nova "Peggy Carter", digo, Visual Trace
Nosso bom e velho Visual Trace está representado abaixo:
Agora, imagine ter um mundo de mensagens aqui e você não ter como reenviar uma simples mensagem?!
Você teria que voltar para a tela do Message Viewer, vasculhar, pesquisar e reenviar sua mensagem.
Por isso, pensamos em mostrar que é possível sim, trazer as informações com um novo visual, oferecer uma funcionalidade simples e acredito que pode sim, auxiliar e facilitar a vida do desenvolvedor.
DEMO
https://iris-message-viewer.contest.community.intersystems.com/csp/msgviewer/messageviewer.csp
Se você curtiu o aplicativo, curte o que estamos fazendo na comunidade, por favor vote em IRIS Message Viewer e nos ajude nessa jornada!
https://openexchange.intersystems.com/contest/current
Anúncio
Evgenia Kurbanova · Maio 14, 2021
Olá Desenvolvedores,
É hora de anunciar os Ganhadores de Abril de 2021! Vamos receber e comemorar nossos incríveis Heróis do Global Masters!
E a chuva de aplausos vai para estes desenvolvedores e sua enorme contribuição para a Comunidade de Desenvolvedores em Abril de 2021:
🥇 @Dmitriy Maslennikov, Co-fundador, CTO e Desenvolvedor, CaretDev Corp, Rússia
🥈 @Lorenzo.Scalese, Arquiteto de Soluções, Zorgi, Bélgica
🥉 @Robert.Cemper1003, ex Sales Engineer Sênior na InterSystems, Áustria
Aprenda mais sobre a competição e sobre nossos incríveis ganhadores abaixo.
Sobre @Lorenzo.Scalese
Lorenzo alcançou o distintivo Master of Answers por 5 respostas aceitas na Comunidade de Desenvolvedores, publicado 3 artigos, e 21 comentários, ganhou o distintivo Bronze Open Exchange Developer por 5 Apps no Open Exchange, e o distintivo Post 5 Reporter Badge por 5 artigos na Comunidade de Desenvolvedores – Parabéns pelo feito! 🤩
"Sou arquiteto de soluções na Zorgi. Zorgi é especialista e líder no mercado Belga em soluções de TI para o setor de saúde.
Eu iniciei minha carreira em 2007 como desenvolvedor e trabalhando em vários projetos relacionados a indústria de saúde: soluções de registro médico eletrônico (EMR), soluções para radiologia, conectividade com soluções de RIS\PACS e modalidades ionizantes, central nacional de intercâmbio de dados de saúde,...
Hoje, meu trabalho é principalmente definir a arquitetura geral de uma solução de EMR, criando ferramentas para desenvolvimento, roteiros para desenvolvimento e migração de aplicações baseadas em Caché\HealthShare para IRIS utilizando contêineres.
Tenho trabalhado com tecnologia InterSystems desde que iniciei minha carreira. desde o Caché 5.2 até o IRIS atualmente.
Sobre mim: Nasci na Bélgica em 1984, meus pais são Italianos. Eu vivo em uma vila no interior, casado, pai de 2 meninos (11 e 8 anos).
Meus passatempos: tecnologias, passeios de mountain bike , faça você mesmo, e vídeo games
Abaixo uma foto de minha vila:
"
🔗Conecte-se com o Lorenzo agora para impulsionar sua rede:
Twitter
Developer Community
LinkedIn
Sobre @Dmitriy Maslennikov
Dmitry ganhou o distintivo Silver Open Exchange Developer por 10 Apps no Open Exchange, escreveu 3 novas postagens, 35 comentários, e 9 respostas aceitas, adicionou 3 aplicações no Open Exchange, teve uma grande atividade no Global Masters - Parabéns ! 🥳 e obrigado pela contribuição constante na Comunidade de Desenvolvedores!
Leiam por favor a biografia de Dmitry nesta postagem.
🔗Conecte-se ao Dmitry agora para impulsionar sua rede:
Twitter
Developer Community
LinkedIn
Sobre @Robert.Cemper1003
Em Abril, Robert ganhou o distintivo Advanced Translator 🧑🎓, subiu 3 aplicações para o Open Exchange, e fez 74 comentários na Comunidade de Desenvolvedores. Obrigado, Robert! ✨
Leiam por favor a biografia de Robert nesta postagem.
🔗Conecte-se ao Robert na Comunidade de Desenvolvedores agora para impulsionar sua rede!
Nossos agradecimentos a todos os vencedores pela sua grande e constante contribuição para a Comunidade de Desenvolvedores InterSystems!
Vamos dar os parabéns a nossos Heróis nos comentários abaixo!
Sobre a competição Global Master do Mês no Global Masters: Todos os meses, nomeamos os participantes que se esforçaram ao máximo estando altamente engajados na Global Masters e na Comunidade de Desenvolvedores. Os vencedores recebem 1000 pontos e um distintivo especial. Também oferecemos aos vencedores a publicação de suas biografias - agora no artigo na Comunidade de Desenvolvedores
Artigo
Danusa Calixto · Out. 27, 2022

Coloquei o Servidor FHIR da InterSystems para trabalhar na[ HL7 FHIR Connectathon em Baltimore](https://www.hl7.org/events/working_group_meeting/2022/09/) no último final de semana, postando pacotes, usando recursos Rest e interrogando o [Guia de Implementação Vulcan](http://www.hl7.org/vulcan/). Nós montamos os projetos Real World Data (RWD) e Schedule of Activity (SoA) para o pessoal do Vulcan IG, indo em frente e conectando pesquisa clínica e dados de saúde. Empregamos uma abordagem bastante decente para atender aos requisitos,
Com os colegas da InterSystems (Huy, Russell, Regilo), estávamos responsáveis por dar suporte ao Servidor FHIR e à apropriação de dados para o evento. Se você já foi encarregado de digitar Pacotes FHIR para um caso de uso específico, acho que pode apreciar como a dificuldade pode ser enganosa.
Provemos alguns Servidores FHIR da InterSystems do tamanho de um aparelho de som, 16 núcleos/128 GB, um para cada projeto, e começamos a trabalhar para cada equipe. As equipes vieram preparadas com seus notebooks Python contra nossos endpoints, com a expectativa de escrever uma História FHIR para a SCA, com um script de teste processual validando as chamadas retornadas com os resultados esperados.
A meta da coorte para o RWD era bastante simples nas consultas de exemplo da[ Síndrome coronária aguda](https://build.fhir.org/ig/HL7/vulcan-rwd/acs.html) para mim:
**Não é?**
```
/Patient?birthdate=le2002-09-01&gender=male,female
/Encounter?reason-code:below=I20,I21,I22,I23,I24,I25&date=ge2020-09-01&date=le2021-09-31&status=finished&dischargeDisposition:not=exp
/MedicationAdministration?status=completed&effective-time=ge[Encounter-Start-Date]&
code=http://www.nlm.nih.gov/research/umls/rxnorm|1116632,http://www.nlm.nih.gov/research/umls/rxnorm|613391,http://www.nlm.nih.gov/research/umls/rxnorm|32968,http://www.nlm.nih.gov/research/umls/rxnorm|687667,http://www.nlm.nih.gov/research/umls/rxnorm|153658
```
**Claro...**
**Fracassos** *Falha do Pacote de Submódulo Synthea* De maneira esperançosa, nossa primeira ave-maria foi para gerar 2 milhões de recursos e milhares de Pacotes Synthea (usando este adorável[ repositório da InterSystems](https://github.com/intersystems-community/irisdemo-base-synthea)) para o endpoint de transação e o recurso de upload do Gerenciamento de Dados, incluindo vários submódulos centrados no coração e comutadores sofisticados...
```
docker run --rm -v $PWD/output:/output -v $PWD/modules:/modules --name synthea-docker intersystemsdc/irisdemo-base-synthea:version-$VERSION --exporter.practitioner.fhir.export true --exporter.hospital.fhir.export true --exporter.fhir.use_us_core_ig true -p 500 -s 21 -d /modules
```
Não alcançamos isso, o que não é surpreendente, eu acho, mas eu meio que esperava pelo menos chegar perto. Não chegamos.
**Vitórias** *O Processo de Geração de Dados* Então, o [Geoff Low](https://github.com/glow-mdsol) nos deu uma pista sobre seu processo, nos separamos e prosperamos... é assim que o processo acontece.
1. Pegue um pacote de ponto de partida, em especial um que seja relevante para a Pesquisa e que tenha um mínimo de pacientes e encontros e use o pacote SDTM no [sourceforge](https://sourceforge.net/projects/fhirloinc2sdtm/files/LZZT_Study_Bundle/):
2. Agora, implemente uma [etapa de patching](https://github.com/sween/soa-bridge-match/blob/feature/connectathon_31/upstream/patch_json.py), para colocar o pacote no lugar, certifique-se de que ele seja carregado com sucesso no Servidor FHIR, carregue ou poste o pacote.
3. Depois de um novo ponto de partida, [aumente os encontros](https://github.com/sween/soa-bridge-match/blob/feature/connectathon_31/src/soa_bridge_match/dataset.py) com os códigos de motivos previstos ( I20,I21,I22,I23,I24,I25 ).
```
reasons = ["I21","I22","I23","I24","I25"]```
```
4. Adicione medicamentos aos encontros, incluindo todos os medicamentos esperados para o encontro para a Pesquisa da SCA.
```
medchoices = [
{
"code": "1116632",
"display": "ticagrelor"
},
{
"code": "613391",
"display": "prasurgrel"
},
{
"code": "32968",
"display": "clopidogrel"
}
]
medchoice = random.choice(medchoices)
medconcept = CodeableConcept(
coding=[
Coding(
code=medchoice["code"],
display=medchoice["display"],
system="http://www.nlm.nih.gov/research/umls/rxnorm",
)
]
)
```
> IMPORTANTE! Verifique se os medicamentos estão dentro das datas/horários do encontro.
>
5. Em seguida, confira se os Encontros realmente são internações e inclua todos os tipos aplicáveis.
```
statuses = ["in-progress","finished"]
dischargeCodes =
{
"code": "home",
"display": "Home"
},
{
"code": "hosp",
"display": "Hospice"
},
{
"code": "exp",
"display": "Expired"
},
{
"code": "long",
"display": "Long-term care"
},
{
"code": "alt-home",
"display": "Alternative home"
},
]
```
**Outra vitória** *Implementando o Parâmetro de Pesquisa do GI* O Guia de Implementação Vulcan inclui um parâmetro de pesquisa que é necessário para retornar encontros por disposição de alta. Abordamos isso de duas maneiras:
a. Carregar todo o GI b. Carregar o Parâmetro de Pesquisa
Carregar só o Parâmetro de Pesquisa era o caminho mais curto e estávamos em uma situação complicada por tempo suficiente, então aqui está como foi esse processo.
Criada a pasta `/tmp/mypackage`, adicione o parâmetro de pesquisa do GI e seu próprio arquivo do pacote.
```
[irisdeploy@ip-192-168-0-37 tmp]$ tree /tmp/mypackage
/tmp/mypackage
├── package.json
└── parameter.json
```
O arquivo do pacote pode parecer assim:
```
{
"name":"ron.sweeney.r4",
"version":"0.0.1",
"dependencies": {
"hl7.fhir.r4.core":"4.0.1"
}
}
```
Em seguida, carregue isso no IRIS, desta maneira:
```
TL4:IRIS:FHIRDB>do ##class(HS.FHIRMeta.Load.NpmLoader).importPackages($lb("/tmp/mypackage"))
Saving ron.sweeney.r4@0.0.1
Load Resources: ron.sweeney.r4@0.0.1
```
A próxima etapa é associar o pacote ao endpoint: 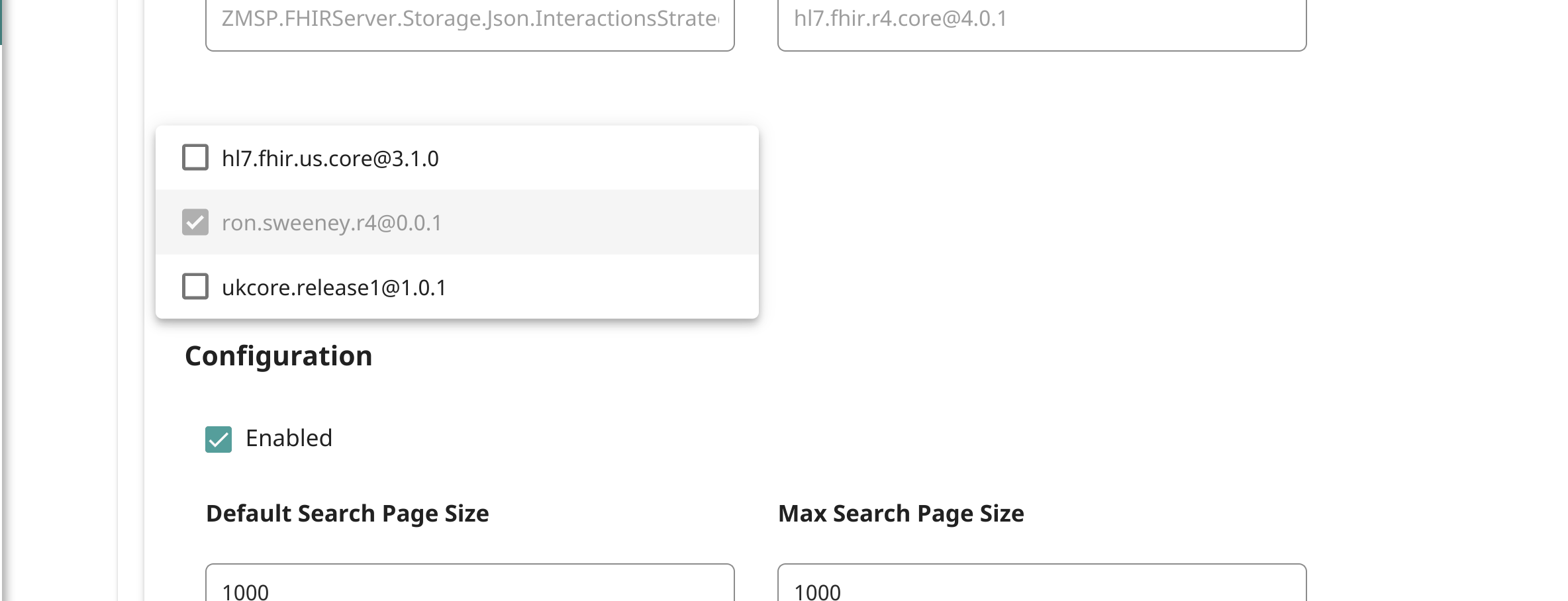
Em seguida, indexe novamente os encontros no repositório: 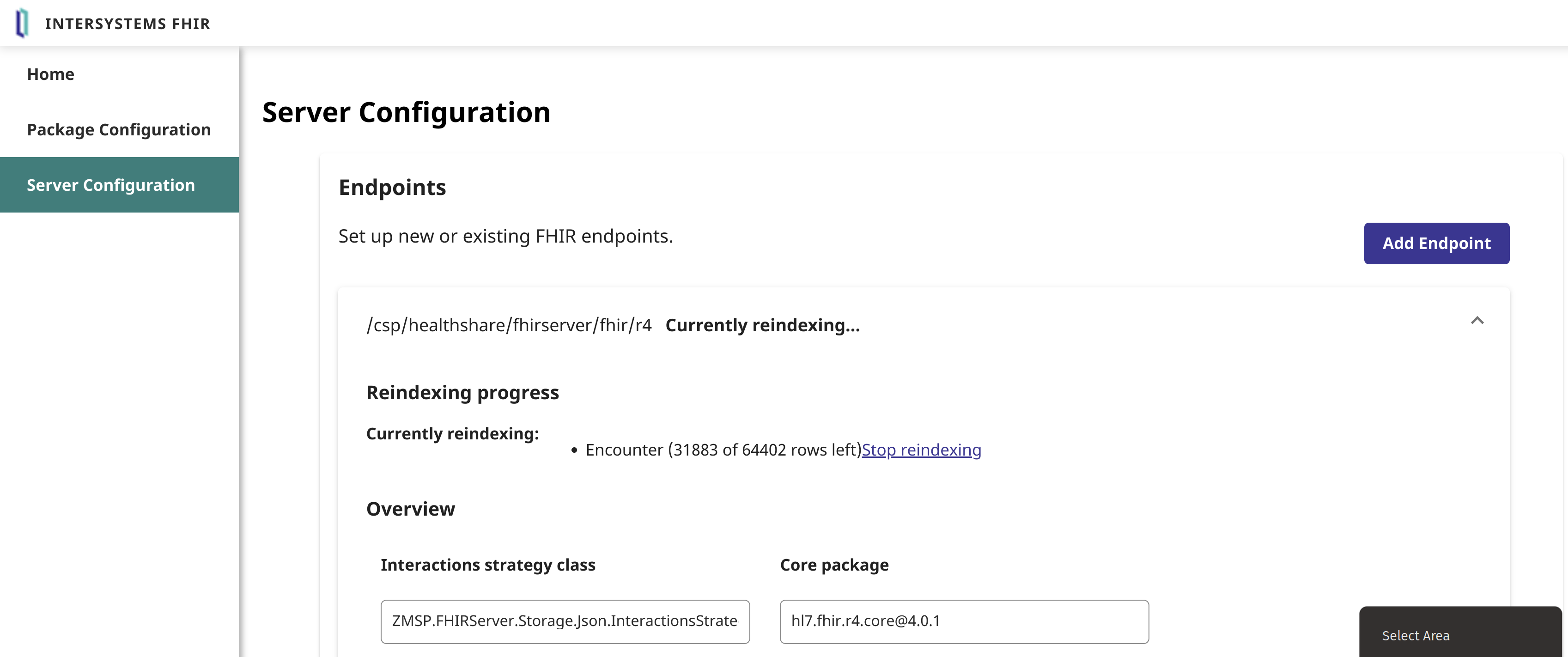
Agora, você já deve ter o parâmetro de pesquisa/pacote carregado no endpoint: 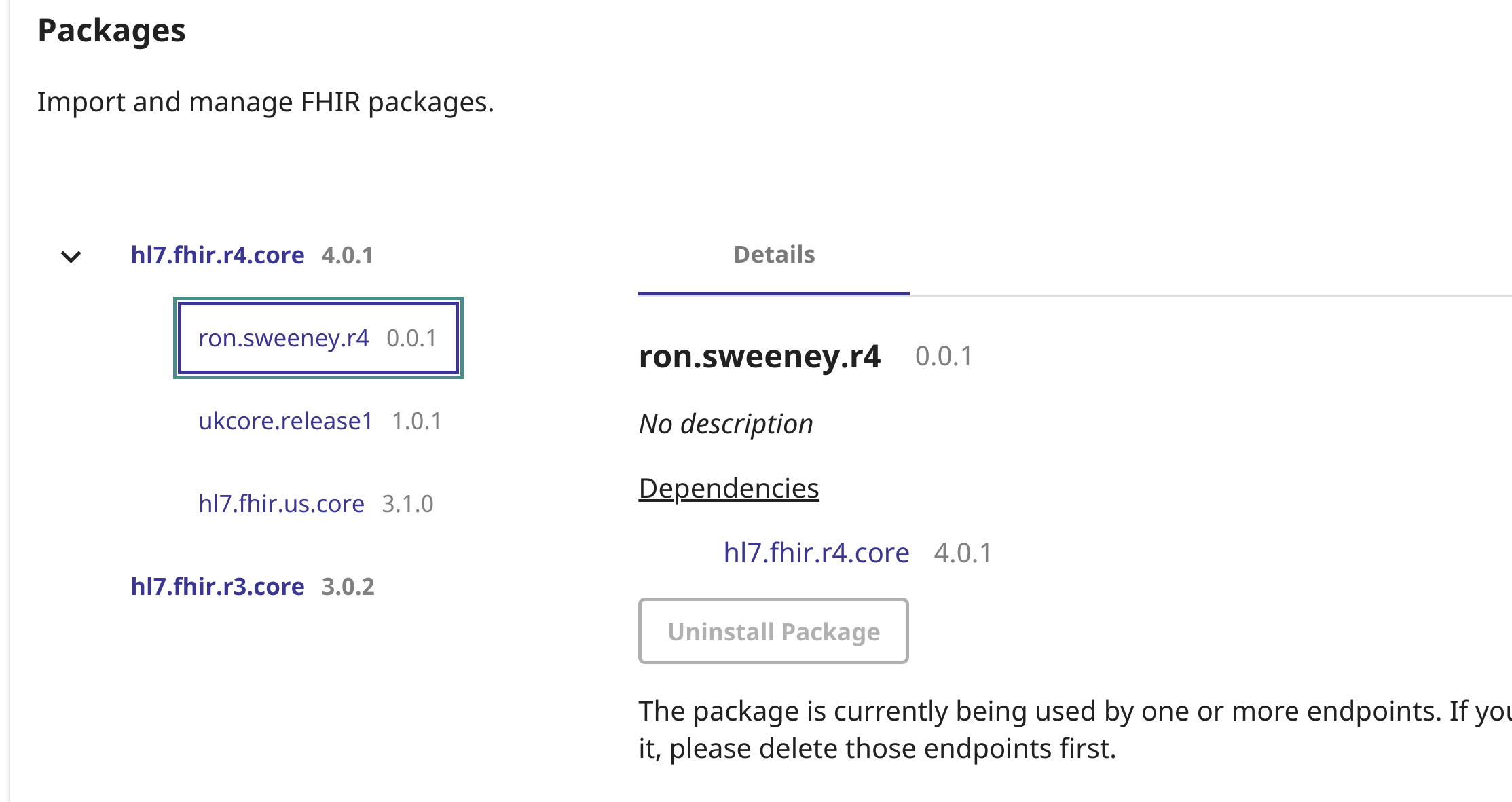
Com o parâmetro de pesquisa carregado, podemos agora usá-lo assim!
`curl https://fhir.ggyxlz8lbozu.workload-prod-fhiraas.isccloud.io/Encounter?dischargeDisposition=hosp`
Enfim, o processo funcionou para nós, e considerar a geração de pacotes pela visão do Python foi uma abordagem muito melhor do que o Synthea às vezes é para conjuntos de dados minuciosos.
O conjunto de dados resultante com que saímos no Domingo está [aqui](https://github.com/sween/soa-bridge-match/tree/feature/connectathon_31/upstream/subjects_35).
Só queria compartilhar a experiência e agradecer às equipes dos projetos por tornarem o que pensei que seria um pesadelo em uma experiência divertida e educativa!