Limpar filtro
Anúncio
Danusa Calixto · Jun. 7, 2023
Olá Comunidade!
Estamos na reta final do nosso 🏆 2º Concurso de Artigos Técnicos em Português da InterSystems 🏆.Restam apenas 5 dias 👀 para o encerramento do prazo de participação do concurso, e em seguida inicia-se o período de votação. Para aqueles que ainda estão elaborando o seu artigo, atenção para não perderem o prazo de publicação que vai até o dia 12 de junho de 2023.
Fiquem ligados no prazo e não percam a chance de participarem! 😉Estamos aguardando por seus artigos.
Boa sorte a todos 🍀
Artigo
Larissa Prussak · Jun. 30
Olá, desenvolvedores!
Observando a avalanche de ferramentas para desenvolvedores movidas por IA e baseadas em vibe-coding que vêm surgindo quase todo mês, com recursos cada vez mais interessantes, eu fiquei me perguntando se seria possível aproveitá-las com o InterSystems IRIS. Pelo menos para construir um frontend. E a resposta é: sim! Pelo menos com a abordagem que eu segui.
Aqui está minha receita para construir a interface via prompting conectada ao backend IRIS:
Tenha uma REST API no lado do IRIS, que siga uma especificação Open API (swagger).
Gere a interface com alguma ferramenta de vibe-coding (por exemplo, Lovable) e aponte essa interface para o endpoint da REST API.
Pronto!
Aqui está o resultado do meu próprio exercício — uma interface 100% criada via prompt conectada a uma REST API IRIS, que permite listar, criar, atualizar e excluir registros de uma classe persistente (Open Exchange, código do frontend, vídeo):
Qual é a receita em detalhes?
Como obter a especificação Open API (Swagger) a partir do backend IRIS
Peguei o template com a classe persistente dc.Person, que contém alguns campos simples: Nome, Sobrenome, Empresa, Idade, etc.
Achei que o ChatGPT poderia gerar a especificação Swagger, mas talvez fosse tímido para fazer isso com ObjectScript (embora talvez consiga agora). Então, gerei o DDL da classe pelo terminal do IRIS:
Do $SYSTEM.SQL.Schema.ExportDDL("dc_Sample","*","/home/irisowner/dev/data/ddl.sql")
E passei esse DDL para o ChatGPT junto com o seguinte prompt:
Por favor, crie uma especificação Open API no formato JSON versão 2.0 a partir do seguinte DDL, que permita obter todos os registros e registros individuais, além de criar, atualizar e excluir entradas. Adicione também um endpoint _spec com OperationId GetSpec. Por favor, atribua nomes significativos para todos os operationId dos endpoints. O DDL: CREATE TABLE dc_Sample.Person( %PUBLICROWID, Company VARCHAR(50), DOB DATE, Name VARCHAR(-1), Phone VARCHAR(-1), Title VARCHAR(50) ) GO CREATE INDEX DOBIndex ON dc_Sample.Person(DOB) GO
E funcionou muito bem — aqui está o resultado.
Depois disso, usei a ferramenta de linha de comando %REST para gerar as classes backend.
Em seguida, implementei a lógica da API REST no IRIS usando ObjectScript para os métodos GET, PUT, POST e DELETE. Na maior parte, manualmente 😉, com alguma ajuda do Co-pilot no VSCode.
Testei a REST API manualmente com o swagger-ui e, depois que tudo estava funcionando, fui construir a interface:
A interface foi criada usando a ferramenta Lovable.dev via prompt:
Por favor, crie uma interface moderna e prática a partir da seguinte especificação Open API, que permita listar, criar, atualizar e excluir pessoas { "swagger":"2.0", "info":{ "title":"Person API," "version":"1.0.0" }, ....(passei a especificação completa)
Depois que a interface foi construída e testada (manualmente), pedi para o Lovable direcioná-la para o endpoint da REST API no IRIS. Primeiro localmente via Docker, e depois de alguns testes e correções (também via prompts), o resultado foi publicado.
Algumas observações e lições aprendidas
A segurança da REST API no lado do IRIS não é muito clara de início (principalmente por questões relacionadas ao CORS). Por exemplo, precisei adicionar uma classe especial cors.cls e modificar manualmente a especificação do Swagger para que o CORS funcionasse.
A documentação Swagger não funciona automaticamente em containers Docker no IRIS, mas isso pode ser resolvido adicionando um endpoint _spec e algumas linhas de código em ObjectScript.
A especificação Swagger para IRIS deve ser na versão 2.0, e não na mais recente 3.1.
Fora isso, essa abordagem se mostrou uma forma bastante eficiente para um desenvolvedor backend IRIS construir protótipos de aplicações full-stack completos em muito pouco tempo, mesmo sem conhecimento de frontend.
Compartilhe sua opinião. Qual é a sua experiência com vibe-coding no desenvolvimento com IRIS?
Aqui está o vídeo demonstrativo:
Anúncio
Rochael Ribeiro · Maio 21, 2021
WEBCAST: PLATAFORMA DE DADOS INTERSYSTEMS: O DIFERENCIAL NOS PROJETOS DE DATA FABRIC DO SETOR FINANCEIRO
27 de Maio de 2021Das 11h ás 12h
Inscreva-se agora!
DESTAQUES
Artigo
Thais Pinheiro · Jun. 9, 2023
Durante a pandemia de Covid-19 tornou-se evidente a necessidade de transformação digital na área da saúde e muito foi questionado sobre como aperfeiçoar processos, melhorar gestão de recursos, modernizar e humanizar os atendimentos ao paciente.
Neste tópico abordaremos especificamente a gestão de medicamentos e vacinas, mais especificamente, a perda desses materiais.
De acordo com a Organização mundial de Saúde (OMS), no ano de 2020, pelo menos 25% de todas as vacinas chegaram degradadas aos cidadãos e 50% das vacinas distribuídas podem ser ineficazes, devido ao armazenamento incorreto e falha de refrigeração, entre outras questões de logística, que de modo geral estão relacionadas a baixa temperatura ideal para conservação. E essas perdas custam primordialmente a saúde da população e muito dinheiro.
O cenário pandêmico escancarou nossas necessidades na área da saúde, impulsionando investimentos em tecnologia e inovação. Hoje nosso cenário é favorável para integração do monitoramento da cadeia fria da saúde com IoT (Internet of Things).
OBJETIVO
Este artigo visa abordar conceitos e discussões sobre IoT como apoio a métricas e monitoria de temperatura em refrigeradores de laboratórios da saúde, tais como: Laboratórios de análises clínicas e farmacêuticos. Abordando tecnologias InterSystems e frisando seus benefícios.
DESENVOLVIMENTO
A cadeia fria se trata de um sistema de conservação, manuseio e transporte de produtos com temperatura controlada, dentro da logística de medicamentos e vacinas. Esse modelo é fundamental para garantir qualidade e integridade para o paciente que irá recebê-los.
A IoT abre um leque de possibilidades em nossas casas e cidades, a ideia é trazê-la para o laboratório, entregando uma monitoria IoT para aumentar o potencial de rastrear e restringir as temperaturas dentro desses ambientes controlados, contando com disparo de e-mails, SMS e push notifications. Podemos contar com a possibilidade de incorporar ferramentas de análise de dados a fim de auxiliar possíveis decisões sobre as alterações de temperatura ou identificar possíveis falhas no equipamento de refrigeração.
Em resumo, estaríamos aplicando a tecnologia InterSystems IRIS Data Platform ao desenvolver, executar e manter nossa aplicação para informar através de vários canais, tanto para consumir quanto para enviar dados. Com recursos de integração e analíticos e possuindo um banco de dados multimodelo transacional incorporado, a InterSystems IRIS também será fundamental para armazenar os dados necessários de modo seguro e eficiente.
A plataforma de integração de dados e sistemas, IRIS Interoperability, será nosso componente de mensageria usando o protocolo MQTT (Message Queuing Telemetry Transport) para os disparos de notificações citados anteriormente. O IntegratedML como recurso incorporado da plataforma IRIS InterSystems, escolhido para o gerenciamento dos dados coletados nos refrigeradores para possíveis tomadas de decisões para auxiliar a alteração de temperatura automaticamente quando necessário por meio de análise preditiva e para gerar insights para quando houver falhas nos equipamentos.
Abaixo segue a explicação de cada escolha e o porquê.
MQTT (Message Queuing Telemetry Transport)
É um protocolo de comunicação M2M (Machine to Machine) com foco em IoT que funciona em cima do protocolo TCP. Sua comunicação se baseia entre o cliente que pode realizar tanto postagens quanto captação de informação e o broker que administra os dados a serem recebidos e enviados. Para essa comunicação, usa-se um paradigma chamado publish-subscribe.
Por que MQTT e não outros protocolos?
Criado em 1999 pela IBM para ser usado no setor de petróleo e gás, o MQTT surgiu a partir da necessidade de um protocolo para largura de banda mínima e perda de bateria mínima para monitorar oleodutos via satélite, sendo, dessa forma, um recurso simples, de baixo consumo de dados e que possibilita uma comunicação bilateral.
Por que mensageria e não HTTP?
Para abordar esta questão é preciso iniciar apontando suas diferenças na arquitetura.
O HTTP funciona com um modelo cliente/servidor ou request-response, como exemplifica a figura abaixo, enquanto o MQTT funciona por meio de publicações e assinaturas de um tópico (publish-subscriber).
No MQTT a conexão é mantida e pings podem ser compartilhados para mantê-la aberta, já o HTTP cria uma conexão apenas quando uma solicitação necessita ser enviada.
E, por fim, é válido acrescentar que o HTTP mantém uma conexão TCP half-duplex (transmissões são realizadas nos dois sentidos da comunicação, mas alternadamente, nunca simultâneas) enquanto o MQTT mantém uma full-duplex (transmissões são simultâneas, um dispositivo pode transmitir informação ao mesmo tempo que a recebe), permitindo comunicações assíncronas entre os serviços para que os mesmos não esperem a resposta do serviço de recebimento, sendo um modelo necessário para mensageria.
Além das diferenças apontadas acima, a mensageria torna a aplicação escalável, visto que o modelo publish-subscriber oferece suporte à mudança de números de serviços.
Após essa breve explicação, podemos dizer que o MQTT é muito mais otimizado para esse cenário em comparação ao HTTP em taxa de transferência, consumo de bateria e largura de banda, tornando-se uma melhor opção para a maioria das aplicações IoT e sendo reconhecido como o padrão de mercado de mensageria nesse contexto.
O IRIS Interoperability, uma plataforma de integração de dados e sistemas, desempenha um papel fundamental como broker para este protocolo e no cenário descrito deste artigo. Ele permite que os dispositivos IOT publiquem mensagens em tópicos específicos, neste caso o tópico de monitoria de temperatura, e também que a aplicação faça um subscribe para receber as mensagens. O IRIS fornece extensões integradas para usar o MQTT.
InterSystems IntegratedML
O AutoML (Automated Machine Learning) é um recurso que surge como opção para o uso do ML (Machine Learning) para desenvolvedores com conhecimento em SQL, mas pouco ou nenhum em ML. Com ele é possível automatizar a criação, treinamento e implementação do aprendizado de máquina, a organização que opta por sua utilização pode poupar tempo e esforço significativos de sua equipe de cientistas de dados, visto que o AutoML abstrai os detalhes e conhecimentos especializados exigidos.
Certo! Mas onde entra o InterSystems IntegratedML?
IntegratedML (Integrated Machine Learning) se trata de um recurso integrado da plataforma de dados InterSystems IRIS que simplifica e fornece recursos AutoML, permitindo o uso de funções automatizadas diretamente do SQL para gerar e manusear modelos preditivos. Sua inclusão ao IRIS permite uma execução dinâmica, atuando em tempo real diretamente nos dados, sem extrair ou mover quaisquer modelos ou bases.
Para exemplificar sua funcionalidade, assume-se que, “no Brasil todo mês de janeiro é quente” e que teremos registros de aproximadamente três anos armazenados na base de dados, obtida por estações meteorológicas. É importante que para essa exemplificação tenhamos em mente que os dados foram preparados e estamos desconsiderando informações abrangentes como mudanças climáticas.
A partir dessa premissa, é necessário treinar nosso modelo para que, ao iniciar cada mês de janeiro, as temperaturas tendem a ser mais elevadas, portanto deve reduzir em 1°C (grau Celsius) a temperatura. Se a temperatura externa aumentar, demanda-se que o sistema de refrigeração seja acionado, resfriando o ambiente interno, mantendo temperaturas indicadas pelos fabricantes e mantendo a integridade dos insumos ali armazenados. Junto ao IRIS, o IntegratedML “automatiza o trabalho básico, como identificar os modelos mais apropriados, definir parâmetros e construir e treinar modelos” e permite melhorias contínuas dos modelos de ML.
O objetivo aqui é criar e implantar modelos de aprendizagem de máquina com um menor esforço, no sentido de não precisar de especialistas para começar aplicar as funcionalidades necessárias de ML, complementar o trabalho do time e dedicar tempo a melhorias e suporte à aplicação e análises. Após a preparação dos dados e criação do modelo, o IntegratedML será responsável por gerenciar os dados coletados dos refrigeradores para auxiliar às possíveis tomadas de decisões, assim como, após o treinamento do modelo, deve ser capaz de ajustar a temperatura de forma automática quando necessário, por meio de análise preditiva, além de gerar insights em caso de falhas nos equipamentos.
A seguir, apresentamos uma imagem ilustrativa da nossa arquitetura e onde o IntegratedML, IRIS Interoperability e o MQTT estão sendo aplicados.
CONCLUSÃO
Mesmo tendo outras soluções disponíveis no mercado, há muitas razões pelas quais aplicar tecnologias InterSystems ao IoT podem ser benéficas. A InterSystems é reconhecida na área da saúde, principalmente pelos produtos InterSystems IRIS for Health e o InterSystems TrakCare, e oferece recursos robustos de integração, permitindo conexão e comunicação eficiente entre diferentes sistemas e dispositivos, flexibilidade, escalabilidade, conformidade. A sua interoperabilidade pode simplificar a implantação e gerenciamento de um sistema abrangente.
É interessante ressaltar que a mesma lógica pode ser aplicada em outros segmentos além dos laboratórios de saúde, como os refrigeradores industriais. Porém, aplicando regras de ML específicas para o uso industrial.
REFERÊNCIAS
Aprendizagem e Análise de Máquina - Plataforma de Análise de Big Data. InterSystems. Disponível em <https://www.intersystems.com/br/sistema-de-gerenciamento-de-banco-de-dados/grande-analise-de-dados/> Acesso em 24 de maio de 2023.
Desperdício de medicamentos: como evitar perdas. NEXXTO, 2022. Disponível em <https://www.linkedin.com/pulse/desperd%C3%ADcio-de-medicamentos-como-evitar-perdas-nexxto/?trk=organization-update-content_share-article> Acesso em 16 de maio de 2023.
Gestão de Bases de Dados. InterSystems. Disponível em <https://www.intersystems.com/br/sistema-de-gerenciamento-de-banco-de-dados/gestao-de-bases-de-dados/> Acesso em 19 de maio de 2023.
Introduction to IntegratedML. InterSystems. Disponível em <https://docs.intersystems.com/irisforhealthlatest/csp/docbook/DocBook.UI.Page.cls?KEY=GIML_Intro>
Acesso em 29 de maio de 2023.
IoT with InterSystems IRIS. Marx Y., 2023. Disponível em <https://community.intersystems.com/post/iot-intersystems-iris> Acesso em 20 de maio de 2023.
Implementation of IoT based Smart Laboratory. M. Poongothai, 2018. Disponível em <https://www.researchgate.net/publication/327723745_Implementation_of_IoT_based_Smart_Laboratory> Acesso em 20 de maio de 2023.
Interoperabilidade - Integração Potente e Flexível com InterSystems IRIS. InterSystems. Disponível em <https://www.intersystems.com/br/sistema-de-gerenciamento-de-banco-de-dados/interoperabilidade/> Acesso em 19 de maio de 2023.
InterSystems IntegratedML - Aprendizagem da máquina facilitada. Intersystems. Disponível em <https://www.intersystems.com/br/solucoes/integratedml/> Acesso em 20 de maio de 2023.
IoT Sample. GOMES Y. , 2023. Disponível em <https://openexchange.intersystems.com/package/IoT-Sample> Acesso em 01 de junho de 2023.
MQTT: Get started with IoT protocols. Sola R., 2016. Disponível em <https://www.opensourceforu.com/2016/11/mqtt-get-started-iot-protocols/> Acesso em 24 de maio de 2023.
Machine Learning Made Easy: InterSystems IntegratedML. InterSystems. Disponível em <https://www.intersystems.com/resources/machine-learning-made-easy-intersystems-integratedml/> Acesso em 20 de maio de 2023.
"MQTT vs HTTP: ¿qué protocolo es mejor para IoT?". H. Angel, 2020. Disponível em <https://borrowbits.com/2020/04/mqtt-vs-http-que-protocolo-es-mejor-para-iot/> Acesso em 24 de maio de 2023
"O que é MQTT?". Amazon. Disponível em <https://aws.amazon.com/pt/what-is/mqtt/> Acesso em 24 de maio de 2023.
Talk2Lab: The Smart Lab of the Future. IEEE, 2020. Disponível em <https://ieeexplore.ieee.org/abstract/document/9094640> Acesso em 20 de maio de 2023. Parabéns pelo excelente artigo! Parabéns!!! Sucinto e objetivo. Parabéns!!! Excelente trabalho. Excelente artigo! Eu trabalho com arquitetura orientada a eventos, e foi muito interessante ver como os serviços de mensageria pode ser utilizado pra outras finalidades. Sem falar da grande integração com as ferramentas da InterSystems. Muito obrigada, Filipe! Muito obrigada! A ideia era ser mesmo objetivo, pois é uma comunidade de tecnologia, então descarta algumas introduções nos temas apresentado e vai direto ao ponto. Muito obrigada, fico feliz que tenha gostado da leitura. Muito obrigada pelas palavras, fico muito feliz em saber que estou entregando valor com este artigo e que tenha gostado de como abordei o tema e as ferramentas da InterSystems. Muito bom o artigo. Parabéns! Muito legal!!! Parabéns!
Aliás, quando vc terminar a graduação, vamos participar do mestrado na FAMERP? Começa com a Disciplina Inovação e Empreendedorismo na Saúde. Topa???
Oi Thaís! Parabéns pelo seu artigo, ficou objetivo, técnico e interessante. Independente de prêmio, você realizou um excelente trabalho. Excelente…artigo muito bem elaborado Uau! Meus parabéns Thais! Este artigo ficou show de bola! Você pretende continuar este trabalho após a sua formatura? Parabéns Thais ótimo artigo. Oi Thaís ... parabéns pelo artigo.. Orgulho! Boa sorte! muito bom!! Parabéns @Thais.Pinheiro Excelente artigo Thais, muito bem elaborado e interessante! Excelente artigo Thais, acompanhei de perto o manuseio de vacinas e medicamentos que necessitam de refrigeração,é realmente muito falho esse controle. interessante demais conhecer esse a tecnologia... Sucesso 🙏 Parabéns pelo artigo @Thais.Pinheiro , excelente trabalho. Muito obrigada! Fico muito lisonjeada pelo convite e agradeço muitíssimo, é uma ótima oportunidade. Vou pensar com carinho e volto a falar com a senhora. Muito obrigada, Márcio! Admiro-o muito, então para mim é muito gratificante que tenha gostado. Obrigada, Mariangela! Muito obrigada, Lucimar! No momento tenho em mente trabalhar esse tema no meu TG para realizar a parte prática. Se tudo der certo acredito que eu dê continuidade, sim. Obrigada, Katia! Olá! Muito obrigada, Adriana. Fico honrada de ver a senhora por aqui. Uma professora que tenho um carinho enorme. Muito obrigada, Taciana! Fico feliz que tenha gostado. Muito obrigada, Laura! Agradeço pela leitura e fico feliz que tenha gostado. Muito obrigada, Cristiane! Conversei com algumas pessoas da área e elas comentaram sobre o gerenciamento de algumas vacinas, o que reforçou ainda mais para mim que foi um tema legal. Que bom que gostou e agradeço novamente. Muito obrigada, Marcio! Agradeço pela leitura e fico feliz que tenha gostado. Muito obrigada, Lucas! Parabéns pelo artigo, Thais! Parabéns pelo artigo!!! Great article Thais. Very complete and useful! Congratulations! Muito bom seu artigo, parabéns. Parabéns, excelente artigo!
Bem claro e objeto! Muito obrigada, fico contente que tenha gostado. Muito obrigada, Reginaldo! Obrigada, Felicio! Muito obrigada, Daniele!
29 Postagens•0 Seguidores
Anúncio
Olga Zavrazhnova · Dez. 14, 2020
Olá Desenvolvedores,
Nós lhes convidamos para pegar alguns minutinhos de seu dia e deixar uma avaliação de sua experiência com nossa plataforma de dados InterSystems IRIS no TrustRadius. Sabemos que enviar sua avaliação requer tempo e esforço e então ficaremos felizes em recompensá-lo com um cartão presente no valor de US$ 25,00 pela avaliação publicada.
Para ganhar o cartão presente da InterSystems siga os seguintes passos:
✅ #1: Clique → neste link ← para submeter sua avaliação (selecione o botão "Start My Review").
✅ #2: Sua avaliação terá um título. Copie o texto do título de sua avaliação e cole ele neste desafio no Global Masters.
✅ #3: Depois que sua avaliação for publicada você receberá o cartão presente VISA no valor de US$25,00 e 3000 pontos no Global Masters.
Observações:
O TrustRadius deve aprovar a avalição para que você esteja qualificado para receber o cartão presente. O TrustRadius não irá aprovar avaliações derevendedores, integradores de sistemas ou MSP / ISVs da InterSystems.
O TrustRadius não aprovará as avaliações que estiverem sido previamente publicadas online.
Feito? Excelente! Seu cartão presente estará a caminho!
Artigo
Fernando Ferreira · Mar. 25, 2021
Olá comunidade,
Nesta 4ª parte vamos falar de uma funcionalidade do InterSystems IRIS Reports chamada de “Bursting”. Vamos primeiro relembrar o que já vimos até o momento.
Entendemos o que é o InterSystems IRIS Reports, instalamos os ambientes: Designer e Server, verificamos os diversos tipos e formatos de relatórios que podemos desenvolver, e entendemos como distribuir um relatório em diversos formatos.
Mas afinal o que é o “Bursting”? Antes de demonstrar está funcionalidade em ação, vamos primeiro refletir sobre a sua necessidade.
Todos nós já nos deparamos com necessidade de processar relatórios com milhares de linhas, e este tipo de relatório normalmente tem um alto custo de processamento no banco de dados com milhares de linhas que não são destinadas a um único usuário, você precisa segregar as informações por região, por alguma categoria seja de produto ou um tipo de exame, ou por alguma hierarquia existente para o seu tipo de negócio. Sem o InterSystems IRIS Reports, você precisaria desenvolver uma ou mais queries aplicando técnicas para filtrar dados com as opções de “filtro” que usuário precisa ou pode ter acesso, e podem ocorrer mais de uma execução por diversos usuários ao longo do dia.
Vamos pegar como exemplo a fonte de dados que estamos usando para esta nossa jornada de conhecimento do InterSystems IRIS Reports. Estamos usando uma base de dados disponível no Kaggle. A base é da Olist, são informações de e-commerce de diversos marketplaces. Neste exemplo determinamos que cada categoria de produto possui um vendedor responsável e precisamos enviar informações para os responsáveis segregando os dados por categoria.
Agora você me pergunta? Então está funcionalidade “Bursting” serve para fazer uma “explosão”, “segregação” de um grande relatório para diversos destinatários? Sim você está certo!
Eu particularmente adoro essa funcionalidade, porque acabamos reduzindo custo de desenvolvimento, reduzindo custo de processamento do banco de dados, nos proporciona a facilidade e a distribuição de relatórios de forma automatizada, ou seja, deixamos todos “stakeholders” dos processos satisfeitos!
Então vamos automatizar o posicionamento de vendas para todas as regiões da sua empresa? Ou automatizar envio de bilhetagem? Qual a sua necessidade de segregação e automatização de relatórios?
Bom vamos colocar então a mão na massa desta funcionalidade: “Bursting”!
Vamos começar com alguns conceitos do “Bursting”:
Bursting Schema
É onde definimos como vamos fazer a divisão dos dados. Para fazer a divisão dos dados precisamos dentro do “bursting Schema” definir o “bursting key” e o “bursting recipientes”.
Bursting key: É um ou mais campos onde o definimos uma chave para que possa ocorrer a segregação dos dados, como exemplo vamos usar a base de dados que estamos utilizando neste tutorial. Temos uma tabela chamada produto e nela temos o campo: product_category_name. Através deste campo definimos o time de vendas responsável em acompanhar o status dos pedidos com os valores sumarizados, portanto, este campo será o nosso “bursting key”.
Bursting recipientes: É a tabela que contêm os campos com as informações dos destinatários que receberam os relatórios. É mandatório que exista o campo que será relacionado com o “bursting key”, no nosso caso é a product_category_name. Para nosso exemplo criamos uma tabela chamada comercial, onde nela contém os campos:
productcategoryname / folderdestino / emaildestino
Como podemos perceber temos o campo que será feito o relacionamento com a tabela produto e mais dois campos. O campo folderdestino contêm o caminho do servidor onde os arquivos do relatório serão distribuídos e o campo emaildestino contêm o e-mail do destinatário que receberá o e-mail. O Bursting também permite a distribuição dos relatórios via FTP. No nosso exemplo vamos distribuir os relatórios por e-mail e na pasta do servidor.
Um passo importante para que possamos criar o “Bursting” é relembrar um passo que fizemos na 3ª parte deste. Precisamos criar uma query onde vamos ter o relacionamento entre a tabela que contém o bursting key e com a tabela Bursting recipientes.
Vamos para o primeiro passo. Como base vamos utilizar o relatório que contém as todas as vendas sumarizadas por categoria:
1º - Dentro do designer, na barra superior clicar em Report, e em seguida clique na opção Bursting.
2º - Clique em: Enable Bursting Report. É possível mudar o nome do Bursting Schema, aqui vamos manter o padrão.
3º - Agora vamos fazer o Mapping do Bursting Key com o Bursting recipientes.
4º - No campo Dataset, carrega automaticamente o Query que está sendo utilizada no relatório, abaixo temo como escolher o campo do bursting key, aqui vamos selecionar o campo que estamos utilizando neste tutorial: product_category_name.
5º - Em Recipient, Data Source, é onde escolhemos a query criada onde possui a relação entre as tabelas do Bursting Key com o Bursting recipientes.
6º - No campo Recipient Mapping Identifier, é onde vamos selecionar o campo que fará o relacionamento com o Bursting Key.
7º - Em Recipient escolhemos os campos onde contém o conteúdo do destinatário do e-mail e da pasta destino.
8º - Opcionalmente pode clicar em E-mail Settings para colocar o assunto do e-mail, informar algum comentário, ou até mesmo selecionar o campo Cc ou Bcc.
9º Agora é só publicar o relatório para o servidor! Lembra deste passo? Fizemos isto na 3ª parte deste artigo, caso não lembre, dá uma passadinha lá!
Agora que o relatório está publicado no servidor, vamos colocar o nosso “Bursting” para trabalhar. Para executar o relatório com está funcionalidade precisamos criar um agendamento no servidor para execução. Já fizemos este tipo de agendamento na 3ª parte deste artigo, mas nesta etapa teremos algumas parametrizações adicionais, segue:
1º Selecionar o relatório e clicar na opção de agendamento.
2º Em Schedule Name, é opcional dar um nome para o agendamento.
3º Em Select Report Tabs, aqui uma opção nova: Select bursting reports, vamos selecionar está opção.
4º Em Report Tab Name, selecionar o relatório onde foi parametrizado nossa funcionalidade.
5º Em Bursting Configuration, escolher o relatório e o Bursting Schema criado no passo anterior.
6º Na aba superior clicar em Publish.
7º Em Bursting Result temos duas opções: To Disk e To E-mail. Aqui uma observação importante parametrizamos o Bursting com duas possibilidades de publicação, para pasta e para e-mail, ou seja, podemos criar agendamentos distintos ou no mesmo agendamento fazer a explosão para os dois destinos. Aqui neste tutorial vamos criar um único agendamento com a explosão para os dois destinos.
8º Em ToDisk, clique em Publish to Disk, agora temos a opção de diversos formatos de geração do relatório, para disco, vamos criar no formato TXT, após clicar em TXT, vamos dar o nome para o relatório e podemos escolher opção o formato da delimitação do TXT.
9º Em ToEmail, clique em Publish to E-mail, e podemos escolher o formato do relatório, para a opção e-mail vamos gerar em PDF, e ao selecionar a opção PDF, vamos dar o nome do arquivo que será gerado.
10º Na aba Conditions podemos escolher o horário e a periodicidade que o relatório será executado, no nosso tutorial vamos usar a opção: Run this task immediately.
11º - Em Notification podemos selecionar um destinatário de e-mail para quando o agendamento executado com sucesso e outro e-mail em caso de falha.
Agora é só clicar em Finish, e verificar resultado do relatório.
Resultado em disco: podemos observar que para cada Bursting Key foi criada uma pasta com o respectivo nome com o relatório gerado:
E aqui o resultado no e-mail:
Obrigado e até a próxima parte!
Anúncio
Angelo Bruno Braga · Abr. 7, 2022
Olá Desenvolvedores.
Ainda não tirou um tempinho para escrever seu artigo para o 1º Concurso de Artigos Técnicos em Português da InterSystems ?
Essa é a hora ! Além de concorrer aos prêmios já anunciados para o concurso, inscrevendo seu artigo no concurso você estará participando automaticamente do sorteio de um ingresso para o Global Summit 2022 da InterSystems que ocorrerá do dia 20 ao dia 23 de junho em Seattle !!!
Esperamos ansiosamente seus artigos !
Boa sorte a todos !!! Olá Desenvolvedores.
Corram que ainda dá tempo ! Já se imaginaram participando do Global Summit da InterSystems??Essa é a chance!
Anúncio
Rochael Ribeiro · Jun. 6, 2022
Olá Desenvolvedores,
Este novo vídeo já se encontra no Canal YouTube dos Desenvolvedores InterSystems:
⏯ Solução Analítica InterSystems HealthShare: Crie e Entregue Análises em Tempo Real em Escala
Muitas organizações orientadas a dados precisam construir fontes de informações confiáveis de alta qualidade, normalizadas e validadas. Aprenda como a Solução Analítica InterSystems HealthShare permite que sua organização consolide e harmonize seus dados em escala, a partir de fontes distintas, em tempo real, permitindo colaboração entre todas as áreas e com entidades externas, mantendo o controle de seus dados.
🗣 Apresentador: Fred Azar, Healthcare Analytics Executive, InterSystems
Curta e compartilhe !
Artigo
Danusa Calixto · Dez. 15, 2022
Nesta série de artigos, quero apresentar e discutir várias abordagens possíveis para o desenvolvimento de software com tecnologias da InterSystems e do GitLab. Vou cobrir tópicos como:
* Git básico
* Fluxo Git (processo de desenvolvimento)
* Instalação do GitLab
* Fluxo de trabalho do GitLab
* Entrega contínua
* **Instalação e configuração do GitLab**
* CI/CD do GitLab
No [primeiro artigo](https://community.intersystems.com/post/continuous-delivery-your-intersystems-solution-using-gitlab-part-i-git), abordamos os fundamentos do Git, por que um entendimento de alto nível dos conceitos do Git é importante para o desenvolvimento de software moderno e como o Git pode ser usado para desenvolver software.
No [segundo artigo](https://community.intersystems.com/post/continuous-delivery-your-intersystems-solution-using-gitlab-part-ii-gitlab-workflow), abordamos o fluxo de trabalho do GitLab: um processo inteiro do ciclo de vida do software e a entrega contínua.
Neste artigo, vamos discutir:
* Instalação e configuração do GitLab
* Conexão dos seus ambientes ao GitLab
## Instalação do GitLab
Vamos instalar o GitLab no local. Há várias maneiras de instalar o GitLab — da fonte, pacote, em um contêiner. Não descreverei todos os passos aqui, há um [guia para isso](https://about.gitlab.com/installation/). Ainda assim, algumas observações.
Pré-requisitos:
* Servidor separado — como é um web application e um recurso bastante intensivo, é melhor executar em um servidor separado
* Linux
* (Opcional, mas altamente recomendável) Domínio — necessário para executar páginas e proteger a configuração inteira
### Configuração
Primeiro de tudo, você provavelmente precisa enviar [e-mails com notificações](https://docs.gitlab.com/omnibus/settings/smtp.html).
Em seguida, recomendo [instalar Páginas](https://docs.gitlab.com/ce/administration/pages/index.html). Como discutido no artigo anterior — artefatos do script podem ser enviados para o GitLab. O usuário pode fazer o download deles, mas é útil poder abri-los diretamente no navegador e, para isso, precisamos de páginas.
Por que você precisa de páginas:
* Para mostrar uma página wiki gerada ou estática para seu projeto
* Para mostrar artefatos html
* [Outras coisas que você pode fazer com páginas](https://docs.gitlab.com/ce/user/project/pages/#explore-gitlab-pages)
Como as páginas html podem ter um redirecionamento onload, elas podem ser usadas para enviar o usuário para onde precisamos. Por exemplo, veja este código que gera uma página html que envia um usuário para o último teste de unidade executado (no momento da geração do html):
ClassMethod writeTestHTML()
{
set text = ##class(%Dictionary.XDataDefinition).IDKEYOpen($classname(), "html").Data.Read()
set text = $replace(text, "!!!", ..getURL())
set file = ##class(%Stream.FileCharacter).%New()
set name = "tests.html"
do file.LinkToFile(name)
do file.Write(text)
quit file.%Save()
}
ClassMethod getURL()
{
set url = "http://host:57772"
set url = url _ $system.CSP.GetDefaultApp("%SYS")
set url = url_"/%25UnitTest.Portal.Indices.cls?Index="_ $g(^UnitTest.Result, 1) _ "&$NAMESPACE=" _ $zconvert($namespace,"O","URL")
quit url
}
XData html
{
If you are not redirected automatically, follow this link to tests.
}
Encontrei um bug usando as páginas (erro 502 ao procurar artefatos), [veja aqui a correção](https://gitlab.com/gitlab-com/infrastructure/issues/3064).
###
## Conexão dos seus ambientes ao GitLab
Para executar scripts de CD, você precisa de ambientes, servidores configurados para executar seu aplicativo. Presumindo que você tem um servidor Linux com o produto InterSystems instalado (digamos InterSystems IRIS, mas funciona também com o Caché e Ensemble), estas etapas conectam o ambiente ao GitLab:
1. [Instalar o runner do GitLab](docs.gitlab.com/runner/)
2. [Registrar o runner com o GitLab](https://docs.gitlab.com/runner/register/index.html)
3. Permitir que o runner chame o InterSystems IRIS
**Observação importante** sobre a instalação do runner GitLab, NÃO clone servidores após instalar o runner do GitLab. Os resultados são imprevisíveis e muito indesejados.
### Registrar o runner com o GitLab
Após executar o inicial:
sudo gitlab-runner register
você verá vários prompts e, embora a maioria das etapas seja bastante direta, várias não são:
**Insira o token gitlab-ci para este runner**
Há vários tokens disponíveis:
* Um para o sistema inteiro (disponível nas configurações de administração)
* Um para cada projeto (disponível nas configurações do projeto)
Conforme você conecta um runner para executar a CD para um projeto específico, você precisa especificar um token para este projeto.
**Insira as tags gitlab-ci para este runner (separadas por vírgulas):**
Na configuração de CD, você pode filtrar quais scripts vão ser executados em quais tags. Então, no caso mais simples, especifique uma tag, que seria o nome do ambiente.
**Insira o executor: ssh, docker+machine, docker-ssh+machine, kubernetes, docker, parallels, virtualbox, docker-ssh, shell:
docker**
Se você estiver usando o servidor habitual sem docker, escolha shell. O Docker será discutido nas partes posteriores.
### Permitir que o runner chame o InterSystems IRIS
Depois de conectar o runner ao GitLab, precisamos permitir que ele interaja com o InterSystems IRIS, para isso:
1. O usuário **gitlab-runner** precisa conseguir chamar csession. Para fazer isso, adicione-o ao grupo cacheusr:
* usermod -a -G cacheusr gitlab-runner
2. [Crie](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GSQL_privileges) o usuário **gitlab-runner** no InterSystems IRIS e dê a ele funções para realizar tarefas de CD (escreva para DB, etc.)
3. [Permitir a autenticação no nível do SO](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GCAS_intro_authe_os)
Para 2 e 3, outras abordagens podem ser usadas, como a transmissão de usuário/código, mas acho que a autenticação de SO é preferível.
## Conclusão
Nesta parte:
* GitLab instalado
* Ambientes conectados ao GitLab
Links
* [Instruções de instalação](https://about.gitlab.com/installation/)
* [Páginas](https://docs.gitlab.com/ce/administration/pages/index.html)
* [Runner](docs.gitlab.com/runner/)
* [Parte I: Git](https://pt.community.intersystems.com/post/entrega-cont%C3%ADnua-de-sua-solu%C3%A7%C3%A3o-intersystems-usando-gitlab-%E2%80%93-parte-i-git)
* [Parte II: fluxo de trabalho do GitLab](https://pt.community.intersystems.com/post/entrega-cont%C3%ADnua-de-sua-solu%C3%A7%C3%A3o-intersystems-usando-gitlab-%E2%80%93-parte-ii-fluxo-de-trabalho-do)
O que vem a seguir
Na próxima parte, escrevemos nossa configuração de entrega contínua.
Artigo
Danusa Calixto · Nov. 9, 2022
Nesta série de artigos, quero apresentar e discutir várias abordagens possíveis para o desenvolvimento de software com tecnologias da InterSystems e do GitLab. Vou cobrir tópicos como:
* Git básico
* Fluxo Git (processo de desenvolvimento)
* Instalação do GitLab
* **Fluxo de trabalho do GitLab**
* **Entrega contínua**
* Instalação e configuração do GitLab
* CI/CD do GitLab
No [artigo anterior](https://pt.community.intersystems.com/post/entrega-cont%C3%ADnua-de-sua-solu%C3%A7%C3%A3o-intersystems-usando-gitlab-%E2%80%93-parte-i-git), abordamos os fundamentos do Git, por que um entendimento de alto nível dos conceitos do Git é importante para o desenvolvimento de software moderno e como o Git pode ser usado para desenvolver software. Ainda assim, nosso foco foi na parte da implementação do desenvolvimento de software, mas esta parte apresenta:
* **Fluxo de trabalho do GitLab** — um processo completo do ciclo de vida do software, desde a ideia até o feedback do usuário
* **Entrega Contínua** — uma abordagem de engenharia de software em que as equipes produzem software em ciclos curtos, garantindo que o software possa ser lançado de forma confiável a qualquer momento. Seu objetivo é construir, testar e lançar software com mais rapidez e frequência.
## Fluxo de trabalho do GitLab
O [fluxo de trabalho do GitLab](https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/) é uma sequência lógica de possíveis ações a serem tomadas durante todo o ciclo de vida do processo de desenvolvimento de software.
O fluxo de trabalho do GitLab leva em consideração o fluxo do GitLab, que discutimos em um artigo anterior. Veja como funciona:
1. Ideia: todas as novas propostas começam com uma ideia.
2. Problema: a maneira mais eficaz de discutir uma ideia é criar um problema para ela. Sua equipe e seus colaboradores podem ajudar você a aprimorar e melhorar a ideia no rastreador de problemas.
3. Plano: quando a discussão chega a um acordo, é hora de programar. Porém, primeiro, precisamos priorizar e organizar nosso fluxo de trabalho ao atribuir problemas a marcos e quadro de problemas.
4. Código: agora estamos prontos para escrever nosso código, já que está tudo organizado.
5. Commit: depois de satisfeitos com o rascunho, podemos enviar nosso código para um feature-branch com controle de versão. O fluxo do GitLab foi explicado em detalhes no artigo anterior.
6. Teste: executamos nossos scripts usando o CI GitLab, para construir e testar nosso aplicativo.
7. Revisão: assim que nosso script funcionar e nossos testes e compilações forem bem-sucedidos, estamos prontos para que nosso código seja revisado e aprovado.
8. Staging: agora é hora de implantar nosso código em um ambiente de staging para verificar se tudo funciona como esperado ou se ainda precisamos de ajustes.
9. Produção: quando tudo estiver funcionando como deve, é hora de implantar no nosso ambiente de produção!
10. Feedback: agora é hora de olhar para trás e verificar qual etapa do nosso trabalho precisa ser melhorada.

Novamente, o processo em si não é novo (ou exclusivo do GitLab) e pode ser alcançado com outras ferramentas da sua escolha.
Vamos discutir várias dessas etapas e o que elas implicam. Também há [documentação](https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/) disponível.
### Problema e plano
As etapas iniciais do fluxo de trabalho do GitLab são centradas em um **problema**: um recurso, bug ou outro tipo de trabalho semanticamente separado.
O problema tem várias finalidades, como:
* Gerenciamento: um problema tem data de vencimento, pessoa designada, tempo gasto e estimativas, etc. para ajudar a monitorar a resolução do problema.
* Administrativo: um problema faz parte de um marco, quadro kanban, que nos permite rastrear nosso software à medida que ele avança de versão para versão.
* Desenvolvimento: um problema tem uma discussão e commits associados a ele.
A etapa de planejamento nos permite agrupar os problemas por prioridade, marco, quadro kanban e ter uma visão geral disso.
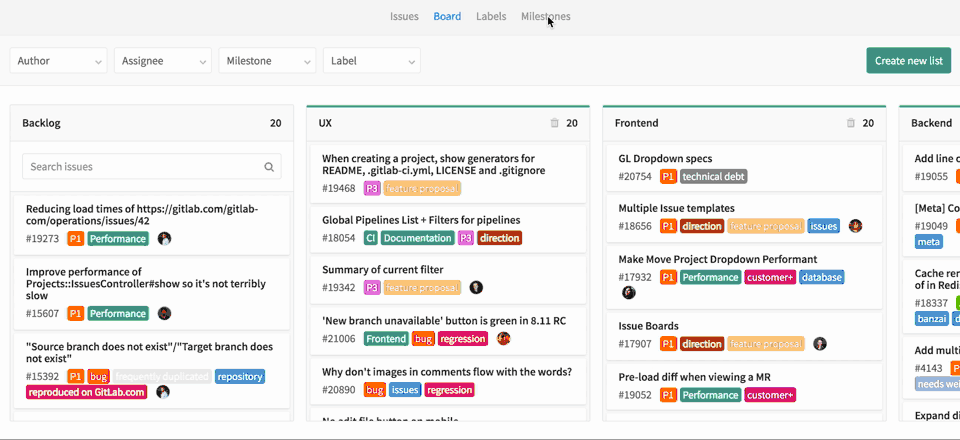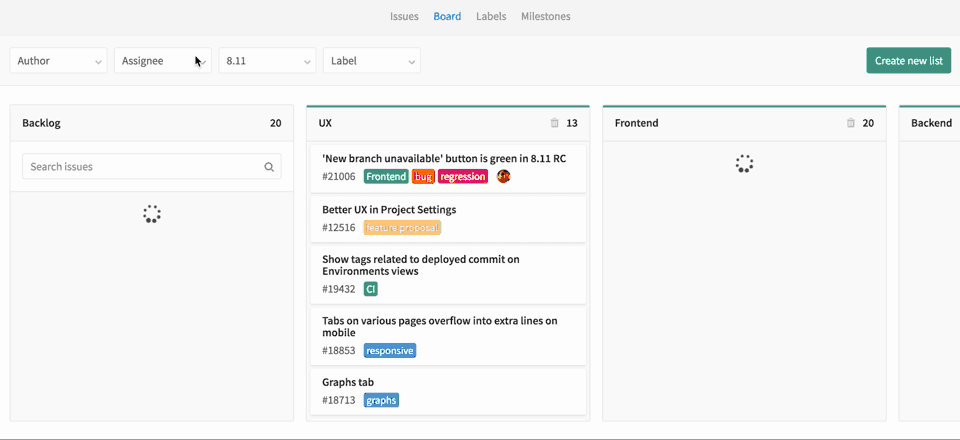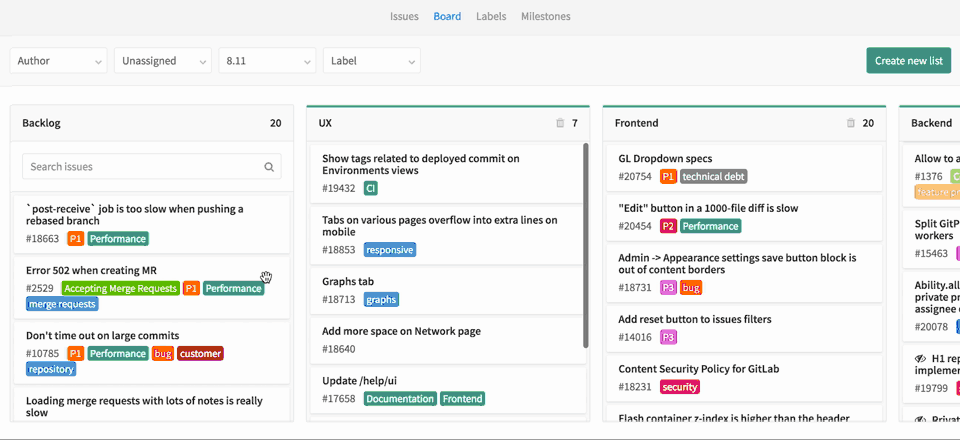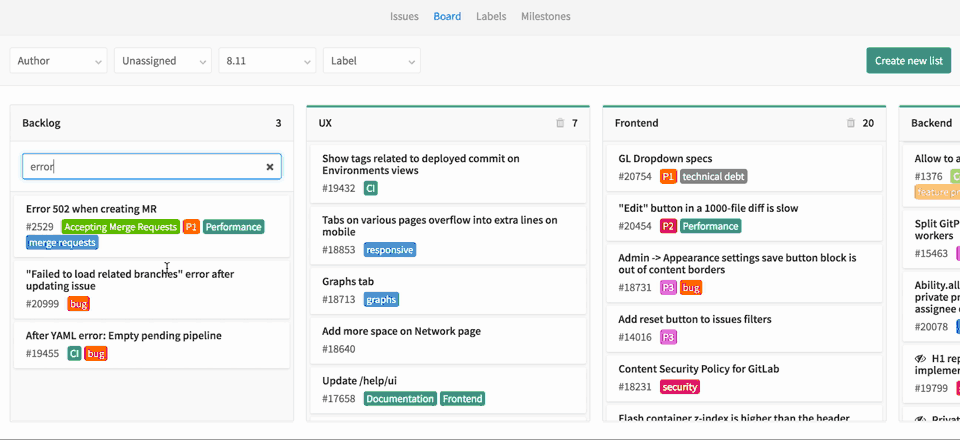
O desenvolvimento foi discutido na parte anterior, basta seguir qualquer fluxo git que quiser. Depois que desenvolvemos nosso novo recurso e o mesclamos no master: o que vem depois?
### Entrega contínua
A entrega contínua é uma abordagem de engenharia de software em que as equipes produzem software em ciclos curtos, garantindo que o software possa ser lançado de forma confiável a qualquer momento. Seu objetivo é construir, testar e lançar software com mais rapidez e frequência. A abordagem ajuda a reduzir o custo, o tempo e o risco da entrega de alterações, permitindo mais atualizações incrementais para aplicativos em produção. Um processo de implantação simples e repetível é importante para a entrega contínua.
### Entrega contínua no GitLab
No GitLab, a configuração da entrega contínua é definida por repositório como um arquivo de configuração YAML.
* A configuração de entrega contínua é uma série de **estágios** consecutivos.
* Cada estágio tem um ou vários **scripts** que são executados em paralelo.
O script define uma ação e quais condições devem ser atendidas para executá-la:
* O que fazer (executar o comando do SO, executar um contêiner)?
* Quando executar o script:
* Quais são os gatilhos (commit de um branch específico)?
* Nós o executamos se os estágios anteriores falharam?
* Executar manualmente ou automaticamente?
* Em que ambiente executar o script?
* Quais artefatos salvar após a execução dos scripts (eles são carregados do ambiente para o GitLab para facilitar o acesso)?
**Ambiente** - é um servidor ou contêiner configurado no qual você pode executar seus scripts.
**Runners** executam scripts em ambientes específicos. Eles são conectados ao GitLab e executam scripts conforme necessário.
O runner pode ser implantado em um servidor, contêiner ou até mesmo na sua máquina local.
Como acontece a entrega contínua?
1. O novo commit é enviado para o repositório.
2. O GitLab verifica a configuração de entrega contínua.
3. A configuração de entrega contínua contém todos os scripts possíveis para todos os casos, para que sejam filtrados para um conjunto de scripts que devem ser executados para esse commit específico (por exemplo, um commit para o branch master aciona apenas ações relacionadas a um branch master). Esse conjunto é chamado de **pipeline**.
4. O pipeline é executado em um ambiente de destino e os resultados da execução são salvos e exibidos no GitLab.
Por exemplo, aqui está um pipeline executado após um commit em um branch master:
Ele consiste em quatro etapas, executadas consecutivamente
1. O estágio de carregamento carrega o código em um servidor
2. O estágio de teste executa testes de unidade
3. O estágio de pacote consiste em dois scripts executados em paralelo:
* Compilação cliente
* Código de exportação do servidor (principalmente para fins informativos)
4. O estágio de implantação move o cliente criado para o diretório do servidor web.
Como podemos ver, todos os scripts foram executados com sucesso. Se um dos scripts falhar, por padrão, os scripts posteriores não são executados (mas podemos alterar esse comportamento):

Se abrirmos o script, podemos ver o log e determinar por que ele falhou:
Running with gitlab-runner 10.4.0 (857480b6)
on test runner (ab34a8c5)
Using Shell executor...
Running on gitlab-test...
<span class="term-fg-l-green term-bold">Fetching changes...</span>
Removing diff.xml
Removing full.xml
Removing index.html
Removing tests.html
HEAD is now at a5bf3e8 Merge branch '4-versiya-1-0' into 'master'
From http://gitlab.eduard.win/test/testProject
* [new branch] 5-versiya-1-1 -> origin/5-versiya-1-1
a5bf3e8..442a4db master -> origin/master
d28295a..42a10aa preprod -> origin/preprod
3ac4b21..7edf7f4 prod -> origin/prod
<span class="term-fg-l-green term-bold">Checking out 442a4db1 as master...</span>
<span class="term-fg-l-green term-bold">Skipping Git submodules setup</span>
<span class="term-fg-l-green term-bold">$ csession ensemble "##class(isc.git.GitLab).loadDiff()"</span>
[2018-03-06 13:58:19.188] Importing dir /home/gitlab-runner/builds/ab34a8c5/0/test/testProject/
[2018-03-06 13:58:19.188] Loading diff between a5bf3e8596d842c5cc3da7819409ed81e62c31e3 and 442a4db170aa58f2129e5889a4bb79261aa0cad0
[2018-03-06 13:58:19.192] Variable modified
var=$lb("MyApp/Info.cls")
Load started on 03/06/2018 13:58:19
Loading file /home/gitlab-runner/builds/ab34a8c5/0/test/testProject/MyApp/Info.cls as udl
Load finished successfully.
[2018-03-06 13:58:19.241] Variable items
var="MyApp.Info.cls"
var("MyApp.Info.cls")=""
Compilation started on 03/06/2018 13:58:19 with qualifiers 'cuk /checkuptodate=expandedonly'
Compiling class MyApp.Info
Compiling routine MyApp.Info.1
ERROR: MyApp.Info.cls(version+2) #1003: Expected space : '}' : Offset:14 [zversion+1^MyApp.Info.1]
TEXT: quit, "1.0" }
Detected 1 errors during compilation in 0.010s.
[2018-03-06 13:58:19.252] ERROR #5475: Error compiling routine: MyApp.Info.1. Errors: ERROR: MyApp.Info.cls(version+2) #1003: Expected space : '}' : Offset:14 [zversion+1^MyApp.Info.1]
> ERROR #5030: An error occurred while compiling class 'MyApp.Info'
<span class="term-fg-l-red term-bold">ERROR: Job failed: exit status 1
</span>
O erro de compilação causou a falha do nosso script.
Conclusão
* O GitLab é compatível com todos os principais estágios de desenvolvimento de software.
* A entrega contínua pode ajudar você a automatizar tarefas de construção, teste e implantação do seu software.
Links
* [Parte I: Git](https://git-scm.com/book/en/v2)
* [Introdução ao fluxo de trabalho do GitLab](https://about.gitlab.com/2016/10/25/gitlab-workflow-an-overview/)
* [Documentação de CI/CD do GitLab](https://about.gitlab.com/features/gitlab-ci-cd/)
* [Fluxo do GitLab](https://docs.gitlab.com/ce/workflow/gitlab_flow.html)
* [Código deste artigo](https://github.com/eduard93/GitGraph-samples)
### O que vem a seguir?
No próximo artigo, vamos:
* Instalar o GitLab.
* Conectá-lo a diversos ambientes com os produtos InterSystems instalados.
* Escrever uma configuração de entrega contínua.
Vamos discutir como a entrega contínua deve funcionar.
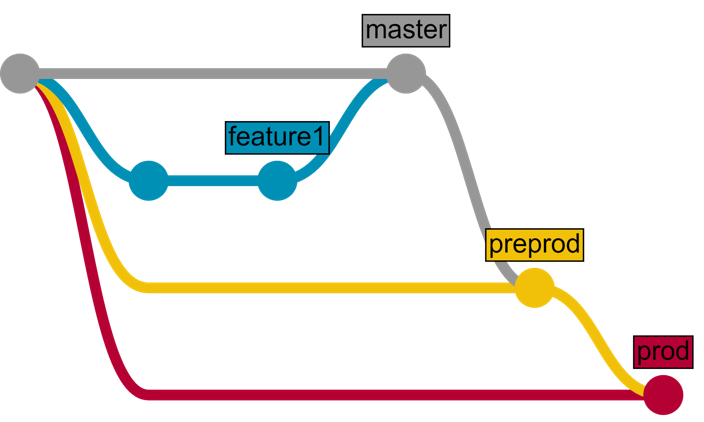
Em primeiro lugar, precisamos de vários ambientes e branches que correspondam a eles. O código entra nesse branch e é entregue ao ambiente de destino:
| Ambiente | Branch | Entrega | Quem pode fazer envios | Quem pode mesclar |
| -------- | ------- | ----------------------------------------------- | ------------------------------ | ------------------------------ |
| Teste | master | Automático | Desenvolvedores Proprietários | Desenvolvedores Proprietários |
| Preprod | preprod | Automático | Ninguém | Proprietários |
| Prod | prod | Semiautomático (pressionar botão para entregar) | Ninguém | Proprietários |
E, como exemplo, desenvolveremos um novo recurso usando o fluxo do GitLab e o entregaremos usando a CD do GitLab.
1. O recurso é desenvolvido em um branch de recursos.
2. O branch de recurso é revisado e mesclado no master branch.
3. Depois de um tempo (vários recursos mesclados), o master é mesclado com o preprod
4. Depois de um tempo (teste do usuário, etc.), o preprod é mesclado com o prod
Veja como ficaria:
1. Desenvolvimento e teste
* O desenvolvedor envia o código para o novo recurso em um branch de recursos separado
* Depois que o recurso se torna estável, o desenvolvedor mescla nosso branch de recursos no master branch
* O código do branch master é entregue ao ambiente de teste, onde é carregado e testado
2. Entrega para o ambiente de pré-produção
* O desenvolvedor cria a solicitação de mesclagem do branch master para o branch de pré-produção
* Depois de algum tempo, o proprietário do repositório aprova a solicitação de mesclagem
* O código do branch de pré-produção é entregue ao ambiente de pré-produção
3. Entrega para o ambiente de produção
* O desenvolvedor cria a solicitação de mesclagem do branch de pré-produção para o branch de produção
* Depois de algum tempo, o proprietário do repositório aprova a solicitação de mesclagem
* O proprietário do repositório aperta o botão "Implantar"
* O código do branch de produção é entregue ao ambiente de produção
Ou o mesmo, mas em formato gráfico: