Conecte a IA e o ML com sua solução de Análise Adaptativa
No cenário de dados atual, as empresas enfrentam vários desafios diferentes. Um deles é fazer análises sobre uma camada de dados unificada e harmonizada disponível para todos os consumidores. Uma camada que possa oferecer as mesmas respostas às mesmas perguntas, independentemente do dialeto ou da ferramenta usada. A Plataforma de Dados InterSystems IRIS responde a isso com um complemento de Análise Adaptativa que pode fornecer essa camada semântica unificada. Há muitos artigos no DevCommunity sobre como usá-lo por ferramentas de BI. Este artigo abordará como consumi-lo com IA e também como recuperar alguns insights. Vamos ir por etapas...
O que é a Análise Adaptativa?
Você pode facilmente encontrar uma definição [no site developer community] (https://community.intersystems.com/tags/adaptive-analytics) Resumindo, ela pode fornecer dados de forma estruturada e harmonizada para diversas ferramentas de sua escolha para consumo e análise posterior. Ela oferece as mesmas estruturas de dados a várias ferramentas de BI. Mas... Ela também pode oferecer as mesmas estruturas de dados para suas ferramentas de IA/ML!
A Análise Adaptativa tem um componente adicional chamado AI-LINK que constrói essa ponte entre a IA e a BI.
O que é exatamente o AI-Link ?
É um componente Python criado para permitir a interação programática com a camada semântica para os fins de otimizar os principais estágios do fluxo de trabalho do aprendizado de máquina (ML) (por exemplo, engenharia de características).
Com o AI-Link, você pode:
- acessar programaticamente características do seu modelo de dados analítico;
- fazer consultas, explorar dimensões e medidas;
- alimentar pipelines de ML; ... e enviar os resultados de volta à camada semântica para que sejam consumidos novamente por outras (por exemplo, pelo Tableau ou Excel).
Como é uma biblioteca Python, ela pode ser usada em qualquer ambiente Python. Incluindo Notebooks. Neste artigo, darei um exemplo simples de como alcançar a solução de Análise Adaptativa a partir do Jupyter Notebook com a ajuda do AI-Link.
Aqui está o repositório git com o Notebook completo como exemplo: https://github.com/v23ent/aa-hands-on
Pré-requisitos
Para os passos a seguir, presume-se que você concluiu os pré-requisitos:
- Solução de Análise Adaptativa em funcionamento (com a Plataforma de Dados IRIS como armazém de dados)
- Jupyter Notebook em funcionamento
- Conexão entre 1. e 2. pode ser estabelecida
Etapa 1: configuração
Primeiro, vamos instalar os componentes necessários em nosso ambiente. Isso baixará alguns pacotes que são necessários para que as próximas etapas funcionem. 'atscale' - nosso pacote principal para a conexão 'prophet' - pacote de que precisaremos para fazer previsões
pip install atscale prophet
Em seguida, precisamos importar as principais classes que representam alguns conceitos importantes da nossa camada semântica. Client - classe que usaremos para estabelecer uma conexão com a Análise Adaptativa; Project - classe para representar projetos dentro da Análise Adaptativa; DataModel - classe que representará nosso cubo virtual;
from atscale.client import Client
from atscale.data_model import DataModel
from atscale.project import Project
from prophet import Prophet
import pandas as pd
Etapa 2: conexão
Agora, deve estar tudo pronto para estabelecer uma conexão com nossa origem de dados.
client = Client(server='http://adaptive.analytics.server', username='sample')
client.connect()
Vá em frente e especifique os detalhes de conexão da sua instância da Análise Adaptativa. Quando for solicitada a organização, responda na caixa de diálogo e insira sua senha da instância da AtScale.
Com a conexão estabelecida, você precisará selecionar seu projeto da lista de projetos publicados no servidor. Você verá a lista de projetos como um prompt interativo, e a resposta deve ser o ID inteiro do projeto. O modelo de dados será selecionado automaticamente se for o único.
project = client.select_project()
data_model = project.select_data_model()
Etapa 3: explore seu conjunto de dados
Há vários métodos preparados pela AtScale na biblioteca de componentes do AI-Link. Eles permitem explorar seu catálogo de dados, consultar dados e até ingerir alguns dados de volta. A documentação da AtScale tem uma vasta referência da API, descrevendo tudo o que está disponível. Primeiro, vamos ver qual é o nosso conjunto de dados ao chamar alguns métodos de "data_model":
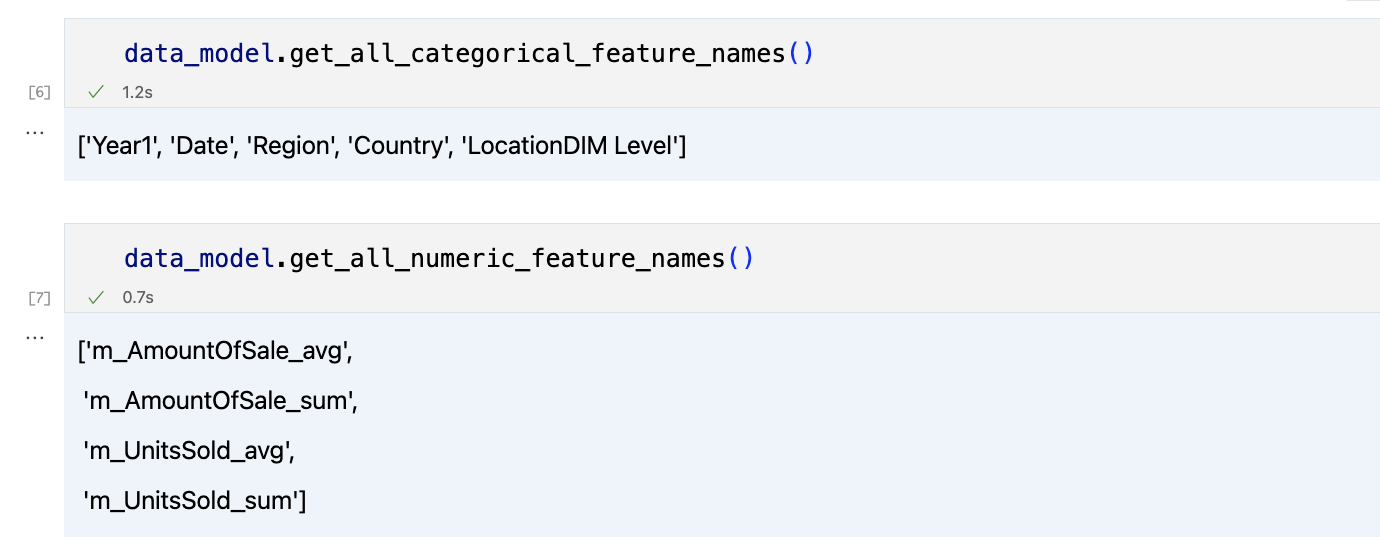
data_model.get_features()
data_model.get_all_categorical_feature_names()
data_model.get_all_numeric_feature_names()
A saída será algo assim
Depois de olhar um pouco, podemos consultar os dados em que realmente temos interesse usando o método "get_data". Ele retornará um DataFrame do pandas com os resultados da consulta.
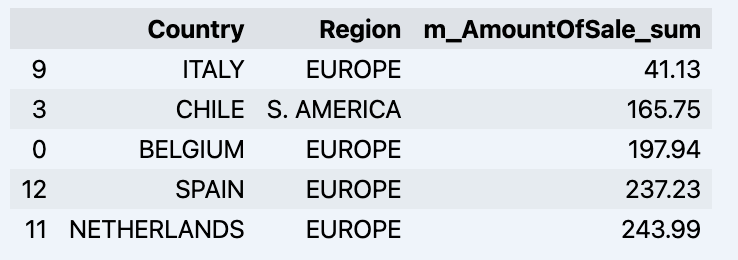
df = data_model.get_data(feature_list = ['Country','Region','m_AmountOfSale_sum'])
df = df.sort_values(by='m_AmountOfSale_sum')
df.head()
Que mostrará seu dataframe:
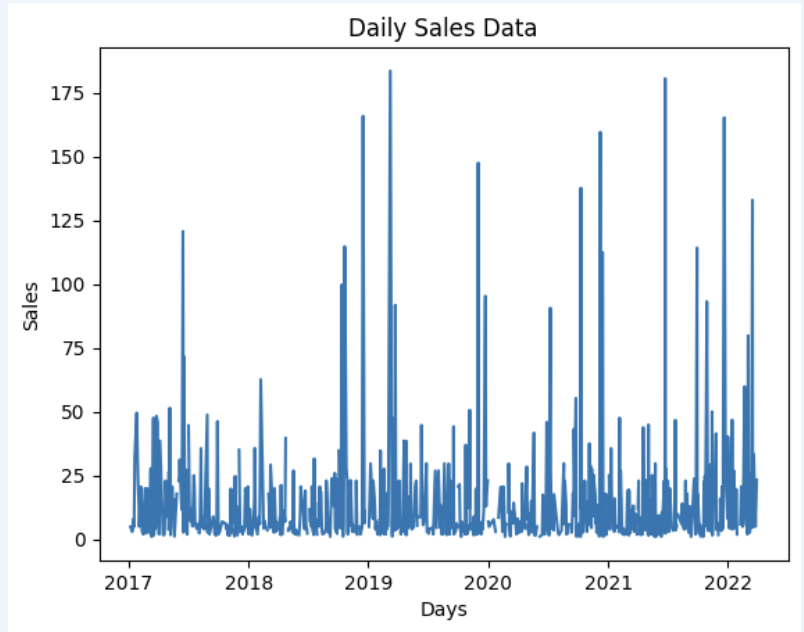
Vamos preparar um conjunto de dados e exibi-lo rapidamente no gráfico
import matplotlib.pyplot as plt
# Estamos pegando as vendas para cada data
dataframe = data_model.get_data(feature_list = ['Date','m_AmountOfSale_sum'])
# Crie um gráfico de linhas
plt.plot(dataframe['Date'], dataframe['m_AmountOfSale_sum'])
# Adicione rótulos e um título
plt.xlabel('Days')
plt.ylabel('Sales')
plt.title('Daily Sales Data')
# Exiba o gráfico
plt.show()
Saída:
Etapa 4: previsão
A próxima etapa seria obter um valor da ponte do AI-Link - vamos fazer algumas previsões simples!
# Carregue os dados históricos para treinar o modelo
data_train = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_less = {'Date':'2021-01-01'}
)
data_test = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_greater = {'Date':'2021-01-01'}
)
Obtemos 2 conjuntos de dados diferentes aqui: para treinar e testar nosso modelo.
# Para a ferramenta, escolhemos fazer a previsão "Prophet", em que precisamos especificar 2 colunas: "ds" e "y"
data_train['ds'] = pd.to_datetime(data_train['Date'])
data_train.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
data_test['ds'] = pd.to_datetime(data_test['Date'])
data_test.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
# Inicialize e ajuste o modelo Prophet
model = Prophet()
model.fit(data_train)
Em seguida, criamos outro dataframe para acomodar nossa previsão e exibi-la no gráfico
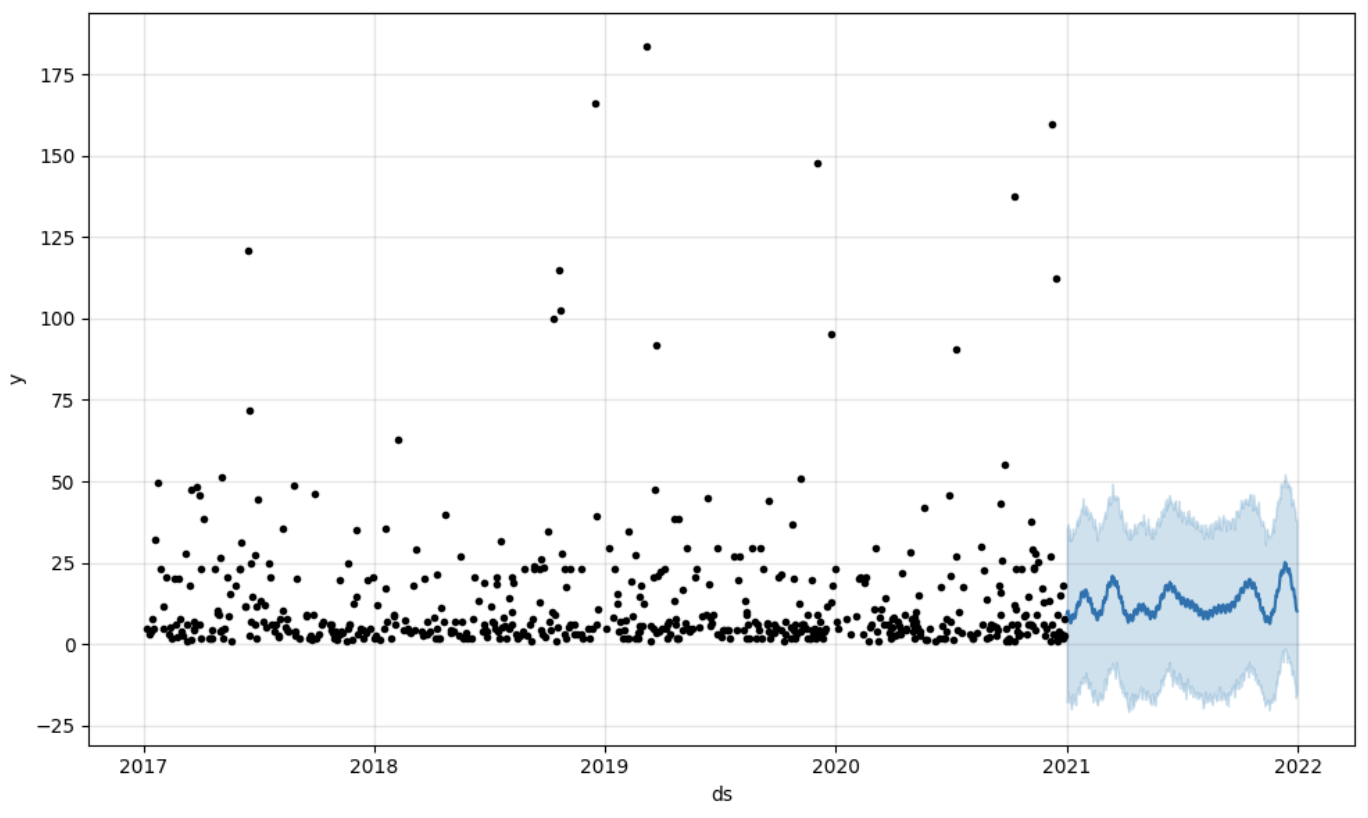
# Crie um dataframe futuro para previsão
future = pd.DataFrame()
future['ds'] = pd.date_range(start='2021-01-01', end='2021-12-31', freq='D')
# Faça previsões
forecast = model.predict(future)
fig = model.plot(forecast)
fig.show()
Saída:
Etapa 5: writeback
Depois de obter a previsão, podemos colocá-la de volta no armazém de dados e adicionar uma agregação ao nosso modelo semântico para que reflita para outros consumidores. A previsão estaria disponível por qualquer outra ferramenta de BI para usuários empresariais e analistas de BI. A previsão em si será colocada em nosso armazém de dados e armazenada lá.
from atscale.db.connections import Iris
db = Iris(
username,
host,
host,
driver,
schema,
schema,
password=None,
warehouse_id=None
)
data_model.writeback(dbconn=db,
table_name= 'SalesPrediction',
DataFrame = forecast)
data_model.create_aggregate_feature(dataset_name='SalesPrediction',
column_name='SalesForecasted',
name='sum_sales_forecasted',
aggregation_type='SUM')
Fim
É isso! Boa sorte com suas previsões!