Limpar filtro
Artigo
Angelo Bruno Braga · Out. 4, 2022
Olá Comunidade,
Deseja obter ajuda, discutir um recurso interessante, fazer um anúncio ou compartilhar seu conhecimento? Neste post, vamos dizer-lhe como fazer tudo isso.
Para facilitar a navegação neste "como fazer" basta seguir o conteúdo:
Diretrizes Gerais
Pergunta
Artigo ou Anúncio
Discussão
Diretrizes Gerais
Para começar, você precisa clicar no botão "Nova postagem" no menu superior do site da Comunidade de desenvolvedores:
Depois disso, você verá o editor que lhe dará a opção de criar uma Pergunta, um Anúncio, um Artigo ou uma Discussão. Diferentes tipos de postagens têm seus próprios conjuntos de campos obrigatórios e opcionais.
Primeiro, vamos falar sobre os campos comuns para todos os tipos de postagens e, em seguida, passar para os detalhes.
Basicamente, cada post tem um Título*, Corpo*, Grupo*, Tags e algumas opções adicionais onde você pode adicionar uma enquete ou anexar arquivos PDF. Todos os campos de texto marcados com asteriscos (*) são obrigatórios. Então, primeiro, você precisa escolher o tipo de postagem, pode ser como mencionado acima uma Pergunta, um Anúncio, um Artigo ou uma Discussão.
Em seguida, formule a ideia principal da sua pergunta da maneira mais precisa e concisa e escreva-a como um Título.
Depois disso, no Corpo, você escreve o que quiser compartilhar com os outros. Existem duas opções para escolher ao escrever o texto do seu post. Você pode usar o editor WYSIWYG ou Markdown. Ambos vão te dar a mesma coisa como resultado, é claro.
vs.
Depois de terminar de escrever o texto, você deve escolher o Grupo, que geralmente é a tecnologia, produto ou serviço fornecido pela InterSystems.
Após o campo Grupo, há um campo Tags onde você pode adicionar tags relacionadas ao conteúdo do seu post. Existem várias tags, então escolha com responsabilidade, porque outras pessoas usam essas tags para procurar ou classificar as informações quando estão pesquisando algo.
Abaixo das Tags, há um link para ver mais opções. Lá você pode anexar um documento em pdf (por exemplo, o horário do evento em formato pdf) e fornecer o nome que deseja que seja exibido.
Outra coisa que você pode fazer através de mais opções é Adicionar uma enquete. Preencha os campos com uma pergunta, possíveis respostas, escolha a duração, etc.
Depois de terminar, você pode Visualizar sua postagem para ver como ela ficará para outras pessoas, Salvá-la para continuar editando mais tarde ou Publicá-la imediatamente.
Além disso, você pode agendar uma publicação do seu post. Basta clicar na seta para baixo, escolher Agendar postagem e definir a data e a hora.
Depois de tudo definido, basta clicar em Agendar postagem e pronto.
Basicamente, isso é para a funcionalidade comum de criar uma postagem.
Pergunta
Pelo nome, é óbvio que você deve escolher esse tipo de postagem se precisar da ajuda de alguém. Aqui, na Comunidade de desenvolvedores, há muitos especialistas e alguém já deve ter se deparado com a mesma situação. Então não hesite em fazer perguntas ou respondê-las ;)
Para pedir ajuda, por favor, formule a ideia principal da sua pergunta e escreva-a como um título. Em seguida, selecione a Versão do produto que você está usando, pois versões diferentes têm funcionalidades e classes diferentes e alguns conselhos podem ser úteis para algumas versões e inúteis para outras.
Para ser ainda mais preciso, você pode fornecer a compilação completa que está usando atualmente utilizando o comando $ZV no terminal. Para obter sua versão completa, você pode abrir o Terminal e executar o comando:
write $ZV
O mesmo pode ser feito no IDE que você está usando ou pode ser vista no Portal de Gerenciamento:
Os demais campos são os mesmos descritos anteriormente.
Artigo or Anúncio
Para compartilhar seu conhecimento ou fazer um anúncio você deve escolher um tipo de postagem de Artigo ou Anúncio respectivamente. Esses tipos de postagens, além dos campos comuns, também possuem alguns adicionais. Esses são o Post Anterior, o Próximo Post e o link do aplicativo Open Exchange.
Então, basicamente, se este artigo/anúncio atual (ou um ramo de uma discussão) estiver vinculado a outro, você pode adicionar o link no campo Postagem anterior e, como resultado, outros membros da comunidade verão as seguintes postagens relacionadas bloquear no final do post.
Você não precisa abrir a postagem anterior e adicionar o link para uma próxima postagem, isso será feito automaticamente.
Se sua postagem tiver um projeto no Open Exchange vinculado a ela, você poderá adicionar o link a este projeto em um campo respectivo.
Discussão
Para iniciar uma conversa sobre algum recurso ou outro ou talvez compartilhar sua experiência com o uso da tecnologia e pedir feedback, você pode iniciar uma Discussão. Esse tipo de postagem tem todos os campos comuns e também os links para Post anterior e Próximo post.
É isso
Isto é o que você precisa saber para iniciar um novo tópico na Comunidade. Boa sorte
E estamos ansiosos para ler seus pensamentos ;
Artigo
Heloisa Paiva · Maio 12
Ao trabalhar com InterSystems IRIS, desenvolvedores e arquitetos de banco de dados frequentemente enfrentam uma decisão crítica: usar Dynamic SQL ou Embedded SQL para consultar e atualizar dados. Ambos os métodos têm seus pontos fortes e casos de uso únicos, mas entender suas implicações de desempenho é essencial para fazer a escolha certa. O tempo de resposta, uma métrica chave na avaliação do desempenho de aplicações, pode variar significativamente dependendo da abordagem SQL utilizada. Dynamic SQL oferece flexibilidade, pois as consultas podem ser construídas e executadas em tempo de execução, tornando-o ideal para cenários com necessidades de consulta imprevisíveis ou altamente variáveis. Por outro lado, Embedded SQL enfatiza a estabilidade e a eficiência ao integrar código SQL diretamente na lógica da aplicação, oferecendo tempos de resposta otimizados para padrões de consulta predefinidos.
Neste artigo, explorarei os tempos de resposta ao usar esses dois tipos de SQL e como eles dependem de diferentes estruturas de classe e do uso de parâmetros. Para fazer isso, usarei as seguintes classes do diagrama:
Para testar os tempos, criei o seguinte número de objetos para cada classe:
Paciente - 50 milhões
Visita - 150 milhões
Médico - 500 mil
Endereço - 50 milhões
Dessa forma, esperava ver um tempo razoável para executar as consultas e observar as diferenças entre a execução de Embedded SQL e Dynamic SQL. O único índice que adicionei foi o índice automático de um-para-muitos para o relacionamento Médico-Visita.
Então, vamos dar uma olhada nas consultas que vou executar e, em seguida, na duração da execução:
select count(*) from Hospital.Address
select count(*) from Hospital.Address where State = :param
select count(*) from Hospital.Patient p left join Hospital.Address a on p.address = a.id
select count(*) from Hospital.Patient p left join Hospital.Address a on p.address = a.id where a.State = :param
select count(a.Address->State) from Hospital.Patient a
select count(*) from Hospital.Patient p where p.Address->State = :param
select count(p.Visit->VisitDate) from Hospital.Patient p
select count(*) from Hospital.Patient p where p.Visit->VisitDate > :param
select count(v.Patient->Name) from Hospital.Visit v
select count(*) from Hospital.Visit v where v.Patient->Name %startswith :param
select count(v.Patient->Address->State) from Hospital.Visit v
select count(*) from Hospital.Visit v where v.Patient->Address->State = :param
select count(v.Doctor->Name) from Hospital.Visit v
select count(*) from Hospital.Visit v where v.Doctor->Name %startswith :param
select count(*) into :p from Hospital.Visit v where v.Doctor->Name %startswith :param and v.Patient->Name %startswith :param
select count(*) into :p from Hospital.Visit v where v.Doctor->Name %startswith :param and v.Patient->Name %startswith :param and v.Patient->Address->State = :param1
Obviamente, o código acima é a sintaxe para Embedded SQL (porque há parâmetros nomeados). Para Dynamic SQL, as consultas são quase as mesmas, mas em vez de parâmetros nomeados, tenho parâmetros não nomeados 😉. Por exemplo, para a última, tenho a seguinte consulta:
select count(*) from Hospital.Visit v where v.Doctor->Name %startswith ? and v.Patient->Name %startswith ? and v.Patient->Address->State = ?
Agora, vamos dar uma olhada nos resultados:
No of query
Embedded SQL (sec)
Dynamic SQL (sec)
1
49
12
2
3
3
3
32
26
4
47
46
5
48
46
6
47
46
7
1767
1806
8
1768
1841
9
31
26
10
83
81
11
41
45
12
73
71
13
23
26
14
1
1
15
2
2
16
3
3
Podemos observar um valor discrepante colossal, que é a primeira consulta. O Embedded SQL levou muito mais tempo para executar do que o Dynamic SQL. Executar as mesmas consultas várias vezes me deu resultados mais ou menos iguais. Então, é o que é.
Em geral, podemos ver que o relacionamento pai-filho é muito mais lento do lado da propriedade dos filhos, mesmo que todos os dados de Paciente e Visita estejam armazenados no global de Paciente. O índice salvou o dia para o relacionamento de um-para-muitos, e o tempo de execução foi consideravelmente menor. No geral, o tempo de resposta é quase sempre similar e difere em menos de 10%; às vezes, é o mesmo. Claro, usei consultas simples que não demoraram muito para preparar, então essa etapa pôde ser quase ignorada.
Artigo
Danusa Calixto · jan 11, 2023
Como você deve se lembrar do Global Summit 2022 ou do 2022.2 launch webinar, estamos lançando um novo e empolgante recurso para incluir em suas soluções analíticas no InterSystems IRIS. O Armazenamento Colunar apresenta uma maneira alternativa de armazenar os dados da tabela SQL que oferece uma aceleração de ordem de grandeza para consultas analíticas. Lançado pela primeira vez como um recurso experimental em 2022.2, o mais recente Developer Preview 2022.3 inclui várias atualizações que achamos que valeriam uma postagem rápida aqui.
Uma rápida recapitulação
Se você não está familiarizado com o Armazenamento Colunar, por favor dê uma olhada neste vídeo de breve introdução ou na sessão do GS2022 sobre o assunto. Resumindo, estamos codificando os dados da tabela em blocos de 64 mil valores por coluna usando um novo tipo de dado $vector. $vector é um tipo de dados interno (por enquanto) que utiliza esquemas de codificação adaptáveis para permitir o armazenamento eficiente de dados esparsos e densos. A codificação também é otimizada para um monte de operações $vector dedicadas, como para calcular agregados, agrupamentos e filtros de partes inteiras de 64k valores por vez, aproveitando instruções SIMD onde possível.
No momento da consulta SQL, aproveitamos essas operações criando um plano de consulta que também opera nesses blocos, o que, como você pode imaginar, gera uma redução massiva na quantidade de IO e no número de instruções ObjectScript para executar sua consulta, em comparação com o clássico processamento linha a linha. É claro que os IOs individuais são maiores e as operações $vector são um pouco mais pesadas do que as contrapartes de valor único do mundo orientado a linha, mas os ganhos são enormes. Usamos o termo planos de consulta vetorizados para estratégias de execução que lidam com dados $vector, empurrando blocos inteiros por meio de uma cadeia de operações individuais rápidas.
Apenas mais rápido
Mais importante ainda, as coisas ficaram mais rápidas. O novo kit inclui várias alterações na pilha que melhoram o desempenho, desde otimizações até aquelas operações $vector de baixo nível sobre alguns aprimoramentos de processamento de consulta e um conjunto mais amplo de planos de consulta vetorizados que podem ser paralelizados. Certas formas de carregar dados, como por meio de instruções INSERT .. SELECT, agora também empregarão um modelo de buffer que já usamos para criar índices e agora permitem a construção de tabelas inteiras com alto desempenho.
JOINs vetorizados
O recurso mais empolgante que adicionamos nesta versão é o suporte para unir dados colunares de maneira vetorizada. Em 2022.2, quando você deseja combinar dados de duas tabelas em uma consulta, ainda recorremos a uma estratégia robusta de JOIN linha por linha que funciona tanto em dados organizados em colunas quanto em linhas. Agora, quando ambas as extremidades do JOIN são armazenadas em formato colunar, usamos uma nova API do kernel para JOIN na memória, mantendo seu formato $vector. Este é outro passo importante para planos de consulta totalmente vetorizados, mesmo para as consultas mais complexas.
Aqui está um exemplo de uma consulta que aproveita a nova função, fazendo um self-JOIN do conjunto de dados New York Taxi que usamos em demonstrações anteriores:
SELECT
COUNT(*),
MAX(r1.total_amount - r2.total_amount)
FROM
NYTaxi.Rides r1,
NYTaxi.Rides r2
WHERE
r1.DOLocationID = r2.PULocationID
AND r1.tpep_dropoff_datetime = r2.tpep_pickup_datetime
AND r2.DOLocationID = r1.PULocationID
AND r1.passenger_count > 2
AND r2.passenger_count > 2
Esta consulta procura pares de viagens com mais de 2 passageiros, onde a segunda viagem começou onde a primeira terminou, exatamente ao mesmo tempo e onde a segunda viagem levou um de volta para onde a primeira começou. Não é uma análise superútil, mas eu só tinha uma tabela real neste esquema e a chave JOIN composta tornou isso um pouco menos trivial. No plano de consulta dessa instrução, você verá trechos como Apply vector operation %VHASH (para construir a chave JOIN composta) e Read vector-join temp-file A, que indicam nosso novo marceneiro vetorizado em ação! Isso pode soar como uma pepita pequena e trivial em um plano de consulta longo, mas envolve muita engenharia inteligente internamente, e há alguns fornecedores de bancos de dados colunares de alto nível por aí que simplesmente não permitem nenhum dos isso e coloque severas restrições em seu layout de esquema, então, por favor, JUNTE-SE a nós para aproveitar isso! :-)
Quando o plano de consulta lê esse arquivo temporário, você pode perceber que ainda há algum processamento linha por linha no trabalho pós-junção, o que nos leva a...
O que vem a seguir?
O Armazenamento Colunar ainda está marcado como "experimental" em 2022.3, mas estamos nos aproximando da prontidão de produção e da vetorização completa de ponta a ponta para consultas de várias tabelas. Isso inclui o trabalho pós-junção mencionado acima, suporte mais amplo no otimizador de consulta, carregamento ainda mais rápido de tabelas colunares e aprimoramentos adicionais no joiner, como suporte a memória compartilhada. Resumindo: agora é um ótimo momento para dar uma primeira chance a tudo isso com o conjunto de dados de taxi de Nova York (agora em IPM ou com script docker) usando o 2022.3 Community Edition, então você só precisa pressionar "Executar" quando lançarmos o 2023.1!
Se você estiver interessado em obter conselhos mais personalizados sobre como aproveitar o armazenamento colunar com seus próprios dados e consultas, entre em contato comigo ou com sua equipe de contas diretamente e talvez nos encontremos no Global Summit 2023 ;-).
Artigo
Danusa Calixto · Mar. 26
A interface de usuário de interoperabilidade agora inclui experiências de usuário modernizadas para os aplicativos Editor DTL e Configuração da Produção que estão disponíveis para aceitação em todos os produtos de interoperabilidade. Você pode alternar entre as visualizações modernizada e padrão. Todas as outras telas de interoperabilidade permanecem na interface de usuário padrão. Observe que as alterações são limitadas a esses dois aplicativos e identificamos abaixo a funcionalidade que está disponível atualmente.
Para experimentar as novas telas antes de atualizar, você pode baixar a versão 2025.1 da nossa página do kit da comunidade aqui: https://evaluation.intersystems.com/Eval/. Revise este breve tutorial sobre os aprimoramentos feitos nessas telas assistindo ao Building Integrations: A New User Experience do Learning Service!
Configuração da Produção - Introdução às Tarefas de Configuração
Configuração da Produção: Suportado nesta versão da Configuração de Produção:
Criando/Editando/Copiando/Excluindo Hosts
Parar/Iniciar Hosts
Editar Configurações da Produção
Parar/Iniciar Produções
Integração de controle de origem: Suporte para integração de controle de origem para a funcionalidade de configuração acima está disponível.
Visualização de Painel Dividido: Os usuários podem abrir o Editor de Regras e o Editor DTL diretamente na tela Configuração de Produção para visualizar e editar regras e transformações incluídas na produção em uma exibição de painel dividido.
Filtros Aprimorados: uma caixa de pesquisa na parte superior permite que você pesquise e filtre em todos os componentes de negócios, incluindo várias categorias, DTLs e subtransformações. Use a barra lateral esquerda para pesquisar independentemente do painel principal para visualizar os resultados da pesquisa em hosts e categorias.
Edição em massa de Categorias de Hosts: você pode adicionar uma nova categoria ou editar uma categoria existente para uma produção adicionando hosts da configuração de produção.
Roteadores expansíveis: Os roteadores podem ser expandidos para visualizar todas as regras, transformações e conexões em linha.
Conexões de Host Retrabalhadas: conexões diretas e indiretas agora são renderizadas quando um host comercial é selecionado, permitindo que você veja o caminho completo que uma mensagem pode tomar. Passe o mouse sobre qualquer host de saída ou entrada para diferenciar ainda mais as conexões. Mostrar Somente Hosts Conectados filtrará apenas os hosts selecionados e suas conexões.
Editor DTL - Introdução às Ferramentas DTL
Integração a Controle de Fontes: suporte para integração de controle de fonte está disponível.
Integração com VS Code: Os usuários podem visualizar esta versão do Editor DTL no VS Code IDE.
Suporte a Python embutido: O suporte ao Python Embutido se estende a esta versão do Editor DTL.
Teste DTL : O utilitário de Teste de DTL está disponível nesta versão do Editor DTL.
Trocar o Layout do Painel: O editor DTL suporta um layout lado a lado e de cima para baixo. Clique no botão de layout na faixa superior para experimentar isso.
Desfazer/Refazer: Os usuários podem desfazer e refazer todas as ações com os botões desfazer/refazer que ainda não foram salvos no código.
Parâmetro Gerar Segmentos Vazios: o parâmetro GENERATEEMPTYSEGMENTS está disponível para gerar segmentos vazios para campos ausentes.
Visualização de Subtransformações: Os usuários podem visualizar as subtransformações clicando no ícone de olho para abrir o DTL da subtransformação em uma nova guia.
Rolagem:
Rolagem Independente: As seções esquerda e direita (origem e destino) do DTL podem ser roladas independentemente posicionando o cursor acima de uma das seções e usando a roda de rolagem ou o trackpad para mover os segmentos verticalmente.
Rolagem Conjunta: as seções de origem e de destino podem ser roladas conjuntamente colocando o cursor no meio do diagrama.
Preenchimento Automático de Campo: Preenchimento automático disponível para: campos 'origem', 'destino' e 'condição', bem como na Classe de origem, Tipo de documento de origem, Classe de destino, Tipo de documento de destino.
Numeração Ordinal: O editor visual permite que você ative ou desative a visualização dos números ordinais e da expressão de caminho completo para cada segmento.
Referências Fáceis: Quando um campo no Editor de Ações está em foco, clicar duas vezes em um segmento no Editor Gráfico insere a referência de segmento correspondente na posição atual do cursor no Editor de Ações.
Sincronização: Clique em um elemento no editor visual para destacar a linha correspondente no editor de ações.
📣 CHAMADA PARA AÇÃO 📣
Se você tiver algum feedback, envie-o das seguintes formas:
✨ NOVOS Recursos em toda a interoperabilidade: Insira uma ideia no portal de ideias ou envolva-se com outras ideias no Portal de Ideias da InterSystems. Para novas ideias, adicione a tag "Interoperabilidade" em sua postagem ou vote positivamente em recursos já propostos na lista!
💻 Feedback Geral da Experiência do Usuário em todas as soluções de interoperabilidade: Por favor, comente seu feedback ou interaja com outros comentários abaixo.
🗒 Sugestões/Feedback sobre aplicativos modernizados (conforme descrito acima): Comente seu feedback ou interaja com outros comentários abaixo.
Por favor, considere completar a oportunidade do Global Master para se envolver com a equipe em uma sessão de feedback guiada privada e ganhar pontos! Inscreva-se para essas sessões via Global Masters >> aqui.
Se você quiser fornecer algum feedback adicional em um formato privado, envie seus pensamentos ou perguntas por e-mail para: ux@intersystems.com
Artigo
Heloisa Paiva · Abr. 3
No artigo anterior, apresentamos o aplicativo d[IA]gnosis, desenvolvido para auxiliar na codificação de diagnósticos na CID-10. Neste artigo, veremos como o InterSystems IRIS for Health nos fornece as ferramentas necessárias para a geração de vetores a partir da lista de códigos da CID-10, usando um modelo de linguagem pré-treinado, seu armazenamento e a subsequente busca por similaridades em todos esses vetores gerados.
Introdução
Uma das principais características que surgiram com o desenvolvimento de modelos de IA é o que conhecemos como RAG (Geração Aumentada por Recuperação), que nos permite melhorar os resultados dos modelos LLM ao incorporar um contexto ao modelo. Bem, em nosso exemplo, o contexto é dado pelo conjunto de diagnósticos da CID-10 e, para usá-los, devemos primeiro vetorizá-los.
Como vetorizar nossa lista de diagnósticos?
SentenceTransformers e Embedded Python
Para a geração de vetores, utilizamos a biblioteca Python SentenceTransformers , que facilita muito a vetorização de textos livres a partir de modelos pré-treinados. Do próprio site deles:
Sentence Transformers (também conhecido como SBERT) é o módulo Python de referência para acessar, usar e treinar modelos de incorporação de texto e imagem de última geração. Pode ser usado para calcular incorporações usando modelos Sentence Transformer (início rápido) ou para calcular pontuações de similaridade usando modelos Cross-Encoder (início rápido). Isso desbloqueia uma ampla gama de aplicações, incluindo busca semântica, similaridade textual semântica, e mineração de paráfrases.
Dentre todos os modelos desenvolvidos pela comunidade SentenceTransformers, encontramos o BioLORD-2023-M, um modelo pré-treinado que gerará vetores de 786 dimensões.
Este modelo foi treinado usando o BioLORD, uma nova estratégia de pré-treinamento para produzir representações significativas para frases clínicas e conceitos biomédicos.
As metodologias de ponta operam maximizando a similaridade na representação de nomes que se referem ao mesmo conceito e evitando o colapso por meio do aprendizado contrastivo. No entanto, como os nomes biomédicos nem sempre são autoexplicativos, às vezes resulta em representações não semânticas.
O BioLORD supera esse problema fundamentando suas representações de conceitos usando definições, bem como descrições curtas derivadas de um grafo de conhecimento multirrelacional que consiste em ontologias biomédicas. Graças a essa fundamentação, nosso modelo produz representações de conceitos mais semânticas que correspondem mais de perto à estrutura hierárquica das ontologias. O BioLORD-2023 estabelece um novo estado da arte para similaridade de texto tanto em frases clínicas (MedSTS) quanto em conceitos biomédicos (EHR-Rel-B).
Como você pode ver em sua definição, este modelo é pré-treinado com conceitos médicos que serão úteis ao vetorizar tanto nossos códigos CID-10 quanto texto livre.
Para o nosso projeto, baixaremos este modelo para acelerar a criação de vetores:
if not os.path.isdir('/shared/model/'):
model = sentence_transformers.SentenceTransformer('FremyCompany/BioLORD-2023-M')
model.save('/shared/model/')
Uma vez em nossa equipe, podemos inserir os textos a serem vetorizados em listas para acelerar o processo. Vamos ver como vetorizamos os códigos CID-10 que registramos anteriormente em nossa classe ENCODER.Object.Codes.
st = iris.sql.prepare("SELECT TOP 50 CodeId, Description FROM ENCODER_Object.Codes WHERE VectorDescription is null ORDER BY ID ASC ")
resultSet = st.execute()
df = resultSet.dataframe()
if (df.size > 0):
model = sentence_transformers.SentenceTransformer("/shared/model/")
embeddings = model.encode(df['description'].tolist(), normalize_embeddings=True)
df['vectordescription'] = embeddings.tolist()
stmt = iris.sql.prepare("UPDATE ENCODER_Object.Codes SET VectorDescription = TO_VECTOR(?,DECIMAL) WHERE CodeId = ?")
for index, row in df.iterrows():
rs = stmt.execute(str(row['vectordescription']), row['codeid'])
else:
flagLoop = False
Como você pode ver, primeiro extraímos os códigos armazenados em nossa tabela de códigos CID-10 que ainda não vetorizamos, mas que registramos em uma etapa anterior após extraí-los do arquivo CSV, depois extraímos a lista de descrições a serem vetorizadas e, usando a biblioteca Python sentence_transformers, recuperaremos nosso modelo e geraremos os embeddings associados.
Finalmente, atualizaremos o código CID-10 com a descrição vetorizada executando o UPDATE. Como você pode ver, o comando para vetorizar o resultado retornado pelo modelo é o comando SQL TO_VECTOR no IRIS.
Usando-o no IRIS
Ok, temos nosso código Python, então só precisamos envolvê-lo em uma classe que estende Ens.BusinessProcess e incluí-la em nossa produção, depois conectá-la ao Business Service encarregado de recuperar o arquivo CSV e pronto!
Vamos dar uma olhada em como esse código ficará em nossa produção:
Como você pode ver, temos nosso Business Service com o adaptador EnsLib.File.InboundAdapter, que nos permitirá coletar o arquivo de códigos e redirecioná-lo para nosso Business Process, no qual realizaremos todas as operações de vetorização e armazenamento, fornecendo-nos um conjunto de registros como o seguinte
Agora nosso aplicativo estaria pronto para começar a procurar possíveis correspondências com os textos que enviamos a ele!
No próximo artigo...
No próximo artigo, mostraremos como o front-end do aplicativo desenvolvido em Angular 17 é integrado à nossa produção no IRIS for Health e como o IRIS recebe os textos a serem analisados, os vetoriza e busca similaridades na tabela de códigos CID-10.
Não perca!
Artigo
Mikhail Khomenko · Nov. 19, 2021
[Da última vez](https://community.intersystems.com/post/deploying-intersystems-iris-solution-gcp-kubernetes-cluster-gke-using-circleci), lançamos uma aplicação IRIS no Google Cloud usando seu serviço GKE.
E, embora criar um cluster manualmente (ou por meio do [gcloud](https://cloud.google.com/kubernetes-engine/docs/how-to/creating-a-cluster)) seja fácil, a [abordagem de Infraestrutura como Código (IaC)](https://martinfowler.com/bliki/InfrastructureAsCode.html) moderna recomenda que a descrição do cluster Kubernetes também seja armazenada no repositório como código. Como escrever este código é determinado pela ferramenta que é usada para IaC.
No caso do Google Cloud, existem várias opções, entre elas o Deployment Manager e o Terraform. As opiniões estão divididas quanto o que é melhor: se você quiser saber mais, leia este tópico no Reddit Opiniões sobre Terraform vs. Deployment Manager? e o artigo no Medium Comparando o GCP Deployment Manager e o Terraform.
Para este artigo, escolheremos o Terraform, já que ele está menos vinculado a um fornecedor específico e você pode usar seu IaC com diferentes provedores em nuvem.
Suporemos que você leu o artigo anterior e já tem uma conta do Google, e que criou um projeto chamado “Desenvolvimento”, como no artigo anterior. Neste artigo, seu ID é mostrado como . Nos exemplos abaixo, altere-o para o ID de seu próprio projeto.
Lembre-se de que o Google não é gratuito, embora tenha um nível gratuito. Certifique-se de controlar suas despesas.
Também presumiremos que você já bifurcou o repositório original. Chamaremos essa bifurcação (fork) de “my-objectscript-rest-docker-template” e nos referiremos ao seu diretório raiz como"" ao longo deste artigo.
Todos os exemplos de código são armazenados neste repositório para simplificar a cópia e a colagem.
O diagrama a seguir descreve todo o processo de implantação em uma imagem:
Então, vamos instalar a versão mais recente do Terraform no momento desta postagem:
$ terraform versionTerraform v0.12.17
A versão é importante aqui, pois muitos exemplos na Internet usam versões anteriores, e a 0.12 trouxe muitas mudanças.
Queremos que o Terraform execute certas ações (use certas APIs) em nossa conta do GCP. Para ativar isso, crie uma conta de serviço com o nome 'terraform' e ative a API do Kubernetes Engine. Não se preocupe sobre como vamos conseguir isso — basta continuar lendo e suas perguntas serão respondidas.
Vamos tentar um exemplo com o utilitário gcloud, embora também possamos usar o console web.
Usaremos alguns comandos diferentes nos exemplos a seguir. Consulte os tópicos da documentação a seguir para obter mais detalhes sobre esses comandos e recursos.
Como criar contas de serviço IAM no gcloud
Como atribuir papéis a uma conta de serviço para recursos específicos
Como criar chaves de conta de serviço IAM no gcloud
Como ativar uma API no projeto do Google Cloud
Agora vamos analisar o exemplo.
$ gcloud init
Como trabalhamos com o gcloud no artigo anterior, não discutiremos todos os detalhes de configuração aqui. Para este exemplo, execute os seguintes comandos:
$ cd $ mkdir terraform; cd terraform$ gcloud iam service-accounts create terraform --description "Terraform" --display-name "terraform"
Agora, vamos adicionar alguns papéis à conta de serviço do terraform além de “Administrador do Kubernetes Engine” (container.admin). Essas funções serão úteis para nós no futuro.
$ gcloud projects add-iam-policy-binding \ --member serviceAccount:terraform@.iam.gserviceaccount.com \ --role roles/container.admin
$ gcloud projects add-iam-policy-binding \ --member serviceAccount:terraform@.iam.gserviceaccount.com \ --role roles/iam.serviceAccountUser
$ gcloud projects add-iam-policy-binding \ --member serviceAccount:terraform@.iam.gserviceaccount.com \ --role roles/compute.viewer
$ gcloud projects add-iam-policy-binding \ --member serviceAccount:terraform@.iam.gserviceaccount.com \ --role roles/storage.admin
$ gcloud iam service-accounts keys create account.json \--iam-account terraform@.iam.gserviceaccount.com
Observe que a última entrada cria o seu arquivo account.json. Certifique-se de manter este arquivo em segredo.
$ gcloud projects list$ gcloud config set project $ gcloud services list --available | grep 'Kubernetes Engine'$ gcloud services enable container.googleapis.com$ gcloud services list --enabled | grep 'Kubernetes Engine'container.googleapis.com Kubernetes Engine API
A seguir, vamos descrever o cluster GKE na linguagem HCL do Terraform. Observe que usamos vários placeholders aqui; substitua-os por seus valores:
Placeholder
Significado
Exemplo
ID do projeto do GCP
possible-symbol-254507
Armazenamento para estado/bloqueio do Terraform - deve ser único
circleci-gke-terraform-demo
Região onde os recursos serão criados
europe-west1
Zona onde os recursos serão criados
europe-west1-b
Nome do cluster GKE
dev-cluster
Nome do pool de nós de trabalho do GKE
dev-cluster-node-pool
Aqui está a configuração HCL para o cluster na prática:
$ cat main.tfterraform { required_version = "~> 0.12" backend "gcs" { bucket = "" prefix = "terraform/state" credentials = "account.json" }}
provider "google" { credentials = file("account.json") project = "" region = ""}
resource "google_container_cluster" "gke-cluster" { name = "" location = "" remove_default_node_pool = true # No cluster regional (localização é região, não zona) # este é um número de nós por zona initial_node_count = 1}
resource "google_container_node_pool" "preemptible_node_pool" { name = "" location = "" cluster = google_container_cluster.gke-cluster.name # No cluster regional (localização é região, não zona) # este é um número de nós por zona node_count = 1
node_config { preemptible = true machine_type = "n1-standard-1" oauth_scopes = [ "storage-ro", "logging-write", "monitoring" ] }}
Para garantir que o código HCL esteja no formato adequado, o Terraform fornece um comando de formatação útil que você pode usar:
$ terraform fmt
O fragmento de código (snippet) mostrado acima indica que os recursos criados serão fornecidos pelo Google e os próprios recursos são google_container_cluster e google_container_node_pool, que designamos como preemptivos para economia de custos. Também optamos por criar nosso próprio pool em vez de usar o padrão.
Vamos nos concentrar brevemente na seguinte configuração:
terraform { required_version = "~> 0.12" backend "gcs" { Bucket = "" Prefix = "terraform/state" credentials = "account.json" }}
O Terraform grava tudo o que é feito no arquivo de status e usa esse arquivo para outro trabalho. Para um compartilhamento conveniente, é melhor armazenar este arquivo em algum lugar remoto. Um lugar típico é um Google Bucket.
Vamos criar este bucket. Use o nome do seu bucket em vez do placeholder . Antes da criação do bucket, vamos verificar se está disponível, pois deve ser único em todo o GCP:
$ gsutil acl get gs://
Boa resposta:
BucketNotFoundException: 404 gs:// bucket does not exist
A resposta ocupado "Busy" significa que você deve escolher outro nome:
AccessDeniedException: 403 does not have storage.buckets.get access to
Também vamos habilitar o controle de versão, como o Terraform recomenda.
$ gsutil mb -l EU gs://
$ gsutil versioning get gs://gs://: Suspended
$ gsutil versioning set on gs://
$ gsutil versioning get gs://gs://: Enabled
O Terraform é modular e precisa adicionar um plugin de provedor do Google para criar algo no GCP. Usamos o seguinte comando para fazer isso:
$ terraform init
Vejamos o que o Terraform fará para criar um cluster do GKE:
$ terraform plan -out dev-cluster.plan
A saída do comando inclui detalhes do plano. Se você não tem objeções, vamos implementar este plano:
$ terraform apply dev-cluster.plan
A propósito, para excluir os recursos criados pelo Terraform, execute este comando a partir do diretório /terraform/:
$ terraform destroy -auto-approve
Vamos deixar o cluster como está por um tempo e seguir em frente. Mas primeiro observe que não queremos colocar tudo no repositório, então vamos adicionar vários arquivos às exceções:
$ cat /.gitignore.DS_Storeterraform/.terraform/terraform/*.planterraform/*.json
Usando Helm
No artigo anterior, armazenamos os manifestos do Kubernetes como arquivos YAML no diretório /k8s/, que enviamos ao cluster usando o comando "kubectl apply".
Desta vez, tentaremos uma abordagem diferente: usando o gerenciador de pacotes Helm do Kubernetes, que foi atualizado recentemente para a versão 3. Use a versão 3 ou posterior porque a versão 2 tinha problemas de segurança do lado do Kubernetes (veja Executando o Helm na produção: melhores práticas de Segurança para mais detalhes). Primeiro, empacotaremos os manifestos Kubernetes de nosso diretório k8s/ em um pacote Helm, que é conhecido como chart. Um chart Helm instalado no Kubernetes é chamado de release. Em uma configuração mínima, um chart consistirá em vários arquivos:
$ mkdir /helm; cd /helm$ tree /helm/helm/├── Chart.yaml├── templates│ ├── deployment.yaml│ ├── _helpers.tpl│ └── service.yaml└── values.yaml
Seu propósito está bem descrito no site oficial. As práticas recomendadas para criar seus próprios charts são descritas no Guia de Melhores Práticas do Chart na documentação do Helm.
Esta é a aparência do conteúdo de nossos arquivos:
$ cat Chart.yamlapiVersion: v2name: iris-restversion: 0.1.0appVersion: 1.0.3description: Helm for ObjectScript-REST-Docker-template applicationsources:- https://github.com/intersystems-community/objectscript-rest-docker-template- https://github.com/intersystems-community/gke-terraform-circleci-objectscript-rest-docker-template
$ cat templates/deployment.yamlapiVersion: apps/v1kind: Deploymentmetadata: name: {{ template "iris-rest.name" . }} labels: app: {{ template "iris-rest.name" . }} chart: {{ template "iris-rest.chart" . }} release: {{ .Release.Name }} heritage: {{ .Release.Service }}spec: replicas: {{ .Values.replicaCount }} strategy: {{- .Values.strategy | nindent 4 }} selector: matchLabels: app: {{ template "iris-rest.name" . }} release: {{ .Release.Name }} template: metadata: labels: app: {{ template "iris-rest.name" . }} release: {{ .Release.Name }} spec: containers: - image: {{ .Values.image.repository }}:{{ .Values.image.tag }} name: {{ template "iris-rest.name" . }} ports: - containerPort: {{ .Values.webPort.value }} name: {{ .Values.webPort.name }}
$ cat templates/service.yaml{{- if .Values.service.enabled }}apiVersion: v1kind: Servicemetadata: name: {{ .Values.service.name }} labels: app: {{ template "iris-rest.name" . }} chart: {{ template "iris-rest.chart" . }} release: {{ .Release.Name }} heritage: {{ .Release.Service }}spec: selector: app: {{ template "iris-rest.name" . }} release: {{ .Release.Name }} ports: {{- range $key, $value := .Values.service.ports }} - name: {{ $key }}{{ toYaml $value | indent 6 }} {{- end }} type: {{ .Values.service.type }} {{- if ne .Values.service.loadBalancerIP "" }} loadBalancerIP: {{ .Values.service.loadBalancerIP }} {{- end }}{{- end }}
$ cat templates/_helpers.tpl{{/* vim: set filetype=mustache: */}}{{/*Expande o nome do chart.*/}}
{{- define "iris-rest.name" -}}{{- default .Chart.Name .Values.nameOverride | trunc 63 | trimSuffix "-" -}}{{- end -}}
{{/*Cria o nome e a versão do chart conforme usado pelo rótulo do chart.*/}}{{- define "iris-rest.chart" -}}{{- printf "%s-%s" .Chart.Name .Chart.Version | replace "+" "_" | trunc 63 | trimSuffix "-" -}}{{- end -}}
$ cat values.yamlnamespaceOverride: iris-rest
replicaCount: 1
strategy: | type: Recreate
image: repository: eu.gcr.io/iris-rest tag: v1
webPort: name: web value: 52773
service: enabled: true name: iris-rest type: LoadBalancer loadBalancerIP: "" ports: web: port: 52773 targetPort: 52773 protocol: TCP
Para criar os charts do Helm, instale o cliente Helm e o utilitário de linha de comando kubectl.
$ helm versionversion.BuildInfo{Version:"v3.0.1", GitCommit:"7c22ef9ce89e0ebeb7125ba2ebf7d421f3e82ffa", GitTreeState:"clean", GoVersion:"go1.13.4"}
Crie um namespace chamado iris. Seria bom se isso fosse criado durante a implantação, mas até agora não é o caso.
Primeiro, adicione credenciais para o cluster criado pelo Terraform ao kube-config:
$ gcloud container clusters get-credentials --zone --project $ kubectl create ns iris
Confirme (sem iniciar uma implantação real) se o Helm criará o seguinte no Kubernetes:
$ cd /helm$ helm upgrade iris-rest \ --install \ . \ --namespace iris \ --debug \ --dry-run
A saída — os manifestos do Kubernetes — foi omitida por causa do espaço aqui. Se tudo estiver certo, vamos implantar:
$ helm upgrade iris-rest --install . --namespace iris$ helm list -n iris --allIris-rest iris 1 2019-12-14 15:24:19.292227564 +0200 EET deployed iris-rest-0.1.0 1.0.3
Vemos que o Helm implantou nossa aplicação, mas como ainda não criamos a imagem Docker eu.gcr.io/iris-rest:v1, o Kubernetes não pode extraí-la (ImagePullBackOff):
$ kubectl -n iris get poNAME READY STATUS RESTARTS AGEiris-rest-59b748c577-6cnrt 0/1 ImagePullBackOff 0 10m
Vamos terminar com isso por agora:
$ helm delete iris-rest -n iris
O Lado do CircleCI
Agora que experimentamos o Terraform e o cliente Helm, vamos colocá-los em uso durante o processo de implantação no lado do CircleCI.
$ cat /.circleci/config.ymlversion: 2.1
orbs: gcp-gcr: circleci/gcp-gcr@0.6.1
jobs: terraform: docker: # A versão da imagem do Terraform deve ser a mesma de quando # você executa o terraform antes da máquina local - image: hashicorp/terraform:0.12.17 steps: - checkout - run: name: Create Service Account key file from environment variable working_directory: terraform command: echo ${TF_SERVICE_ACCOUNT_KEY} > account.json - run: name: Show Terraform version command: terraform version - run: name: Download required Terraform plugins working_directory: terraform command: terraform init - run: name: Validate Terraform configuration working_directory: terraform command: terraform validate - run: name: Create Terraform plan working_directory: terraform command: terraform plan -out /tmp/tf.plan - run: name: Run Terraform plan working_directory: terraform command: terraform apply /tmp/tf.plan k8s_deploy: docker: - image: kiwigrid/gcloud-kubectl-helm:3.0.1-272.0.0-218 steps: - checkout - run: name: Authorize gcloud on GKE working_directory: helm command: | echo ${GCLOUD_SERVICE_KEY} > gcloud-service-key.json gcloud auth activate-service-account --key-file=gcloud-service-key.json gcloud container clusters get-credentials ${GKE_CLUSTER_NAME} --zone ${GOOGLE_COMPUTE_ZONE} --project ${GOOGLE_PROJECT_ID} - run: name: Wait a little until k8s worker nodes up command: sleep 30 # It’s a place for improvement - run: name: Create IRIS namespace if it doesn't exist command: kubectl get ns iris || kubectl create ns iris - run: name: Run Helm release deployment working_directory: helm command: | helm upgrade iris-rest \ --install \ . \ --namespace iris \ --wait \ --timeout 300s \ --atomic \ --set image.repository=eu.gcr.io/${GOOGLE_PROJECT_ID}/iris-rest \ --set image.tag=${CIRCLE_SHA1} - run: name: Check Helm release status command: helm list --all-namespaces --all - run: name: Check Kubernetes resources status command: | kubectl -n iris get pods echo kubectl -n iris get servicesworkflows: main: jobs: - terraform - gcp-gcr/build-and-push-image: dockerfile: Dockerfile gcloud-service-key: GCLOUD_SERVICE_KEY google-compute-zone: GOOGLE_COMPUTE_ZONE google-project-id: GOOGLE_PROJECT_ID registry-url: eu.gcr.io image: iris-rest path: . tag: ${CIRCLE_SHA1} - k8s_deploy: requires: - terraform - gcp-gcr/build-and-push-image
Você precisará adicionar várias variáveis de ambiente ao seu projeto no lado do CircleCI:
O GCLOUD\_SERVICE\_KEY é a chave da conta de serviço CircleCI e o TF\_SERVICE\_ACCOUNT_KEY é a chave da conta de serviço Terraform. Lembre-se de que a chave da conta de serviço é todo o conteúdo do arquivo _account.json_.
A seguir, vamos enviar nossas alterações para um repositório:
$ cd $ git add .circleci/ helm/ terraform/ .gitignore$ git commit -m "Add Terraform and Helm"$ git push
O painel da IU do CircleCI deve mostrar que tudo está bem:
Terraform é uma ferramenta idempotente e se o cluster GKE estiver presente, o trabalho "terraform" não fará nada. Se o cluster não existir, ele será criado antes da implantação do Kubernetes.Por fim, vamos verificar a disponibilidade de IRIS:
$ gcloud container clusters get-credentials --zone --project
$ kubectl -n iris get svcNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEIris-rest LoadBalancer 10.23.249.42 34.76.130.11 52773:31603/TCP 53s
$ curl -XPOST -H "Content-Type: application/json" -u _system:SYS 34.76.130.11:52773/person/ -d '{"Name":"John Dou"}'
$ curl -XGET -u _system:SYS 34.76.130.11:52773/person/all[{"Name":"John Dou"},]
Conclusão
Terraform e Helm são ferramentas DevOps padrão e devem ser perfeitamente integrados à implantação do IRIS.
Eles exigem algum aprendizado, mas depois de alguma prática, eles podem realmente economizar seu tempo e esforço.
Artigo
Henry Pereira · Ago. 10, 2021

Calma, calma, não estou incentivando uma guerra contra as máquinas no melhor estilo sci-fi para impedir ao dominação mundial do Ultron ou da Skynet.
Ainda não... ainda não 🤔
Convido você para desafiarmos as máquinas através da criação de um jogo bem simples utilizando ObjectScript com Python embarcado.
Tenho que dizer que fiquei super empolgado com a feature do Embedded Python no InterSystems IRIS, é incrível o leque de possibilidades que se abre para criar aplicações fantásticas.
Vamos construir um jogo da velha, as regras são bem simples e acredito que todos sabem como jogar.
Era o que me salvava do tédio na minha infância durante viagens longas de carro com a família, antes de crianças terem celulares ou tablets, nada como desafiar meus irmãos a jogar algumas partidas no vidro embaçado.
Então apertem o cinto e vamos lá!
## Regras
Como comentado, as regras são muito simples:
- apenas 2 jogadores por partida
- é jogado em turnos em um grid de 3x3
- o jogador humano sempre será a letra X e o computador a letra O
- os jogadores só poderão colocar as letras nos espaços vazios
- o primeiro que completar uma sequência de 3 letras iguais na horizontal, ou na vertical ou na diagonal, é o vencedor
- quando os 9 espaços estiverem ocupados será empate e o fim da partida

Todo o mecanismo e as regras escreveremos em ObjectScript, o mecanismo do jogador do computador será escrito em Python.
## Vamos colocar as mãos na massa
Controlaremos o tabuleiro em uma global, sendo que cada linha estará em um nó e cada coluna em um piece.
Nosso primeiro método é para iniciar o tabuleiro, para facilitar irei iniciar a global já com os nós (linhas A, B e C) e com os 3 pieces:
```
/// Iniciate a New Game
ClassMethod NewGame() As %Status
{
Set sc = $$$OK
Kill ^TicTacToe
Set ^TicTacToe("A") = "^^"
Set ^TicTacToe("B") = "^^"
Set ^TicTacToe("C") = "^^"
Return sc
}
```
neste momento iremos criar o método para adicionar as letras nos espaços vazios, para isto cada jogador irá passar a localização do espaço do tabuleiro.
Cada linha uma letra e coluna um número, para colocar o X no meio, por exemplo, passamos B2 e a letra X para o método.
```
ClassMethod MakeMove(move As %String, player As %String) As %Boolean
{
Set $Piece(^TicTacToe($Extract(move,1,1)),"^",$Extract(move,2,2)) = player
}
```
Vamos validar se a coordenada passada é válida, a maneira mais simples que vejo é utilizando uma expressão regular:
```
ClassMethod CheckMoveIsValid(move As %String) As %Boolean
{
Set regex = ##class(%Regex.Matcher).%New("(A|B|C){1}[0-9]{1}")
Set regex.Text = $ZCONVERT(move,"U")
Return regex.Locate()
}
```
precisamos garantir que o espaço selecionado esteja vazio
```
ClassMethod IsSpaceFree(move As %String) As %Boolean
{
Quit ($Piece(^TicTacToe($Extract(move,1,1)),"^",$Extract(move,2,2)) = "")
}
```
Nooice!
Agora vamos verificar se algum jogador venceu a partida ou se o jogo já terminou, para isto vamos criar o método CheckGameResult.
Primeiro verificamos se teve algum vencedor completando pela horizontal, usaremos uma list com as linhas e um simples $Find resolve
```
Set lines = $ListBuild("A","B","C")
// Check Horizontal
For i = 1:1:3 {
Set line = ^TicTacToe($List(lines, i))
If (($Find(line,"X^X^X")>0)||($Find(line,"O^O^O")>0)) {
Return $Piece(^TicTacToe($List(lines, i)),"^", 1)_" won"
}
}
```
Com outro for verificamos a vertical
```
For j = 1:1:3 {
If (($Piece(^TicTacToe($List(lines, 1)),"^",j)'="") &&
($Piece(^TicTacToe($List(lines, 1)),"^",j)=$Piece(^TicTacToe($List(lines, 2)),"^",j)) &&
($Piece(^TicTacToe($List(lines, 2)),"^",j)=$Piece(^TicTacToe($List(lines, 3)),"^",j))) {
Return $Piece(^TicTacToe($List(lines, 1)),"^",j)_" won"
}
}
```
para verificar a diagonal:
```
If (($Piece(^TicTacToe($List(lines, 2)),"^",2)'="") &&
(
(($Piece(^TicTacToe($List(lines, 1)),"^",1)=$Piece(^TicTacToe($List(lines, 2)),"^",2)) &&
($Piece(^TicTacToe($List(lines, 2)),"^",2)=$Piece(^TicTacToe($List(lines, 3)),"^",3)))||
(($Piece(^TicTacToe($List(lines, 1)),"^",3)=$Piece(^TicTacToe($List(lines, 2)),"^",2)) &&
($Piece(^TicTacToe($List(lines, 2)),"^",2)=$Piece(^TicTacToe($List(lines, 3)),"^",1)))
)) {
Return ..WhoWon($Piece(^TicTacToe($List(lines, 2)),"^",2))
}
```
por último, verificamos se teve um empate
```
Set gameStatus = ""
For i = 1:1:3 {
For j = 1:1:3 {
Set:($Piece(^TicTacToe($List(lines, i)),"^",j)="") gameStatus = "Not Done"
}
}
Set:(gameStatus = "") gameStatus = "Draw"
```
Great!
## É hora de criarmos a máquina!
Vamos criar o nosso adversário, precisamos criar um algoritmo capaz de calcular todos os movimentos disponíveis e usar uma métrica para saber qual é o melhor movimento.
O ideal é utilizar um algoritmo de decisão chamado de MiniMax ([Wikipedia: MiniMax](https://en.wikipedia.org/wiki/Minimax#Minimax_algorithm_with_alternate_moves))

O algoritmo MiniMax é uma regra de decisão utilizado em teoria dos jogos, teoria de decisão e inteligência artificial.
Basicamente, precisamos saber como jogar assumindo quais serão os possíveis movimentos do oponente e pegar o melhor cenário possível.
Em detalhes, pegamos o cenário atual e recursivamente verificamos o resultado do movimento de cada jogador, caso o computador ganhar a partida pontuamos com +1, caso perder então pontuamos como -1 e 0 como um empate.
Caso não for o final do jogo, abrimos outra árvore a partir do estado atual. Feito isto encontramos a jogada com o valor máximo para o computador e a mínima para o adversário.
Veja o diagrama abaixo, existem 3 movimentos disponíveis: B2, C1 e C3.
Escolhendo C1 ou C3, o oponente tem uma chance de ganhar no próximo turno, já escolhendo B2 independente do movimento do adversário ganhamos a partida.
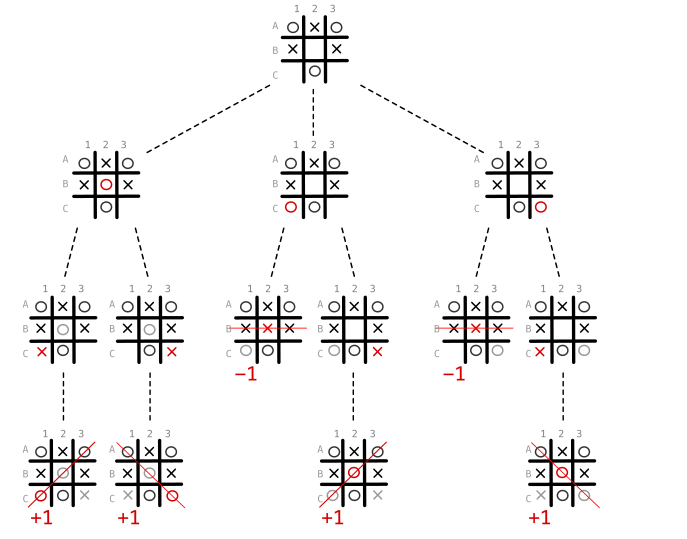
É como ter a joia do tempo em suas mãos para encontrar a melhor linha do tempo.

Convertendo para python
```python
ClassMethod ComputerMove() As %String [ Language = python ]
{
import iris
from math import inf as infinity
computerLetter = "O"
playerLetter = "X"
def isBoardFull(board):
for i in range(0, 8):
if isSpaceFree(board, i):
return False
return True
def makeMove(board, letter, move):
board[move] = letter
def isWinner(brd, let):
# check horizontals
if ((brd[0] == brd[1] == brd[2] == let) or \
(brd[3] == brd[4] == brd[5] == let) or \
(brd[6] == brd[7] == brd[8] == let)):
return True
# check verticals
if ((brd[0] == brd[3] == brd[6] == let) or \
(brd[1] == brd[4] == brd[7] == let) or \
(brd[2] == brd[5] == brd[8] == let)):
return True
# check diagonals
if ((brd[0] == brd[4] == brd[8] == let) or \
(brd[2] == brd[4] == brd[6] == let)):
return True
return False
def isSpaceFree(board, move):
#Retorna true se o espaco solicitado esta livre no quadro
if(board[move] == ''):
return True
else:
return False
def copyGameState(board):
dupeBoard = []
for i in board:
dupeBoard.append(i)
return dupeBoard
def getBestMove(state, player):
done = "Done" if isBoardFull(state) else ""
if done == "Done" and isWinner(state, computerLetter): # If Computer won
return 1
elif done == "Done" and isWinner(state, playerLetter): # If Human won
return -1
elif done == "Done": # Draw condition
return 0
# Minimax Algorithm
moves = []
empty_cells = []
for i in range(0,9):
if state[i] == '':
empty_cells.append(i)
for empty_cell in empty_cells:
move = {}
move['index'] = empty_cell
new_state = copyGameState(state)
makeMove(new_state, player, empty_cell)
if player == computerLetter:
result = getBestMove(new_state, playerLetter)
move['score'] = result
else:
result = getBestMove(new_state, computerLetter)
move['score'] = result
moves.append(move)
# Find best move
best_move = None
if player == computerLetter:
best = -infinity
for move in moves:
if move['score'] > best:
best = move['score']
best_move = move['index']
else:
best = infinity
for move in moves:
if move['score'] < best:
best = move['score']
best_move = move['index']
return best_move
lines = ['A', 'B', 'C']
game = []
current_game_state = iris.gref("^TicTacToe")
for line in lines:
for cell in current_game_state[line].split("^"):
game.append(cell)
cellNumber = getBestMove(game, computerLetter)
next_move = lines[int(cellNumber/3)]+ str(int(cellNumber%3)+1)
return next_move
}
```
Primeiro converto a global em um array simples, ignorando colunas e linhas deixando flat para facilitar.
A cada movimento analisado chamamos o método copyGameState, que como o nome diz, copia o estado do jogo naquele momento, onde aplicamos o MinMax.
O método getBestMove que será chamado recursivamente até finalizar o jogo encontrando um vencedor ou o empate.
Primeiro os espaços vazios são mapeados e verificamos o resultado de cada movimento alternando entre os jogadores.
Os resultados são armazenados em move['score'] para depois de verificar todas as possibilidades encontrar o melhor movimento.
Espero que você tenha se divertido, é possível melhorar a inteligência utilizando algoritmos como Alpha-Beta Pruning ([Wikipedia: AlphaBeta Pruning](https://en.wikipedia.org/wiki/Alpha%E2%80%93beta_pruning)) ou redes neurais, só cuidado para não dar vida a Skynet.

Fique livre para deixar comentários ou perguntas
That's all folks
Código completo:
[InterSystems Iris versão 2021.1.0PYTHON](https://www.notion.so/5be7e2147955bec0f623b718cfd83a9d)
Artigo
Henrique Dias · Nov. 25, 2020
Fala galera! Tudo bem?
Quando @Evgeny.Shvarov anunciou o primeiro InterSystems IRIS Programming Contest, Comecei a pensar em algumas ideias.
Coloquei tudo junto nesse aplicativo e o isc-utils é sobre isso:
Conversões
Temperatura
Distância
Câmbio de Moedas
Clima
Conversão de Escala de Temperatura
IRISAPP>write ##class(diashenrique.Utils.Temperature).CelsiusToFahrenheit(28)
82.4
IRISAPP>write ##class(diashenrique.Utils.Temperature).CelsiusToKelvin(28)
301.15
IRISAPP>write ##class(diashenrique.Utils.Temperature).FahrenheitToCelsius(82.4)
28
IRISAPP>write ##class(diashenrique.Utils.Temperature).FahrenheitToKelvin(82.4)
301.15
IRISAPP>write ##class(diashenrique.Utils.Temperature).KelvinToCelsius(301.15)
28
IRISAPP>write ##class(diashenrique.Utils.Temperature).KelvinToFahrenheit(301.15)
82.37
Conversão de Escala de Distância
IRISAPP>write ##class(diashenrique.Utils.Length).KmToMiles(120)
74.58
IRISAPP>write ##class(diashenrique.Utils.Length).MilesToKm(74.58)
120
Taxa de Câmbio
IRISAPP>do ##class(diashenrique.Utils.ExchangeRate).Latest(1,"USD","ALL")
Date: 2020-03-18
Conversion of 1 USD
GBP Pound sterling 0.843
HKD Hong Kong dollar 7.766
IDR Indonesian rupiah 15449.552
ILS Israeli shekel 3.810
DKK Danish krone 6.835
INR Indian rupee 74.205
CHF Swiss franc 0.965
MXN Mexican peso 23.963
CZK Czech koruna 24.834
SGD Singapore dollar 1.441
THB Thai baht 32.420
HRK Croatian kuna 6.945
EUR Euro 0.915
MYR Malaysian ringgit 4.371
NOK Norwegian krone 10.701
CNY Chinese yuan renminbi 7.035
BGN Bulgarian lev 1.789
PHP Philippine peso 51.620
PLN Polish zloty 4.117
ZAR South African rand 16.977
CAD Canadian dollar 1.440
ISK Icelandic krona 139.656
BRL Brazilian real 5.134
RON Romanian leu 4.431
NZD New Zealand dollar 1.713
TRY Turkish lira 6.447
JPY Japanese yen 107.719
RUB Russian rouble 79.656
KRW South Korean won 1260.106
USD US dollar 1.000
AUD Australian dollar 1.698
HUF Hungarian forint 321.365
SEK Swedish krona 10.081
Parâmetros:
Quantia
Moeda base. Ex.: JPY
Taxas de Câmbio
ALL - para todas as moedas disponíveis na API
Taxas de câmbio de moedas específicas. Ex.: "BRL,AUD,CAD,RUB"
Por data
IRISAPP>do ##class(diashenrique.Utils.ExchangeRate).ByDate("2020-01-01",1,"USD","BRL,JPY,AUD,CAD")
Date: 2020-01-01
Conversion of 1 USD
JPY Japanese yen 108.545
AUD Australian dollar 1.424
CAD Canadian dollar 1.299
BRL Brazilian real 4.020
Parâmetros:
Data = YYYY-MM-DD
Quantia
Moeda base. Ex.: BRL
Taxas de Câmbio
ALL - para todas as moedas disponíveis na API
Taxas de câmbio de moedas específicas. Ex.: "BRL,AUD,CAD,RUB"
Existe uma global ^defaultCurrency, que mantém suas opções de moedas preferidas.
Sendo assim, você pode chamar o ClassMethod Latest, sem nenhum parâmetro
IRISAPP>do ##class(diashenrique.Utils.ExchangeRate).Latest()
Default Base Currency:
Apenas informe a moeda base de sua preferência:
IRISAPP>do ##class(diashenrique.Utils.ExchangeRate).Latest()
Default Base Currency: USD
Date: 2020-03-18
Conversion of 1 USD
GBP Pound sterling 0.843
HKD Hong Kong dollar 7.766
IDR Indonesian rupiah 15449.552
ILS Israeli shekel 3.810
DKK Danish krone 6.835
INR Indian rupee 74.205
CHF Swiss franc 0.965
MXN Mexican peso 23.963
CZK Czech koruna 24.834
SGD Singapore dollar 1.441
THB Thai baht 32.420
HRK Croatian kuna 6.945
EUR Euro 0.915
MYR Malaysian ringgit 4.371
NOK Norwegian krone 10.701
CNY Chinese yuan renminbi 7.035
BGN Bulgarian lev 1.789
PHP Philippine peso 51.620
PLN Polish zloty 4.117
ZAR South African rand 16.977
CAD Canadian dollar 1.440
ISK Icelandic krona 139.656
BRL Brazilian real 5.134
RON Romanian leu 4.431
NZD New Zealand dollar 1.713
TRY Turkish lira 6.447
JPY Japanese yen 107.719
RUB Russian rouble 79.656
KRW South Korean won 1260.106
USD US dollar 1.000
AUD Australian dollar 1.698
HUF Hungarian forint 321.365
SEK Swedish krona 10.081
Clima
IRISAPP>do ##class(diashenrique.Utils.Weather).GetWeather()
Default City:
Default Country:
Default Termo Scale(C,F,K):
O ClassMethod GetWeather, tem opções de preferência também. Para possibilidades padrão, temos:
Cidade
País
Escala de Temperatura (Celsius, Fahrenheit ou Kelvin)
IRISAPP>do ##class(diashenrique.Utils.Weather).GetWeather()
Default City: Boston
Default Country: USA
Default Termo Scale(C,F,K): F
City: Boston | Country: USA
Temperature: 53.46 °F
Real Feel: 46.02 °F
Condition: Clear
Mas, você pode consultar qualquer outra cidade apenas passando os parâmetros:
IRISAPP>do ##class(diashenrique.Utils.Weather).GetWeather("Sao Paulo","Brazil","C")
City: Sao Paulo | Country: Brazil
Temperature: 27.55 °C
Real Feel: 28.4 °C
Condition: Rain
Depois de definir seus parâmetros padrão, eles se tornam opcionais:
IRISAPP>do ##class(diashenrique.Utils.Weather).GetWeather("Sao Paulo","Brazil")
City: Sao Paulo | Country: Brazil
Temperature: 82.17 °F
Real Feel: 83.95 °F
Condition: Rain
Artigo
Cristiano Silva · Jun. 7, 2023
Você já deve ter ouvido falar que, a partir das versões IRIS e HealthShare HealthConnect 2023.2, o Apache Server interno será removido da instalação padrão, então será necessário ter um servidor de aplicativos externo como Apache Server ou NGINX.
Neste artigo, procederei à instalação de um HealthShare HealthConnect 2023.1 para que funcione com um servidor Apache pré-instalado. Para isso usarei uma máquina virtual na qual instalei um Ubuntu 22.04.
Instalando Apache Server
Como indicamos, devemos instalar previamente nosso servidor Apache e o faremos seguindo as etapas indicadas em seu próprio site.
sudo apt update
sudo apt install apache2
Com o servidor Apache instalado, vamos prosseguir com a instalação do HealthConnect.
Instalando HealthConnect
Vamos revisar o que a documentação oficial da InterSystems nos diz. Se você consultar a documentação, ela nos informa como descompactar o arquivo que baixamos do WRC. No meu caso, terei que fazer alguns ajustes, pois tenho o instalador do HealthConnect em uma pasta compartilhada com minha máquina virtual.
mkdir /tmp/iriskit
chmod og+rx /tmp/iriskit
umask 022
gunzip -c /mnt/hgfs/shared/HealthConnect-2023.1.0.229.0-lnxubuntu2204x64.tar.gz | ( cd /tmp/iriskit ; tar xf - )
Vamos revisar o que estamos fazendo com esses comandos:
Criamos o diretório onde vamos descompactar nossa fonte HealthConnect.
Damos permissões de leitura e execução do diretório criado tanto ao proprietário do arquivo quanto a todos os usuários do grupo do proprietário para poder descompactar o arquivo no diretório indicado.
Damos permissões de leitura, gravação e execução em todos os arquivos e diretórios que serão criados.
Descompactamos o arquivo gz e acessando o caminho onde o descompactamos, descompactamos o arquivo tar.
Vamos ver como ficou nosso diretório temporário.
Perfeito, aqui temos o código do nosso HealthShare HealthConnect. Próximo passo, crie um usuário que será o dono da instalação do HealthConnect, vamos chamá-lo de irisusr e a partir do nosso diretório temporário executaremos o comando de instalação:
sudo useradd irisusr
sudo sh irisinstall
Ao executar a instalação, veremos uma série de opções que teremos que configurar com os valores que desejamos. Neste caso vamos realizar uma instalação PERSONALIZADA para poder configurar o WebGateway com o servidor web Apache
Continuando...
Neste ponto devemos indicar que queremos configurar o Web Gateway com o Apache Web Server já implantado em nosso servidor e continuar definindo seu caminho de instalação.
Configuração do Apache Server
A instalação configurará automaticamente o Web Gateway para funcionar com o servidor Apache e nossa instância APACHETEST do HealthConnect. Neste exemplo, sendo Ubuntu 22.0.4, o arquivo de configuração do Apache está localizado no caminho /etc/apache2/apache2.conf , para outras distribuições Linux você pode consultar a documentação.
Se abrirmos o arquivo apache2.conf e rolar até o final dele, podemos verificar as alterações introduzidas pela instalação do Web Gateway:
Esta configuración está redirigiendo todas las llamadas que reciba el puerto 80 (puerto en el que Apache Server escucha por defecto) con la ruta /csp a nuestro Web Gateway, el cual a su vez enviará la llamada a nuestra instancia de HealthConnect. Por defecto el parámetro CSPFileTypes está configurada únicamente para redireccionar los archivos de tipo "csp cls zen cxw", para poder trabajar con el portal de gestión sin inconveniente lo hemos modificado para aceptar todos los tipos "*". El cambio de CSPFileTypes exige reiniciar Apache Server.
Esta configuração está redirecionando todas as chamadas recebidas pela porta 80 (a porta padrão do Apache Server) com a rota /csp para nosso Web Gateway, que por sua vez enviará a chamada para nossa instância HealthConnect. Por padrão, o parâmetro CSPFileTypes é configurado apenas para redirecionar arquivos do tipo "csp cls zen cxw", para trabalhar com o portal de gerenciamento sem nenhum problema, modificaremos para aceitar todos os tipos "*". Alterar os CSPFileTypes requer uma reinicialização do Servidor Apache.
Acceso ao Portal de Gerenciamento do Sistema
Muito bem, temos nosso Apache escutando na porta 80, nosso Web Gateway configurado e a instância HealthConnect iniciada. Vamos testar o acesso ao Portal de Derenciamento do Sistema usando a porta 80 do Apache.
No meu caso, a URL de acesso será http://192.168.31.214/csp/sys/%25CSP.Portal.Home.zen, como a porta 80 é a porta padrão, não será necessário incluí-la na URL.
Aquí tenemos nuestro portal de gestión plenamente operativo. Introduzcamos el usuario y la contraseña que definimos durante la instalación y abramos la configuración del Web Gateway desde la opción System Administrator --> Configuration --> Web Gateway Management. Esta vez el usuario de acceso será CSPSystem. Recordemos que el Web Gateway está configurado para funcionar con el Apache Web Server que hemos instalado previamente.
Aqui temos nosso portal de gestão totalmente operacional. Vamos inserir o nome de usuário e a senha que definimos durante a instalação e abrir a configuração do Web Gateway na opção System Administrator --> Configuration --> Web Gateway Management. Desta vez o usuário de acesso será o CSPSystem. Lembre-se de que o Web Gateway está configurado para funcionar com o Apache Web Server que instalamos anteriormente.
Vamos acessar a opção Server Access para verificar a configuração da nossa instância HealthConnect no Web Gateway:
Temos nossa instância. Vamos verificar como o Web Gateway gerencia as chamadas recebidas do servidor Apache abrindo a opção Application Access.
Vamos ver o que ele faz com URLs começando com /csp
Aí está nossa instância configurada por padrão para receber as chamadas que chegam ao nosso Servidor Apache.
Já temos nossa instância do HealthShare HealthConnect configurada para funcionar com um servidor Apache externo e o Web Gateway. Se você tiver alguma dúvida ou sugestão, sinta-se à vontade para nos enviar um comentário.
Artigo
Heloisa Paiva · Abr. 1
Frequentemente, clientes, fornecedores ou equipes internas me pedem para explicar o planejamento de capacidade de CPU para _para grandes bancos de dados de produção_ rodando no VMware vSphere.
Em resumo, existem algumas práticas recomendadas simples a seguir para dimensionar a CPU para grandes bancos de dados de produção:
- Planeje um vCPU por núcleo de CPU físico.
- Considere o NUMA e, idealmente, dimensione as VMs para manter a CPU e a memória locais para um nó NUMA.
- Dimensione as máquinas virtuais corretamente. Adicione vCPUs apenas quando necessário.
Geralmente, isso leva a algumas perguntas comuns:
- Devido ao hyper-threading, o VMware me permite criar VMs com o dobro do número de CPUs físicas. Isso não dobra a capacidade? Não devo criar VMs com o máximo de CPUs possível?
- O que é um nó NUMA? Devo me preocupar com o NUMA?
- As VMs devem ser dimensionadas corretamente, mas como sei quando estão?
Respondo a estas perguntas com exemplos abaixo. Mas também lembre-se, as melhores práticas não são imutáveis. Às vezes, você precisa fazer concessões. Por exemplo, é provável que grandes VMs de banco de dados de produção NÃO caibam em um nó NUMA e, como veremos, isso está OK. As melhores práticas são diretrizes que você terá que avaliar e validar para seus aplicativos e ambiente.~
Embora eu esteja escrevendo isso com exemplos para bancos de dados rodando em plataformas de dados InterSystems, os conceitos e regras se aplicam geralmente ao planejamento de capacidade e desempenho para qualquer VM grande (Monstro).
Para melhores práticas de virtualização e mais posts sobre planejamento de desempenho e capacidade;
[Uma lista de outros posts na série de Plataformas de Dados InterSystems e desempenho está aqui.](https://community.intersystems.com/post/capacity-planning-and-performance-series-index)
#VMs Monstruosas
Este post é principalmente sobre a implantação de _VMs Monstruosas _, às vezes chamadas de _VMs Largas_. Os requisitos de recursos de CPU de bancos de dados de alta transação significam que eles são frequentemente implantados em VMs Monstruosas.
> Uma VM monstruosa é uma VM com mais CPUs virtuais ou memória do que um nó NUMA físico.
# Arquitetura de CPU e NUMA
A arquitetura de processador Intel atual possui arquitetura de Memória de Acesso Não Uniforme (NUMA). Por exemplo, os servidores que estou usando para executar testes para este post têm:
- Dois sockets de CPU, cada um com um processador de 12 núcleos (Intel E5-2680 v3).
- 256 GB de memória (16 x 16GB RDIMM)
Cada processador de 12 núcleos tem sua própria memória local (128 GB de RDIMMs e cache local) e também pode acessar a memória em outros processadores no mesmo host. Os pacotes de 12 núcleos de CPU, cache de CPU e 128 GB de memória RDIMM são um nó NUMA. Para acessar a memória em outro processador, os nós NUMA são conectados por uma interconexão rápida.
Processos em execução em um processador que acessam a memória RDIMM e Cache local têm menor latência do que atravessar a interconexão para acessar a memória remota em outro processador. O acesso através da interconexão aumenta a latência, então o desempenho não é uniforme. O mesmo design se aplica a servidores com mais de dois sockets. Um servidor Intel de quatro sockets tem quatro nós NUMA.
O ESXi entende o NUMA físico e o agendador de CPU do ESXi é projetado para otimizar o desempenho em sistemas NUMA. Uma das maneiras pelas quais o ESXi maximiza o desempenho é criar localidade de dados em um nó NUMA físico. Em nosso exemplo, se você tiver uma VM com 12 vCPUs e menos de 128 GB de memória, o ESXi atribuirá essa VM para ser executada em um dos nós NUMA físicos. O que leva à regra;
> Se possível, dimensione as VMs para manter a CPU e a memória locais em um nó NUMA.
Se você precisar de uma VM Monstruosa maior que um nó NUMA, está OK, o ESXi faz um trabalho muito bom calculando e gerenciando automaticamente os requisitos. Por exemplo, o ESXi criará nós NUMA virtuais (vNUMA) que agendam de forma inteligente nos nós NUMA físicos para um desempenho ideal. A estrutura vNUMA é exposta ao sistema operacional. Por exemplo, se você tiver um servidor host com dois processadores de 12 núcleos e uma VM com 16 vCPUs, o ESXi pode usar oito núcleos físicos em cada um dos dois processadores para agendar vCPUs da VM, o sistema operacional (Linux ou Windows) verá dois nós NUMA.
Também é importante dimensionar corretamente suas VMs e não alocar mais recursos do que o necessário, pois isso pode levar a recursos desperdiçados e perda de desempenho. Além de ajudar a dimensionar para NUMA, é mais eficiente e resultará em melhor desempenho ter uma VM de 12 vCPUs com alta (mas segura) utilização de CPU do que uma VM de 24 vCPUs com utilização de CPU de VM baixa ou mediana, especialmente se houver outras VMs neste host precisando ser agendadas e competindo por recursos. Isso também reforça a regra;
> Dimensione as máquinas virtuais corretamente.
__Nota:__ Existem diferenças entre as implementações NUMA da Intel e da AMD. A AMD tem múltiplos nós NUMA por processador. Já faz um tempo desde que vi processadores AMD em um servidor de cliente, mas se você os tiver, revise o layout NUMA como parte do seu planejamento.
## VMs Largas e Licenciamento
Para o melhor agendamento NUMA, configure VMs largas;
Correção Junho de 2017: Configure VMs com 1 vCPU por socket.
Por exemplo, por padrão, uma VM com 24 vCPUs deve ser configurada como 24 sockets de CPU, cada um com um núcleo.
>Siga as regras de melhores práticas do VMware..
Consulte [este post nos blogs do VMware para exemplos. ](https://blogs.vmware.com/performance/2017/03/virtual-machine-vcpu-and-vnuma-rightsizing-rules-of-thumb.html)
O post do blog do VMware entra em detalhes, mas o autor, Mark Achtemichuk, recomenda as seguintes regras práticas:
- Embora existam muitas configurações avançadas de vNUMA, apenas em casos raros elas precisam ser alteradas dos padrões.
- Sempre configure a contagem de vCPU da máquina virtual para ser refletida como Núcleos por Socket, até que você exceda a contagem de núcleos físicos de um único nó NUMA físico.
- Quando você precisar configurar mais vCPUs do que há núcleos físicos no nó NUMA, divida uniformemente a contagem de vCPU pelo número mínimo de nós NUMA.
- Não atribua um número ímpar de vCPUs quando o tamanho da sua máquina virtual exceder um nó NUMA físico.
- Não habilite o Hot Add de vCPU a menos que você esteja OK com o vNUMA sendo desabilitado.
- Não crie uma VM maior que o número total de núcleos físicos do seu host.t.
O licenciamento do Caché conta núcleos, então isso não é um problema, no entanto, para software ou bancos de dados diferentes do Caché, especificar que uma VM tem 24 sockets pode fazer diferença para o licenciamento de software, então você deve verificar com os fornecedores.
# Hyper-threading e o agendador de CPU
Hyper-threading (HT) frequentemente surge em discussões, e ouço: "hyper-threading dobra o número de núcleos de CPU". O que, obviamente, no nível físico, não pode acontecer — você tem tantos núcleos físicos quanto possui. O Hyper-threading deve ser habilitado e aumentará o desempenho do sistema. A expectativa é talvez um aumento de 20% ou mais no desempenho do aplicativo, mas a quantidade real depende do aplicativo e da carga de trabalho. Mas certamente não o dobro.
Como postei no [post de melhores práticas do VMware](https://community.intersystems.com/post/intersystems-data-platforms-and-performance-%E2%80%93-part-9-cach%C3%A9-vmware-best-practice-guide), um bom ponto de partida para dimensionar _grandes VMs de banco de dados de produção_ ié assumir que o vCPU tem dedicação total de núcleo físico no servidor — basicamente ignore o hyper-threading ao planejar a capacidade. Por exemplo;
> Para um servidor host de 24 núcleos, planeje um total de até 24 vCPUs para VMs de banco de dados de produção, sabendo que pode haver folga disponível.
Após dedicar tempo monitorando o desempenho da aplicação, do sistema operacional e do VMware durante os horários de pico de processamento, você pode decidir se uma consolidação de VMs mais alta é possível. Na postagem de melhores práticas, eu estabeleci a regra como;
> Um CPU físico (inclui hyper-threading) = Um vCPU (inclui hyper-threading).
## Por que o Hyper-threading não dobra o CPU
O HT em processadores Intel Xeon é uma forma de criar dois CPUs _lógicos _ CPUsem um núcleo físico. O sistema operacional pode agendar eficientemente nos dois processadores lógicos — se um processo ou thread em um processador lógico estiver esperando, por exemplo, por E/S, os recursos do CPU físico podem ser usados pelo outro processador lógico Apenas um processador lógico pode estar progredindo em qualquer ponto no tempo, então, embora o núcleo físico seja utilizado de forma mais eficiente, _o desempenho não é dobrado_.
Com o HT habilitado na BIOS do host, ao criar uma VM, você pode configurar um vCPU por processador lógico HT. Por exemplo, em um servidor de 24 núcleos físicos com HT habilitado, você pode criar uma VM com até 48 vCPUs. O agendador de CPU do ESXi otimizará o processamento executando os processos das VMs em núcleos físicos separados primeiro (enquanto ainda considera o NUMA). Eu exploro mais adiante na postagem se alocar mais vCPUs do que núcleos físicos em uma VM de banco de dados "Monster" ajuda no escalonamento.
### Co-stop e agendamento de CPU
Após monitorar o desempenho do host e da aplicação, você pode decidir que algum sobrecomprometimento dos recursos de CPU do host é possível. Se esta é uma boa ideia dependerá muito das aplicações e cargas de trabalho. Uma compreensão do agendador e uma métrica chave para monitorar podem ajudá-lo a ter certeza de que você não está sobrecomprometendo os recursos do host.
Às vezes ouço; para que uma VM progrida, deve haver o mesmo número de CPUs lógicos livres que vCPUs na VM. Por exemplo, uma VM de 12 vCPUs deve 'esperar' que 12 CPUs lógicos estejam 'disponíveis' antes que a execução progrida. No entanto, deve-se notar que, no ESXi após a versão 3, este não é o caso. O ESXi usa co-agendamento relaxado para CPU para melhor desempenho da aplicação.
Como múltiplos threads ou processos cooperativos frequentemente se sincronizam uns com os outros, não agendá-los juntos pode aumentar a latência em suas operações. Por exemplo, um thread esperando para ser agendado por outro thread em um loop de espera ocupada (spin loop). Para melhor desempenho, o ESXi tenta agendar o máximo possível de vCPUs irmãs juntas. Mas o agendador de CPU pode agendar vCPUs de forma flexível quando há múltiplas VMs competindo por recursos de CPU em um ambiente consolidado. Se houver muita diferença de tempo, enquanto algumas vCPUs progridem e outras irmãs não (a diferença de tempo é chamada de skew), então a vCPU líder decidirá se interrompe a si mesma (co-stop). Observe que são as vCPUs que fazem co-stop (ou co-start), não a VM inteira. Isso funciona muito bem mesmo quando há algum sobrecomprometimento de recursos, no entanto, como você esperaria; muito sobrecomprometimento de recursos de CPU inevitavelmente impactará o desempenho. Mostro um exemplo de sobrecomprometimento e co-stop mais adiante no Exemplo 2.
Lembre-se que não é uma corrida direta por recursos de CPU entre VMs; o trabalho do agendador de CPU do ESXi é garantir que políticas como shares de CPU, reservas e limites sejam seguidas, maximizando a utilização da CPU e garantindo justiça, throughput, responsividade e escalabilidade. Uma discussão sobre o uso de reservas e shares para priorizar cargas de trabalho de produção está além do escopo desta postagem e depende da sua aplicação e mix de cargas de trabalho. Posso revisitar isso em um momento posterior se encontrar alguma recomendação específica do Caché. Existem muitos fatores que entram em jogo com o agendador de CPU, esta seção apenas arranha a superfície. Para um mergulho profundo, consulte o white paper da VMware e outros links nas referências no final da postagem.
# Exemplos
Para ilustrar as diferentes configurações de vCPU, executei uma série de benchmarks usando um aplicativo de Sistema de Informação Hospitalar baseado em navegador com alta taxa de transações. Um conceito semelhante ao benchmark de banco de dados DVD Store desenvolvido pela VMware.
Os scripts para o benchmark são criados com base em observações e métricas de implementações hospitalares reais e incluem fluxos de trabalho, transações e componentes de alto uso que utilizam os maiores recursos do sistema. VMs de driver em outros hosts simulam sessões web (usuários) executando scripts com dados de entrada aleatórios em taxas de transação de fluxo de trabalho definidas. Um benchmark com uma taxa de 1x é a linha de base. As taxas podem ser aumentadas e diminuídas em incrementos.
Juntamente com as métricas do banco de dados e do sistema operacional, uma boa métrica para avaliar o desempenho da VM do banco de dados do benchmark é o tempo de resposta do componente (que também pode ser uma transação) medido no servidor. Um exemplo de um componente é parte de uma tela do usuário final. Um aumento no tempo de resposta do componente significa que os usuários começariam a ver uma mudança para pior no tempo de resposta do aplicativo. Um sistema de banco de dados com bom desempenho deve fornecer alto desempenho _consistente_ para os usuários finais. Nos gráficos a seguir, estou medindo em relação ao desempenho consistente do teste e uma indicação da experiência do usuário final, calculando a média do tempo de resposta dos 10 componentes de alto uso mais lentos. O tempo de resposta médio do componente deve ser inferior a um segundo, uma tela de usuário pode ser composta por um componente, ou telas complexas podem ter muitos componentes.
> Lembre-se de que você sempre está dimensionando para a carga de trabalho máxima, mais um buffer para picos inesperados de atividade. Geralmente, busco uma utilização média de 80% da CPU no pico.
Uma lista completa do hardware e software do benchmark está no final da postagem.
## Exemplo 1. Dimensionamento correto - VM "monstro" única por host
É possível criar uma VM de banco de dados dimensionada para usar todos os núcleos físicos de um servidor host, por exemplo, uma VM de 24 vCPUs em um host de 24 núcleos físicos. Em vez de executar o servidor "bare-metal" em um espelho de banco de dados Caché para alta disponibilidade (HA) ou introduzir a complicação do clustering de failover do sistema operacional, a VM do banco de dados é incluída em um cluster vSphere para gerenciamento e HA, por exemplo, DRS e VMware HA.
Tenho visto clientes seguirem o pensamento da velha guarda e dimensionarem uma VM de banco de dados primária para a capacidade esperada no final da vida útil de cinco anos do hardware, mas como sabemos acima, é melhor dimensionar corretamente; você obterá melhor desempenho e consolidação se suas VMs não forem superdimensionadas e o gerenciamento de HA será mais fácil; pense em Tetris se houver manutenção ou falha do host e a VM monstro do banco de dados tiver que migrar ou reiniciar em outro host. Se a taxa de transações for prevista para aumentar significativamente, os vCPUs podem ser adicionados antecipadamente durante a manutenção planejada.
> Observação, a opção de 'adicionar a quente' (hot add) de CPU desativa o vNUMA, portanto, não a use para VMs monstro.
Considere o seguinte gráfico mostrando uma série de testes no host de 24 núcleos. A taxa de transações 3x é o ponto ideal e a meta de planejamento de capacidade para este sistema de 24 núcleos.
- Uma única VM está sendo executada no host.
- Quatro tamanhos de VM foram usados para mostrar o desempenho em 12, 24, 36 e 48 vCPUs.
- Taxas de transação (1x, 2x, 3x, 4x, 5x) foram executadas para cada tamanho de VM (se possível).
- O desempenho/experiência do usuário é mostrado como o tempo de resposta do componente (barras).
- Utilização média da CPU% na VM convidada (linhas).
- A utilização da CPU do host atingiu 100% (linha tracejada vermelha) na taxa de 4x para todos os tamanhos de VM.

Há muita coisa acontecendo neste gráfico, mas podemos nos concentrar em algumas coisas interessantes.
- A VM com 24 vCPUs (laranja) escalou suavemente para a taxa de transação alvo de 3x. Com a taxa de 3x, a VM convidada está com uma média de 76% de CPU (picos foram em torno de 91%). A utilização da CPU do host não é muito maior do que a da VM convidada. O tempo de resposta do componente é praticamente plano até 3x, então os usuários estão satisfeitos. Quanto à nossa taxa de transação alvo — esta _VM está dimensionada corretamente_.
Então, chega de dimensionamento correto, e quanto a aumentar as vCPUs, o que significa usar hyper threads? É possível dobrar o desempenho e a escalabilidade? A resposta curta é _Não!_
Neste caso, a resposta pode ser vista observando o tempo de resposta do componente a partir de 4x. Embora o desempenho seja "melhor" com mais núcleos lógicos (vCPUs) alocados, ele ainda não é plano e consistente como era até 3x. Os usuários relatarão tempos de resposta mais lentos em 4x, independentemente de quantas vCPUs forem alocadas. Lembre-se que em 4x o _host _ já está no limite, com 100% de utilização da CPU, conforme relatado pelo vSphere. Em contagens de vCPU mais altas, mesmo que as métricas de CPU do convidado (vmstat) estejam relatando menos de 100% de utilização, esse não é o caso para os recursos físicos. Lembre-se que o sistema operacional convidado não sabe que está virtualizado e está apenas relatando os recursos apresentados a ele. Observe também que o sistema operacional convidado não vê threads HT, todas as vCPUs são apresentadas como núcleos físicos.
O ponto é que os processos do banco de dados (existem mais de 200 processos Caché na taxa de transação 3x) estão muito ocupados e fazem um uso muito eficiente dos processadores, não há muita folga para os processadores lógicos agendarem mais trabalho ou consolidarem mais VMs neste host. Por exemplo, grande parte do processamento do Caché está ocorrendo na memória, então não há muita espera por IO. Portanto, embora você possa alocar mais vCPUs do que núcleos físicos, não há muito a ganhar porque o host já está 100% utilizado.
Caché é muito bom em lidar com altas cargas de trabalho. Mesmo quando o host e a VM estão com 100% de utilização da CPU, o aplicativo ainda está em execução e a taxa de transações ainda está aumentando — o escalonamento não é linear e, como podemos ver, os tempos de resposta estão ficando mais longos e a experiência do usuário sofrerá — mas o aplicativo não "cai de um penhasco" e, embora não seja um bom lugar para se estar, os usuários ainda podem trabalhar. Se você tiver um aplicativo que não é tão sensível aos tempos de resposta, é bom saber que você pode empurrar até o limite, e além, e o Caché ainda funciona com segurança.
> Lembre-se de que você não deseja executar sua VM de banco de dados ou seu host com 100% de utilização da CPU. Você precisa de capacidade para picos inesperados e crescimento na VM, e o hipervisor ESXi precisa de recursos para todas as atividades de rede, armazenamento e outras que realiza.
Eu sempre planejo para picos de 80% de utilização da CPU. Mesmo assim, dimensionar a vCPU apenas até o número de núcleos físicos deixa alguma folga para o hipervisor ESXi em threads lógicos, mesmo em situações extremas.
>Se você estiver executando uma solução hiperconvergente (HCI), você DEVE também considerar os requisitos de CPU do HCI no nível do host. Veja minha [postagem anterior sobre HCI ](https://community.intersystems.com/post/intersystems-data-platforms-and-performance-%E2%80%93-part-8-hyper-converged-infrastructure-capacity "previous post on HCI") para mais detalhes. O dimensionamento básico da CPU de VMs implantadas em HCI é o mesmo que o de outras VMs.
Lembre-se, você deve validar e testar tudo em seu próprio ambiente e com seus aplicativos.
##Exemplo 2. Recursos supercomprometidos
Tenho visto sites de clientes relatando desempenho "lento" do aplicativo enquanto o sistema operacional convidado relata que há recursos de CPU de sobra.
Lembre-se de que o sistema operacional convidado não sabe que está virtualizado. Infelizmente, as métricas do convidado, por exemplo, conforme relatado pelo vmstat (por exemplo, em pButtons) podem ser enganosas, você também deve obter métricas de nível de host e métricas ESXi (por exemplo `esxtop`) para realmente entender a saúde e a capacidade do sistema.
Como você pode ver no gráfico acima, quando o host está relatando 100% de utilização, a VM convidada pode estar relatando uma utilização menor. A VM de 36 vCPU (vermelha) está relatando 80% de utilização média da CPU na taxa de 4x, enquanto o host está relatando 100%. Mesmo uma VM dimensionada corretamente pode ser privada de recursos, se, por exemplo, após a entrada em produção, outras VMs forem migradas para o host ou os recursos forem supercomprometidos por meio de regras DRS mal configuradas.
Para mostrar as principais métricas, para esta série de testes, configurei o seguinte:
- Duas VMs de banco de dados em execução no host.
- - uma de 24 vCPU em execução a uma taxa de transação constante de 2x (não mostrada no gráfico).
- -uma de 24 vCPU em execução a 1x, 2x, 3x (essas métricas são mostradas no gráfico).
Com outro banco de dados usando recursos; na taxa de 3x, o sistema operacional convidado (RHEL 7) vmstat está relatando apenas 86% de utilização média da CPU e a fila de execução tem uma média de apenas 25. No entanto, os usuários deste sistema estarão reclamando alto, pois o tempo de resposta do componente disparou à medida que os processos são desacelerados.
Como mostrado no gráfico a seguir, Co-stop e Tempo de Preparo contam a história de por que o desempenho do usuário é tão ruim. As métricas de Tempo de Preparo (`%RDY`) e CoStop (`%CoStop`) mostram que os recursos da CPU estão massivamente supercomprometidos na taxa alvo de 3x. Isso realmente não deveria ser uma surpresa, já que o _host_ está executando 2x (outra VM) _e_ a taxa de 3x desta VM de banco de dados.

O gráfico mostra que o tempo de espera (Ready time) aumenta quando a carga total da CPU no host aumenta.
> Tempo de espera (Ready time) é o tempo em que uma VM está pronta para executar, mas não pode porque os recursos da CPU não estão disponíveis.
O co-stop também aumenta. Não há CPUs lógicas livres suficientes para permitir que a VM do banco de dados avance (como detalhei na seção HT acima). O resultado final é que o processamento é atrasado devido à contenção por recursos físicos da CPU.
Eu vi exatamente essa situação em um site de cliente onde nossa visão de suporte de pButtons e vmstat mostrava apenas o sistema operacional virtualizado. Enquanto o vmstat reportava folga de CPU, a experiência de desempenho do usuário era terrível.
A lição aqui é que só quando as métricas do ESXi e uma visão em nível de host foram disponibilizadas é que o problema real foi diagnosticado; recursos de CPU supercomprometidos causados por escassez geral de recursos de CPU do cluster e, para piorar a situação, regras DRS ruins fazendo com que VMs de banco de dados de alta transação migrassem juntas e sobrecarregassem os recursos do host.
## Exemplo 3. Recursos supercomprometidos
Neste exemplo, usei uma VM de banco de dados de linha de base de 24 vCPUs executando a uma taxa de transação 3x, e depois duas VMs de banco de dados de 24 vCPUs a uma taxa de transação constante de 3x.
A utilização média da CPU da linha de base (veja o Exemplo 1 acima) foi de 76% para a VM e 85% para o host. Uma única VM de banco de dados de 24 vCPUs está usando todos os 24 processadores físicos. Executar duas VMs de 24 vCPUs significa que as VMs estão competindo por recursos e estão usando todas as 48 threads de execução lógicas no servidor.

Lembrando que o host não estava 100% utilizado com uma única VM, ainda podemos ver uma queda significativa no throughput e no desempenho, pois duas VMs de 24 vCPUs muito ocupadas tentam usar os 24 núcleos físicos no host (mesmo com HT). Embora o Caché seja muito eficiente ao usar os recursos de CPU disponíveis, ainda há uma queda de 16% no throughput do banco de dados por VM e, mais importante, um aumento de mais de 50% no tempo de resposta do componente (usuário).
## Resumo
Meu objetivo com este post é responder às perguntas comuns. Veja a seção de referência abaixo para um mergulho mais profundo nos recursos de CPU do host e no agendador de CPU do VMware.
Embora existam muitos níveis de ajustes e detalhes técnicos do ESXi para extrair a última gota de desempenho do seu sistema, as regras básicas são bastante simples.
Para _grandes bancos de dados de produção_ :
- Planeje um vCPU por núcleo de CPU físico.
- Considere o NUMA e, idealmente, dimensione as VMs para manter a CPU e a memória locais em um nó NUMA.
- Dimensione corretamente as máquinas virtuais. Adicione vCPUs somente quando necessário.
Se você deseja consolidar VMs, lembre-se de que grandes bancos de dados são muito ocupados e utilizarão intensamente as CPUs (físicas e lógicas) em horários de pico. Não as superinscreva até que seu monitoramento indique que é seguro.
## Referências
- [Blog da VMware - Quando Supercomprometer vCPU:pCPU para VMs Monstruosas](https://blogs.vmware.com/vsphere/2014/02/overcommit-vcpupcpu-monster-vms.html)
- [Introdução à Série de Mergulho Profundo em NUMA 2016](http://frankdenneman.nl/2016/07/06/introduction-2016-numa-deep-dive-series)
- [O Agendador de CPU no VMware vSphere 5.1](http://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/techpaper/vmware-vsphere-cpu-sched-performance-white-paper.pdf)
## Testes
Executei os exemplos neste post em um cluster vSphere composto por dois processadores Dell R730 conectados a um array all-flash. Durante os exemplos, não houve gargalos na rede ou no armazenamento.
- Caché 2016.2.1.803.0
PowerEdge R730
- 2x Intel(R) Xeon(R) CPU E5-2680 v3 @ 2.50GHz
- 16x 16GB RDIMM, 2133 MT/s, Dual Rank, x4 Data Width
- SAS 12Gbps HBA External Controller
- HyperThreading (HT) on
PowerVault MD3420, 12G SAS, 2U-24 drive
- 24x 24 960GB Solid State Drive SAS Read Intensive MLC 12Gbps 2.5in Hot-plug Drive, PX04SR
- 2 Controller, 12G SAS, 2U MD34xx, 8G Cache
VMware ESXi 6.0.0 build-2494585
- As VMs estão configuradas para as melhores práticas; VMXNET3, PVSCSI, etc.
RHEL 7
- Páginas grandes (Large pages)
A taxa de linha de base 1x teve uma média de 700.000 glorefs/segundo (acessos ao banco de dados/segundo). A taxa 5x teve uma média de mais de 3.000.000 glorefs/segundo para 24 vCPUs. Os testes foram permitidos a serem executados até que o desempenho constante fosse alcançado e, em seguida, amostras de 15 minutos foram coletadas e calculadas a média.
> Estes exemplos são apenas para mostrar a teoria, você DEVE validar com sua própria aplicação!
Artigo
Danusa Calixto · Ago. 11, 2022
Olá, comunidade,
Este é o terceiro artigo da série sobre a inicialização de instâncias da IRIS com Docker. Desta vez, focaremos no **E**nterprise **C**ache **P**rotocol (ECP).
De maneira bastante simplificada, o ECP permite configurar algumas instâncias da IRIS como servidores de aplicação e outras como servidores de dados. As informações técnicas detalhadas podem ser encontradas na documentação oficial.
O objetivo deste artigo é descrever o seguinte:
* Como programar a inicialização de um servidor de dados e como programar a inicialização de um ou mais servidores de aplicação.
* Como estabelecer uma conexão criptografada entre os nós com Docker.
Para fazer isso, geralmente, usamos algumas das ferramentas já abordadas nos artigos anteriores sobre Web Gateway e espelhamento (*Mirror*), que descrevem instrumentos como OpenSSL, envsubst e Config-API.
## Requisitos
O ECP não está disponível com a versão da Comunidade da IRIS. Portanto, é necessário o acesso à Central de Suporte (WRC) para fazer o download de uma licença de contêiner e conectar ao registro containers.intersystems.com.
## Preparando o sistema
O sistema precisa compartilhar alguns arquivos locais com os contêineres. É necessário criar determinados usuários e grupos para evitar o erro "acesso negado".
```bash
sudo useradd --uid 51773 --user-group irisowner
sudo useradd --uid 52773 --user-group irisuser
sudo groupmod --gid 51773 irisowner
sudo groupmod --gid 52773 irisuser
```
Se você ainda não tem a licença "iris.key", faça o download na WRC e adicione ao diretório do início.
## Recupere o repositório de amostra
Todos os arquivos necessários estão disponíveis em um repositório público, exceto a licença "iris.key", então comece por clonar:
```bash
git clone https://github.com/lscalese/ecp-with-docker.git
cd ecp-with-docker
```
## Certificados SSL
Para criptografar as comunicações entre os servidores de aplicação e o servidor de dados, precisamos de certificados SSL.
Um script pronto para uso ("gen-certificates.sh") está disponível. No entanto, fique à vontade para modificá-lo, para a consistência das configurações do certificado com sua localização, empresa etc.
Execute:
```bash
sh ./gen-certificates.sh
```
Os certificados gerados estão agora no diretório "./certificates".
| Arquivo | Contêiner | Descrição |
| ------------------------------ | ----------------------------------------- | ------------------------------------------------------------- |
| ./certificates/CA_Server.cer | Servidor de aplicação e servidor de dados | Certificado do servidor da autoridade |
| ./certificates/app_server.cer | Servidor de aplicação | Certificado para a instância do servidor de aplicação da IRIS |
| ./certificates/app_server.key | Servidor de aplicação | Chave privada relacionada |
| ./certificates/data_server.cer | Servidor de dados | Certificado para a instância do servidor de dados da IRIS |
| ./certificates/data_server.key | Servidor de dados | Chave privada relacionada |
## Construa a imagem
Primeiro, faça login no registro docker da InterSystems. A imagem de base será baixada do registro durante a construção:
```bash
docker login -u="YourWRCLogin" -p="YourICRToken" containers.intersystems.com
```
Se você não sabe seu token, faça login em https://containers.intersystems.com/ com a conta da WRC.
Durante essa construção, adicionaremos alguns utilitários de software à imagem de base da IRIS:
* **gettext-base**: permitirá substituir as variáveis do ambiente nos arquivos de configuração com o comando "envsubst".
* **iputils-arping**: é necessário se quisermos espelhar o servidor de dados.
* **ZPM**: gerente de pacotes ObjectScript.
[Dockerfile](https://github.com/lscalese/ecp-with-docker/blob/master/Dockerfile):
```
ARG IMAGE=containers.intersystems.com/intersystems/iris:2022.2.0.281.0
# Não é necessário fazer o download da imagem do WRC. Ela será extraída do ICR no momento da construção.
FROM $IMAGE
USER root
# Installe iputils-arping para ter um comando de arping. É necessário para configurar o IP Virtual.
# Baixe a última versão do ZPM (incluso somente na edição da comunidade).
RUN apt-get update && apt-get install iputils-arping gettext-base && \
rm -rf /var/lib/apt/lists/*
USER ${ISC_PACKAGE_MGRUSER}
WORKDIR /home/irisowner/demo
RUN --mount=type=bind,src=.,dst=. \
iris start IRIS && \
iris session IRIS < iris.script && \
iris stop IRIS quietly
```
Não há nada especial neste Dockerfile, exceto a última linha. Ela configura a instância do servidor de dados da IRIS para aceitar até 3 servidores de aplicação. Atenção: essa configuração exige a reinicialização da IRIS. Atribuímos o valor deste parâmetro durante a construção para evitar a reinicialização do script depois.
Inicie a construção:
```bash
docker-compose build –no-cache
```
## Arquivo de configuração
Para a configuração das instâncias da IRIS (servidores de aplicação e dados), usamos o formato de arquivo SON config-api. Você verá que esses arquivos contêm variáveis de ambiente "${variable_name}". Os valores são definidos nas seções do "ambiente" do arquivo "docker-compose.yml" que veremos ainda neste documento. Essas variáveis serão substituídas logo antes do carregamento dos arquivos usando o utilitário "envsubst".
### Servidor de dados
Para o servidor de dados, vamos:
* Permitir o serviço ECP e definir a lista de clientes autorizados (servidores de aplicação).
* Criar a configuração "SSL %ECPServer" necessária para a criptografia de comunicações.
* Criar uma base de dados "myappdata". Ela será usada como uma base de dados remota dos servidores de aplicação.
(data-serer.json)[https://github.com/lscalese/ecp-with-docker/blob/master/config-files/data-server.json]
```json
{
"Security.Services" : {
"%Service_ECP" : {
"Enabled" : true,
"ClientSystems":"${CLIENT_SYSTEMS}",
"AutheEnabled":"1024"
}
},
"Security.SSLConfigs": {
"%ECPServer": {
"CAFile": "${CA_ROOT}",
"CertificateFile": "${CA_SERVER}",
"Name": "%ECPServer",
"PrivateKeyFile": "${CA_PRIVATE_KEY}",
"Type": "1",
"VerifyPeer": 3
}
},
"Security.System": {
"SSLECPServer":1
},
"SYS.Databases":{
"/usr/irissys/mgr/myappdata/" : {}
},
"Databases":{
"myappdata" : {
"Directory" : "/usr/irissys/mgr/myappdata/"
}
}
}
```
Esse arquivo de configuração é carregado na inicialização do contêiner do servidor de dados pelo script "init_datasrv.sh". Todos os servidores de aplicação conectados ao servidor de dados precisam ser confiáveis. Esse script validará automaticamente todas as conexões dentro de 100 segundos para limitar as ações manuais no portal de administração. É claro que isso pode ser melhorado para aprimorar a segurança.
### Servidor de aplicação
Para os servidores de aplicação, vamos:
* Ativar o serviço ECP.
* Criar a configuração do SLL "%ECPClient" necessária para a criptografia da comunicação.
* Configurar as informações da conexão para o servidor de dados.
* Criar a configuração da base de dados remota "myappdata".
* Criar um mapeamento global "demo.*" no espaço de nome "USER" para a base de dados "myappdata". Isso permitirá o teste da operação do ECP mais tarde.
[app-server.json](https://github.com/lscalese/ecp-with-docker/blob/master/config-files/app-server.json):
```json
{
"Security.Services" : {
"%Service_ECP" : {
"Enabled" : true
}
},
"Security.SSLConfigs": {
"%ECPClient": {
"CAFile": "${CA_ROOT}",
"CertificateFile": "${CA_CLIENT}",
"Name": "%ECPClient",
"PrivateKeyFile": "${CA_PRIVATE_KEY}",
"Type": "0"
}
},
"ECPServers" : {
"${DATASERVER_NAME}" : {
"Name" : "${DATASERVER_NAME}",
"Address" : "${DATASERVER_IP}",
"Port" : "${DATASERVER_PORT}",
"SSLConfig" : "1"
}
},
"Databases": {
"myappdata" : {
"Directory" : "/usr/irissys/mgr/myappdata/",
"Name" : "${REMOTE_DB_NAME}",
"Server" : "${DATASERVER_NAME}"
}
},
"MapGlobals":{
"USER": [{
"Name" : "demo.*",
"Database" : "myappdata"
}]
}
}
```
O arquivo de configuração é carregado na inicialização de um contêiner do servidor de aplicação pelo script "[init_appsrv.sh](https://github.com/lscalese/ecp-with-docker/blob/master/init_appsrv.sh)".
## Inicializando os contêineres
Agora, podemos inicializar os contêineres:
* 2 servidores de aplicação.
* 1 servidor de dados.
Para fazer isso execute:
docker-compose up –scale ecp-demo-app-server=2
Veja mais detalhes no arquivo [docker-compose](https://github.com/lscalese/ecp-with-docker/blob/master/docker-compose.yml):
```
# As variáveis são definidas no arquivo .env
# para mostrar o arquivo docker-compose revolvido, execute
# docker-compose config
version: '3.7'
services:
ecp-demo-data-server:
build: .
image: ecp-demo
container_name: ecp-demo-data-server
hostname: data-server
networks:
app_net:
environment:
# Lista dos clientes ECP permitidos (servidor de aplicação).
- CLIENT_SYSTEMS=ecp-with-docker_ecp-demo-app-server_1;ecp-with-docker_ecp-demo-app-server_2;ecp-with-docker_ecp-demo-app-server_3
# Path authority server certificate
- CA_ROOT=/certificates/CA_Server.cer
# Path to data server certificate
- CA_SERVER=/certificates/data_server.cer
# Path to private key of the data server certificate
- CA_PRIVATE_KEY=/certificates/data_server.key
# Path to Config-API file to initiliaze this IRIS instance
- IRIS_CONFIGAPI_FILE=/home/irisowner/demo/data-server.json
ports:
- "81:52773"
volumes:
# Script após o início - inicialização do servidor de dados.
- ./init_datasrv.sh:/home/irisowner/demo/init_datasrv.sh
# Montar certificados (ver gen-certificates.sh para gerar certificados)
- ./certificates/app_server.cer:/certificates/data_server.cer
- ./certificates/app_server.key:/certificates/data_server.key
- ./certificates/CA_Server.cer:/certificates/CA_Server.cer
# Montar arquivo de configuração
- ./config-files/data-server.json:/home/irisowner/demo/data-server.json
# Licença da IRIS
- ~/iris.key:/usr/irissys/mgr/iris.key
command: -a /home/irisowner/demo/init_datasrv.sh
ecp-demo-app-server:
image: ecp-demo
networks:
app_net:
environment:
# Nome do host ou ID do servidor de dados.
- DATASERVER_IP=data-server
- DATASERVER_NAME=data-server
- DATASERVER_PORT=1972
# Caminho do certificado do servidor de autoridade
- CA_ROOT=/certificates/CA_Server.cer
- CA_CLIENT=/certificates/app_server.cer
- CA_PRIVATE_KEY=/certificates/app_server.key
- IRIS_CONFIGAPI_FILE=/home/irisowner/demo/app-server.json
ports:
- 52773
volumes:
# Após o início do script - inicialização do servidor de aplicação.
- ./init_appsrv.sh:/home/irisowner/demo/init_appsrv.sh
# Montar certificados
- ./certificates/CA_Server.cer:/certificates/CA_Server.cer
# Caminho para a chave privada do certificado do servidor de dados
- ./certificates/app_server.cer:/certificates/app_server.cer
# Caminho para a chave privada do certificado do servidor de dados
- ./certificates/app_server.key:/certificates/app_server.key
# Caminho para o arquivo Config-API inicializar a instância da IRIS
- ./config-files/app-server.json:/home/irisowner/demo/app-server.json
# Licença da IRIS
- ~/iris.key:/usr/irissys/mgr/iris.key
command: -a /home/irisowner/demo/init_appsrv.sh
networks:
app_net:
ipam:
driver: default
config:
# A variável APP_NET_SUBNET é definida no arquivo .env
- subnet: "${APP_NET_SUBNET}"
```
## Vamos testar!
### Acesso ao portal de administração do servidor de dados
Os contêineres foram inicializados. Vamos conferir o status do servidor de dados.
A porta 52773 é mapeada para a porta local 81, então você pode acessar por este endereço: [http://localhost:81/csp/sys/utilhome.csp](http://localhost:81/csp/sys/utilhome.csp)
Entre com o login e a senha padrão e acesse System -> Configuration -> ECP Params. Clique em "ECP Application Servers". Se tudo estiver funcionando, você verá 2 servidores de aplicação com o status "Normal". A estrutura do nome do cliente é "nome do servidor de dados":"hostname do servidor de aplicação":"nome da instância IRIS". No nosso caso, não configuramos os hostnames do servidor de aplicação, então temos hostnames gerados.
### Acessando o portal de administração dos servidores de aplicação
Para se conectar ao portal de administração dos servidores de aplicação, primeiro, você precisa ter o número da porta. Já que usamos a opção "--scale", não conseguimos definir as portas no arquivo docker-compose. Então, precisamos recuperá-las com o comando `docker ps`:
```
docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a1844f38939f ecp-demo "/tini -- /iris-main…" 25 minutes ago Up 25 minutes (unhealthy) 1972/tcp, 2188/tcp, 53773/tcp, 54773/tcp, 0.0.0.0:81->52773/tcp, :::81->52773/tcp ecp-demo-data-server
4fa9623be1f8 ecp-demo "/tini -- /iris-main…" 25 minutes ago Up 25 minutes (unhealthy) 1972/tcp, 2188/tcp, 53773/tcp, 54773/tcp, 0.0.0.0:49170->52773/tcp, :::49170->52773/tcp ecp-with-docker_ecp-demo-app-server_1
ecff03aa62b6 ecp-demo "/tini -- /iris-main…" 25 minutes ago Up 25 minutes (unhealthy) 1972/tcp, 2188/tcp, 53773/tcp, 54773/tcp, 0.0.0.0:49169->52773/tcp, :::49169->52773/tcp ecp-with-docker_ecp-demo-app-server_2
```
Neste exemplo, as portas são:
* 49170 para o primeiro servidor de aplicação http://localhost:49170/csp/sys/utilhome.csp
* 49169 para o segundo servidor de aplicação http://localhost:49169/csp/sys/utilhome.csp
### Teste de leitura/escrita na base de dados remota
Vamos realizar alguns testes de leitura/escrita no terminal.
Abra um terminal IRIS no primeiro servidor de aplicação:
```
docker exec -it ecp-with-docker_ecp-demo-app-server_1 iris session iris
Set ^demo.ecp=$zdt($h,3,1) _ “ write from the first application server.”
```
Agora, abra um terminal no segundo servidor de aplicação:
```
docker exec -it ecp-with-docker_ecp-demo-app-server_2 iris session iris
Set ^demo.ecp(2)=$zdt($h,3,1) _ " write from the second application server."
zwrite ^demo.ecp
```
Você deverá ver as respostas dos dois servidores:
```
^demo.ecp(1)="2022-07-05 23:05:10 write from the first application server."
^demo.ecp(2)="2022-07-05 23:07:44 write from the second application server."
```
Por fim, abra um terminal IRIS no servidor de dados e realize a leitura do global demo.ecp:
```
docker exec -it ecp-demo-data-server iris session iris
zwrite ^["^^/usr/irissys/mgr/myappdata/"]demo.ecp
^["^^/usr/irissys/mgr/myappdata/"]demo.ecp(1)="2022-07-05 23:05:10 write from the first application server."
^["^^/usr/irissys/mgr/myappdata/"]demo.ecp(2)="2022-07-05 23:07:44 write from the second application server."
```
Isso é tudo por hoje. Espero que tenha gostado deste artigo. Não hesite em deixar seus comentários.
Artigo
Yuri Marx · Abr. 10, 2022
O InterSystems HealthShare é uma plataforma integrada de serviços digitais capaz de conectar dados, serviços e processos de negócio em saúde para entregar uma operação harmoniosa baseada em Repositório Eletrônico de Saúde centralizado, HL7, FHIR e outros conhecidos padrões de mercado. Estes serviços digitais permitem:
A troca de dados e documentos clínicos e do negócio na forma de mensagens entre os envolvidos e sistemas internos e externos;
Um repositório corporativo centralizado (unificando dados de todos os centros e unidades de atendimento) de pacientes, fornecedores, profissionais de saúde e unidades de atendimento para consulta e registro centralizado;
A Gestão de consentimentos no acesso aos dados dos pacientes (ótimo para atender à LGPD);
Um Visualizador clínico com o prontuário eletrônico, resultados de exames, histórico de atendimento e demais informações de forma unificada (os dados residentes em cada unidade de atendimento no visualizador);
A disponibilização de API e Barramento SOA para integração e interoperabilidade com terceiros, aplicações internas e externas;
O uso de padrões e terminologia reconhecidos no mercado, especialmente HL7 e FHIR; e
A segurança avançada, com suporte à criptografia, auditoria e gestão de autorização e autenticação de usuários.
Não importa qual o ERP ou Sistema de Gestão Hospitalar que as unidades de saúde utilizam, toda a rede passa a operar orquestrada pelo HealthShare, potencializando as capacidades de gestão, governança e operação de dados, serviços e processos de negócio de toda a rede.
Os problemas a serem resolvidos
As unidades de saúde possuem sistemas de gestão clínica e bancos de dados locais em cada unidade. Além disto, estes sistemas apresentam problemas de interoperabilidade com os demais sistemas da unidade, com grande impacto na qualidade dos dados necessários à operação e ao atendimento dos pacientes, evidenciando os seguintes problemas:
O profissional de saúde não conhece todo o histórico clínico do paciente e não possui acesso aos exames e imagens realizados em outras unidades de saúde onde o paciente esteve. Daí, se originam dois grandes problemas, o primeiro é o custo e a perda de tempo de requisitar novos exames e imagens, o segundo é realizar um diagóstico com menos dados do que seria possível.
O paciente acaba por repetir exames de forma desnecessária, ampliando o tempo de atendimento ou internação, elevando seus custos e muitas vezes seu sofrimento, além de não ter todo o seu histórico de saúde considerado.
O plano de saúde ou o governo gastam dinheiro a mais com novos exames e maior tempo de atendimento e internação, com reflexos no valor do plano de saúde e nos custos de saúde para a Sociedade.
A operação da unidade de saúde se torna mais morosa e deficiente em dados essenciais à qualidade e agilidade no atendimento.
A boa avaliação dos programas de prevenção e combate às doenças é afetada em razão da falta de bom indicadores baseados em dados com qualidade e variedade.
A operação em rede ocorre de forma parcial, muito mais física do que digital, assim cada unidade da rede não consegue oferecer de forma plena todos os dados da operação e do paciente para auxiliar as demais unidades da rede.
Os desafios
A operação em rede é uma realidade, novas aquisições e fusões ocorrem todos os anos. As redes passam a operar com diferentes sistemas de gestão clínica e administrativa/financeira e dezenas de parceiros, incluindo planos de saúde, sistemas de governo, fornecedores, parceiros clínicos, laboratórios, muitos sem qualquer padrão de interoperabilidade na troca de dados. Os dados do paciente estão fragmentados em diferentes unidades, sob diferentes sistemas e ambientes operacionais.
O desafio, indispensável, é conectar os diferentes sistemas internos e externos de todas as unidades da rede de atendimento, dos planos de saúde, do governo, dos laboratórios e demais parceiros para harmonizar e agilizar os processos de atendimento clínico e da operação de negócio de todos os envolvidos para assim atender melhor aos pacientes, reduzir custos e reduzir falhas na operação. É necessário ter:
Um motor informatizado de coleta, transformação e enriquecimento de dados que permita ingerir dados em diferentes formatos e protocolos e unificá-los para consulta e processamento de forma padronizada (FHIR/HL7) e com a qualidade necessária para o melhor diagnóstico.
Um barramento de dados clínicos e da operação que entregue os dados no formato e na periodicidade requeridos por cada sistema interno ou externo às unidades, sejam próprios ou de parceiros.
Um visualizador clínico capaz de unificar todos os dados clínicos, de procedimentos e de histórico do paciente captados em quaisquer das unidades de atendimento, e até mesmo residentes nos parceiros, para permitir ao profissional de saúde ter uma visão 360º e de timeline do paciente, sempre entregando ao paciente a gestão de consentimento no acesso a estes dados.
Um ambiente de análise e exploração científica dos dados de atendimento para acompanhar o desempenho das ações e programas em saúde estabelecidos nas unidades e na rede de atendimento (programas de controle de infecção, eficiência de novos procedimentos e medicamentos, saúde preventiva, dentre outros), sempre respeitando os consentimentos e a privacidade dos pacientes.
Um repositório clínico unificado capaz de reduzir duplicidades de dados, qualificar os dados do cadastro do paciente e dos atendimentos para entregar o melhor cadastro possível aos profissionais e gestores em saúde.
Este desafio não é possível para sistemas de gestão clínica e administrativa/financeira em específico, pois cada unidade possui seus próprios sistemas, assim como os planos de saúde e o governo, restando estabelecer um mecanismo de intermediação e unificação que todos podem consumir:
Adaptado de: http://www.intersystems.com/https:/cdn.intersystems.psdops.com/1d/f7/eefd49e348c2a311b9d6f053a82f/healthshare-managed-connections.pdf
Cenários de Uso e Resposta do HealthShare
Cenário de Uso
Com o HealthShare
Diferentes Unidades de Saúde utilizam Tasy, TrakCare e Cerner, cada um com seu modelo de dados, mas elas precisam entregar ao médico em qualquer uma destas unidades um Visualizador com todos os dados do paciente, dos exames de laboratório e de imagem e do histórico de medicações registrados em cada uma destas unidades, de forma unificada
O Health Connect utiliza adaptadores de conexão de dados e fluxos automatizados e de coleta, transformação, padronização e armazenamento unificado no Patient Index para entregar a visão unificada para o Médico no Visualizador do Unified Care Record ou no Visualizador da escolha da Rede (que irá consumir a API com os dados unificados e renderizar suas próprias visões)
A rede precisa lidar com diferentes tabelas de referência e codificação de exames e medicamentos dos laboratórios e fornecedores e realizar o DePara automatizado na visão final
O Health Connect realiza o DePara e o Visualizador Clínico apresenta na codificação utilizada pelo Hospital
A Rede de Atendimento precisa integrar com um novo sistema de laboratório e uma das unidades da rede irá alterar seu Sistema de Gestão Clínica, mas isto não pode afetar o Visualizador Clínico do Médico
O Health Connect cria uma nova conexão de dados com os novos sistemas e armazena no MPI (Patient Index) e no UCR (Unified Care Record), sem que o Visualizador seja afetado, uma vez que o dado é consumido deste repositório e não de cada sistema diretamente em cada hospital
Em razão da LGPD (Lei de Geral de Proteção de Dados) é necessário gerir o consentimento de acesso aos dados dos pacientes
O UCR utiliza seu motor de gestão de consentimentos para retornar ao médico e aos sistemas conectados apenas os dados que o paciente der consentimento o que os parceiros/rede puderem acessar em razão da base legal estabelecida
O Gestor da Rede precisa de diversos indicadores de atendimento, na verdade um BI (Business Intelligence) para explorar e analisar desempenho dos atendimentos
O Health Insight entrega diversos painéis de análise dos atendimentos e permite ao usuário com permissão criar e compartilhar novos painéis de análise de indicadores
O médico e a família do paciente querem ser notificados imediatamente sobre resultados de exames e de imagens
O UCR possui um motor de notificação por e-mail, caixa de entrada, dentre outras notificações customizáveis, sempre que novos exames, procedimentos ou dados chegam
A Rede de Atendimento criou um Área de Ciência de Dados e precisa de um Data Lake, ferramentas de Análise e de IA para realizar seu trabalho
O HealthShare conta com o Health Insight (BI), repositório com todos dados de atendimento e do paciente disponíveis para consumo e com um motor de AutoML e de execução de IA com Python
A Rede Atendimento precisa de identificar de forma precisa, inequívoca e unificada um paciente que deu entrada na emergência, mesmo que tenha apresentado um novo número de convênio ou de número social
O MPI do HealthShare possui mecanismos e regras que analisam os dados fornecidos e retornam o percentual de chance de ser um determinado paciente na existente na base de dados, evitando duplicar o paciente e assim não ter acesso a todo o histórico em quaisquer das unidades da rede
Estes são apenas alguns cenários, mas vários outros cenários são possíveis quando se conta com um intermediador e unificador de dados em saúde que entregue serviços de barramento de dados, BI, IA, mensageria baseada em padrões, Gestor de Consentimentos e Repositório Multimodelo com MPI para os dados do paciente e dos atendimentos.
Saiba mais em: https://www.intersystems.com/br/plataforma-de-interoperabilidade
Bom dia Yuri, não consegui abrir a página de referencia (https://www.intersystems.com/de/resources/detail/healthshare-managed-connections/).
Poderia verificar e corrigir?
Obrigada! Corrigido!
Artigo
Danusa Calixto · Set. 7, 2022
Olá! Meu nome é Sergei Sarkisian e crio o front-end do Angular há mais de 7 anos trabalhando na InterSystems. Como o Angular é um framework bastante popular, ele é geralmente escolhido pelos nossos desenvolvedores, clientes e parceiros como parte da pilha para seus aplicativos.
Quero começar uma série de artigos sobre diferentes aspectos do Angular: conceitos, instruções, práticas recomendadas, tópicos avançados e muito mais. Essa série será destinada às pessoas que já estão familiarizadas com o Angular e não abordará conceitos básicos. Como ainda estou no processo de planejamento dos artigos, queria começar destacando alguns recursos importantes da versão mais recente do Angular.
## Formulários com tipos estritos
Provavelmente, esse é um dos recursos mais desejados do Angular nos últimos anos. Com o Angular 14, os desenvolvedores agora podem usar toda a funcionalidade de verificação de tipos estritos do TypeScript com os formulários reativos do Angular.
A classe FormControl é agora genérica e assume o tipo do valor que detém.
```typescript
/* Antes do Angular 14 */
const untypedControl = new FormControl(true);
untypedControl.setValue(100); // o valor está definido, sem erros
// Agora
const strictlyTypedControl = new FormControl(true);
strictlyTypedControl.setValue(100); // você receberá a mensagem de erro de verificação de tipo aqui
// Também no Angular 14
const strictlyTypedControl = new FormControl(true);
strictlyTypedControl.setValue(100); // você receberá a mensagem de erro de verificação de tipo aqui
```
Como você pode ver, o primeiro e o último exemplos são quase iguais, mas têm resultados diferentes. Isso ocorre porque, no Angular 14, a nova classe FormControl deduz tipos do valor inicial informado pelo desenvolvedor. Portanto, se o valor `true` foi fornecido, o Angular define o tipo `boolean | null` para FormControl. O valor anulável é necessário para o método `.reset()`, que anula os valores se nenhum for fornecido.
Uma classe FormControl antiga e sem tipo foi convertida para `UntypedFormControl` (isso também se aplica para `UntypedFormGroup`, `UntypedFormArray` e `UntypedFormBuilder`), que é basicamente um codinome para `FormControl`. Se você estiver fazendo upgrade de uma versão anterior do Angular, todas as menções à classe `FormControl` serão substituídas pela classe `UntypedFormControl` pela CLI do Angular.
As classes sem tipo* são usadas com metas específicas:
1. Fazer seu app funcionar da mesma maneira como era antes da transição da versão anterior (lembre-se de que o novo FormControl deduzirá o tipo a partir do valor inicial).
2. Verificar se todos os usos de `FormControl` são desejados. Portanto, você precisará mudar qualquer UntypedFormControl para `FormControl` por conta própria.
3. Dar aos desenvolvedores mais flexibilidade (abordaremos isso abaixo).
Lembra-se de que, se o valor inicial for `null`, você precisará especificar explicitamente o tipo FormControl. Além disso, o TypeScript tem um bug que exige que você faça o mesmo se o valor inicial for `false`.
Para o grupo do formulário, você também pode definir a interface e transmitir essa interface como um tipo para FormGroup. Nesse caso, TypeScript deduzirá todos os tipos dentro de FormGroup.
```typescript
interface LoginForm {
email: FormControl;
password?: FormControl;
}
const login = new FormGroup({
email: new FormControl('', {nonNullable: true}),
password: new FormControl('', {nonNullable: true}),
});
```
O método `.group()` do FormBuilder agora tem um atributo genérico que pode aceitar sua interface predefinida, como no exemplo acima, em que criamos manualmente o FormGroup:
```typescript
interface LoginForm {
email: FormControl;
password?: FormControl;
}
const fb = new FormBuilder();
const login = fb.group({
email: '',
password: '',
});
```
Como nossa interface só tem tipos primitivos não anuláveis, ela pode ser simplificada com a nova propriedade `nonNullable` do FormBuilder (que contém a instância da classe `NonNullableFormBuilder`, também criada diretamente):
```typescript
const fb = new FormBuilder();
const login = fb.nonNullable.group({
email: '',
password: '',
});
```
❗ Se você usar o FormBuilder nonNullable ou definir a opção nonNullable no FormControl, quando chamar o método `.reset()`, ele usará o valor inicial do FormControl como um valor de redefinição.
Além disso, também é muito importante observar que todas as propriedades em `this.form.value` serão marcadas como opcionais. Desta forma:
```typescript
const fb = new FormBuilder();
const login = fb.nonNullable.group({
email: '',
password: '',
});
// login.value
// {
// email?: string;
// password?: string;
// }
```
Isso ocorre porque, quando você desativa qualquer FormControl dentro do FormGroup, o valor desse FormControl será excluído do `form.value`
```typescript
const fb = new FormBuilder();
const login = fb.nonNullable.group({
email: '',
password: '',
});
login.get('email').disable();
console.log(login.value);
// {
// password: ''
// }
```
Para obter todo o objeto do formulário, você precisa usar o método `.getRawValue()`:
```typescript
const fb = new FormBuilder();
const login = fb.nonNullable.group({
email: '',
password: '',
});
login.get('email').disable();
console.log(login.getRawValue());
// {
// email: '',
// password: ''
// }
```
Vantagens de formulários com tipos estritos:
1. Qualquer propriedade e método que retorna valores do FormControl / FormGroup é agora estritamente tipado. Por exemplo: `value`, `getRawValue()`, `valueChanges`.
2. Qualquer método de mudança do valor do FormControl é agora seguro para os tipos: `setValue()`, `patchValue()`, `updateValue()`
3. Os FormControls têm agora tipos estritos. Isso também se aplica ao método `.get()` do FormGroup. Isso evitará que você acesse FormControls inexistentes no momento da compilação.
### Nova classe FormRecord
A desvantagem da nova classe `FormGroup` é que ela perdeu sua natureza dinâmica. Após a definição, você não poderá adicionar ou remover FormControls dela rapidamente.
Para resolver esse problema, o Angular apresenta uma nova classe — `FormRecord`. `FormRecord` é praticamente igual ao `FormGroup`, mas é dinâmico e todos os seus FormControls devem ter o mesmo tipo.
```typescript
folders: new FormRecord({
home: new FormControl(true, { nonNullable: true }),
music: new FormControl(false, { nonNullable: true })
});
// Adicione o novo FormContol ao grupo
this.foldersForm.get('folders').addControl('videos', new FormControl(false, { nonNullable: true }));
// Isso gerará um erro de compilação, já que o controle tem um tipo diferente
this.foldersForm.get('folders').addControl('books', new FormControl('Some string', { nonNullable: true }));
```
Como você pode ver, há uma outra limitação — todos os FormControls precisam ter o mesmo tipo. Se você realmente precisar de um FormGroup dinâmico e heterogêneo, deverá usar a classe`UntypedFormGroup` para definir seu formulário.
## Componentes sem módulos (individuais)
Apesar de ainda ser considerado experimental, esse é um recurso interessante. Ele permite definir componentes, diretivas e pipes sem incluí-los em qualquer módulo.
O conceito ainda não está totalmente pronto, mas já conseguimos desenvolver um aplicativo sem ngModules.
Para definir um componente individual, você precisa usar a nova propriedade `standalone` no decorator Component/Pipe/Directive:
```typescript
@Component({
selector: 'app-table',
standalone: true,
templateUrl: './table.component.html'
})
export class TableComponent {
}
```
Nesse caso, o componente não pode ser declarado em qualquer NgModule. No entanto, ele pode ser importado em NgModules e outros componentes individuais.
Cada componente/pipe/diretiva individual agora tem um mecanismo para importar as dependências diretamente no decorator:
```typescript
@Component({
standalone: true,
selector: 'photo-gallery',
// um módulo existente é importado diretamente em um componente individual
// CommonModule é importado diretamente para usar diretivas padrão do Angular como *ngIf
// o componente individual declarado acima também é importado diretamente
imports: [CommonModule, MatButtonModule, TableComponent],
template: `
...
Next Page
`,
})
export class PhotoGalleryComponent {
}
```
Como mencionei acima, você pode importar componentes individuais em qualquer ngModule existente. Não é mais necessário importar todo o sharedModule. Podemos importar somente o que é realmente necessário. Essa também é uma boa estratégia para começar a usar novos componentes individuais:
```typescript
@NgModule({
declarations: [AppComponent],
imports: [BrowserModule, HttpClientModule, TableComponent], // import our standalone TableComponent
bootstrap: [AppComponent]
})
export class AppModule {}
```
Você pode criar um componente individual com a CLI do Angular ao digitar:
```bash
ng g component --standalone user
```
### Aplicativo Bootstrap sem módulos
Se você quiser se livrar de todos os ngModules do seu aplicativo, você precisa usar o bootstrap de maneira diferente. O Angular tem uma nova função para isso que você precisa chamar no arquivo main.ts:
```typescript
bootstrapApplication(AppComponent);
```
O segundo parâmetro dessa função permitirá definir os fornecedores necessários em todo o app. Como a maioria dos fornecedores geralmente existe em módulos, o Angular (por enquanto) exige o uso de uma nova função de extração `importProvidersFrom` para eles:
```typescript
bootstrapApplication(AppComponent, { providers: [importProvidersFrom(HttpClientModule)] });
```
### Rota de componente individual de lazy load:
O Angular tem uma nova função `loadComponent` de rota de lazy loading, que serve exatamente para o carregamento de componentes individuais:
```typescript
{
path: 'home',
loadComponent: () => import('./home/home.component').then(m => m.HomeComponent)
}
```
Agora, `loadChildren` não só permite o lazy load de ngModule, mas também carrega rotas filhas diretamente do arquivo de rotas:
```typescript
{
path: 'home',
loadChildren: () => import('./home/home.routes').then(c => c.HomeRoutes)
}
```
### Algumas observações no momento da redação do artigo
- O recurso de componentes individuais ainda está em fase experimental. Ela receberá melhorias no futuro com a migração para Vite builder em vez de Webpack, ferramentas otimizadas, tempos de desenvolvimento mais rápidos, arquitetura de app mais robusta, testes mais fáceis e muito mais. Por enquanto, várias dessas coisas estão faltando, então não recebemos o pacote completo, mas pelo menos podemos começar a desenvolver nossos apps com o novo paradigma do Angular em mente.
- Os IDEs e ferramentas do Angular ainda não estão totalmente prontos para analisar estatisticamente novas entidades individuais. Já que é necessário importar todas as dependências em cada entidade individual, se você deixar algo passar, o compilador pode também não perceber e falhar no tempo de execução. Isso melhorará com o tempo, mas agora as importações exigem maior atenção dos desenvolvedores.
- Não há importações globais no Angular no momento (como em Vue, por exemplo), então você precisa importar cada uma das dependências em todas as entidades individuais. Espero que isso seja solucionado em uma versão futura, já que o principal objetivo desse recurso a meu ver seja reduzir o boilerplate e facilitar as coisas.
#
Isso é tudo por hoje. Até mais!
Anúncio
Jose-Tomas Salvador · Nov. 3, 2020
Desta vez, quero falar sobre algo não específico do InterSystems IRIS, mas que acho importante se você deseja trabalhar com Docker e seu servidor no trabalho é um PC ou laptop com Windows 10 Pro ou Enterprise.
Como você provavelmente sabe, a tecnologia de contêineres vem basicamente do mundo Linux e, hoje em dia, está em hosts Linux onde apresenta potencial máximo. Quem usa o Windows normalmente vê que tanto a Microsoft quanto o Docker têm feito esforços importantes nos últimos anos que nos permitem rodar contêineres baseados em imagens Linux em nosso sistema Windows de uma maneira muito fácil... mas é algo que não é suportado para sistemas em produção e, este é o grande problema, não é confiável se quisermos manter os dados persistentes fora dos contêineres, no sistema host... principalmente devido às grandes diferenças entre os sistemas de arquivos Windows e Linux. No final, o próprio _Docker para Windows usa uma pequena máquina virtual Linux (_MobiLinux_) para executar os contêineres... ele faz isso de forma transparente para o usuário do Windows... e funciona perfeitamente bem se, como eu disse, você não exigir que seus bancos de dados sobrevivam mais do que o contêiner...
Bem... vamos direto ao ponto... o ponto é que muitas vezes, para evitar problemas e simplificar, precisamos de um sistema Linux completo e, se nosso servidor for baseado em Windows, a única maneira de fazê-lo é por meio de uma máquina virtual. Pelo menos até o WSL2 no Windows ser lançado, mas isso será uma outra história e com certeza levará um pouco de tempo para se tornar robusto o suficiente.
Neste artigo, vou lhe dizer, passo a passo, como instalar um ambiente onde você poderá trabalhar, se precisar, com contêineres Docker em um sistema Ubuntu em seu servidor Windows. Vamos lá...
1. Habilite o Hyper-V
Se você ainda não o habilitou, vá em adicionar `Recursos do Windows` e habilite o Hyper-V. Você precisará reiniciar (os textos da imagem estão em espanhol pois esse é o meu espaço de trabalho atual. Espero que junto com as instruções ajudem a "descriptografá-la" se você não conhece a língua de Dom Quixote 😉)
.png)
2. Crie uma máquina virtual Ubuntu no Hyper-V
Não acho que haja uma maneira mais fácil de criar uma máquina virtual (VM). Basta abrir a janela do `Gerenciador Hyper-V`, ir para a opção Criação Rápida...(logo acima na tela) e criar sua máquina virtual usando qualquer uma das versões do Ubuntu já oferecidas (você pode baixar um arquivo _ISO _de qualquer outro Linux e assim criar a VM com uma distro diferente). No meu caso, escolhi a última versão disponível do Ubuntu: 19.10. Enfim, tudo que você verá aqui é válido para o dia 18/04. Em 15 ou 20 minutos, dependendo do que a imagem leva para baixar, você terá sua nova VM criada e pronta.
Importante: Deixe a opção de Switch padrão como é oferecida. Isso garantirá que você tenha acesso à Internet tanto no host quanto na máquina virtual.
3. Crie uma sub-rede local
Um dos problemas no uso de máquinas virtuais que encontrei com frequência tem a ver com configuração de rede... às vezes funciona, outras não, ou funciona se eu estiver conectado com Wi-Fi, mas não por cabo ou o oposto, ou se eu estabelecer uma VPN no host Windows, perco o acesso à Internet na VM, ou a comunicação entre a VM (Linux) e o host (Windows) quebra... enfim... é uma loucura! Faz com que eu não confie no meu ambiente quando uso meu laptop para desenvolvimento, pequenas e rápidas demonstrações ou para apresentações, onde provavelmente o acesso à Internet não é tão importante quanto ter certeza de que as comunicações entre meu host e minhas VMs funcionam em uma forma confiável.
Com uma sub-rede local ad-hoc, compartilhada entre seu host Windows e suas máquinas virtuais, você resolve. Para permitir que eles se comuniquem entre si, você usa essa sub-rede e é isso. Você só precisa atribuir IPs específicos ao seu host e às suas VMs e tudo pronto.
É muito fácil fazer isso com essas etapas. Basta ir em Gerenciador de Comutador virtual... que você encontrará em seu `Gerenciador Hyper-V`:
.png)
Uma vez lá, vá até a opção _Novo Comutador Virtual __ _(será como uma nova placa de rede para a VM):
.png)
Certifique-se de defini-la como uma _Rede Interna _, escolha o nome que queremos e deixe as outras opções como padrão
.png)
Agora, se formos ao _`Painel de Controle do Windows > Central de Rede e Compartilhamento`_, veremos que já temos lá o switch que acabamos de criar:
.png)
4. Configure a sub-rede local compartilhada pelo host e as máquinas virtuais
Neste ponto, você pode concluir a configuração de sua nova rede local. Para fazer isso, coloque o cursor sobre a conexão _Meu Novo Comutador LOCAL_, clique e vá em Propriedades, e de lá para o protocolo IPv4 para atribuir um endereço IP fixo:
.png)
Importante: O IP que você atribuir aqui será o IP do seu host (Windows) nesta sub-rede local.
5. Conecte e configure sua nova rede local para sua máquina virtual
Agora volte ao seu `Gerenciador Hyper-V`. Se sua VM estiver em execução, pare-a. Depois de parado, vá para sua configuração e adicione o novo switch virtual interno:
.png)
_(Nota – Na imagem você pode ver outro switch, o Comutador INTERNO Hyper-V. É para outra sub-rede que eu tenho. Mas não é necessário para você nesta configuração) _
Depois de clicar em Adicionar, você só terá que selecionar o switch que você criou anteriormente:
.png)
Bem, uma vez feito isso, clique em Aplicar, Aceitar... e você está pronto! Você pode iniciar e entrar novamente em sua máquina virtual para finalizar a configuração da conexão interna. Para fazer isso, assim que a VM iniciar, clique no ícone de rede (à direita) e você verá que tem 2 redes: _eth0 _e _eth1_. O _eth1_ aparece como desconectado... por agora:
.png)
Vá para a configuração da Ethernet (eht1) e atribua um IP fixo para esta sub-rede local, por exemplo: _155.100.101.1_, e a máscara de sub-rede:_ 255.255.255.0_
.png)
e isso é tudo. Aqui você tem sua máquina virtual, identificada com o IP 155.100.101.1 compartilhando a mesma sub-rede com seu host.
7. Permitir acesso ao Windows 10 de sua máquina virtual
Você provavelmente descobrirá que o Windows 10 não permite por padrão a conexão de outro servidor e, para o seu sistema Windows, a VM que você acabou de criar é exatamente isso, um servidor externo e potencialmente perigoso... então você terá que adicionar uma regra no Firewall para poder se conectar ao seu host a partir dessas máquinas virtuais. Como? Muito fácil, basta procurar pelo `Firewall do Windows Defender` no seu `Painel de Controle do Windows`, ir em Configuração Avançada e criar uma nova *Regra de Entrada*:
.png)
Você pode definir uma porta ou um ou vários intervalos nelas... (também pode definir a regra para todas as portas)...
.png)
A ação que queremos é _Permitir Conexão_...
.png)
Para _todos os tipos de redes_...
.png)
Dê um nome à sua regra...
.png)
E **importante**, imediatamente depois disso, abra novamente as propriedades de sua regra recém-criada e *limite o escopo da aplicação*, para aplicar apenas nas conexões dentro de sua sub-rede local...
.png)
8. PRONTO. Instale o Docker e qualquer outra aplicação em sua nova máquina virtual Ubuntu
Depois de passar por todo o processo de instalação e ter sua nova VM pronta e atualizada, com acesso à internet, etc. você pode instalar as aplicações que desejar... Docker é o mínimo, essa foi a ideia para começar, você também pode instalar seu cliente VPN se precisar de uma conexão com a rede de sua empresa, VS Code, Eclipse+Atelier,...
Especificamente, para instalar o Docker, em sua VM, você pode seguir as instruções que encontrará aqui: [https://docs.docker.com/install/linux/docker-ce/ubuntu/](https://docs.docker.com/install/linux/docker-ce/ubuntu/)
Certifique-se de que o tempo de execução do Docker está funcionando, baixe alguma imagem de teste, etc... e é isso.
Com isso... _**Está tudo pronto!**_, agora você poderá ter contêineres rodando sem limitações (além da capacidade do seu hardware) em sua VM Ubuntu, aos quais você poderá se conectar a partir de seu host Windows 10, de um navegador ou aplicativo e vice-versa, de seu Ubuntu VM para seu host Windows 10. Tudo isso usando seus endereços IP configurados em sua sub-rede local compartilhada, que funcionará independente se você tem uma VPN estabelecida ou não, se você acessa à Internet através de seu adaptador Wi-Fi ou via cabo ethernet.
Ah... um último conselho. Se você deseja trocar arquivos entre o Windows 10 e suas máquinas virtuais, uma opção muito útil e simples é usar o [WinSCP](https://winscp.net/eng/download.php). É gratuito e funciona muito bem.
Bem, com certeza existem outras configurações... mas esta é a que utilizo e provou ser a mais confiável. Espero que você também ache útil. Se eu evitei qualquer dor de cabeça, este artigo terá valido a pena.
Boa codificação!
Artigo
Danusa Calixto · Set. 20, 2022
# Apache Web Gateway com Docker
Olá, comunidade.
Neste artigo, vamos configurar programaticamente um Apache Web Gateway com Docker usando:
* Protocolo HTTPS.
* TLS\SSL para proteger a comunicação entre o Web Gateway e a instância IRIS.
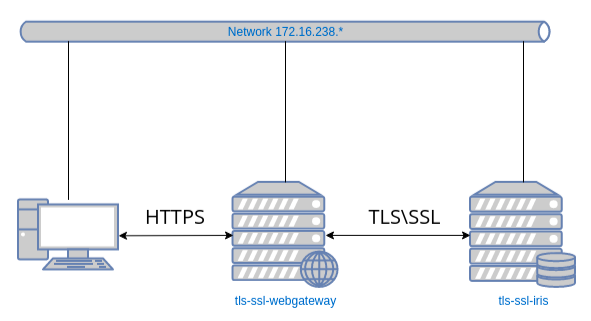
Usaremos duas imagens: uma para o Web Gateway e a segunda para a instância IRIS.
Todos os arquivos necessários estão disponíveis neste [repositório do GitHub](https://github.com/lscalese/docker-webgateway-sample).
Vamos começar com um git clone:
```bash
git clone https://github.com/lscalese/docker-webgateway-sample.git
cd docker-webgateway-sample
```
## Prepare seu sistema
Para evitar problemas com permissões, seu sistema precisa de um usuário e um grupo:
* www-data
* irisowner
É necessário compartilhar arquivos de certificados com os contêineres. Se não estiverem no seu sistema, basta executar:
```bash
sudo useradd --uid 51773 --user-group irisowner
sudo groupmod --gid 51773 irisowner
sudo useradd –user-group www-data
```
## Gere certificados
Nesta amostra, usaremos três certificados:
1. Uso do servidor Web HTTPS.
2. Criptografia TLS\SSL no cliente do Web Gateway.
3. Criptografia TLS\SSL na instância IRIS.
Um script pronto para uso está disponível para gerá-los.
No entanto, você deve personalizar o sujeito do certificado. Basta editar o arquivo [gen-certificates.sh](https://github.com/lscalese/docker-webgateway-sample/blob/master/gen-certificates.sh).
Esta é a estrutura do argumento `subj` do OpenSSL:
1. **C**: Código do país
2. **ST**: Estado
3. **L**: Local
4. **O**: Organização
5. **OU**: Unidade de organização
6. **CN**: Nome comum (basicamente, o nome do domínio ou do host)
Fique à vontade para mudar esses valores.
```bash
# sudo é necessário devido a chown, chgrp, chmod ...
sudo ./gen-certificates.sh
```
Se estiver tudo certo, você verá dois novos diretórios `./certificates/` e `~/webgateway-apache-certificates/` com certificados:
| Arquivo | Contêiner | Descrição |
| ------------------------------------------------------ | --------------- | ---------------------------------------------------------------------------------------------------- |
| ./certificates/CA_Server.cer | webgateway,iris | Certificado do servidor da autoridade |
| ./certificates/iris_server.cer | iris | Certificado para a instância IRIS (usado para a criptografia de comunicação do espelho e webgateway) |
| ./certificates/iris_server.key | iris | Chave privada relacionada |
| ~/webgateway-apache-certificates/apache_webgateway.cer | webgateway | Certificado para o servidor da Web Apache |
| ~/webgateway-apache-certificates/apache_webgateway.key | webgateway | Chave privada relacionada |
| ./certificates/webgateway_client.cer | webgateway | Certificado para criptografar a comunicação entre o webgateway e IRIS |
| ./certificates/webgateway_client.key | webgateway | Chave privada relacionada |
Considere que, se houver certificados autoassinados, os navegadores da Web mostrarão alertas de segurança. Obviamente, se você tiver um certificado entregue por uma autoridade certificada, você pode usá-lo em vez de um autoassinado (especialmente para o certificado do servidor Apache).
## Arquivos de configuração do Web Gateway
Observe os arquivos de configuração.
### CSP.INI
Você pode ver um arquivo CSP.INI no diretório `webgateway-config-files`.
Ele será empurrado para dentro da imagem, mas o conteúdo pode ser modificado no ambiente de execução. Considere o arquivo como um modelo.
Na amostra, os seguintes parâmetros serão substituídos na inicialização do contêiner:
* Ip_Address
* TCP_Port
* System_Manager
Consulte [startUpScript.sh](https://github.com/lscalese/docker-webgateway-sample/blob/master/startUpScript.sh) para ver mais detalhes. Basicamente, a substituição é realizada com a linha de comando `sed`.
Além disso, esse arquivo contém a configuração SSL\TLS para proteger a comunicação com a instância IRIS:
```
SSLCC_Certificate_File=/opt/webgateway/bin/webgateway_client.cer
SSLCC_Certificate_Key_File=/opt/webgateway/bin/webgateway_client.key
SSLCC_CA_Certificate_File=/opt/webgateway/bin/CA_Server.cer
```
Essas linhas são importantes. Precisamos garantir que os arquivos dos certificados estarão disponíveis para o contêiner.
Faremos isso mais tarde no arquivo `docker-compose` com um volume.
### 000-default.conf
Esse é um arquivo de configuração do Apache. Ele permite o uso do protocolo HTTPS e redireciona chamadas HTTP para HTTPS.
Os arquivos de certificado e chave privada são configurados neste arquivo:
```
SSLCertificateFile /etc/apache2/certificate/apache_webgateway.cer
SSLCertificateKeyFile /etc/apache2/certificate/apache_webgateway.key
```
## Instância IRIS
Para nossa instância IRIS, configuramos somente o requisito mínimo para permitir a comunicação SSL\TLS com o Web Gateway. Isso envolve:
1. Configuração SSL `%SuperServer`.
2. Permitir a configuração de segurança SSLSuperServer.
3. Restringir a lista de IPs que podem usar o serviço Web Gateway.
Para facilitar a configuração, config-api é usado com um arquivo de configuração JSON simples.
```json
{
"Security.SSLConfigs": {
"%SuperServer": {
"CAFile": "/usr/irissys/mgr/CA_Server.cer",
"CertificateFile": "/usr/irissys/mgr/iris_server.cer",
"Name": "%SuperServer",
"PrivateKeyFile": "/usr/irissys/mgr/iris_server.key",
"Type": "1",
"VerifyPeer": 3
}
},
"Security.System": {
"SSLSuperServer":1
},
"Security.Services": {
"%Service_WebGateway": {
"ClientSystems": "172.16.238.50;127.0.0.1;172.16.238.20"
}
}
}
```
Nenhuma ação é necessária. A configuração será carregada automaticamente durante a inicialização do contêiner.
## Imagem tls-ssl-webgateway
### dockerfile
```
ARG IMAGEWEBGTW=containers.intersystems.com/intersystems/webgateway:2021.1.0.215.0
FROM ${IMAGEWEBGTW}
ADD webgateway-config-files /webgateway-config-files
ADD buildWebGateway.sh /
ADD startUpScript.sh /
RUN chmod +x buildWebGateway.sh startUpScript.sh && /buildWebGateway.sh
ENTRYPOINT ["/startUpScript.sh"]
```
Por padrão, o ponto de entrada é `/startWebGateway`, mas precisamos realizar algumas operações antes de iniciar o webserver. Lembre-se de que nosso arquivo CSP.ini é um `modelo`, e precisamos mudar alguns parâmetros (IP, porta, gerente de sistemas) na inicialização. `startUpScript.sh` realizará essas mudanças e executará o script de ponto de entrada inicial `/startWebGateway`.
## Inicializando os contêineres
### arquivo docker-compose
Antes de iniciar os contêineres, o arquivo `docker-compose.yml` precisa ser modificado:
* `**SYSTEM_MANAGER**` precisa ser definido com o IP autorizado para ter acesso ao **Gerenciamento do Web Gateway** https://localhost/csp/bin/Systems/Module.cxw Basicamente, é seu endereço IP (pode ser uma lista separada por vírgulas).
* `**IRIS_WEBAPPS**` precisa ser definido com a lista dos seus aplicativos CSP. A lista é separada por espaços, por exemplo: `IRIS_WEBAPPS=/csp/sys /swagger-ui`. Por padrão, apenas `/csp/sys` é exposto.
* As portas 80 e 443 são mapeadas. Adapte a outras portas se elas já estão em uso no seu sistema.
```
version: '3.6'
services:
webgateway:
image: tls-ssl-webgateway
container_name: tls-ssl-webgateway
networks:
app_net:
ipv4_address: 172.16.238.50
ports:
# mude a porta local já em uso no seu sistema.
- "80:80"
- "443:443"
environment:
- IRIS_HOST=172.16.238.20
- IRIS_PORT=1972
# Troque pela lista de endereços IP permitidos para abrir o gerente de sistema de CSP
# https://localhost/csp/bin/Systems/Module.cxw
# veja o arquivo .env para definir a variável de ambiente.
- "SYSTEM_MANAGER=${LOCAL_IP}"
# a lista de web apps
# /csp permite que o webgateway redirecione todas as solicitações que começam com /csp à instância iris
# Você pode especificar uma lista separada por um espaço : "IRIS_WEBAPPS=/csp /api /isc /swagger-ui"
- "IRIS_WEBAPPS=/csp/sys"
volumes:
# Monte os arquivos dos certificados.
- ./volume-apache/webgateway_client.cer:/opt/webgateway/bin/webgateway_client.cer
- ./volume-apache/webgateway_client.key:/opt/webgateway/bin/webgateway_client.key
- ./volume-apache/CA_Server.cer:/opt/webgateway/bin/CA_Server.cer
- ./volume-apache/apache_webgateway.cer:/etc/apache2/certificate/apache_webgateway.cer
- ./volume-apache/apache_webgateway.key:/etc/apache2/certificate/apache_webgateway.key
hostname: webgateway
command: ["--ssl"]
iris:
image: intersystemsdc/iris-community:latest
container_name: tls-ssl-iris
networks:
app_net:
ipv4_address: 172.16.238.20
volumes:
- ./iris-config-files:/opt/config-files
# Monte os arquivos dos certificados.
- ./volume-iris/CA_Server.cer:/usr/irissys/mgr/CA_Server.cer
- ./volume-iris/iris_server.cer:/usr/irissys/mgr/iris_server.cer
- ./volume-iris/iris_server.key:/usr/irissys/mgr/iris_server.key
hostname: iris
# Carregue o arquivo de configuração IRIS ./iris-config-files/iris-config.json
command: ["-a","sh /opt/config-files/configureIris.sh"]
networks:
app_net:
ipam:
driver: default
config:
- subnet: "172.16.238.0/24"
```
Compile e comece:
```bash
docker-compose up -d --build
```
Os contêineres `tls-ssl-iris e tls-ssl-webgateway devem ser inicializados.`
## Teste o acesso a Web
### Página padrão do Apache
Abra a página [http://localhost](http://localhost). Você será automaticamente redirecionado para [https://localhost](https://localhost).
Os navegadores mostram alertas de segurança. Esse é o comportamento padrão com um certificado autoassinado, aceite o risco e continue.
### Página de gerenciamento do Web Gateway
Abra [https://localhost/csp/bin/Systems/Module.cxw](https://localhost/csp/bin/Systems/Module.cxw) e teste a conexão com o servidor. 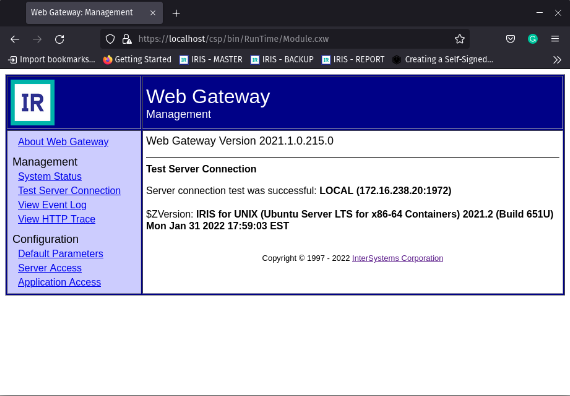
### Portal de gerenciamento
Abra [https://localhost/csp/sys/utilhome.csp](https://localhost/csp/sys/utilhome.csp)
Ótimo! A amostra do Web Gateway está funcionando!
## Espelho IRIS com Web Gateway
No artigo anterior, criamos um ambiente de espelho, mas faltava o Web Gateway. Agora, podemos aprimorar isso.
Um novo repositório [iris-miroring-with-webgateway](https://github.com/lscalese/iris-mirroring-with-webgateway) está disponível, incluindo o Web Gateway e mais algumas melhorias:
1. Os certificados não são mais gerados na hora, mas em um processo separado.
2. Os endereços IP são substituídos pelas variáveis de ambiente nos arquivos de configuração docker-compose e JSON. As variáveis são definidas no arquivo '.env'.
3. O repositório pode ser usado como modelo.
Veja o arquivo [README.md](https://github.com/lscalese/iris-mirroring-with-webgateway) do repositório para a execução em um ambiente como este:
