Limpar filtro
Artigo
Danusa Calixto · Maio 9, 2023
# Prefácio
O InterSystems IRIS a partir da versão 2022.2 inclui a capacidade de autenticar uma API REST usando JSON web tokens (JWTs). Esse recurso aprimora a segurança ao limitar quando e com que frequência as senhas são transferidas pela rede, além de definir um tempo de expiração para o acesso.
O objetivo deste artigo é servir como um tutorial de como implementar uma API REST simulada usando o InterSystems IRIS e bloquear o acesso a ela com JWTs.
***OBSERVAÇÃO*** NÃO sou uma desenvolvedora. Não faço alegações sobre a eficiência, escalabilidade ou qualidade das amostras de código que uso neste artigo. Estes exemplos são APENAS para fins educacionais. Eles NÃO se destinam a código de produção.
# Prólogo
Depois de fazer esse aviso, vamos explorar os conceitos que serão analisados aqui.
## O que é REST?
REST é um acrônimo para "REpresentational State Transfer". É uma arquitetura para os programas se comunicarem com os aplicativos da Web e acessarem as funções publicadas por esses aplicativos.
## O que é um JWT?
Um JSON web token (JWT) é uma maneira compacta e segura para o URL de representar informações transferidas entre duas partes que podem ser assinadas digitalmente, criptografadas ou ambos. Se você quiser saber mais sobre os JWTs e outras classes da Web JSON compatíveis com o InterSystems IRIS, leia [esta postagem](https://community.intersystems.com/post/reference-json-web-classes).
# Colocando a mão na massa
## De acordo com a especificação
Para consumir uma API REST, primeiro precisamos ter uma API REST. Disponibilizei uma [amostra de especificação da OpenAPI 2.0](https://gist.github.com/greycatsec/4bdb1c8b5ddd4b06da2390184870b8c1) para um RPG de mesa (TTRPG). Ela será usada nos exemplos deste artigo. Há vários exemplos de como escrever a sua online, então fique à vontade para se aprofundar nisso, mas a especificação é apenas um modelo. A única coisa que faz é informar como usar a API.
## Geração da API REST
O InterSystems IRIS oferece uma maneira bastante organizada de gerar stubs de código da API REST. [Esta documentação](https://docs.intersystems.com/iris20223/csp/docbook/DocBook.UI.Page.cls?KEY=GREST_mgmnt#GREST_mgmnt_api) oferece uma maneira completa de gerar stubs de código. Fique à vontade para usar a especificação da OpenAPI 2.0 que forneci na seção anterior.
## Implementação
É aqui que vamos ir a fundo. A seção de geração criará três arquivos `.cls` para você:
1. `impl.cls`
2. `disp.cls`
3. `spec.cls`
Vamos passar a maior parte do nosso tempo no `impl.cls`, talvez mexer no `disp.cls` para depurar e não encostar no `spec.cls`.
No `impl.cls`, há stubs de código para os métodos que `disp.cls` chamará quando receber uma solicitação da API. A especificação da OpenAPI definida nessas assinaturas. Ela informa o que você quer que seja feito, mas é você quem precisa implementar isso no final. Então, vamos fazer isso!
### Criação
Uma das maneiras que usamos um banco de dados é adicionando objetos a ele. Esses objetos servem como uma base para outras funções. Sem objetos existentes, não haverá nada para ver, então vamos começar com nosso modelo de objeto: um `Character` (personagem)!
Um `Character` precisa ter nome e, como opção, especificar a classe, a raça e o nível. Veja abaixo um exemplo de implementação da classe `TTRPG.Character`
```objectscript
Class TTRPG.Character Extends %Persistent
{
Property Name As %String [ Required ];
Property Race As %String;
Property Class As %String;
Property Level As %String;
Index IndexName On Name [ IdKey ];
ClassMethod GetCharByName(name As %String) As TTRPG.Character
{
set character = ##class(TTRPG.Character).%OpenId(name)
Quit character
}
}
```
Já que queremos armazenar objetos `Character` no banco de dados, precisamos herdar a classe `%Persistent`. Queremos que seja possível procurar personagens pelo nome, em vez de atribuir uma chave de ID arbitrária. Portanto, definimos o atributo `[ IdKey ]` no Index para a propriedade `Character.Name`. Isso também garante a exclusividade do nome do personagem.
Com nosso modelo de objeto base definido, podemos analisar a implementação da API REST. O primeiro método que vamos explorar é o `PostCharacter`.
Como visão geral, esta parte consome uma solicitação HTTP POST para o endpoint `/characters` com nossas propriedades de personagem definidas no corpo. Ela deve pegar os argumentos fornecidos e criar um objeto `TTRPG.Character` a partir deles, salvá-lo no banco de dados e informar se teve êxito ou não.
```objectscript
ClassMethod PostCharacter(name As %String, class As %String, race As %String, level As %String) As %DynamicObject
{
set results = {} // cria o retorno %DynamicObject
//cria o objeto character
set char = ##class(TTRPG.Character).%New()
set char.Name = name
set char.Class = class
set char.Race = race
set char.Level = level
set st = char.%Save()
if st {
set charInfo = {}
set charInfo.Name = char.Name
set charInfo.Class = char.Class
set charInfo.Race = char.Race
set charInfo.Level = char.Level
set results.Character = charInfo
Set results.Status = "success"
}
else {
Set results.Status = "error"
Set results.Message = "Unable to create the character"
}
Quit results
}
```
Agora que podemos criar personagens, como buscamos aquele que acabamos de criar? De acordo com a especificação da OpenAPI, o endpoint `/characters/{charName}` permite a busca de um personagem pelo nome. Buscamos a instância do personagem, se ela existir. Se não existir, retornamos um erro para informar ao usuário que não existe um personagem com o nome fornecido. Isso é implementado no método `GetCharacterByName`.
```objectscript
ClassMethod GetCharacterByName(charName As %String) As %DynamicObject
{
// Cria um novo objeto dinâmico para armazenar os resultados
Set results = {}
set char = ##class(TTRPG.Character).GetCharByName(charName)
if char {
set charInfo = {}
set charInfo.Name = char.Name
set charInfo.Class = char.Class
set charInfo.Race = char.Race
set charInfo.Level = char.Level
set results.Character = charInfo
Set results.Status = "success"
}
// Se nenhum character foi encontrado, define uma mensagem de erro no objeto dos resultados
else {
Set results.Status = "error"
Set results.Message = "No characters found"
}
// Retorna o objeto dos resultados
Quit results
}
```
Mas isso é só o seu personagem. E todos os personagens que as outras pessoas criaram? Podemos ver esses personagens usando o método `GetCharacterList`. Ele consome uma solicitação HTTP GET para o endpoint `/characters` para compilar uma lista de todos os personagens no banco de dados e retorna essa lista.
```objectscript
ClassMethod GetCharacterList() As %DynamicObject
{
// Cria um novo objeto dinâmico para armazenar os resultados
Set results = {}
set query = "SELECT Name, Class, Race, ""Level"" FROM TTRPG.""Character"""
set tStatement = ##class(%SQL.Statement).%New()
set qstatus = tStatement.%Prepare(query)
if qstatus '= 1 { Do ##class(TTRPG.impl).%WriteResponse("Error: " _ $SYSTEM.Status.DisplayError(qstatus)) }
set rset = tStatement.%Execute()
Set characterList = []
while rset.%Next(){
Set characterInfo = {}
Set characterInfo.Name = rset.Name
set characterInfo.Race = rset.Race
Set characterInfo.Class = rset.Class
Set characterInfo.Level = rset.Level
Do characterList.%Push(characterInfo)
}
if (rset.%SQLCODE < 0) {write "%Next failed:", !, "SQLCODE ", rset.%SQLCODE, ": ", rset.%Message quit}
set totalCount = rset.%ROWCOUNT
// Define as propriedades status, totalCount e characterList no objeto dos resultados
Set results.Status = "success"
Set results.TotalCount = totalCount
Set results.CharacterList = characterList
// Retorna o objeto dos resultados
Quit results
}
```
E essa é nossa API! A especificação atual não oferece uma maneira de atualizar ou excluir personagens do banco de dados, e isso fica como um exercício para o leitor!
## Configuração do IRIS
Agora que implementamos nossa API REST, como fazemos a comunicação com o IRIS? No Portal de Gerenciamento, se você acessar a página `System Administration > Security > Applications > Web Applications`, poderá criar um novo aplicativo da Web. O nome do aplicativo é o endpoint que você usará ao fazer solicitações. Por exemplo, se o nome for `/api/TTRPG/`, as solicitações da API vão para `http://{IRISServer}:{host}/api/TTRPG/{endpoint}`. Para uma instalação do IRIS padrão local com segurança normal, é assim: `http://localhost:52773/api/TTRPG/{endpoint}`. Adicione uma boa descrição, defina o namespace desejado e clique no botão de opção para REST. Para ativar a autenticação JWT, selecione a caixa "Use JWT Authentication". O `JWT Access Token Timeout` determina a frequência com que o usuário precisará receber um novo JWT. Se você planeja testar a API por um longo período, recomendo definir esse valor como uma hora (3600 segundos) e o `JWT Refresh Token Timeout` (o período de renovação antes que o token expire para sempre) como 900 segundos.
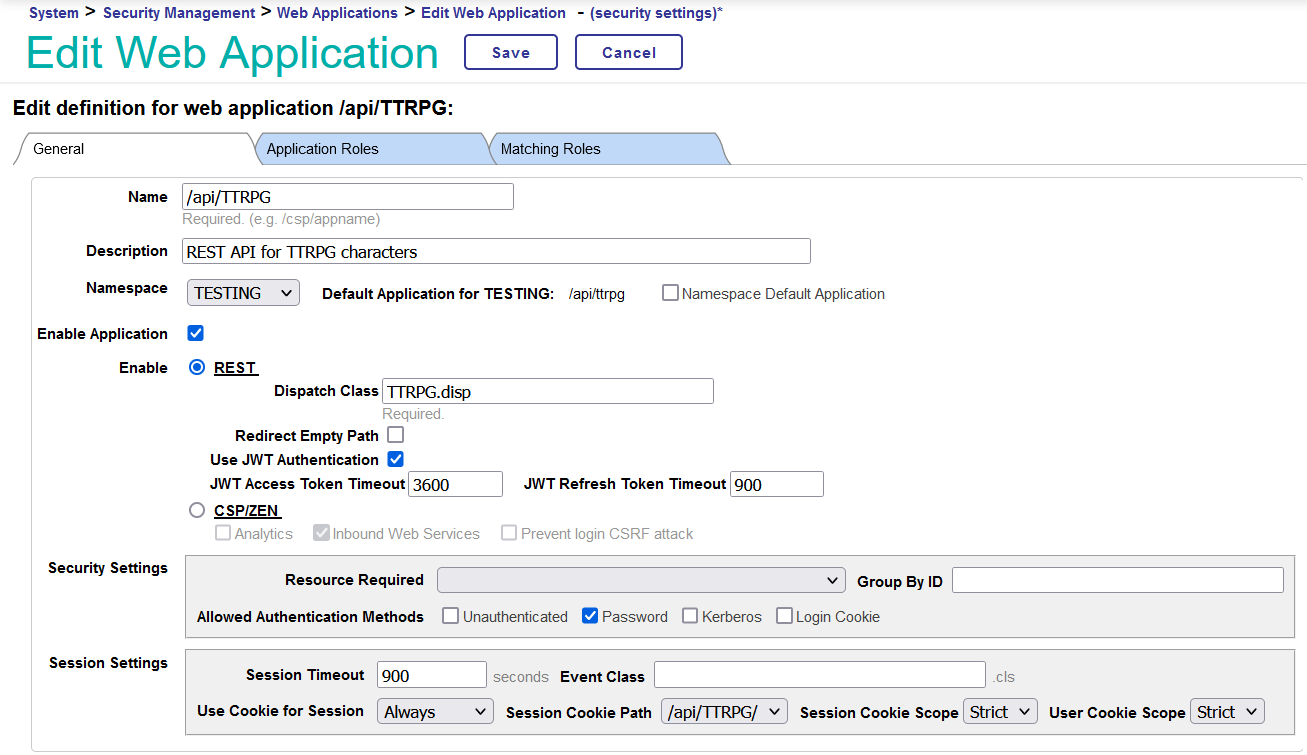
Agora que o aplicativo foi configurado, precisamos configurar o próprio IRIS para permitir a autenticação de JWT. É possível configurar essa opção em `System Administration > Security > System Security > Authentication/Web Session Options`. Na parte inferior, está o campo do emissor de JWT e o algoritmo de assinatura que será usado para assinar e validar os JWTs. O campo do emissor aparecerá na seção de informações do JWT e a finalidade é informar quem forneceu o token a você. Você pode defini-lo como "InterSystems".

## Hora de testar
Está tudo configurado e implementado, então vamos testar! Carregue sua ferramenta favorita para criar solicitações de API (vou usar uma extensão do Firefox chamada RESTer nos exemplos) e vamos começar a construir solicitações da API REST.
Primeiro, vamos tentar listar os personagens existentes.
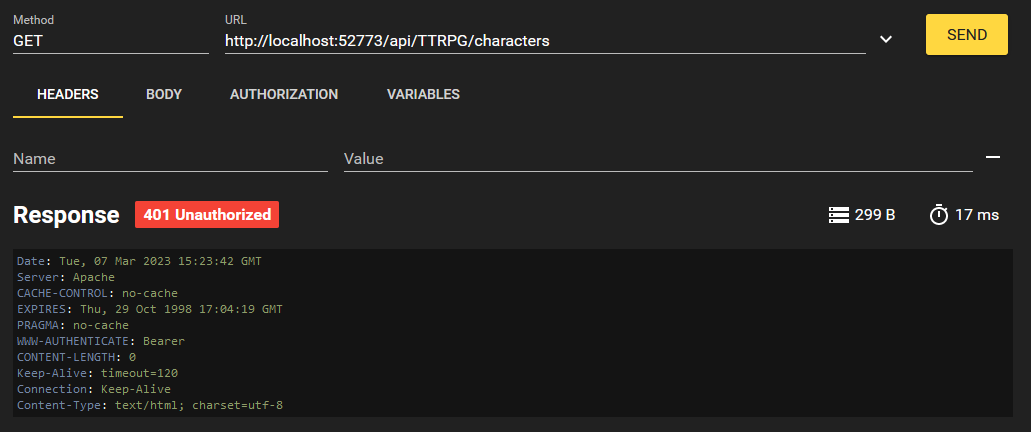
Recebemos um erro 401 Unauthorized. Isso ocorreu porque não fizemos login. Você talvez esteja pensando: Elliott, não implementamos funcionalidade de login nessa API REST. Não tem problema, porque o InterSystems IRIS cuida disso para nós quando usamos a autenticação de JWT. Ele oferece quatro endpoints que podemos usar para gerenciar nossa sessão. São eles: `/login`, `/logout` `/revoke` e `/refresh`. Eles podem ser personalizados no `disp.cls` conforme o exemplo abaixo:
```objectscript
Parameter TokenLoginEndpoint = "mylogin";
Parameter TokenLogoutEndpoint = "mylogout";
Parameter TokenRevokeEndpoint = "myrevoke";
Parameter TokenRefreshEndpoint = "myrefresh";
```
Vamos acessar o endpoint `/login` agora.
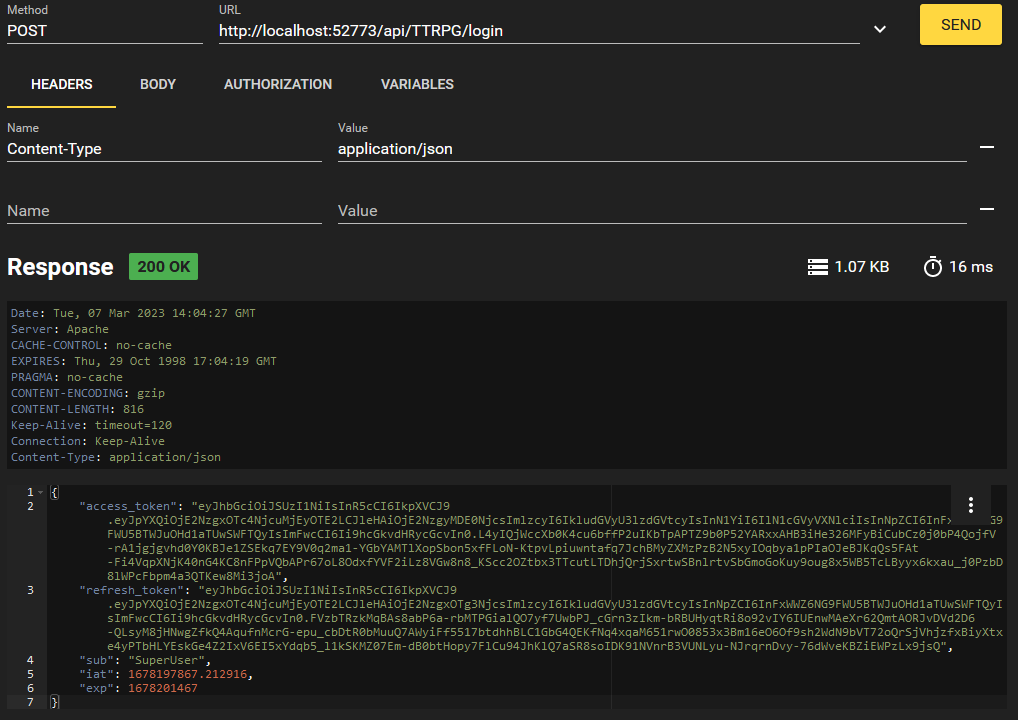
O corpo dessa solicitação não é exibido por medidas de segurança, mas ele segue esta estrutura JSON:
```json
{"user":"{YOURUSER}", "password":"{YOURPASSWORD}"}
```
Em troca da senha, recebemos um JWT! Esse é o valor de "access_token". Vamos copiar isso e usar nas nossas solicitações futuras para não precisar sempre transmitir a senha.
Agora que temos um JWT para autenticação, vamos tentar criar um personagem!
Formatamos nossa solicitação conforme abaixo:
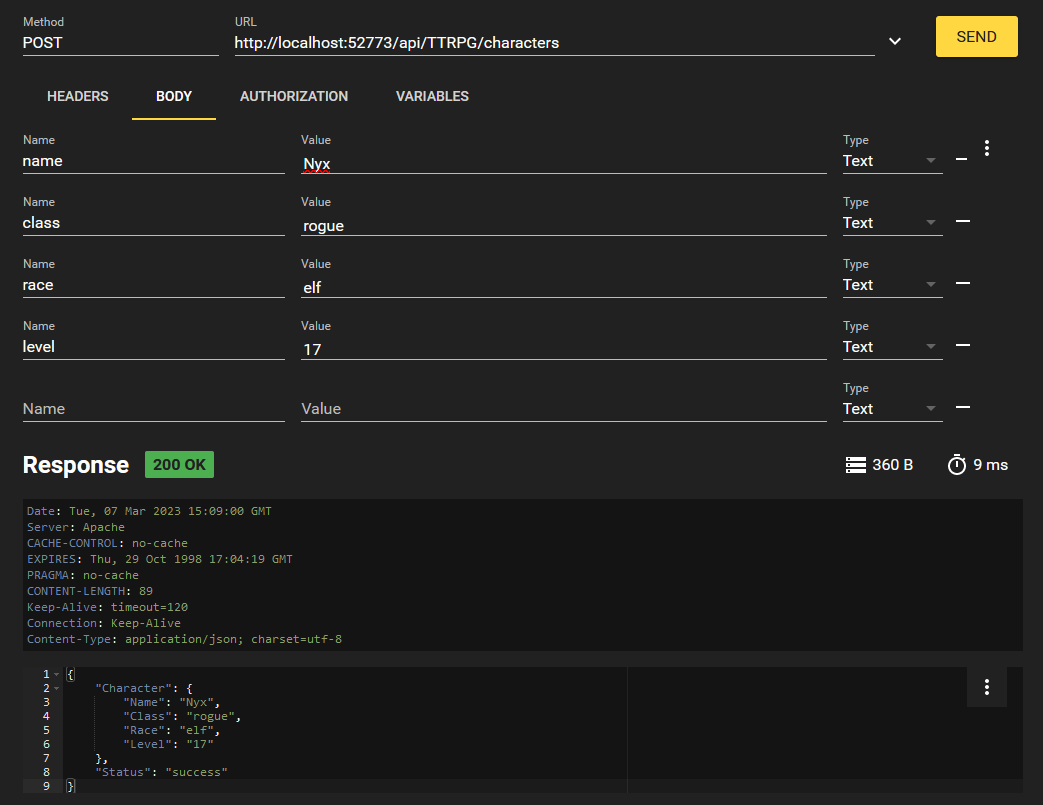
Usando o bearer token como cabeçalho no formato de " Authorization: Bearer {JWTValue}". Em uma solicitação curl, você pode escrever isso com `-H "Authorization: Bearer {JWTValue}"`
Vamos criar outro personagem por diversão, usando os valores que você quiser.
Agora, vamos tentar listar todos os personagens que existem no banco de dados.
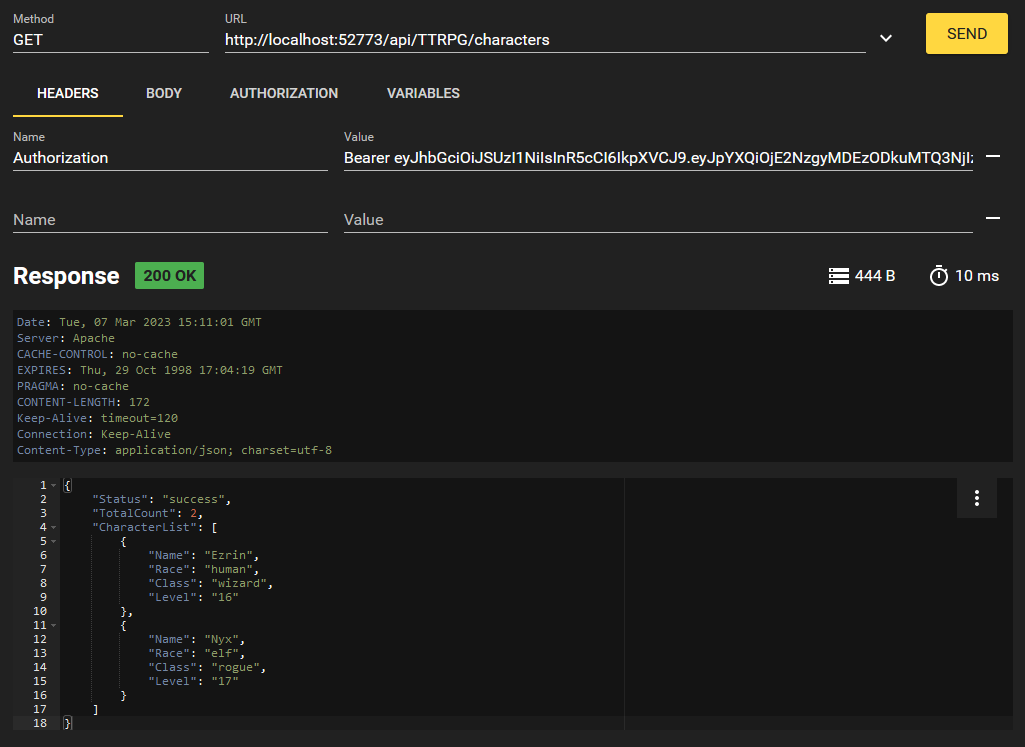
Obtemos os dois personagens que criamos! E se só quisermos acessar um? Implementamos isso com o endpoint `/characters/{charName}`. Podemos formatar essa solicitação desta forma:
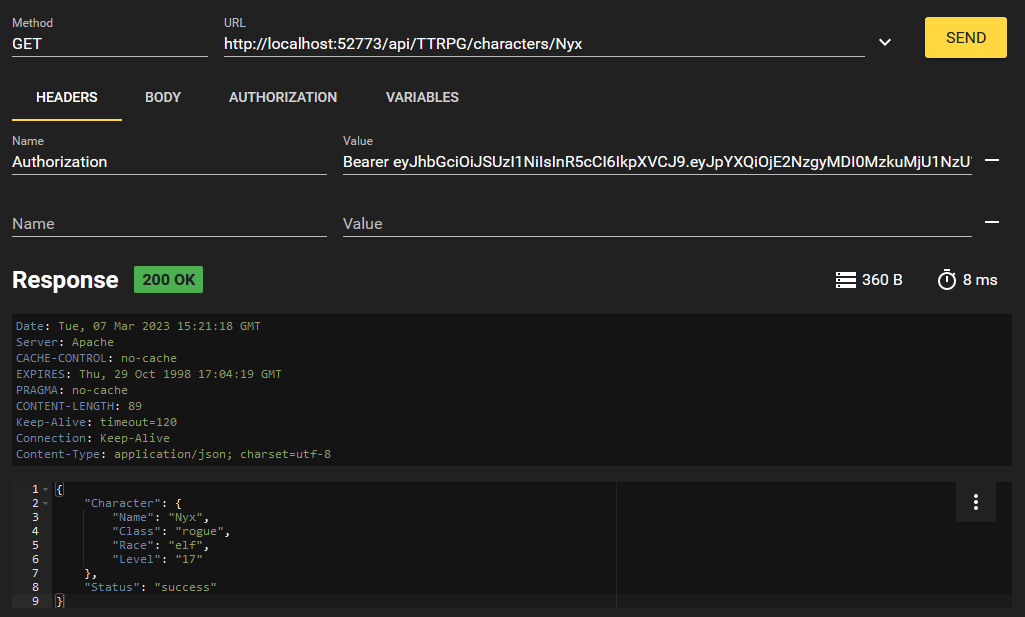
Essa é a nossa API REST em ação, pessoal! Quando concluir sua sessão, é possível sair no endpoint `/logout` usando seu JWT. Isso revogará e bloqueará o JWT para que não seja possível usá-lo novamente.
# Conclusão
O InterSystems IRIS a partir da versão 2022.2 inclui a capacidade de autenticar uma API REST usando JSON web tokens (JWTs). Esse recurso aprimora a segurança ao limitar o uso da senha e definir uma data de expiração para o acesso à API.
Espero que este manual sobre como gerar uma API REST e protegê-la com JWTs pelo IRIS tenha sido útil. Me avise se foi! Agradeço qualquer feedback.
Anúncio
Angelo Bruno Braga · Out. 28, 2020
Olá desenvolvedores,
A InterSystems está propondo um novo e fácil desafio como parte do Global Summit 2020. Como vocês já sabem, as plataformas de dados IRIS Data Platform 2020.4 e IRIS for Health 2020.4 estão no momento em sua versão de prévia. Nós estamos buscando melhorar a experiência dos desenvolvedores que pretendem migrar dos lançamentos anteriores em contêineres de 2020 destes produtos para a versão prévia 2020.4Nós os convidamos para responder a pesquisa e ganhar 7000 pontos no Global Masters🎁
2 passos para participar do desafio:1️⃣ Atualize qualquer contêiner 2020.x para IRIS Data Platform 2020.4, ou IRIS for Health 2020.4 versão prévia.2️⃣ Após a atualização, nos forneça as seguintes informações:
Seu nível de conhecimento em contêineres Docker? (iniciante, intermediário ou avançado)
A plataforma que você realizou a atualização.
Sua experiência - Como foi, o que você gostou, o que poderia ser melhor.
Os arquivos docker-compose.yml (ou Dockerfile) e messages.log da atualização.
Quais problemas (se ocorrerem) que você encontrou.
Você já utilizou uma nova funcionalidade na versão 2020.4? Em caso positivo, de que você gostou ?
➫ Por favor envie estas informações para Olga Zavrazhnova em Olga.Zavrazhnova_CTR@intersystems.com até 6 de novembro de 2020🚩. Obrigado desenvolvedores por ajudar-nos a tornar as plataformas IRIS e IRIS for Health, cada vez mais a melhor escolha para desenvolvimento de aplicações de ponta.
Você pode resgatar seus pontos por qualquer prêmio disponível no Global Masters. Não é um membro ainda ? Leia aqui sobre o Global Masters e junte-se ao programa ainda hoje!
Artigo
Larissa Prussak · Out. 26, 2021
As tecnologias da InterSystems são conhecidas por seus bancos de dados de alto desempenho, que suportam os sistemas e operações de muitas organizações. No entanto, um ingrediente chave para esse sucesso é a qualidade e a facilidade de manutenção de seu código.
A qualidade do código pode afetar tudo, desde a velocidade e facilidade de corrigir bugs e fazer melhorias, até o desempenho geral de sua organização e sua capacidade de chegar à frente no mercado.
Ao garantir que seu código seja sustentável, você pode reduzir aproximadamente 75% dos custos do ciclo de vida do sistema *. É por isso que, na George James Software, as soluções que construímos são sempre diretas e escritas em código de alta qualidade - porque sabemos que essa base sólida pode impactar positivamente o resto da sua organização.
Com um sistema que pode ser mantido, você pode reduzir a manutenção geral, pois qualquer problema que ocorra é significativamente mais rápido de identificar e corrigir. Isso significa que você está livre para alocar tempo e orçamento para melhorias, permitindo que você obtenha o máximo valor de suas aplicações e, em última análise, dê um melhor suporte à sua organização.
Fique atento às nossas próximas postagens sobre como é um sistema sustentável e as ferramentas que podem ajudá-lo a manter seu código sustentável, a fim de ajudá-lo a reduzir esses custos de manutenção.
*Ref: C. Chen, R. Alfayez, K. Srisopha, B. Boehm and L. Shi, "Why Is It Important to Measure Maintainability and What Are the Best Ways to Do It?," 2017 IEEE/ACM 39th International Conference on Software Engineering Companion (ICSE-C), 2017, pp. 377-378, doi: 10.1109/ICSE-C.2017.75.
Anúncio
Danusa Calixto · Ago. 19, 2022
Bem-vindos ao Lançamento de Julho 22 da Comunidade !
Fizemos recentemente algumas mudanças interessantes para sua experiencia na Comunidade da InterSystems:
📌 notificações como nas redes sociais
📌 configuração de inscrição aprimorada
📌 nova página "Sobre nós"
📌 página "Membros" mais amigável
Vamos dar uma olhada em todas essas melhorias!
NOTIFICAÇÕES
A partir de agora, você poderá ver que há novas notificações no canto superior direito da página perto da sua foto. Basta clicar no sino e você verá um menu suspenso com todas as suas notificações recentes, a partir do qual você pode acessar a página com detalhes:
Ao clicar no link "Ver todas", você será redirecionado para uma página onde poderá ver todas as suas notificações
A partir desta página, você pode "Marcar tudo como lido" ou seguir o link para a página que gerou a notificação. E gerencie suas configurações de assinatura.
INSCRIÇÕES
Alteramos o design da página Inscrições. Espero que seja mais fácil de usar agora
Você pode escolher quais notificações receberá da Comunidade de desenvolvedores, seja por e-mail ou pelo site. Você pode encontrá-lo na seção "Inscrições" da sua conta.
SOBRE NÓS
Já comentamos que criamos uma página nova "Sobre nós". Mas é tão fofa quanto um botão, então vale a pena mencionar mais uma vez 🥰
Você pode encontrá-la no menu superior, na seção Sobre --> Sobre nós:
MEMBROS
E outra página que ajustamos para sua conveniência é a página "Membros". Adicionamos uma nova coluna "Última atividade". E, claro, não esqueça que você pode classificar por qualquer coluna apenas clicando em seu nome.
Por enquanto é isso! Espero que você aprove todas as nossas melhorias.
Até a próxima com mais novidades!
Artigo
Larissa Prussak · Out. 28, 2021
Eu escrevi um tutorial passo a passo no repositório qewd-howtos sobre como você pode escrever aplicativos da web Node.js de última geração de várias páginas usando o QEWD-Up WebSocket/REST api back-end integrado com um framework da web como NuxtJS e Vue.js. Em particular com o mais recente framework NuxtJS/Vue.js , escrever aplicativos da web torna-se divertido novamente, permitindo que você escreva seus aplicativos de forma muito eficiente, ocultando todo o código template de você.
O tutorial deve ser muito fácil de fazer em sua máquina de desenvolvimento e consiste em duas partes:
Instruções para criar uma configuração básica QEWD-Up setup Node.js com WebSocket e REST endpoints usando um banco de dados InterSystems IRIS/Caché.
Instruções para criar um app demo front-end NuxtJS 3 (para a última versão beta do Nuxt 3) ou - alternativamente - instruções para um app demo front-end NuxtJS 2 (a versão de produção atual do Nuxt 2.x)
Você pode simplesmente clonar as configurações de demonstração do GitHub e executá-las em sua máquina de desenvolvimento usando Visual Studio Code onde sua instância de desenvolvimento IRIS / Caché está rodando. A demonstração é mantida o mais fácil possível, mas contém todas as etapas principais de que você precisa para começar a escrever aplicativos da vida real..Algumas capturas de tela:
O front-end NuxtJS 3:
O back-end do NuxtJS 3 em execução no Node.js:
O back-end QEWD-Up rodando em Node.js + IRIS / Caché:
Se você tiver comentários ou encontrar problemas, crie um problema no repositório GitHub relevante!
Boa codificação e poste seus comentários abaixo do que você achou!
Ward
Anúncio
Angelo Bruno Braga · Ago. 18, 2022
Olá Desenvolvedores,
Não percam esta sessão hands-on apresentada pelo @Donald.Woodlock, Vice Presidente Soluções para Saúde na InterSystems:
⏯ Machine Learning 201 - Redes Neurais e Reconhecimento de Imagens
Veja como treinar um modelo de Machine Learning para realizar Classificação de Imagens. Um dos problemas clássicos originais que o processo de machine learning tentava resolver por décadas era como distinguir um gato de um cachorro em fotos – algo que mesmo uma criança pequena consegue fazer mas era muito difícil para computadores. Depois de muitas décadas o problema foi resolvido pavimentando o caminho para o ML para agora podermos utilizá-lo na leitura de imagens de radiologia, identificação de rostos, identificação de tipos de objetos para carros autônomos, identificar desmatamento a partir de imagens de satélites e vários outros tipos de situações. Aprenderemos como isso é feito em uma sessão de hands-on. Em particular, trabalharemos sobre um problema baseado na identificação de dígitos escritos a mão. Construiremos, de forma sucessiva, modelos cada vez mais sofisticados para melhorar a acurácia desta tarefa utilizando Regressão Logística, We will build successively more sophisticated models to improve the accuracy of this task including Logistic Regression, uma Rede Neural Direta e uma Rede Neural Convolucional.
Esta é uma sessão de 2 horas que foi gravada ao vivo com poucos participantes. Não é necessária experiência em ML ou python mas se sentir a vontade em codificar pode ajudar.
Você precisará de uma conta do Kaggle (http://www.kaggle.com) para acompanhar o vídeo. Esta conta precisa ser 'verificada por telefone' para permitir oi uso das funcionalidades GPU do Kaggle, necessárias para um dos exercícios.
Os links que você precisará são: https://www.kaggle.com/competitions/digit-recognizerOs Notebooks estão neste link: http://www.donwoodlock.com/ml201/25Jul2022/index.html
Aproveitem e, fiquem ligados!
Discussão
Heloisa Paiva · Maio 2
Já faz um tempo desde que a nova interface de usuário para Produções e DTL foi publicada como uma prévia e eu gostaria de saber suas opiniões sobre ela.
AVISO: Esta é uma opinião pessoal, totalmente pessoal e não relacionada com a InterSystems Corporation.
Vou começar com a tela de Interoperabilidade:
Tela de Produção:
O estilo é sóbrio e sem adornos, seguindo a linha do design de serviços de nuvem, eu gosto.
Mas, sempre um mas... ou talvez dois:
Na minha opinião, há informação demais, o menu esquerdo é supérfluo. É verdade que você pode recolhê-lo, mas não quero fazer isso cada vez que uso a tela. Não preciso ver o tempo todo todas as produções no meu NAMESPACE, os Itens de Produção, Conjuntos de Regras e Transformações de Dados. Sinto que os designers sofreram um "horror vacui"
Sobre esses menus, parece que as opções estão muito próximas:
E exibir os editores de Regras e Transformações de Dados na mesma tela para telas pequenas como a de um laptop é um pesadelo de rolagem:
Uma janela pop-up com os editores seria mais "limpa" para o usuário comum. Um ponto positivo é que podemos selecionar como queremos abrir os editores.
Mas talvez tenhamos opções demais.
Editor de DTL:
Bem, eu gosto, o design é simples e claro, talvez, como na tela de Produção, as linhas estejam muito próximas e perdemos o arrastar e soltar para ligar os campos.
Conclusão:
O design foi modernizado e parece agradável, mas na minha opinião como um ex-desenvolvedor web "menos é mais". Eu gostaria de trabalhar com telas mais simples, com um comportamento bem definido, não preciso acessar todas as funcionalidades de interoperabilidade na mesma tela.
Minha modesta opinião, precisamos equilibrar funcionalidades e uma interface de usuário amigável e moderna, o novo design parece ir nessa direção. Obrigado a toda a equipe envolvida no desenvolvimento!
[OBS.: o texto reflete a opinião pessoal do AUTOR, não do TRADUTOR.]
Artigo
Henrique Dias · Out. 26, 2020
Fala pessoal!
Quero dividir com vocês um projeto pessoal, que iniciou como um simples pedido no meu trabalho:
É possível saber quantas licenças Caché estamos utilizando?
Lendo outros artigos aqui na comunidade, eu encontrei este excelente artigo de David Loveluck
APM - Utilizando Caché History Monitorhttps://community.intersystems.com/post/apm-using-cach%C3%A9-history-monitor
Então, utilizando o artigo de David como base, eu comecei a utilizar o Caché History Monitor e a exibir todas as informações.Quando me deparei com o seguinte dilema: Qual a melhor tecnologia de frontend que eu posso usar?
Minha decisão acabou sendo pelo, bom e velho CSP, assim o cliente para qual estou trabalhando poderia se dar conta de que Caché é muito mais que MUMPS/Aplicações de Terminal.E depois de criar as páginas para exibir os históricos de licenças, crescimento de dataset e sessões CSP, eu resolvi me arriscar e imaginar um novo layout para System Dashboard e para página de Processos.Tudo funcionou perfeitamente com minha instância Caché.
Entretando, como isso ficaria no IRIS?
Seguindo outro ótimo artigo de Evgeny Shvarov
Using Docker with your InterSystems IRIS development repositoryhttps://community.intersystems.com/post/using-docker-your-intersystems-iris-development-repository
Passei a utilizar Docker no meu projeto e disponibilizei o código no Github, então agora, todos vocês podem usufruir do meu projeto seguindo alguns passos.
Como executar
Para iniciar a testar o código do repositório, basta você fazer o seguinte:
1. Faça o clone/git pull do repositório em algum diretório local$ git clone https://github.com/diashenrique/iris-history-monitor.git
2. Abra o terminal no diretório escolhido e execute:$ docker-compose build
3. Execute o container IRIS do seu projeto com o comando:$ docker-compose up -d
Como testar
Abra seu browser favorito e vá para:
Ex.: http://localhost:52773/csp/irismonitor/dashboard.csp
O usuário _SYSTEM pode executar o dashboard e outras funcionalidades.
System Dashboard
System Dashboard contém os seguintes itens:
Licença
Tempo Ativo
Erros de Aplicação
Processos Caché
Sessões CSP
Tabela de Lock
Espaço do Journal
Status do Journal
ECP AppServer
ECP DataServer
Write Daemon
Eficiência Caché
Alertas Sérios
O gráfico de linha, plota um ponto no gráfico a cada 5 segundos
System Menu
System Processes
Processes Filters
Use filtros diferentes para atingir o resultado que você precisa. Você também pode selecionar múltiplos filtros, pressione Shift + clicando no cabeçalho da coluna. E até exportar o datagrid para Excel!
History Monitor
O monitor de dados históricos para Sessões CSP e Licenciamento exibem informações divididas em 3 seções:
A cada 5 minutos
Diariamente
De hora em hora
Crescimento de dataset somente exibe as informações diárias.
As páginas de histórico compartilham as seguintes funcionalidades abaixo:
Seletor de intervalo de datas
O valor padrão é "Últimos 7 dias."
Gráfico / Data Table
No canto superior direito de cada seção existem 2 botões (Gráfico/Data Table)
O Data Table exibe a informação que alimenta o gráfico, e você ainda pode fazer download disso no formato Excel.
O arquivo excel exibe o mesmo formato, conteúdo e o agrupamento definido na página CSP.
Zoom
Todos os gráficos tem a opção de Zoom, para que a informação desejada, possa ser visualizada com maiores detalhes.
Média e Máximo
Nas seções Diariamente e De hora em hora, os gráficos exibem as informações Média/Máxima.
Média
Máxima
Aproveitem!
Artigo
Yuri Marx · Nov. 30, 2021
A InterSystems IRIS possui um ótimo sistema de auditoria. Ele é responsável por auditar eventos do sistema, mas você pode usá-lo para auditar seus aplicativos (ótimo recurso).
O sistema de auditoria é baseado no conceito de evento. Os eventos podem ocorrer com o IRIS ou em um aplicativo. Portanto, temos dois tipos de eventos para o sistema de auditoria:
1. Eventos do sistema: eventos ocorridos nos componentes IRIS da InterSystems (banco de dados, interoperabilidade, análise e core);
2. Eventos de usuário: evento ocorrido em aplicativos de usuário / empresa (seus), com os tipos de eventos de usuário criados (mapeados) por você no Portal de gerenciamento> Sistema> Gerenciamento de segurança> Eventos de usuário.
Para ver os eventos registrados pelos componentes do IRIS, vá para System Administration > Security > Auditing > Configure System Events. Os eventos do sistema começam com o caractere % + módulo IRIS (por exemplo,% Ensemble /% Production / StartStop,% System /% Login / Login). Se você clicar em Alterar status, poderá ativar ou desativar o tipo de evento do sistema.
Para ver o evento registrado por aplicativos de negócios (seus aplicativos), vá para System Administration > Security > Configure User Events. Você precisa modelar/registrar os tipos de eventos de seu aplicativo. O caractere % no início do nome da auditoria é reservado para os eventos de auditoria do sistema.
Todos os registros de auditoria são armazenados na tabela Security.Events Persitent Class / SQL. O nome do evento de auditoria possui 3 campos:
1. Fonte: fonte do evento (nome do aplicativo ou módulo);
2. Tipo: tipo de evento (tipo de dado ou tipo de característica);
3. Evento: nome do evento (nome da empresa, meio / descrição do evento).
Para consultar ou ver um relatório com registros de auditoria, vá para System Administration > Security > Auditing > View Audit Database. Veja:
No artigo, vou mostrar a você como fazer eventos de auditoria de usuário dentro do seu aplicativo, usando um aplicativo REST como exemplo. O aplicativo de amostra para ver os eventos de auditoria do usuário é: https://openexchange.intersystems.com/package/Audit-Mediator.
Siga estas etapas para o aplicativo de auditoria de amostra:
1. Clone o projeto
$ git clone git@github.com: yurimarx/iris-api-audit-mediator.git
2. Construa e faça o build o código-fonte do projeto
$ docker-compose up -d --build
3. Vá para Administration > Security > Auditing > Configure User Events4. Pressione o botão Create New Event5. Defina o Event Source: RESTAPI6. Defina o Event Type: solicitação7. Defina o Event Name: RESTAPI8. Pressione Save9. Preencha seu aplicativo Person com dados, chame o endpoint http://localhost:52773/crud/persons/populate10. Agora, ligue para http://localhost:52773/crud/persons/all ou qualquer outro endpoint11. Esta solicitação será registrada no banco de dados de auditoria12. Agora vá para System Administration > Security > Auditing > View Audit Database13. Procure as linhas com Event Source RESTAPI e Event Type Request e clique em Detail para ver os detalhes do registro de auditoria. Ver:
14. Clique em Details e veja:
O código fonte responsável por registrar a auditoria é:
SET tSC = $$$OK
TRY {
Set tSC = $SYSTEM.Security.Audit("RESTAPI","Request", "RESTAPI","URL: "_pUrl_". Method: "_pMethod_".","REST API request")
} CATCH ex {
SET tSC = ex.AsStatus()
}
Então, é muito fácil auditar, você deve usar a classe de método $SYSTEM.Security.Audit(). Veja mais detalhes em: https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=AAUDIT.
Artigo
Claudio Devecchi · Out. 13, 2020
##Introdução
Estamos na era da **economia multi-plataforma**, e as API's são a *"liga"* deste cenário digital. Sendo tão importantes, elas são encaradas por desenvolvedores como um **serviço** ou **produto** a ser consumido. Assim sendo, a **experiência** na sua utilização é um fator crucial de **sucesso**.
Visando melhorar esta experiência, padrões de especificação, como o [OpenAPI Specification (OAS)](https://swagger.io/specification/#:~:text=Introduction,or%20through%20network%20traffic%20inspection.) estão cada vez mais sendo adotados no desenvolvimento de API's RESTFul.
##O que é o IRIS ApiPub?
IRIS ApiPub é um projeto [Open Source](https://en.wikipedia.org/wiki/Open_source), que tem como principal objetivo **publicar** automaticamente **API's RESTful** criadas com a tecnologia [Intersystems IRIS](https://www.intersystems.com/try-intersystems-iris-for-free/), da forma mais simples e rápida possível, utilizando o padrão [Open API Specification](https://swagger.io/specification/) (OAS) versão 3.0.
Ele permite que o usuário foque principalmente na **implementação** e nas **regras de negócio** das API’s (Web Methods), abstraindo e automatizando os demais aspectos relacionados a **documentação, exposição, execução e monitoramento** dos serviços.
Este projeto também inclui uma implementação de exemplo completa (**apiPub.samples.api**) do *sample* [Swagger Petstore](https://app.swaggerhub.com/apis/Colon-Org/Swagger-PetStore-3.0/1.1), utilizado como *sample* oficial do [swagger](https://swagger.io/).
## Faça um teste com os teus serviços SOAP existentes
Se você já possui serviços SOAP publicados, você pode testar a sua publicação com Rest/JSON com OAS 3.0.
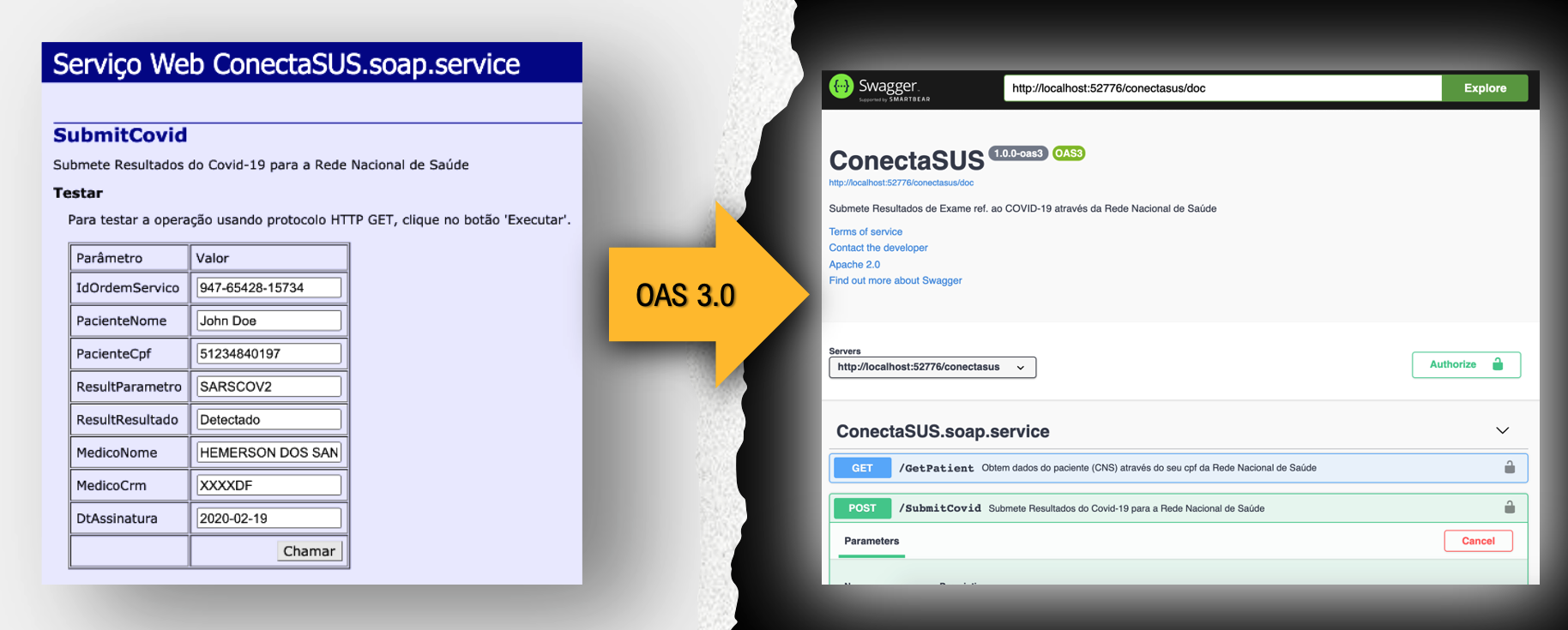
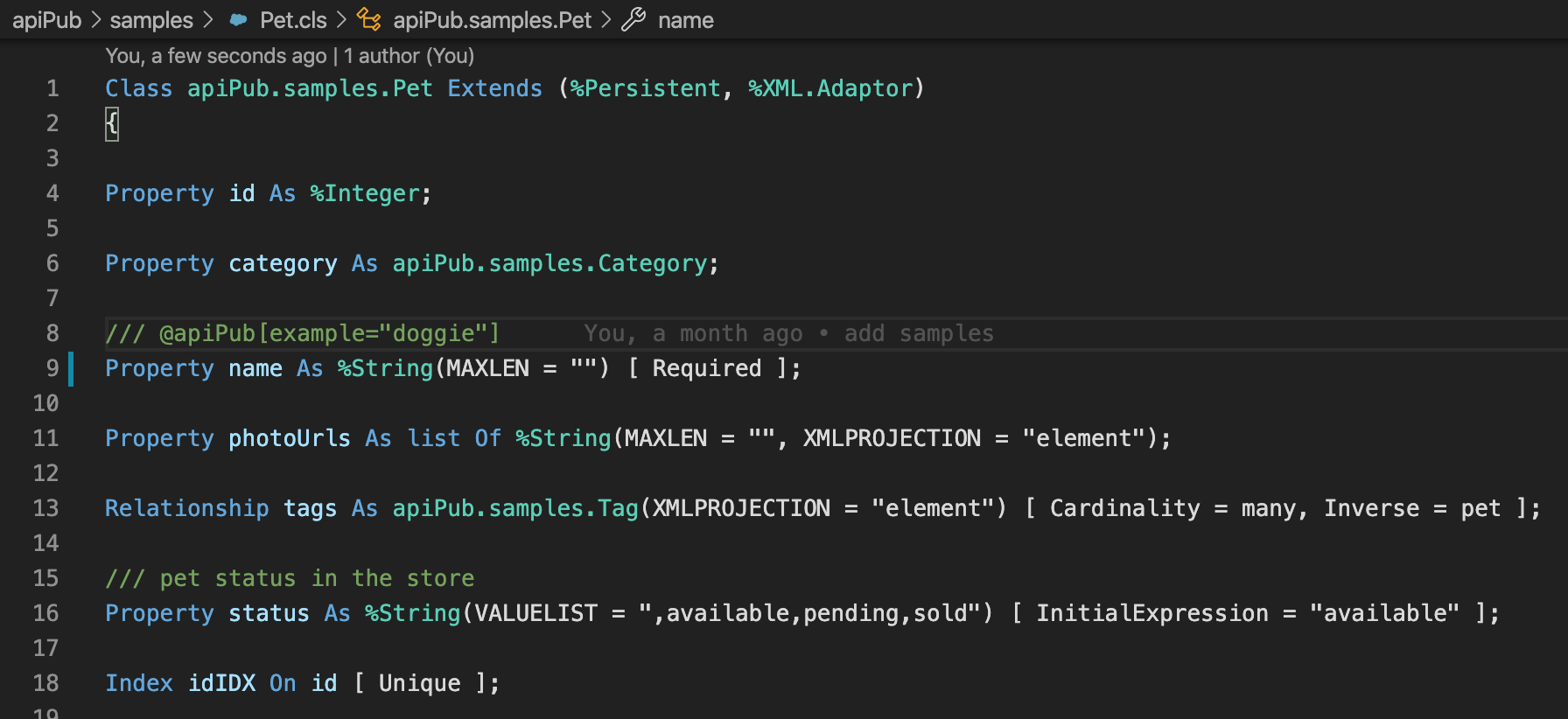
Ao publicar métodos com tipos complexos é necessário que a classe do objeto seja uma subclasse de %XML.Adaptor. Desta maneira serviços SOAP já construídos se tornam automaticamente compatíveis.
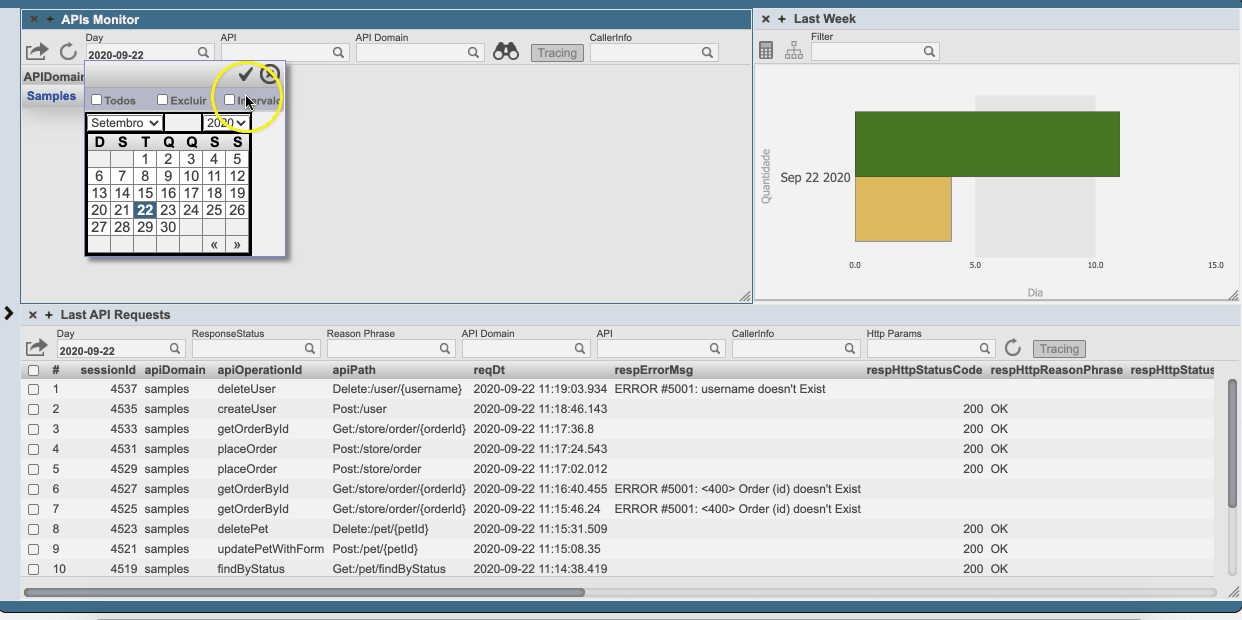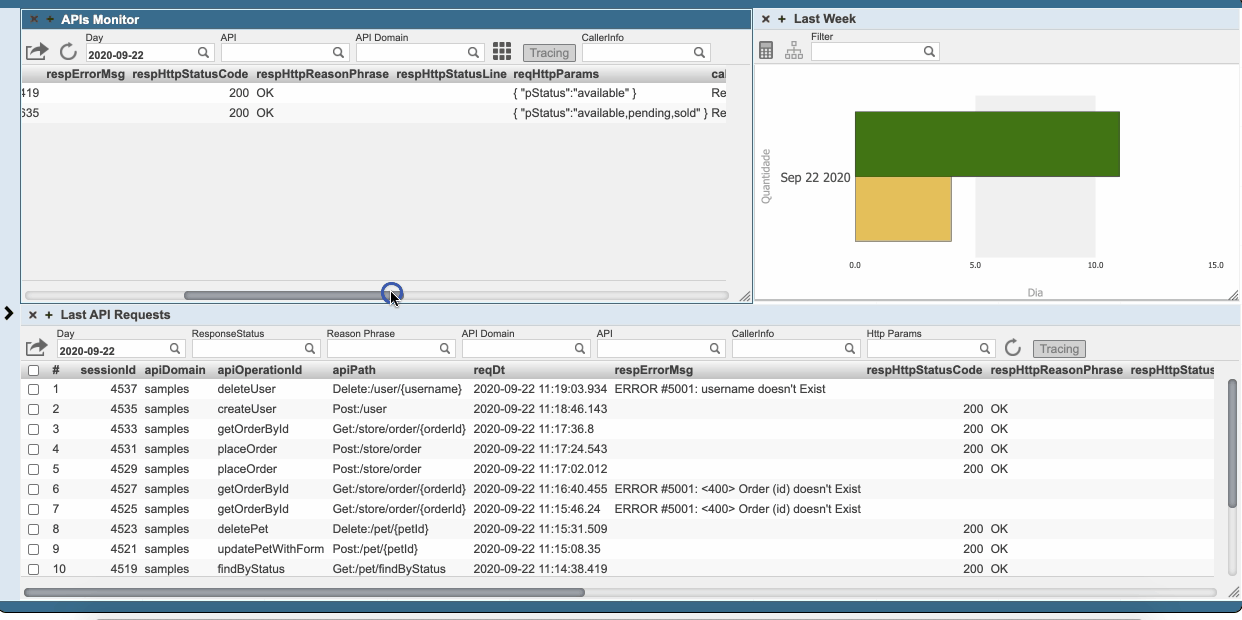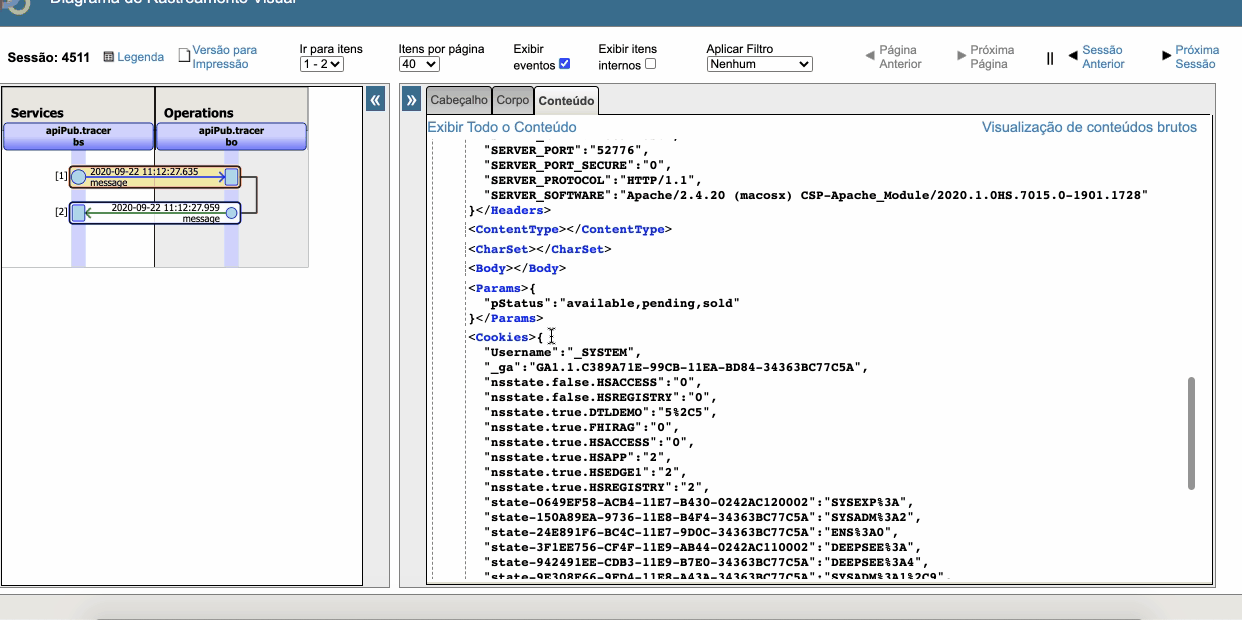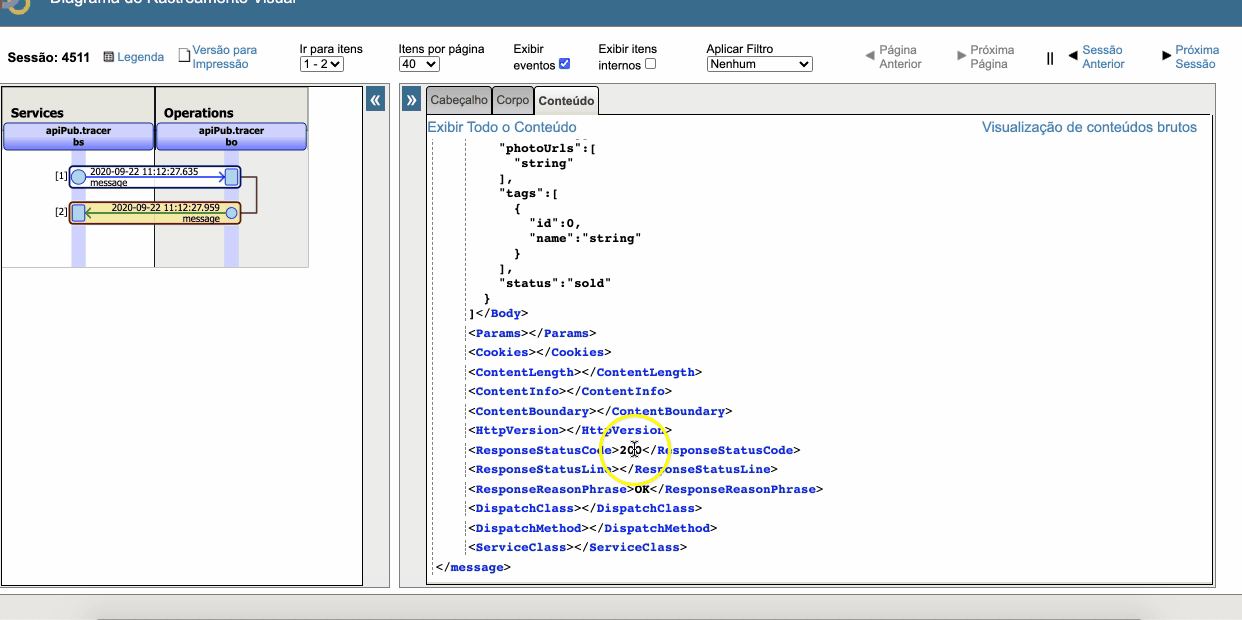
## Monitore as tuas API's com o IRIS Analytics
Habilite o monitoramento das API's para **administrar** e **rastrear** todas as *chamadas Rest*. Monte também os seus próprios indicadores.
## Instalação
1. Faça um *Clone/git pull* do repositório no diretório local.
```
$ git clone https://github.com/devecchijr/apiPub.git
```
2. Abra o terminal neste diretorio e execute o seguinte comando:
```
$ docker-compose build
```
3. Execute o container IRIS com o projeto:
```
$ docker-compose up -d
```
## Testando a Aplicação
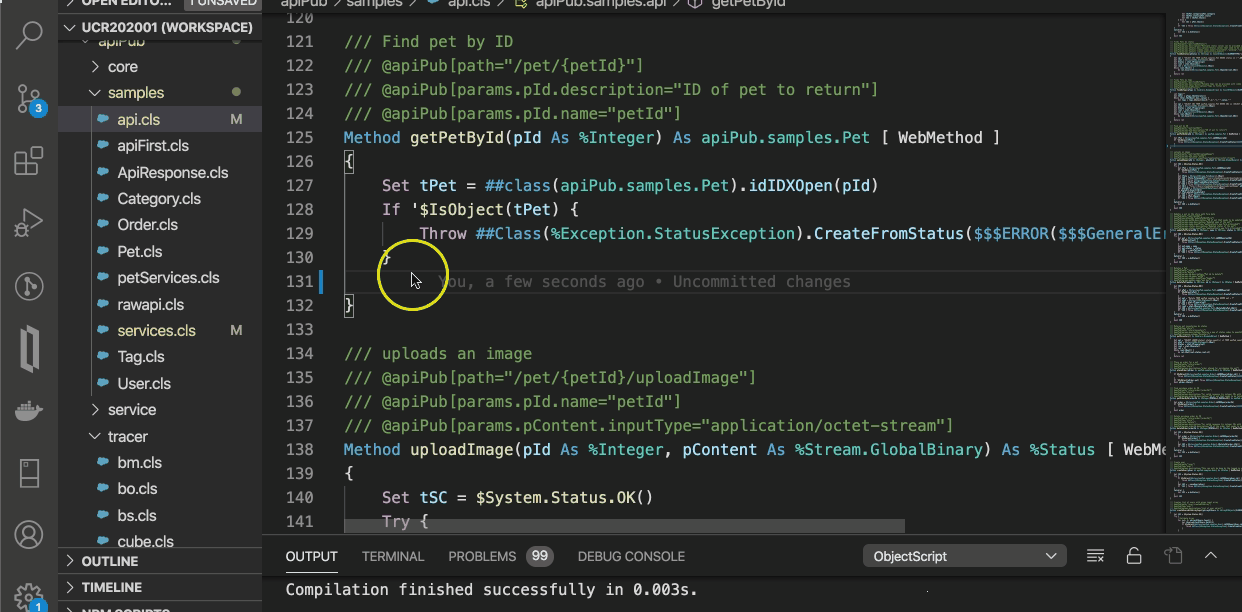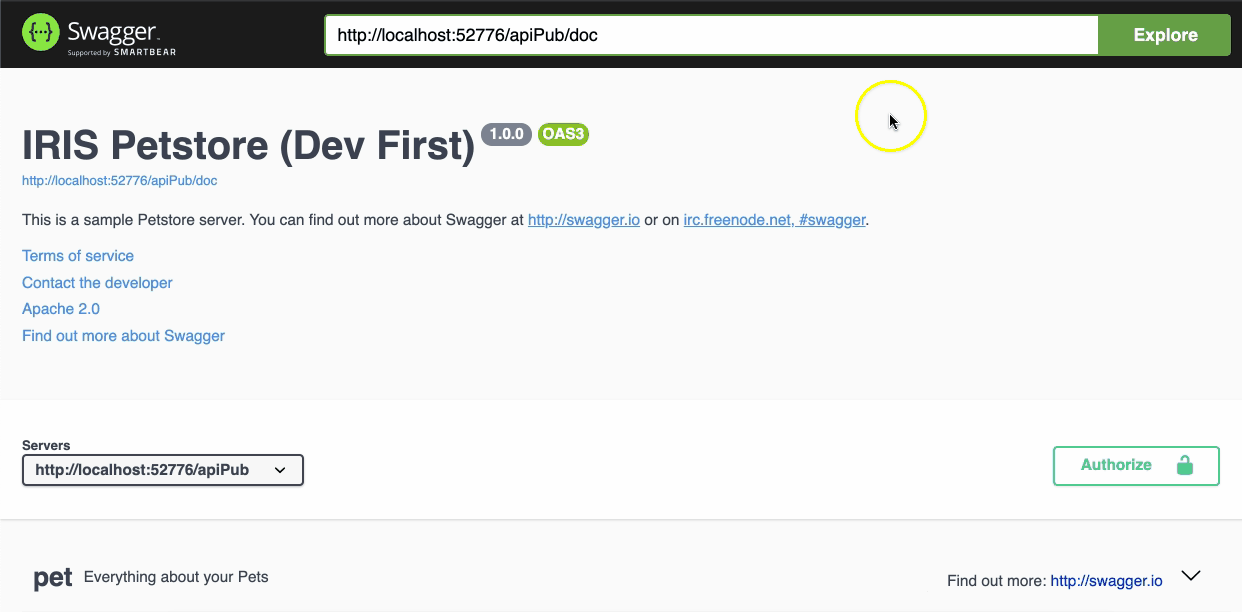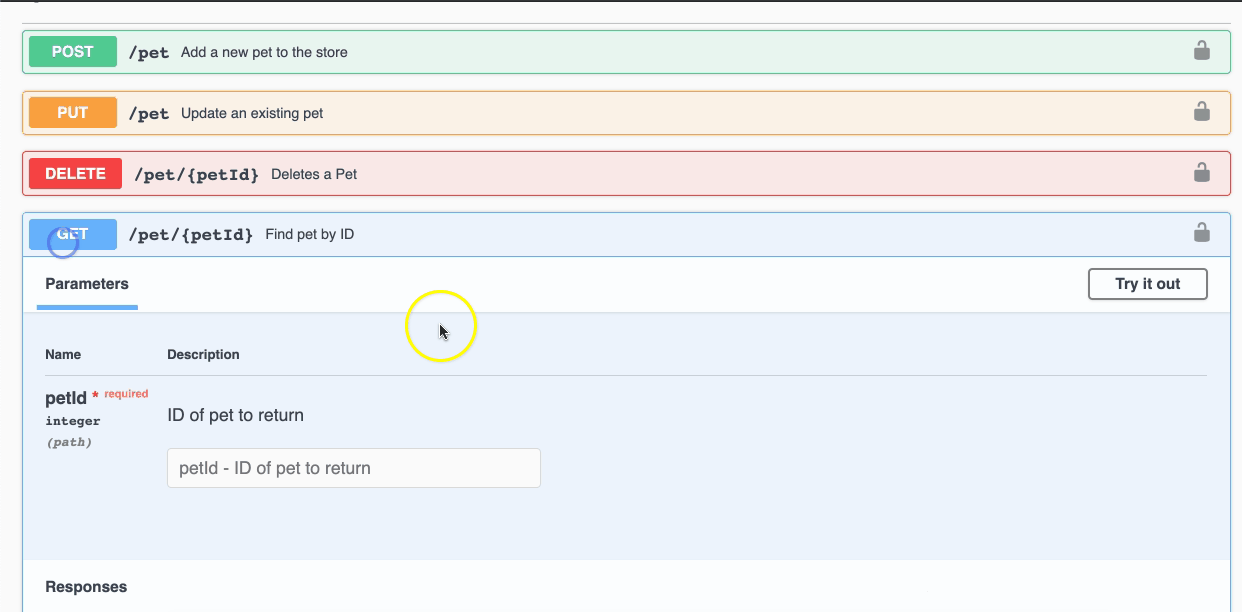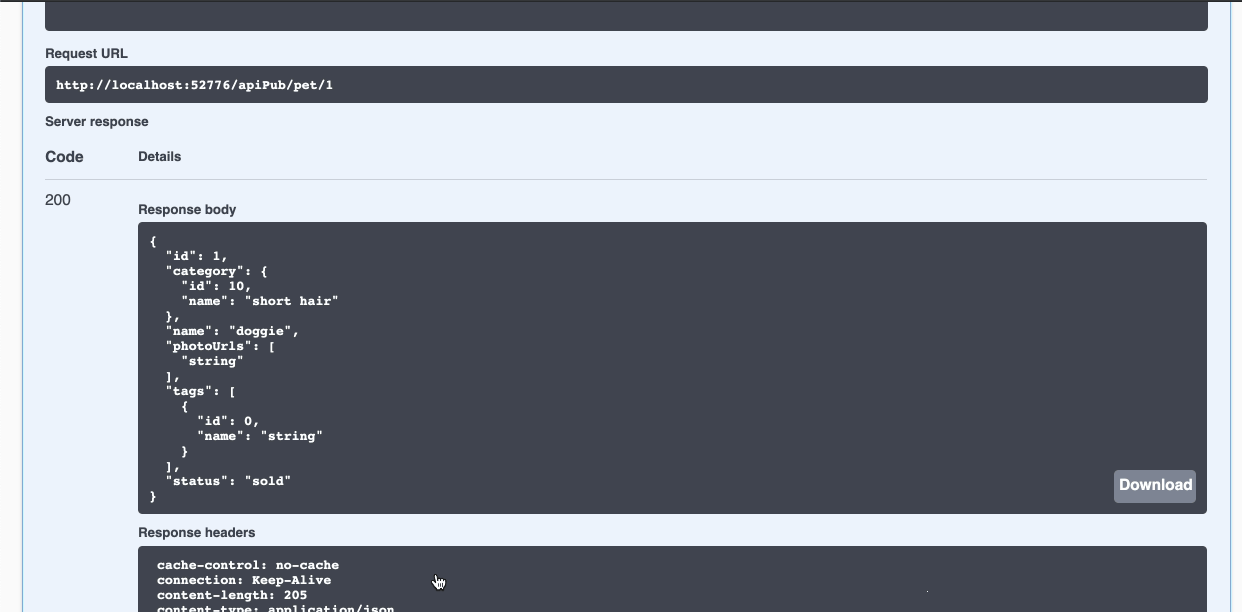
Abra a URL do swagger http://localhost:52773/swagger-ui/index.html
Tente executar alguma API do Petstore, como fazer o *post* de um novo *pet*.
Veja o [dashboard do apiPub Monitor](http://localhost:52773/csp/irisapp/_DeepSee.UserPortal.DashboardViewer.zen?DASHBOARD=apiPub_Monitor_Dashboard/apiPub%20Monitor.dashboard). Tente fazer um drill down no domínio petStore para explorar e analisar as mensagens.
Mude ou crie metódos na classe [apiPub.samples.api](https://github.com/devecchijr/apiPub/blob/master/src/apiPub/samples/api.cls) e volte a consultar a documentação gerada.
Repare que todas as mudanças são automaticamentes refletidas na documentação OAS ou nos schemas.
## **Publique sua API no padrão OAS 3.0 em apenas 3 passos:**
## Passo 1
Defina a classe de implementação das tuas API’s e **rotule** os métodos com o atributo [WebMethod]
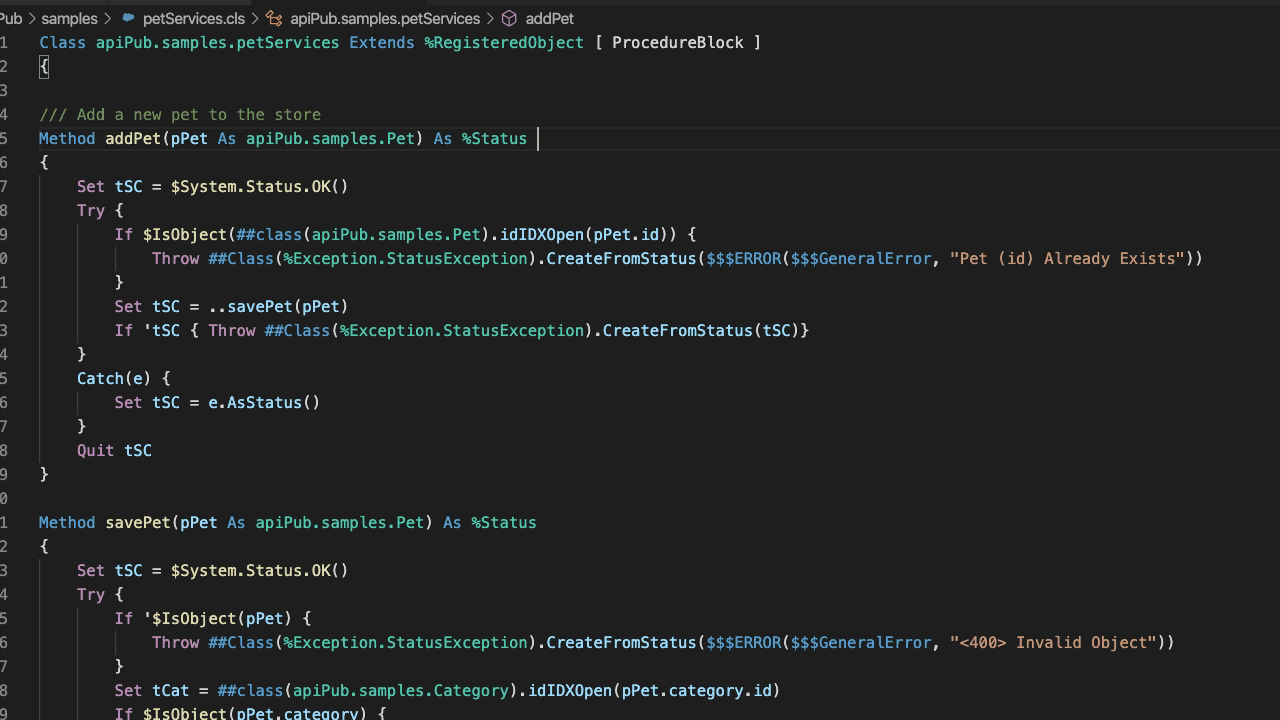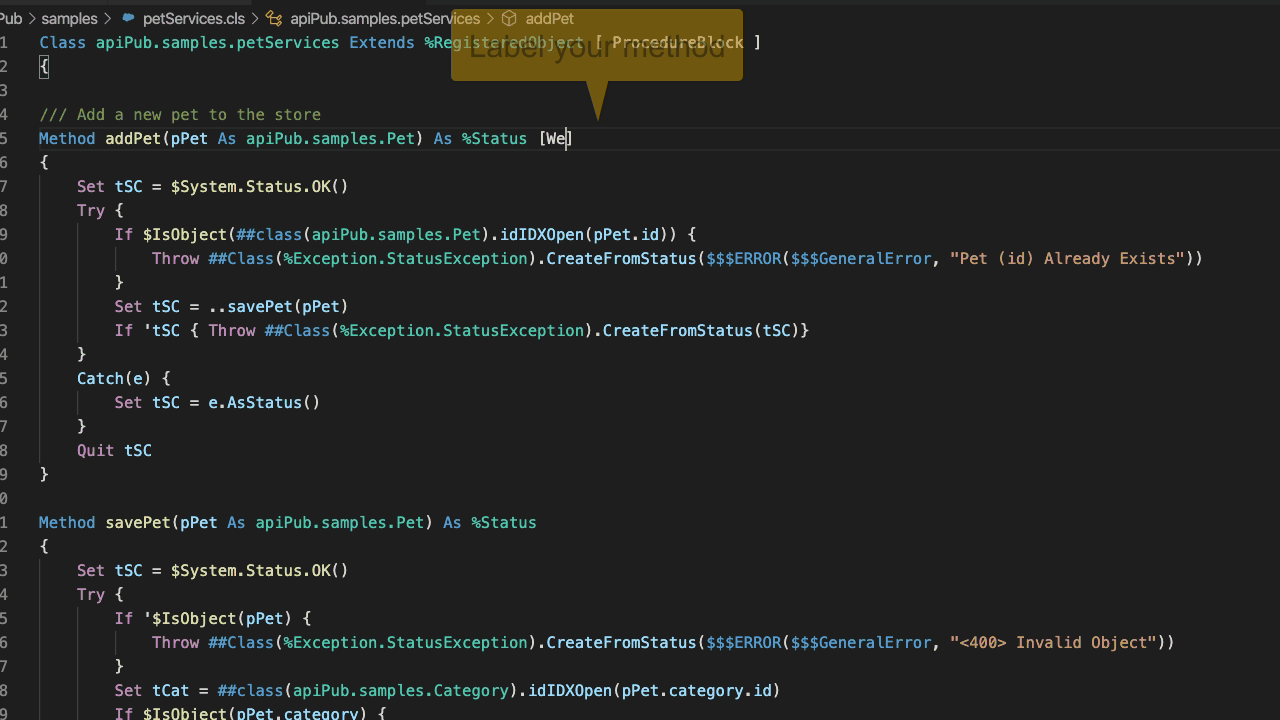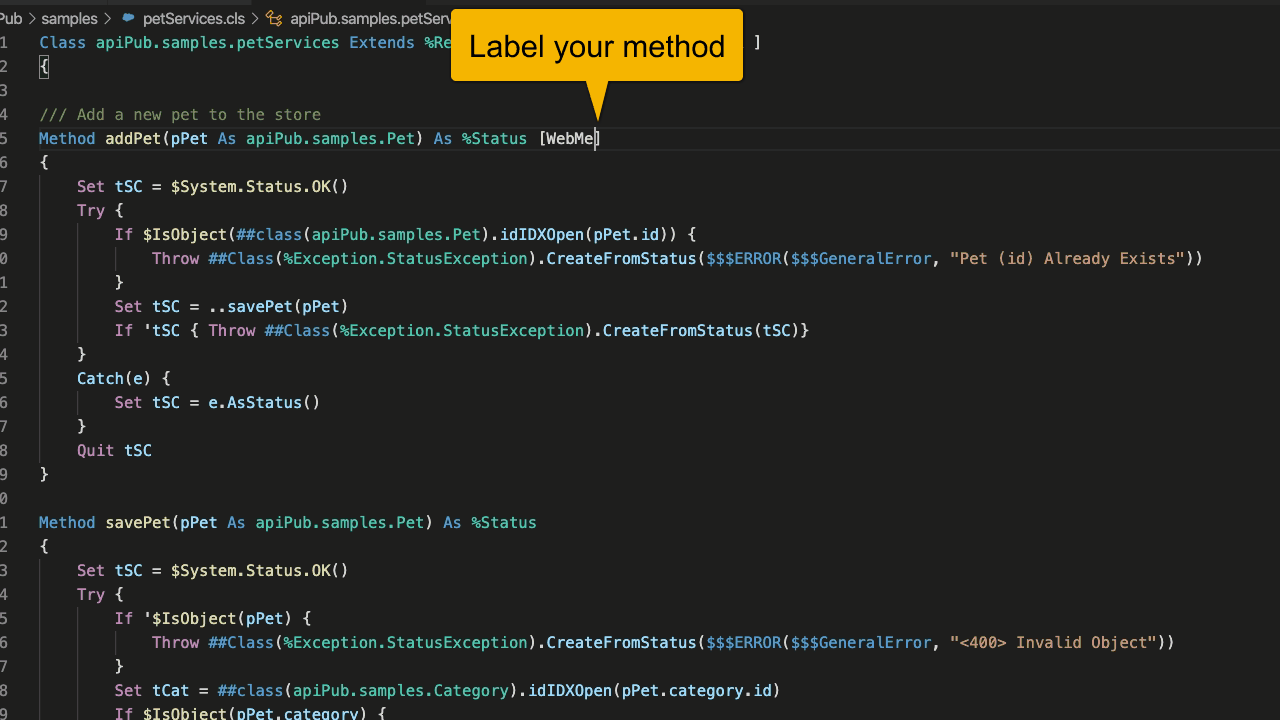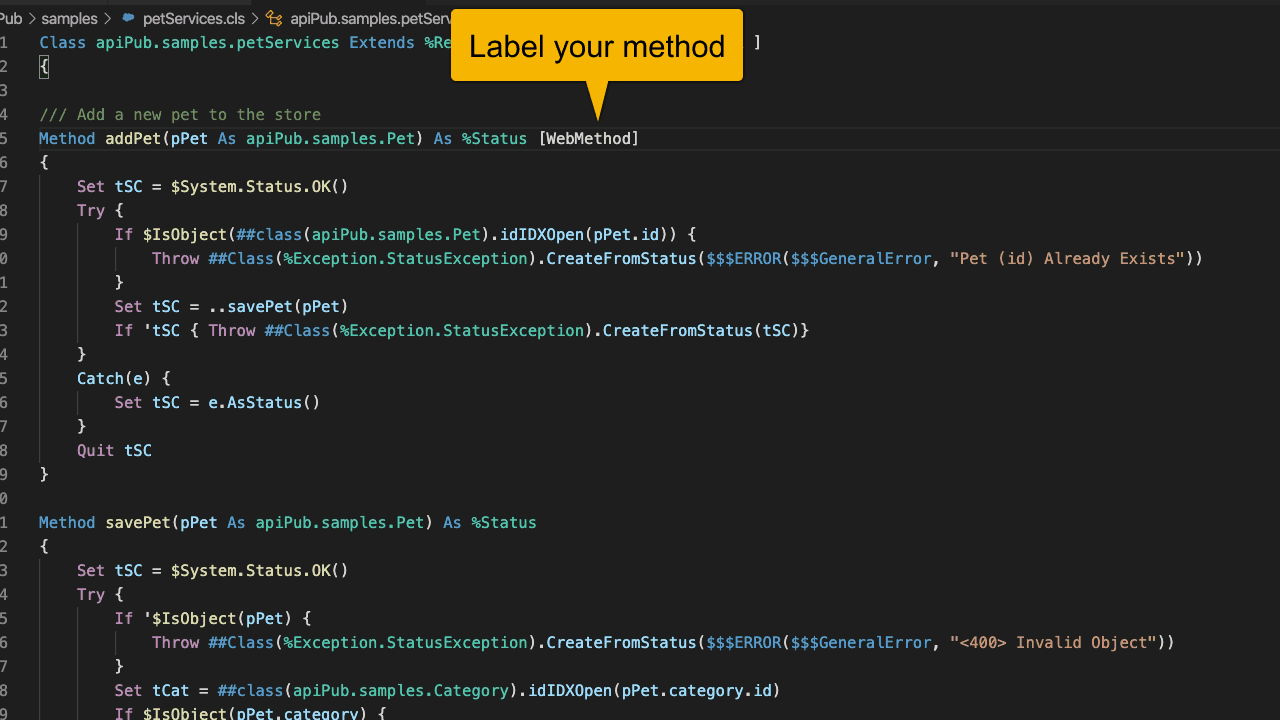
*Caso você já possua alguma implementação com WebServices esse passo não é necessário.*
## Passo 2
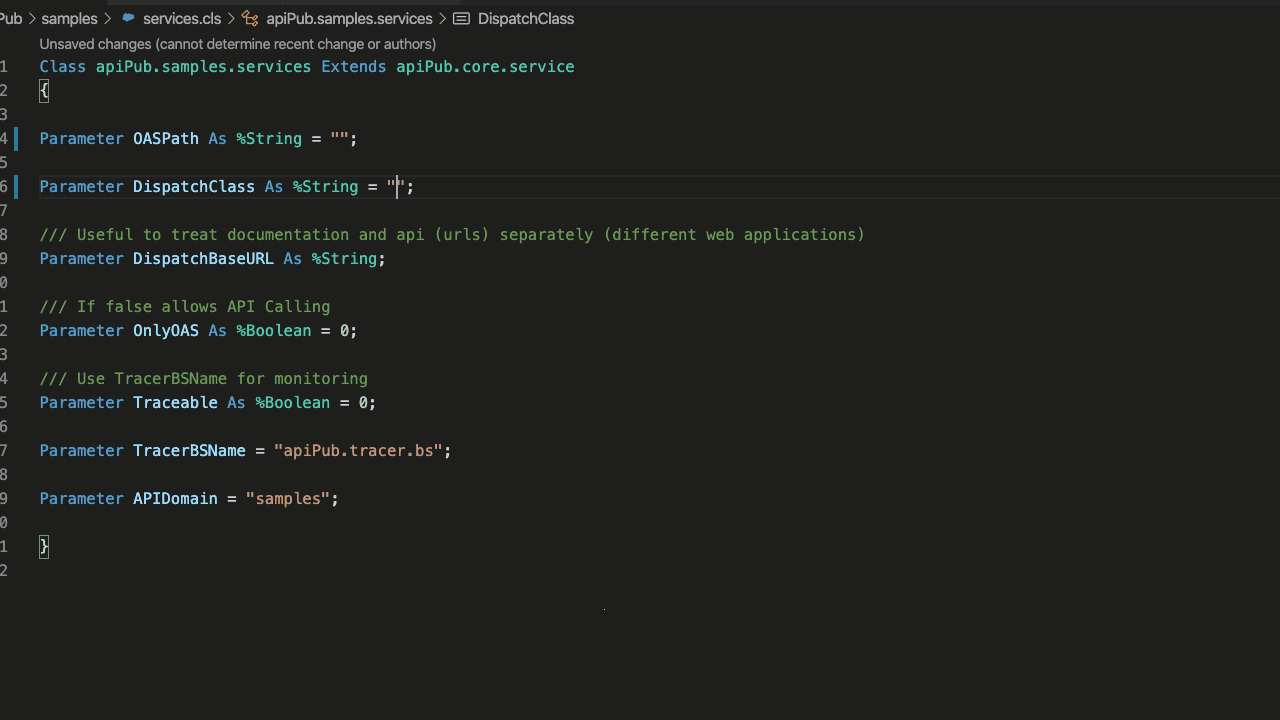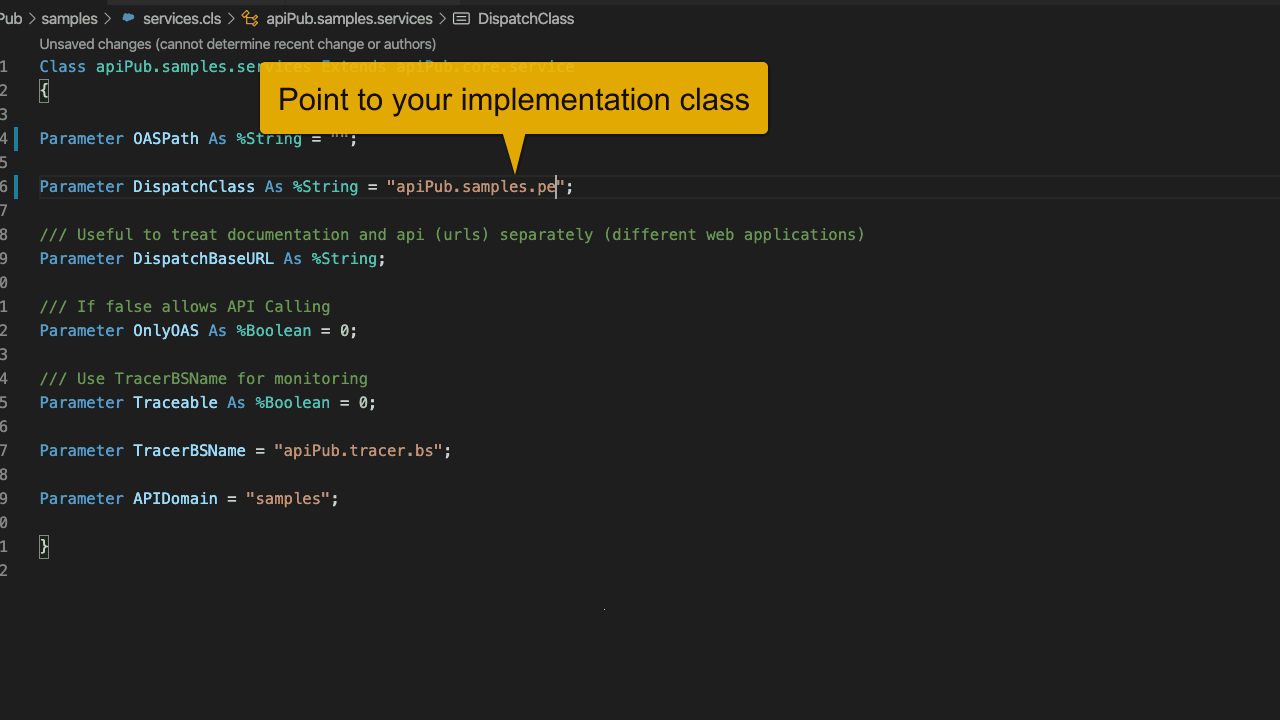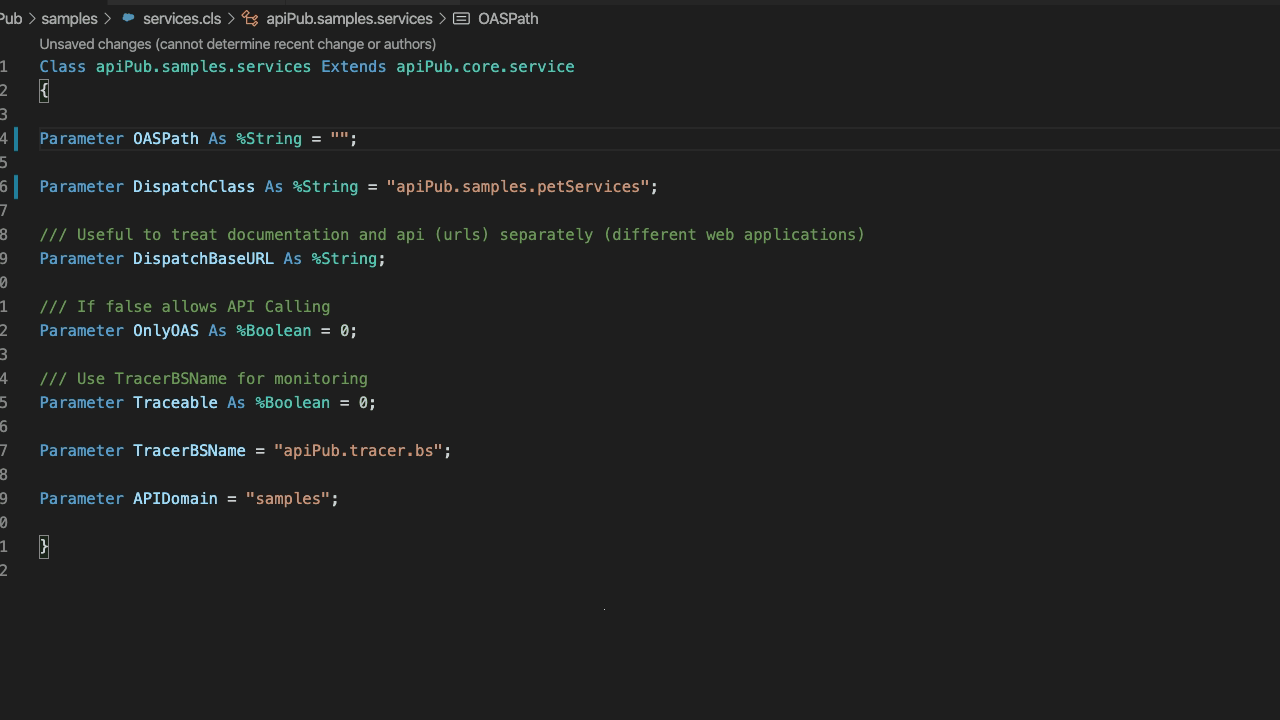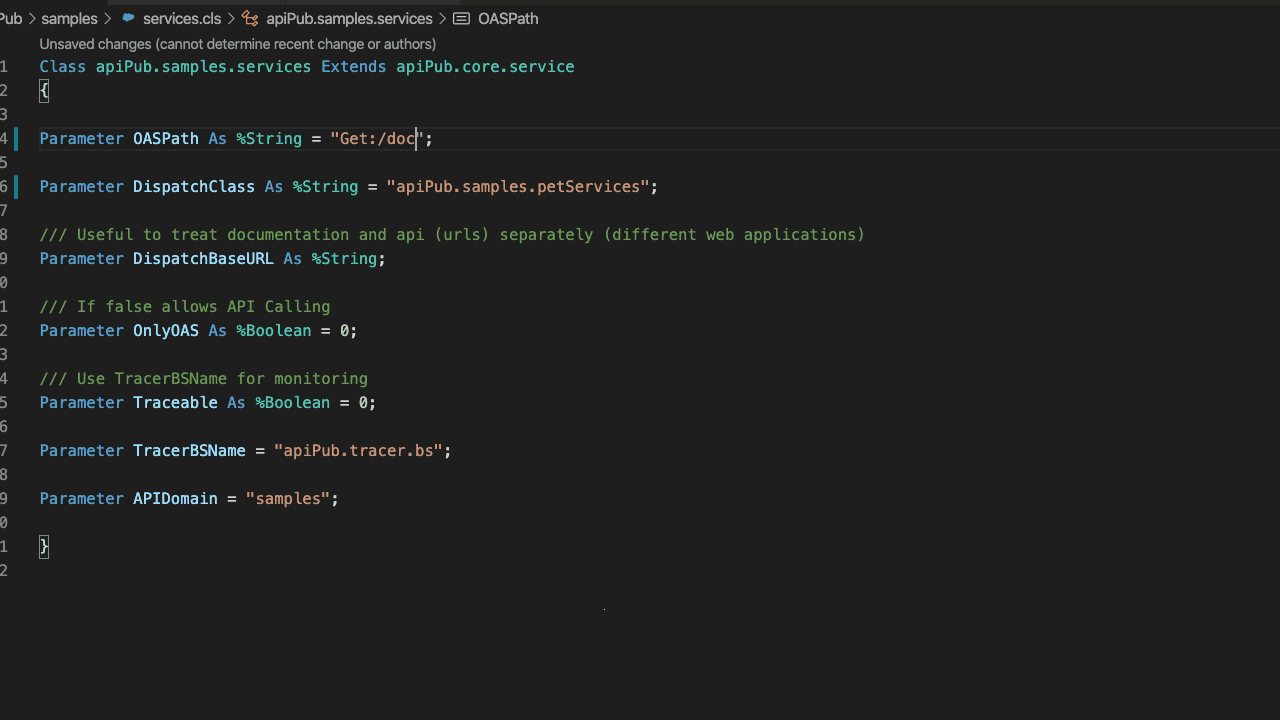
Crie uma **subclasse** de apiPub.core.service e aponte a propriedade DispatchClass para a sua classe de Implementação criada anteriormente. Informe também o path de documentação OAS 3.0. Se desejar, aponte para a classe apiPub.samples.api (PetStore).
## Passo 3
Crie uma Aplicação Web e aponte a classe de Dispatch para a classe de serviço criada anteriomente.
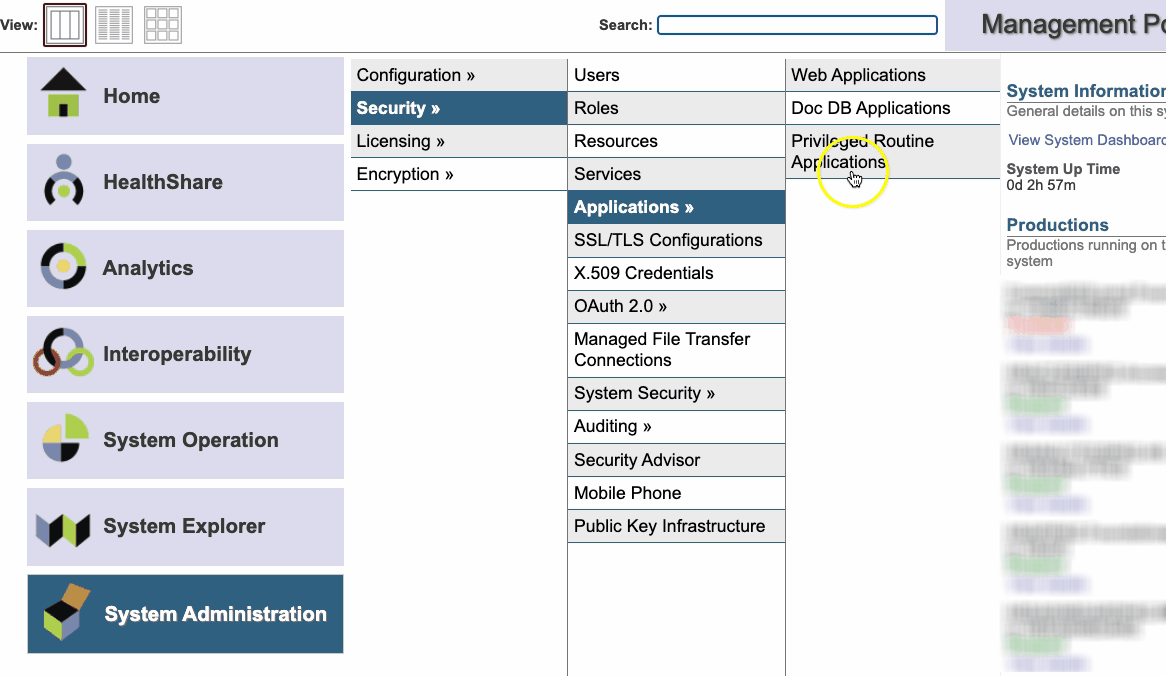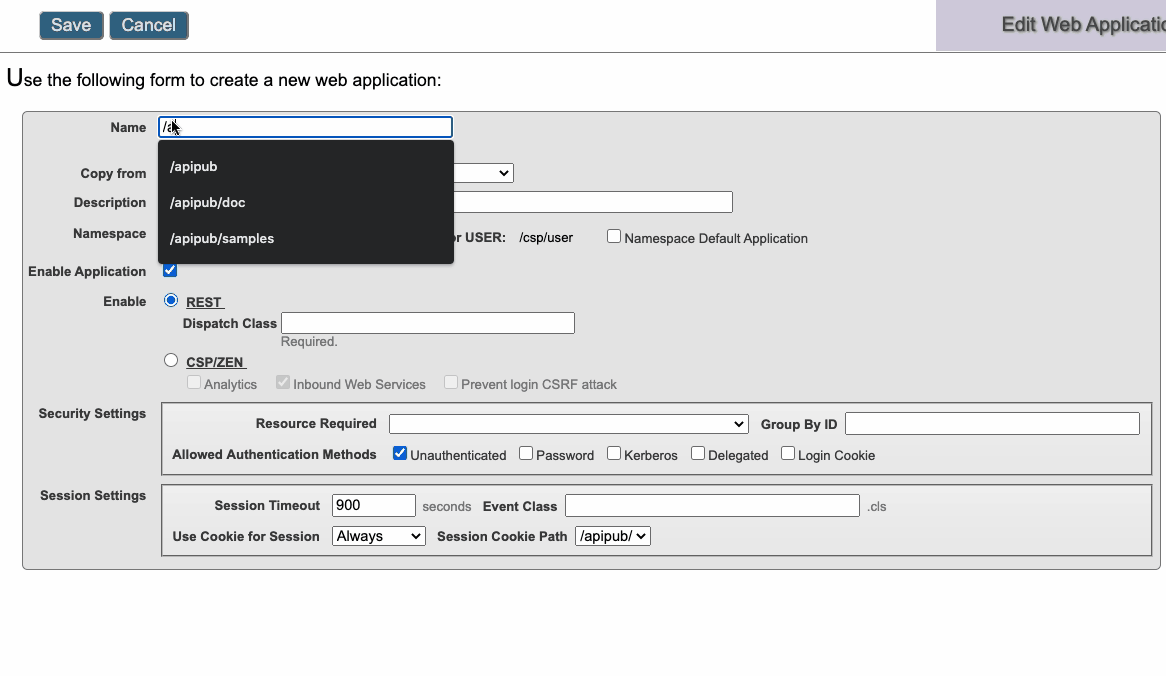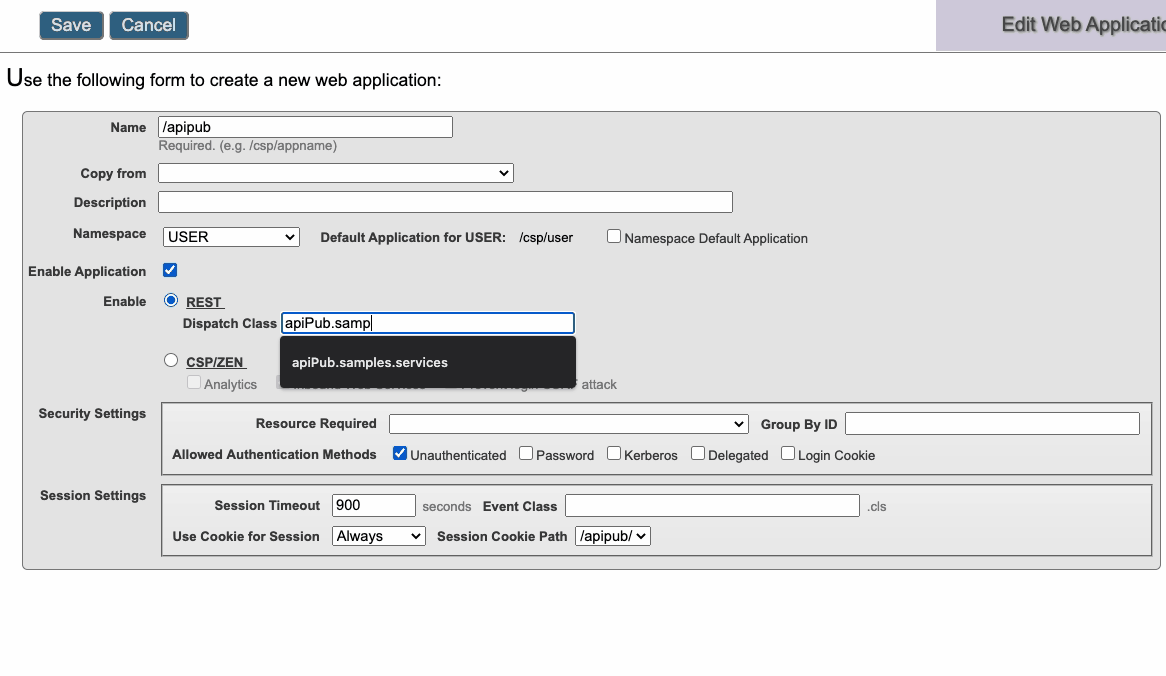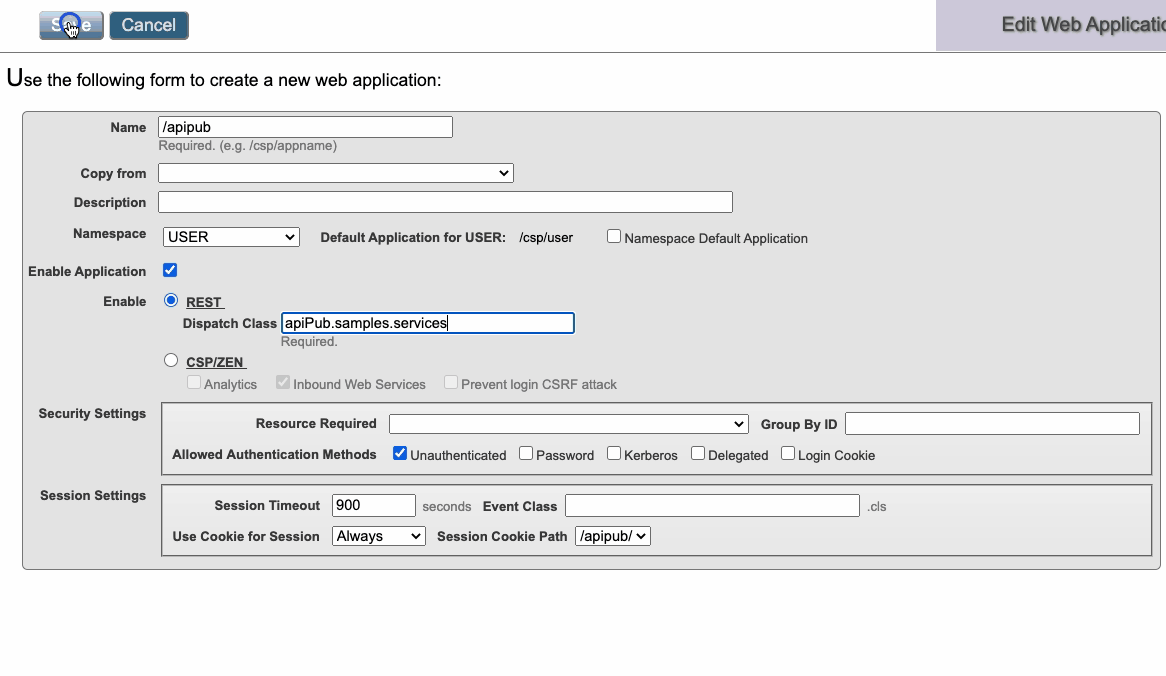
## Utilize o Swagger
Com o [iris-web-swagger-ui](https://openexchange.intersystems.com/package/iris-web-swagger-ui) é possível expor a especificação do teu serviço. Basta apontar para o path de documentação e ... **VOILÁ!!**
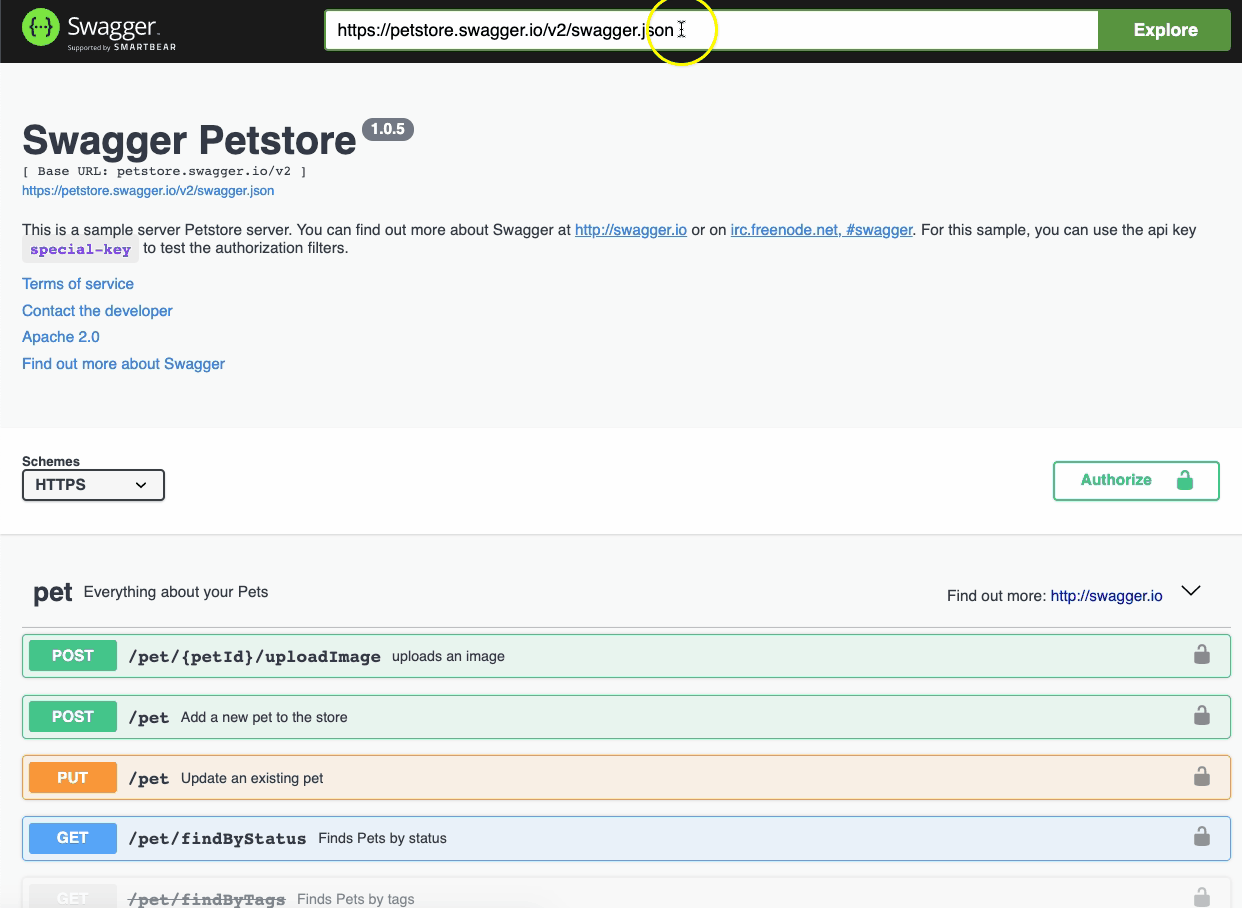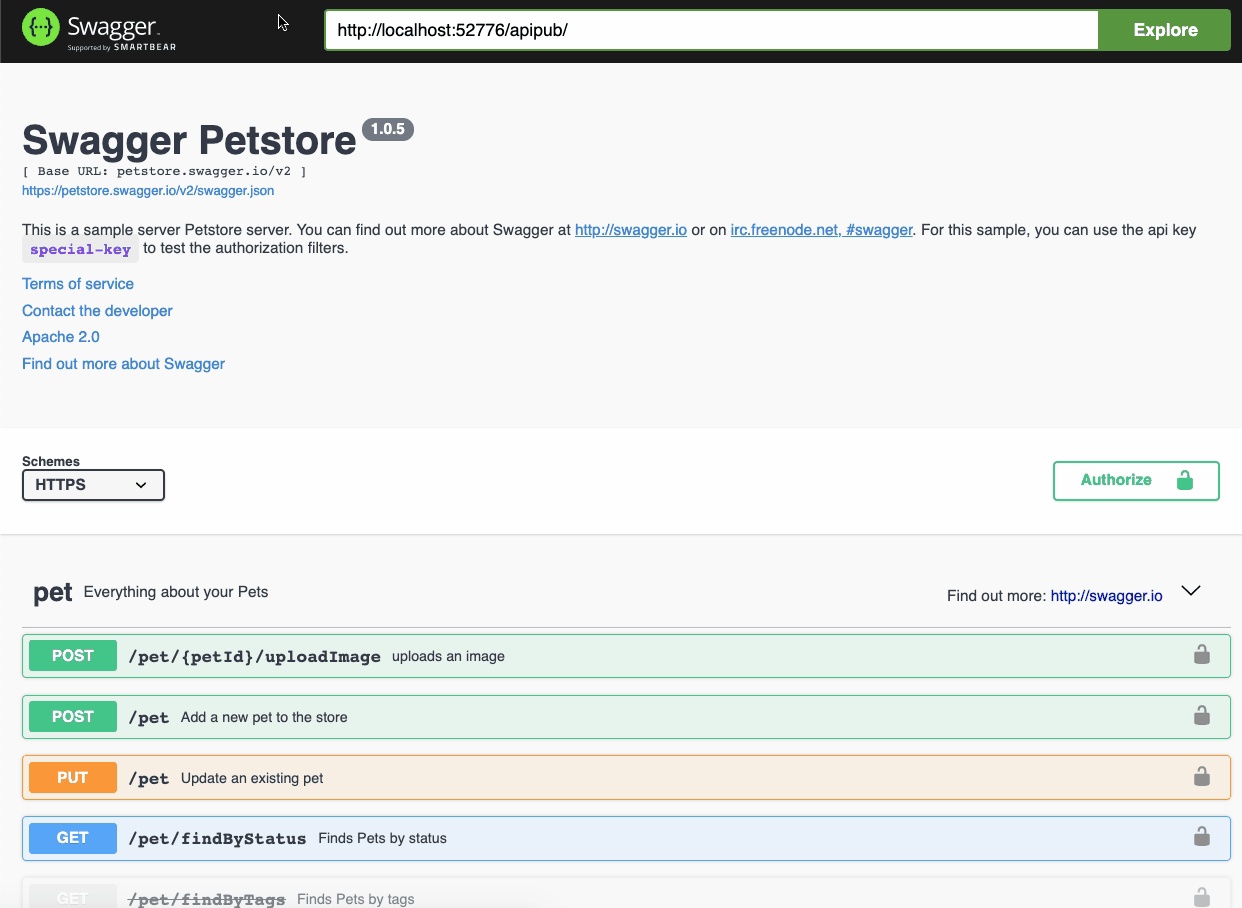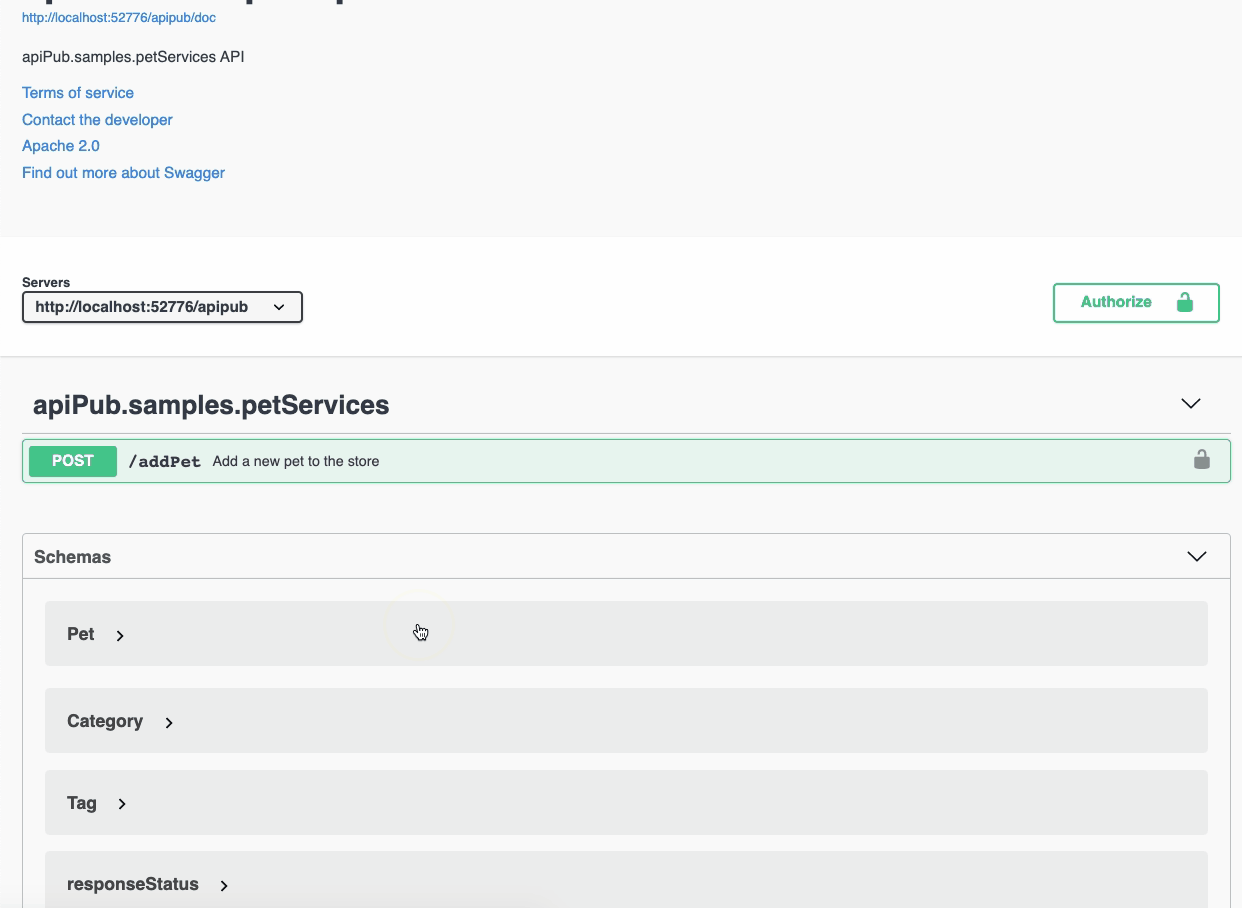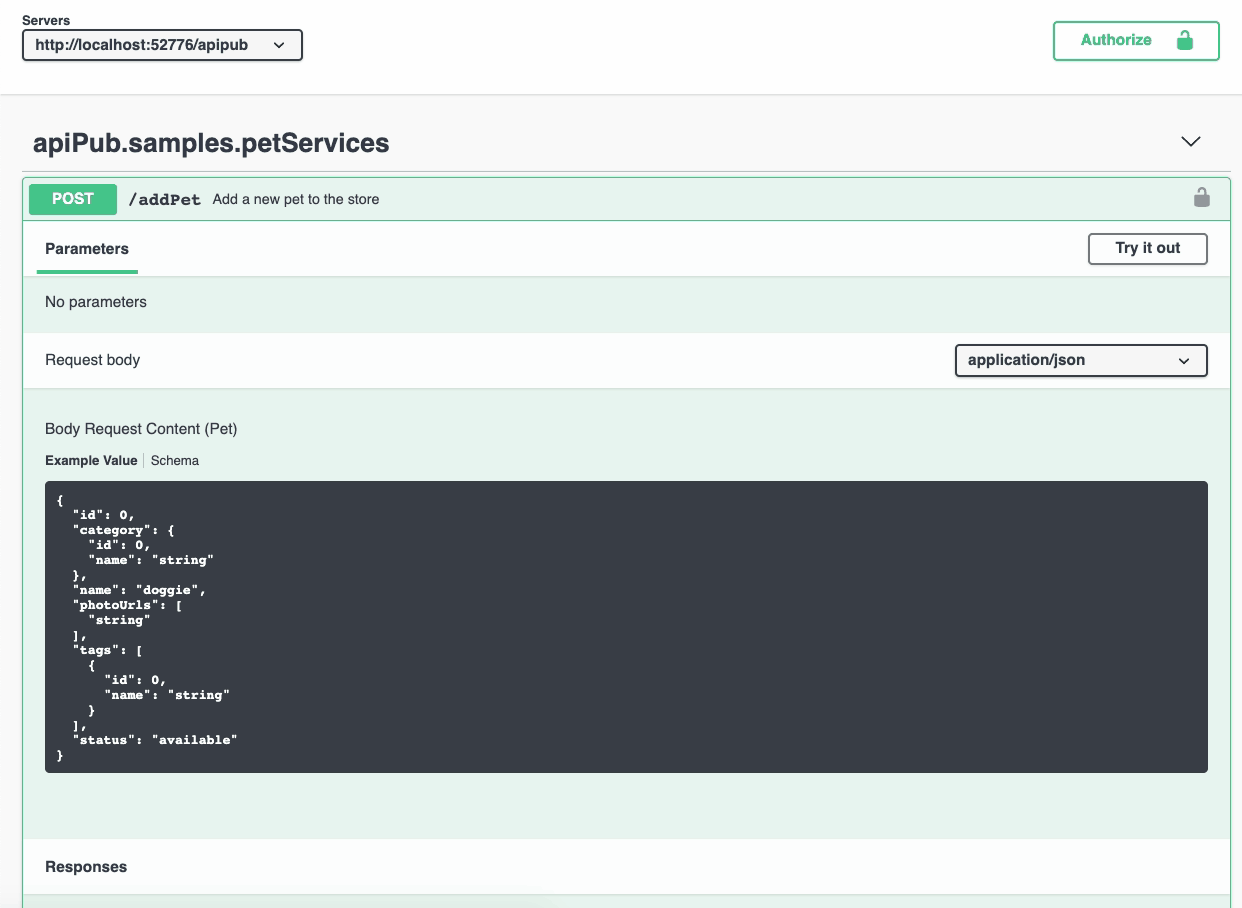
## Defina o cabeçalho da especificação OAS
Há duas maneiras de definir o cabeçalho OAS 3.0:
A primeira é através da criação de um bloco JSON XDATA nomeado como *apiPub* na classe de implementação. Este método permite que se tenha mais de uma Tag e a modelagem é compatível com o padrão OAS 3.0. As propriedades permitidas para customização são *info, tags* e *servers*.
```
XData apiPub [ MimeType = application/json ]
{
{
"info" : {
"description" : "This is a sample Petstore server. You can find\nout more about Swagger at\n[http://swagger.io](http://swagger.io) or on\n[irc.freenode.net, #swagger](http://swagger.io/irc/).\n",
"version" : "1.0.0",
"title" : "IRIS Petstore (Dev First)",
"termsOfService" : "http://swagger.io/terms/",
"contact" : {
"email" : "apiteam@swagger.io"
},
"license" : {
"name" : "Apache 2.0",
"url" : "http://www.apache.org/licenses/LICENSE-2.0.html"
}
},
"tags" : [ {
"name" : "pet",
"description" : "Everything about your Pets",
"externalDocs" : {
"description" : "Find out more",
"url" : "http://swagger.io"
}
}, {
"name" : "store",
"description" : "Access to Petstore orders"
}, {
"name" : "user",
"description" : "Operations about user",
"externalDocs" : {
"description" : "Find out more about our store",
"url" : "http://swagger.io"
}
} ]
}
}
```
A segunda maneira é através da definição de parâmetros na classe de implementação, assim como no exemplo a seguir:
```
Parameter SERVICENAME = "My Service";
Parameter SERVICEURL = "http://localhost:52776/apipub";
Parameter TITLE As %String = "REST to SOAP APIs";
Parameter DESCRIPTION As %String = "APIs to Proxy SOAP Web Services via REST";
Parameter TERMSOFSERVICE As %String = "http://www.intersystems.com/terms-of-service/";
Parameter CONTACTNAME As %String = "John Doe";
Parameter CONTACTURL As %String = "https://www.intersystems.com/who-we-are/contact-us/";
Parameter CONTACTEMAIL As %String = "support@intersystems.com";
Parameter LICENSENAME As %String = "Copyright InterSystems Corporation, all rights reserved.";
Parameter LICENSEURL As %String = "http://docs.intersystems.com/latest/csp/docbook/copyright.pdf";
Parameter VERSION As %String = "1.0.0";
Parameter TAGNAME As %String = "Services";
Parameter TAGDESCRIPTION As %String = "Legacy Services";
Parameter TAGDOCSDESCRIPTION As %String = "Find out more";
Parameter TAGDOCSURL As %String = "http://intersystems.com";
```
## Customize as tuas API's
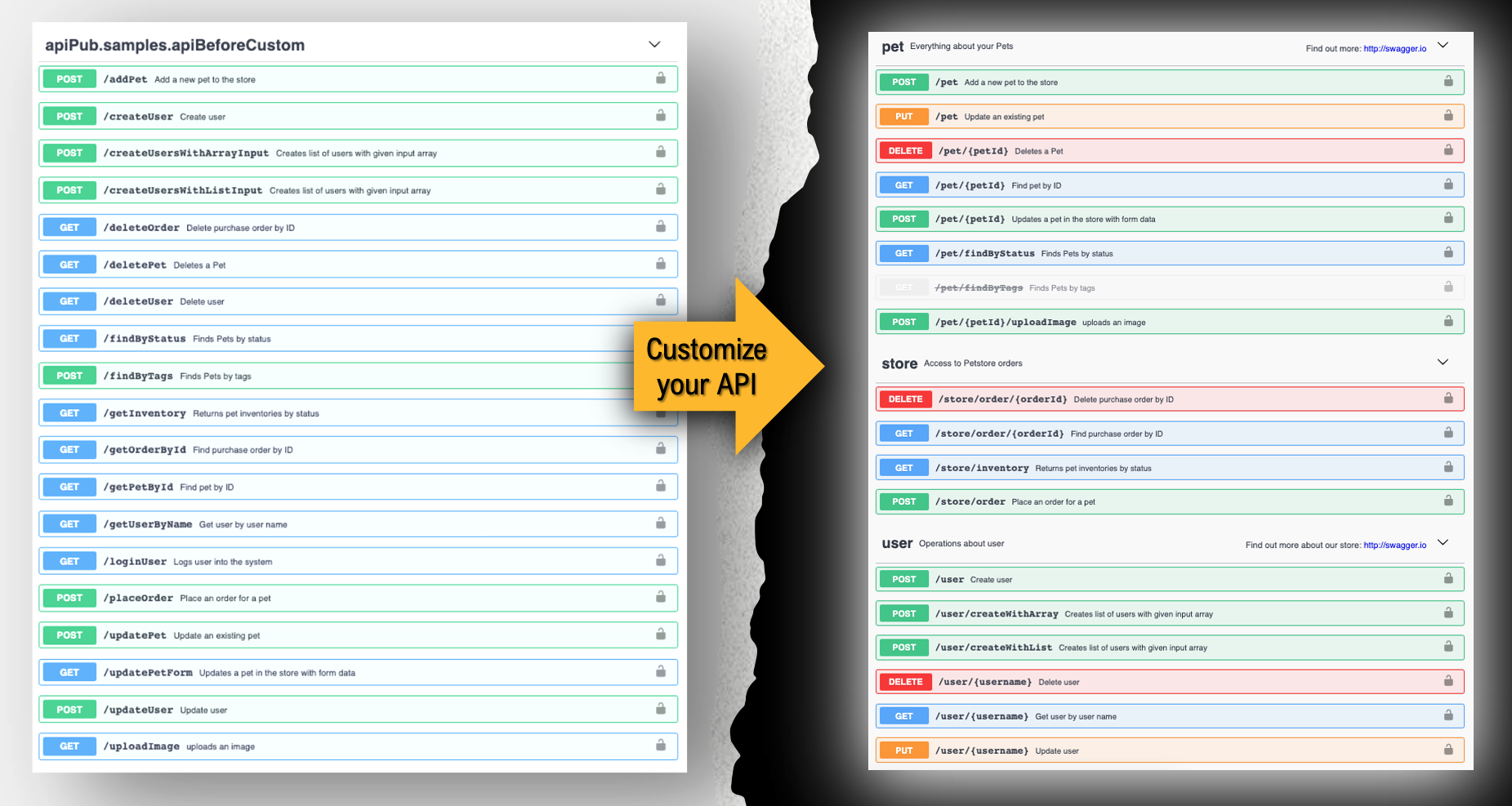
É possível customizar vários aspectos das API's, como ***tags, paths e verbos***. Para tal, é necessária a utilização de uma notação específica, definida no comentário do método a ser customizado.
Sintaxe:
>***/// @apiPub[assignment clause]***
[*Method/ClassMethod*] *methodName(params as type) As returnType* {
>
>}
Todas as customizações dadas como exemplo nesta documentação estão disponíveis na classe [apiPub.samples.api](https://github.com/devecchijr/apiPub/blob/master/src/apiPub/samples/api.cls).
## Customizando os Verbos
Quando não há nenhum tipo complexo como parâmetro de entrada, apiPub atribui automaticamente o verbo como *Get*. Caso contrário é atribuído o verbo *Post*.
Caso se queira customizar o método adiciona-se a seguinte linha nos comentários do método.
>/// @apiPub[verb="*verb*"]
Onde *verb* pode ser **get, post, put, delete ou patch**.
Exemplo:
>/// @apiPub[verb="put"]
## Customizando os Caminhos (Paths)
Esta ferramenta atribui automaticamente os *paths* ou o roteamento para os *Web Methods*. Ele utiliza como padrão o nome do método como *path*.
Caso se queira customizar o **path** adiciona-se a seguinte linha nos comentários do método.
>/// @apiPub[path="*path*"]
Onde *path* pode ser qualquer valor precedido com barra, desde que não conflita com outro *path* na mesma classe de implementação.
Exemplo:
>/// @apiPub[path="/pet"]
Outro uso bastante comum do path é definir um ou mais parâmetros no próprio path. Para tal, é necessário que o nome do parâmetro definido no método esteja entre chaves.
Exemplo:
>/// @apiPub[path="/pet/{petId}"]
Method getPetById(petId As %Integer) As apiPub.samples.Pet [ WebMethod ]
{
}
Quando o nome do parâmetro interno difere do nome do parâmetro exposto, pode-se equalizar o nome conforme exemplo a seguir:
>/// @apiPub[path="/pet/{petId}"]
/// @apiPub[params.pId.name="petId"]
Method getPetById(pId As %Integer) As apiPub.samples.Pet [ WebMethod ]
{
}
No exemplo acima, o parâmetro interno *pId* é exposto como *petId*.
## Customizando as Tags
É possível definir a **tag**(agrupamento) do método quando há mais que uma tag definida no cabeçalho.
>/// @apiPub[tag="*value*"]
Exemplo:
>/// @apiPub[tag="user"]
## Customizando o *Status Code* de Sucesso
Caso se queira alterar o *Status Code* sucesso do método, que é por padrão ***200***, utiliza-se a seguinte notação.
>/// @apiPub[successfulCode="*code*"]
Exemplo:
>/// @apiPub[successfulCode="201"]
## Customizando *Status Codes* de Exceção
Esta ferramenta assume como padrão o ***Status Code 500*** para quaisquer exceções. Caso se queira adicionar novos códigos para exceção na documentação, utiliza-se a seguinte notação.
>/// @apiPub[statusCodes=[{code:"*code*",description:"*description*"}]]
Onde a propriedade *statusCodes* é um array de objetos com código e descrição.
Exemplo:
> /// @apiPub[statusCodes=[
/// {"code":"400","description":"Invalid ID supplied"}
/// ,{"code":"404","description":"Pet not found"}]
/// ]
Ao disparar a exceção, Inclua o *Status Code* na descrição da exceção entre os sinais de "".
Exemplo:
> Throw ##Class(%Exception.StatusException).CreateFromStatus($$$ERROR($$$GeneralError, "****** Invalid ID supplied"))}
Veja o método ***getPetById*** da classe [apiPub.samples.api](https://github.com/devecchijr/apiPub/blob/master/src/apiPub/samples/api.cls)
## Marcando a API como Descontinuada
Para que a API seja exposta como ***deprecated***, utiliza-se a seguinte notação:
>/// @apiPub[deprecated="true"]
## Customizando o *operationId*
Segundo a especificação OAS, ***operationId*** é uma string única usada para identificar uma API ou operação. Nesta ferramenta ela é utilizada para a mesma finalidade no [monitoramento e rastreamento](https://github.com/devecchijr/apiPub#monitore-a-chamada-das-suas-apis-com-o-iris-analytics) das operações.
Por padrão, ela recebe o mesmo nome do método da classe de implementação.
Caso se queira alterá-la utiliza-se a seguinte notação
>/// @apiPub[operationId="updatePetWithForm"]
## Alterando o charset do método
O charset padrão da geralmente é definido através do parâmetro CHARSET na classe de serviço, descrita no [Passo 2](https://github.com/devecchijr/apiPub#passo-2). Caso se queira customizar o charset de um método, deve se utilizar a seguinte notação:
>/// @apiPub[charset="*value*"]
Exemplo:
>/// @apiPub[charset="UTF-8"]
## Customizando nomes e outras funcionalidades dos parâmetros
Pode-se customizar vários aspectos de cada parâmetro de entrada e saída dos métodos, como por exemplo os nomes e as descrições que serão expostas para cada parâmetro.
Para se customizar um parametro específico utiliza-se a seguinte notação
>/// @apiPub[params.*paramId.property*="*value*"]
ou para respostas:
>/// @apiPub[response.*property*="*value*"]
Exemplo:
>/// @apiPub[params.pId.name="petId"]
/// @apiPub[params.pId.description="ID of pet to return"]
Neste caso, está sendo atribuido o nome *petId* e a descrição *ID of pet to return* para o parâmetro definido como *pId*
Quando a customização não é específica para um determinado parâmetro, utiliza-se a seguinte notação
>/// @apiPub[params.*property*="*value*"]
No exemplo abaixo, a descrição *This can only be done by the logged in user* é atribuída para todo o *request*, não apenas para um parâmetro:
>/// @apiPub[params.description="This can only be done by the logged in user."]
## Outras Propriedades que podem ser customizadas para parâmetros específicos
Utilize a seguinte notação para parâmetros de entrada ou saída:
>/// @apiPub[params.*paramId.property*="*value*"]
Para respostas:
>/// @apiPub[response.*property*="*value*"]
| Propriedade |
|----------------------------------------------------------------------------------------------------------------------------------------|
| ***required***: "true" se o parâmetro for requerido. Todos os parâmetros do tipo **path** já são automaticamente requeridos |
| ***schema.items.enum***: exposição de Enumeradores para tipos %String ou %Library.DynamicArray. Veja o método ***findByStatus*** da classe [apiPub.samples.api](https://github.com/devecchijr/apiPub/blob/master/src/apiPub/samples/api.cls) |
| ***schema.default***: Aponta para um valor default para enumeradores. |
| ***inputType***: Por padrão é **query parameter** para os tipos simples e **application/json** para os tipos complexo (body). Caso se queira alterar o tipo de input, pode se utilizar este parâmetro. Exemplo de uso: Upload de uma imagem, que normalmente não é do tipo JSON. Veja método ***uploadImage*** da classe [apiPub.samples.api](https://github.com/devecchijr/apiPub/blob/master/src/apiPub/samples/api.cls). |
| ***outputType***: Por padrão é **header** para os tipos %Status e **application/json** para o restante. Caso se queira alterar o tipo de output, pode se utilizar este parâmetro. Exemplo de uso: Retorno de um token ("text/plain"). Veja método ***loginUser*** da classe [apiPub.samples.api](https://github.com/devecchijr/apiPub/blob/master/src/apiPub/samples/api.cls) |
## Relacione Schemas Parseáveis a tipos JSON Dinâmicos ***(%Library.DynamicObject)***

É possível relacionar [schemas OAS 3.0](https://swagger.io/docs/specification/data-models/) a [tipos dinâmicos](https://docs.intersystems.com/hs20201/csp/docbook/DocBook.UI.Page.cls?KEY=GJSON_create) internos.
A vantagem de se relacionar o schema com o parâmetro, além de informar ao usuário a especificação do objeto requerido, é o ***parsing automático*** do request é realizado na chamada da API. Se o usuário da API por exemplo enviar uma propriedade que não está no schema, enviar uma data em um formato inválido ou não enviar uma propriedade obrigatória, um ou mais erros serão retornados ao usuário informando as irregularidades.
O primeiro passo é incluir o schema desejado no bloco XDATA conforme exemplo abaixo. Neste caso o schema chamado *User* pode ser utilizado por qualquer método. Ele deve seguir as mesmas regras da modelagem [OAS 3.0](https://swagger.io/docs/specification/data-models/).
```
XData apiPub [ MimeType = application/json ]
{
{
"schemas": {
"User": {
"type": "object",
"required": [
"id"
],
"properties": {
"id": {
"type": "integer",
"format": "int64"
},
"username": {
"type": "string"
},
"firstName": {
"type": "string"
},
"lastName": {
"type": "string"
},
"email": {
"type": "string"
},
"password": {
"type": "string"
},
"phone": {
"type": "string"
},
"userStatus": {
"type": "integer",
"description": "(short) User Status"
}
}
}
}
}
}
```
O segundo passo é relacionar o nome do schema informado no passo anterior ao parâmetro interno do tipo [%Library.DynamicObject](https://docs.intersystems.com/hs20201/csp/docbook/DocBook.UI.Page.cls?KEY=GJSON_create) usando a seguinte notação:
>/// @apiPub[params.*paramId*.*schema*="*schema name*"]
Exemplo associando o parâmetro *user* ao schema *User*:
```
/// @apiPub[params.user.schema="User"]
Method updateUserUsingOASSchema(username As %String, user As %Library.DynamicObject) As %Status [ WebMethod ]
{
code...
}
```
Exemplo de request com erro a ser submetido. A propriedade username2 não existe no schema *User*. A propriedade id também não foi especificada e é requerida:
```
{
"username2": "devecchijr",
"firstName": "claudio",
"lastName": "devecchi junior",
"email": "devecchijr@gmail.com",
"password": "string",
"phone": "string",
"userStatus": 0
}
```
Exemplo de erro retornado:
```
{
"statusCode": 0,
"message": "ERRO #5001: Path User.id is required; Invalid path: User.username2",
"errorCode": 5001
}
```
Veja métodos ***updateUserUsingOASSchema*** e ***getInventory*** da classe [apiPub.samples.api](https://github.com/devecchijr/apiPub/blob/master/src/apiPub/samples/api.cls). O método ***getInventory*** é um exemplo de schema associado à saída do método (response), portanto não é parseável.
### Gere o schema OAS 3.0 com base em um objeto JSON
Para auxiliar na geração do schema OAS 3.0, você pode usar o seguinte recurso:
**Defina** uma variável com uma amostra do objeto JSON.
```
set myObject = {"prop1":"2020-10-15","prop2":true, "prop3":555.55, "prop4":["banana","orange","apple"]}
```
**Utilize o método utilitário** da classe [apiPub.core.publisher](https://github.com/devecchijr/apiPub/blob/master/src/apiPub/core/publisher.cls) para gerar o schema:
```
do ##class(apiPub.core.publisher).TemplateToOpenApiSchema(myObject,"objectName",.schema)
```
**Copie e cole** o schema retornado no bloco XDATA:
Exemplo:
```
XData apiPub [ MimeType = application/json ]
{
{
"schemas": {
{
"objectName":
{
"type":"object",
"properties":{
"prop1":{
"type":"string",
"format":"date",
"example":"2020-10-15"
},
"prop2":{
"type":"boolean",
"example":true
},
"prop3":{
"type":"number",
"example":555.55
},
"prop4":{
"type":"array",
"items":{
"type":"string",
"example":"apple"
}
}
}
}
}
}
}
}
```
## Habilite o Monitoramento *(Opcional)*
1 - Adicione e ative os seguintes componentes na tua *Production* (*IRIS Interoperability*)
| Component | Type |
|----------------------|-------------------|
| apiPub.tracer.bm | Service (BS) |
| apiPub.tracer.bs | Service (BS) |
| apiPub.tracer.bo | Operation (BO) |
2 - Ative o monitoramento na classe descrita no [Passo 2](https://github.com/devecchijr/apiPub#passo-2)
O parâmetro ***Traceable*** deve estar ativado.
```
Parameter Traceable As %Boolean = 1;
Parameter TracerBSName = "apiPub.tracer.bs";
Parameter APIDomain = "samples";
```
O parâmetro ***APIDomain*** é utilizado para agrupar as API's no monitoramento.
3 - Importe os dashboards
```
zn "IRISAPP"
Set sc = ##class(%DeepSee.UserLibrary.Utils).%ProcessContainer("apiPub.tracer.dashboards",1)
```
Outros dashboards também podem ser criados com base no cubo ***apiPub Monitor***.
## Utilize esta ferramenta em conjunto com o Intersystems API Manager
Roteie as suas API's geradas e obtenha diversas vantagens com o [Intersystems API Manager](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=AFL_IAM)
## Compatibilidade
[ApiPub](https://github.com/devecchijr/apiPub#iris-apipub) é compatível com o produto [Intersystems IRIS](https://www.intersystems.com/products/intersystems-iris/) ou [Intersystems IRIS for Health](https://www.intersystems.com/products/intersystems-iris-for-health/) a partir da versão 2018.1.
## Repositório
***Github***: [apiPub](https://github.com/devecchijr/apiPub#iris-apipub) Parabéns @Claudio.Devecchi Artigo e aplicação excelentes!
Será de grande ajuda! Muito obrigado Henrique!
Artigo
Eduard Lebedyuk · Nov. 9, 2020
Neste artigo eu gostaria de falar sobre a abordagem de especificação primeiro (spec-first) para o desenvolvimento de APIs REST.
Embora o desenvolvimento de API REST com código primeiro (code-first) tradicional seja assim:
* Escrever o código
* Habilitando-o com REST
* Documentando-o (como uma API REST)
A especificação primeiro (spec-first) segue os mesmos passo, mas ao contrário. Começamos com uma especificação, também usando-a como documentação, geramos uma aplicação REST padrão a partir dela e, finalmente, escrevemos alguma lógica de negócios.
Isso é vantajoso porque:
* Você sempre tem uma documentação relevante e útil para desenvolvedores externos ou front-end que desejam usar sua API REST
* A especificação criada em OAS (Swagger) pode ser importada em uma variedade de ferramentas permitindo edição, geração de cliente, gerenciamento de API, teste de unidade e automação ou simplificação de muitas outras tarefas
* Arquitetura de API aprimorada. Na abordagem de código primeiro (code-first), a API é desenvolvida método a método então um desenvolvedor pode facilmente perder o controle da arquitetura geral da API, no entanto, com a especificação primeiro (spec-first), o desenvolvedor é forçado a interagir com uma API a partir da posição de um consumidor de API, o que geralmente ajuda no design de uma arquitetura melhor da API.
* Desenvolvimento mais rápido - como todo código padrão é gerado automaticamente, você não terá que escrevê-lo, tudo o que resta é desenvolver a lógica de negócios.
* Loops de feedback mais rápidos - os consumidores podem obter uma visão da API imediatamente e podem oferecer sugestões com mais facilidade, simplesmente modificando as especificações
Vamos desenvolver nossa API em uma abordagem de especificação primeiro!
### Plano
1. Desenvolver especificação no swagger
* Docker
* Localmente
* On-line
2. Carregar especificações no IRIS
* API REST de Gerenciamento de API
* ^REST
* Classes
3. O que aconteceu com a nossa especificação?
4. Implementação
5. Desenvolvimento adicional
6. Considerações
* Parâmetros especiais
* CORS
7. Carregar especificações no IAM
### Desenvolver especificação
O primeiro passo é, sem surpresa, escrever a especificação. O InterSystems IRIS oferece suporte à Especificação Open API (OAS):
> A **Especificação OpenAPI** (anteriormente Especificação Swagger) é um formato de descrição de API para APIs REST. Um arquivo OpenAPI permite que você descreva toda a sua API, incluindo:
>
> * Endpoints disponíveis (`/users`) e operações em cada endpoint (`GET /users`, `POST /users`)
> * Parâmetros de entrada e saída para cada operação
> * Métodos de autenticação
> * Informações de contato, licença, termos de uso e outras informações.
>
> As especificações das APIs podem ser escritas em YAML ou JSON. O formato é fácil de aprender e legível tanto para humanos como para máquinas. A Especificação OpenAPI completa pode ser encontrada no GitHub: [Especificação OpenAPI 3.0](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.0.md)
- da documentação Swagger.
Usaremos Swagger para escrever nossa API. Existem várias maneiras de usar o Swagger:
* [On-line](https://editor.swagger.io/)
* Docker: `docker run -d -p 8080:8080 swaggerapi/swagger-editor`
* [Instalação local](https://swagger.io/docs/open-source-tools/swagger-editor/)
Após instalar/executar o Swagger, você deverá ver esta janela em um navegador web:
No lado esquerdo, você edita a especificação da API e, à direita, vê imediatamente a documentação/ferramenta de teste da API renderizada.
Vamos carregar nossa primeira especificação de API nele (em [YAML](https://en.wikipedia.org/wiki/YAML)). É uma API simples com uma solicitação GET - retornando um número aleatório em um intervalo especificado.
Especificação da API matemática
swagger: "2.0"
info:
description: "Math"
version: "1.0.0"
title: "Math REST API"
host: "localhost:52773"
basePath: "/math"
schemes:
- http
paths:
/random/{min}/{max}:
get:
x-ISC_CORS: true
summary: "Get random integer"
description: "Get random integer between min and max"
operationId: "getRandom"
produces:
- "application/json"
parameters:
- name: "min"
in: "path"
description: "Minimal Integer"
required: true
type: "integer"
format: "int32"
- name: "max"
in: "path"
description: "Maximal Integer"
required: true
type: "integer"
format: "int32"
responses:
200:
description: "OK"
Aqui está seu conteúdo:
Informações básicas sobre nossa API e versão OAS usada.
swagger: "2.0"
info:
description: "Math"
version: "1.0.0"
title: "Math REST API"
Host do servidor, protocolo (http, https) e nomes de aplicações web:
host: "localhost:52773"
basePath: "/math"
schemes:
- http
Em seguida, especificamos um caminho (para que a URL completa seja `http://localhost:52773/math/random/:min/:max`) e o método de solicitação HTTP (get, post, put, delete):
paths:
/random/{min}/{max}:
get:
Depois disso, especificamos informações sobre nossa solicitação:
x-ISC_CORS: true
summary: "Get random integer"
description: "Get random integer between min and max"
operationId: "getRandom"
produces:
- "application/json"
parameters:
- name: "min"
in: "path"
description: "Minimal Integer"
required: true
type: "integer"
format: "int32"
- name: "max"
in: "path"
description: "Maximal Integer"
required: true
type: "integer"
format: "int32"
responses:
200:
description: "OK"
Nesta parte, definimos nossa solicitação:
* Habilita suporte a CORS (falarei mais sobre isso posteriormente)
* Fornece um _resumo_ e _descrição_
* O _operationId_ permite referência dentro das especificações, também é um nome de método gerado em nossa classe de implementação
* _produz_ - formato de resposta (como texto, xml, json)
* _parâmetros_ especificam parâmetros de entrada (sejam eles em URL ou corpo), no nosso caso especificamos 2 parâmetros - intervalo para nosso gerador de número aleatório
* _respostas_ lista respostas possíveis do servidor
Como você pode ver, este formato não é particularmente desafiador, embora haja muitos outros recursos disponíveis, aqui está uma [especificação](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.2.md).
Finalmente, vamos exportar nossa definição como um JSON. Vá em File → Convert and save as JSON. A especificação deve ser semelhante a esta:
Especificação da API matemática
{
"swagger": "2.0",
"info": {
"description": "Math",
"version": "1.0.0",
"title": "Math REST API"
},
"host": "localhost:52773",
"basePath": "/math",
"schemes": [
"http"
],
"paths": {
"/random/{min}/{max}": {
"get": {
"x-ISC_CORS": true,
"summary": "Get random integer",
"description": "Get random integer between min and max",
"operationId": "getRandom",
"produces": [
"application/json"
],
"parameters": [
{
"name": "min",
"in": "path",
"description": "Minimal Integer",
"required": true,
"type": "integer",
"format": "int32"
},
{
"name": "max",
"in": "path",
"description": "Maximal Integer",
"required": true,
"type": "integer",
"format": "int32"
}
],
"responses": {
"200": {
"description": "OK"
}
}
}
}
}
}
### Carregar especificação no IRIS
Agora que temos nossas especificações, podemos gerar um código padrão para esta API REST no InterSystems IRIS.
Para passar para este estágio, precisaremos de três coisas:
* Nome da aplicação REST: pacote para nosso código gerado (utilizaremos `math`)
* Especificação OAS em formato JSON: acabamos de criá-la em uma etapa anterior
* Nome da aplicação WEB: um caminho base para acessar nossa API REST (`/math` em nosso caso)
Existem três maneiras de usar nossa especificação para geração de código, elas são essencialmente as mesmas e apenas oferecem várias maneiras de acessar a mesma funcionalidade
1. Chamar a rotina `^%REST` (`Do ^%REST` em uma sessão de terminal interativa), [documentação](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GREST_routine).
2. Chamar a classe `%REST` (`Set sc = ##class(%REST.API).CreateApplication(applicationName, spec)`, não interativa), [documentação](https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=GREST_objectscriptapi).
3. Usar a API REST de gerenciamento de API, [documentação](https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=GREST_apimgmnt).
Acho que a documentação descreve adequadamente as etapas necessárias, então apenas escolha uma. Vou adicionar duas notas:
* No caso (1) e (2) você pode passar a um objeto dinâmico, um nome de arquivo ou uma URL
* Nos casos (2) e (3) você **deve** fazer uma chamada adicional para criar uma aplicação WEB:: `set sc = ##class(%SYS.REST).DeployApplication(restApp, webApp, authenticationType)`, então em nosso caso, `set sc = ##class(%SYS.REST).DeployApplication("math", "/math")`, obter valores para o argumento `authenticationType` do arquivo de inclusão `%sySecurity`, entradas relevantes são `$$$Authe*`, então para um acesso não autenticado use `$$$AutheUnauthenticated`. Se omitido, o parâmetro padroniza para autenticação de senha.
### O que aconteceu com a nossa especificação?
Se você criou a aplicação com sucesso, um novo pacote `math` deve ter sido criado com três classes:
* _Spec_ - armazena a especificação no estado em que se encontra.
* _Disp_ - chamado diretamente quando o serviço REST é chamado. Ele empacota o tratamento REST e chama os métodos de implementação.
* _Impl_ - contém a implementação interna atual do serviço REST. Você deve editar apenas esta classe.
[Documentação](https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=GREST_intro#GREST_intro_classes) com mais informações sobre as classes.
### Implementação
Inicialmente, nossa classe de implementação `math.impl` contém apenas um método, correspondendo à nossa operação `/random/{min}/{max}`:
/// Obtenha um número inteiro aleatório entre min e max
/// Os argumentos do método contêm valores para:
/// min, número inteiro mínimo
/// max, número inteiro máximo
ClassMethod getRandom(min As %Integer, max As %Integer) As %DynamicObject
{
//(Place business logic here)
//Do ..%SetStatusCode()
//Do ..%SetHeader(,)
//Quit (Coloque a resposta aqui) ; a resposta pode ser uma string, uma stream ou um objeto dinâmico
}
Vamos começar com a implementação trivial:
ClassMethod getRandom(min As %Integer, max As %Integer) As %DynamicObject
{
quit {"value":($random(max-min)+min)}
}
E, finalmente, podemos chamar nossa API REST abrindo esta página no navegador: `http://localhost:52773/math/random/1/100`
A saída deve ser:
{
"value": 45
}
Também no editor Swagger, pressionando o botão `Try it out` e preenchendo os parâmetros da solicitação, também será enviada a mesma solicitação:
Parabéns! Nossa primeira API REST criada com uma abordagem de especificação primeiro (spec-first) está agora disponível!
### Desenvolvimento adicional
Claro, nossa API não é estática e precisamos adicionar novos caminhos e assim por diante. Com o desenvolvimento de especificação primeiro, você começa modificando a especificação, em seguida atualiza a aplicação REST (utilizando as mesmas chamadas que foram utilizadas para criar a aplicação) e finalmente escreve o código. Observe que as atualizações de especificações são seguras: seu código não é afetado, mesmo se o caminho for removido de uma especificação, o método não seria excluído da classe de implementação.
### Considerações
Mais notas!
#### Parâmetros especiais
A InterSystems adicionou parâmetros especiais à especificação swagger, aqui estão:
Nome
Tipo de Dado
Padrão
Local
Descrição
x-ISC_DispatchParent
classname
%CSP.REST
info
Super classe para a classe de despacho.
x-ISC_CORS
boolean
false
operation
Flag para indicar que requisições CORS para esta combinação endpoint/método deve ser suportada.
x-ISC_RequiredResource
array
operation
Lista separada por vírgulas dos recursos definidos e seus modos de acesso (recurso:modo) que são requeridos para acesso a este endponit do serviço REST. Exemplo: ["%Development:USE"]
x-ISC_ServiceMethod
string
operation
Nome do método de classe invocado internamente para atender a esta operação; o valor padrão é o operationId, o que é normalmente adequado.
#### CORS
Existem três maneiras de habilitar o suporte ao CORS.
1. Em uma rota na rota base, especificando `x-ISC_CORS` como verdadeiro (true). Isso é o que fizemos em nossa API REST de matemática.
2. Por API, adicionando
Parameter HandleCorsRequest = 1;
e recompilando a classe. Ele também sobreviveria à atualização das especificações.
3. (Recomendado) Por API, implementando a superclasse de dispatcher customizada (deve estender `%CSP.REST`) e escrevendo a lógica de processamento CORS lá. Para usar esta superclasse, adicione `x-ISC_DispatchParent` à sua especificação.
### Carregar especificações no IAM
Finalmente, vamos adicionar nossa especificação no IAM para que seja publicada para outros desenvolvedores.
Se você ainda não começou a utilizar o IAM, consulte [este artigo](https://community.intersystems.com/post/introducing-intersystems-api-manager). Ele também fala a respeito da disponibilização da API REST através do IAM, por isso não o descreverei aqui. Você pode querer modificar a especificação do `host` e os parâmetros do `basepath` para que eles apontem para o IAM, em vez de apontar para a instância InterSystems IRIS.
Abra o portal do administrador do IAM e acesse a aba `Specs` no espaço de trabalho relevante.
Clique no botão `Add Spec` e insira o nome da nova API (`math` em nosso caso). Depois de criar uma nova especificação no IAM, clique em `Edit` e cole o código da especificação (JSON ou YAML - não importa para o IAM):
Não se esqueça de clicar em `Update File`.
Agora nossa API está publicada para desenvolvedores. Abra o Portal do Desenvolvedor e clique em `Documentação` no canto superior direito. Além das três APIs padrão, nossa nova `API REST Math` deve estar disponível:
Abra-a:
Agora os desenvolvedores podem ver a documentação de nossa nova API e testá-la no mesmo lugar!
###
### Conclusão
O InterSystems IRIS simplifica o processo de desenvolvimento de APIs REST e, a abordagem de especificação primeiro (spec-first) permite um gerenciamento mais rápido e fácil do ciclo de vida das APIs REST. Com essa abordagem, você pode usar uma variedade de ferramentas para uma variedade de tarefas relacionadas, como geração de cliente, teste de unidade, gerenciamento de API e muitos outros.
### Links
* [Especificação OpenAPI 3.0](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.0.md)
* [Criação de serviços REST](https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=GREST)
* [Começando com IAM](https://community.intersystems.com/post/introducing-intersystems-api-manager)
* [Documentação IAM](https://docs.intersystems.com/irislatest/csp/docbook/apimgr/index.html)
Anúncio
Rochael Ribeiro · Mar. 3, 2022
Bem vindos aos lançamentos da Comunidade de Fevereiro de 2022!
Estamos gratos em apresentar nosso novo Calendário de Eventos da Comunidade para desenvolvedores InterSystems:
🎯 https://pt.community.intersystems.com/events
Neste calendário você verá o histórico de eventos da Comunidade de Desenvolvedores. Descubra mais sobre os eventos que estão acontecendo agora ou em breve, verifique os eventos que já ocorreram e assista às gravações dos webinars e encontros da Comunidade.
Vamos olhar em detalhe como utilizá-lo.
Para acessar o Calendário da Comunidade, clique no menu superior Eventos e vá para a seção Calendário de Eventos:
Neste calendário você encontrará os eventos disponíveis e já ocorridos, que podem ser ordenados em categorias:
Todos os eventos
Webinars
Encontros
Concursos
Clicando no modo "Pré-visualizar" do evento você verá seu anúncio:
Sintam-se a vontade para utilizar o modo "Lista", que apresenta as chamadas dos eventos com a opção de adicionar qualquer evento disponível ao seu calendário:
Você também pode selecionar qualquer data no calendário reduzido a direita para descobrir qual evento está agendado ou ocorreu naquele dia:
Além disto, você pode criar seu próprio evento clicando no botão "Novo evento". Você será automaticamente redirecionado para a página de criação de eventos.
❗️ Adicionar a tag Eventos a uma postagem irá abrir campos especiais para a criação de um evento:
Ao completar os campos com o nome do evento, link para realização do registro e horário, seu evento será automaticamente destacado na página principal, na área de eventos:
Você também verá no anúncio de seu evento:– uma área especial com o link para registro– um botão para adicionar rapidamente o evento ao seu calendário
Sintam-se a vontade para adicionar maiores detalhes sobre seus eventos adicionando uma descrição curta / link direto para participação / local.
Espero que tenham gostado das nossas atualizações!
Enviem suas solicitações de melhorias e bugs para o GitHub da Comunidade de Desenvolvedores ou coloque-as nos comentários desta postagem.
Fiquem atentos às novidades!
Artigo
Henrique Dias · Jul. 21, 2021
Conversando com um amigo especialista em Machine Learning @Renato.Banzai , um dos pontos que ele me passou e que hoje é um dos grandes desafios de Machine Learning das corporações é realizar o deploy de modelos de ML/AI em produção. InterSystems IRIS oferece IntegratedML, uma ótima solução para treinar, testar e realizar o deploy dos modelos ML/AI.
A parte mais complexa deste processo para criar modelos de ML/AI é fazer o tratamento dos dados, limpa-los, deixa-los confiáveis.
E é aí que tiramos proveito do poderoso padrão FHIR!
A ideia deste projeto é mostrar como podemos criar/treinar/validar modelos de ML/AI com FHIR e utilizar estes modelos treinados, com dados vindos de diferentes produções.
Acreditamos que este projeto tem um grande potencial e algumas das ideias a serem exploradas são:
Reuso/extensão de transformações DTL em outras bases de dados FHIR para modelos customizados de ML.
Utilizar transformações DTL para padronizar mensagens FHIR e publicar modelos ML como serviços
Criar uma espécie de repositório + regras de transformação para serem utilizados dentro de qualquer dataset FHIR. Ex.: pacotes zpm com modelos prontos.
Explorando as possibilidades que este projeto nos traz, podemos visualizar uma fonte de dados diferente.
Na imagem acima, o ponto FHIR Resource consumindo uma API REST, pode muito bem ser utilizada com FHIRaaS.
E não apenas utilizar o FHIRaaS on AWS, podemos também utilizar o novo serviço HealthShare Message Transformation Services, que automatiza a conversão de mensagens HL7v2 para FHIR.
Com essas pequenas demonstrações, visualizo esses recursos sendo muito bem aproveitados em cenários maiores, possibilitando e entregando com mais facilidade deploys em produção em ambientes realmente inovadores, como o AWS Healthlake. Por que não?!
Votação
Se você curtiu a ideia, curte o que estamos fazendo na comunidade, por favor vote em fhir-integratedml-example e nos ajude nessa jornada!
Artigo
Heloisa Paiva · Jun. 1, 2023
Esse é um artigo da página de "Perguntas frequentes" (FAQ) da InterSystems.
1. Exportar API
a. Use $system.OBJ.Export() para especificar rotinas individuais para exportar. Por exemplo:
do $system.OBJ.Export("TEST1.mac,TEST2.mac","c:\temp\routines.xml",,.errors)
O formato que você deve especificar é: NomeDaRotina.extensão, e a extensão pode ser: mac, bas, int, inc, obj.
Os erros durante a exportação se armazenam na variável "errors".
Veja a referência da classe %SYSTEM.OBJ para mais detalhes sobre $system.OBJ.Export().
b. Use $system.OBJ.Export() ao fazer uma exportação genérica usando * (wildcards). Por exemplo:
do $system.OBJ.Export("*.mac",c:\temp\allmacroutines.xml")
*Antes da versão 2008.1, utilize $system.OBJ.ExportPattern().
2. Importar API
a. Use $system.OBJ.Load() para importar todas as rotinas contidas no arquivo. Por exemplo:
do $system.OBJ.Load("c:\temp\routines.xml",,.errors)
b. Importe só algumas das rotinas contidas no arquivo
Observe o exemplo abaixo. Se quiser selecionar e importar somente algumas das rotinas inclusas no arquivo XML, coloque 1 no 5º argumento "listonly" numa primeira execução e carregue o arquivo XML com $system.OBJ.Load(), estabelecendo o 4º argumento (argumento de saída, list no exemplo abaixo). Isto criará uma lista de elementos na variável list. Depois poderemos recorrer essa lista e decidir que elementos (loaditem) queremos carregar, votando a executar $system.OBJ.Load() e indicando o elemento a carregar no 6º argumento. Você pode ver mais claramente neste exemplo:
Set file="c:\temp\routines.xml" // First get the list of items contained in the XML Do $system.OBJ.Load(file,,.errors,.list,1 /* listonly */) Set item=$Order(list("")) Kill loaditem While item'="" { If item["Sample" Set loaditem(item)="" { // Import only those containing Sample Set item=$Order(list(item)) } } // Execute import process with created list Do $system.OBJ.Load(file,,.errors,,,.loaditem)
Artigo
Danusa Calixto · Out. 10, 2022
No vasto e variado mercado de banco de dados SQL, o InterSystems IRIS se destaca como uma plataforma que vai muito além do SQL, oferecendo uma experiência multimodelo otimizada e a compatibilidade com um rico conjunto de paradigmas de desenvolvimento. Em especial, o mecanismo Object-Relational avançado ajudou as organizações a usar a abordagem de desenvolvimento mais adequada para cada faceta das cargas de trabalho com muitos dados, por exemplo, fazendo a ingestão de dados por objetos e consultando-os simultaneamente por SQL. As Classes Persistentes correspondem às tabelas SQL, suas propriedades às colunas da tabela, e a lógica de negócios é facilmente acessada usando as Funções Definidas pelo Usuário ou os Procedimentos Armazenados. Neste artigo, focaremos um pouco na mágica logo abaixo da superfície e discutiremos como isso pode afetar suas práticas de desenvolvimento e implantação. Essa é uma área do produto em que temos planos de evoluir e melhorar, portanto, não hesite em compartilhar suas opiniões e experiências usando a seção de comentários abaixo.
## Salvando a definição de armazenamento
Escrever uma nova lógica de negócios é fácil e, supondo que você tenha APIs e especificações bem definidas, adaptá-la ou ampliá-la também costuma ser. No entanto, quando não é apenas lógica de negócios, mas também envolve dados persistentes, qualquer coisa que você alterar na versão inicial precisará ser capaz de lidar com os dados que foram ingeridos por essa versão anterior.
No InterSystems IRIS, os dados e código coexistem em um único mecanismo de alto desempenho, sem a meia dúzia de camadas de abstração que você vê em outras estruturas de programação 3GL ou 4GL. Isso significa que há apenas um mapeamento muito fino e transparente para traduzir as propriedades da sua classe para posições $list em um nó global por linha de dados ao usar o armazenamento padrão. Se você adicionar ou remover propriedades, não quer que os dados de uma propriedade removida apareçam em uma nova propriedade. É desse mapeamento das propriedades da sua classe que a Definição de Armazenamento cuida, um bloco de XML um pouco enigmático que você deve ter percebido na parte inferior da definição da sua classe. Na primeira vez que você compila uma classe, uma nova Definição de Armazenamento é gerada com base nas propriedades e nos parâmetros da classe. Quando você faz alterações na definição da classe, no momento da recompilação, essas alterações são reconciliadas com a Definição de Armazenamento existente e alteradas para manter a compatibilidade com os dados existentes. Assim, enquanto você se esforça para refatorar as classes, a Definição de Armazenamento considera cuidadosamente sua criatividade anterior e garante que os dados antigos e novos permaneçam acessíveis. Chamamos isso de **evolução de esquema**.
Na maioria dos outros bancos de dados SQL, o armazenamento físico das tabelas é muito mais opaco, se visível, e as alterações só podem ser feitas por declarações `ALTER TABLE`. Esses são comandos de DDL (linguagem de definição de dados) padrão, mas normalmente são muito menos expressivos do que é possível alcançar ao modificar uma definição de classe e um código de procedimento diretamente no IRIS.
Na InterSystems, nos esforçamos para oferecer aos desenvolvedores do IRIS a capacidade de separar de forma limpa o código e os dados, pois isso é crucial para garantir o empacotamento e a implantação suave dos aplicativos. A Definição de Armazenamento desempenha uma função única nisso, pois captura como um mapeia para o outro. Por isso, vale a pena examinar mais a fundo o contexto de práticas gerais de desenvolvimento e pipelines de CI/CD em particular.
## Exportando para UDL
No século atual, o gerenciamento de código-fonte é baseado em arquivos, então vamos primeiro analisar o formato principal de exportação de arquivos do IRIS. A **Linguagem de Descrição Universal** (Universal Description Language ou UDL, na sigla em inglês) pretende, como o nome sugere, ser um formato de arquivo universal para todo e qualquer código que você escrever no InterSystems IRIS. É o formato de exportação padrão ao trabalhar com o plug-in VS Code ObjectScript e leva a arquivos fáceis de ler que parecem quase iguais ao que você veria em um IDE, com um arquivo .cls individual para cada classe (tabela) no seu aplicativo. Você pode usar $SYSTEM.OBJ.Export() para criar arquivos UDL explicitamente ou apenas aproveitar a integração do VS Code.
Da época do Studio, talvez você se lembre de um formato XML que capturava as mesmas informações do UDL e permitia agrupar várias classes em uma única exportação. Embora essa última parte seja conveniente em alguns cenários, é muito menos prático ler e rastrear diferenças entre versões, então vamos ignorá-la por enquanto.
Como a UDL é destinada a capturar tudo o que o IRIS pode expressar sobre uma classe, ela incluirá todos os elementos de uma definição de classe, incluindo a Definição de Armazenamento completa. Ao importar uma definição de classe que já inclui uma Definição de Armazenamento, o IRIS verificará se essa Definição de Armazenamento abrange todas as propriedades e índices da classe e, se for o caso, usará no estado em que está e substituirá a Definição anterior para essa classe. Isso torna a UDL um formato prático para o gerenciamento de versões das classes e a Definição de Armazenamento, pois preserva essa compatibilidade para dados ingeridos por versões anteriores da classe, onde quer que você implante.
Se você é um desenvolvedor hardcore, talvez se pergunte se essas Definições de Armazenamento continuam crescendo e se essa "bagagem" precisa ser transportada indefinidamente. O objetivo das Definições de Armazenamento é preservar a compatibilidade com dados pré-existentes, portanto, se você sabe que não há nada disso e quiser se livrar de uma genealogia longa, pode "redefinir" a Definição de Armazenamento ao removê-la da definição da classe e gerar outra com o compilador da classe. Por exemplo, você pode usar isso para aproveitar novas práticas recomendadas, como o uso de Conjuntos de Extensão, que implementam nomes globais com hash e separam cada índice em um próprio global, melhorando as eficiências de baixo nível. Para a compatibilidade com versões anteriores nos aplicativos dos clientes, não podemos mudar universalmente esses padrões na superclasse %Persistent (embora os aplicaremos ao criar uma tabela do zero usando o comando DDL `CREATE TABLE`). Portanto, uma revisão periódica das classes e do armazenamento vale a pena. Também é possível editar o XML de Definição de Armazenamento diretamente, mas os usuários precisam ter muito cuidado, pois isso pode tornar os dados existentes inacessíveis.
Até aqui, tudo bem. As Definições de Armazenamento oferecem um mapeamento inteligente entre suas classes e se adaptam automaticamente com a evolução do esquema. O que mais tem lá?
## Estático x Estatísticas?
Como você provavelmente sabe, o mecanismo SQL do InterSystems IRIS faz o uso avançado de estatísticas de tabela para identificar o plano de consulta ideal para qualquer declaração executada pelo usuário. As estatísticas de tabela incluem métricas sobre o tamanho de uma tabela, como os valores são distribuídos em uma coluna e muito mais. Essas informações ajudam o otimizador de SQL do IRIS a decidir qual índice é mais vantajoso, em que ordem unir as tabelas, etc. Portanto, intuitivamente, quanto mais atualizadas as estatísticas estiverem, maiores serão as chances de planos de consulta ideais. Infelizmente, até a introdução da amostragem de bloco rápida no IRIS 2021.2, coletar estatísticas de tabela precisas costumava ser uma operação computacionalmente cara. Portanto, quando os clientes implantavam o mesmo aplicativo em vários ambientes com padrões de dados basicamente iguais, fazia sentido considerar as estatísticas de tabela como parte do código do aplicativo e incluí-las nas definições da tabela.
Por isso, no IRIS hoje você encontra as estatísticas de tabela incorporadas à Definição de Armazenamento. Ao coletar estatísticas de tabela por uma chamada manual para `TUNE TABLE` ou de maneira implícita pela consulta (veja abaixo), as novas estatísticas são gravadas na Definição de Armazenamento e os planos de consulta existentes para essa tabela são invalidados, para que possam aproveitar as novas estatísticas durante a próxima execução. Por serem parte da Definição de Armazenamento, essas estatísticas farão parte das exportações de classe UDL e, portanto, podem acabar no seu repositório de código-fonte. No caso de estatísticas cuidadosamente verificadas para um aplicativo empacotado, isso é desejado, pois você quer que essas estatísticas específicas levem à geração do plano de consulta para todas as implantações do aplicativo.
A partir de 2021.2, o IRIS coletará automaticamente as estatísticas de tabela no início do planejamento de consulta ao consultar uma tabela que não possui nenhuma estatística e está qualificada para a amostragem de bloco rápida. Nos nossos testes, os benefícios de trabalhar com estatísticas atualizadas em vez de nenhuma estatística superaram claramente o custo da coleta de estatísticas em tempo real. Para alguns clientes, no entanto, isso teve o lamentável efeito colateral das estatísticas coletadas automaticamente na instância do desenvolvedor terminarem na Definição de Armazenamento no sistema de controle de fonte e, por fim, no aplicativo empacotado. Obviamente, os dados nesse ambiente de desenvolvedor e, portanto, as estatísticas nele talvez não sejam representativos para uma implantação real do cliente e levem a planos de consulta abaixo do ideal.
É fácil evitar essa situação. As estatísticas de tabela podem ser excluídas da exportação da definição de classe usando o qualificador `/exportselectivity=0` ao chamar $SYSTEM.OBJ.Export(). O padrão do sistema para essa sinalização pode ser configurado usando $SYSTEM.OBJ.SetQualifiers("/exportselectivity=0"). Depois, deixe para a coleta automática na eventual implantação coletar estatísticas representativas, tornar a coleta de estatísticas explícitas parte do processo de implantação, o que substituirá qualquer coisa que possa ter sido empacotada com o aplicativo, ou gerenciar suas estatísticas de tabela separadamente pelas próprias funções de importação/exportação: $SYSTEM.SQL.Stats.Table.Export() e Import().
A longo prazo, pretendemos mover as estatísticas de tabela para ficar com os dados, em vez de fazer parte do código, e diferenciar mais claramente entre quaisquer estatísticas configuradas explicitamente por um desenvolvedor e as coletadas de dados reais. Além disso, estamos planejando mais automação em relação à atualização periódica dessas estatísticas, com base em quanto os dados da tabela mudam ao longo do tempo.
## Conclusão
Neste artigo, descrevemos a função de uma Definição de Armazenamento no mecanismo ObjectRelational do IRIS, como ela é compatível com a evolução do esquema e o que significa incluí-la no seu sistema de controle de fonte. Também descrevemos por que as estatísticas de tabela são atualmente armazenadas nessa Definição de Armazenamento e sugerimos práticas de desenvolvimento para garantir que as implantações de aplicativos acabem com estatísticas representativas dos dados reais do cliente. Conforme mencionado anteriormente, planejamos aprimorar ainda mais esses recursos. Portanto, aguardamos seu feedback sobre a funcionalidade atual e planejada para refinar nosso design conforme apropriado.