Limpar filtro
Anúncio
Danusa Calixto · Dez. 19, 2022
No nosso último episódio do Data Points, tive uma conversa com Carmen Logue e Mary Ann Fusi sobre Adaptive Analytics e Smart Data Fabrics. Muita coisa mudou e melhorou desde a última vez que discutimos este produto no podcast, então ouça!
Para mais informações e para assinar o podcast, acesse https://datapoints.intersystems.com.
Para assistir à apresentação de Carmen e Joe no AtScale Semantic Layer Summit, veja aqui: https://www.intersystems.com/resources/unlocking-the-power-of-your-data-using-a-data-fabric-architecture-with-a-universal-semantic-layer/
Para saber mais sobre programas de acesso antecipado para tecnologias de nuvem da InterSystems, veja aqui: https://gs2022.isccloud.io/#early-access
Anúncio
Stefan Wittmann · Fev. 18, 2021
Publicado o novo lançamento da versão 1.5 do InterSystems API Manager (IAM).
O contêiner do IAM, incluindo todos os artefatos necessários para realizar a atualização a partir de versões anteriores do IAM podem ser baixados do site de Distribuição de Software do WRC na área de Componentes.
O número de registro deste lançamento é IAM 1.5.0.9-4.
O Gerenciador de APIs InterSystems 1.5 facilita o gerenciamento do tráfego de suas APIs, a integração de seu ambiente e usuários com suas APIs. Ele possui várias novas funcionalidades incluindo:
Experiência do Usuário aprimorada
Introdução de novas ferramentas no Portal do Desenvolvedor
Suporte à conectividade com Kafka
Este lançamento é baseado no Kong Enterprise versão 1.5.0.9. Os lançamentos anteriores do IAM incluíam uma versão "white-label" do Kong Enterprise, e com este lançamento nós incluímos o Kong Enterprise sem necessidade do "white-label". Esta mudança nos permite trazer novos lançamentos em uma maior frequência, bem como prover tanto a documentação quanto outros ativos que a Kong disponibiliza, de forma mais efetiva.
A documentação do IAM 1.5 pode ser obtida aqui. Esta documentação cobre apenas elementos que são específicos ao IAM. Os links da documentação no produto levam os usuários diretamente para a documentação da Kong Enterprise.
A atualização a partir do IAM 0.34-1 necessita de atualizações incrementais de três lançamentos intermediários, processo descrito em maiores detalhes na documentação.
O IAM está disponível apenas através de OCI (Open Container Initiative) também conhecido por formato em contêiner Docker. Imagens de Contêineres estão disponíveis para Linux x86-64 e Linux ARM64, conforme detalhado em Plataformas Suportadas.
Abraço a todos,
Stefan
Pergunta
Davidson Espindola · Abr. 17, 2023
Dears, good morning
I've been developing cache scripts for over 25 years, my entire ERP system has cached scripts, everything is global, no graphic/web screen.I have a little knowledge in JS, Html and CSS, and I'm wanting to start web development for my system, go gradually.I would like if you can help me which would be the best option in development to be able to start. As I live in a region with few training options and specific courses, I will have to take a distance course.If possible, and if someone can, of course, send me a model accessing the cache base, so that I can have an idea of how to start, I would be very grateful.
Anyway, thanks for everyone's attention.
AttDavidson Espindola Hello Davidson.
I suggest you check the courses and guides from the InterSystems Learning to support you.Here are listed some of them:
Angular, JSON, and REST – Oh My!Building Modern Web ApplicationsCaché Web Applications Tutorial
You will find other free courses and tutorials in the InterSystems Learning. If you do not have an account, create a new one.
Hope it helps!
Artigo
Henry Pereira · Set. 12, 2021

Sou apaixonado por documentários! No último final de semana estava assistindo um documentário da Netflix chamado [This is Pop](https://www.netflix.com/br/title/81050786), como está na época do concurso InterSystems IRIS Analytics, pensei: Por que não criar um analítico da música Pop com InterSystems Iris?
O primeiro desafio era a base. Encontrei no [Data World project](https://data.world/typhon/billboard-hot-100-songs-2000-2018-w-spotify-data-lyrics) um arquivo CSV com a lista dos top 100 da Billboard de 2000 à 2018, criado por "Michael Tauberg" @typhon, que encaixava perfeitamente.
Estava conversando com o @Henrique.GonçalvesDias e ele me deu a ideia de usar o [Microsoft Power BI](https://powerbi.microsoft.com/) para criar um relatório com gráficos bonitos.
### Quais foram os gêneros mais populares entre 2000 e 2018?
### Quais artistas tiveram mais músicas na Billboard?
### Que ano teve mais músicas dançantes?
Vamos analisar a base de dados, com ajuda do [csvgen](https://openexchange.intersystems.com/package/csvgen) importamos o arquivo CSV.
A base contém:
**Title** — nome da música
**Artist** — nome do Artista
**Energy** — a energia da música — maior o valor, mais energia
**Danceability** — maior o valor, mais fácil de dançar a música
**Loudness..dB.**. — maior o valor, mais alta é a música
**Liveness** — maior o valor, mais provável que a música é uma gravação ao vivo.
**Valence**. — maior o valor, mais positiva é o estado de espírito da música.
**Duration_ms**. — a duração da música em milisegundos.
**Acousticness**.. maior o valor, mais acústica é a música
**Speechiness**. — maior o valor, mais palavras a música contém
**Lyrics** — Letra da música.
**Genre** — Gênero musical
No arquivo CSV o gênero é um array como este: **[u'dance pop', u'hip pop', u'pop', u'pop rap', u'rap']**
Minha ideia é criar uma tabela Genre (Gênero) e outra para resolver o relacionamento N:N. Um simples script popula estas tabelas.
Depois disto, é só conectar o Power BI no InterSystems Iris ([aqui tem um passo-a-passo de como fazer isto](https://community.intersystems.com/post/power-bi-connector-intersystems-iris-part-i)).
Próximo passo: Infograficos legais.
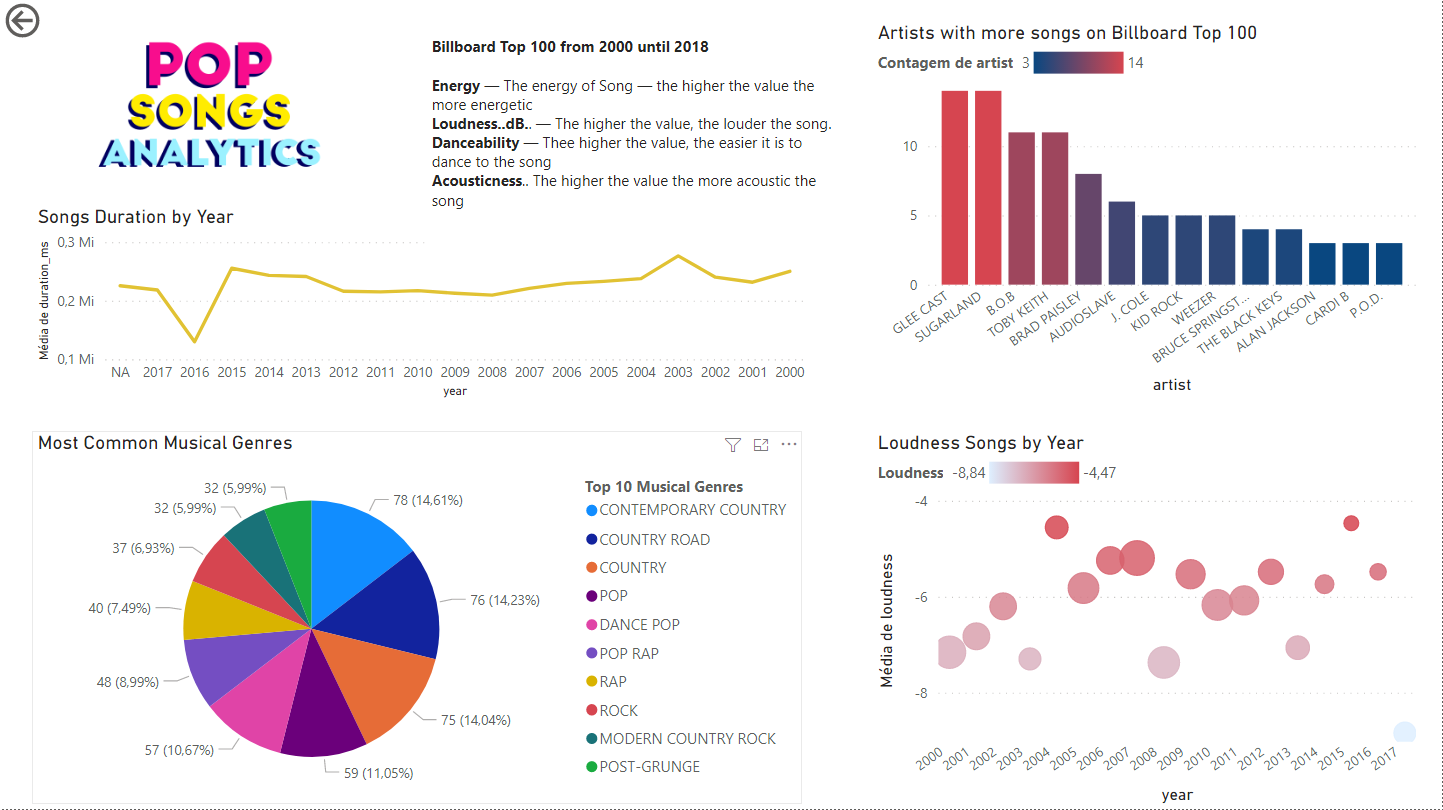
Um gráfico de barras mostra a quantidade de artistas com mais músicas na Billboard e um gráfico de linha exibe a duração média das músicas por ano.
Um gráfico de pizza mostra os gêneros mais comuns, para minha surpresa, country contemporâneo é o gênero mais popular.
Música pop tem se tornado barulhenta com o passar dos anos? Para responder usei um diagrama de dispersão com a média loudness das músicas.
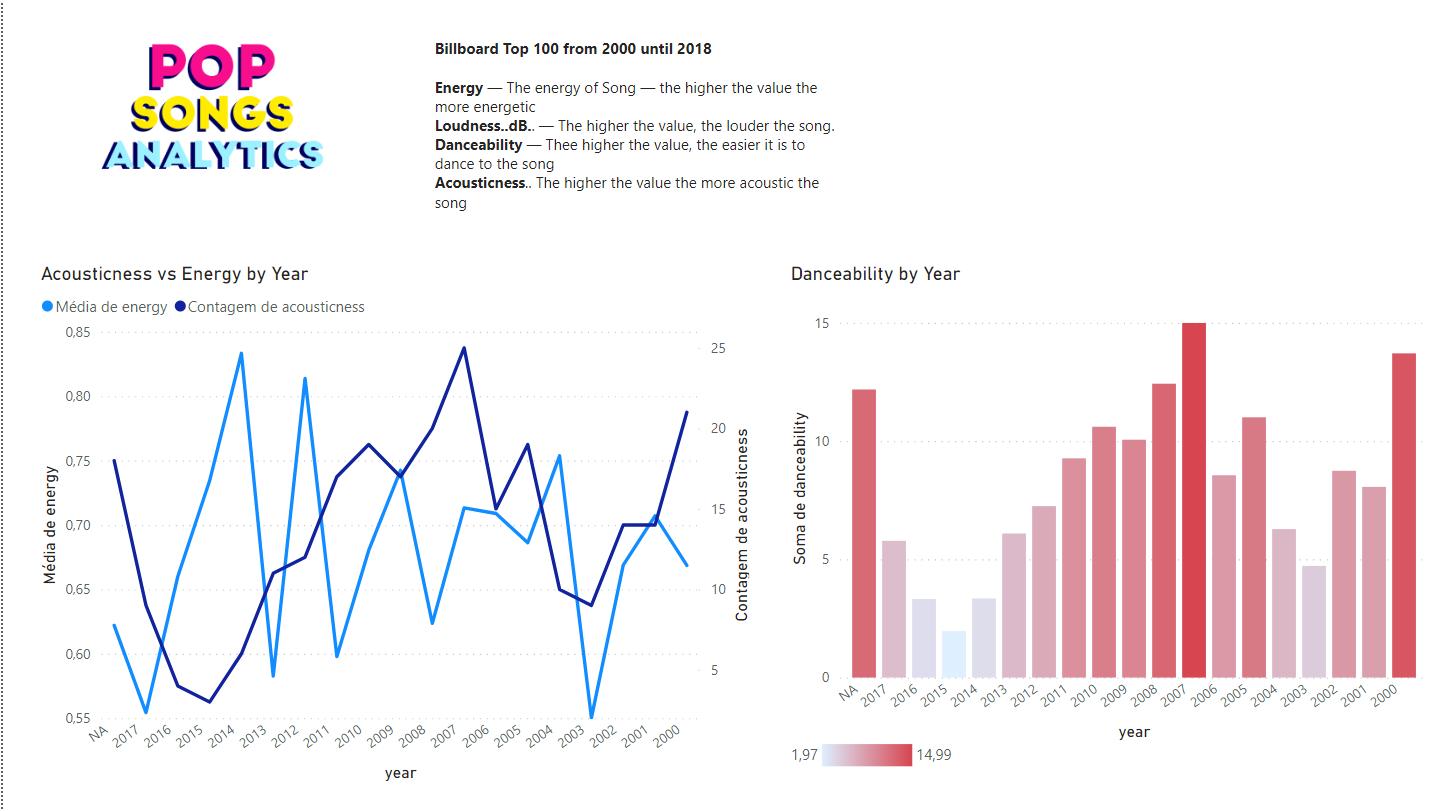
### A música pop tem se tornado menos ou mais dançante?
Na segunda página um gráfico de barras mostra a como a danceability mudou pelos anos e a relação entre energy versus acousticness.
[https://openexchange.intersystems.com/contest/current](https://openexchange.intersystems.com/contest/current)
Agradecimento especial ao @Henrique.GonçalvesDias pelas boas conversas e pelo apoio.
Artigo
Lily Taub · Dez. 21, 2020
## Introdução
A maior parte da comunicação servidor-cliente na web é baseada em uma estrutura de solicitação e resposta. O cliente envia uma solicitação ao servidor e o servidor responde a esta solicitação. O protocolo WebSocket fornece um canal bidirecional de comunicação entre um servidor e um cliente, permitindo que os servidores enviem mensagens aos clientes sem primeiro receber uma solicitação. Para obter mais informações sobre o protocolo WebSocket e sua implementação no InterSystems IRIS, consulte os links abaixo.
* [Protocolo WebSocket](https://tools.ietf.org/html/rfc6455)
* [WebSockets na documentação do InterSystems IRIS](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GCGI_websockets)
Este tutorial é uma atualização de ["Asynchronous Websockets - um tutorial rápido"](https://community.intersystems.com/post/asynchronous-websockets-quick-tutorial) para Caché 2016.2+ e InterSystems IRIS 2018.1+.
#### *Operação assíncrona vs síncrona*
No InterSystems IRIS, uma conexão WebSocket pode ser implementada de forma síncrona ou assíncrona. O modo como a conexão WebSocket entre o cliente e o servidor opera é determinado pela propriedade “SharedConnection” da classe %CSP.WebSocket.
* SharedConnection=1 : operação assíncrona
* SharedConnection=0: operação síncrona
Uma conexão WebSocket entre um cliente e um servidor hospedado em uma instância do InterSystems IRIS inclui uma conexão entre a instância IRIS e o Web Gateway. Na operação síncrona de WebSocket, a conexão usa um canal privado. Na operação assíncrona de WebSocket, um grupo de clientes WebSocket compartilha um conjunto de conexões entre a instância IRIS e o Web Gateway. A vantagem de uma implementação assíncrona de WebSockets se destaca quando se tem muitos clientes se conectando ao mesmo servidor, pois esta implementação não exige que cada cliente seja tratado por uma conexão exclusiva entre o Web Gateway e a instância IRIS.
Neste tutorial, implementaremos WebSockets de forma assíncrona. Portanto, todas as janelas de bate-papo abertas compartilham um conjunto de conexões entre o Web Gateway e a instância IRIS que hospeda a classe do servidor WebSocket.
## Visão geral da aplicação de chat
O “hello world” do WebSockets é uma aplicação de chat em que um usuário pode enviar mensagens que são transmitidas a todos os usuários logados na aplicação. Neste tutorial, os componentes da aplicação de chat incluem:
* Servidor: implementado em uma classe que estende %CSP.WebSocket
* Cliente: implementado por uma página CSP
A implementação desta aplicação de chat irá realizar o seguinte:
* Os usuários podem transmitir mensagens para todas as janelas do chat abertas
* Os usuários on-line aparecerão na lista “Usuários on-line” de todas as janelas de chat abertas
* Os usuários podem alterar seu nome de usuário compondo uma mensagem começando com a palavra-chave “alias” e esta mensagem não será transmitida, mas atualizará a lista de “Usuários On-line”
* Quando os usuários fecham a janela de chat, eles são removidos da lista de “Usuários on-line”
Para ver o código fonte da aplicação de chat, visite este [repositório no GitHub](https://github.com/intersystems/InterSystems-WebSockets).
## O Cliente
O lado do cliente da nossa aplicação de chat é implementado por uma página CSP contendo o estilo para a janela do chat, a declaração da conexão WebSocket, eventos do WebSocket e métodos que tratam da comunicação de e para o servidor, e funções auxiliares que empacotam mensagens enviadas para o servidor e processam as mensagens de entrada.
Primeiro, veremos como a aplicação inicia a conexão WebSocket usando uma biblioteca Javascript WebSocket.
```javascript
ws = new WebSocket(((window.location.protocol === "https:")? "wss:":"ws:")
+ "//"+ window.location.host + "/csp/user/Chat.Server.cls");
```
`new` cria uma nova instância da classe WebSocket. Isso abre uma conexão WebSocket com o servidor usando o protocolo "wss" (indica o uso de TLS para o canal de comunicação WebSocket) ou "ws". O servidor é especificado pelo número da porta do servidor web e nome do host da instância que define a classe `Chat.Server` (essas informações estão contidas na variável `window.location.host`). O nome de nossa classe no servidor (`Chat.Server.cls`) está incluído no URI de abertura do WebSocket como uma solicitação GET para o recurso no servidor.
O evento `ws.onopen` é disparado quando a conexão WebSocket é estabelecida com êxito, fazendo a transição de um estado de **_conectando_** para um estado **_aberto_**.
```javascript
ws.onopen = function(event){
document.getElementById("headline").innerHTML = "CHAT - CONNECTED";
};
```
Este evento atualiza o cabeçalho da janela do chat para indicar que o cliente e o servidor estão conectados.
### *Enviando mensagens*
A ação de um usuário enviando uma mensagem aciona a função de `envio`. Essa função atua como um invólucro em torno do método `ws.send`, que contém a mecânica de envio da mensagem do cliente ao servidor pela conexão WebSocket.
```javascript
function send() {
var line=$("#inputline").val();
if (line.substr(0,5)=="alias"){
alias=line.split(" ")[1];
if (alias==""){
alias="default";
}
var data = {}
data.User = alias
ws.send(JSON.stringify(data));
} else {
var msg=btoa(line);
var data={};
data.Message=msg;
data.Author=alias;
if (ws && msg!="") {
ws.send(JSON.stringify(data));
}
}
$("#inputline").val("");
}
```
`send` envia pacotes as informações a serem enviadas ao servidor em um objeto JSON, definindo pares de chave/valor de acordo com o tipo de informação que está sendo enviada (atualização de alias ou mensagem geral). `btoa` traduz o conteúdo de uma mensagem geral em uma string ASCII codificada em base 64.
### *Recebendo mensagens*
Quando o cliente recebe uma mensagem do servidor, o evento `ws.onmessage` é acionado.
```javascript
ws.onmessage = function(event) {
var d=JSON.parse(event.data);
if (d.Type=="Chat") {
$("#chat").append(wrapmessage(d));
$("#chatdiv").animate({ scrollTop: $('#chatdiv').prop("scrollHeight")}, 1000);
} else if(d.Type=="userlist") {
var ul = document.getElementById("userlist");
while(ul.firstChild){ul.removeChild(ul.firstChild)};
$("#userlist").append(wrapuser(d.Users));
} else if(d.Type=="Status"){
document.getElementById("headline").innerHTML = "CHAT - connected - "+d.WSID;
}
};
```
Dependendo do tipo de mensagem que o cliente recebe (“Chat”, “userlist” ou “status”), o evento `onmessage` chama `wrapmessage` ou `wrapuser` para popular as seções apropriadas da janela de chat com os dados de entrada. Se a mensagem recebida for uma atualização de status, o cabeçalho de status da janela do chat é atualizado com o ID do WebSocket, que identifica a conexão WebSocket bidirecional associada à janela do chat.
### *Componentes adicionais do cliente*
Um erro na comunicação entre o cliente e o servidor aciona o método WebSocket `onerror`, que emite um alerta que nos notifica do erro e atualiza o cabeçalho de status da página.
```javascript
ws.onerror = function(event) {
document.GetElementById("headline").innerHTML = "CHAT - error";
alert("Received error");
};
```
O método `onclose` é disparado quando a conexão WebSocket entre o cliente e o servidor é fechada, e atualiza o cabeçalho de status.
```javascript
ws.onclose = function(event) {
ws = null;
document.getElementById("headline").innerHTML = "CHAT - disconnected";
}
```
## O servidor
O lado do servidor da aplicação de chat é implementado pela classe `Chat.Server`, que estende de `%CSP.WebSocket`. Nossa classe de servidor herda várias propriedades e métodos de `%CSP.WebSocket`, alguns dos quais discutirei abaixo. `Chat.Server` também implementa métodos personalizados para processar mensagens de entrada e transmitir mensagens para o(s) cliente(s).
### *Antes de iniciar o servidor*
`OnPreServer()` é executado antes de o servidor WebSocket ser criado e é herdado da classe `%CSP.WebSocket`.
```
Method OnPreServer() As %Status
{
set ..SharedConnection=1
if (..WebSocketID '= ""){
set ^Chat.WebSocketConnections(..WebSocketID)=""
} else {
set ^Chat.Errors($INCREMENT(^Chat.Errors),"no websocketid defined")=$HOROLOG
}
Quit $$$OK
}
```
Este método define o parâmetro da classe `SharedConnection` em 1, indicando que nossa conexão WebSocket será assíncrona e suportada por vários processos que definem conexões entre a instância InterSystems IRIS e o Web Gateway. O parâmetro `SharedConnection` só pode ser alterado em `OnPreServer()`. O `OnPreServer()` também armazena o ID WebSocket associado ao cliente no `^Chat.WebSocketConnections` global.
### *O método do servidor*
O corpo principal da lógica executada pelo servidor está contido no método `Server()`.
```
Method Server() As %Status
{
do ..StatusUpdate(..WebSocketID)
for {
set data=..Read(.size,.sc,1)
if ($$$ISERR(sc)){
if ($$$GETERRORCODE(sc)=$$$CSPWebSocketTimeout) {
//$$$DEBUG("no data")
}
if ($$$GETERRORCODE(sc)=$$$CSPWebSocketClosed){
kill ^Chat.WebSocketConnections(..WebSocketID)
do ..RemoveUser($g(^Chat.Users(..WebSocketID)))
kill ^Chat.Users(..WebSocketID)
quit // Client closed WebSocket
}
} else{
if data["User"{
do ..AddUser(data,..WebSocketID)
} else {
set mid=$INCREMENT(^Chat.Messages)
set ^Chat.Messages(mid)=data
do ..ProcessMessage(mid)
}
}
}
Quit $$$OK
}
```
Este método lê as mensagens recebidas do cliente (usando o método `Read` da classe `%CSP.WebSockets`), adiciona os objetos JSON recebidos ao `^Chat.Messages` global e chama o `ProcessMessage()` para encaminhar a mensagem a todos os outros clientes de chat conectados. Quando um usuário fecha sua janela de chat (encerrando assim a conexão WebSocket com o servidor), a chamada do método `Server()` para `Read` retorna um código de erro que avalia a macro `$$$CSPWebSocketClosed` e o método prossegue para tratar o encerramento de acordo.
### *Processamento e distribuição de mensagens*
`ProcessMessage()` adiciona metadados à mensagem de chat recebida e chama o `SendData()`, passando a mensagem como um parâmetro.
```
ClassMethod ProcessMessage(mid As %String)
{
set msg = ##class(%DynamicObject).%FromJSON($GET(^Chat.Messages(mid)))
set msg.Type="Chat"
set msg.Sent=$ZDATETIME($HOROLOG,3)
do ..SendData(msg)
}
```
`ProcessMessage()` recupera a mensagem formatada em JSON do `^Chat.Messages` global e a converte em um objeto do InterSystems IRIS usando a classe `%DynamicObject` e o método '`%FromJSON`. Isso nos permite editar facilmente os dados antes de encaminharmos a mensagem para todos os clientes de chat conectados. Adicionamos um atributo `Type` com o valor “Chat”, que o cliente usa para determinar como lidar com a mensagem recebida. `SendData()` envia a mensagem para todos os outros clientes de chat conectados.
```
ClassMethod SendData(data As %DynamicObject)
{
set c = ""
for {
set c = $order(^Chat.WebSocketConnections(c))
if c="" Quit
set ws = ..%New()
set sc = ws.OpenServer(c)
if $$$ISERR(sc) { do ..HandleError(c,"open") }
set sc = ws.Write(data.%ToJSON())
if $$$ISERR(sc) { do ..HandleError(c,"write") }
}
}
```
`SendData()` converte o objeto do InterSystems IRIS de volta em uma string JSON (`data.%ToJSON()`) e envia a mensagem para todos os clientes de chat. `SendData()` obtém o ID WebSocket associado a cada conexão cliente-servidor do `^Chat.WebSocketConnections` global e usa o ID para abrir uma conexão WebSocket por meio do método `OpenServer` da classe `%CSP.WebSocket`. Podemos usar o método `OpenServer` para fazer isso porque nossas conexões WebSocket são assíncronas - extraímos do pool existente de processos do IRIS-Web Gateway e atribuímos um ID WebSocket que identifica a conexão do servidor a um cliente de chat específico. Por fim, o método `Write()` `%CSP.WebSocket` envia a representação da string JSON da mensagem para o cliente.
## Conclusão
Esta aplicação de chat demonstra como estabelecer conexões WebSocket entre um cliente e um servidor hospedado pelo InterSystems IRIS. Para continuar lendo sobre o protocolo e sua implementação no InterSystems IRIS, dê uma olhada nos links na introdução.
Anúncio
Angelo Bruno Braga · Ago. 22, 2022
Estamos muito empolgados em anunciar o lançamento da série de Mesas Redondas da Comunidade de Desenvolvedores!
As sessões de Mesas Redondas são para você aprender novidades e conectar com outros membros da Comunidade. Todo mês será selecionado um novo tópico, disponibilizada uma visão geral e selecionada uma data e horário específico para este evento.
Nós discutimos sobre alguns tópicos para esta primeira Mesa Redonda mas, acima de tudo, nós queremos saber de vocês qual assunto vocês gostariam de debater!
Navegue >> para este desafio << no Global Masters para escolher um tópico e sugerir o seu.
Ainda não é um membro do Global Masters? Junte-se aqui - utilize suas credenciais InterSystems SSO para acessar.
Aprenda mais sobre o Global Masters, nossa plataforma de gamificação para desenvolvedores aqui.
Anúncio
Danusa Calixto · Maio 11, 2023
Olá Desenvolvedores,
Divirta-se assistindo ao novo video em InterSystems Developers YouTube:
⏯ Quebrando silos de dados por meio de Parcerias Estratégicas de Saúde @ Global Summit 2022
Saiba como o Rhodes Group, uma empresa de software que atende laboratórios e sistemas de saúde, aproveitou dados agregados para atender às necessidades de saúde pública relacionadas à hepatite C no Novo México. Você obterá informações sobre como os dados de laboratório são posicionados de maneira exclusiva para atender a uma variedade de necessidades em grande escala. Exploraremos as lições aprendidas, discutiremos parte da arquitetura técnica e compartilharemos como planejamos aproveitar esses dados e muito mais para enfrentar os desafios futuros.
🗣 Apresentadores: Rick VanNess, Director, Product Development, Rhodes Group
Divirta-se e fique ligado! 👍
Anúncio
Danusa Calixto · Abr. 24
HealthShare Unified Care Record - Visão Geral – Virtual 15-16 de Maio, 2025
O curso Visão Geral do HealthShare Unified Care Record é uma ótima maneira para qualquer pessoa se familiarizar com o Unified Care Record, mas especialmente para aqueles que precisam entender seus recursos, mas não como configurá-lo.
Este é um curso de treinamento presencial não técnico, ministrado por instrutor, que fornece uma introdução abrangente ao HealthShare Unified Care Record.
Este curso é para qualquer pessoa que precise saber sobre a funcionalidade e a arquitetura do HealthShare Unified Care Record. (Se precisar de informações sobre como configurar e solucionar problemas do Unified Care Record, considere a aula de Fundamentos do Unified Care Record.
Nenhum conhecimento ou experiência prévia é necessária para a aula de Visão Geral e qualquer funcionário da InterSystems pode se inscrever.
Registre-se aqui!
Anúncio
Angelo Bruno Braga · Out. 9, 2020
Olá desenvolvedores !!!
Você irá se juntar a nós no InterSystems Virtual Summit 2020?
⚡️ AS INSCRIÇÕES JÁ ESTÃO ABERTAS ⚡️
Haverá algo para todos no Virtual Summit, seja você um executivo com experiência em tecnologia, um gerente técnico, um desenvolvedor ou um integrador de sistemas. E este ano todas as sessões são gratuitas!
O tema geral do Summit será Interação & Informação. E o que o espera no Summit ?
✅ KEYNOTESCriando uma Organização Adaptável20-22 de Outubro 2020
✅ +60 SESSÕES AO VIVOMelhores práticas, nova tecnologia, roadmaps27-29 de Outubro 2020
✅ PERGUNTE AOS EXPERTSUm a Um30 de Outubro e 2 de Novembro 2020
✅ LABORATÓRIOSPráticas com nossa tecnologia2-5 de Novembro 2020
Maiores detalhes podem ser obtidos aqui: intersystems.com/summit20
Então!
Junte-se a nós no Virtual Summit 2020!
Anúncio
Drew Spoelstra · Fev. 18, 2021
Nós somos uma Rede de Informações de Saúde multiestado procurando analistas de integração com experiência para preencher posições de forma imediata. Atualmente estas posições são para trabalho 100% remoto. Excelentes benefícios.
Os candidatos ideiais devem possuir vasta experiência com o HealthShare da InterSystems, experiência com Serviços Web da Amazon, HL7 v2 & v3, e perfis IHE ITI. Experiência com o Rhapsody ou outras ferramentas de integração é um diferencial. Procuramos pessoas confiantes e motivadas, com fortes habilidades de comunicação e a capacidade de se envolver diretamente com uma variedade de partes interessadas na área da saúde.
Para maiores informações e se candidatar, visite a página de carreiras da MiHIN: https://mihin.applytojob.com/apply
Candidatos devem ser elegíveis para trabalhar nos Estados Unidos.
Sinta-se à vontade para entrar em contato comigo se tiver dúvidas.
-Drew Spoelstra
Pergunta
Guilherme Koerber · Abr. 29, 2021
Estou tentando instalar o IRIS for Health pela primeira vez em meu Mac doméstico para fins de avaliação. Quero poder instalar o IRIS e o Ensemble. Baixei o pacote, mas ele não vem com instruções e estou tendo problemas. Existe um conjunto de instruções de instalação simples online ou alguém tem um que você possa repassar?
Obrigado, Jim Winski Oi Jim, eu consegui instalar usando o link da documentação da Intersystems abaixo:
https://docs.intersystems.com/iris20191/csp/docbook/Doc.View.cls?KEY=GCI_unix Opa, tudo bem?
Eu tenho utilizado Docker e seu uso tem se mostrado muito mais simples e prático. Nesse link, tem o passo a passo de como subir o ambiente utilizando essa estrutura. No começo pode parecer meio "estranho", mas você logo se acostuma com a praticidade.
Anúncio
Timothy Leavitt · Out. 28, 2021
Eu gostaria de chamar a atenção de vocês ára duas sessões do Virtual Summit, mesmo elas não sendo tão legais quanto a Embedded Python.
Git & GitLab for Shared Development Environments detalha o recém lançado pacote git-source-control (veja também no Open Exchange) que disponibiliza uma nova solução de ponta para integração IRIS/Git no lado servidor, especialmente para ambientes de desenvolvimento remotos compartilhados. (Eu preciso escrever uma postagem especifica sobre este pacote e planejo fazê-lo em breve.)
InterSystems Package Manager Advanced Topics mostra que nosso gerenciador de pacotes (conhecido afetivamente por "ZPM") é mais do que apenas uma ferramenta para conseguir pacotes úteis da comunidade - ele pode na verdade direcionar a construção, empacotamento e distribuição de soluções completas.
Ficarei feliz em responder qualquer pergunta aqui ou por mensagens/emails !
Artigo
Heloisa Paiva · Mar. 28, 2023
O Visual Studio Code (VSCode) é o editor de código mais popular do mercado. Foi criado pela Microsoft e distribuído como um IDE gratuito. O VSCode suporta dezenas de linguagens de programação, incluindo ObjectScript, até 2018, Atelier (baseado no Eclipse). Foi considerado como uma das principais opções para desenvolver produtos InterSystems. No entando, em Dezembro de 2018, quando a Comunidade de Desenvolvedores InterSystems lançou suporte para o VSCode, uma porção relevante dos profissionais InterSystems começaram a realmente utilizar esse editor e isso tem sido feito desde então, especialmente os desenvolvedores trabalhando com novas tecnologias (Docker, Kubernetes, NodeJS, Angular, React, DevOps, Gitlab etc.). Algumas das melhores características do VSCode são os recursos de Debug. É por isso que esse artigo vai demonstrar em detalhes como debugar um código ObjectScript, incluindo código de classe e código de %CSP.REST.
O que é debugar?
Debugar é um processo de detectar e resolver "bugs" - erros no seu código ObjectScript. Alguns erros são lógicos, não de compilação. É por isso que para entendê-los na lógica de execução do seu código fonte, você precisa ver o programa rodar linha por linha. Esse é o melhor jeito de identificar condições ou lógica de programação e achar erros lógicos. Outros erros são os de tempo de execução. Para nós conseguirmos debugar esse tipo de problema, é essencial checar os valores das variáveis atribuídas primeiro.
Instalar todas as extensões de InterSystems IRIS para VSCode
Antes de tudo, você deve instalar as extensões de InterSystems IRIS para o o seu IDE VSCode. Para isso, vá em Extensões, pesquise por InterSystems e instale essas extensões:
A última extensão (InterSystems ObjectScript Extension Pack) deve ser instalada primeiro, porque é um pacote de extensões requiridas para conectar, editar, desenvolver e debugar ObjectScript. As outras extensões são opcionais.
Aplicação de exemplo
Vamos usar uma aplicação do meu repositório GitHub (https://github.com/yurimarx/debug-objectscript.git) para os exemplos de debug nesse artigo. Então, siga os passos e seguir para obter, rodar e debugar a aplicação em VSCode:1. Crie um diretório local e obtenha o código fonte do projeto nesse diretório:
$ git clone https://github.com/yurimarx/debug-objectscript.git
2. Abra o terminal nesse diretório (diretório iris-rest-api-template) e rode:
$ docker-compose up -d --build
3. Abra o VSCode dentro do diretório de iris-rest-api-template usando $code . ou clique com o botão direito na pasta e selecione Abrir com Code.4. No rodapé, clique em ObjectScript para abrir as opções configuradas em .vscode/launch.json:
5. Selecione Toggle Connection para habilitar a conexão atual:
6. Após habilitar essa conexão, você a terá mostrada abaixo:
7. Se você não está conectado em IRIS no seu VSCode, você não poderá debugar seu código ObjectScript. Então cheque sua conexão clicando na extensão ObjectScript VSCode:
8. Abra Person.cls, vá para a linha número 25 e aponte o mouse para o número 25 à sua esquerda.
9. Agora, aponte o mouse acima de ClassMethod e clique em Debugar esse método:
10. O VSCode vai abrir um Diálogo para você setar valores para os parâmetros, então defina os valores como os demonstrados abaixo e clique em Enter:
11. O VSCode vai quebrar a execução do código na linha 25:
12. Agora, no topo à esquerda, você pode ver os valores atuais das variáveis.
13. Abaixo à esquerda, você pode ver a lista de Breakpoints e a pilha de chamadas para o breakpoint atual.
14. No topo à direita, você pode ver o código fonte com o breakpoint e um conjunto de botões para controlar a execução de debugar.
15. Se você precisa usar o Console de Debug para escrever algo, digite: Name_","_Title para ver a concatenação das variáveis usando o Console de Debug:
16. Selecione a variável de resultado, clique com o botão direito do mouse e selecione Add to Watch:
17. Agora você pode monitorar ou mudar o valor atual da variável resultante na seção WATCH:
18. Por fim, a barra de rodapé é laranja e indica o debug:
Usando o Console de Debug
O Console de Debug permite que você escreva expressões durante o Debug, então você pode checar valores de diferentes variáveis (tipo simples ou tipo objeto) ou validar o valor atual e outras condições. Ele pode executar qualquer coisa que possa retornar alguns valores, então $zv vai funcionar também. Siga esses passos para ver algumas opções:
1. Escreva Name_","_Title_" From "_Company no prompt do Terminal de Debug e veja os valores de Name, Title e Company concatenados como output:
Usando a Barra de Ferramentas de Debug
A Barra de Ferramentas de Debug permite que você controle a execução do debug, então cheque as funções dos botões aqui:
1. Botão de continuar (F9): continua a execução até o próximo ponto de parada. Se não há ponto de parada, segue até o final.2. Pular (F8): vá para a próxim alinha sem entrar no código fonte de um método interno (não entre no método Populate)3. Entrar (F7): vá para a próxima linha dentro do código fonte do método interno (vá para a primeira linha do método Populate)4. Sair (Shift + F8): vá para a linha atual do código fonte chamador do método.5. Recomeçar: (Ctrl +Shift + F5): recomece o debug.6. Parar: para a sessão de debug.
Debugando métodos de classe de %CSP.REST
Para debugar métodos de classe REST, é necessário aplicar um pequeno truque revelado pelo Fábio Gonçalves (cheque aqui o artigo https://community.intersystems.com/post/atelier-debugging-attach-process). É necessário adicionar um HANG (minha recomendação é entre 20 e 30 segundos). Simplesmente siga esses passos:
1. Abra o Arquivo src\dc\Sample\PersonREST.cls e vá para o método GetInfo(), adicione HANG 30 (isso é necessário para ganhar tempo, 30 segundos, para começar o debug desse método):
2. Defina pontos de parada nas linhas do HANG e do SET version (círculos vermelhos):
3. Abra um client HTTP para chamar um método REST (vou chamar GetInfo da classe PersonREST):
4. Defina Basic Auth para Authorization (Usuário _SYSTEM e Senha SYS):
5. Envie um GET http://localhost:52773/crud/.6. Clique em ObjectScript Attach na barra de rodapé:
7. Escolha ObjectScript Attach:
8. Escolha o processo de PersonREST:
9. Espere um tempo (cerca de 30 segundos) para o VSCode quebrar a execução atual no ponto de parada:
Nota 1: remova o HANG 30 quando acabar o debug, porque o HANG vai pausar a execução.
Nota 2: se o processo PersonREST não aparecer, reinicie seu VSCode e tente novamente.
10. Agora você pode fazer seu processo de debug.
Editar ponto de parada
Você pode clicar com o botão direito no ponto de parada para remover ou configurar pontos de parada condicionais (parar no ponto de parada com uma condição verdadeira). O comando de parada integrado no código também será percebido pelo debugger. Você pode tentar isso também.
1. Clique com o botão direito no ponto de parada e selecione Edit Breakpoint:
2. Entre na expressão mencionada abaixo e pressione Enter:
Nota: tente versão = 1.0.5 para ver o ponto de parada falso e 1.0.6 para ver o ponto de parada verdadeiro.
Configure opções de debug em .vscode/launch.json
O arquivo Launch.json é usado para configurar opções de debug para o seu projeto. Para ver alternativas, vá para esse arquivo:
Para esse exemplo, temos duas opções para selecionar para debugar:
1. Podemos lançar o debug na classe configurada no atributo do programa diretamente com um programa (nesse exemplo o debugador vai começar na classe PackageSample.ObjectScript, método Test()).2. Podemos anexar PickProcess para o processo do programa selecionado que queira debugar. Nesse exemplo o debugador vai abrir no topo uma lista de processos para selecionar qual processo (cada programa tem seu processo) será debugado. A segunda opção é mais comum.
Em geral, esses atributos são obrigatórios para qualquer configuração de debug (fonte: https://intersystems-community.github.io/vscode-objectscript/rundebug/):
type - Identifica o tipo de debugador para usar. Nesse caso, objectscript é fornecido pela extensão InterSystems ObjectScript.
request - Identifica o tipo de ação para essa configuração de lançamento. Possíveis valores são launch e attach.
name - Um nome arbitrário para identificar a configuração. Esse nome aparece na lista suspensa ao clicar Start Debugging.
Em adição, para uma configuração de lançamento ObjectScript, você precisa fornecer o programa de atributos, que especifica a rotina ou ClassMethod para rodar quando lança o debugador, como mostrado no exemplo:
"launch": {
"version": "0.2.0",
"configurations": [
{
"type": "objectscript",
"request": "launch",
"name": "ObjectScript Debug HelloWorld",
"program": "##class(Test.MyClass).HelloWorld()",
},
{
"type": "objectscript",
"request": "launch",
"name": "ObjectScript Debug GoodbyeWorld",
"program": "##class(Test.MyOtherClass).GoodbyeWorld()",
},
]
}
Para uma configuração de anexo ObjectScript, você deve fornecer os seguintes atributos:
processId - Especifica o ID do processo para anexar a uma string ou número. O padrão é "${command:PickProcess}" prove uma lista suspensa de IDs de processo para anexar em tempo de execução.
system - Especifica se deve ou não permitir anexos para o processo de sistema. O padrão é falso.
O exemplo a seguir mostra múltiplas configurações de anexo ObjectScript válidas:
"launch": {
"version": "0.2.0",
"configurations": [
{
"type": "objectscript",
"request": "attach",
"name": "Attach 1",
"processId": 5678
},
{
"type": "objectscript",
"request": "attach",
"name": "Attach 2",
"system": true
},
]
}
Agora, você pode selecionar uma configuração da lista que o VSCode fornece no campo Run and Debug no topo da barra lateral de debug (fonte: https://intersystems-community.github.io/vscode-objectscript/rundebug/):
Se você clicar na seta verde, a configuração atualmente selecionada irá rodar.
Ao começar um lançamento de sessão de debug ObjectScript, esteja seguro que o arquivo contendo o programa que você está debugando está aberto no seu editor e está na aba ativa. O VS Code vai começar uma sessão de debug com o servidor do arquivo no editor ativo (a aba em que o usuário está focado). Isso também se aplica para sessões de debug ObjectScript anexadas.
Essa extensão usa WebSockets para se comunicar com o servidor InterSystems durante o debug. Se você está tendo problemas quando tenta começar uma sessão de debug, cheque se o servidor web do servidor InterSystems permite conexões WebSocket.
Comandos de debug e itens na menu Run funcionam basicamente da mesma maneira que funcionam para outras linguagens suportadas pelo VS Code. Para informações adicionais no debug do VS Code, veja os recursos da documentação listada no começo dessa seção.
Definir a sincronização entre um código fonte local e um código fonte do servidor (no servidor IRIS)
Também é importante ter uma estrutura de pastas para o código fonte, que pode ser adotada pelas configurações de "objectscript.export". Essa informação será usada para converter os nomes das classes do servidor para arquivos locais. Se estiver incorreta, pode abrir classes no modo de leitura mesmo se existirem só localmente.1. Abra .vscode\settings.json arquivo e configure objectscript.export:
2. Passe o mouse por cima da pasta e adicione Categoria e outros parâmetros para ver a documentação dela.
Outras técnicas para complementar o processo de debug
Em adição ao seu programa de debug, lembre-se de documentar bem o seu código fonte, logar operações performadas por códigos importantes e performar testes unitários e ferramentas de análise estáticas de códigos fonte. Dessa forma, a qualidade dos seus programas será muito melhor, reduzindo manutenção e tempo de ajuste e custo.
Aprendendo mais
Você pode ler mais sobre debugar ObjectScript no VSCode se olhar esses recursos:1. https://www.youtube.com/watch?v=diLHwA0rlGM2. https://intersystems-community.github.io/vscode-objectscript/rundebug/3. https://code.visualstudio.com/docs/introvideos/debugging4. https://code.visualstudio.com/docs/editor/debugging5. https://docs.intersystems.com/iris20221/csp/docbook/Doc.View.cls?KEY=TOS_VSCode Obrigado por traduzir!
Anúncio
Angelo Bruno Braga · Mar. 23, 2021
Olá Comunidade,
Temos o prazer de convidá-lo a participar do próximo webinar "Conecte silos de dados e aplicativos para acelerar os insights de negócios em escala" dia 8 de Abril às 11:00, horário de Brasília.
A explosão de sistemas e processos de negócios e os silos de dados resultantes destes fizeram com que a obtenção de uma visão abrangente das informações corporativas se tornasse mais desafiadora do que nunca. Junte-se a dois veteranos do setor de gerenciamento de dados enquanto eles discutem os últimos avanços em tecnologia de gerenciamento de dados, trabalhando com dados transacionais e analíticos, e entenda como o setor de serviços financeiros está enfrentando os desafios para acelerar o insight e a inovação.
Palestrantes:🗣 Scott Gnau, Vice Presidente, Plataformas de Dados, InterSystems🗣 Dave Mariani, Cofundador & CTO, AtScale
Data: Terça-feira 8 de Abril de 2021Horário: 11:00 horário de Brasília
➡️ REGISTRE-SE HOJE!
Anúncio
Angelo Bruno Braga · Maio 14, 2021
Olá Comunidade,
É um prazer convidá-los para o nosso próximo webinar em Espanhol "Aprendendo ObjectScript do zero"!
Data & Horário: 25 de Maio, 11:00 horário de Brasília
Palestrante: @David.Reche, Gerente da Comunidade de Desenvolvedores em Espanhol
O público alvo deste webinar são:
Desenvolvedores que não conhece o ObjectScript e gostaria de utilizá-lo
Desenvolvedores que tem utilizado o ObjectScript por um tempo mas gostariam de utilizá-lo ao máximo
Nós iremos explicar os conceitos básicos do ObjectScript, e mostrar algumas dicas e truques úteis.
Ao final do webinar, será disponibilizado um questionário online, desta forma será possível que vocês demonstrem o que vocês aprenderam! Ganhadores receberão uma camisa polo da InterSystems ... e alguns outros prêmios! Nota: este webinar será realizado em Espanhol.
Estamos aguardando vocês !
➡️ David Reche convida vocês para se juntarem ao webinar! >>
➡️ Registrem-se aqui! >>