Usando o Python no InterSystems IRIS – Calculando uma Regressão Logística Binária
Usando o Python no InterSystems IRIS – Calculando uma Regressão Logística Binária
Olá,
Neste artigo vamos ver como usar o python para calcular uma regressão logística binária no Iris.
A regressão logística é um método estatístico utilizado para modelar e prever a probabilidade de um evento ocorrer, sendo particularmente útil quando a variável dependente (ou de saída) é categórica. A forma mais comum é a regressão logística binária, onde o objetivo é prever entre duas classes, como "sim/não", "0/1" ou "positivo/negativo". Podemos usar como exemplos de utilização da regressão logística binária a avaliação de concessão um empréstimo, a possibilidade de venda em um site, detecção de fraudes em transações, seleção de pessoal, e por aí vai.
Antes de entrarmos no código vamos pensar no nosso projeto. Existe um conceito muito utilizado em projetos que são os 5W: Who, What, When, Where e Why. São perguntas que você faz para balizar o desenvolvimento do projeto:
1. Who (Quem?)
- Quem são os stakeholders?
- Identifique quem está envolvido ou será impactado pelo projeto.
- Quem irá usar o modelo?
- É um sistema automatizado? Um analista? Um cliente final?
- Quem fornece os dados?
- Determine as fontes de dados e sua qualidade.
2. What (O que?)
- O que o modelo deve fazer?
- Defina o objetivo do projeto.
- O que você está tentando prever ou inferir?
- Exemplos: aprovação de crédito, previsão de vendas, etc.
- O que está disponível?
- Quais são os dados disponíveis? Eles são suficientes para atingir o objetivo?
3. When (Quando?)
- Quando o modelo será usado?
- Previsões diárias, ou análise histórica?
- Quando os dados serão atualizados?
- Avalie a frequência de atualização dos dados para manter o modelo relevante.
4. Where (Onde?)
- Onde os dados estão armazenados?
- Identifique a origem dos dados: bancos de dados, APIs, arquivos locais, etc.
- Onde o impacto será sentido?
- Considere onde os resultados do modelo afetarão a organização ou o processo.
5. Why (Por quê?)
- Por que estamos resolvendo este problema?
- Relacione o problema a um objetivo de negócio ou impacto claro.
- Por que este método/modelo?
- Justifique a escolha do algoritmo ou abordagem com base no problema e nos dados.
- Por que esses dados são relevantes?
- Avalie se as variáveis escolhidas têm valor preditivo suficiente.
Respondidas estas perguntas, temos então informações importantes para a montagem do nosso projeto. Essas respostas, associadas ao Relatório de Exploração de Dados e ao Canvas de Workflow (ver em https://pt.community.intersystems.com/post/usando-o-python-no-intersystems-iris-%E2%80%93-montando-o-relat%C3%B3rio-de-an%C3%A1lise-explorat%C3%B3ria-de-dados) nos permite montar uma documentação inicial do projeto que já nos ajuda a identificar as necessidades e os recursos disponíveis, assim como aponta os caminhos a seguir e os resultados esperados.
Voltando então para o nosso código, em python existe a biblioteca scikit-learn que tem a classe LinearRegression, que implementa o cálculo de regressão logística.
No exemplo vamos avaliar se uma pessoa navegando em um site irá ou não realizar uma compra. Para isso vamos utilizar como variáveis independentes as informações de idade, tempo de navegação, número de produtos visualizados e se clicou em promoção. Vamos criar o dataframe manualmente com essas informações, mas elas poderiam vir, por exemplo, de algum log de acesso ao site e recuperadas via SQL conforme vimos em exemplos de postagens anteriores.
ClassMethod CalcularRegressaoLogistica() As %String [ Language = python ]
{
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, accuracy_score, confusion_matrix
from sklearn.preprocessing import StandardScaler
from sklearn.compose import ColumnTransformer
import matplotlib
import matplotlib.pyplot as plt
matplotlib.use("Agg")
# Criando as informações manualmente para uso no modelo
data = {
'idade': [24, 31, 45, 36, 29, 41, 53, 27, 34, 44, 25, 38, 32, 43, 56, 26, 33, 40, 37, 47, 50, 32, 18, 22, 30],
'tempo_navegacao': [ 6, 11, 9, 15, 8, 4, 7, 13, 10, 5, 12, 3, 8, 10, 14, 9, 11, 7, 6, 10, 8, 5, 10, 4, 1],
'produtos_visualizados': [ 4, 6, 8, 5, 7, 9, 6, 7, 10, 5, 6, 2, 8, 7, 9, 6, 7, 8, 6, 9, 5, 2, 3, 1, 1],
'clicou_promo': [ 1, 0, 1, 1, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 1, 0, 0, 1, 1, 0],
'comprou': [ 0, 0, 1, 1, 0, 0, 1, 0, 1, 0, 1, 1, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0]
}
# Convertendo para o DataFrame
df = pd.DataFrame(data)
# Separando as variáveis independentes (X) e dependente (y)
X = df.drop(columns=['comprou']) # Todas as colunas, menos a comprou
y = df['comprou'] # Somente a coluna comprou
# Dividindo em dados de treino (70%) e teste (30%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Tratando as colunas binarias e não-binarias
colunas_binarias = ['clicou_promo']
colunas_nao_binarias = ['idade', 'tempo_navegacao', 'produtos_visualizados']
pre = ColumnTransformer(
transformers=[
('scaler', StandardScaler(), colunas_nao_binarias) # Escalar apenas colunas não binarias
],
remainder='passthrough' # Deixar as colunas binárias como estão
)
# Normalizando os dados
X_train_scaled = pre.fit_transform(X_train)
X_test_scaled = pre.transform(X_test)
# Criando o modelo de Regressão Logística
modelo = LogisticRegression(random_state=42)
# Treinando o modelo com os dados de treino
modelo.fit(X_train_scaled, y_train)
# Fazendo previsões
y_pred = modelo.predict(X_test_scaled)
# Criar a matriz de confusão
conf_matrix = confusion_matrix(y_test, y_pred)
print("\nMatriz de Confusão:")
print(conf_matrix)
# Avaliando o modelo
print("\nAcurácia:")
print(accuracy_score(y_test, y_pred))
# Gerando o Relatório de Classificação
print("\nRelatório de Classificação:")
print(classification_report(y_test, y_pred))
# Recuperando os coeficientes
coeficientes = modelo.coef_[0]
# Nomes das features
features = ['idade', 'tempo_navegacao', 'produtos_visualizados', 'clicou_promo']
# Visualizando o peso de cada feature
plt.figure(figsize=(8, 6))
plt.bar(features, coeficientes)
plt.title('Peso das Features - Regressão Logística')
plt.xlabel('Features')
plt.ylabel('Coeficiente (Peso)')
plt.savefig('c:\\temp\\pesos_features.png', dpi=300)
return "fim"
}
No nosso código dividimos o dataframe em duas partes: 70% para treinamento e 30% para teste. Desta forma temos o modelo treinado e depois avaliado.
Ainda no nosso código, podemos ver que em dado momento estamos fazendo uma conversão das colunas idade, tempo_navegacao e produtos_visualizados. Isso acontece pois estas colunas estão em uma amplitude diferente. Veja o exemplo abaixo:
- Idade: valores de 0 a 100.
- Tempo de navegação: valores de 0 a 60 minutos.
- Número de cliques: valores de 0 a 200.
Desta forma ao serem interpretados os valores, pode haver distorções. Para evitar isso utilizamos o scaler para harmonizar estas colunas e deixa-las dentro de uma mesma escala. Esta tarefa não altera a relação entre as variáveis, apenas ajusta os valores para que estejam na mesma escala, o que é importante para não haver problemas de interpretação dos valores.
Assim, explicados esses pontos, vamos a execução do nosso código:
>d ##Class(Python.Estatistica).CalcularRegressaoLogistica()
Matriz de Confusão:
[[4 0]
[2 2]]
Acurácia:
0.75
Relatório de Classificação:
precision recall f1-score support
0 0.67 1.00 0.80 4
1 1.00 0.50 0.67 4
accuracy 0.75 8
macro avg 0.83 0.75 0.73 8
weighted avg 0.83 0.75 0.73 8
Como resultado temos 3 informações sobre o modelo criado:
Matriz de Confusão: É uma matriz que mostra a performance de um modelo classificando corretamente ou incorretamente as classes. A estrutura é a seguinte:
-
- Verdadeiros Positivos (VP): Predição correta como positiva.
- Falsos Positivos (FP): Predição incorreta como positiva.
- Verdadeiros Negativos (VN): Predição correta como negativa.
- Falsos Negativos (FN): Predição incorreta como negativa.
As informações ficam distribuídas na matriz da seguinte forma:

Acurácia: Mede a proporção de predições corretas sobre o total de predições. Abaixo temos a fórmula utilizada:

Relatório de Classificação: É um resumo detalhado das métricas principais para avaliar modelos de classificação, conforme abaixo:
-
- Precisão (Precision): Proporção de predições positivas corretas.
- Revocação (Recall): Proporção de positivos corretamente identificados.
- F1-Score: Média harmônica entre precisão e revocação.
- Suporte: Quantidade de exemplos de cada classe.
Estas informações são importantes para nos ajudar a avaliar o modelo. No nosso caso a acurácia está em 75%, o que pode ser interessante dependendo do uso a ser dado para a predição.
Adicionalmente, o código pode nos gerar um gráfico com os pesos de cada feature do modelo:
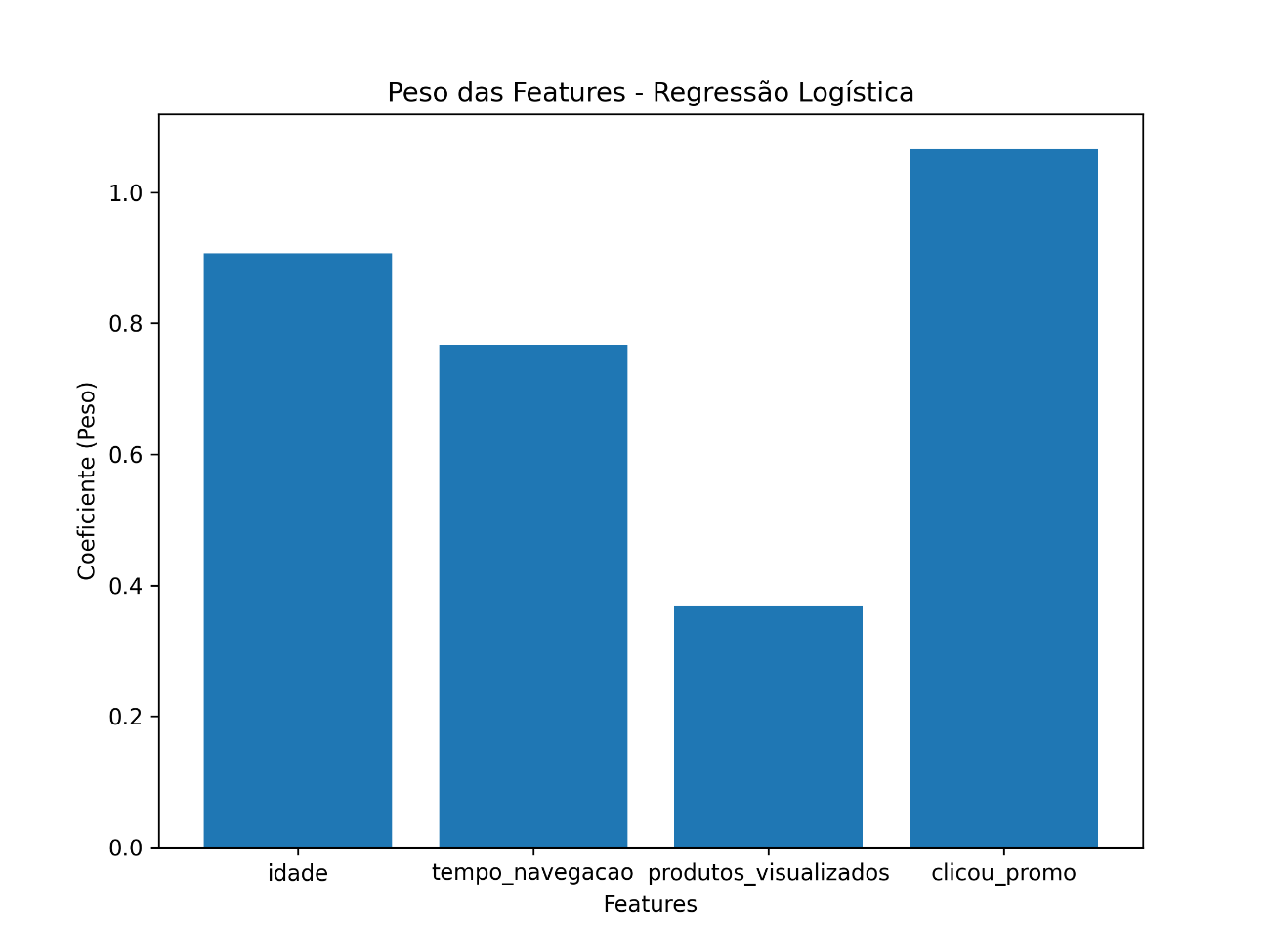
Podemos ver que o número de produtos visualizados tem pouco peso no modelo, enquanto clicar em promoção tem um peso alto. Já idade e tempo de navegação tem pesos moderados. Este gráfico é interessante pois nos ajuda a entender como o modelo trabalha e quais as informações mais relevantes para a predição.
Podemos armazenar este modelo para uso com informações pontuais conforme vimos em exemplos anteriores já postados nesta série de artigos. Somente lembre de escalar as variáveis da mesma forma que fizemos com os dados de treinamento, para manter a padronização. É possível também salvar e utilizar o scaler da mesma forma que fazemos com o modelo. Veja abaixo:
Salvando o scaler para uso futuro:
from joblib import dump
# Salvar o ColumnTransformer em um arquivo
dump(pre, 'c:\\temp\\preprocessor_scaler.joblib')
Recuperando o scaler salvo para uso em uma nova predição
from joblib import load
# Carregar o ColumnTransformer salvo
pre_loaded = load('c:\\temp\\preprocessor_scaler.joblib')
# Exemplo de novos dados
novos_dados = pd.DataFrame({
'idade': [25],
'tempo_navegacao': [10],
'produtos_visualizados': [3],
'clicou_promo': [1]})
# Escalar os novos dados
novos_dados_escalados = pre_loaded.transform(novos_dados)
print(novos_dados_escalados)
Agora uma curiosidade: Você deve ter notado o valor de random_state=42 no código. O valor 42 é arbitrado para que o código possa ter reprodutibilidade, ou seja, sempre que executar o resultado será o mesmo para a divisão de dados entre treinamento e teste, e também na aquisição de valores do cálculo da regressão logística. Poderia ser qualquer outro valor, desde que ele seja usado sempre no código. Se você uma vez fizer a execução com um valor e depois com outro poderá receber valores diferentes de saída.
Mas de onde vem o valor 42, muito usado em ML? Essa é uma história curiosa, que remete ao filme “Mochileiros das Galáxias”. Sim, é um easter-egg da cultura pop. O computador Deep Thought no filme, depois de milhões de anos de cálculos, dá como resposta a Questão Definitiva da Vida esse valor, ou seja, 42. E é daí que vem esse número. Existem outras hipóteses, como por exemplo, ser o ângulo formado pelo arco-íris (42 graus), entre outras. Mas no fim é simplesmente um número qualquer que você pode arbitrar.
Assim finalizamos mais este artigo. Ao longo desta série de artigos vimos como usar python no Iris, recuperar dados armazenados no Iris para montar um dataframe, verificamos opções de modelos de ML, verificamos também opções de avaliação dos modelos, adquirimos ferramentas para análise inicial dos dados e a geração de relatórios exploratórios dos dados.
Até a próxima!