Uma introdução ao Adaptive Analytics
Introdução
O InterSystems IRIS Adaptive Analytics é uma extensão opcional que fornece uma camada de modelo de dados virtual orientada a negócios entre o InterSystems IRIS e as ferramentas de Business Intelligence (BI) e Inteligência Artificial (IA). O Adaptive Analytics é desenvolvido pela AtScale. A documentação da AtScale pode ser encontrada neste link: https://documentation.intersystems.atscale.com
Este artigo irá mostrar algumas funcionalidades do AtScane que podem facilitar a análise de dados::
- Criação do cubo
- Visualização no Excel
- Parallel Period
- Queries
- Snowflake
- Segurança
-
Aggregates (agregados)
1. Criação do cubo
Cria um cubo no AtScale é simples. Dentro do canvas do cubo, clique no botão de Data Sources, procure sua tabela de fatos (no nosso exemplo, tabela de vendas realizadas) e arreste até o canvas. A tabela de fatos será mostrada com um cabeçalho azul:
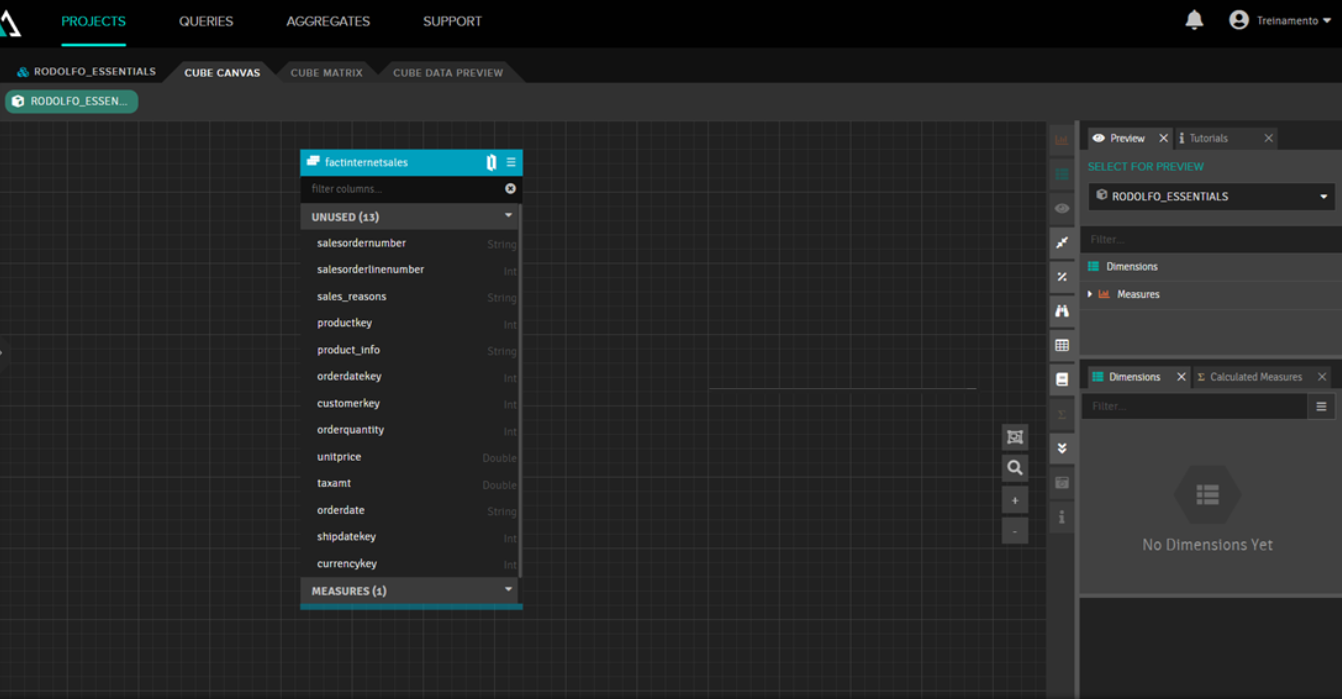
Depois disso você precisa adicionar tabelas de dimensões arrastando-as para a caixa Dimensions que está à direita e então ligá-la à tabela de fatos arrastando-e-soltando a propriedade que contém o ID do registro. Então é preciso adicionar medidas, para fazer isso basta arrastar-e-soltar os campos para a caixa Measures à direita e especificar o tipo de agregação desejada (soma, contador, média, etc). Este artigo não tem como objetivo focar nesse passao, até porque é difícil mostrar o arrastar-e-soltar por imagens, então apenas mostraremos como nosso modelo fica ao final:
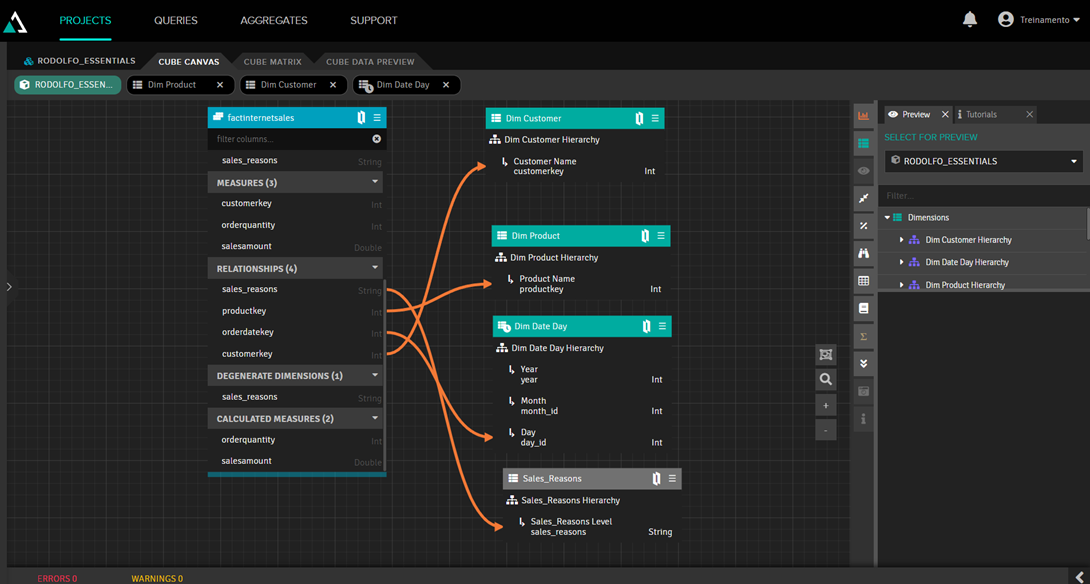
Perceba que a dimensão Sales_Reasons tem um cabeçalho cinza. Isso acontece porque ele é uma dimensão junked, que é uma dimensão criada a partir de uma propriedade da tabela de fatos que não tem relacionamento com outra tabela. Para criá-la basta arrastar-e-soltar o campo que você quer que se transforme numa dimensão em qualquer lugar em branco do canvas.
Outra observação é que adicionamos uma dimensão de calendário, que é uma tabela com dados fixos que contém todas as datas detalhadas por dia, semana, ano, semestre, etc. Nessa dimensão configuramos uma hierarquia de ano, mês e dia para criar um drilldown para o usuário. Para fazer isso, demos 2 cliques na dimensão, assim acessamos a edição da dimensão, onde informamos o ano, mês e dia na hierarquia:
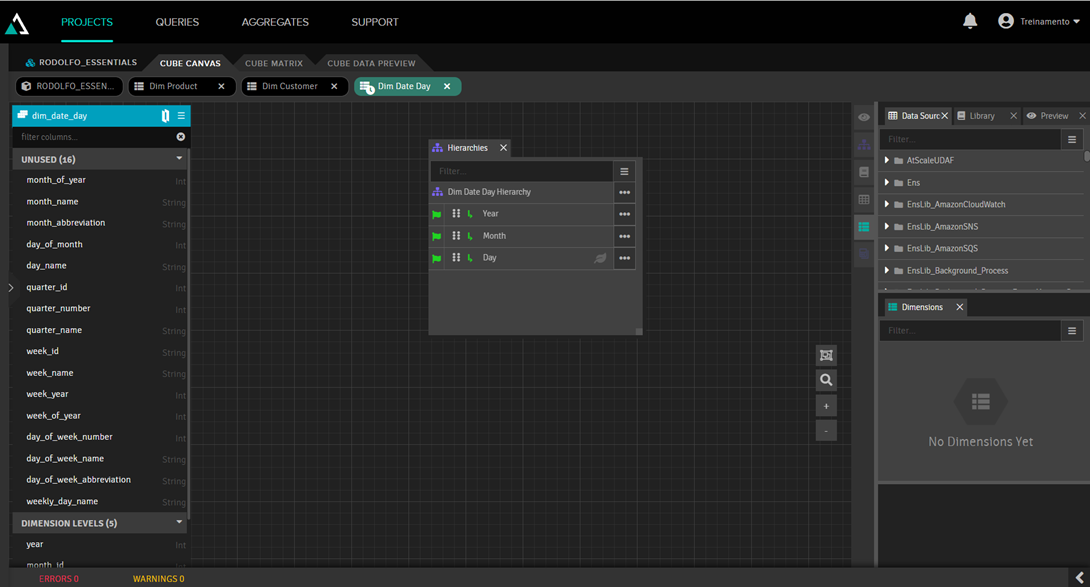
Clicando em Cube Data Preview tab, podemos ver como os dados estão:
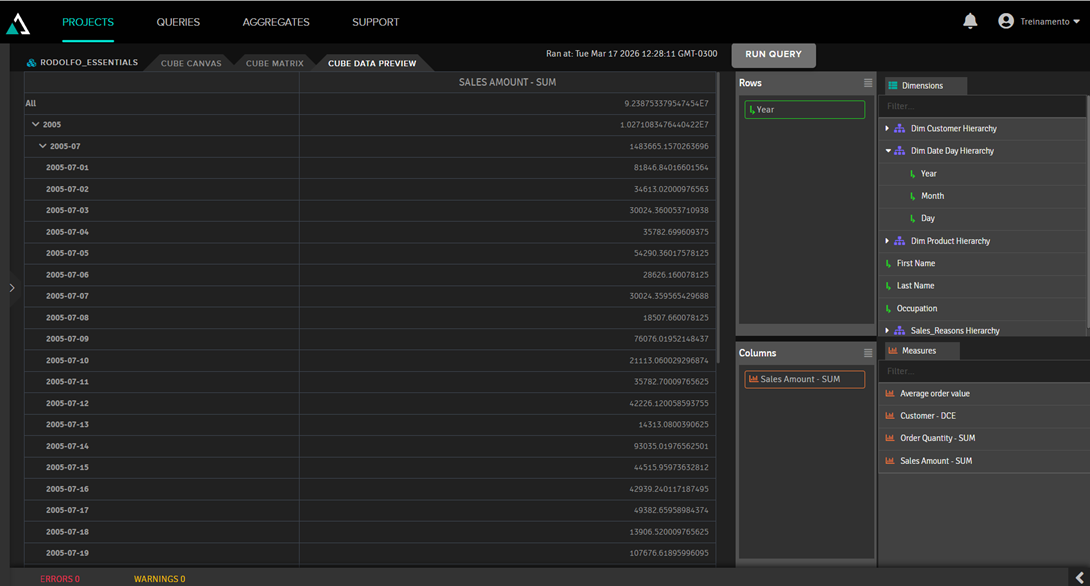
2. Visualização no Excel
Para ver dados de um aplicativo externo (Power BI, Tableau, Excel), primeiro é necessário publicar o cubo. Para fazer isso basta clicar no botão Publicar. Após isso as strings de conexão serão mostradas:
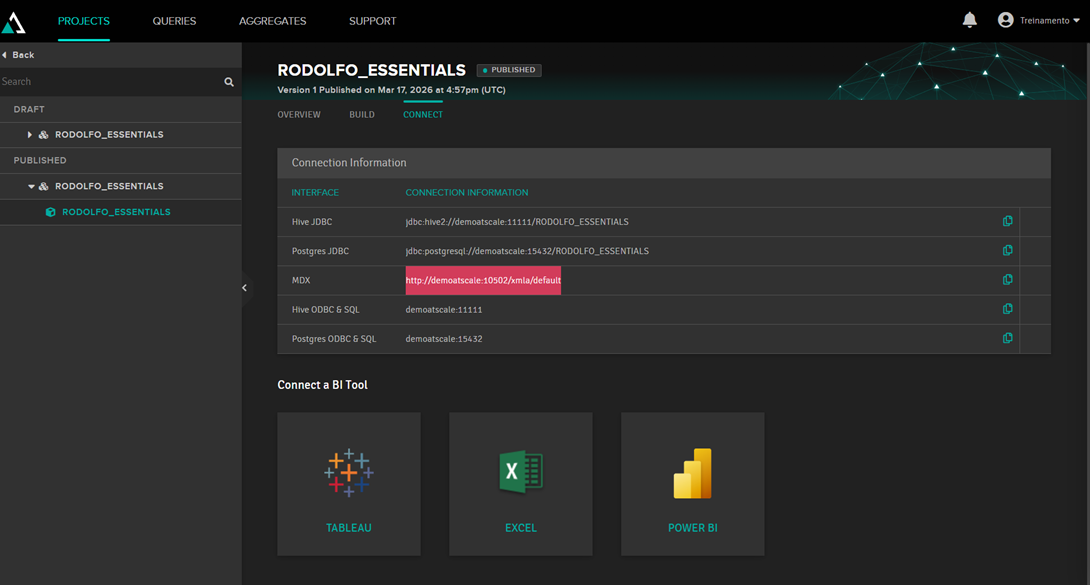
Com essa string, selecionamos a opção "From analysis server" no Excel para buscar os dados do AtScale:
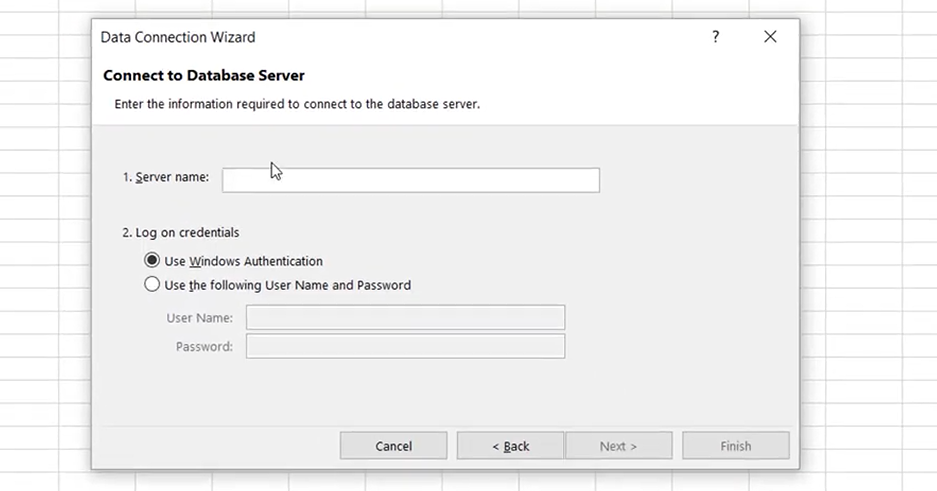
Na tela acima basta informar a string de conexão no campo Server Name e informar o usuário e senha usados no AtScale. Na próxima página selecione o cubo:
Então os dados serão mostrados como uma tabela pivot:
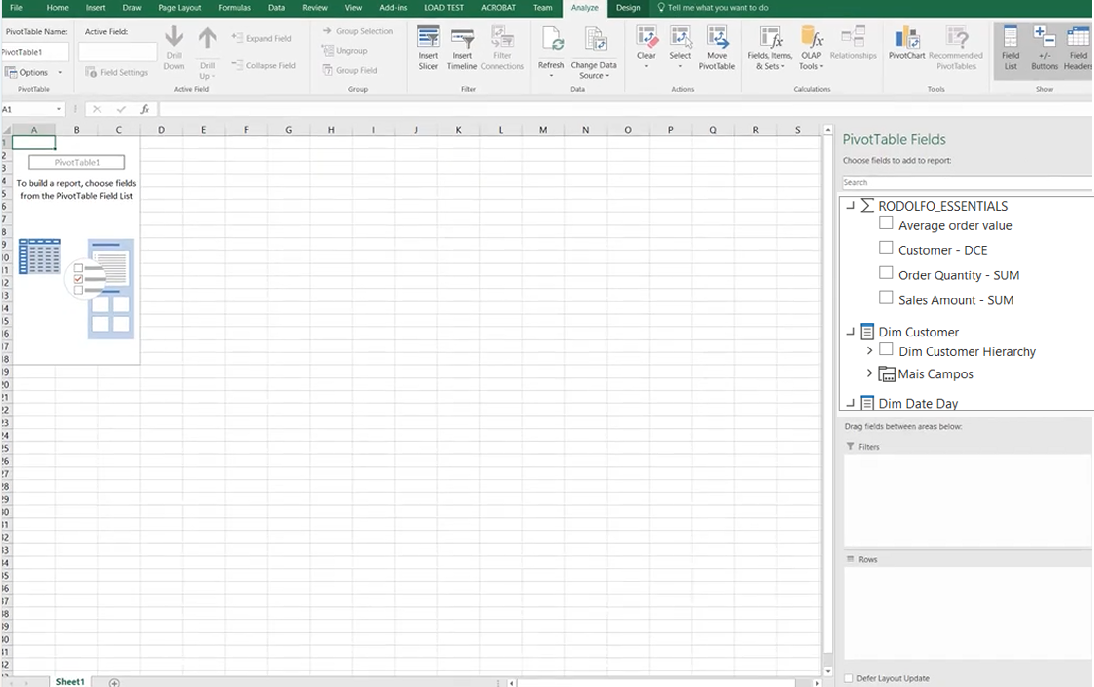
3. Parallel period
Paraller Period é uma função muito útil para comparar dados de diferentes períodos (uma situação muito comum é precisar comparar as vendas do ano atual com as do ano passado). No AtScale isso é feito adicionando uma medida calculada e usando a função ParallelPeriod desse jeito:
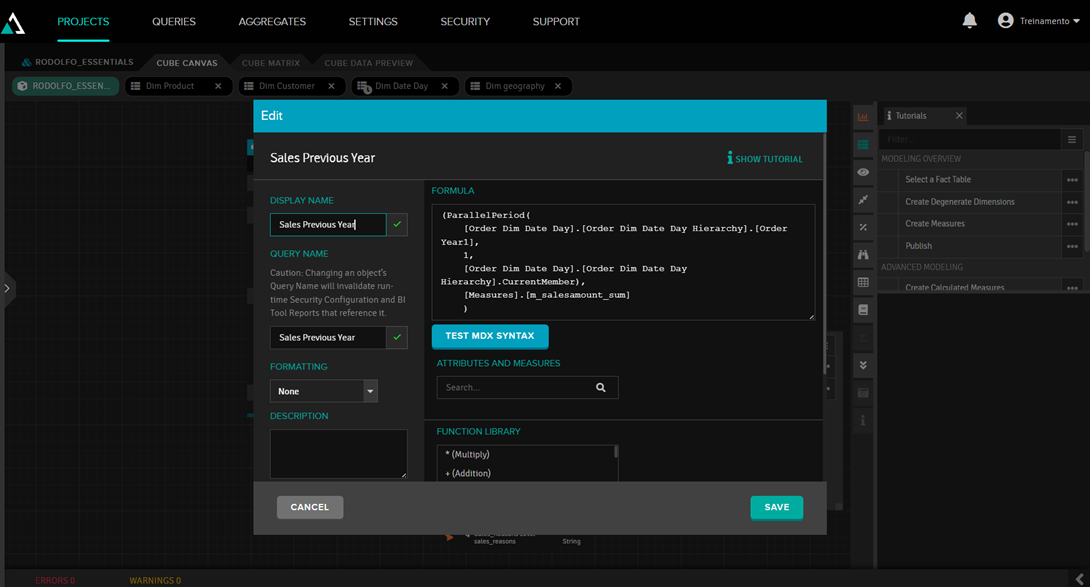
Desse modo, a medida Sales Previous Year vai mostrar valores de um ano atrás:
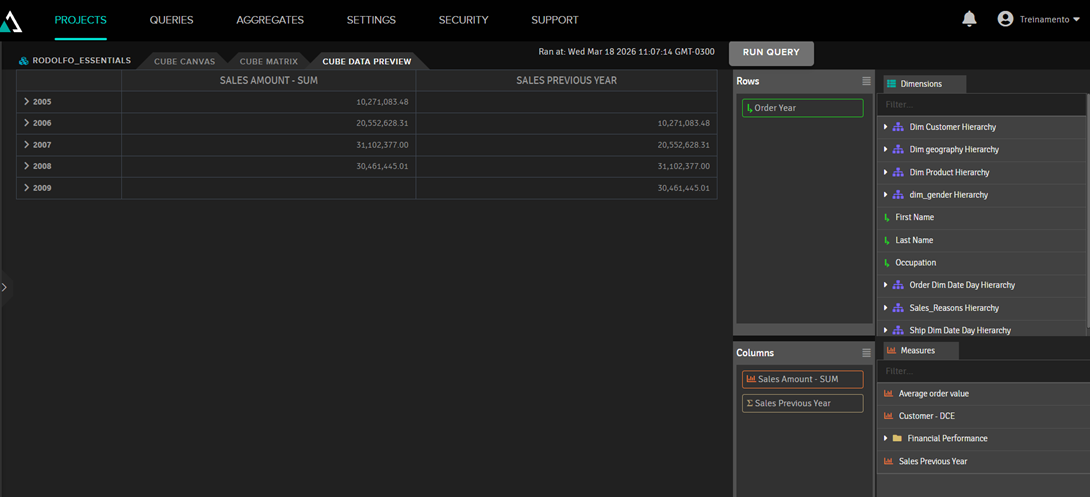
4. Queries
Na seção de Queries do AtScale nós visualizamos as queries que estão sendo executadas, tanto pode aplicativos externos quanto pelo preview do AtScale. Exemplo:
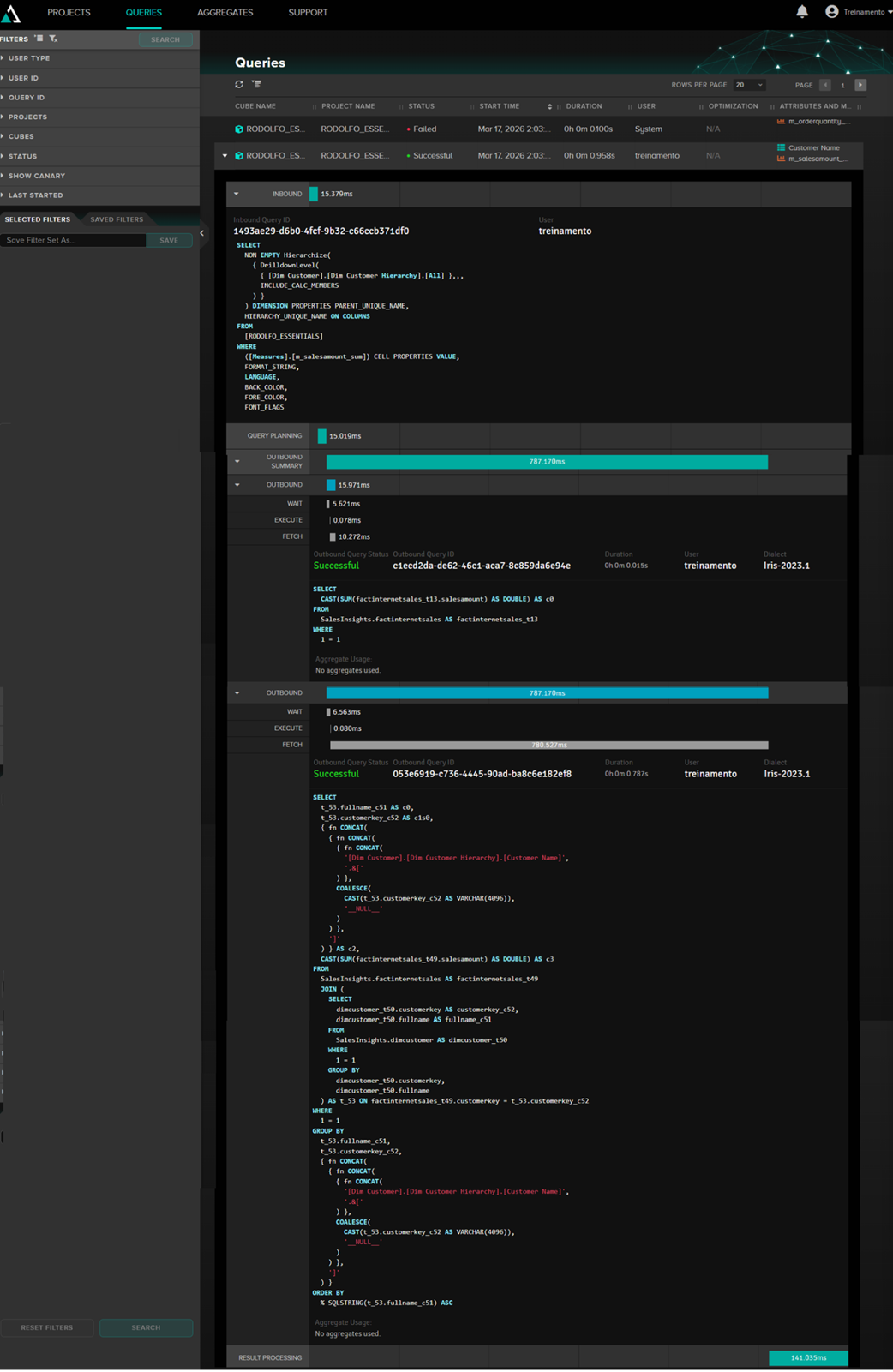
Nessa tela podemos ver a consulta MDX interna do AtScale, a consulta que é passada pro IRIS bem como os tempos de execução.
5. Snowflake
Snowflake se refere à habilidade de expandir o modelo. No exemplo abaixo nós entramos na dimensão Customer e a expandimos adicionando informação geográfica, através de uma tabela de cidades, e a informação de gênero:
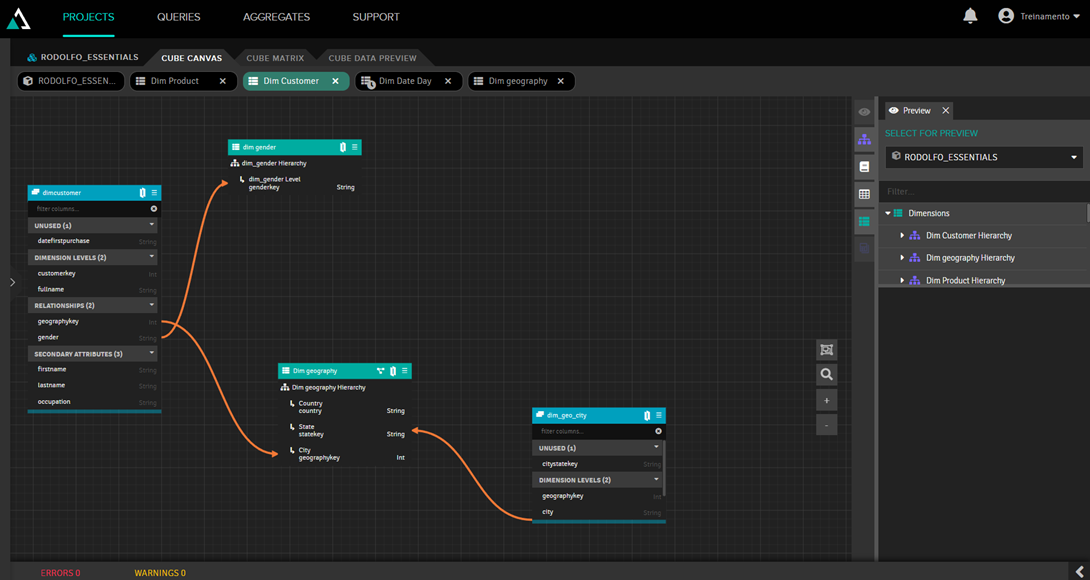
Desse modo, podemos adicionar tabelas no modelo mantendo uma organização fácil de entender.
6. Segurança
Dividiremos a parte de segurança em dois tópicos: perspectivas, que limitam quais colunas o usuário pode ver, e dimensão de segurança, que limia quais linhas o usuário pode ver.
a) Perspectivas
Perspectivas servem para definir o escopo de um cubo, caso haja usuários que não podem ver todos os dados. No exemplo abaixo, criamos uma perspectiva para o marketing. Clicando no "olho" podemos definis quais campos ele poderá ver e quais não:
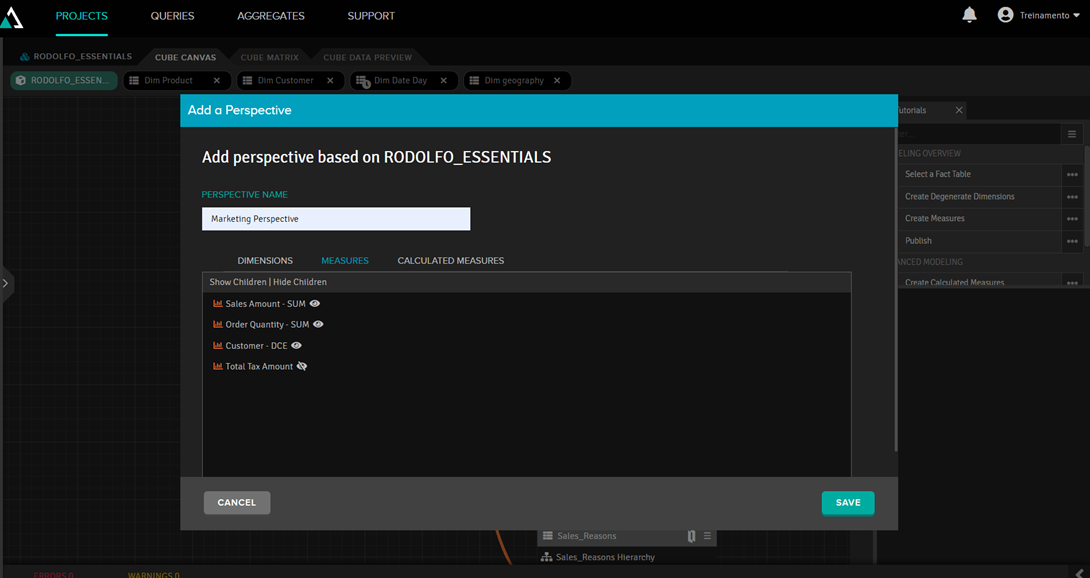
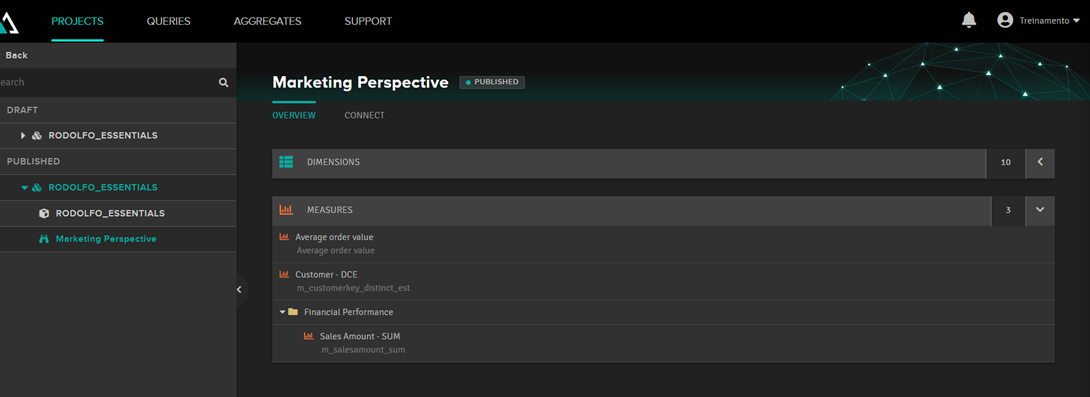
Quando publicar o cubo outro registro será criado com o nome da perspectiva e suas próprias strings de conexão:
b) Dimensão de segurança
A dimensão de segurança é aplicada nos dados como se fosse um filtro. Exemplo: usuários da Austrália só podem ver dados da Austrália.
Para fazer isso, primeiro precisamos de uma tabela que diga quais dados cada usuário pode ver. Isso pode ser uma tabela normal do banco de dados, mas no nosso caso iremos criar uma tabela fictícia usando a opção "add new dataset":
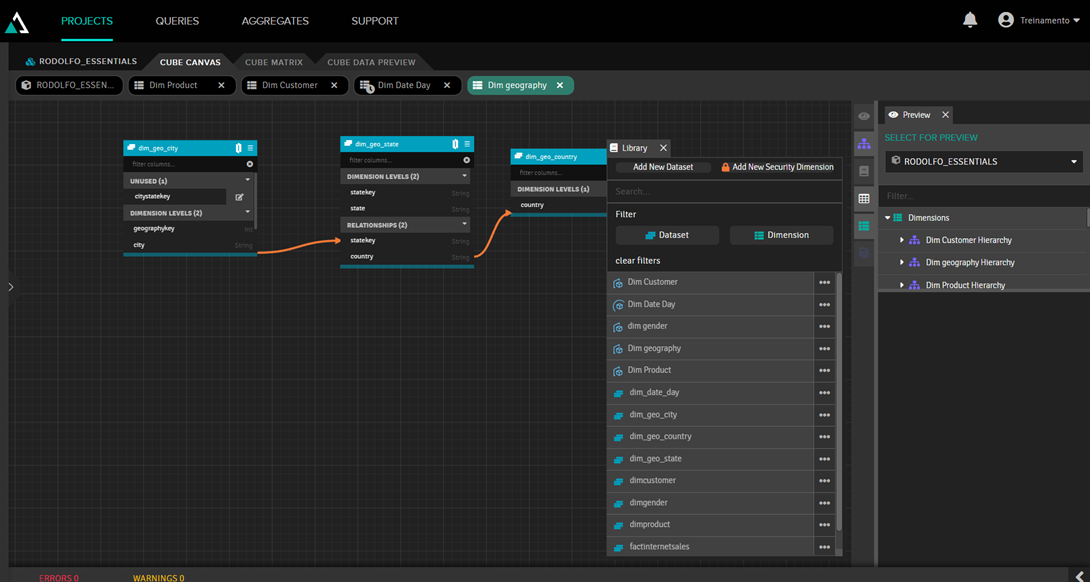
Nesse dataset, iremos digitar um SQL que traga dados fixos:
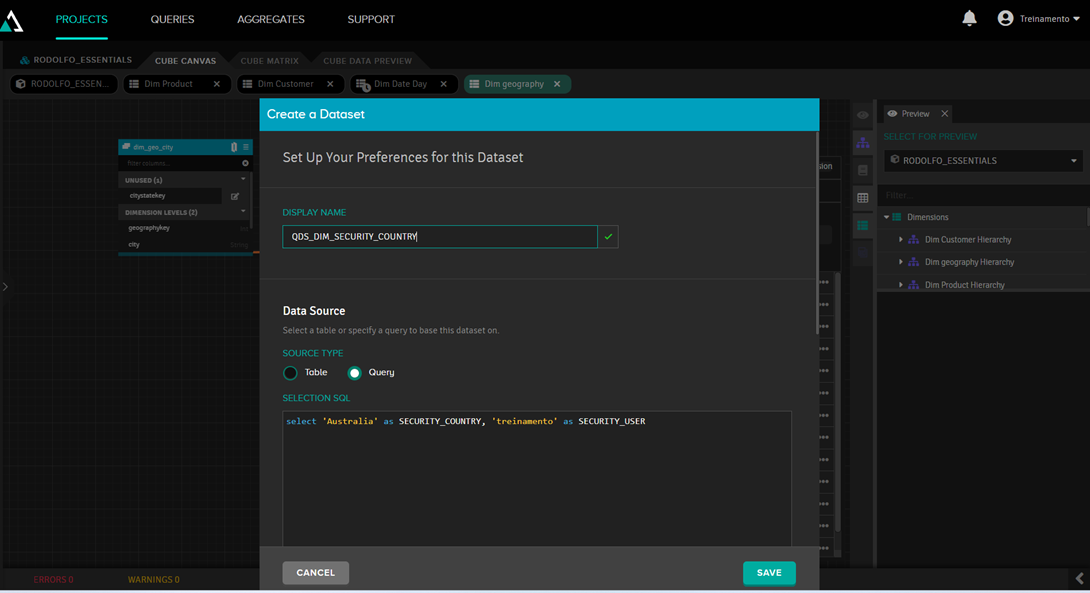
Depois disso, clique em “Add new security dimension” e informe os dados do dataset que acabamos de criar:
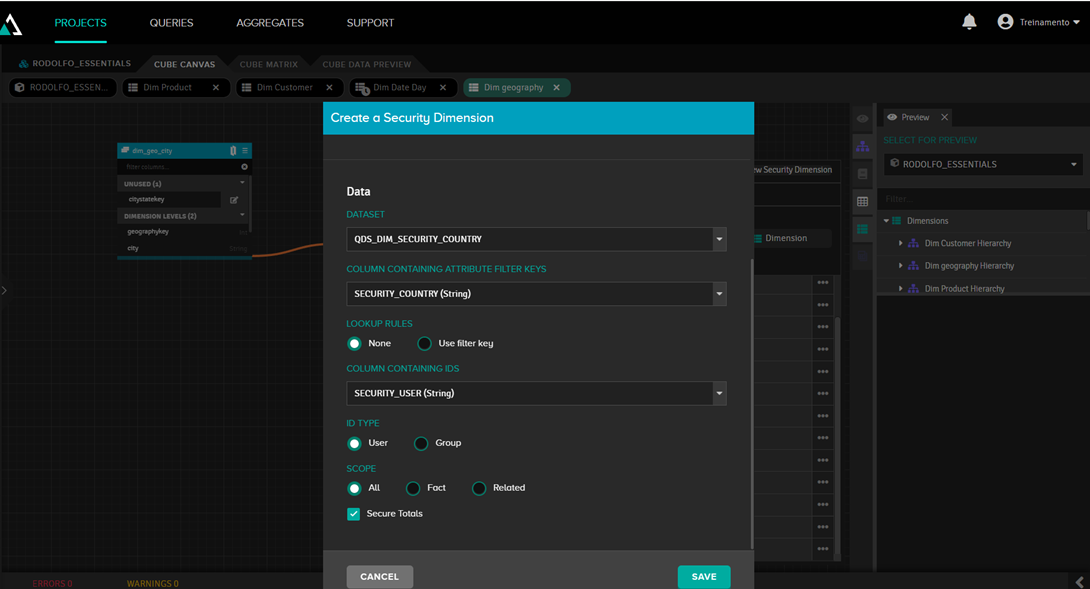
Depois ligamos o campo "country" (país) a essa dimensão, pois é o país que queremos filtrar:
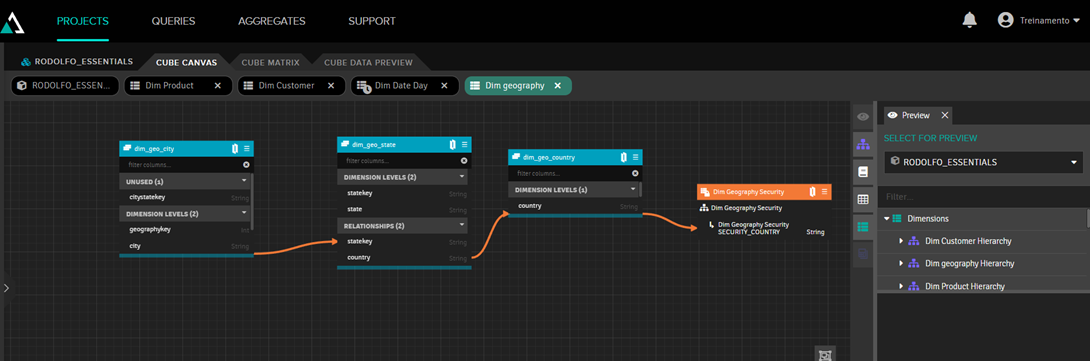
A partir de agora, quando vemos os dados no Excel com o usuário 'treinamento', vemos somente dados da Austrália:

7. Aggregates (agregados)
Aggregations no AtScale são tabelas otimizadas que contém dados pré-calculados e sumarizados (como somas, contados e médias) da tabela de fatos. Esass tabelas são desenhadas para melhorar a performance, uma vez que o AtScale pode ler esses dados já sumarizados ao invés de processar bilhões de linhas da tabela de fatos.
Na aba Aggregates podemos ver as tabelas de agregações:
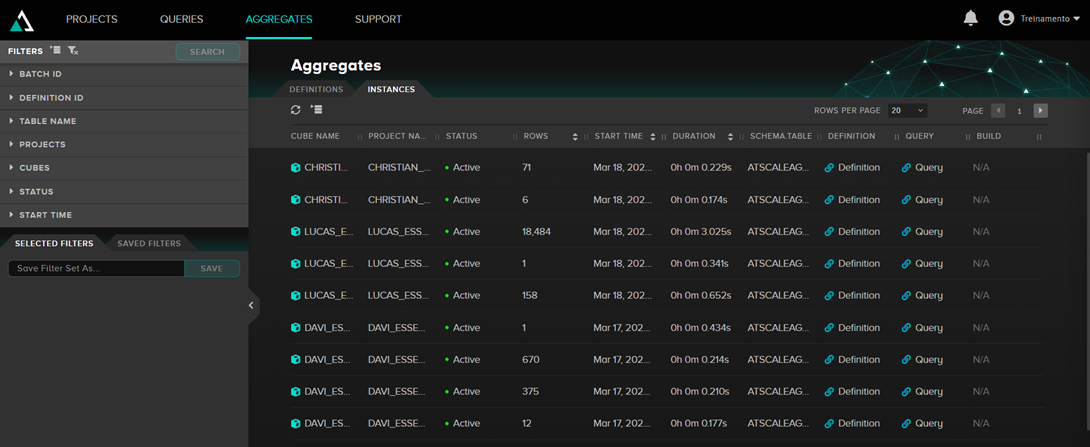
Quando o AtScale está usando agregações, podemos ver na query que ele está executando que está lendo dados de tabelas que começam com ATSCALEAGG.as_agg_xxxx.
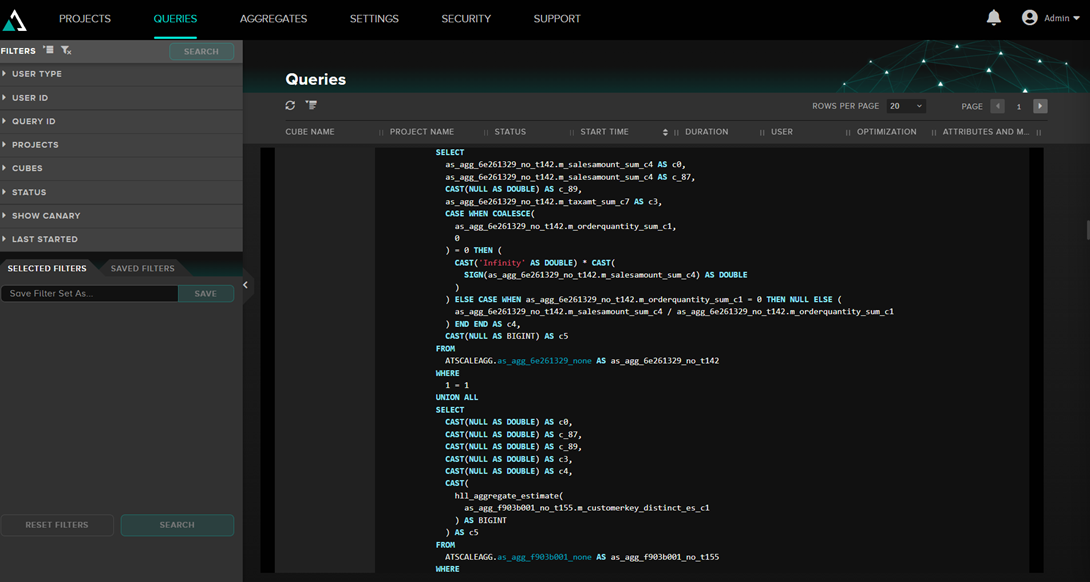
Essas tabelas de agregações são armazenadas no IRIS. Nas configurações do AtScale é possível informar em qual pacote elas ficarão (no exemplo acima é ATSCALEAGG) e até determinar se queremos que elas sejam armazenadas num namespace ou instância diferente de IRIS.
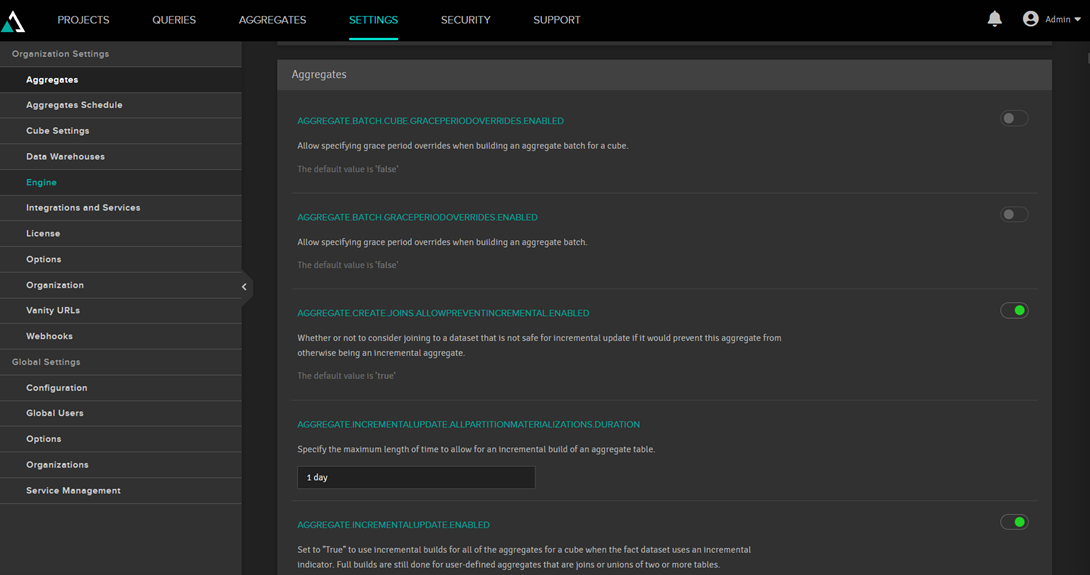
O AtScale é quem decide se cria ou não agregações. O critério mais importante é se a tabela de agregação será mesmo menos que a de fatos. Por padrão o AtScale usa um fator de 3, ou seja, se a tabela de agregação for mais que 3 vezes menos ele cria. Isso não é fixo, pode ser alterado nas configurações do AtScale:.
a) Atualizando os aggregates
As tabelas de agregação devem ser atualizadas periodicamente para refletir as mudança na tabela de fatos.Por padrão isso é feito uma vez por dia, conforme configuração:
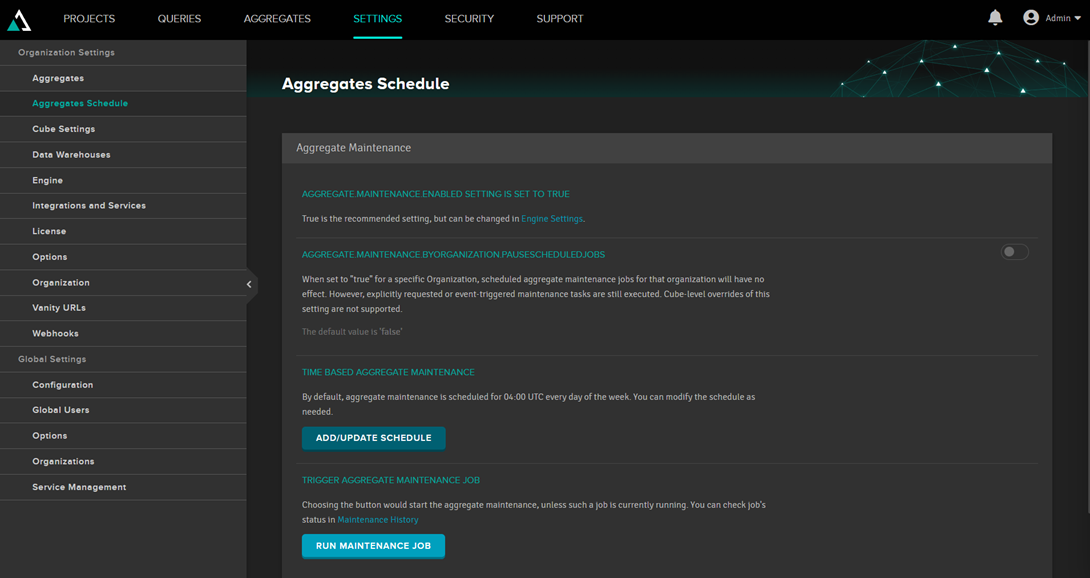
Também é possível criar agendamentos para atualizar:
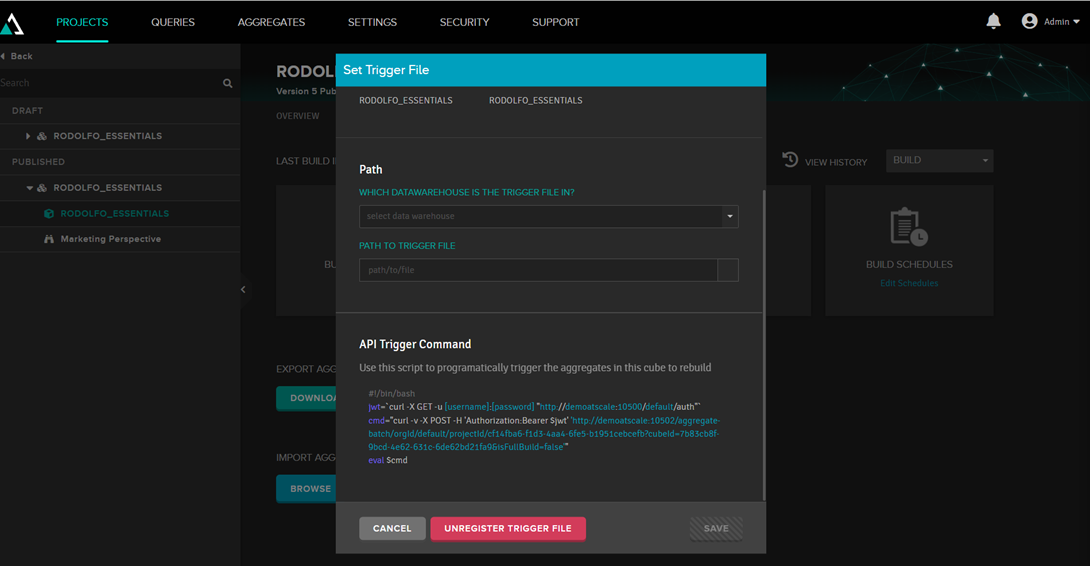
Ou chamar uma trigger para fazer a atualizar, assim um programa externo pode invocar a atualização:
Conclusão
Espero que esse artigo tenha mostrado algumas das funcionalidades do Adaptive AnaIytics, ajudando a mostrar as capacidades que essa ferramenta oferece.