Machine Learning no IRIS usando a API HuggingFace e/ou modelos de ML no local
Neste GitHub, você pode encontrar todas as informações sobre como usar um modelo de machine learning / IA do HuggingFace no Framework IRIS usando python.

1. iris-huggingface
Uso de modelos de machine learning no IRIS usando Python. Para modelos text-to-text, text-to-image e image-to-image.
Modelos de exemplo:
2. Instalação
2.1. Iniciando a produção
Na pasta iris-local-ml, abra um terminal e insira:
docker-compose up
Na primeira vez, pode levar alguns minutos para criar a imagem corretamente e instalar todos os módulos necessários para o Python.
2.2. Acesse a produção
Seguindo este link, acesse a produção: Acesse a produção
2.3. Encerrando a produção
docker-compose down
Como funciona
Por enquanto, alguns modelos talvez não funcionem com essa implementação, já que tudo é feito automaticamente, ou seja, não importa o modelo de entrada, tentaremos fazer com que funcione usando a biblioteca transformers pipeline.
Pipeline é uma ferramenta poderosa da equipe HuggingFace que analisa a pasta em que o modelo foi baixado e entende qual biblioteca deve usar entre PyTorch, Keras, Tensorflow ou JAX. Em seguida, ela carrega esse modelo usando AutoModel.
Então, ao inserir a tarefa, o pipeline sabe o que fazer com o modelo, tokenizer ou até extrator de características nessa pasta e gerencia a entrada automaticamente, tokeniza, processa, transfere para o modelo e retorna um resultado decodificado que podemos usar diretamente.
3. API do HuggingFace
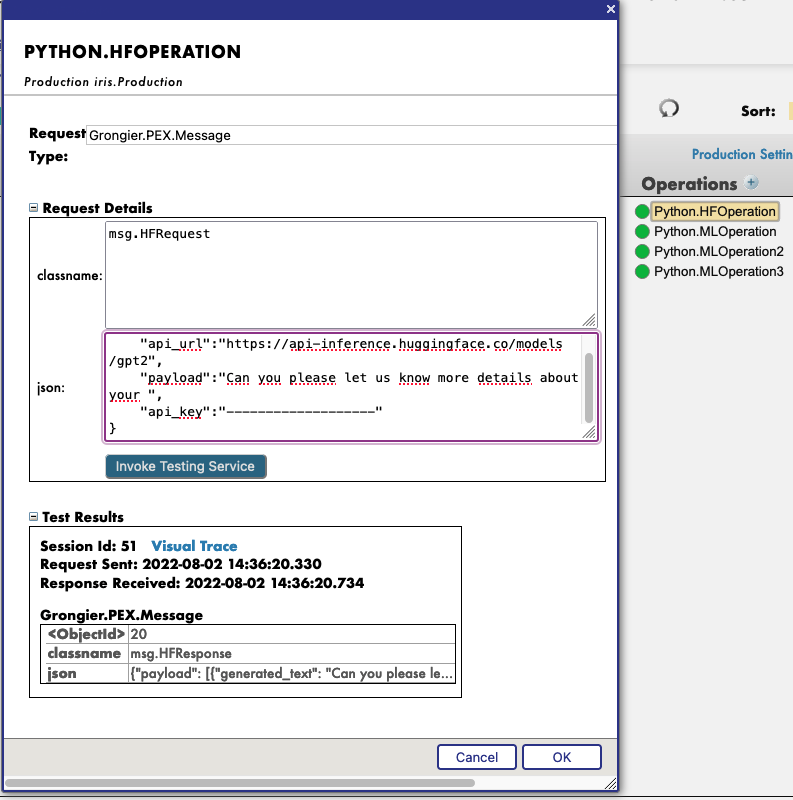
Primeiro, você precisa iniciar a demonstração, usando o botão verde Start, ou use Stop e Start novamente para aplicar as mudanças nas configurações.
Em seguida, ao clicar na operação Python.HFOperation escolhida e selecionar na guia à direita action, você pode aplicar test à demonstração.
Na janela de test, selecione:
Tipo de solicitação: Grongier.PEX.Message
Em classname, insira:
msg.HFRequest
Para json, veja um exemplo de uma chamada para GPT2:
{
"api_url":"https://api-inference.huggingface.co/models/gpt2",
"payload":"Can you please let us know more details about your ",
"api_key":"----------------------"
}
Agora, você pode clicar em Visual Trace para ver nos detalhes o que aconteceu e visualizar os registros.
OBSERVE que você precisa ter uma chave de API do HuggingFace antes de usar essa Operação (as chaves de API são gratuitas, basta fazer a inscrição na HF)
OBSERVE que você pode mudar o URL para testar outros modelos do HuggingFace. Talvez seja necessário mudar o payload.
Veja este exemplo:
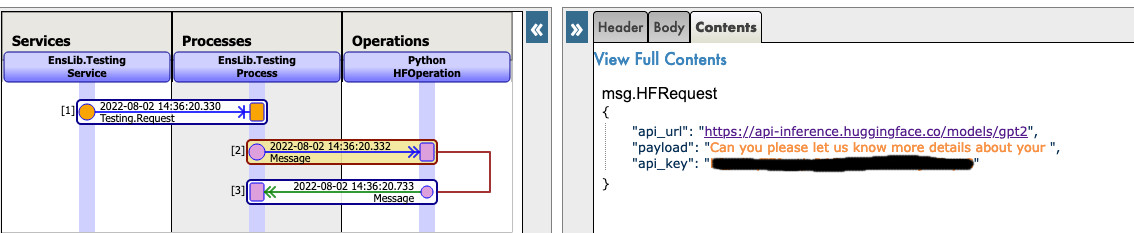

4. Use qualquer modelo da web
Nesta seção, vamos ensinar você a usar praticamente qualquer modelo da internet, HuggingFace ou não.
4.1. PRIMEIRO CASO: VOCÊ TEM SEU PRÓPRIO MODELO
Nesse caso, você precisa copiar e colar seu modelo, com config, tokenizer.json etc. dentro de uma pasta na pasta do modelo.
Caminho: src/model/yourmodelname/
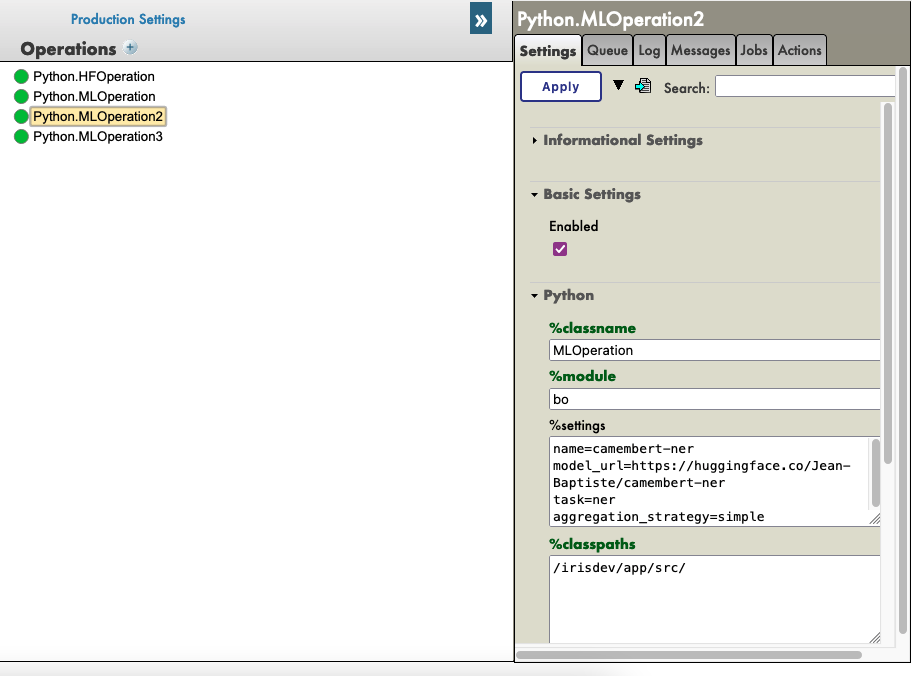
Depois, você precisa acessar os parâmetros de Python.MLOperation.
Clique em Python.MLOperation e vá para settings na guia à direita. Depois, na parte Python e na parte %settings.
Aqui, você pode inserir ou modificar quaisquer parâmetros (não se esqueça de pressionar apply depois de terminar).
Veja a configuração padrão para esse caso:
%settings
name=yourmodelname
task=text-generation
OBSERVE que qualquer configuração que não for name ou model_url entrará nas configurações PIPELINE.
Agora você pode clicar duas vezes na operação Python.MLOperation e executar o start.
Você precisa ver na parte Log a inicialização do modelo.
Em seguida, criamos um PIPELINE utilizando transformers que usam o arquivo config na pasta como vimos antes.
Para chamar esse pipeline, clique na operação Python.MLOperation e selecione action na guia à direita. Você pode aplicar test à demonstração.
Na janela de test, selecione:
Tipo de solicitação: Grongier.PEX.Message
Em classname, insira:
msg.MLRequest
Para json, você precisa inserir todos os argumentos necessários para o modelo.
Aqui está um exemplo de uma chamada para GPT2:
{
"text_inputs":"Unfortunately, the outcome",
"max_length":100,
"num_return_sequences":3
}
Clique em Invoke Testing Service (Invocar serviço de teste) e aguarde a operação do modelo.
Veja este exemplo:

Agora, você pode clicar em Visual Trace para ver nos detalhes o que aconteceu e visualizar os registros.
Veja este exemplo:

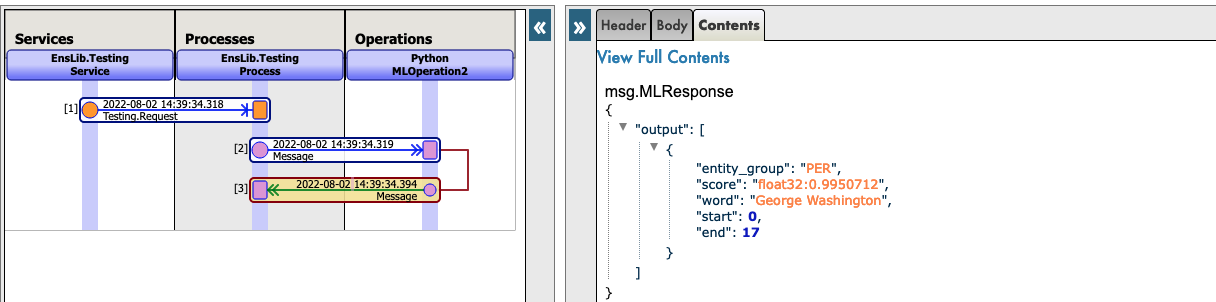
4.2. SEGUNDO CASO: VOCÊ QUER BAIXAR UM MODELO DO HUGGINGFACE
Nesse caso, você precisa encontrar o URL do modelo no HuggingFace.
4.2.1. Configurações
Depois, você precisa acessar os parâmetros de Python.MLOperation.
Clique em Python.MLOperation e vá para settings na guia à direita. Depois, na parte Python e na parte %settings.
Aqui, você pode inserir ou modificar quaisquer parâmetros (não se esqueça de pressionar apply depois de terminar).
Veja um exemplo de configuração para alguns modelos que encontramos no HuggingFace:
%settings para gpt2
model_url=https://huggingface.co/gpt2
name=gpt2
task=text-generation
%settings para camembert-ner
name=camembert-ner
model_url=https://huggingface.co/Jean-Baptiste/camembert-ner
task=ner
aggregation_strategy=simple
%settings para bert-base-uncased
name=bert-base-uncased
model_url=https://huggingface.co/bert-base-uncased
task=fill-mask
%settings para detr-resnet-50
name=detr-resnet-50
model_url=https://huggingface.co/facebook/detr-resnet-50
task=object-detection
%settings para detr-resnet-50-protnic
name=detr-resnet-50-panoptic
model_url=https://huggingface.co/facebook/detr-resnet-50-panoptic
task=image-segmentation
OBSERVE que qualquer configuração que não for name ou model_url entrará nas configurações PIPELINE. Então, no segundo exemplo, o pipeline camembert-ner requer a especificação de aggregation_strategy e task, enquanto gpt2 requer apenas uma task.
Veja este exemplo:
Agora você pode clicar duas vezes na operação Python.MLOperation e executar o start.
Você precisa ver na parte Log a inicialização e o download do modelo.
OBSERVAÇÃO Você pode atualizar esses logs a cada x segundos para ver o avanço dos downloads.

Em seguida, criamos um PIPELINE utilizando transformers que usam o arquivo config na pasta como vimos antes.
4.2.2. Testes
Para chamar esse pipeline, clique na operação Python.MLOperation e selecione action na guia à direita. Você pode aplicar test à demonstração.
Na janela de test, selecione:
Tipo de solicitação: Grongier.PEX.Message
Em classname, insira:
msg.MLRequest
Para json, você precisa inserir todos os argumentos necessários para o modelo.
Aqui está um exemplo de uma chamada para GPT2 (Python.MLOperation):
{
"text_inputs":"George Washington lived",
"max_length":30,
"num_return_sequences":3
}
Aqui está um exemplo de uma chamada para Camembert-ner (Python.MLOperation2):
{
"inputs":"George Washington lived in washington"
}
Aqui está um exemplo de uma chamada para bert-base-uncased (Python.MLOperation3):
{
"inputs":"George Washington lived in [MASK]."
}
Aqui está um exemplo de uma chamada para detr-resnet-50 usando um URL online (Python.MLOperationDETRRESNET):
{
"url":"http://images.cocodataset.org/val2017/000000039769.jpg"
}
Aqui está um exemplo de uma chamada para detr-resnet-50-panoptic usando um URL como caminho (Python.MLOperationDetrPanoptic):
{
"url":"/irisdev/app/misc/000000039769.jpg"
}
Clique em Invoke Testing Service (Invocar serviço de teste) e aguarde a operação do modelo.
Agora, você pode clicar em Visual Trace para ver nos detalhes o que aconteceu e visualizar os registros.
OBSERVE que, após fazer pela primeira vez o download de um modelo, a produção não fará o download novamente, mas usará os arquivos em cache encontrados em src/model/TheModelName/.
Se alguns arquivos estiverem ausentes, a Produção fará o download novamente.
Veja este exemplo:
Veja este exemplo:


5. Solução de problemas
Se você tiver problemas, a leitura é o primeiro conselho que podemos dar a você. A maioria dos erros são facilmente compreendidos apenas ao ler os logs, pois quase todos os erros são capturados por um try/catch e registrados.
Se você precisar instalar um novo módulo ou dependência do Python, abra um terminal dentro do contêiner e digite, por exemplo: "pip install new-module"
Há várias formas de abrir um terminal,
- Se você usa os plugins da InterSystems, pode clicar na barra abaixo no VSCode, que se parece com
docker:iris:52795[IRISAPP], e selecionarOpen Shell in Docker(Abrir Shell no Docker). - Em qualquer terminal local, digite:
docker-compose exec -it iris bash - No Docker-Desktop, encontre o contêiner IRIS e clique em
Open in terminal(Abrir no terminal)
Alguns modelos talvez exijam algumas alterações no pipeline ou nas configurações, por exemplo. É sua responsabilidade adicionar as informações corretas nas configurações e na solicitação.
6. Conclusão
Depois disso, você poderá usar qualquer modelo que de precisa ou possui no IRIS.
OBSERVE que você pode criar uma Python.MLOperation para cada um dos seus modelos e ter todos ativados ao mesmo tempo.