IRIS AI Studio: Conectores para transformar seus arquivos em vetores incorporados para capacidades do GenAI
No artigo anterior, vimos diferentes módulos do Studio IRIS AI e como ele poderia ajudar a explorar as capacidades da GenAI além do IRIS DB perfeitamente, mesmo para alguém não técnico. Nesse artigo, vamos mergulhar a fundo pelo módulo "Connectors", o que permite que os usuários carreguem dados desde uma fonte local ou cloud (AWS S3, Airtable, Azure Blob) no IRSI DB como vetores incorporados, ao configurar também definições de incorporação como modelo e dimensões.
Novas Atualizações ⛴️
- Demo Online da aplicação está disponível agora emt https://iris-ai-studio.vercel.app
- Módulo de Connectors module agora podem carregar dados de (incorporações OpenAI/Cohere)
- Armazenamento Local
- AWS S3
- Armazenamento Azure Blob
- Airtable
- Módulo Playground é totalmente funcional com
- Procura Semântica
- Chat with Docs (Conversa com Docs)
- Máquina de recomendação
- Cohere Re-rank
- OpenAI Re-rank
- Máquina de Similaridades
Connectors
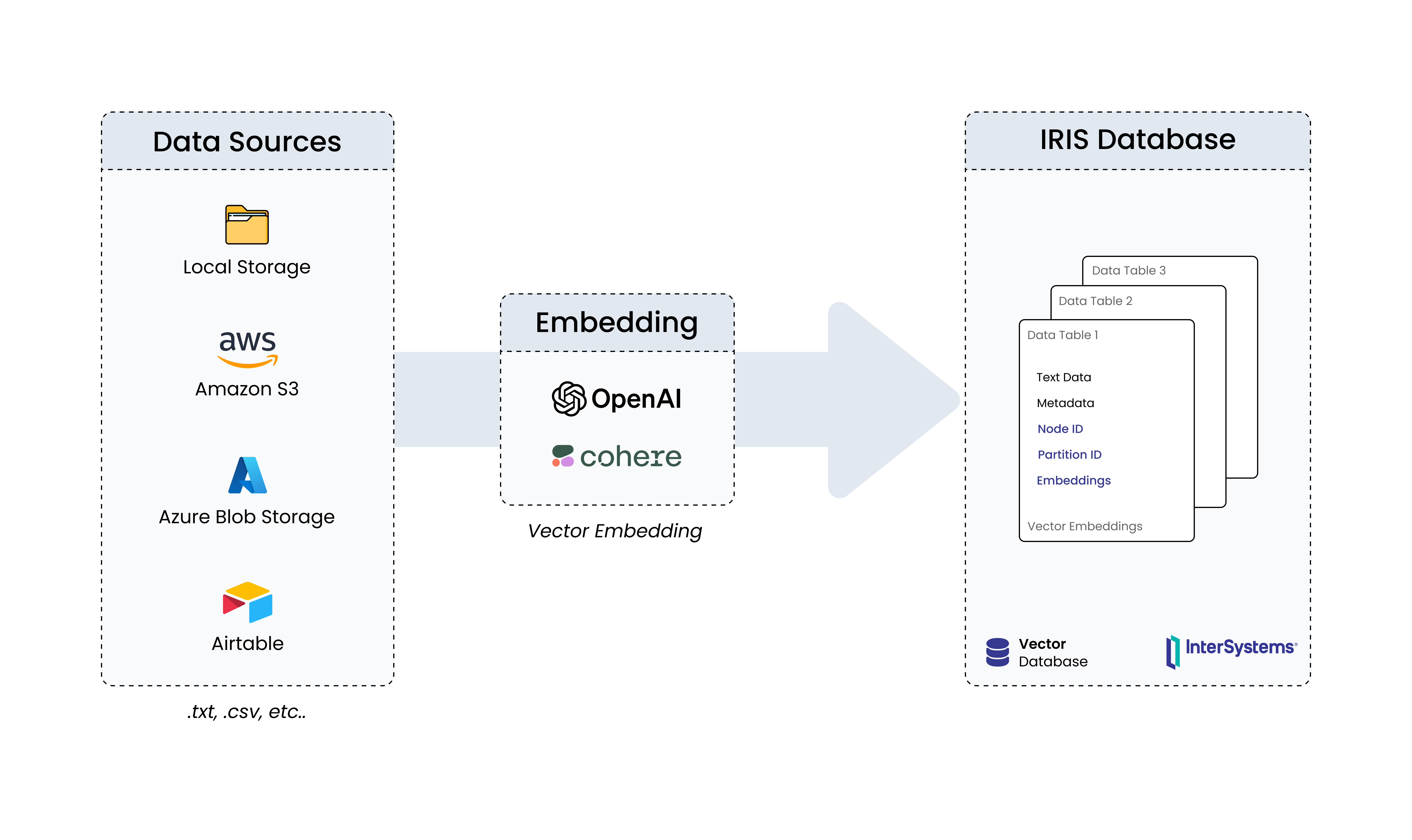
Se você já usou o ChatGPT 4 ou outros serviços LLM (Large Language Model - Grandes modelos de linguagem) onde se usa a inteligência a partir de um contexto, isso idealmente adiciona valor de negócio sobre uma LLM genérica. Esse módulo oferece uma interface fora da caixa e no-code (sem código) para carregar dados de diferentes fontes, realiza incorporações neles e os carrega na IRIS DB. Esse módulo de conectores passam por 3 passos num geral.
- Buscar dados de fontes diferentes
- Pegar os dados incorporados usando modelos de incorporação OpenAI/Cohere
- Carregar as incorporações e texto dentro da IRIS DB
Passo 1: Buscando dados de diferentes fontes
1. Armazenamento Local - Subir arquivos. Eu usei os Indexes Llama do SimpleDirectoryReader para carregar dados dos arquivos.
(uma limitação de um máximo de 10 arquivos é usada para sustentar o carregamento no pequeno servidor usado para fins de demonstração. Isso pode ser negad na sua implementação.)
# Checa por arquivos carregados
if "files" not in request.files:
return jsonify({"error": "No files uploaded"}), 400
uploaded_files = request.files.getlist("files")
if len(uploaded_files) > 10:
return jsonify({"error": "Exceeded maximum file limit (10)"}), 400
temp_paths = []
for uploaded_file in uploaded_files:
fd, temp_path = tempfile.mkstemp()
with os.fdopen(fd, "wb") as temp:
uploaded_file.save(temp)
temp_paths.append(temp_path)
# Carrega dados dos arquivos
documents = SimpleDirectoryReader(input_files=temp_paths).load_data()
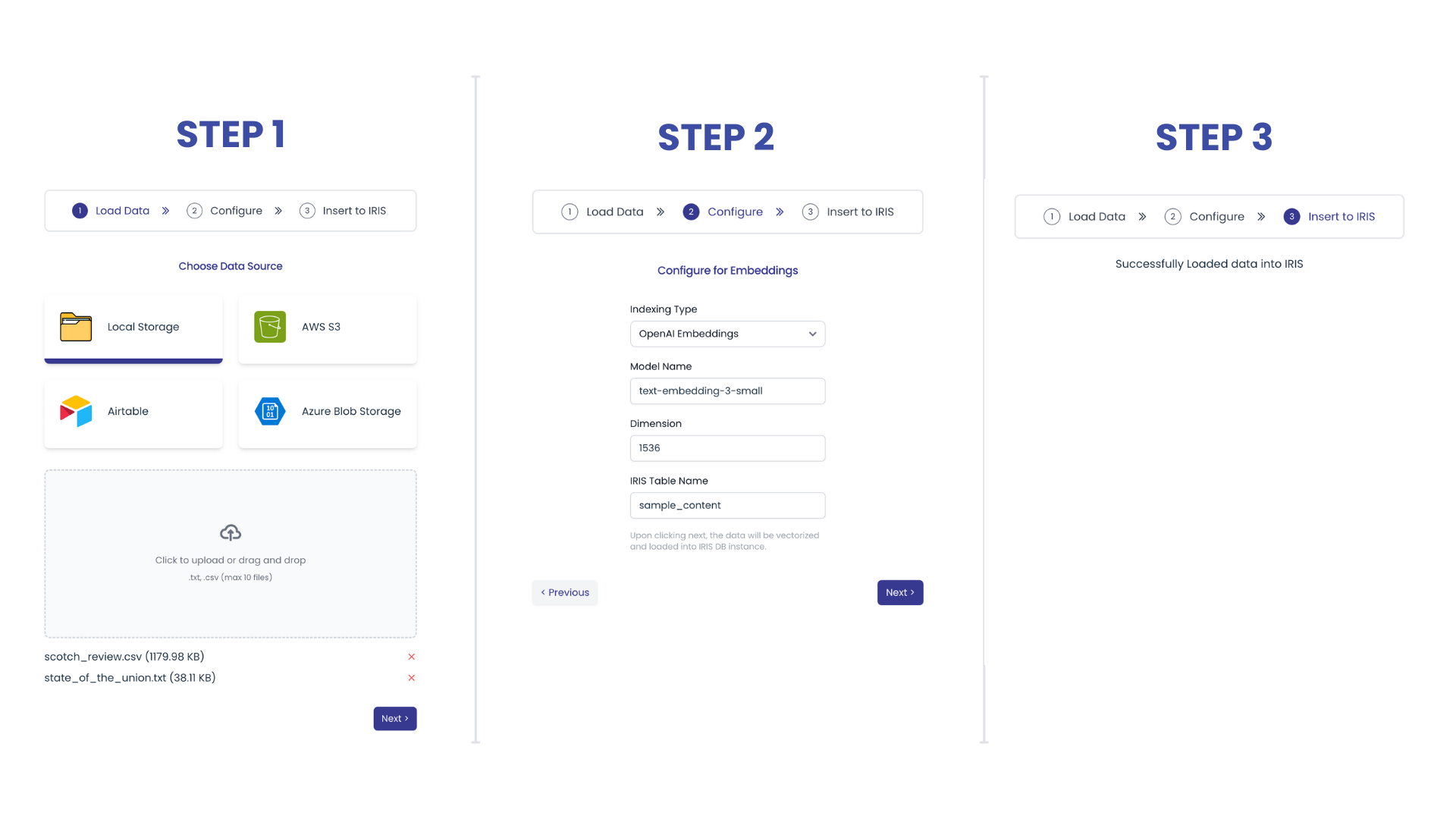 2. AWS S3
2. AWS S3
Parâmetros de Entrada: Client ID, Client Secret e Bucket Name. Você pode buscar o ID do cliente e o segredo da console AWS - IAM ou criando permissões de leitura para seu bucket do lado de lá.
Eu usei a livraria "s3fs" para buscar o conteúdo do AWS S3 e os Index Llama SimpleDirectoryReader para carregar os dados dos arquivos obtidos.
access_key = request.form.get('aws_access_key')
secret = request.form.get('aws_secret')
bucket_name = request.form.get('aws_bucket_name')
if not all([access_key, secret, bucket_name]):
return jsonify({"error": "Missing required AWS S3 parameters"}), 400
s3_fs = S3FileSystem(key=access_key, secret=secret)
reader = SimpleDirectoryReader(input_dir=bucket_name, fs=s3_fs, recursive=True)
documents = reader.load_data()
3. Airtable
Parâmetros de Input: Token (API Key), Base ID e Table ID. A Chave API pode ser recuperada do Airtable's Developer Hub. O Base ID e o Table ID podem ser achados da URL da tabela. A que começa com "app..." é o Base ID e a que começa com "tbl..." é o Table ID.
Eu usei o Airtable Reader do LlamaHub para buscar os conteúdos do Airtable e o Index do Llama SimpleDirectoryReader para carregar dados dos arquivos buscados.
airtable_token = request.form.get('airtable_token')
table_id = request.form.get('table_id')
base_id = request.form.get('base_id')
if not all([airtable_token, table_id, base_id]):
return jsonify({"error": "Missing required Airtable parameters"}), 400
reader = AirtableReader(airtable_token)
documents = reader.load_data(table_id=table_id, base_id=base_id)
.png)
4. Armazenamento Azure Blob:
Parâmetros de entrada: Nome do Container e String de Conexão. Essas informações podem ser recuperadas da página Azure's AD.
I have used AzStorageBlob Reader from LlamaHub to fetch the contents from Azure Storage and Llama Index's SimpleDirectoryReader to load data from the fetched files.
container_name = request.form.get('container_name')
connection_string = request.form.get('connection_string')
if not all([container_name, connection_string]):
return jsonify({"error": "Missing required Azure Blob Storage parameters"}), 400
loader = AzStorageBlobReader(
container_name=container_name,
connection_string=connection_string,
)
documents = loader.load_data()O LlamaHub contem mais de 500 conectores desde tipos diferentes tipos de arquivos até serviços. Adicionar um novo conector baseado nas suas necessidades deve ser bastante simples.
Passo 2: Buscando os dados incorporados usando modelos de incorporação OpenAI/Cohere
Incorporações são representações numéricas que capturam a semântica do texto, permitindo aplicações como pesquisa e correspondência por similaridade. Idealmente o objetivo é, quando um usuário faz uma pergunta, sua incorporação é comparada com as incorporações de documentos usando métodos como similaridade de cosseno - maior similaridade indica maior conteúdo relevante.
Aqui, estou usando a livraria llama-iris para armazenar incorporações na IRIS DB. Na IRISVectorStore, parâmetors
- Connection String é necess´rio para interação com a DB (database - base de dados)
- Para testar na versão de demonstração online, você não poderá usar uma instância local (localhost).
- Você precisaria de uma instância IRIS que rode em AWS/Azure/GCP com versão 2024.1+ , já que essas suportam armazenamento e recuperação de vetores.
- A instância de comunidade IRIS, fornecida pelo learning hub parece estar rodando com a versão 2022.1, então não pode ser usada para explorações aqui.purpose.
- Table Name é o que será usado para criar ou atualizar os registros.
- A livraria "llama-iris" acrescenta "data_" ao começo do nome da tabela. Então, quando estiver tentando checar os dados por meio de um cliente DB, acrescente "data_" ao começo do nome da tabela. Por exemplo, se você nomeou uma tabela como "usuarios", você terá que recuperar como "data_usuarios".
- Embed Dim / Embedding Dimension é a dimensão do modelo de incorporação que o usuário utilizou
- Digamos que você tenha carregado a tabela "usuarios" usando incorporações OpenAI - "text-embedding-3-small", com dimensão 1536 . Você seria capaz de carregar mais dados na tabela, mas apenass com dimensão 1536. O mesmo ocorre com recuperações de incorporações também. Então, tenha certeza de escolher o modedlo correto nas fases iniciais.
CONNECTION_STRING = f"iris://{username}:{password}@{hostname}:{port}/{namespace}"
vector_store = IRISVectorStore.from_params(
connection_string=CONNECTION_STRING,
table_name=table_name,
embed_dim=embedding_dimension
)
Settings.embed_model = set_embedding_model(indexing_type, model_name, api_key)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents,
storage_context=storage_context
)
Passo 3: Carregando a incorporação e texto na IRIS DB
O código escrito acima cobre a indexação e carregamento de dados dentro da IRIS DB. Essa deve ser a aparência dos dados:
.png)
Text - Informação em texto puro que foi extraída dos arquivos que carregamos
Node ID - Isso seria utilizado como referência quando fazemos recuperações
Embeddings (incorporações) - A representação numérica dos dados de texto
Esses três passos são a maneira que o módulo de conectores funciona. Quando se trata de dados requeridos, como credenciais de DB, e chaves de API, eu busco do usuário e salvo no armazenamento local do navegador (Detalhes da Instância) e no armazenamento da sessão (chaves de API). Isso dá maior modularidade à aplicação para qualquer um explorar.
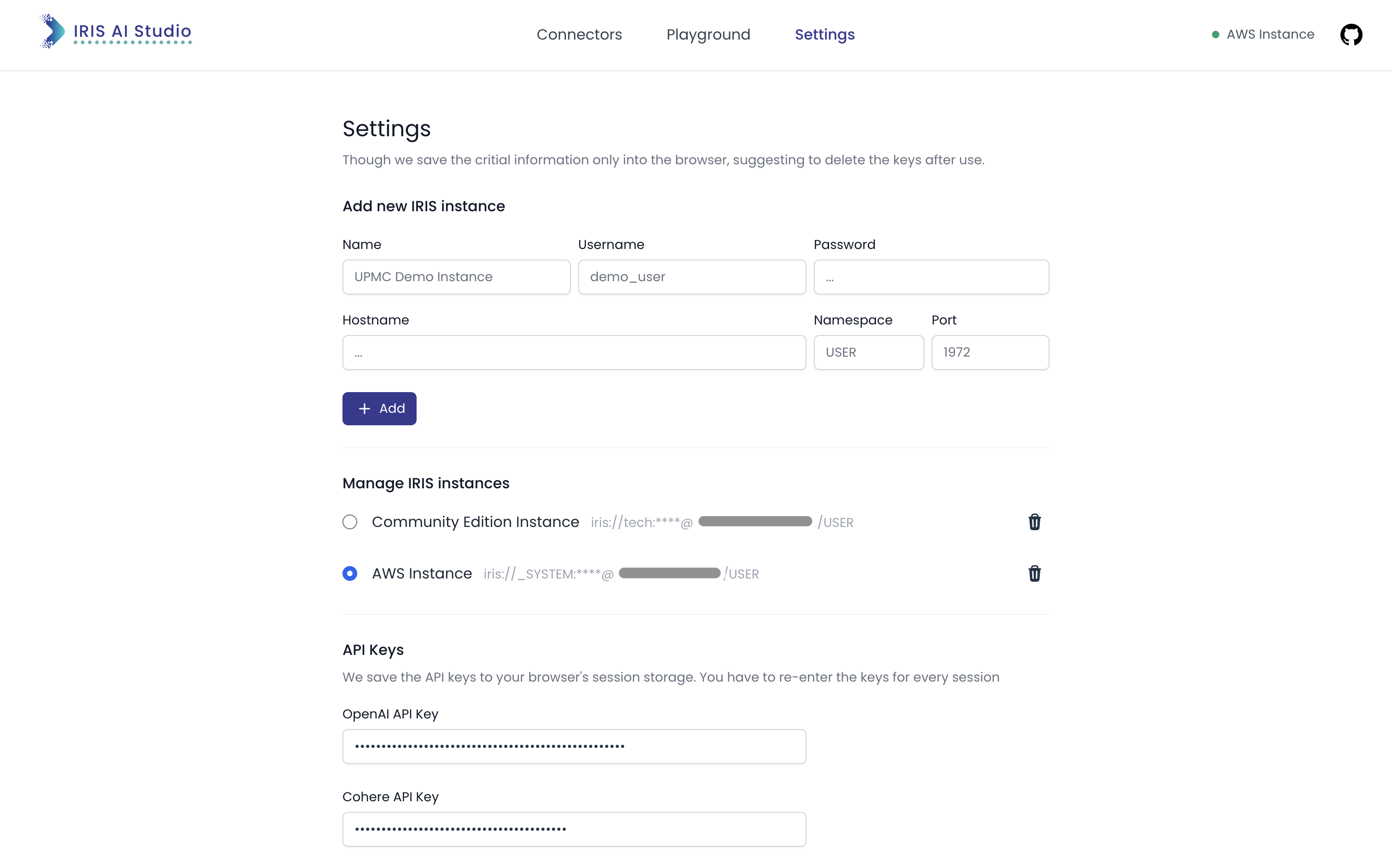
Ao unir o carregamento de dados incorporados por vetores de arquivos e a recuperação de conteúdo por vários canais, o Studio IRIS AI permite uma maneira intuitiva de explorar as possibilidades de Generative AI que o InterSystems IRIS oferece - não apenas para clientes atuais, mas também para novas perspectivas.
🚀 Vote por essa aplicação na competição de Vector Search, GenAI and ML, se acreditar que ela tem futuro!
Se você pensar em alguma aplicação em potencial usando essa implementação, por favor sinta-se à vontade para compartilhar no fio de discussão.