The A-Level periodic table arranges chemical components in groups and periods according to their atomic number. It highlights patterns in areas such as ionization energy, reactivity, and electronegativity. While it is an integral part of studying chemical properties, students use these patterns to predict chemical behaviors and reactions. In chemical analysis, it is vital to master these patterns as they explain how and why chemical components interact.
Students who require more guidance may hire online A Level Chemistry tutors to establish a more solid foundation in these concepts. This guide will cover everything there is to know about the periodic table, its significance and the role of periodic elements in alkaline earth metals.
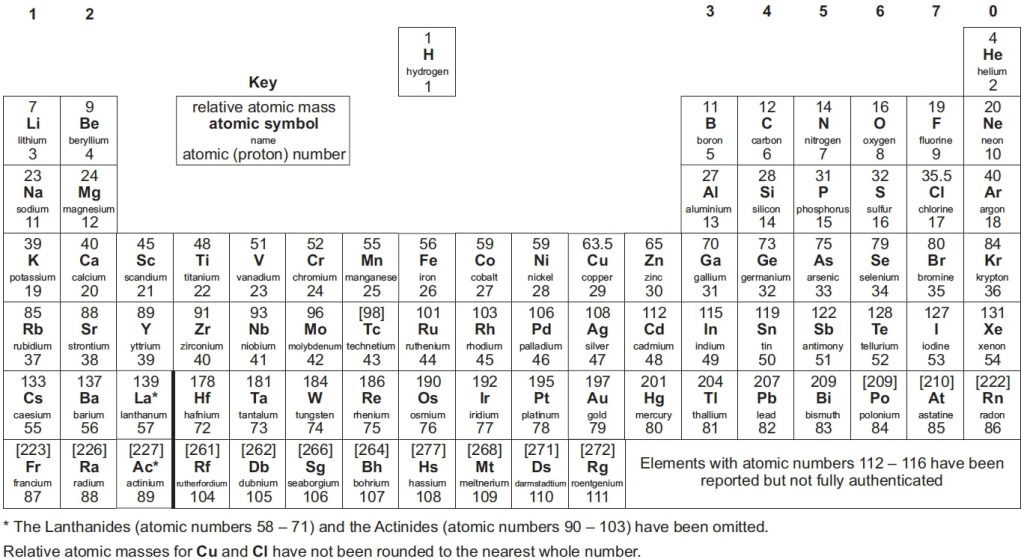
Understanding the Structure of the Periodic Table
Many students don't realize that the periodic table is alphabetically organized. The Periodic Table is arranged according to atomic numbers and groups, and periods that indicate the chemical properties of the elements, telling you everything you need to know about the elements. Elements within a group share similar properties and behaviors, along with similar arrangements of their energy levels, or valence electrons. With these shared properties, elements will share similar behaviors in resulting aspects like atomic radius and ionization energy.
The arrangement of the periodic table by Mendeleev allowed for further development of the table as the configuration of electrons improved the placement of elements. The d block has transition metals with varying oxidation states and bright compounds, mainly as they function as catalysts. A well-structured periodic table provides critical and structural understanding to students.
Historical Context and Evolution of the Periodic Table
The periodic table of elements is one of the core components of A level chemistry and deals with the classification of data as a result of research. Mendeleev, in 1869, developed a version of the periodic table that had elements arranged in increasing order of their atomic mass. By doing so, he showed the periodic nature of the elements and even left gaps for elements that had not been discovered.
The version of Mendeleev’s table had a lot of mistakes. These mistakes were corrected in the year of 1913 by a scientist named Henry Mosley. He ordered the elements in the table by atomic number, and this was a significant improvement to the table. The current version of the periodic table has elements arranged in periods and groups. The elements in a group have similar chemical properties, and this is due to the similar number of their valence electrons. Due to quantum mechanics, we now have a better understanding of the elements, and this explains the periodic trends.
The Concept of Periodicity in Chemistry
The idea of periodicity in chemistry, which shows the regular patterns of element properties, can be appreciated by building on an understanding of the structure of the Periodic Table.
Atomic structure and electron configuration give rise to periodicity, which reflects patterns impacted by atomic number. Atomic radius, initial ionization energy, and electronegativity all change as elements go through a period or down a group.
These patterns help predict chemical behavior, which is crucial for the formation of compounds. Bonding types have an impact on melting and boiling points, which also show periodic trends. Historical advancements in atomic models and table organization further highlight the importance of periodicity.
Trends Across Periods and Groups
Predicting the physical and chemical properties of elements requires an understanding of the patterns throughout periods and groups in the periodic table. Atomic mass usually increases as atomic number increases over time. An atom's capacity to attract electrons is strengthened by increased electronegativity. Melting points for metals rise over time, while those for nonmetals typically fall.
Group trends show changes in reactivity; alkali metals get more reactive as they move down the group, in contrast to halogens. Increased electron shielding causes electronegativity to drop within a group. For students involved in chemical research and discovery, these trends help in predicting the behavior of elements.
Investigating Atomic Radius and Ionization Energy
Further understanding of the characteristics can be gained by looking at the atomic radius and ionization energy. As the nuclear charge rises over time, electrons are drawn closer to the nucleus, and the atomic radius falls. On the other hand, adding electron shells to a group increases the atomic radius and separates electrons from the nucleus.
Because of a larger effective nuclear charge, ionization energy (the energy needed to remove the outermost electron) increases over a period but drops down a group because of improved shielding. Predicting the reactivity and chemical behavior of elements requires an understanding of these trends in atomic radius and ionization energy.
Melting Points and their Variations
Examining the melting points of elements reveals clear differences across the periodic table's various eras, with Period 3 showing higher tendencies. From sodium to silicon, the melting points rise, reaching a climax at silicon because of its enormous covalent structure. The melting point of silicon is significantly higher at 1414°C than that of sodium, which is at 98°C.
Phosphorus and sulfur are examples of non-metals with molecular configurations that result in melting temperatures of 44°C and 115°C, respectively. Differences in bonding and structures drive these patterns. By understanding these patterns, students can use their scientific knowledge to benefit others by describing the complexity of chemical behavior.
The Role and Reactions of Alkaline Earth Metals
Following an analysis of the differences in melting points amongst elements, especially in Period 3, focus turns to the unique properties and reactions of alkaline earth metals. They belong to Group 2 and contain magnesium and barium, which are distinguished by their surface and low density. Ionic compounds are formed when these metals take on a +2 oxidation state.
Magnesium reacts slowly with water, whereas barium reacts quickly, generating hydrogen and hydroxides. Reactivity rises along the group. From magnesium to barium, the hydroxides become more soluble in water, which affects their usefulness. They produce essential ionic halides when they react with halogens, which are necessary for many industrial uses.
Practical Applications of Periodic Trends
Knowing periodic patterns provides knowledge into the behavior and interactions of elements, influencing several real-world applications. Chemical element behavior, such as reactivity and bonding qualities, can be predicted by analyzing atomic number and physical characteristics.
For example, increased nuclear charge causes the atomic radius to shrink over time, which has an impact on bonding and structure. The ease of electron loss, which is crucial for analyzing reactions, is also influenced by ionization energy trends. Environmental science and medicine are affected by solubility trends, such as those for alkaline earth metals.
Tips for studying and memorizing the periodic table
Mastering the periodic table requires a combination of understanding and memorization. While learning the principles and trends is crucial, memorizing certain elements and their properties can be a valuable asset. Here are some tips offered by online A-level Chemistry tutors to help you study and memorize the periodic table effectively:
Mnemonics and Acronyms
Create memorable phrases or acronyms to help you remember the order of elements or their properties. ‘Harry Helped His Uncle Get Supplies’ can help you recall the first nine elements (Hydrogen, Helium, Lithium, Beryllium, Boron, Carbon, Nitrogen, Oxygen, Fluorine).
Flashcards
Create flashcards with element symbols, names, and properties on one side and the related information on the other. Regular practice with these flashcards can boost your knowledge and help with memorization.
Periodic Table Games
Engage in interactive games or quizzes that challenge you to identify elements, their properties, or their positions in the periodic table. These games can make the learning process more enjoyable and effective.
Visualization Techniques
Utilize visual aids, such as color-coding or diagrams, to associate elements with their properties or positions in the periodic table. Visual cues can help improve your understanding and memory.
Repetition and Practice
Consistent repetition and practice are key to memorizing the periodic table effectively. Regularly review the elements, their properties, and their positions in the periodic table to solidify your knowledge.
Relate to Real-World Examples
Connect elements and their properties to real-world applications or examples. This can help make the information more relatable and easier to remember.
Bottom Line
A-Level Chemistry is challenging but rewarding, with the A-level periodic table at its core. While it is considered more demanding than some of the easiest A-level options, understanding this not only supports exams but also builds the future for future scientific paths. With the help of dedicated online tutoring, mastering the periodic table and other chemistry concepts can become a more manageable and enjoyable journey.
Your exploration of the periodic table could inspire you to contribute to the discovery of the next element. If you are searching for A-Level Chemistry tutors. Online tutoring platform like Mixt Academy connects students and parents with tutors from top UK universities, ensuring high-quality educational support tailored to individual needs.
FAQs
Do you get a periodic table in Chemistry A Level?
In A-Level Chemistry examinations, students receive a Periodic Table, which includes atomic numbers, symbols, and relative atomic masses. This essential tool supports students in understanding chemical properties and solving related problems effectively.
What is the Periodic Table of elements overview?
The periodic table organises elements by atomic number, electron configuration, and chemical properties. It highlights elemental trends and periodicity, assisting in predicting chemical behaviour, thereby enabling students to better understand and engage in chemistry effectively.
What is Periodicity AQA A Level Chemistry?
Periodicity in AQA A-Level Chemistry examines trends in elemental properties across the Periodic Table. Understanding these trends, such as atomic radius and ionisation energy, enables students to predict the chemical behaviours of elements, building a comprehensive understanding of chemistry's role in society.
Is A Level Chemistry complex?
A-Level Chemistry is considered challenging due to its complex concepts and reliance on mathematical skills. Students who approach the subject with dedication, seeking help from Mixt Academy when necessary, often find fulfillment in mastering its complexities with confidence.
Can I get an A * in A-level chemistry?
Yes, achieving an A* in A-Level Chemistry is possible with consistent effort, effective study strategies, and the expert support of online A-level chemistry tutors.
.png)
.png)