.png)
Mirror Your Database Across the Galaxy with Seeding
Hello cpf fans! This distraction I used the "seed" capability in IRIS to provision an entire IrisCluster mirror, 4 maps wide with compute starting from an IRIS.DAT in a galaxy far far away. This is pretty powerful if you have had a great deal of success with a solution running on a monolithic implementation and want it to scale to the outer rim with Kubernetes and the InterSystems Kubernetes Operator. Even though my midichlorian count is admittely low, I have seen some hardcore CACHE hackers shovel around DATS, compact and shrink and update their ZROUTINES, so this same approach could also be helpful shrinking and securing your containerized workload too. If you squint and feel all living things around you, you can see a glimpse of in place (logical) mirroring in the future as a function of the operator and a migration path to a fully operational mirrored Death Star as the workload matures.
.png)
Mission
Ill show you how I built an IrisCluster that pulls an IRIS.DAT file from an arbitrary location via an initContainer and uses it to "seed" a mirrored database throughout its topology.
I used a repo that I visit at least annually @Guillaume Rongier 's repo InstallSamples which features a committed IRIS.DAT, there is also another one that appropriately puts ENSDEMO back on your systems too, but I kept it simple adhering to my prescription of Focusyn.
https://media.githubusercontent.com/media/grongierisc/InstallSamples/ref...
.png)
🌱 This will be the seed for the IrisCluster, and I expect it to be production grade mirrored and like deployable on a Friday if you know what I mean.
Kubernetes Cluster (Kind)
So I provision a quick kind cluster, give it 5 worker nodes, install Cilium as the default CNI and install the InterSystems Kubernetes Operator. Waited for it to complete, then when it did, I labelled the nodes, one per Star Wars planet, including one from the Outer Rim.
cat <<EOF | kind create cluster --name ikoseed --config=-
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: worker
- role: worker
- role: worker
- role: worker
- role: worker
networking:
disableDefaultCNI: true
EOF
kind get kubeconfig --name ikoseed > ikoseed.kubeconfig
cilium install --version v1.18.0 --kubeconfig ikoseed.kubeconfig
cilium status --wait --kubeconfig ikoseed.kubeconfig
helm install iko iris-operator/ --kubeconfig ikoseed.kubeconfig
planets=(tatooine coruscant hoth naboo endor)
i=0
for node in $(kubectl get nodes --no-headers --kubeconfig ikoseed.kubeconfig | awk '/worker/{print $1}'); do
planet=${planets[$i]}
kubectl label node "$node" topology.kubernetes.io/zone="$planet" --overwrite --kubeconfig ikoseed.kubeconfig
echo "$node → zone=$planet"
i=$(( (i+1) % ${#planets[@]} ))
done
kubectl get nodes -L topology.kubernetes.io/zone --kubeconfig ikoseed.kubeconfig
I now have a happy Kubernetes cluster, nodes are ready and labelled as planets=(tatooine coruscant hoth naboo endor)... warp speed.
.png)
And an InterSystems Kubernetes Operator parked in orbit around the forest moon of Endor.
.png)
Then I had R2 declare the IrisCluster topology...
IrisCluster
Here is is in its entirety, but we will break it down, starting with the init container.
apiVersion: intersystems.com/v1alpha1
kind: IrisCluster
metadata:
name: ikoplus-seed-sweenx12
namespace: ikoplus
spec:
imagePullSecrets:
- name: containers-pull-secret
licenseKeySecret:
name: license-key-secret
tls:
webgateway:
secret:
secretName: cert-secret
volumes:
- name: foo
emptyDir: {}
- name: airgapdir
emptyDir: {}
- name: seed-before-volume
configMap:
name: seed-before-script
- name: seed-after-volume
configMap:
name: seed-after-script
topology:
data:
updateStrategy: {}
image: containers.intersystems.com/intersystems/irishealth:2025.1
mirrorMap: primary,backup,drasync,rwrasync
mirrored: true
volumeMounts:
- name: airgapdir
mountPath: /airgapdir
- name: foo
mountPath: "/irissys/foo/"
- name: seed-before-volume
mountPath: /hs/before/
- name: seed-after-volume
mountPath: /hs/after/
irisDatabases:
- name: SAMPLES
directory: /irissys/data/IRIS/mgr/SAMPLES
mirrored: true
ecp: true
seed: /airgapdir/
logicalOnly: false
irisNamespaces:
- name: ENSDEMO
routines: SAMPLES
globals: SAMPLES
interop: true
podTemplate:
spec:
args:
- --before
- /usr/bin/bash /hs/before/before.sh
- --after
- /usr/bin/bash /hs/after/after.sh
securityContext:
fsGroup: 51773
runAsGroup: 51773
runAsNonRoot: true
runAsUser: 51773
initContainers:
- name: init-grongierisc-samples
image: debian:bookworm-slim
command:
- sh
- -c
- |
echo "Installing getting Samples from @grongierisc's repository https://github.com/grongierisc/InstallSamples/tree/master ..."
#set -euo pipefail
apt-get update
DEBIAN_FRONTEND=noninteractive apt-get install -y curl
cd /airgapdir
curl -L https://media.githubusercontent.com/media/grongierisc/InstallSamples/refs/heads/master/samples/IRIS.DAT --output IRIS.DAT
#curl -L http://192.168.1.231:8080/IRIS.DAT --output IRIS.DAT
chmod -R 777 /airgapdir
chown -R 51773:51773 /airgapdir
volumeMounts:
- name: airgapdir
mountPath: /airgapdir
securityContext:
runAsUser: 0
runAsNonRoot: false
readOnlyRootFilesystem: false
preferredZones:
- tatooine
- coruscant
- hoth
- naboo
webgateway:
replicas: 1
updateStrategy: {}
alternativeServers: LoadBalancing
applicationPaths:
- /csp/sys
- /csp/user
- /csp/broker
- /csp/hssys
- /api
- /api/healthshare-rest/hssys/register
- /csp/healthshare/hssys/services
- /isc
- /oauth2
- /ui
- /csp/healthshare
- /csp/bin
- /*
ephemeral: true
image: containers.intersystems.com/intersystems/webgateway-lockeddown:2025.1
loginSecret:
name: webgateway-secret
type: apache-lockeddown
arbiter:
image: containers.intersystems.com/intersystems/arbiter:2025.1
updateStrategy: {}
compute:
image: containers.intersystems.com/intersystems/irishealth:2025.1
ephemeral: true
replicas: 1
preferredZones:
- endor
serviceTemplate:
spec:
type: LoadBalancer
externalTrafficPolicy: Local
---
apiVersion: v1
data:
iris.key: REDACTED
kind: Secret
metadata:
name: license-key-secret
namespace: ikoplus
---
apiVersion: v1
data:
password: U1lT
username: Q1NQU3lzdGVt
kind: Secret
metadata:
name: webgateway-secret
namespace: ikoplus
---
apiVersion: v1
data:
.dockerconfigjson: REDACTED
kind: Secret
metadata:
name: containers-pull-secret
namespace: ikoplus
type: kubernetes.io/dockerconfigjson
---
apiVersion: v1
data:
ca.pem: REDACTED
tls.crt: REDACTED
tls.key: REDACTED
kind: Secret
metadata:
creationTimestamp: null
name: cert-secret
namespace: ikoplus
---
apiVersion: v1
kind: ConfigMap
metadata:
name: seed-before-script
namespace: ikoplus
data:
before.sh: |-
echo "Seed Before Script"
---
apiVersion: v1
data:
password: U1lT
username: REDACTED
kind: Secret
metadata:
name: webgateway-secret
---
apiVersion: v1
kind: ConfigMap
metadata:
name: seed-after-script
namespace: ikoplus
data:
after.sh: |-
if ! [ -f "/irissys/data/after.done" ]; then
echo "HS After Script executed..."
iris session IRIS <<-'EOF'
zn "%SYS"
set tSC=##Class(Security.Users).Create("intersystems","%All","intersystems","USER","","","",0,1,,,,,,1,1)
do
set user("Enabled")=1
set user("Password")="HS_Services"
set status =
write $System.Status.GetErrorText(status)
zn "HSSYS"
Set oCredential =
Set oCredential.Password = "HS_Services"
Set tSC = oCredential.%Save()
do
HANG 30
zn "%SYS"
if $SYSTEM.Mirror.IsPrimary() { Set tSC =
if '($SYSTEM.Mirror.IsPrimary()) { Set tSC = ##class(SYS.Mirror).ActivateMirroredDatabase("/irissys/data/IRIS/mgr/SAMPLES/") }
Set SFNlist = $lb(9)
if '($SYSTEM.Mirror.IsPrimary()) { Set sc =
Halt
EOF
touch "/irissys/data/after.done"
fi
exit
init-container
Our init-container has one job, and is going to retrieve our seed database from github, and appropriate it with a mount and hand it off to our IRIS pods so it can be referenced from a POSIX path.
...
initContainers:
- name: init-grongierisc-samples
image: debian:bookworm-slim
command:
- sh
- -c
- |
echo "Installing getting Samples from @grongierisc's repository https://github.com/grongierisc/InstallSamples/tree/master ..."
#set -euo pipefail
apt-get update
DEBIAN_FRONTEND=noninteractive apt-get install -y curl
cd /airgapdir
curl -L https://media.githubusercontent.com/media/grongierisc/InstallSamples/refs/heads/master/samples/IRIS.DAT --output IRIS.DAT
#curl -L http://192.168.1.231:8080/IRIS.DAT --output IRIS.DAT
chmod -R 777 /airgapdir
chown -R 51773:51773 /airgapdir
volumeMounts:
- name: airgapdir
mountPath: /airgapdir
...
The database will show up at /airgapdir/IRIS.DAT in the IRIS pods.
Data
💫The seeding comes in at this block in the specification, this is telling the operator to weild the force
irisDatabases:
- name: SAMPLES
directory: /irissys/data/IRIS/mgr/SAMPLES
mirrored: true
ecp: true
seed: /airgapdir/
logicalOnly: false
irisNamespaces:
- name: ENSDEMO
routines: SAMPLES
globals: SAMPLES
interop: true
I enabled mirroring, turned ecp to true as we will be including a compute node, and pointed it at our seed directory of the database. Under the hood, IKO is generating a cpf for merge in the Actions directive, which is really accountable for the heavy seeding capability.
[Actions]
ModifyService:Name=%service_ecp,Enabled=0
CreateDatabase:Name=iriscluster,Directory=/irissys/data/IRIS/mgr/iriscluster
CreateNamespace:Name=IRISCLUSTER,Globals=iriscluster,Routines=iriscluster
CreateDatabase:Name=SAMPLES,Directory=/irissys/data/IRIS/mgr,Seed=/airgapdir
CreateNamespace:Name=ENSDEMO,Globals=SAMPLES,Routines=SAMPLES,Interop=1
Compute
I added a single replica of an ecp node to the equation, a clone if you will.
compute:
image: containers.intersystems.com/intersystems/irishealth:2025.1
ephemeral: true
replicas: 1
preferredZones:
- endor
mirrorMap
The mirrormap includes the following roles:
mirrorMap: primary,backup,drasync,rwrasync
mirrored: true
Zones
To stay in step with the Star Wars theme Ill lock our mirror topolology to the labelled nodes.
preferredZones:
- tatooine
- coruscant
- hoth
- naboo
Note that we already set a zone for the compute node on Endor.
Apply
kubectl apply -f iriscluster.yaml --kubeconfig ikoseed.kubeconfig
iriscluster.intersystems.com/ikoplus-seed-sweenx12 created
secret/license-key-secret unchanged
secret/webgateway-secret unchanged
secret/containers-pull-secret unchanged
secret/cert-secret configured
configmap/seed-before-script unchanged
secret/webgateway-secret unchanged
configmap/seed-after-script unchanged
I waited a few minutes and it the IrisCluster came to life...
.png)
The IrisCluster role view...
.png)
And a view from Hubble...
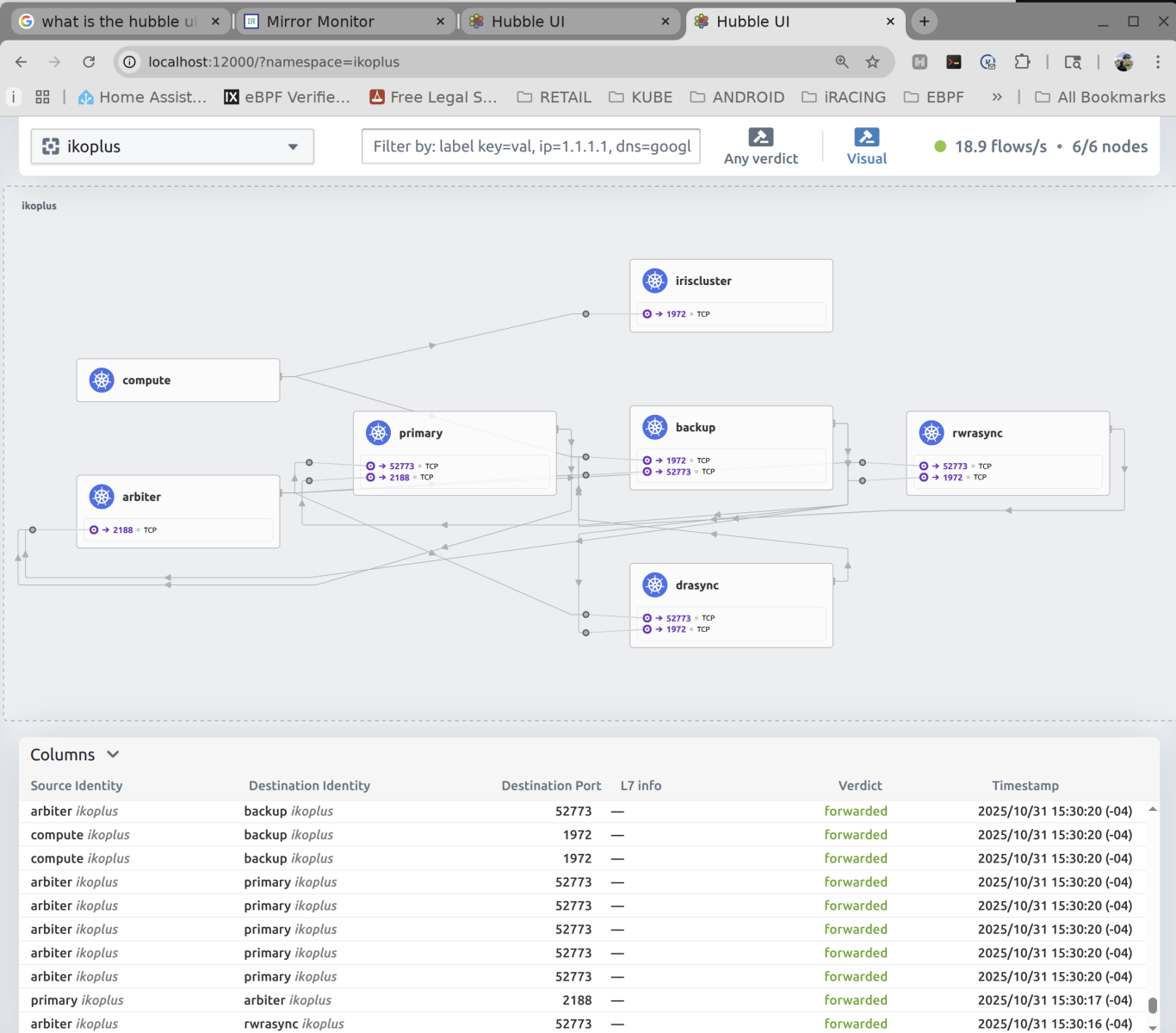
I pulled up Mirroring Monitor, to see if our seeded database "SAMPLES" in Namespace "ENSDEMO" made it to the mirror party
.png)
🎉 It DID!
Then I inspected the result of the clone operation on the pod itself to make sure the DAT is in all the right places (podspec, filesystem, DATADIR).
.png)
.png)
🎉 They ARE!
And just to check the topology, lets see if the single replica ECP client is connected...
.png)
🎉 Totally IS!
Attestation
I am a little weirded out by these force powers and hand waving, back in the day I seemed to have to square dance mounting/shuffling around the DAT with PVC swings, SFTP, ssh, whatever, and even wrote sscp with @Eduard Lebedyuk to do the task over the superserver.
So I write a global out in the on the Primary mirror on the IrisCluster...
.png)
Then loop over the topology to see if it it got mirrored appropriately across the galaxy.
#!/bin/bash
export KUBECONFIG=ikoseed.kubeconfig
NAMESPACE=${1:-default}
CMD='iris session IRIS -U ENSDEMO -B <<'EOF'
ZWRITE ^MayTheForce
HALT
EOF'
echo "Running '$CMD' in all pods in namespace '$NAMESPACE'..."
for pod in $(kubectl get pods -n "$NAMESPACE" -o jsonpath='{.items[*].metadata.name}'); do
kubectl -n "$NAMESPACE" --kubeconfig ikoseed.kubeconfig exec "$pod" -- /bin/sh -c "$CMD" || echo "⚠️ Failed on $pod"
echo
done
Its a little sloppy, Wado did not give me the day off today, but the results are good...
.png)
The force seems to be with us on:
✅ primary (persisted)
✅ backup (persisted)
✅ drasync (persisted)
✅ rwrasync (persisted)
✅ compute (accessible)
🎉
Set ^iFind="Your Lack of Faith Disturbing"
(1).jpg)
.png)
.png)