Limpar filtro
Artigo
Vinicius Maranhao Ribeiro de Castro · Mar. 9, 2021
Introdução
Com a transformação digital no mundo dos negócios, novos recursos ou funcionalidades nos softwares oferecidos por uma empresa, podem significar vantagem competitiva. No entanto, se o time de TI não estiver preparado com a cultura, metodologia, práticas e ferramentas corretas, pode ser muito difícil garantir a entrega dessas novas funcionalidades a tempo hábil.
Integração contínua (do inglês “Continuous Integration”, CI) e entrega contínua (do inglês “Continuous Delivery”, CD) incorporam uma cultura, um conjunto de princípios operacionais e uma coleção de práticas que permitem que as equipes de desenvolvimento entreguem esses novos recursos ou novas funcionalidades com maior frequência e confiabilidade.
Neste artigo, veremos como criar e configurar uma esteira de CI/CD para uma aplicação desenvolvida na plataforma InterSystems IRIS utilizando serviços disponíveis na Amazon Web Services (AWS). Neste primeiro momento, vamos adaptar um workshop da própria AWS (link no final do artigo) porém, construindo e entregando um serviço REST implementado no InterSystems IRIS. Vamos ainda supor que este é um serviço “stateless”, ou seja, não há persistência de dados.
Serviços Utilizados e Arquitetura
Neste artigo, utilizaremos os seguintes serviços para compor nossa esteira de CI/CD:
GitHub: repositório de código
AWS Code Build: serviço responsável por fazer a construção (“build”) da aplicação
AWS Code Pipeline: serviço responsável por fazer a orquestração dos processos de construção (“build”) e implantação (“deploy”)
AWS Elastic Container Registry (ECR): repositório das imagens de container construídas
AWS Elastic Kubernetes Service(EKS): Cluster de Kubernetes gerenciado pela AWS
A arquitetura e interação entre os serviços descritos acima pode ser ilustrada pelo seguinte diagrama:
Desenvolvedores “comitam” código para o repositório do GitHub. Quando um “commit” é realizado, o AWS Code Pipeline detecta automaticamente as mudanças e começa a processá-las através da esteira definida
O AWS CodeBuild empacota as mudanças do código juntamente com qualquer dependência e constrói a imagem Docker. Opcionalmente, não abordado neste artigo, outro estágio da esteira testa o código e o pacote, também utilizando o AWS CodeBuild.
A imagem Docker construída é armazenada no AWS Elastic Container Registry (ECR) após uma construção e/ou teste bem sucedido.
AWS CodePipeline realiza a substituição da tag da imagem definida no manifesto de deployment da aplicação no Kubernetes para apontar para a imagem recém construída e chama a API do Kubernetes para fazer a atualização dos pods
O Kubernetes, neste caso o AWS Elastic Kubernetes Service (EKS), faz a atualização dos “pods” para rodar a imagem recém construída e disponibilizada no AWS ECR.
O serviço REST implementado no InterSystems IRIS será, portanto, um “pod” dentro do EKS. Neste artigo, reaproveitamos o projeto “iris-rest-api-template” desenvolvido pelo @Evgeny.Shvarov, disponível no github: https://github.com/intersystems-community/iris-rest-api-template
Este serviço implementa endpoints para criar, ler, atualizar ou remover uma pessoa (um registro da classe dc.Sample.Person).
Sem mais delongas, vamos pôr a mão na massa para criarmos uma esteira de CI/CD na prática com o InterSystems IRIS!
Criação dos serviços e projetos
Um pré-requisito para este projeto é possuir um cluster do EKS rodando. Para isso, é possível seguir essa documentação para entender como provisionar um cluster EKS na AWS:
https://docs.aws.amazon.com/eks/latest/userguide/getting-started.html
A criação dos projetos do AWS Code Build e do AWS Code Pipeline será realizada através de um template do AWS Cloud Formation, assim como o repositório do ECR, o “bucket” do S3 e as “Policies” do Identity Access Manager da AWS. Esse template está disponibilizado no repositório deste artigo. O Cloud Formation é um serviço da AWS que permite modelar e configurar recursos da AWS a partir de um arquivo com essas definições, seguindo a metodologia de infraestrutura como código.
Pré-requisitos da AWS e do EKS
Para fazermos a implantação via esteira de CI/CD no EKS, há algumas configurações que precisamos fazer antes. Primeiramente, será necessário criar uma role no AWS Identity and Access Management (IAM) para permitir que o serviço do CodeBuild possa interagir com o EKS, já que o CodeBuild que executará o comando para fazer o “deploy” no EKS. Vamos fazer a criação desta “role” e adicionar uma “inline Policy” através do AWS CLI. Para informações sobre como instalar o AWS CLI, seguir esta documentação:
https://docs.aws.amazon.com/cli/latest/userguide/install-cliv2.html
Com o AWS CLI instalado, executar os seguintes comandos:
TRUST="{ \"Version\": \"2012-10-17\", \"Statement\": [ { \"Effect\": \"Allow\", \"Principal\": { \"AWS\": \"arn:aws:iam::${ACCOUNT_ID}:root\" }, \"Action\": \"sts:AssumeRole\" } ] }"
echo '{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "eks:Describe*", "Resource": "*" } ] }' > /tmp/iam-role-policy
aws iam create-role --role-name EksDemoSE --assume-role-policy-document "$TRUST" --output text --query 'Role.Arn'
aws iam put-role-policy --role-name EksDemoSE --policy-name eks-describe --policy-document file:///tmp/iam-role-policy
Agora que temos a “role” criada, é necessário adicionar esta role a ConfigMap aws auth no EKS. Para isso, execute os seguintes comandos (não remova espaços em branco):
ROLE=" - rolearn: arn:aws:iam::${ACCOUNT_ID}:role/EksDemoSE\n username: build\n groups:\n - system:masters"
kubectl get -n kube-system configmap/aws-auth -o yaml | awk "/mapRoles: \|/{print;print \"$ROLE\";next}1" > /tmp/aws-auth-patch.yml
kubectl patch configmap/aws-auth -n kube-system --patch "$(cat /tmp/aws-auth-patch.yml)"
Com isso, o CodeBuild já consegue interagir com o EKS através dos comandos “kubectl”.
Repositório GitHub
O próximo passo é criar um repositório no GitHub. É possível fazer um fork do repositório utilizado neste artigo para já criar um repositório juntamente com todos os arquivos necessários.
Para isso, basta fazer o login com sua conta do GitHub, acessar o repositório deste artigo em
https://github.com/vmrcastro/iris-rest-api-template
e clicar em Fork:
Para permitir o CodePipeline receber “callbacks” do GitHub, de forma que o gatilho para disparar a execução da nossa esteira de CI/CD seja quando um commit for feito para o repositório, é necessário gerar um token de acesso do GitHub.
Para isso acesse a página
https://github.com/settings/tokens/new
Marque a caixa “repo”
E clique no botão “Generate Token” no final da página.
Na página seguinte, copie o token gerado e grave em um lugar seguro. Necessitaremos dele nos próximos passos. Se atente para o fato de que este token é exibido somente uma vez após a criação e não é possível recuperá-lo posteriormente.
Criação e configuração do CodePipeline
Como havia sido mencionado anteriormente, a criação e configuração dos projetos do CodePipeline e do CodeBuild serão realizados através do Cloud Formation. Portanto, abra a console do Cloud Formation e clique em “Create Stack” e, em seguida, “With new resources (standard)”.
Na seção “Prepare Template”, deixe marcada a caixa “Template is ready” e, na seção “Specify Template”, marque a caixa “Upload template file”. Clique no botão “Choose file” e aponte para o arquivo “ci-cd-codepipeline.cfn.yml” na pasta “IaC” do projeto presente no repositório do GitHub. Em seguida, clique em “Next”.
Na tela seguinte, na seção “Stack name”, dê um nome para o projeto. Na seção “Parameters”, altere os campos de acordo com as instruções abaixo. Os campos não mencionados, devem continuar com o valor padrão.
GitHub
Username: seu username do GitHub
Access Token: Access Token para o Code Pipeline interagir com seu repositório do git, gerado no final da seção anterior deste artigo
Repository: o nome do seu repositório do GitHub. Neste caso, é o seu repositório oriundo do fork, demonstrado anteriormente neste artigo, cujo nome é “iris-rest-api-template”
Branch: defina qual será a branch que o CodePipeline ficará “ouvindo” para disparar a execução da esteira assim que houver um commit
EKS
EKS cluster name: nome do cluster de EKS já provisionado na AWS
Uma vez todos os campos preenchidos, clique em “Next”. Na tela seguinte, não é necessário fazer nenhuma alteração, somente clicar em “Next”. Finalmente, na última tela, confira os valores definidos e, se estiver tudo certo, marque a caixa “I acknowledge that AWS CloudFormation might create IAM resources.” e clique no botão “Create stack”.
Aguarde até o seu projeto do Cloud Formation ficar com o status de “CREATE_COMPLETE”:
Acompanhando a construção e entrega do projeto no Code Pipeline
Uma vez criado todos os recursos através do Cloud Formation, o processo de construção e implantação (“deploy”) é executado automaticamente pela primeira vez. Para acompanhar, vá até a console do Cloud Formation, expanda a seção “Pipeline” no menu esquerdo, clique em “Pipelines” e localize o seu projeto.
Se esta página foi aberta logo após a execução bem sucedida do Cloud Formation ou logo após um commit no seu repositório GitHub configurado no projeto, provavelmente o projeto estará com o status de “’In Progress”. Para acompanhar detalhes da execução, clique no nome do seu projeto, e a seguinte página deve abrir:
Na tela acima, podemos observar que a etapa “Source” foi executada com sucesso. Nesta etapa, o CodePipeline faz o download do repositório do GitHub configurado, armazena no S3 e disponibiliza para o CodeBuild executar a etapa “Build”, que está em execução. Clicando em “Details”, é possível acompanhar os logs da etapa, conforme mostrado na imagem a seguir:
Ainda é possível ficar “seguindo” os logs desta etapa, clicando no botão “Tail logs”:
Uma vez a etapa “Build” completada com sucesso, será possível observar o status “Succeded”:
O término com sucesso desta etapa significa que o projeto foi construído e foi feito o deploy no cluster de Kubernetes (EKS) configurado. Para verificarmos, podemos executar alguns comandos a partir de um “shell” que tenha o “kubectl” configurado para interagir com o EKS.
Primeiramente, vamos verificar se o deployment do nosso projeto, denominado “demose”, está rodando:
$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
demosebr 1/1 1 1 131m
Podemos verificar também os pods que estão em execução e sua respectiva “idade”:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
demosebr-7f5dbdfb46-mkgsg 1/1 Running 0 2m8s
Aparentemente, nosso projeto foi entregue com sucesso ao EKS!
Vamos agora testar nosso serviço REST. Para isso, precisamos verificar o endereço do “service” do Kubernetes que será responsável por enviar requisições externas aos respectivos “pods”. Para isso, vamos executar o comando e copiar o conteúdo do campo da linha “demosebr” e da coluna “EXTERNAL-IP”. Este é o endereço para qual devemos enviar as requisições.
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
demosebr LoadBalancer 10.100.103.71 a2472[…]76.us-east-1.elb.amazonaws.com 52773:31752/TCP,1972:31866/TCP 130m
Veja que as portas expostas neste serviço foram a 52773 (webserver) e a 1972 (superserver). A configuração desse serviço é definida no arquivo “deploy.yml”, na raíz do nosso repositório.
Portanto, agora só resta enviar uma requisição para testar nosso serviço REST rodando no InterSystems IRIS. Para isso, eu utilizarei o cURL (mas utilize o cliente REST que você está mais habituado).
$ curl -v -u '_SYSTEM:SYS' -X POST 'http:// a2472[…]76.us-east-1.elb.amazonaws.com:52773/crud/persons/' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"Name":"Elon Mask","Title":"CEO","Company":"Tesla","Phone":"123-123-1233","DOB":"1982-01-19"}'
* Trying 52.[…].100:52773...
* TCP_NODELAY set
* Connected to a2472[…]76.us-east-1.elb.amazonaws.com (52.[…].100) port 52773 (#0)
* Server auth using Basic with user '_SYSTEM'
> POST /crud/persons/ HTTP/1.1
> Host: a2472[…]76.us-east-1.elb.amazonaws.com:52773
> Authorization: Basic X1NZU1RFTTpTWVM=
> User-Agent: curl/7.68.0
> accept: application/json
> Content-Type: application/json
> Content-Length: 94
>
* upload completely sent off: 94 out of 94 bytes
* Mark bundle as not supporting multiuse
< HTTP/1.1 204 No Content
< Date: Mon, 08 Mar 2021 17:26:30 GMT
< Server: Apache
< CACHE-CONTROL: no-cache
< EXPIRES: Thu, 29 Oct 1998 17:04:19 GMT
< PRAGMA: no-cache
<
* Connection #0 to host a2472[…]76.us-east-1.elb.amazonaws.com left intact
E voilá! Recebemos o código HTTP 204 de resposta, então aparentemente o serviço REST está funcional e o “Elon Mask” foi cadastrado! Para termos certeza, vamos fazer outra requisição REST para listar todas as pessoas cadastradas, desta vez, sem o verbose do cURL para imprimirmos somente o corpo da resposta:
$ curl -u '_SYSTEM:SYS' -X GET 'http:// a2472[…]76.us-east-1.elb.amazonaws.com:52773/crud/persons/all' -H 'accept: application/json'
[{"Name":"Elon Mask","Title":"CEO","Company":"Tesla","Phone":"123-123-1233","DOB":"1982-01-19"}]
Como pode ser observado, o serviço REST do IRIS está 100% funcional!
Obs: Não utilize autenticação básica (usuário e senha) em requisições HTTP e não utilize o usuário _SYSTEM. Esta é uma configuração totalmente insegura.
Entendendo o funcionamento da esteira
Se você chegou até aqui, você pode estar se perguntando:
Como ou onde é definido as etapas para fazer a construção e implantação (“deploy”) do projeto?
Esta é uma excelente pergunta e você verá que as respostas estão em arquivos dentro do próprio repositório!
Tudo começa na definição da etapa “Build” do nosso projeto do CodePipeline. Esta etapa é definida pelo arquivo denominado “buildspec.yml”. Dentro deste arquivo, dividimos a etapa “Build” em 3 fases: “pre_build”, “build” e “post_build”. Cada fase irá conter um conjunto de comandos diferentes, também definidos dentro do mesmo arquivo.
Na fase de “pre_build”, basicamente definimos uma “tag” para a imagem do nosso serviço REST que estamos construindo, substituímos a string “CONTAINER_IMAGE” no arquivo “deploy.yml” pelo nome da imagem que estamos fazendo o build e fazemos o login no repositório de imagens Docker da AWS, o ECR, para posteriormente enviarmos a imagem construída para lá.
O arquivo “deploy.yml” mencionado anteriormente também está presente na raíz do repositório. Ele é o manifesto do Kubernetes, que indica todos os recursos que devem ser criados pelo Kubernetes para implantar nossa aplicação.
Já na fase de “build”, não há nenhuma novidade. É nela em que é feita a construção da imagem Docker da nossa aplicação através do comando “docker build”. Lembrando que este comando irá construir a imagem a partir do arquivo “Dockerfile”, também presente na raíz do projeto. Além de construir a imagem, estamos etiquetando com a “tag” definida na fase anterior.
Finalmente, na fase de “post_build”, fazemos o upload da imagem construída para o ECR, configuramos o kubectl para o EKS desejado e aplicamos o arquivo de manifesto do Kubernetes, o “deploy.yml”.
Considerações finais
Neste artigo prático foi abordado como construir uma esteira CI/CD para fazer a implantação do InterSystems IRIS no Kubernetes utilizando os serviços da AWS. A aplicação escolhida é simples e a implantação realizada não contempla alguns aspectos, como persistência de dados, por exemplo. O objetivo deste artigo é dar uma ideia dos primeiros passos para implementar uma esteira CI/CD. Caso tenha interesse, poste nos comentários deste artigo suas dúvidas ou detalhes que você deseja entender mais.
Até a próxima!
Fontes consultadas e utilizadas
https://community.intersystems.com/post/continuous-delivery-your-intersystems-solution-using-gitlab-part-i-git
https://www.eksworkshop.com/intermediate/220_codepipeline/
https://openexchange.intersystems.com/package/iris-rest-api-template
Anúncio
Angelo Bruno Braga · Ago. 4, 2022
Olá Desenvolvedores,
Vocês postaram 83 perguntas na Comunidade de Desenvolvedores em Julho:
Spoiler
InterSystems IRIS
Is there a way to use IRIS from command line (eg: batch file), the same way as it can be done in CACHE ?by Norman W. Freeman
INI parser/writer?by Eduard Lebedyuk
Cleaning up CacheStream Globalby Mark OReilly
Web teminal : lost connection with server (code 1006)by Jules Pontois
%JSONImport & TimeStampby Matjaz Murko
Convert UTC to Specific time zone, Objectscript onlyby Marcel den Ouden
How to add global nodes in management portal?by Jens Cheung
Delete first part of HL7 field up to first "(" characterby Jonathan Harris
ERROR #5540: SQLCODE: -99 Message: User UnknownUser is not privileged for the operationby Oliver Wilms
login failureby Oliver Wilms
Assigning Service or Process items as global values?by Jens Cheung
IRIS as a backend database for Java applicationby Oliver Wilms
Error compiling cache code on irisby Peter smit
How to use a variable in "{fieldName*C} "when using ObjectScript Trigger Codeby Yan Kevin
Can you help meHow to Convert HL7 input message into JSON Object Output Message by Smythe Smythee
Currently Running Processes with Mirroringby Gordon Sjostrom
What's the best way to structure a list of tuples for passing into a method?by Dominic Chui
About the callback method %OnSaveFinally()by Joseph Tsang
Dynamic SQL giving security errorby Peter smit
AWS EFS, EBS Shared e SQS Support?by Alfredo Neto
Blocking other streamlet types associated with a blocked Clinical Information Typeby Stella Ticker
IRIS SQL LOAD DATA <ERROR #5023: Remote Gateway Error: Connection cannot be established>by Jack Boulton
Handling StreamContainer in Business Processby Minoru Horita
Converting POSIX to ODBC timestamp in SQLby Timothy Leavitt
Webterminal broken :(by Kurro Lopez
How to get rid of gibberish in menu?by Iryna Mykhailova
%JSON.Adaptor and relationship propertyby Matjaz Murko
InterSystems - Database Management / Remote Connectivityby Erol Gurcinar
Can we integrate zen framework with Angular? If yes can anyone please help me in find out any resources for reference. by Prudhvi Arram
How to convert from internal date format to web formatby Yuri Marx
IRIS when is it safe to delete Journalsby Phillip Wu
Is there an equivalent to the Business Intelligence (BI) classes in IRIS ?by Norman W. Freeman
XSLT Samplesby Lesley Anderson
InterSystems IRIS for Health
How to access Production items through Objectscript?by Markus Suonpää
Given a Start Time, Time Zone and Duration (in Minutes): How to calculate End Timeby Victor Castanon
Iris for health, community, problems with new namespaces and productions.by Antti Suomi
Dynamically change output file name for a schedule taskby Marykutty George
iris health and Grafanaby Phillip Wu
Data showing as NULL in Power BI when it shouldn'tby Carla Davies
Can I create an User Account from codeby Joost Platenburg
Howto disable journaling temporarily for one database by Stefan Schick
Patient Labels Design Dilemma: ZPL Abstract Class vs JReport(LOGI)by Tom Cross
Installing IRISHealth_Community-2022.1.0.209.0-lnxubuntu2004x64 on Ubuntu 20.04 LTS on oracle virtual box by Jefferson Borges
Add REST Service Classes To VS Code Projectby Michael Davidovich
Do we have an option within Healthconnect to limit the number of messages sent at a time to downstream application from outboundby Praveen Bhoomiyal
%REST disp.cls, apps, and packages - How to structure?by Michael Davidovich
Opinions on CSP methods to REST services?by Michael Davidovich
HealthShare
MAXLEN usage for stringsby Ramesh Ramachandran
Custom hyperlink in Clinical Viewer (CV2)by Igor Titarenko
Data Quality Manager rebuild Cubesby Ephraim Malane
XML Projection when edit and resend- why not available to edit XML- custom classesby Mark OReilly
Configuration of Hub endpoints from UCR Edge by Ephraim Malane
Default Database Resource by Marykutty George
Open Exchange
Errors installing OpenExchange git-source-control using ZPMby Steve Pisani
Open Exchange Terminal in VSCodeby Yehuda Israel
Installing Apps without Dockerby Scott Roth
Ensemble
Exporting to Excel with %DisplayFormattedby Rochdi Badis
Shutdown Ensemble Business Service upon Warning in the Event Logby Jimmy Christian
Send zen report to file pathby Rochdi Badis
Crystal Report 2020 compatibility by Rochdi Badis
Bulk Testing Business Process (Rules)by Scott Roth
Deleted recordsby Rochdi Badis
Clone Classby Rochdi Badis
Empty HTTP responseby Rochdi Badis
Interoperability - Interface Mapsby Scott Roth
Dealing with single Quote in SQL Queryby Rochdi Badis
how to convert a docx file into pdf using Ensemble without using External librariesby Mohan Reddy
Inbound Adaptersby Rochdi Badis
Zen Page source urlby Rochdi Badis
Caché
HELP DOUBTS MSM-MUMPS-UNIXby Roger Andre
CSP event log errorby Paul Coviello
ASTM-XML | ASTM E1394 Specification anyone?by Patrick Halloran
Purge/Delete a RecordMap Batch before roll-over. by Blake Herlick
Dynamic SQL query on record that is lockedby MARK PONGONIS
SQL ODBC Warnings On Null Values in a Stored Procedureby Thembelani Mlalazi
Zen errorby Lowell Buschert
Laravel and Cache DBby Ramil TK
Problem converting Image to Base64by Fabio Care
How to obtain object value in DTL Trace Eventby Daniel Lee
VSCode
How i can test POST in Rest APIby Luiz Henrique Carvalho Martarelli
Syntax highlighting in VS Code markdownby Gertjan Klein
TrakCare
Trakcare Report development Using Object Scriptby Ramil TK
Documentation
Process XML documentby Adrian Izadpanah
E agora é a hora de anunciar as Perguntas Chave de Julho escolhidas pelos Especialistas InterSystems!
Estas perguntas serão destacadas com a tag #Key Question e seus autores irão receber o distintivo Key Question no Global Masters!
Então, aqui estão as perguntas escolhidas no mês de Julho de 2022:
📌 Delete first part of HL7 field up to first "(" character de @Jonathan.Harris
📌 Web teminal : lost connection with server (code 1006) de @Jules.Pontois8611
📌 Bulk Testing Business Process (Rules) de @Scott.Roth
📌 Interoperability - Interface Maps de @Scott.Roth
Obrigado pela contribuição!
Nos vemos no mês que vem! Continuem a mandar suas perguntas ;)
Artigo
Heloisa Paiva · Maio 29, 2023
Programação e suas linguagens
Ser um programador hoje em dia é basicamente uma versão nerd de ser um poliglota. Claro, a maioria de nós aqui na comunidade InterSystems "falamos ObjectScript". Entretando, eu acredito que essa não foi a primeira língua de muita gente. Por exemplo, eu nunca tinha ouvido falar nela antes de receber o treinamento apropriado na Innovatium.
A parte mais fascinante disso é que mesmo que sejamos aptos a aprender qualquer linguagem e nos tornar fluentes nela, sempre teremos nossas favoritas - as que nos sentimos mais confortáveis e familiares. Geralmente isso tem muito a ver com a primeira linguagem que aprendemos.
Pensando nisso, me deparei com a ideia Make JSON representation of messages in Interoperability message viewer instead of XML no portal de Ideias InterSystems e descobri que @Guillaume.Rongier7183 já resolveu isso para nós. Meu objetivo nesse artigo é mostrar como usar a solução dele e discutir sobre algumas utilidades.
O contexto
Para cada produção que construímos, o Portal de Administração do InterSystems IRIS cria uma interface que exibe todos os componentes conectados e cada mensagem relacionada a seu comportamento.
A figura acima ilustra o Portal de Configurações de Produção, onde você pode ver todos os Business Services, Processes e Operations, divididos em categorias de sua escolha. Para cada um, você pode checar e/ou alterar configurações gerais ou personalizadas, além de executar ações como mudar o estado, testar, exportar, checar os jobs, filas e logs relacionados a eles, etc. No entando, o que é mais importante para nós agora é a possibilidade de checar as mensagens.
Selecionando Mensagens na aba a direita, você poderá ver uma tabela com todas as mensagens relacionadas a essa produção. Ao mesmo tempo, se clicar em Ir Ao Visualizador de Mensagens você verá uma tabela mais detalhada com várias opções de filtros. Além disso, se escolher um componente Business antes de selecionar a aba de mensagens, verá apenas as mensagens da produção que se comunicam com o componente designado.
Nessa outra figura, podemos observar o Visualizador de Mensagens e finalmente resgatar a informação que queremos. Se selecionar uma linha na tabela, abrirá uma sessão a direita com todo detalhe possível sobre a mensagem escolhida. Isso significa que terá uma aba para a Header (cabeçalho), outra para o Body (corpo), mais uma para Tracing (rastreamento) e uma com um diagrama que mostra de onde a mensagem veio e os componentes relacionados. A aba que procuramos é a Contents (conteúdos).
A aba de conteúdos nos mostra uma versão em XML da mensagem e hoje vamos mudá-la para uma versão em JSON.
PS.: você também pode clicar no número da Sessão na tabela para obter uma visão focada do rastreamento ao lado da aba de Header, Body e Contents, como exemplificado na imagem abaixo
Desvio!
Essa sessão tem o objetivo de ser um pequeno desvio sobre o básico de construir uma API, um caso comum que utiliza muito JSON, e para familiarizar o contexto onde a aplicação pode ajudar.
Para trazer um sentimento real das alterações que essa aplicação promove, vamos construir um exemplo simples de uma API que recebe alguma informação numa request HTTP em formato JSON. Se já está familiarizado com APIs, sinta-se à vontade para pular para a próxima sessão, embora eu recomende pelo menos dar uma olhada nessa. Assim, você acompanhará melhor os exemplos discutidos a frente.
Eu vou seguir as boas práticas da Innovatium, mas lembre-se que esse não é o único jeito possível de fazer.
Primeiro, precisamos criar um service Dispatch, extendendo %CSP.REST e Ens.BusinessService, com o adaptador EnsLib.HTTP.InboundAdapter que lida requisições HTTP recebidas. Devemos especificar se o serviço lida com requisições CORS. Também podemos opcionalmente implementar o método de classe OnHandleOptionsRequest e finalmente definir um XData URlMap com parâmetros de Map, que dão seguimento para a próxima classe que vamos criar.
Class Sample.Service.Dispatch Extends (%CSP.REST, Ens.BusinessService)
{
Parameter HandleCorsRequest = 1;
Parameter ADAPTER = "EnsLib.HTTP.InboundAdapter";
XData UrlMap [ XMLNamespace = "http://www.intersystems.com/urlmap" ]
{
<Routes>
<Map Prefix="/send" Forward="Sample.Service.Send"/>
</Routes>
}
ClassMethod GetService(Output tService As Ens.BusinessService) As %Status
{
Quit ##class(Ens.Director).CreateBusinessService(..%ClassName(1), .tService)
}
ClassMethod OnHandleOptionsRequest(url As %String) As %Status
{
; your code here
}
}
Então, no Portal de Administração criamos uma aplicação web com REST habilitado com a classe que acabamos de criar como a classe Dispatch.
Em seguida, desenvolvemos uma classe, que estende a Dispatch, com um XData UrlMap com parâmetros Route e construímos o método que vai de fato lidar com a requisição recebida. Isso também poderia ter sido feito direto no serviço de Dispatch. Através desse método, você pode fazer o que quiser com a requisição. No entanto, vamos focar em receber um JSON, transformá-lo em um objeto e enviar a um Business Operation que será responsável por lidar com a informação de qualquer forma necessária.
Class Sample.Service.Send Extends Sample.Service.Dispatch
{
Parameter CONTENTTYPE = "application/json";
Parameter CHARSET = "utf-8";
XData UrlMap [ XMLNamespace = "http://www.intersystems.com/urlmap" ]
{
<Routes>
<Route Method="POST" Url="/message" Call="SendMessage"/>
</Routes>
}
ClassMethod SendMessage() As %Status
{
Set tSC = $$$OK
Try
{
#Dim %request As %CSP.Request
#Dim %response As %CSP.Response
#Dim Service As Ens.BusinessService
Set %response.ContentType = "application/json"
Set %response.CharSet = "utf-8"
; code for authentication - this part was cut out for simplification
; in this part I set the variables tUsername and tBasicAuth, used to create the request below.
; implementing authentication is optional, this is just an example
// creates service
Set tSC = ..GetService(.tService)
If $System.Status.IsError(tSC) Quit
// gets request body
Set tReceived = ##class(%Stream.GlobalCharacter).%New()
Set tSC = tReceived.CopyFrom(%request.Content)
If $System.Status.IsError(tSC) Quit
Set tMessage = ##class(%DynamicObject).%FromJSON(tReceived)
// creates request object for the business operation
Set tRequest = ##Class(Sample.Operation.SendMessage.Request).%New()
Set tRequest.Message = tMessage.message
Set tRequest.token = tBasicAuth
Set tRequest.Username = tUsername
Set tSC = tService.SendRequestSync("Sample.Operation",tRequest,.tResponse)
If $System.Status.IsError(tSC) Quit
// treats response
If $IsObject(tResponse)
{
Set tSC = tResponse.CopyToObject(.tJSON)
Quit:$$$ISERR(tSC)
}
Set tResult = ##class(%Stream.GlobalCharacter).%New()
Do tResult.Write(tJSON.%ToJSON())
Do tResult.OutputToDevice()
}
Catch Ex
{
Set tSC = Ex.AsStatus()
}
Quit tSC
}
}
É bom saber, mas por que eu deveria me incomodar?
Nessa sessão, vou tentar te convencer que é uma boa ideia ter a opção de mostrar o conteúdo de suas mensagens em formato JSON.
JSON é também legível por humanos, significando que você pode abrir um arquivo e ver o que está dentro dele sem ter que executá-lo por um parser Isso faz problemas de debug com seu código mais acessível e ajuda a documentar os dados recebidos de outras aplicações. (tradução livre)
É claro, às vezes "se sentir confortável" com uma linguagem não é suficiente para mudar algo na sua rotina de trabalho, afinal a mudança em si pode não ser confortável. No entanto, na API que acabamos de construir, há algumas outras coisas a se considerar além da questão de conveniência. Podemos notar que o código não foi escrito em XML em nada, então vê-lo nessa linguagem adicionaria um novo nível de complexidade.
Deixe-me explicar essa complexidade. Ainda que não pareça fazer uma grande diferença para um desenvolvedor ler uma simples mensagem com apenas uma propriedade string em tags (<tags>) ou formato JSON, também é importante fazer essa mensagem parecer familiar para os não-desenvolvedores que podem ter acesso a esse portal e devem ser capazes de entender de um modo geral o processamento da informação, já que JSON é muito mais amigável ao usuário. Além disso, quando as mesagens carregam propriedades de outros objetos ou tipos, somente serão enviadas adequadamente em JSON se têm a adaptação apropriada para isso. O IRIS torna isso fácil de resolver simplesmente estendendo a classe %JSON.Adaptor. Ao mesmo tempo, mensagens só aparecerão no Visualizador de Mensagens se têm a adaptação adequada para XML, que o IRIS também torna fácil estendendo %XML.Adaptor. Ainda assim, se o Visualizador de Mensagens mostrasse em JSON, esse último problema não existiria. De forma prática, isso significa diminuir a quantidade de dependências do projeto, o que, em idioma humano, significa reduzir o número de coisas que podem dar errado enquanto desenvolve e quando atualizações futuras do projeto ou até mesmo do IRIS saírem. E além de tudo, você não precisa de um time capacitado para lidar com XML.
Por fim, quando o time está procurando por erros e testando a API, você tem o formato exato da requisição recebida logada no Visualizador de mensagens, então é apenas uma questão de copiar e colar para testar em plataformas como Postman e outras para entender exatamente o que o sistema está lendo e escrevendo.
Se você quer saber ainda mais sobre os prós e contras de XML e JSON, eu recomendo fortemente que dê uma olhada no artigo json-vs-xml, que fornece uma incrível discussão sobre situações onde ambos são usados. A citação acima foi tirada desse website.
Ok, isso é demais! Me mostre como se usa!
Instalando
Você pode instalar com ZPM digitando no seu terminal no namespace desejado:
zpm "install objectscript-json-trace-viewer"
Outra opção é entrar no modo ZPM digitando zpm e então digitarinstall objectscript-json-trace-viewer
Se você não tem uma instância de IRIS na sua máquina, outra opção para testar é clonar o repositório e executar docker-compose build e então docker-compose up -d. Uma vez que tenha terminado de rodar o container, abra o link http://localhost:52777/csp/sys/UtilHome.csp?$NAMESPACE=DEMO e entre com usuário _SYSTEM e senha SYS para ver como funciona. Você também pode checar os códigos do repositório GitHub para exemplos de implementação.
Usando
Para cada classe que quer rastrear como JSON e não XML, adicione "Grongier.JsonTraceViewer.Message" para a lista de extensões ou qualquer de suas subclasses. Essa é a minha classe de Request do exemplo da última sessão:
Class Sample.Operation.SendMessage.Request Extends (Grongier.JsonTraceViewer.Request, Ens.Request)
{
Parameter XMLTYPE = "RequestSample";
Parameter RESPONSECLASSNAME = "Sample.Operation.SendMessage.Response";
Property Message As %String;
Property Username As %String;
Property token As %String;
}
Agora, ao chamar a API novamente, o Visualizador de Mensagens exibe o conteúdo como a imagem a seguir:
Erros que você pode enfrentar
Erro ao tentar executar o docker-compose build:
failed to solve: rpc error: code = Unknown desc = failed to solve with frontend dockerfile.v0: failed to create LLB definition: docker.io/store/intersystems/iris-community:2020.2.0.196.0: not found
SOLUCIONADO ao abrir a Dockerfile e mudar o valor de ARG IMAGE para uma imagem disponível no seu docker. Outra opção é usar a InterSystems extension de CaretDev e executar um pull na imagem iris-community mais recente. No meu caso, a primeira linha da Dockerfile ficou assim:
ARG IMAGE=containers.intersystems.com/intersystems/iris-community:2023.1.0.229.0
Erro ao tentar rodar o container:
#12 19.05 Error: ERROR #5001: Could not start SuperServer on port 1972, may be in use by another instance - Shutting down the system : $zu(56,2)=$Id: //iris/2023.1.0/kernel/common/src/journal.c#3 $ 10906 0Starting IRIS
failed to solve: executor failed running [/irissession.sh do $SYSTEM.OBJ.Load("Installer.cls", "ck") set sc = ##class(App.Installer).setup() do $system.OBJ.Load("/tmp/deps/zpm.xml", "ck") zn "DEMO"]: exit code: 225
SOLUCIONADO ao parar qualquer instância de IRIS existente na máquina e tentar rodar novamente.
Erro ao tentar rodar o container:
Error response from daemon: Ports are not available: exposing port TCP 0.0.0.0:52777 -> 0.0.0.0:0: listen tcp 0.0.0.0:52777: bind: An attempt was made to access a socket in a way forbidden by its access permissions.
SOLUCIONADO no Windows ao executar o terminal do sistema como administrador e rodar o comando a seguir. Esse erro pode ocorrer se a porta escolhida já estiver sendo usada. Você pode simplesmente alterá-lal no docker-compose.yml ou parar o processo que a esteja utilizando.
net stop hns
net start hns
Erro ao compilar classes personalizadas usando as classes deJsonTraceViewer:
Error #6281: XMLTYPE of Sample.Operation.SendMessage.Request class must be able to differentiate child classes of Grongier.JsonTraceViewer.Request.
> Error #5090: An error occurred while creating projection Grongier.JsonTraceViewer.Request:XMLEnabled.
SOLUCIONADO ao adicionar "Parameter XMLTYPE = 'type'" para toda classe que estende Grongier.JsonTraceViewer.Message, e alterando "type" por tipos únicos para cada classe.
Artigo
Guilherme Koerber · Dez. 21, 2021
Trabalhando com suporte, geralmente me perguntam por quantos dias devo manter um journals. Deve demorar dois dias ou depois de dois backups? Mais? Menos? Por que dois?
A resposta correta (para a maioria dos ambientes) é que você deve manter os journals desde o último backup validado. Ou seja, até que você não verifique se um backup é válido (restaurando o arquivo e verificando com o utilitário de integridade), você não pode ter certeza de que há uma boa cópia de seus dados e não pode limpar os journals com segurança.
Por exemplo, imagine que você precise restaurar seu sistema após uma falha de hardware que corrompeu alguns bancos de dados. A primeira etapa é ir aos últimos backups e restaurá-los. Mas, o que acontece se o backup for corrompido ou salvo em um disco com defeito? Você precisará procurar um backup anterior até encontrar uma cópia correta e limpa. Então, se você quiser se recuperar até o último momento, precisará aplicar os journals. Se você tiver apenas um ou dois dias, não será o suficiente e poderá perder dados.
A única maneira de ter certeza de que seus backups são válidos é verificando-os! E para verificar, quero dizer restaurar os bancos de dados e validar os dados neles. A maneira de verificar os dados dentro de um banco de dados é usando o utilitário Integrity.
Quando explico isso, a maioria dos administradores considera uma tarefa complexa, que leva muito tempo e é difícil de automatizar. Então, decidi construir um verificador / validador de backup super simples que ajuda você a validar backups facilmente. Estou enviando o utilitário para o site de troca aberta.
O utilitário é um verificador / validador de backup simples para backups feitos com o InterSystems Iris. Ele restaurará seu arquivo de backup (.cbk) automaticamente e executará um relatório de integridade posteriormente. Toda a "mágica" é feita no método restoreAll da classe Installer. Você pode pegar o código emprestado e melhorá-lo para enviar um e-mail quando terminar com os resultados.
Depois que o backup for restaurado e a verificação de integridade executada, o docker log (e messages.log) conterá os resultados da verificação de restauração e integridade. Os bancos de dados restaurados aparecerão em uma pasta Restaurar.
Pergunta
Fernando Beira · Mar. 2, 2022
Pessoal, tudo bem!?
Na instituição que trabalho estou enfrentando algo inusitado, temos duas instancias EC2 (AWS) em mirror e durante algum tempo em funcionamento a instância primaria nos lança um erro no message.log dizendo o seguinte (Journal Daemon has been inactive with I/O pending for 10 seconds) e em seguida efetua o chaveamento de máquina para o nó 2 da configuração, isso esta ocorrendo com uma frequência grande impactando a operação.
A infra diz que o link está com 50% de carga e em teoria não há gargalo na comunicação.
Trecho do message.log:
Sabem se pode ser alguma configuração relacionada aos discos virtuais da AWS?
Gostaria de saber se alguém já passou por esse tipo de situação? E como devemos proceder?
Desde já agradeço! Bom dia Fernando,
Você sabe qual foi o tipo de disco associado a estás máquinas EC2 na AWS?
Existem diversos tipos de discos lá inclusive os de baixa performance, se forem os do tipo magnético. Oi Djeniffer, obrigado pelo retorno!
Estamos com discos GP2 com block size de 4KB. Olá Fernando,
Seria importante realizar um teste utilizando discos do tipo gp3, pois o gp2 tem uma limitação bem especifica no "Max throughput per volume" e já tivemos problemas com ele devido a isso.
Aqui tem um link com estas diferenças entre os discos: https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ebs-volume-types.html Oi Djeniffer,
Compartilhei seu retorno com o pessoal que tem acesso a conta da AWS e descobrimos que a tempo atrás tivemos uma GMUD que realmente mudou o tipo do disco e efetuamos o rollback.
O ambiente está estável já a um dia e meio com poucas entradas no log, apenas do sincronismo do journal do mirror e alguns outros por menores, sem qualquer tipo de menção ao Deamon.
Agora, o que é interessante é que, segundo o Analista que efetuou a mudança dos discos, estávamos com o tipo GP3 e voltamos a usar o GP2 sem mexer em qualquer configuração de IOPS.
De qualquer forma criamos um ticket com a InterSystems para avaliação e seguimos monitorando daqui.
Muito obrigado pela ajuda!!
Olá Fernando,
Ótimo.
Pergunta
Guilherme Koerber · Set. 9, 2021
Olá comunidade!
Estou enfrentando um problema de crescimento da base, que está sendo gerado por um processo e por uma característica do Ensemble.
Ao executar o processo de limpeza das filas de mensagens o Ensemble “preserva” as Streams que fizeram parte dessas mensagens apagando somente o Header e Body. Desta forma a base de dados (de um dos namespaces) tem crescido cerca de 60GB por dia, o que vem estourando a capacidade do disco.
A InterSystems informou que isso se trata de uma característica e que está explicado nos documentos abaixo mencionados.
https://community.intersystems.com/post/ensemble-orphaned-messages
E também nesta parte da documentação: https://cedocs.intersystems.com/ens201812/csp/docbook/DocBook.UI.Page.cls?KEY=EGMG_purge_basic
Penso que o procedimento é implementar a remoção desses objetos tipo stream no método %OnDelete() da classe referente a essa mensagem, porém a complexidade dessa mensagem faz com que essa propriedade específica não seja alcançada pelo purge padrão. A stream não é exatamente o que tem no conteúdo, pois dentro dele você pode ter campos do tipo Stream, GlobalCharacterStream, etc.São esses campos que ele não apaga e ele deveria apagar. Pelo que entendi os dados ficam dentro de uma global chamada ^CacheStream e de lá elas nunca são apagadas.
Com isso estou tendo dificuldades em saber o que tem dentro dela, o que é de cada interface e o que ainda está sendo usado. Tendo em vista que ela não tem ligação direta com as classes de Stream.
Alguém já teve um problema assim que possa me auxiliar?
Desde já agradeço,
Guilherme Koerber. Olá Guilherme,
Na sua classe de mensagens você possui uma propriedade que aponta a outro objeto que possui stream ou a propriedade já é stream?
Pergunto pois já tive essa situação diversas vezes e resolvemos isso com uma mudança na classe de mensagens para não mais referenciar outros objetos. Djeniffer,De fato, esta apontado para um objeto. Irei tentar adaptar a classe para não referenciar mais objetos.Obrigado pela sugestão! =D Olá Guilherme,
Exato, o que fizemos aqui em algumas integrações foi converter o XML em uma FileCharacterStream e quando é necessário usar este objeto fazemos o correlate dele diretamente na BO, ai só existe o tráfego dessas streams e não mais dos objetos externos que dificultam o processo de limpeza.
Se precisar de alguma ajuda me informe.
Anúncio
Angelo Bruno Braga · jan 16, 2023
Olá Comunidade!
Temos o prazer de dar as boas-vindas a @Niu.Yuxiang como nosso novo moderador na equipe da Comunidade de Desenvolvedores!
Vamos cumprimentar @Niu.Yuxiang com muitos aplausos e dar uma olhada em sua biografia!
@Niu.Yuxiang é atualmente o líder da equipe clínica do Centro de Informações do Beijing Friendship Hospital, Capital Medical Universit
Aqui está uma breve introdução sobre @Niu.Yuxiang:
Tenho quase 10 anos de experiência em informatização da área médica. Atualmente lidero uma pequena equipe focada em pesquisa aplicada e desenvolvimento de sistemas de informação hospitalar (Hospital Information System, HIS) baseado no banco de dados Caché. Nossa equipe está familiarizada com HTML, CSS, JavaScript e linguagens de front-end derivadas. Nosso trabalho diário se concentra principalmente no desenvolvimento de funções correspondentes de acordo com as necessidades do usuário e na otimização constante das funções do programa com base nas dificuldades e pontos problemáticos do negócio clínico. Após dois anos de estudo e esforços, nossa equipe concluiu um total de mais de 1.000 novas funções clínicas e requisitos de otimização. Com o desenvolvimento de nosso departamento de TI, nossa força de desenvolvimento se tornará cada vez mais forte, o que pode garantir melhor a resposta oportuna às necessidades clínicas, otimizar e melhorar constantemente os bugs do sistema e melhorar a eficiência do trabalho clínico. Ao mesmo tempo, também atuei como membro da equipe de emergência, responsável pela operação do banco de dados e solução de problemas, para garantir a solução de problemas a tempo.
A plataforma de dados da InterSystems é uma excelente plataforma de integração que traz grande comodidade ao nosso negócio com o auxílio desta tecnologia. Também espero que essa excelente tecnologia possa agregar valor para mais unidades irmãs e parceiros. Também espero me comunicar com outras pessoas da comunidade e compartilhar um pouco da minha experiência prática. Ao mesmo tempo, também espero usar esta plataforma para aprender algumas práticas excelentes com você. Vamos crescer e progredir juntos!
Obrigado e parabéns, @Niu.Yuxiang! 👏🏼
Espero que você seja um ótimo moderador! Desejamos-lhe uma ótima viagem pela Comunidade de Desenvolvedores!
Artigo
Henry Pereira · Maio 30

Sabe aquela sensação de receber o resultado do seu exame de sangue e parecer que está em grego? É exatamente esse problema que o **FHIRInsight** veio resolver.
Surgiu da ideia de que dados médicos não deveriam ser assustadores ou confusos – deveriam ser algo que todos podemos utilizar. Exames de sangue são extremamente comuns para verificar nossa saúde, mas, sejamos sinceros, interpretá-los é difícil para a maioria das pessoas e, às vezes, até para profissionais da área que não trabalham em um laboratório.
O **FHIRInsight** quer tornar todo esse processo mais simples e acessível.

## 🤖 Por que criamos o FHIRInsight
Tudo começou com uma simples pergunta:
> “Por que interpretar um exame de sangue ainda é tão difícil — até para médicos, às vezes?”
Se você já olhou para um resultado de laboratório, provavelmente viu um monte de números, abreviações enigmáticas e uma “faixa de referência” que pode ou não se aplicar à sua idade, sexo ou condição.
É uma ferramenta de diagnóstico, com certeza — mas sem contexto, vira um jogo de adivinhação. Até profissionais de saúde experientes às vezes precisam recorrer a diretrizes, artigos científicos ou opiniões de especialistas para entender tudo direito.
É aí que o **FHIRInsight** entra em cena.
Não foi feito apenas para pacientes — fizemos para quem está na linha de frente do atendimento. Para médicos em plantões intermináveis, para enfermeiros que captam sutis padrões nos sinais vitais, para qualquer profissional de saúde que precise tomar decisões certas com tempo limitado e muita responsabilidade. Nosso objetivo é facilitar um pouco o trabalho deles — transformando dados clínicos FHIR em algo **claro, útil e fundamentado em ciência médica real**. Algo que fale a língua humana.
O FHIRInsight faz mais do que só explicar valores de exames. Ele também:
- **Fornece aconselhamento contextual** sobre se um resultado é leve, moderado ou grave
- **Sugere causas potenciais e diagnósticos diferenciais** com base em sinais clínicos
- **Recomenda próximos passos** — sejam exames adicionais, encaminhamentos ou atendimento de urgência
- **Utiliza RAG (Retrieval-Augmented Generation)** para incorporar **artigos científicos relevantes** que fundamentam a análise
Imagine um jovem médico revisando um hemograma de um paciente com anemia. Em vez de buscar cada valor no Google ou vasculhar revistas médicas, ele recebe um relatório que não só resume o problema, mas cita estudos recentes ou diretrizes da OMS que embasam o raciocínio. Esse é o poder de combinar **IA** e **busca vetorial sobre pesquisas selecionadas**.
E o paciente?
Ele não fica mais diante de um monte de números, sem saber o que significa “bilirrubina 2,3 mg/dL” ou se deve se preocupar.
Em vez disso, recebe uma explicação simples e cuidadosa. Algo que se assemelha mais a uma conversa do que a um laudo clínico. Algo que ele realmente entende — e que pode levar ao consultório do médico mais preparado e menos ansioso.
Porque é disso que o **FHIRInsight** trata de verdade: **transformar complexidade médica em clareza** e **ajudar profissionais e pacientes a tomarem decisões melhores e mais confiantes** — juntos.
## 🔍 Por dentro da tecnologia
Claro que toda essa simplicidade na superfície é viabilizada por uma tecnologia poderosa atuando discretamente nos bastidores.
Veja do que o FHIRInsight é feito:
- **FHIR (Fast Healthcare Interoperability Resources)** — padrão global de dados de saúde. É assim que recebemos informações estruturadas como resultados de exames, histórico do paciente, dados demográficos e atendimentos. O FHIR é a linguagem que os sistemas médicos falam — e nós traduzimos essa linguagem em algo que as pessoas possam usar.
- **Busca Vetorial RAG (Retrieval-Augmented Generation)**: o FHIRInsight aprimora seu raciocínio diagnóstico indexando **artigos científicos em PDF e URLs confiáveis** em um **banco de dados usando a busca vetorial nativa do InterSystems IRIS**. Quando um resultado de exame fica ambíguo ou complexo, o sistema recupera conteúdo relevante para embasar suas recomendações — não da memória do modelo, mas de **pesquisas reais e atualizadas**.
- **Engenharia de Prompts para Raciocínio Médico**: refinamos nossos prompts para guiar o LLM na identificação de um amplo espectro de condições relacionadas ao sangue. Desde anemia por deficiência de ferro até coagulopatias, desequilíbrios hormonais ou gatilhos autoimunes — o prompt conduz o LLM pelas variações de sintomas, padrões laboratoriais e causas possíveis.
- **Integração com LiteLLM**: um adaptador customizado direciona requisições para múltiplos provedores de LLM (OpenAI, Anthropic, Ollama etc.) através de uma interface unificada, permitindo fallback, streaming e troca de modelo com facilidade.
Tudo isso acontece em segundos — transformando valores brutos de laboratório em **insights médicos explicáveis e acionáveis**, seja para um médico revisando 30 prontuários ou um paciente tentando entender seus números.
## 🧩 o Adapter LiteLLM: Uma Interface para Todos os Modelos
Nos bastidores, os relatórios do FHIRInsight movidos a IA são impulsionados pelo **LiteLLM** — uma library python que nos permite chamar mais de **100 LLMs** (OpenAI, Claude, Gemini, Ollama etc.) por meio de uma única interface estilo OpenAI.
Porém, integrar o LiteLLM ao **InterSystems IRIS** exigiu algo mais permanente e reutilizável do que scripts Python escondidos numa Business Operation. Então, criamos nosso próprio **Adapter LiteLLM**.
### Conheça o `LiteLLMAdapter`
Esse adaptador lida com tudo o que você esperaria de uma integração robusta de LLM:
- Recebe parâmetros como `prompt`, `model` e `temperature`
- Carrega dinamicamente variáveis de ambiente (por exemplo, chaves de API)
Para encaixar isso em nossa produção de interoperabilidade em um simples **Business Operation**:
- Gerencia configuração em produção por meio da configuração padrão `LLMModel`
- Integra-se ao componente FHIRAnalyzer para geração de relatórios em tempo real
- Atua como uma “ponte de IA” central para quaisquer componentes futuros que precisem de acesso a LLM
Eis o fluxo de forma simplificada:
```
set response = ##class(dc.LLM.LiteLLMAdapter).CallLLM("Me fale sobre hemoglobina.", "openai/gpt-4o", 0.7)
write response
```
## 🧪 Conclusão
Quando começamos a desenvolver o FHIRInsight, nossa missão era simples: **tornar exames de sangue mais fáceis de entender — para todo mundo**. Não apenas pacientes, mas médicos, enfermeiros, cuidadores... qualquer pessoa que já tenha encarado um resultado de laboratório e pensado: “Ok, mas o que isso realmente significa?”
Todos nós já passamos por isso.
Ao combinar a estrutura do FHIR, a velocidade do InterSystems IRIS, a inteligência dos LLMs e a profundidade de pesquisas médicas reais via busca vetorial, criamos uma ferramenta que transforma números confusos em histórias significativas. Histórias que ajudam pessoas a tomarem decisões mais inteligentes sobre sua saúde — e, quem sabe, detectar algo cedo que passaria despercebido.
Mas o FHIRInsight não é só sobre dados. É sobre **como nos sentimos ao olhar para esses dados**. Queremos que seja claro, acolhedor e empoderador. Que a experiência seja... como um verdadeiro **“vibecoding” na saúde** — aquele ponto perfeito onde código inteligente, bom design e empatia humana se encontram.
Esperamos que você experimente, teste, questione — e nos ajude a melhorar.
Diga o que gostaria de ver no próximo release. Mais condições? Mais explicações? Mais personalização?
Isso é só o começo — e adoraríamos que você ajudasse a moldar o que vem a seguir.
Artigo
Ron Sweeney · Fev. 10, 2021
Se você está procurando uma maneira inteligente de integrar sua solução IRIS no ecossistema Amazon Web Services, aplicativos sem servidor ou script python baseado em `boto3`, usar a [API Nativa IRIS para Python](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=AFL_PYNATIVE) pode ser o caminho a seguir. Até que você precise obter ou definir algo no IRIS, você não tem que ir muito longe com uma implementação em produção para fazer sua aplicação funcionar de um maneira incrível, então, espero que você encontre valor neste artigo e construa algo que seja importante para outros ou somente para você, pois ambos são igualmente válidos.

Se você está procurando algumas justificativas para implementar isso:
* Você precisa acertar a trigger de geração de pré-token no Cognito para pesquisar e inserir o contexto de ID do paciente no token para uma solução baseada em SMART on FHIR(R) implementando um fluxo de trabalho com OAUTH2.
* Você deseja publicar as configurações de ajuste de provisionamento do IRIS com base no tipo de instância, grupo de nós, toaster ou cluster ECS que você disparou para executar o IRIS no anel zero.
* Você quer impressionar a família e os amigos no Zoom com suas habilidades de gerenciamento do IRIS sem que o seu shell saia da AWS cli.
## O ponto
Aqui, vamos provisionar uma função lambda da AWS que se comunica com o IRIS e fornecer alguns exemplos sobre como provisioná-la e como interagir com ela em várias capacidades, na esperança de que possamos discutir sobre isso e **publicá-la no pip para tornar as coisas mais fáceis.**
## Com pressa????

Confira o streaming
## Em todo o caso...
Para participar da diversão, você precisará definir algumas coisas em seu plano de voo.
### Rede
Você tem o IRIS em execução da maneira que deseja, rodando em uma AWS VPC com exatamente duas sub-redes e um grupo de segurança que permite acesso ao super servidor rodando IRIS... usamos 1972 por motivos nostálgicos e pelo simples fato de que a InterSystems se deu ao trabalho de registrar essa porta no [IANA](https://tools.ietf.org/html/rfc6335), e se você adicionar a nova porta em `/etc/services` sem fazer isso, não é a melhor prática, mas tudo bem. Em nosso caso, é um conjunto de instâncias EC2 espelhadas com verificações de integridade adequadas em torno de um balanceador de carga de rede AWS v2.
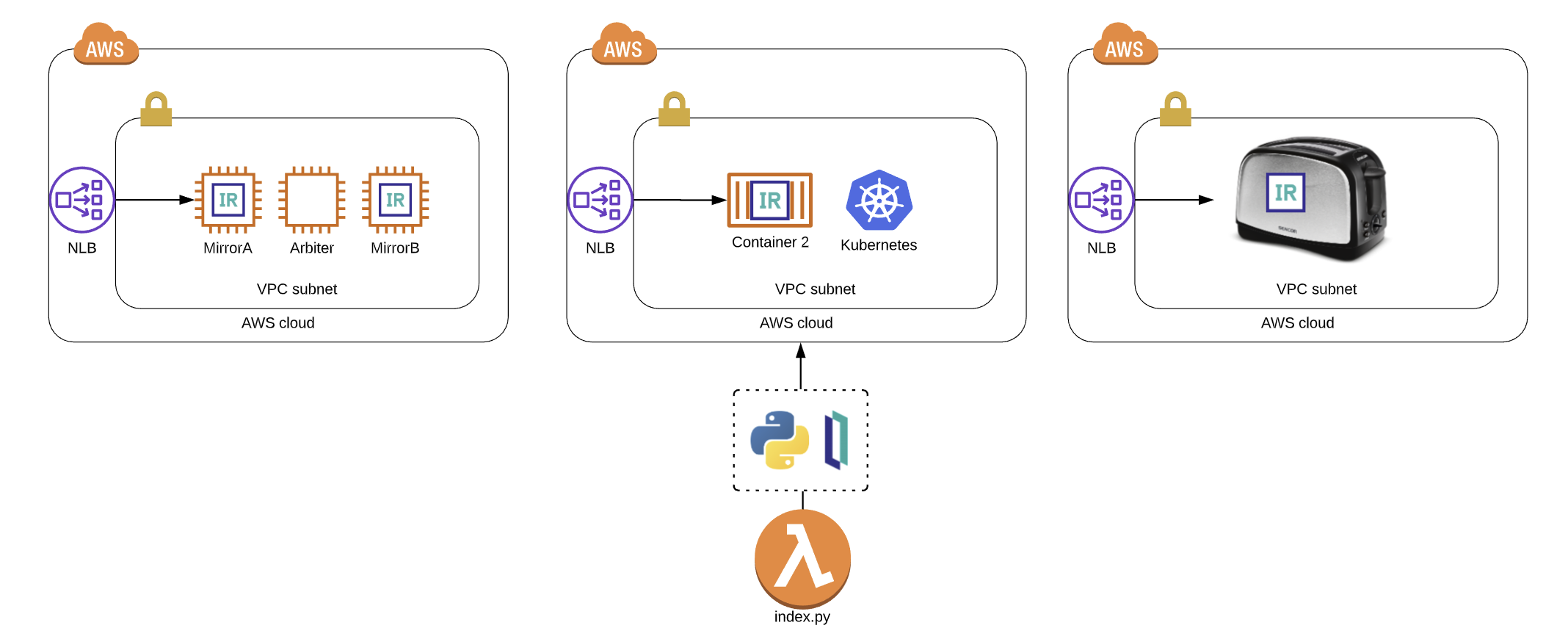
### Classe de exemplo importada
De alguma forma, você conseguiu criar e importar a classe na raiz deste repositório para o namespace `%SYS` em sua instância IRIS. A seguir está um exemplo da classe que gera a saída acima. Se você está se perguntando por que precisamos importar uma classe aqui, consulte a nota abaixo, onde a abordagem recomendada é provisionar algumas classes de wrapper para uso por meio do python.
> Nota do Docs: Embora esses métodos também possam ser usados com as classes InterSystems definidas na Biblioteca de Classes, a melhor prática é chamá-las indiretamente, de dentro de uma classe ou rotina definida pelo usuário. Muitos métodos de classe retornam apenas um código de status, passando os resultados reais de volta em um argumento (que não pode ser acessado pela API nativa). As funções definidas pelo sistema (listadas em Funções ObjectScript na Referência ObjectScript) não podem ser chamadas diretamente.
Classe de Exemplo:
```
Class ZDEMO.IRIS.Lambda.Operations Extends %Persistent
{
ClassMethod Version() As %String
{
Set tSC = 0
Set tVersion = $ZV
if ( tVersion '="" ) { set tSC = $$$OK }
Set jsonret = {}
Set jsonret.status = tSC
Set jsonret.payload = tVersion
Quit jsonret.%ToJSON()
}
}
```
Observe acima que decidi trabalhar com base na convenção de sempre retornar um objeto JSON como uma resposta, que também me permite retornar o status e possivelmente preencher a lacuna ao retornar algumas coisas por referência.
### Acesso AWS
Obtenha algumas chaves de acesso IAM que permitirão que você provisione e invoque a Função Lambda com a qual iremos mudar o mundo.
Verificação antes do voo:
```
IRIS [ $$$OK ]
VPC [ $$$OK ]
Subnets [ $$$OK ]
Security Group [ $$$OK ]
IAM Access [ $$$OK ]
Imported Class [ $$$OK ]
```
$$$OK, **Vamos lá**.
## Empacotando a API Nativa IRIS para Python para uso na Função Lambda
Esta é a parte que seria fantástica se fosse um pacote pip, especialmente se fosse apenas para Linux, já que as funções da AWS Lambda são executadas no BoXenLinux. No momento deste commit, a API não está disponível via pip, mas somos engenhosos e podemos lançar a nossa própria.
```
mkdir iris_native_lambda
cd iris_native_lambda
wget https://github.com/intersystems/quickstarts-python/raw/master/Solutions/nativeAPI_wheel/irisnative-1.0.0-cp34-abi3-linux_x86_64.whl
unzip nativeAPI_wheel/irisnative-1.0.0-cp34-abi3-linux_x86_64.whl
```
Crie `connection.config`
Exemplo: [connection.config](https://raw.githubusercontent.com/basenube/iris_native_lambda/main/examples/connection.config)
Crie seu manipulador, `index.py` ou use aquele na pasta de exemplos, no [repositório de demonstração no GitHub](https://github.com/basenube/iris_native_lambda). Observe que a versão de demonstração usa variáveis de ambiente e um arquivo externo para as informações de conectividade IRIS.
Exemplo:
[index.py](https://raw.githubusercontent.com/basenube/iris_native_lambda/main/examples/index.py)
Agora compacte-o para uso:
```
zip -r9 ../iris_native_lambda.zip *
```
Crie um bucket S3 e carregue o zip de função nele.
```
cd ..
aws s3 mb s3://iris-native-bucket
s3 sync iris_native_lambda.zip s3://iris-native-bucket
```
> Isso conclui o empacotamento da API e do manipulador para uso como uma função AWS Lambda.
Agora, clique no console para criar a função ou use algo como o Cloudformation para executar o trabalho:
```
IRISAPIFunction:
Type: "AWS::Lambda::Function"
DependsOn:
- IRISSG
- VPC
Properties:
Environment:
Variables:
IRISHOST: "172.31.0.10"
IRISPORT: "1972"
NAMESPACE: "%SYS"
USERNAME: "intersystems"
PASSWORD: "lovetheyneighbor"
Code:
S3Bucket: iris-native-bucket
S3Key: iris_native_lambda.zip
Description: "Função API Nativa IRIS para Python"
FunctionName: iris-native-lambda
Handler: "index.lambda_handler"
MemorySize: 128
Role: "arn:aws:iam::8675309:role/BeKindtoOneAnother"
Runtime: "python3.7"
Timeout: 30
VpcConfig:
SubnetIds:
- !GetAtt
- SubnetPrivate1
- Outputs.SubnetId
- !GetAtt
- SubnetPrivate2
- Outputs.SubnetId
SecurityGroupIds:
- !Ref IRISSG
```
Isso foi BASTANTE, mas agora você pode enlouquecer e chamar o IRIS através da função lambda com Python e mudar o mundo.
## Execução!
Da forma como o descrito acima é implementado, espera-se que a função seja passada em um objeto de evento que é um tanto estruturado para reutilização, você pode ver a ideia no exemplo de objeto de evento abaixo:
```
{
"method": "Version",
# importante, se o método não requer argumentos, aplique "none"
"args": "none"
# exemplo de método com argumentos, separados por vírgulas
# "args": "thing1, thing2"
}
```
agora você pode, se tiver tolerância para exemplos em linha de comando, dar uma olhada na execução abaixo usando a AWS CLI:
```
(base) sween @ basenube-pop-os ~/Desktop/BASENUBE
└─ $ ▶ aws lambda invoke --function-name iris-native-lambda --payload '{"method":"Version","args":"none"}' --invocation-type RequestResponse --cli-binary-format raw-in-base64-out --region us-east-2 --profile default /dev/stdout
{{\"status\":1,\"payload\":\"IRIS for UNIX (Red Hat Enterprise Linux for x86-64) 2020.2 (Build 210U) Thu Jun 4 2020 15:48:46 EDT\"}"
"StatusCode": 200,
"ExecutedVersion": "$LATEST"
}
```
Agora, se dermos um passo adiante, a AWS CLI oferece suporte a aliases, então crie um para você mesmo e você pode brincar com total integração com o seu comando aws legal. Aqui está um exemplo de alias cli:
```
└─ $ ▶ cat ~/.aws/cli/alias
[toplevel]
whoami = sts get-caller-identity
iris =
!f() {
aws lambda invoke \
--function-name iris-native-lambda \
--payload \
"{\"method\":\""${1}"\",\"args\":\"none\"}" \
--invocation-type RequestResponse \
--log-type None \
--cli-binary-format raw-in-base64-out \
gar.json > /dev/null
cat gar.json
echo
echo
}; f
```
...e agora, você pode apenas fazer...

Se cuide! – Argumentos técnicos são bem-vindos!
Ótimo trabalho, estava curioso sobre essa comunicação de Iris, Python e AWS.
Artigo
Henrique Dias · Abr. 21, 2021
Fala galera,
@José.Pereira e eu queremos falar sobre nosso novo projeto, ZPM Explorer, é uma interface gráfica para explorar e descobrir as grandes aplicações que estão disponíveis no InterSystems Package Manager.
## A ideia
A ideia do ZPM Explorer é deixar a vida de todos mais fácil quando procurarem por aplicações que são oferecidas pelo ZPM. A cada dia mais e mais aplicações se juntam ao universo ZPM, então, porque não ajudar desenvolvedores e não desenvolvedores a tirarem proveito deste incrível universo?
## A aplicação
ZPM é uma aplicação simples e poderosa, para isso tentamos traduzir a simplicidade em algo simples de usar e poderosa na forma de pesquisar, facilitando a vida das pessoas na hora de encontrar a solução ideal com um simples clique.
A página inicial do ZPM Explorer é uma tabela com os dados fornecidos pelo endpoint [https://pm.community.intersystems.com/packages/-/all](https://pm.community.intersystems.com/packages/-/all)
Com os seguintes campos:
- Name: nome da aplicação
- Description: descrição do que a aplicação faz
- Repository: link para o repositório Github
- Version: versão atual da aplicação hospedada no Package Manager
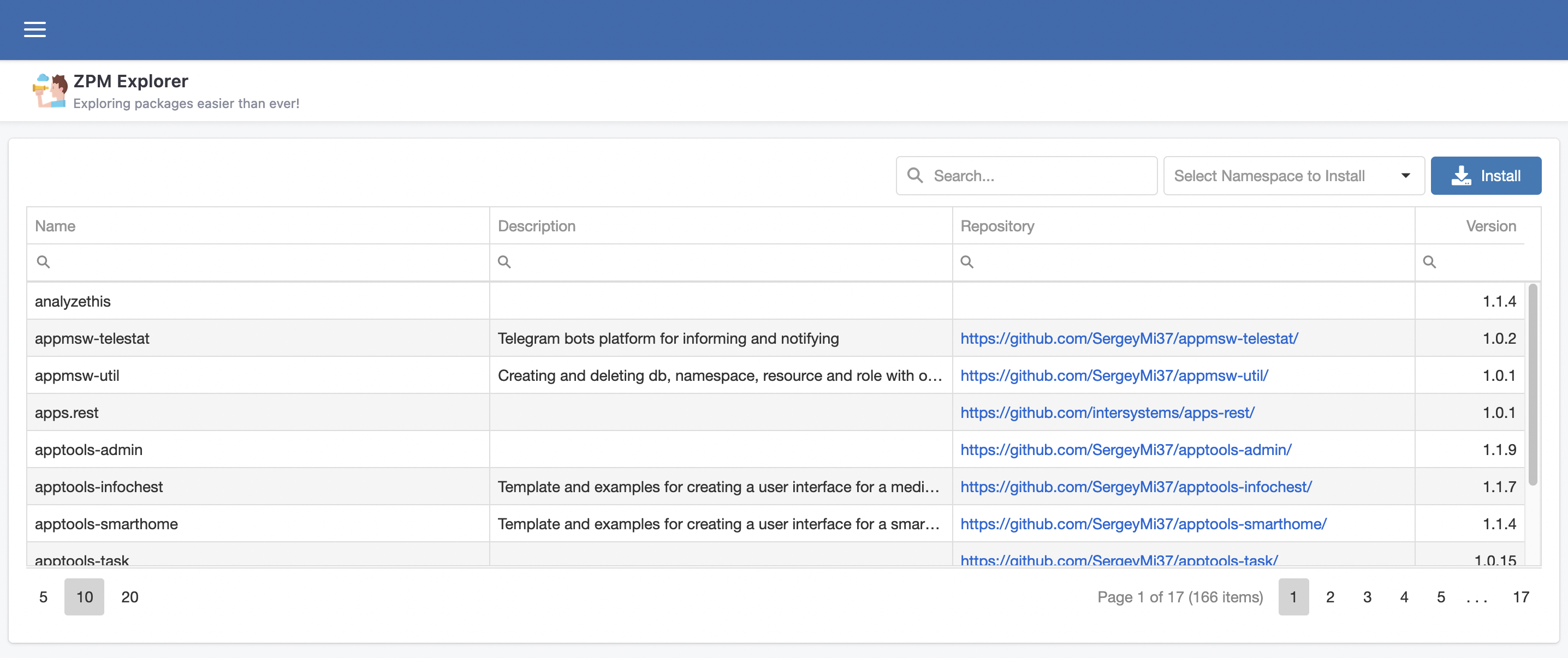
## Instalando novas aplicações
O uso da aplicação é simples, rápido e objetivo.
1. Pesquisa a aplicação desejada
2. Seleciona a aplicação
3. Clique no botão "Install"
4. Confirme se desejar instalar
5. Pronto
6. Agora é só correr para o abraço e tirar proveito da nova solução instalada
## Gerenciando pacotes instalados
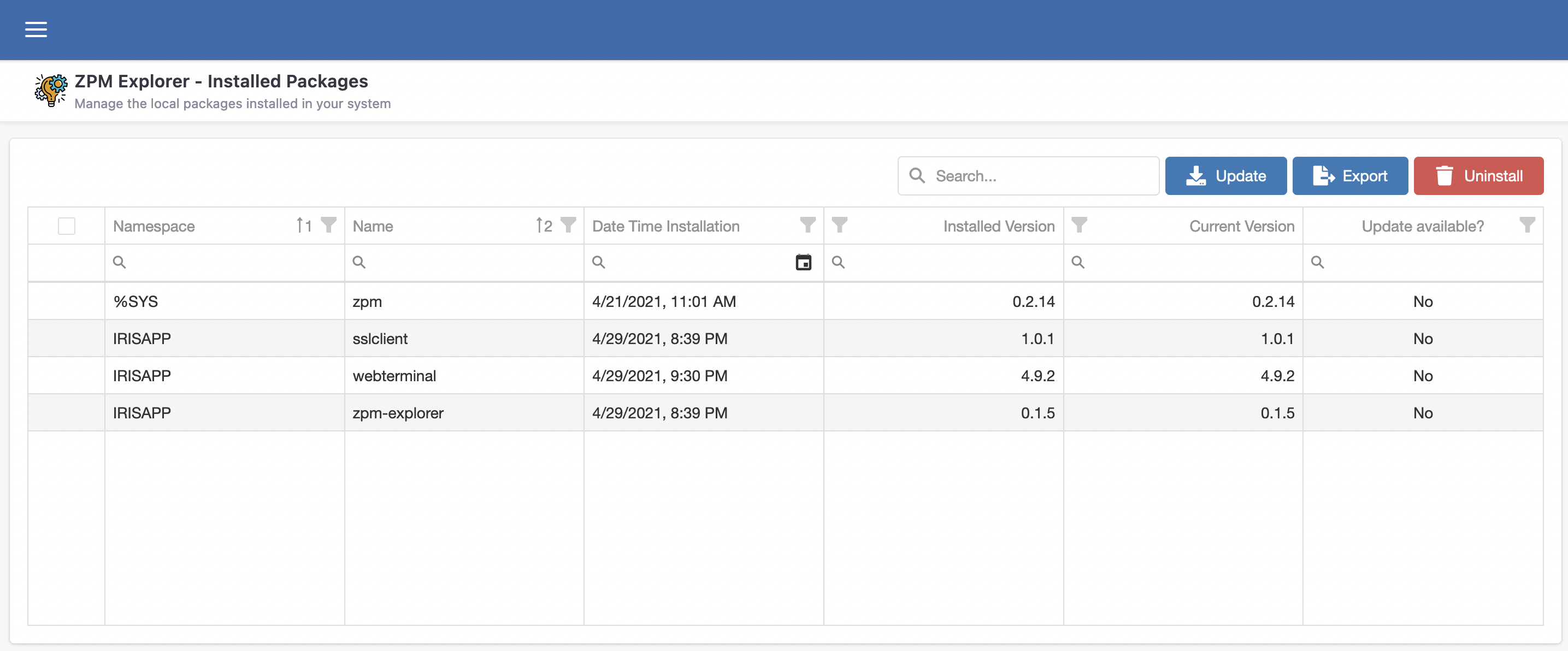
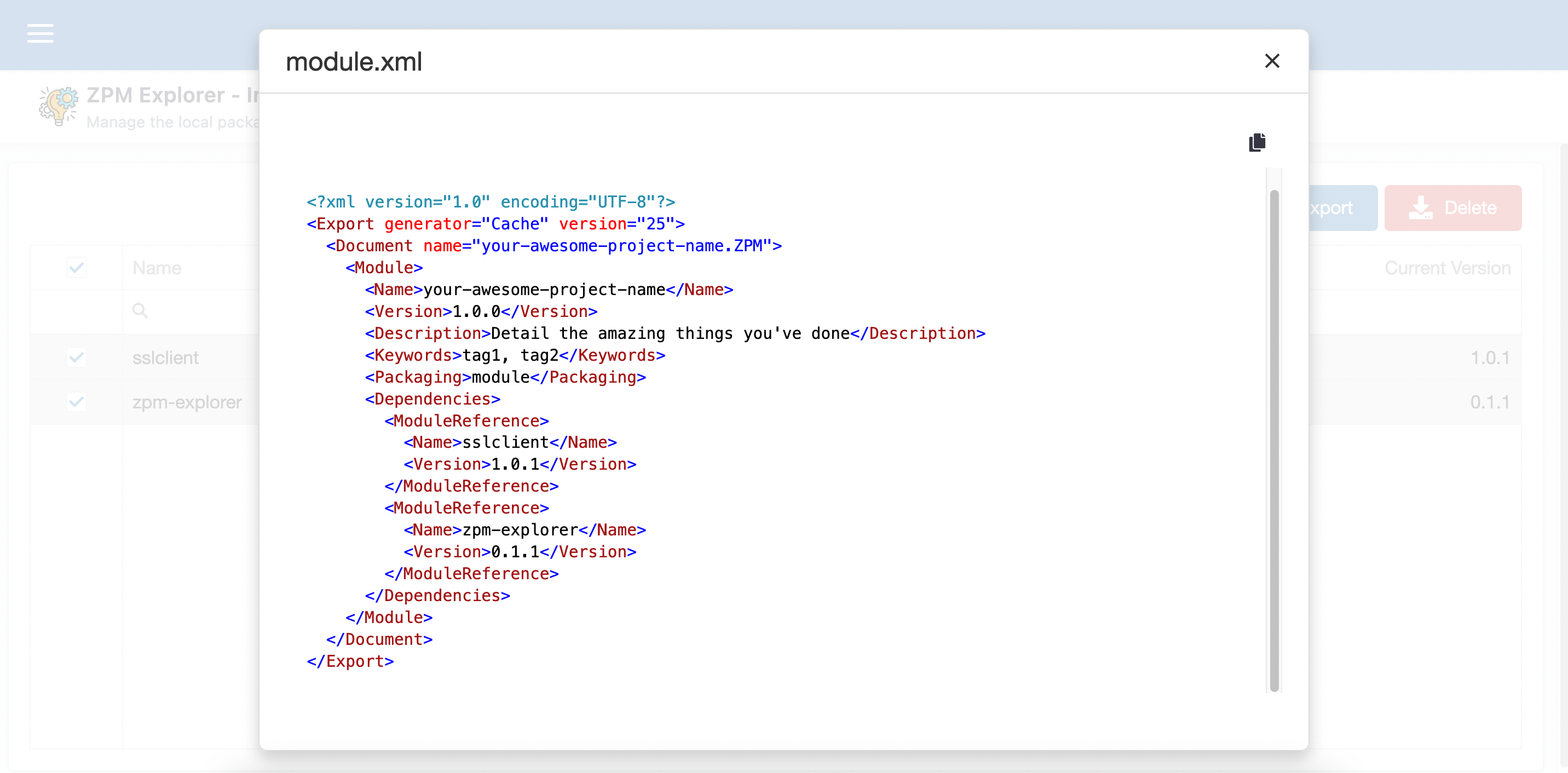
ZPM Explorer também oferece uma página para você fazer o gerenciamento das aplicações existentes, instaladas através do ZPM.
Nessa página você pode atualizar, desinstalar e até mesmo usar um "wizard" para faciitar sua vida na hora de criar seu module.xml e mencionar as aplicações desejadas como dependentes.
## Demo
[https://zpm-explorer.contest.community.intersystems.com/csp/irisapp/explorer.html](https://zpm-explorer.contest.community.intersystems.com/csp/irisapp/explorer.html)
Se você curtiu o aplicativo e acredita que merecemos seu voto, por favor, vote em **zpm-explorer**!
https://openexchange.intersystems.com/contest/current

Artigo
Henrique Dias · Fev. 9, 2023
Fala galera, beleza?
iiii lá vamos nós. Ano novo, nova competição, novo projeto, velhos motivos.
Triple Slash na área!
Aprendi o meu primeiro if, hello world, em 1999.
Ainda lembro do meu professor tentando explicar para turma toda como um simples "while" funcionava para descobrir se uma determinada condição havia sido atingida. @Renato.Banzai ainda lembra do professor Barbosa tentando chegar a porta na explicação "passo-a-passo"?
De lá pra cá, sempre amei a ideia de programar, criar coisas, transformar ideias em projetos, em coisas úteis. Mas para criar algo, você precisa ter certeza de que isso funciona. Não apenas sair fazendo coisas novas, mas garantir que o que você criou funciona, mesmo adicionando novas funcionalidades.
E sendo super transparente, eu acho a parte de testes chata demais! Imagina uma parada chata, é o que teste é pra mim. Se você curte essas paradas, nada contra, mas não é minha praia.
Comparando mal e porcamente, seria como limpar a casa. Todo mundo curte um ambiente limpinho, mas limpar a casa, passar roupa, etc é uma baita chatice.
Com isso em mente, pensamos em facilitar a vida de todo desenvolvedor na hora de testar suas aplicações.
Inspirando no estilo do elixir e nessa ideia da InterSystems Ideas (Valeu @Evgeny.Shvarov)! Nós tentamos melhorar o processo de testes e torná-lo mais fácil e agradável de se fazer.
Simplificamos o %UnitTest e para mostrar como utilizar o TripleSlash para criar seus testes unitários, se liga no exemplo abaixo:
Vamos supor que você tenha a seguinte classe e método e queira escrever um teste unitário:
Class dc.sample.ObjectScript
{
ClassMethod TheAnswerForEverything() As %Integer
{
Set a = 42
Write "Hello World!",!
Write "This is InterSystems IRIS with version ",$zv,!
Write "Current time is: "_$zdt($h,2)
Return a
}
}
Como podemos ver o método TheAnswerForEverything() apenas retorna o número 42. Então, vamos documentar o método e como o TripleSlash deve criar o teste unitário:
/// A simple method for testing purpose.
///
/// <example>
/// Write ##class(dc.sample.ObjectScript).Test()
/// 42
/// </example>
ClassMethod TheAnswerForEverything() As %Integer
{
...
}
Testes unitários devem estar entre a tag <example></example>. Você pode colocar todo o tipo de documentação, mas todos os testes devem estar obrigatoriamente dentro da tag.
Agora, vamos iniciar uma sessão no IRIS, ir para o Namespace IRISAPP, criar uma instância da classe Core passando o nome da classe (ou o nome do pacote de classes para todas elas) e executar o método Execute() :
USER>ZN "IRISAPP"
IRISAPP>Do ##class(iris.tripleSlash.Core).%New("dc.sample.ObjectScript").Execute()
TripleSlash vai interpretar mais ou menos como "Dado o resultado do método Test(), afirmamos que é igual a 42". Então, a nova classe será criada:
Class iris.tripleSlash.tst.ObjectScript Extends %UnitTest.TestCase
{
Method TestTheAnswerForEverything()
{
Do $$$AssertEquals(##class(dc.sample.ObjectScript).TheAnswerForEverything(), 42)
}
}
Agora vamos adicionar um novo método para testar outras coisas e falar para o TripleSlash como escrever esses testes.
Class dc.sample.ObjectScript
{
ClassMethod GuessTheNumber(pNumber As %Integer) As %Status
{
Set st = $$$OK
Set theAnswerForEveryThing = 42
Try {
Throw:(pNumber '= theAnswerForEveryThing) ##class(%Exception.StatusException).%New("Sorry, wrong number...")
} Catch(e) {
Set st = e.AsStatus()
}
Return st
}
}
Como podem ver, o método GuessTheNumber() espera um número, retorna um $$$OK apenas quando o número 42 é passado e devolve um erro para qualquer outro valor. Então vamos falar como queremos que o TripleSlash crie o teste unitário:
/// Another simple method for testing purpose.
///
/// <example>
/// Do ##class(dc.sample.ObjectScript).GuessTheNumber(42)
/// $$$OK
/// Do ##class(dc.sample.ObjectScript).GuessTheNumber(23)
/// $$$NotOK
/// </example>
ClassMethod GuessTheNumber(pNumber As %Integer) As %Status
{
...
}
Executando novamente o método Execute() e verá um novo método de teste na sua classe de teste iris.tripleSlash.tst.ObjectScript:
Class iris.tripleSlash.tst.ObjectScript Extends %UnitTest.TestCase
{
Method TestGuessTheNumber()
{
Do $$$AssertStatusOK(##class(dc.sample.ObjectScript).GuessTheNumber(42))
Do $$$AssertStatusNotOK(##class(dc.sample.ObjectScript).GuessTheNumber(23))
}
}
Atualmente temos suporte para: $$$AssertStatusOK, $$$AssertStatusNotOK and $$$AssertEquals.
TripleSlash nos permite gerar testes a partir de exemplos de códigos encontrados na documentação dos métodos. Isso ajuda a matar 2 coelhos com uma cajadada só, melhorando sua documentação de classe e criando um teste unitário.
Agradecimentos
Uma vez mais, queremos agradecer a todos que vem nos dando apoio na comunidade com as aplicações que criamos.
Se você achou nosso aplicativo interessante, pensa com carinho para votar em iris-tripleslash e nos ajude a continuar contribuindo para o crescimento da comunidade a e aseguir nesse caminho!
Artigo
Andre Larsen Barbosa · Jul. 14, 2021
O InterSystems IRIS 2019.1 já foi lançado há algum tempo e gostaria de abordar algumas melhorias para lidar com JSON que podem ter passado despercebidas. Lidar com JSON como um formato de serialização é uma parte importante da construção de aplicativos modernos, especialmente ao interagir com terminais REST.
Formatando JSON
Em primeiro lugar, ajuda se você pode formatar JSON para torná-lo mais legível. Isso é muito útil quando você precisa depurar seu código e observar o conteúdo JSON de um determinado tamanho. Estruturas simples são fáceis de procurar por um humano, mas assim que você tiver vários elementos aninhados, pode ficar complicado com bastante facilidade. Aqui está um exemplo simples:
{"name":"Gobi","type":"desert","location":{"continent":"Asia","countries":["China","Mongolia"]},"dimensions":{"length":1500,"length_unit":"km","width":800,"width_unit":"km"}}
Um formato mais legível torna mais fácil explorar a estrutura do conteúdo. Vamos dar uma olhada na mesma estrutura JSON, mas desta vez com quebras de linha e recuo adequados:
{
"name":"Gobi",
"type":"desert",
"location":{
"continent":"Asia",
"countries":[
"China",
"Mongolia"
]
},
"dimensions":{
"length":1500,
"length_unit":"km",
"width":800,
"width_unit":"km"
}
}
Mesmo este exemplo simples aumenta um pouco a saída, então você pode ver por que este não é o padrão em muitos sistemas. Mas com essa formatação detalhada, você pode identificar subestruturas facilmente e ter uma noção se algo está errado.
InterSystems IRIS 2019.1 introduziu um pacote com o nome %JSON. Você pode encontrar alguns utilitários úteis aqui, sendo um formatador, que permite que você obtenha exatamente o que viu acima: Formate seus objetos dinâmicos e matrizes e strings JSON em uma representação mais legível. %JSON.Formatter é uma classe com uma interface muito simples. Todos os métodos são métodos de instância, então você sempre começa recuperando uma instância.
USER>set formatter = ##class(%JSON.Formatter).%New()
A razão por trás dessa escolha é que você pode configurar seu formatador para usar certos caracteres para o recuo (por exemplo, espaços em branco x tabulações) e terminadores de linha uma vez e usá-los sempre que precisar.
O método Format() pega um objeto / array dinâmico ou uma string JSON. Vejamos um exemplo simples usando um objeto dinâmico:
USER>do formatter.Format({"type":"string"})
{
"type":"string"
}
E aqui está um exemplo com o mesmo conteúdo JSON, mas desta vez representado como uma string JSON:
USER>do formatter.Format("{""type"":""string""}")
{
"type":"string"
}
O método Format() envia a string formatada para o dispositivo atual, mas você também verá os métodos FormatToString() e FormatToStream() caso queira direcionar a saída para uma variável.
Mudando a marcha
O texto acima é bom, mas pode não valer um artigo por si só. O InterSystems IRIS 2019.1 também apresenta uma maneira de serializar objetos persistentes e transitórios de e para JSON. A classe que você deseja examinar é%JSON.Adaptor. O conceito é muito semelhante a% XML.Adaptor, daí o nome. Qualquer classe que você gostaria de serializar de e para JSON precisa ter a subclasse%JSON.Adaptor. A classe herdará alguns métodos úteis, os mais notáveis são %JSONImport() e %JSONExport(). É melhor demonstrar isso com um exemplo. Suponha que temos as seguintes classes:
Class Model.Event Extends (%Persistent, %JSON.Adaptor)
{
Property Name As %String;
Property Location As Model.Location;
}
e
Class Model.Location Extends (%Persistent, %JSON.Adaptor)
{
Property City As %String;
Property Country As %String;
}
Como você pode ver, temos uma classe de evento persistente, que se vincula a um local. Ambas as classes herdam de %JSON.Adaptor. Isso nos permite preencher um gráfico de objeto e exportá-lo diretamente como uma string JSON:
USER>set event = ##class(Model.Event).%New()
USER>set event.Name = "Global Summit"
USER>set location = ##class(Model.Location).%New()
USER>set location.City = "Boston"
USER>set location.Country = "United States of America"
USER>set event.Location = location
USER>do event.%JSONExport()
{"Name":"Global Summit","Location":{"City":"Boston","Country":"United States of America"}}
Claro, você também pode ir na outra direção com %JSONImport():
USER>set jsonEvent = {"Name":"Global Summit","Location":{"City":"Boston","Country":"United States of America"}}
USER>set event = ##class(Model.Event).%New()
USER>do event.%JSONImport(jsonEvent)
USER>write event.Name
Global Summit
USER>write event.Location.City
Boston
Os métodos de importação e exportação funcionam para estruturas aninhadas arbitrariamente. Semelhante ao %XML.Adaptor, você pode especificar a lógica de mapeamento para cada propriedade individual definindo os parâmetros correspondentes. Vamos mudar a classe Model.Event para a seguinte definição:
Class Model.Event Extends (%Persistent, %JSON.Adaptor)
{
Property Name As %String(%JSONFIELDNAME = "eventName");
Property Location As Model.Location(%JSONINCLUDE = "INPUTONLY");
}
Supondo que temos a mesma estrutura de objeto atribuída ao evento variável como no exemplo acima, uma chamada para %JSONExport () retornaria o seguinte resultado:
USER>do event.%JSONExport()
{"eventName":"Global Summit"}
O nome da propriedade é mapeado para o nome do campo eventName e a propriedade Location é excluída da chamada %JSONExport(), mas será preenchida quando presente no conteúdo JSON durante uma chamada %JSONImport(). Existem vários parâmetros disponíveis para permitir que você ajuste o mapeamento:
%JSONFIELDNAME corresponde ao nome do campo no conteúdo JSON.
%JSONIGNORENULL permite que o desenvolvedor substitua o tratamento padrão de strings vazias para propriedades de string.
%JSONINCLUDE controla se essa propriedade será incluída na saída / entrada JSON.
If %JSONNULL for verdadeiro (= 1), as propriedades não especificadas serão exportadas como o valor nulo. Caso contrário, o campo correspondente à propriedade é apenas ignorado durante a exportação.
%JSONREFERENCE especifica como as referências do objeto são tratadas. "OBJECT" é o padrão e indica que as propriedades da classe referenciada são usadas para representar o objeto referenciado. Outras opções são "ID", "OID" e "GUID".
Isso fornece um alto nível de controle e é muito útil. Já se foi o tempo de mapear manualmente seus objetos para JSON.
Mais uma coisa
Em vez de definir os parâmetros de mapeamento no nível da propriedade, você também pode definir um mapeamento JSON em um bloco XData. O seguinte bloco XData com o nome OnlyLowercaseTopLevel tem as mesmas configurações de nossa classe de evento acima.
Class Model.Event Extends (%Persistent, %JSON.Adaptor)
{
Property Name As %String;
Property Location As Model.Location;
XData OnlyLowercaseTopLevel
{
<Mapping xmlns="http://www.intersystems.com/jsonmapping">
<Property Name="Name" FieldName="eventName"/>
<Property Name="Location" Include="INPUTONLY"/>
</Mapping>
}
}
Há uma diferença importante: os mapeamentos JSON em blocos XData não alteram o comportamento padrão, mas você deve referenciá-los nas chamadas %JSONImport() e %JSONExport() correspondentes como o último argumento, por exemplo:
USER>do event.%JSONExport("OnlyLowercaseTopLevel")
{"eventName":"Global Summit"}
Se não houver bloco XData com o nome fornecido, o mapeamento padrão será usado. Com essa abordagem, você pode configurar vários mapeamentos e fazer referência ao mapeamento necessário para cada chamada individualmente, concedendo ainda mais controle e tornando seus mapeamentos mais flexíveis e reutilizáveis.
Espero que essas melhorias facilitem sua vida e aguardo seu feedback. Deixe-me saber o que você pensa nos comentários.
Artigo
Heloisa Paiva · Maio 26, 2023
Introdução
Dentre as diversas soluções que desenvolvemos aqui na Innovatium, um desafio comum é a necessidade de acesso ao tamanho das bases de dados. Entretanto, notei que isso não é algo tão trivial no IRIS. Esse tipo de informação é importante para manter um controle do fluxo de dados e do custo em GB's de um sistema a ser implementado. Contudo, o que realmente me chamou atenção é a necessidade dela para uma função muito importante: migrar para cloud. Afinal, quem não quer migrar seus sistemas para cloud hoje em dia, certo?
Os serviços de cloud oferecem tudo que um sistema precisa de maneira descomplicada: mirroring, escalabilidade, proteção dos dados, facilidade de fluxo, e o que faz toda pessoa jurídica se apaixonar: é pago pelo uso. E ainda mais, com as gigantescas Google (Cloud), Microsoft (Azure), Amazon (AWS), etc. oferecendo seus serviços quase impecáveis a preços acessíveis, é algo que com um pouco de investimento pode ser uma realidade para qualquer um que queira aumentar seus lucros e economizar a longo prazo. Além do mais, para quem já está aqui, a própria InterSystems tem seus serviços de Cloud também.
Por essa razão venho aqui apresentar o app que estou desenvolvendo, no qual não é só possível, mas também é fácil observar tamanhos das globais, para que as análises necessárias para obter um serviço em cloud seja apenas tão complicada quanto o seu provedor favorito a complique.
Inspiração
Me inspirando nas aplicações isc-global-size-tracing e globals-tool, estou criando uma versão que possa unir o que há de melhor nas duas e acrescentar adaptações necessárias para o nosso negócio. Mas antes de mostrar meu desenvolvimento, vou apresentar brevemente as aplicações inspiradas.
A isc-global-size-tracing oferece serviços de análises a partir de classes dentro do próprio Iris, com métodos mais amigáveis ao usuário e opções de tasks scheduladas que atualizam uma tabela com vários dados sobre as globais. Há também opções prontas de exportação das informações para arquivos externos. Assim, se já existe uma familiaridade com Object Script não é tão difícil tirar alguns minutos para entender o seu funcionamento e adaptar ao seu negócio.
Já a globals-tool mostra um portal em forma de website onde é possível checar os tamanhos alocados e os tamanhos disponíveis para cada global, dentro de seus namespaces. É um pouco mais simples, porém mais amigável ao usuário, podendo ser utilizada também para disponibilizar os dados para pessoas de outras áreas sem conhecimento algum em programação. Mudanças e adaptações podem exigir conhecimento prévio não somente em Object Script, mas também em React e similares.
O que eu gostaria então é de trazer as várias opções da primeira com a usabilidade da segunda, além de adicionar outras opções de análises e exportações.
O App - o que já está disponível
Nesta sessão, vou explicar um pouco do que já foi feito e como pode ser aproveitado por você e sua empresa.
Todo o código está disponível para consulta, clone ou download no meu Github.
Para começar a utilizar é muito simples, basta clonar ou fazer download do repositório na pasta que preferir e configurar para a sua instância do IRIS.
Abra o terminal na pasta onde deseja clonar o repositório e use o comando
git clone https://github.com/heloisatambara/iris-size-django
Entre na pasta iris-size-django e instale os requisitos necessários:
.../iris-size-django > pip install -r requirements.txt
Edite o arquivo .../iris-size-django/globalsize/settings.py para personalizar as configurações da base de dados. Não mude o parâmetro ENGINE, ele deve apontar para a aplicação de CaretDev, django-iris. Contudo, altere o NAME para o namespace, USER e PASSWORD para um usuário com privilégios adequados (é necessário acesso ao namespace %SYS e poder criar uma tabela no namespace desejado) e os parâmetros HOST e PORT devem direcionar à sua instância.
De volta ao terminal, vamos rodar os comandos makemigrations para preparar o app, migrate para criar a tabela onde vamos armazenar as informações das globais e runserver para colocar tudo em prática.
> python manage.py makemigrations
> python manage.py migrate
> python manage.py runserver
Agora, é só abrir o link http://127.0.0.1:8000/globals/ no seu navegador preferido e clicar em update. Em poucos segundos você deve ter uma tabela com todos os namespaces e suas respectivas globais, mostrando a quantidade (em MB) de memória alocada e utilizada, como mostra a imagem no início da sessão.
A instância a ser analizada está em globals/api/methods.py, e não precisa ser necessariamente a mesma em que definimos em DATABASES, em settings.py. Para mais detalhes sobre esse tipo de conexão, você pode ler a documentação sobre InterSystems IRIS Cloud SQL ou os tutoriais Python e IRIS na prática com exemplos (na sessão ObjectScript no ambiente Python) ou Retornando valores com Python.
Agora vamos dar uma olhada melhor na parte de cima da foto:
Aqui, podemos ver as opções de filtros, exportação e ordenação.
Você pode digitar parte do nome da base de dados ou das globais para ver resultados específicos, ou digitar um número positivo em Size ou Allocated para ver resultados acima daquele valor. Se digitar um número negativo, verá os resultados abaixo do módulo do valor. Clique no botão Filter para efetivar o filtro.
Selecione o modelo de exportação (CSV, XML, JSON) e clique em Export para exportar para a pasta iris-size-django. Lembrando que os filtros aplicados serão refletidos na exportação. Além disso, você pode mudar o endereço de exportação no código, em .../iris-size-django/globals/views.py.>
Por fim, você pode selecionar ordenação crescente em ordem alfabética pelo nome da base de dados e da global ou pelo tamanho ocupado ou quantidade alocada. Clique no botão Filter para efetivar a ordenação e os filtros digitados. Obs.: A ordenação não será refletida na exportação.
No final da página você pode ver a contagem de globais dentro dos filtros selecionados, além da quantidade total alocada e utilizada:
Se você quiser fazer análises mais profundas ou até mesmo ver a tabela original, uma opção boa é entrar no portal de administração da instância referida em settings.py, na sessão do SQL e selecionar o namespace referido no mesmo local. A tabela terá sido criada automaticamente pelo Django com o nome de SQLUser.globals_iglobal, e ali você pode usar as ferramentas da InterSystems para executar todo tipo de query.
Obs.: em settings, o parâmetro DEBUG está marcado como TRUE pois ainda está em desenvolvimento.
Ideias futuras
Minhas primeiras ideias são trazer mais funções para o portal. Atualmente é possível alterar configurações de exportação e da base de dados diretamente no código, além de fazer queries mais complexas pelo portal do IRIS. Contudo, acredito que unificar tudo isso no portal será mais eficiente. Além disso, também estou estudando para acrescentar um acompanhamento do fluxo de dados por período.
Por fim, gostaria de ouvir de você: acha que esse tipo de aplicação pode ajudar seu negócio? Que outras funções você gostaria de ver aqui? Gostaria de ver alguma função já existente do IRIS de maneira mais amigável? Ou gostaria que algo apresentado aqui fosse mais simplificado?
Pergunta
Jullyanna Mendes · Dez. 22, 2020
Boa tarde, estou desenvolvimento uma demo com iKnow, e gostaria de saber como eu acesso dados do healthshare? Tudo bem Jullyanna?
Que tipo de informação não estruturada você pretende recuperar do HealthShare ? Você consegue me explicar um pouco mais sobre a demo que você tem em mente ?
Obrigado. Boa tarde, basicamente seria pegar o acessos dos pacientes oncológicos e identificar as possibilidades de ser avançado, iniciante ou mediano. Uma forma de prevenir e antecipar os tratamentos. bom dia Jullyanna,
entendo que esta informação deva estar em algum laudo de exame carregado no HealthShare, correto? portanto deve estar dentro do SDA, de onde podemos extrair e utilizar o NLP(iKnow) analisar semanticamente o conteúdo. Você já definou os conceitos que indicaram o estado do evento? avançado, iniciante ou mediano, já que teremos que entender que conceitos indicam os estados que pretendemos avaliar. Se você quiser podemos marcar uma conversa para entender melhor suas necessidades. Olá Jullyanna.
Como cliente você pode acessar tanto a documentação do produto como os treinamentos online, seja para o HealthShare ou para o iKnow.
Assim como o Rochael, me coloco também a disposição para uma conversa para entendermos melhor a sua necessidade.
Obrigado. Boa tarde, o SDA ele está transmitindo o binário do PDF. Dentro do healthshare o documento ta em formado pdf. bom dia Jullyanna,
neste caso teremos que montar uma alternativa para extrair o conteúdo do PDF.
Podemos marcar uma conversa na semana que vem para tratarmos do assunto?
obrigado e feliz natal Oi Juliana, tudo bem?
Você já viu aplicação do @Yuri.Gomes no OpenExchange?
https://openexchange.intersystems.com/package/OCR-Service
Na descrição da aplicação você tem a seguinte informação:InterSystems IRIS Interoperability OCR ServiceThis is an InterSystems IRIS Interoperability OCR Service to extract text from images and pdfs from a file into a multipart request from form or http request.
What The the service doesThis application receive a http multipart request with a file, extract text using OCR from Tesseract and returns the result
Também tem um video que ele fez demonstrando um pouco mais.
https://www.youtube.com/watch?v=E8MHJ0kAdbk
Espero que possa ajudar.
Abraços
Pergunta
Alexandre Lago · Jun. 21, 2022
Olá, comecei a trabalhar com Caché a pouco, e estou em treinamento.
Me surgiu uma dúvida de uma determinada atividade, aonde a regra solicita que o usuário digite uma string, e selecione uma das opções listradas, e uma delas e informar a palavra com maior número de carácteres da string.
Já tentei de tudo, porém não consegui chegar a nenhuma conclusão.
Desde já agradeço Olá Alexandre,Não entendi muito bem, mas, você já fez a contagem de caracteres da string que o usuário digitou? Se não de uma olhada na função $Length https://docs.intersystems.com/ens201815/csp/docbook/Doc.View.cls?KEY=RCOS_flength
Oi Alexandre! O que me veio em mente rapidamente foi criar um código que transforme a sua string/frase em uma lista de palavras para depois percorrer a lista contando o numero de letras de cada palavra da lista.
Algo assim:
Set frase = "Como contar a palavra com maior numero de caracteres"
#; cria uma lista da string com delimitador " " espaço Set fraseList = $Listfromstring(frase," ")
#; percorre a lista e imprime a posição da palavra na frase (i), o tamanho da palavra ($length) e a palavra ($listget(fraseList,i))For i=1:1:$Listlength(fraseList) w !,i_"- tamanho:"_$length($listget(fraseList,i))_"->"_$lg(fraseList,i)
O código acima pode ser executado no Terminal. Mas se você somente desejar saber o maior tamanho, basta salvar o tamanho em uma variável comparando os tamanhos. Exemplo:
Set maiorTamanho=""For i=1:1:$Listlength(fraseList) { set tamanho=$length($listget(fraseList,i)) if tamanho>maiorTamanho { set maiorTamanho=tamanho set maiorPalavra=$listget(fraseList,i) }}
Write !,maiorPalavra_" - tamanho: "_maiorTamanho
Espero que ajude! :-) MAIORPALAVRA ;Verifica qual é a maior palavra da frase Set Frase="O Cache da InterSystems é Imbativel" Write !,"Frase : ",Frase,! ; Escreve Set qp=$Length(Frase," ") ; Conta as palavras da frase Set (qtl,mqtl)=0 ; Zera os contadores For pal=1:1:qp { ; comando For Set palavra=$Piece(Frase," ",pal) ; percorre as palavras Set qtl=$L(palavra) ; Verifica tamanho da palavra If qtl>mqtl Set mqtl=qtl,pi=pal ; Define a maior palavra } Write !,"A maior palavra da frase é ",$Piece(Frase," ",pi),! ; Escreve a maior palavra ; ; Crie um programa COS com os comandos acima e execute no terminal