Limpar filtro
Pergunta
Fernando Beira · Mar. 2, 2022
Pessoal, tudo bem!?
Na instituição que trabalho estou enfrentando algo inusitado, temos duas instancias EC2 (AWS) em mirror e durante algum tempo em funcionamento a instância primaria nos lança um erro no message.log dizendo o seguinte (Journal Daemon has been inactive with I/O pending for 10 seconds) e em seguida efetua o chaveamento de máquina para o nó 2 da configuração, isso esta ocorrendo com uma frequência grande impactando a operação.
A infra diz que o link está com 50% de carga e em teoria não há gargalo na comunicação.
Trecho do message.log:
Sabem se pode ser alguma configuração relacionada aos discos virtuais da AWS?
Gostaria de saber se alguém já passou por esse tipo de situação? E como devemos proceder?
Desde já agradeço! Bom dia Fernando,
Você sabe qual foi o tipo de disco associado a estás máquinas EC2 na AWS?
Existem diversos tipos de discos lá inclusive os de baixa performance, se forem os do tipo magnético. Oi Djeniffer, obrigado pelo retorno!
Estamos com discos GP2 com block size de 4KB. Olá Fernando,
Seria importante realizar um teste utilizando discos do tipo gp3, pois o gp2 tem uma limitação bem especifica no "Max throughput per volume" e já tivemos problemas com ele devido a isso.
Aqui tem um link com estas diferenças entre os discos: https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ebs-volume-types.html Oi Djeniffer,
Compartilhei seu retorno com o pessoal que tem acesso a conta da AWS e descobrimos que a tempo atrás tivemos uma GMUD que realmente mudou o tipo do disco e efetuamos o rollback.
O ambiente está estável já a um dia e meio com poucas entradas no log, apenas do sincronismo do journal do mirror e alguns outros por menores, sem qualquer tipo de menção ao Deamon.
Agora, o que é interessante é que, segundo o Analista que efetuou a mudança dos discos, estávamos com o tipo GP3 e voltamos a usar o GP2 sem mexer em qualquer configuração de IOPS.
De qualquer forma criamos um ticket com a InterSystems para avaliação e seguimos monitorando daqui.
Muito obrigado pela ajuda!!
Olá Fernando,
Ótimo.
Pergunta
Guilherme Koerber · Set. 9, 2021
Olá comunidade!
Estou enfrentando um problema de crescimento da base, que está sendo gerado por um processo e por uma característica do Ensemble.
Ao executar o processo de limpeza das filas de mensagens o Ensemble “preserva” as Streams que fizeram parte dessas mensagens apagando somente o Header e Body. Desta forma a base de dados (de um dos namespaces) tem crescido cerca de 60GB por dia, o que vem estourando a capacidade do disco.
A InterSystems informou que isso se trata de uma característica e que está explicado nos documentos abaixo mencionados.
https://community.intersystems.com/post/ensemble-orphaned-messages
E também nesta parte da documentação: https://cedocs.intersystems.com/ens201812/csp/docbook/DocBook.UI.Page.cls?KEY=EGMG_purge_basic
Penso que o procedimento é implementar a remoção desses objetos tipo stream no método %OnDelete() da classe referente a essa mensagem, porém a complexidade dessa mensagem faz com que essa propriedade específica não seja alcançada pelo purge padrão. A stream não é exatamente o que tem no conteúdo, pois dentro dele você pode ter campos do tipo Stream, GlobalCharacterStream, etc.São esses campos que ele não apaga e ele deveria apagar. Pelo que entendi os dados ficam dentro de uma global chamada ^CacheStream e de lá elas nunca são apagadas.
Com isso estou tendo dificuldades em saber o que tem dentro dela, o que é de cada interface e o que ainda está sendo usado. Tendo em vista que ela não tem ligação direta com as classes de Stream.
Alguém já teve um problema assim que possa me auxiliar?
Desde já agradeço,
Guilherme Koerber. Olá Guilherme,
Na sua classe de mensagens você possui uma propriedade que aponta a outro objeto que possui stream ou a propriedade já é stream?
Pergunto pois já tive essa situação diversas vezes e resolvemos isso com uma mudança na classe de mensagens para não mais referenciar outros objetos. Djeniffer,De fato, esta apontado para um objeto. Irei tentar adaptar a classe para não referenciar mais objetos.Obrigado pela sugestão! =D Olá Guilherme,
Exato, o que fizemos aqui em algumas integrações foi converter o XML em uma FileCharacterStream e quando é necessário usar este objeto fazemos o correlate dele diretamente na BO, ai só existe o tráfego dessas streams e não mais dos objetos externos que dificultam o processo de limpeza.
Se precisar de alguma ajuda me informe.
Anúncio
Angelo Bruno Braga · jan 16, 2023
Olá Comunidade!
Temos o prazer de dar as boas-vindas a @Niu.Yuxiang como nosso novo moderador na equipe da Comunidade de Desenvolvedores!
Vamos cumprimentar @Niu.Yuxiang com muitos aplausos e dar uma olhada em sua biografia!
@Niu.Yuxiang é atualmente o líder da equipe clínica do Centro de Informações do Beijing Friendship Hospital, Capital Medical Universit
Aqui está uma breve introdução sobre @Niu.Yuxiang:
Tenho quase 10 anos de experiência em informatização da área médica. Atualmente lidero uma pequena equipe focada em pesquisa aplicada e desenvolvimento de sistemas de informação hospitalar (Hospital Information System, HIS) baseado no banco de dados Caché. Nossa equipe está familiarizada com HTML, CSS, JavaScript e linguagens de front-end derivadas. Nosso trabalho diário se concentra principalmente no desenvolvimento de funções correspondentes de acordo com as necessidades do usuário e na otimização constante das funções do programa com base nas dificuldades e pontos problemáticos do negócio clínico. Após dois anos de estudo e esforços, nossa equipe concluiu um total de mais de 1.000 novas funções clínicas e requisitos de otimização. Com o desenvolvimento de nosso departamento de TI, nossa força de desenvolvimento se tornará cada vez mais forte, o que pode garantir melhor a resposta oportuna às necessidades clínicas, otimizar e melhorar constantemente os bugs do sistema e melhorar a eficiência do trabalho clínico. Ao mesmo tempo, também atuei como membro da equipe de emergência, responsável pela operação do banco de dados e solução de problemas, para garantir a solução de problemas a tempo.
A plataforma de dados da InterSystems é uma excelente plataforma de integração que traz grande comodidade ao nosso negócio com o auxílio desta tecnologia. Também espero que essa excelente tecnologia possa agregar valor para mais unidades irmãs e parceiros. Também espero me comunicar com outras pessoas da comunidade e compartilhar um pouco da minha experiência prática. Ao mesmo tempo, também espero usar esta plataforma para aprender algumas práticas excelentes com você. Vamos crescer e progredir juntos!
Obrigado e parabéns, @Niu.Yuxiang! 👏🏼
Espero que você seja um ótimo moderador! Desejamos-lhe uma ótima viagem pela Comunidade de Desenvolvedores!
Artigo
Henry Pereira · Maio 30

Sabe aquela sensação de receber o resultado do seu exame de sangue e parecer que está em grego? É exatamente esse problema que o **FHIRInsight** veio resolver.
Surgiu da ideia de que dados médicos não deveriam ser assustadores ou confusos – deveriam ser algo que todos podemos utilizar. Exames de sangue são extremamente comuns para verificar nossa saúde, mas, sejamos sinceros, interpretá-los é difícil para a maioria das pessoas e, às vezes, até para profissionais da área que não trabalham em um laboratório.
O **FHIRInsight** quer tornar todo esse processo mais simples e acessível.

## 🤖 Por que criamos o FHIRInsight
Tudo começou com uma simples pergunta:
> “Por que interpretar um exame de sangue ainda é tão difícil — até para médicos, às vezes?”
Se você já olhou para um resultado de laboratório, provavelmente viu um monte de números, abreviações enigmáticas e uma “faixa de referência” que pode ou não se aplicar à sua idade, sexo ou condição.
É uma ferramenta de diagnóstico, com certeza — mas sem contexto, vira um jogo de adivinhação. Até profissionais de saúde experientes às vezes precisam recorrer a diretrizes, artigos científicos ou opiniões de especialistas para entender tudo direito.
É aí que o **FHIRInsight** entra em cena.
Não foi feito apenas para pacientes — fizemos para quem está na linha de frente do atendimento. Para médicos em plantões intermináveis, para enfermeiros que captam sutis padrões nos sinais vitais, para qualquer profissional de saúde que precise tomar decisões certas com tempo limitado e muita responsabilidade. Nosso objetivo é facilitar um pouco o trabalho deles — transformando dados clínicos FHIR em algo **claro, útil e fundamentado em ciência médica real**. Algo que fale a língua humana.
O FHIRInsight faz mais do que só explicar valores de exames. Ele também:
- **Fornece aconselhamento contextual** sobre se um resultado é leve, moderado ou grave
- **Sugere causas potenciais e diagnósticos diferenciais** com base em sinais clínicos
- **Recomenda próximos passos** — sejam exames adicionais, encaminhamentos ou atendimento de urgência
- **Utiliza RAG (Retrieval-Augmented Generation)** para incorporar **artigos científicos relevantes** que fundamentam a análise
Imagine um jovem médico revisando um hemograma de um paciente com anemia. Em vez de buscar cada valor no Google ou vasculhar revistas médicas, ele recebe um relatório que não só resume o problema, mas cita estudos recentes ou diretrizes da OMS que embasam o raciocínio. Esse é o poder de combinar **IA** e **busca vetorial sobre pesquisas selecionadas**.
E o paciente?
Ele não fica mais diante de um monte de números, sem saber o que significa “bilirrubina 2,3 mg/dL” ou se deve se preocupar.
Em vez disso, recebe uma explicação simples e cuidadosa. Algo que se assemelha mais a uma conversa do que a um laudo clínico. Algo que ele realmente entende — e que pode levar ao consultório do médico mais preparado e menos ansioso.
Porque é disso que o **FHIRInsight** trata de verdade: **transformar complexidade médica em clareza** e **ajudar profissionais e pacientes a tomarem decisões melhores e mais confiantes** — juntos.
## 🔍 Por dentro da tecnologia
Claro que toda essa simplicidade na superfície é viabilizada por uma tecnologia poderosa atuando discretamente nos bastidores.
Veja do que o FHIRInsight é feito:
- **FHIR (Fast Healthcare Interoperability Resources)** — padrão global de dados de saúde. É assim que recebemos informações estruturadas como resultados de exames, histórico do paciente, dados demográficos e atendimentos. O FHIR é a linguagem que os sistemas médicos falam — e nós traduzimos essa linguagem em algo que as pessoas possam usar.
- **Busca Vetorial RAG (Retrieval-Augmented Generation)**: o FHIRInsight aprimora seu raciocínio diagnóstico indexando **artigos científicos em PDF e URLs confiáveis** em um **banco de dados usando a busca vetorial nativa do InterSystems IRIS**. Quando um resultado de exame fica ambíguo ou complexo, o sistema recupera conteúdo relevante para embasar suas recomendações — não da memória do modelo, mas de **pesquisas reais e atualizadas**.
- **Engenharia de Prompts para Raciocínio Médico**: refinamos nossos prompts para guiar o LLM na identificação de um amplo espectro de condições relacionadas ao sangue. Desde anemia por deficiência de ferro até coagulopatias, desequilíbrios hormonais ou gatilhos autoimunes — o prompt conduz o LLM pelas variações de sintomas, padrões laboratoriais e causas possíveis.
- **Integração com LiteLLM**: um adaptador customizado direciona requisições para múltiplos provedores de LLM (OpenAI, Anthropic, Ollama etc.) através de uma interface unificada, permitindo fallback, streaming e troca de modelo com facilidade.
Tudo isso acontece em segundos — transformando valores brutos de laboratório em **insights médicos explicáveis e acionáveis**, seja para um médico revisando 30 prontuários ou um paciente tentando entender seus números.
## 🧩 o Adapter LiteLLM: Uma Interface para Todos os Modelos
Nos bastidores, os relatórios do FHIRInsight movidos a IA são impulsionados pelo **LiteLLM** — uma library python que nos permite chamar mais de **100 LLMs** (OpenAI, Claude, Gemini, Ollama etc.) por meio de uma única interface estilo OpenAI.
Porém, integrar o LiteLLM ao **InterSystems IRIS** exigiu algo mais permanente e reutilizável do que scripts Python escondidos numa Business Operation. Então, criamos nosso próprio **Adapter LiteLLM**.
### Conheça o `LiteLLMAdapter`
Esse adaptador lida com tudo o que você esperaria de uma integração robusta de LLM:
- Recebe parâmetros como `prompt`, `model` e `temperature`
- Carrega dinamicamente variáveis de ambiente (por exemplo, chaves de API)
Para encaixar isso em nossa produção de interoperabilidade em um simples **Business Operation**:
- Gerencia configuração em produção por meio da configuração padrão `LLMModel`
- Integra-se ao componente FHIRAnalyzer para geração de relatórios em tempo real
- Atua como uma “ponte de IA” central para quaisquer componentes futuros que precisem de acesso a LLM
Eis o fluxo de forma simplificada:
```
set response = ##class(dc.LLM.LiteLLMAdapter).CallLLM("Me fale sobre hemoglobina.", "openai/gpt-4o", 0.7)
write response
```
## 🧪 Conclusão
Quando começamos a desenvolver o FHIRInsight, nossa missão era simples: **tornar exames de sangue mais fáceis de entender — para todo mundo**. Não apenas pacientes, mas médicos, enfermeiros, cuidadores... qualquer pessoa que já tenha encarado um resultado de laboratório e pensado: “Ok, mas o que isso realmente significa?”
Todos nós já passamos por isso.
Ao combinar a estrutura do FHIR, a velocidade do InterSystems IRIS, a inteligência dos LLMs e a profundidade de pesquisas médicas reais via busca vetorial, criamos uma ferramenta que transforma números confusos em histórias significativas. Histórias que ajudam pessoas a tomarem decisões mais inteligentes sobre sua saúde — e, quem sabe, detectar algo cedo que passaria despercebido.
Mas o FHIRInsight não é só sobre dados. É sobre **como nos sentimos ao olhar para esses dados**. Queremos que seja claro, acolhedor e empoderador. Que a experiência seja... como um verdadeiro **“vibecoding” na saúde** — aquele ponto perfeito onde código inteligente, bom design e empatia humana se encontram.
Esperamos que você experimente, teste, questione — e nos ajude a melhorar.
Diga o que gostaria de ver no próximo release. Mais condições? Mais explicações? Mais personalização?
Isso é só o começo — e adoraríamos que você ajudasse a moldar o que vem a seguir.
Artigo
Ron Sweeney · Fev. 10, 2021
Se você está procurando uma maneira inteligente de integrar sua solução IRIS no ecossistema Amazon Web Services, aplicativos sem servidor ou script python baseado em `boto3`, usar a [API Nativa IRIS para Python](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=AFL_PYNATIVE) pode ser o caminho a seguir. Até que você precise obter ou definir algo no IRIS, você não tem que ir muito longe com uma implementação em produção para fazer sua aplicação funcionar de um maneira incrível, então, espero que você encontre valor neste artigo e construa algo que seja importante para outros ou somente para você, pois ambos são igualmente válidos.

Se você está procurando algumas justificativas para implementar isso:
* Você precisa acertar a trigger de geração de pré-token no Cognito para pesquisar e inserir o contexto de ID do paciente no token para uma solução baseada em SMART on FHIR(R) implementando um fluxo de trabalho com OAUTH2.
* Você deseja publicar as configurações de ajuste de provisionamento do IRIS com base no tipo de instância, grupo de nós, toaster ou cluster ECS que você disparou para executar o IRIS no anel zero.
* Você quer impressionar a família e os amigos no Zoom com suas habilidades de gerenciamento do IRIS sem que o seu shell saia da AWS cli.
## O ponto
Aqui, vamos provisionar uma função lambda da AWS que se comunica com o IRIS e fornecer alguns exemplos sobre como provisioná-la e como interagir com ela em várias capacidades, na esperança de que possamos discutir sobre isso e **publicá-la no pip para tornar as coisas mais fáceis.**
## Com pressa????

Confira o streaming
## Em todo o caso...
Para participar da diversão, você precisará definir algumas coisas em seu plano de voo.
### Rede
Você tem o IRIS em execução da maneira que deseja, rodando em uma AWS VPC com exatamente duas sub-redes e um grupo de segurança que permite acesso ao super servidor rodando IRIS... usamos 1972 por motivos nostálgicos e pelo simples fato de que a InterSystems se deu ao trabalho de registrar essa porta no [IANA](https://tools.ietf.org/html/rfc6335), e se você adicionar a nova porta em `/etc/services` sem fazer isso, não é a melhor prática, mas tudo bem. Em nosso caso, é um conjunto de instâncias EC2 espelhadas com verificações de integridade adequadas em torno de um balanceador de carga de rede AWS v2.
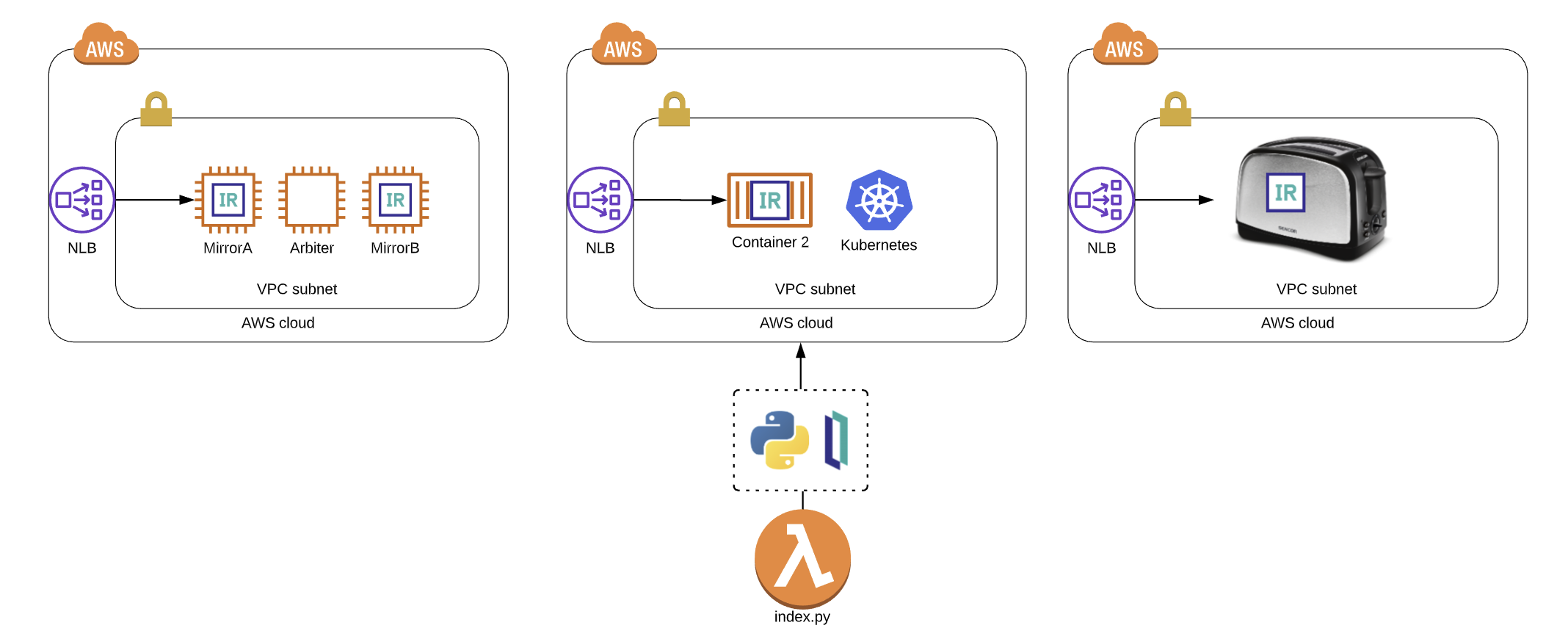
### Classe de exemplo importada
De alguma forma, você conseguiu criar e importar a classe na raiz deste repositório para o namespace `%SYS` em sua instância IRIS. A seguir está um exemplo da classe que gera a saída acima. Se você está se perguntando por que precisamos importar uma classe aqui, consulte a nota abaixo, onde a abordagem recomendada é provisionar algumas classes de wrapper para uso por meio do python.
> Nota do Docs: Embora esses métodos também possam ser usados com as classes InterSystems definidas na Biblioteca de Classes, a melhor prática é chamá-las indiretamente, de dentro de uma classe ou rotina definida pelo usuário. Muitos métodos de classe retornam apenas um código de status, passando os resultados reais de volta em um argumento (que não pode ser acessado pela API nativa). As funções definidas pelo sistema (listadas em Funções ObjectScript na Referência ObjectScript) não podem ser chamadas diretamente.
Classe de Exemplo:
```
Class ZDEMO.IRIS.Lambda.Operations Extends %Persistent
{
ClassMethod Version() As %String
{
Set tSC = 0
Set tVersion = $ZV
if ( tVersion '="" ) { set tSC = $$$OK }
Set jsonret = {}
Set jsonret.status = tSC
Set jsonret.payload = tVersion
Quit jsonret.%ToJSON()
}
}
```
Observe acima que decidi trabalhar com base na convenção de sempre retornar um objeto JSON como uma resposta, que também me permite retornar o status e possivelmente preencher a lacuna ao retornar algumas coisas por referência.
### Acesso AWS
Obtenha algumas chaves de acesso IAM que permitirão que você provisione e invoque a Função Lambda com a qual iremos mudar o mundo.
Verificação antes do voo:
```
IRIS [ $$$OK ]
VPC [ $$$OK ]
Subnets [ $$$OK ]
Security Group [ $$$OK ]
IAM Access [ $$$OK ]
Imported Class [ $$$OK ]
```
$$$OK, **Vamos lá**.
## Empacotando a API Nativa IRIS para Python para uso na Função Lambda
Esta é a parte que seria fantástica se fosse um pacote pip, especialmente se fosse apenas para Linux, já que as funções da AWS Lambda são executadas no BoXenLinux. No momento deste commit, a API não está disponível via pip, mas somos engenhosos e podemos lançar a nossa própria.
```
mkdir iris_native_lambda
cd iris_native_lambda
wget https://github.com/intersystems/quickstarts-python/raw/master/Solutions/nativeAPI_wheel/irisnative-1.0.0-cp34-abi3-linux_x86_64.whl
unzip nativeAPI_wheel/irisnative-1.0.0-cp34-abi3-linux_x86_64.whl
```
Crie `connection.config`
Exemplo: [connection.config](https://raw.githubusercontent.com/basenube/iris_native_lambda/main/examples/connection.config)
Crie seu manipulador, `index.py` ou use aquele na pasta de exemplos, no [repositório de demonstração no GitHub](https://github.com/basenube/iris_native_lambda). Observe que a versão de demonstração usa variáveis de ambiente e um arquivo externo para as informações de conectividade IRIS.
Exemplo:
[index.py](https://raw.githubusercontent.com/basenube/iris_native_lambda/main/examples/index.py)
Agora compacte-o para uso:
```
zip -r9 ../iris_native_lambda.zip *
```
Crie um bucket S3 e carregue o zip de função nele.
```
cd ..
aws s3 mb s3://iris-native-bucket
s3 sync iris_native_lambda.zip s3://iris-native-bucket
```
> Isso conclui o empacotamento da API e do manipulador para uso como uma função AWS Lambda.
Agora, clique no console para criar a função ou use algo como o Cloudformation para executar o trabalho:
```
IRISAPIFunction:
Type: "AWS::Lambda::Function"
DependsOn:
- IRISSG
- VPC
Properties:
Environment:
Variables:
IRISHOST: "172.31.0.10"
IRISPORT: "1972"
NAMESPACE: "%SYS"
USERNAME: "intersystems"
PASSWORD: "lovetheyneighbor"
Code:
S3Bucket: iris-native-bucket
S3Key: iris_native_lambda.zip
Description: "Função API Nativa IRIS para Python"
FunctionName: iris-native-lambda
Handler: "index.lambda_handler"
MemorySize: 128
Role: "arn:aws:iam::8675309:role/BeKindtoOneAnother"
Runtime: "python3.7"
Timeout: 30
VpcConfig:
SubnetIds:
- !GetAtt
- SubnetPrivate1
- Outputs.SubnetId
- !GetAtt
- SubnetPrivate2
- Outputs.SubnetId
SecurityGroupIds:
- !Ref IRISSG
```
Isso foi BASTANTE, mas agora você pode enlouquecer e chamar o IRIS através da função lambda com Python e mudar o mundo.
## Execução!
Da forma como o descrito acima é implementado, espera-se que a função seja passada em um objeto de evento que é um tanto estruturado para reutilização, você pode ver a ideia no exemplo de objeto de evento abaixo:
```
{
"method": "Version",
# importante, se o método não requer argumentos, aplique "none"
"args": "none"
# exemplo de método com argumentos, separados por vírgulas
# "args": "thing1, thing2"
}
```
agora você pode, se tiver tolerância para exemplos em linha de comando, dar uma olhada na execução abaixo usando a AWS CLI:
```
(base) sween @ basenube-pop-os ~/Desktop/BASENUBE
└─ $ ▶ aws lambda invoke --function-name iris-native-lambda --payload '{"method":"Version","args":"none"}' --invocation-type RequestResponse --cli-binary-format raw-in-base64-out --region us-east-2 --profile default /dev/stdout
{{\"status\":1,\"payload\":\"IRIS for UNIX (Red Hat Enterprise Linux for x86-64) 2020.2 (Build 210U) Thu Jun 4 2020 15:48:46 EDT\"}"
"StatusCode": 200,
"ExecutedVersion": "$LATEST"
}
```
Agora, se dermos um passo adiante, a AWS CLI oferece suporte a aliases, então crie um para você mesmo e você pode brincar com total integração com o seu comando aws legal. Aqui está um exemplo de alias cli:
```
└─ $ ▶ cat ~/.aws/cli/alias
[toplevel]
whoami = sts get-caller-identity
iris =
!f() {
aws lambda invoke \
--function-name iris-native-lambda \
--payload \
"{\"method\":\""${1}"\",\"args\":\"none\"}" \
--invocation-type RequestResponse \
--log-type None \
--cli-binary-format raw-in-base64-out \
gar.json > /dev/null
cat gar.json
echo
echo
}; f
```
...e agora, você pode apenas fazer...

Se cuide! – Argumentos técnicos são bem-vindos!
Ótimo trabalho, estava curioso sobre essa comunicação de Iris, Python e AWS.
Artigo
Henrique Dias · Abr. 21, 2021
Fala galera,
@José.Pereira e eu queremos falar sobre nosso novo projeto, ZPM Explorer, é uma interface gráfica para explorar e descobrir as grandes aplicações que estão disponíveis no InterSystems Package Manager.
## A ideia
A ideia do ZPM Explorer é deixar a vida de todos mais fácil quando procurarem por aplicações que são oferecidas pelo ZPM. A cada dia mais e mais aplicações se juntam ao universo ZPM, então, porque não ajudar desenvolvedores e não desenvolvedores a tirarem proveito deste incrível universo?
## A aplicação
ZPM é uma aplicação simples e poderosa, para isso tentamos traduzir a simplicidade em algo simples de usar e poderosa na forma de pesquisar, facilitando a vida das pessoas na hora de encontrar a solução ideal com um simples clique.
A página inicial do ZPM Explorer é uma tabela com os dados fornecidos pelo endpoint [https://pm.community.intersystems.com/packages/-/all](https://pm.community.intersystems.com/packages/-/all)
Com os seguintes campos:
- Name: nome da aplicação
- Description: descrição do que a aplicação faz
- Repository: link para o repositório Github
- Version: versão atual da aplicação hospedada no Package Manager
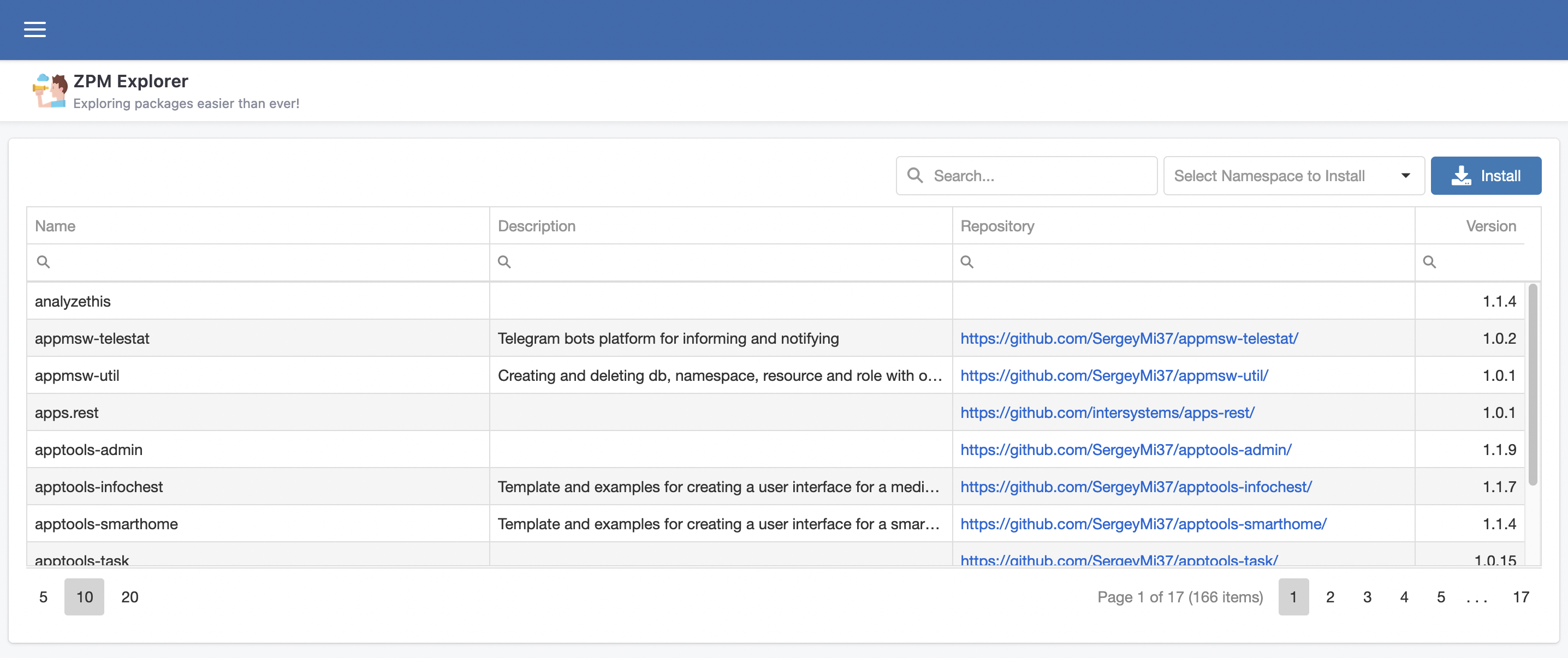
## Instalando novas aplicações
O uso da aplicação é simples, rápido e objetivo.
1. Pesquisa a aplicação desejada
2. Seleciona a aplicação
3. Clique no botão "Install"
4. Confirme se desejar instalar
5. Pronto
6. Agora é só correr para o abraço e tirar proveito da nova solução instalada
## Gerenciando pacotes instalados
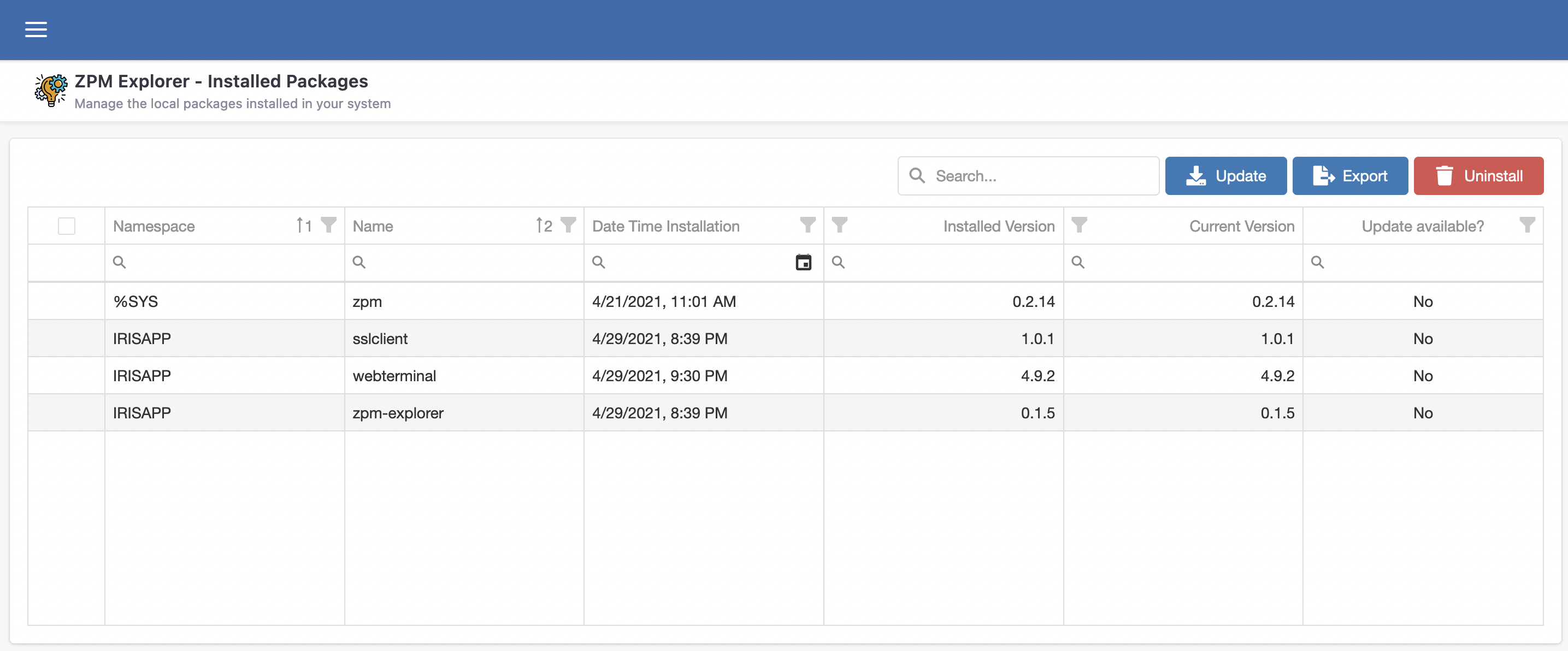
ZPM Explorer também oferece uma página para você fazer o gerenciamento das aplicações existentes, instaladas através do ZPM.
Nessa página você pode atualizar, desinstalar e até mesmo usar um "wizard" para faciitar sua vida na hora de criar seu module.xml e mencionar as aplicações desejadas como dependentes.
## Demo
[https://zpm-explorer.contest.community.intersystems.com/csp/irisapp/explorer.html](https://zpm-explorer.contest.community.intersystems.com/csp/irisapp/explorer.html)
Se você curtiu o aplicativo e acredita que merecemos seu voto, por favor, vote em **zpm-explorer**!
https://openexchange.intersystems.com/contest/current

Artigo
Henrique Dias · Fev. 9, 2023
Fala galera, beleza?
iiii lá vamos nós. Ano novo, nova competição, novo projeto, velhos motivos.
Triple Slash na área!
Aprendi o meu primeiro if, hello world, em 1999.
Ainda lembro do meu professor tentando explicar para turma toda como um simples "while" funcionava para descobrir se uma determinada condição havia sido atingida. @Renato.Banzai ainda lembra do professor Barbosa tentando chegar a porta na explicação "passo-a-passo"?
De lá pra cá, sempre amei a ideia de programar, criar coisas, transformar ideias em projetos, em coisas úteis. Mas para criar algo, você precisa ter certeza de que isso funciona. Não apenas sair fazendo coisas novas, mas garantir que o que você criou funciona, mesmo adicionando novas funcionalidades.
E sendo super transparente, eu acho a parte de testes chata demais! Imagina uma parada chata, é o que teste é pra mim. Se você curte essas paradas, nada contra, mas não é minha praia.
Comparando mal e porcamente, seria como limpar a casa. Todo mundo curte um ambiente limpinho, mas limpar a casa, passar roupa, etc é uma baita chatice.
Com isso em mente, pensamos em facilitar a vida de todo desenvolvedor na hora de testar suas aplicações.
Inspirando no estilo do elixir e nessa ideia da InterSystems Ideas (Valeu @Evgeny.Shvarov)! Nós tentamos melhorar o processo de testes e torná-lo mais fácil e agradável de se fazer.
Simplificamos o %UnitTest e para mostrar como utilizar o TripleSlash para criar seus testes unitários, se liga no exemplo abaixo:
Vamos supor que você tenha a seguinte classe e método e queira escrever um teste unitário:
Class dc.sample.ObjectScript
{
ClassMethod TheAnswerForEverything() As %Integer
{
Set a = 42
Write "Hello World!",!
Write "This is InterSystems IRIS with version ",$zv,!
Write "Current time is: "_$zdt($h,2)
Return a
}
}
Como podemos ver o método TheAnswerForEverything() apenas retorna o número 42. Então, vamos documentar o método e como o TripleSlash deve criar o teste unitário:
/// A simple method for testing purpose.
///
/// <example>
/// Write ##class(dc.sample.ObjectScript).Test()
/// 42
/// </example>
ClassMethod TheAnswerForEverything() As %Integer
{
...
}
Testes unitários devem estar entre a tag <example></example>. Você pode colocar todo o tipo de documentação, mas todos os testes devem estar obrigatoriamente dentro da tag.
Agora, vamos iniciar uma sessão no IRIS, ir para o Namespace IRISAPP, criar uma instância da classe Core passando o nome da classe (ou o nome do pacote de classes para todas elas) e executar o método Execute() :
USER>ZN "IRISAPP"
IRISAPP>Do ##class(iris.tripleSlash.Core).%New("dc.sample.ObjectScript").Execute()
TripleSlash vai interpretar mais ou menos como "Dado o resultado do método Test(), afirmamos que é igual a 42". Então, a nova classe será criada:
Class iris.tripleSlash.tst.ObjectScript Extends %UnitTest.TestCase
{
Method TestTheAnswerForEverything()
{
Do $$$AssertEquals(##class(dc.sample.ObjectScript).TheAnswerForEverything(), 42)
}
}
Agora vamos adicionar um novo método para testar outras coisas e falar para o TripleSlash como escrever esses testes.
Class dc.sample.ObjectScript
{
ClassMethod GuessTheNumber(pNumber As %Integer) As %Status
{
Set st = $$$OK
Set theAnswerForEveryThing = 42
Try {
Throw:(pNumber '= theAnswerForEveryThing) ##class(%Exception.StatusException).%New("Sorry, wrong number...")
} Catch(e) {
Set st = e.AsStatus()
}
Return st
}
}
Como podem ver, o método GuessTheNumber() espera um número, retorna um $$$OK apenas quando o número 42 é passado e devolve um erro para qualquer outro valor. Então vamos falar como queremos que o TripleSlash crie o teste unitário:
/// Another simple method for testing purpose.
///
/// <example>
/// Do ##class(dc.sample.ObjectScript).GuessTheNumber(42)
/// $$$OK
/// Do ##class(dc.sample.ObjectScript).GuessTheNumber(23)
/// $$$NotOK
/// </example>
ClassMethod GuessTheNumber(pNumber As %Integer) As %Status
{
...
}
Executando novamente o método Execute() e verá um novo método de teste na sua classe de teste iris.tripleSlash.tst.ObjectScript:
Class iris.tripleSlash.tst.ObjectScript Extends %UnitTest.TestCase
{
Method TestGuessTheNumber()
{
Do $$$AssertStatusOK(##class(dc.sample.ObjectScript).GuessTheNumber(42))
Do $$$AssertStatusNotOK(##class(dc.sample.ObjectScript).GuessTheNumber(23))
}
}
Atualmente temos suporte para: $$$AssertStatusOK, $$$AssertStatusNotOK and $$$AssertEquals.
TripleSlash nos permite gerar testes a partir de exemplos de códigos encontrados na documentação dos métodos. Isso ajuda a matar 2 coelhos com uma cajadada só, melhorando sua documentação de classe e criando um teste unitário.
Agradecimentos
Uma vez mais, queremos agradecer a todos que vem nos dando apoio na comunidade com as aplicações que criamos.
Se você achou nosso aplicativo interessante, pensa com carinho para votar em iris-tripleslash e nos ajude a continuar contribuindo para o crescimento da comunidade a e aseguir nesse caminho!
Artigo
Andre Larsen Barbosa · Jul. 14, 2021
O InterSystems IRIS 2019.1 já foi lançado há algum tempo e gostaria de abordar algumas melhorias para lidar com JSON que podem ter passado despercebidas. Lidar com JSON como um formato de serialização é uma parte importante da construção de aplicativos modernos, especialmente ao interagir com terminais REST.
Formatando JSON
Em primeiro lugar, ajuda se você pode formatar JSON para torná-lo mais legível. Isso é muito útil quando você precisa depurar seu código e observar o conteúdo JSON de um determinado tamanho. Estruturas simples são fáceis de procurar por um humano, mas assim que você tiver vários elementos aninhados, pode ficar complicado com bastante facilidade. Aqui está um exemplo simples:
{"name":"Gobi","type":"desert","location":{"continent":"Asia","countries":["China","Mongolia"]},"dimensions":{"length":1500,"length_unit":"km","width":800,"width_unit":"km"}}
Um formato mais legível torna mais fácil explorar a estrutura do conteúdo. Vamos dar uma olhada na mesma estrutura JSON, mas desta vez com quebras de linha e recuo adequados:
{
"name":"Gobi",
"type":"desert",
"location":{
"continent":"Asia",
"countries":[
"China",
"Mongolia"
]
},
"dimensions":{
"length":1500,
"length_unit":"km",
"width":800,
"width_unit":"km"
}
}
Mesmo este exemplo simples aumenta um pouco a saída, então você pode ver por que este não é o padrão em muitos sistemas. Mas com essa formatação detalhada, você pode identificar subestruturas facilmente e ter uma noção se algo está errado.
InterSystems IRIS 2019.1 introduziu um pacote com o nome %JSON. Você pode encontrar alguns utilitários úteis aqui, sendo um formatador, que permite que você obtenha exatamente o que viu acima: Formate seus objetos dinâmicos e matrizes e strings JSON em uma representação mais legível. %JSON.Formatter é uma classe com uma interface muito simples. Todos os métodos são métodos de instância, então você sempre começa recuperando uma instância.
USER>set formatter = ##class(%JSON.Formatter).%New()
A razão por trás dessa escolha é que você pode configurar seu formatador para usar certos caracteres para o recuo (por exemplo, espaços em branco x tabulações) e terminadores de linha uma vez e usá-los sempre que precisar.
O método Format() pega um objeto / array dinâmico ou uma string JSON. Vejamos um exemplo simples usando um objeto dinâmico:
USER>do formatter.Format({"type":"string"})
{
"type":"string"
}
E aqui está um exemplo com o mesmo conteúdo JSON, mas desta vez representado como uma string JSON:
USER>do formatter.Format("{""type"":""string""}")
{
"type":"string"
}
O método Format() envia a string formatada para o dispositivo atual, mas você também verá os métodos FormatToString() e FormatToStream() caso queira direcionar a saída para uma variável.
Mudando a marcha
O texto acima é bom, mas pode não valer um artigo por si só. O InterSystems IRIS 2019.1 também apresenta uma maneira de serializar objetos persistentes e transitórios de e para JSON. A classe que você deseja examinar é%JSON.Adaptor. O conceito é muito semelhante a% XML.Adaptor, daí o nome. Qualquer classe que você gostaria de serializar de e para JSON precisa ter a subclasse%JSON.Adaptor. A classe herdará alguns métodos úteis, os mais notáveis são %JSONImport() e %JSONExport(). É melhor demonstrar isso com um exemplo. Suponha que temos as seguintes classes:
Class Model.Event Extends (%Persistent, %JSON.Adaptor)
{
Property Name As %String;
Property Location As Model.Location;
}
e
Class Model.Location Extends (%Persistent, %JSON.Adaptor)
{
Property City As %String;
Property Country As %String;
}
Como você pode ver, temos uma classe de evento persistente, que se vincula a um local. Ambas as classes herdam de %JSON.Adaptor. Isso nos permite preencher um gráfico de objeto e exportá-lo diretamente como uma string JSON:
USER>set event = ##class(Model.Event).%New()
USER>set event.Name = "Global Summit"
USER>set location = ##class(Model.Location).%New()
USER>set location.City = "Boston"
USER>set location.Country = "United States of America"
USER>set event.Location = location
USER>do event.%JSONExport()
{"Name":"Global Summit","Location":{"City":"Boston","Country":"United States of America"}}
Claro, você também pode ir na outra direção com %JSONImport():
USER>set jsonEvent = {"Name":"Global Summit","Location":{"City":"Boston","Country":"United States of America"}}
USER>set event = ##class(Model.Event).%New()
USER>do event.%JSONImport(jsonEvent)
USER>write event.Name
Global Summit
USER>write event.Location.City
Boston
Os métodos de importação e exportação funcionam para estruturas aninhadas arbitrariamente. Semelhante ao %XML.Adaptor, você pode especificar a lógica de mapeamento para cada propriedade individual definindo os parâmetros correspondentes. Vamos mudar a classe Model.Event para a seguinte definição:
Class Model.Event Extends (%Persistent, %JSON.Adaptor)
{
Property Name As %String(%JSONFIELDNAME = "eventName");
Property Location As Model.Location(%JSONINCLUDE = "INPUTONLY");
}
Supondo que temos a mesma estrutura de objeto atribuída ao evento variável como no exemplo acima, uma chamada para %JSONExport () retornaria o seguinte resultado:
USER>do event.%JSONExport()
{"eventName":"Global Summit"}
O nome da propriedade é mapeado para o nome do campo eventName e a propriedade Location é excluída da chamada %JSONExport(), mas será preenchida quando presente no conteúdo JSON durante uma chamada %JSONImport(). Existem vários parâmetros disponíveis para permitir que você ajuste o mapeamento:
%JSONFIELDNAME corresponde ao nome do campo no conteúdo JSON.
%JSONIGNORENULL permite que o desenvolvedor substitua o tratamento padrão de strings vazias para propriedades de string.
%JSONINCLUDE controla se essa propriedade será incluída na saída / entrada JSON.
If %JSONNULL for verdadeiro (= 1), as propriedades não especificadas serão exportadas como o valor nulo. Caso contrário, o campo correspondente à propriedade é apenas ignorado durante a exportação.
%JSONREFERENCE especifica como as referências do objeto são tratadas. "OBJECT" é o padrão e indica que as propriedades da classe referenciada são usadas para representar o objeto referenciado. Outras opções são "ID", "OID" e "GUID".
Isso fornece um alto nível de controle e é muito útil. Já se foi o tempo de mapear manualmente seus objetos para JSON.
Mais uma coisa
Em vez de definir os parâmetros de mapeamento no nível da propriedade, você também pode definir um mapeamento JSON em um bloco XData. O seguinte bloco XData com o nome OnlyLowercaseTopLevel tem as mesmas configurações de nossa classe de evento acima.
Class Model.Event Extends (%Persistent, %JSON.Adaptor)
{
Property Name As %String;
Property Location As Model.Location;
XData OnlyLowercaseTopLevel
{
<Mapping xmlns="http://www.intersystems.com/jsonmapping">
<Property Name="Name" FieldName="eventName"/>
<Property Name="Location" Include="INPUTONLY"/>
</Mapping>
}
}
Há uma diferença importante: os mapeamentos JSON em blocos XData não alteram o comportamento padrão, mas você deve referenciá-los nas chamadas %JSONImport() e %JSONExport() correspondentes como o último argumento, por exemplo:
USER>do event.%JSONExport("OnlyLowercaseTopLevel")
{"eventName":"Global Summit"}
Se não houver bloco XData com o nome fornecido, o mapeamento padrão será usado. Com essa abordagem, você pode configurar vários mapeamentos e fazer referência ao mapeamento necessário para cada chamada individualmente, concedendo ainda mais controle e tornando seus mapeamentos mais flexíveis e reutilizáveis.
Espero que essas melhorias facilitem sua vida e aguardo seu feedback. Deixe-me saber o que você pensa nos comentários.
Artigo
Heloisa Paiva · Maio 26, 2023
Introdução
Dentre as diversas soluções que desenvolvemos aqui na Innovatium, um desafio comum é a necessidade de acesso ao tamanho das bases de dados. Entretanto, notei que isso não é algo tão trivial no IRIS. Esse tipo de informação é importante para manter um controle do fluxo de dados e do custo em GB's de um sistema a ser implementado. Contudo, o que realmente me chamou atenção é a necessidade dela para uma função muito importante: migrar para cloud. Afinal, quem não quer migrar seus sistemas para cloud hoje em dia, certo?
Os serviços de cloud oferecem tudo que um sistema precisa de maneira descomplicada: mirroring, escalabilidade, proteção dos dados, facilidade de fluxo, e o que faz toda pessoa jurídica se apaixonar: é pago pelo uso. E ainda mais, com as gigantescas Google (Cloud), Microsoft (Azure), Amazon (AWS), etc. oferecendo seus serviços quase impecáveis a preços acessíveis, é algo que com um pouco de investimento pode ser uma realidade para qualquer um que queira aumentar seus lucros e economizar a longo prazo. Além do mais, para quem já está aqui, a própria InterSystems tem seus serviços de Cloud também.
Por essa razão venho aqui apresentar o app que estou desenvolvendo, no qual não é só possível, mas também é fácil observar tamanhos das globais, para que as análises necessárias para obter um serviço em cloud seja apenas tão complicada quanto o seu provedor favorito a complique.
Inspiração
Me inspirando nas aplicações isc-global-size-tracing e globals-tool, estou criando uma versão que possa unir o que há de melhor nas duas e acrescentar adaptações necessárias para o nosso negócio. Mas antes de mostrar meu desenvolvimento, vou apresentar brevemente as aplicações inspiradas.
A isc-global-size-tracing oferece serviços de análises a partir de classes dentro do próprio Iris, com métodos mais amigáveis ao usuário e opções de tasks scheduladas que atualizam uma tabela com vários dados sobre as globais. Há também opções prontas de exportação das informações para arquivos externos. Assim, se já existe uma familiaridade com Object Script não é tão difícil tirar alguns minutos para entender o seu funcionamento e adaptar ao seu negócio.
Já a globals-tool mostra um portal em forma de website onde é possível checar os tamanhos alocados e os tamanhos disponíveis para cada global, dentro de seus namespaces. É um pouco mais simples, porém mais amigável ao usuário, podendo ser utilizada também para disponibilizar os dados para pessoas de outras áreas sem conhecimento algum em programação. Mudanças e adaptações podem exigir conhecimento prévio não somente em Object Script, mas também em React e similares.
O que eu gostaria então é de trazer as várias opções da primeira com a usabilidade da segunda, além de adicionar outras opções de análises e exportações.
O App - o que já está disponível
Nesta sessão, vou explicar um pouco do que já foi feito e como pode ser aproveitado por você e sua empresa.
Todo o código está disponível para consulta, clone ou download no meu Github.
Para começar a utilizar é muito simples, basta clonar ou fazer download do repositório na pasta que preferir e configurar para a sua instância do IRIS.
Abra o terminal na pasta onde deseja clonar o repositório e use o comando
git clone https://github.com/heloisatambara/iris-size-django
Entre na pasta iris-size-django e instale os requisitos necessários:
.../iris-size-django > pip install -r requirements.txt
Edite o arquivo .../iris-size-django/globalsize/settings.py para personalizar as configurações da base de dados. Não mude o parâmetro ENGINE, ele deve apontar para a aplicação de CaretDev, django-iris. Contudo, altere o NAME para o namespace, USER e PASSWORD para um usuário com privilégios adequados (é necessário acesso ao namespace %SYS e poder criar uma tabela no namespace desejado) e os parâmetros HOST e PORT devem direcionar à sua instância.
De volta ao terminal, vamos rodar os comandos makemigrations para preparar o app, migrate para criar a tabela onde vamos armazenar as informações das globais e runserver para colocar tudo em prática.
> python manage.py makemigrations
> python manage.py migrate
> python manage.py runserver
Agora, é só abrir o link http://127.0.0.1:8000/globals/ no seu navegador preferido e clicar em update. Em poucos segundos você deve ter uma tabela com todos os namespaces e suas respectivas globais, mostrando a quantidade (em MB) de memória alocada e utilizada, como mostra a imagem no início da sessão.
A instância a ser analizada está em globals/api/methods.py, e não precisa ser necessariamente a mesma em que definimos em DATABASES, em settings.py. Para mais detalhes sobre esse tipo de conexão, você pode ler a documentação sobre InterSystems IRIS Cloud SQL ou os tutoriais Python e IRIS na prática com exemplos (na sessão ObjectScript no ambiente Python) ou Retornando valores com Python.
Agora vamos dar uma olhada melhor na parte de cima da foto:
Aqui, podemos ver as opções de filtros, exportação e ordenação.
Você pode digitar parte do nome da base de dados ou das globais para ver resultados específicos, ou digitar um número positivo em Size ou Allocated para ver resultados acima daquele valor. Se digitar um número negativo, verá os resultados abaixo do módulo do valor. Clique no botão Filter para efetivar o filtro.
Selecione o modelo de exportação (CSV, XML, JSON) e clique em Export para exportar para a pasta iris-size-django. Lembrando que os filtros aplicados serão refletidos na exportação. Além disso, você pode mudar o endereço de exportação no código, em .../iris-size-django/globals/views.py.>
Por fim, você pode selecionar ordenação crescente em ordem alfabética pelo nome da base de dados e da global ou pelo tamanho ocupado ou quantidade alocada. Clique no botão Filter para efetivar a ordenação e os filtros digitados. Obs.: A ordenação não será refletida na exportação.
No final da página você pode ver a contagem de globais dentro dos filtros selecionados, além da quantidade total alocada e utilizada:
Se você quiser fazer análises mais profundas ou até mesmo ver a tabela original, uma opção boa é entrar no portal de administração da instância referida em settings.py, na sessão do SQL e selecionar o namespace referido no mesmo local. A tabela terá sido criada automaticamente pelo Django com o nome de SQLUser.globals_iglobal, e ali você pode usar as ferramentas da InterSystems para executar todo tipo de query.
Obs.: em settings, o parâmetro DEBUG está marcado como TRUE pois ainda está em desenvolvimento.
Ideias futuras
Minhas primeiras ideias são trazer mais funções para o portal. Atualmente é possível alterar configurações de exportação e da base de dados diretamente no código, além de fazer queries mais complexas pelo portal do IRIS. Contudo, acredito que unificar tudo isso no portal será mais eficiente. Além disso, também estou estudando para acrescentar um acompanhamento do fluxo de dados por período.
Por fim, gostaria de ouvir de você: acha que esse tipo de aplicação pode ajudar seu negócio? Que outras funções você gostaria de ver aqui? Gostaria de ver alguma função já existente do IRIS de maneira mais amigável? Ou gostaria que algo apresentado aqui fosse mais simplificado?
Pergunta
Jullyanna Mendes · Dez. 22, 2020
Boa tarde, estou desenvolvimento uma demo com iKnow, e gostaria de saber como eu acesso dados do healthshare? Tudo bem Jullyanna?
Que tipo de informação não estruturada você pretende recuperar do HealthShare ? Você consegue me explicar um pouco mais sobre a demo que você tem em mente ?
Obrigado. Boa tarde, basicamente seria pegar o acessos dos pacientes oncológicos e identificar as possibilidades de ser avançado, iniciante ou mediano. Uma forma de prevenir e antecipar os tratamentos. bom dia Jullyanna,
entendo que esta informação deva estar em algum laudo de exame carregado no HealthShare, correto? portanto deve estar dentro do SDA, de onde podemos extrair e utilizar o NLP(iKnow) analisar semanticamente o conteúdo. Você já definou os conceitos que indicaram o estado do evento? avançado, iniciante ou mediano, já que teremos que entender que conceitos indicam os estados que pretendemos avaliar. Se você quiser podemos marcar uma conversa para entender melhor suas necessidades. Olá Jullyanna.
Como cliente você pode acessar tanto a documentação do produto como os treinamentos online, seja para o HealthShare ou para o iKnow.
Assim como o Rochael, me coloco também a disposição para uma conversa para entendermos melhor a sua necessidade.
Obrigado. Boa tarde, o SDA ele está transmitindo o binário do PDF. Dentro do healthshare o documento ta em formado pdf. bom dia Jullyanna,
neste caso teremos que montar uma alternativa para extrair o conteúdo do PDF.
Podemos marcar uma conversa na semana que vem para tratarmos do assunto?
obrigado e feliz natal Oi Juliana, tudo bem?
Você já viu aplicação do @Yuri.Gomes no OpenExchange?
https://openexchange.intersystems.com/package/OCR-Service
Na descrição da aplicação você tem a seguinte informação:InterSystems IRIS Interoperability OCR ServiceThis is an InterSystems IRIS Interoperability OCR Service to extract text from images and pdfs from a file into a multipart request from form or http request.
What The the service doesThis application receive a http multipart request with a file, extract text using OCR from Tesseract and returns the result
Também tem um video que ele fez demonstrando um pouco mais.
https://www.youtube.com/watch?v=E8MHJ0kAdbk
Espero que possa ajudar.
Abraços
Pergunta
Alexandre Lago · Jun. 21, 2022
Olá, comecei a trabalhar com Caché a pouco, e estou em treinamento.
Me surgiu uma dúvida de uma determinada atividade, aonde a regra solicita que o usuário digite uma string, e selecione uma das opções listradas, e uma delas e informar a palavra com maior número de carácteres da string.
Já tentei de tudo, porém não consegui chegar a nenhuma conclusão.
Desde já agradeço Olá Alexandre,Não entendi muito bem, mas, você já fez a contagem de caracteres da string que o usuário digitou? Se não de uma olhada na função $Length https://docs.intersystems.com/ens201815/csp/docbook/Doc.View.cls?KEY=RCOS_flength
Oi Alexandre! O que me veio em mente rapidamente foi criar um código que transforme a sua string/frase em uma lista de palavras para depois percorrer a lista contando o numero de letras de cada palavra da lista.
Algo assim:
Set frase = "Como contar a palavra com maior numero de caracteres"
#; cria uma lista da string com delimitador " " espaço Set fraseList = $Listfromstring(frase," ")
#; percorre a lista e imprime a posição da palavra na frase (i), o tamanho da palavra ($length) e a palavra ($listget(fraseList,i))For i=1:1:$Listlength(fraseList) w !,i_"- tamanho:"_$length($listget(fraseList,i))_"->"_$lg(fraseList,i)
O código acima pode ser executado no Terminal. Mas se você somente desejar saber o maior tamanho, basta salvar o tamanho em uma variável comparando os tamanhos. Exemplo:
Set maiorTamanho=""For i=1:1:$Listlength(fraseList) { set tamanho=$length($listget(fraseList,i)) if tamanho>maiorTamanho { set maiorTamanho=tamanho set maiorPalavra=$listget(fraseList,i) }}
Write !,maiorPalavra_" - tamanho: "_maiorTamanho
Espero que ajude! :-) MAIORPALAVRA ;Verifica qual é a maior palavra da frase Set Frase="O Cache da InterSystems é Imbativel" Write !,"Frase : ",Frase,! ; Escreve Set qp=$Length(Frase," ") ; Conta as palavras da frase Set (qtl,mqtl)=0 ; Zera os contadores For pal=1:1:qp { ; comando For Set palavra=$Piece(Frase," ",pal) ; percorre as palavras Set qtl=$L(palavra) ; Verifica tamanho da palavra If qtl>mqtl Set mqtl=qtl,pi=pal ; Define a maior palavra } Write !,"A maior palavra da frase é ",$Piece(Frase," ",pi),! ; Escreve a maior palavra ; ; Crie um programa COS com os comandos acima e execute no terminal
Artigo
Heloisa Paiva · Jun. 5
Duas Grandes Mudanças para a Ferramenta de Código Aberto TestCoverage: Suporte a Python Embutido e uma Nova Interface de Usuário
Python Embutido
Anteriormente, o TestCoverage conseguia rastrear a cobertura de testes unitários apenas para códigos escritos em ObjectScript. Ele ignorava o código escrito em outras linguagens, como Python, nas estatísticas de cobertura.
À medida que mais e mais código de aplicativo IRIS está sendo escrito em Python Embutido em vez de apenas ObjectScript, é fundamental que o TestCoverage possa incluir os resultados de cobertura para o código Python Embutido . Clientes (através dos issues do TestCoverage no GitHub), bem como outros na InterSystems, expressaram interesse em ver o suporte ao Python Embutido.
O usuário ainda instala e executa o TestCoverage da mesma forma que antes, conforme descrito no TestCoverage GitHub. TOs resultados de cobertura para código Python Embutido agora são incluídos nas estatísticas de cobertura agregadas, bem como na coloração individual das linhas, como exibido no exemplo acima.
Por baixo do capô, a cobertura do Python Embutido é rastreada usando o tracer sys.settrace do Python, independentemente do %Monitor.System.LineByLine do ObjectScript, e então os resultados são combinados e exibidos juntos. Isso pode causar pequenas discrepâncias em quais linhas são marcadas como executáveis (ou seja, podem ser executadas). Por exemplo, na imagem acima, o Python considera a instrução elif como executável, mas o ObjectScript não considera a instrução ElseIf como executável. No fim das contas, qualquer linha de código marcada em vermelho não foi coberta, e qualquer linha de código marcada em verde ainda foi coberta; isso apenas afeta ligeiramente quais linhas de código ignoramos, o que não causa nenhum problema.
Nova Interface de Usuário do TestCoverage
A interface de usuário anterior do TestCoverage era uma antiga Zen UI que não mostrava muitas das estatísticas úteis que o TestCoverage rastreava. Além disso, o TestCoverage só podia ser executado a partir da linha de comando.
Para resolver esses problemas, criamos uma nova Angular UI baseada no isc.perf.ui, a interface de usuário existente para interagir com o Line-By-Line Monitor (^%SYS.MONLBL). O aplicativo web vem com uma API REST e uma conexão WebSocket para recuperar dados do servidor IRIS. Ele também corrige a autenticação de usuário anterior para o isc.perf.ui, de modo que agora ele usa o login/logout padrão do IRIS. Isso também está publicamente disponível no Open Exchange, sob o nome isc-perf-ui. Abaixo estão algumas das novas funcionalidades e usos da interface de usuário.
Instalação
Existem algumas etapas adicionais para instalar o isc.perf.ui se você quiser usar os novos recursos do TestCoverage. Apenas no Windows, você precisa habilitar o protocolo WebSocket do IIS. Em qualquer sistema operacional, você precisa conceder a um usuário específico (geralmente CSPSystem) uma permissão de recurso (geralmente %DB_User) no portal de gerenciamento do IRIS. Essas etapas são descritas na página do GitHub do isc-perf-ui..
Página de Cobertura de Teste
Na página de Cobertura de Teste, você pode selecionar os parâmetros com os quais deseja executar o TestCoverage em seus testes de unidade.
As explicações dos parâmetros incluem descrições do que cada um deles controla. Você também pode clicar em uma caixa de entrada para ver um valor de exemplo, e há validação de entrada para garantir que seus dados estejam em um formato válido.
Depois de clicar em "enviar", a chamada para executar o TestCoverage será iniciada, e você verá o progresso ao vivo dos seus testes de unidade no registro na parte inferior da página.
Após a conclusão da execução dos testes, o menu suspenso à direita deve abrir com uma lista de combinações de rotina e caminho de teste, bem como a porcentagem geral de cobertura do seu código e o link para os próprios resultados dos testes de unidade.
Clique em qualquer um deles para ser levado à página de resultados de cobertura daquela rotina, dentro do diretório de teste de unidade.
Aqui, você consegue ver quais linhas de código foram cobertas pelos seus testes de unidade, de acordo com o TestCoverage. Há também métricas adicionais, como TempoTotal, que monitora a quantidade de tempo que o código passou em uma determinada linha, do início ao fim da execução.
Você pode ordenar ainda mais em ordem crescente ou decrescente clicando nas setas ao lado dos cabeçalhos; essa é uma forma útil de ver quais linhas de código demoram mais para executar.
Por fim, o botão "Mostrar Métodos" abre uma tabela com a complexidade ciclomática de cada um dos seus métodos, mostrando quais são os mais complexos e vulneráveis a bugs.
Quando terminar, você pode clicar no botão "Voltar" para retornar à página inicial. O botão vermelho "Limpar resultados" permite apagar todas as suas execuções de cobertura de teste.
Página de Cobertura Histórica
Após clicar em um ID de Execução específico de uma execução anterior, você pode visualizar os resultados de cobertura em nível de classe (cobertura de linha, cobertura de método, tempo) para todas as classes daquela execução. Estes são os mesmos dados da página de resultados principal do TestCoverage. Esta tabela também é classificável por cada coluna.
Mais uma vez, ambas as ferramentas estão disponíveis no InterSystems Open Exchange (isc-perf-ui e Test Coverage Tool) e no GitHub. Bons testes a todos!
Artigo
Angelo Bruno Braga · Fev. 25, 2022
Neste artigo iremos construir uma configuração IRIS de alta disponibilidade utilizando implantações Kubernetes com armazenamento persistente distribuído substituindo o "tradicional" espelhamento IRIS. Esta implantação será capaz de tolerar falhas relacionadas a infraestrutura como falhas em nós, armazenamento e de Zonas de Disponibilidade. A abordagem descrita reduz muito a complexidade da implantação em detrimento um objetivo de tempo de recuperação (RTO) ligeiramente estendido.Figura 1 - Espelhamento Tradicional x Kubernetes com Armazenamento Distribuído
Todos os códigos fonte deste artigo estão disponíveis em https://github.com/antonum/ha-iris-k8s TL;DR
Assumindo que você possui um cluster com 3 nós e também uma certa familiaridade com o Kubernetes – vá em frente:
kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/master/deploy/longhorn.yaml
kubectl apply -f https://github.com/antonum/ha-iris-k8s/raw/main/tldr.yaml
Se você não tem certeza sobre o que as duas linhas acima fazem ou não possui o sistema onde executá-las - pule para a seção “Requisitos de Alta Disponibilidade". Iremos explicar tudo detalhadamente conforme evoluirmos no artigo.
Esta primeira linha instala o Longhorn - armazenamento distribuído Kubernetes de código aberto. A segunda instala o InterSystems IRIS, utilizando um volume baseado no Longhorn para o Durable SYS.
Aguarde até que todos os pods atinjam o estado de "em execução". kubectl get pods -A
Agora você deve ser capaz de acessar o portal de administração do IRIS em http://<IP Público do IRIS>:52773/csp/sys/%25CSP.Portal.Home.zen (a senha padrão é 'SYS') e a linha de comando do IRIS através de:
kubectl exec -it iris-podName-xxxx -- iris session iris
Simule a Falha
Agora pode começar a bagunçar as coisas. Mas, antes de fazê-lo, tente adicionar alguns dados na base de dados para se certificar que estarão lá quando o IRIS voltar a ficar disponível.
kubectl exec -it iris-6d8896d584-8lzn5 -- iris session iris
USER>set ^k8stest($i(^k8stest))=$zdt($h)_" running on "_$system.INetInfo.LocalHostName()
USER>zw ^k8stest
^k8stest=1
^k8stest(1)="01/14/2021 14:13:19 running on iris-6d8896d584-8lzn5"
Nossa "engenharia do caos" inicia aqui:
# Parar o IRIS - Contêiner será reiniciado automaticamente
kubectl exec -it iris-6d8896d584-8lzn5 -- iris stop iris quietly
# Deletar o pod - O Pod será recriado
kubectl delete pod iris-6d8896d584-8lzn5
# "Drenar à força" o nó que está servindo o pod IRIS - O Pod seria recriado em outro nó
kubectl drain aks-agentpool-29845772-vmss000001 --delete-local-data --ignore-daemonsets --force
# Deletar o nó - O Pod seria recriado em outro nó
# bem... você não pode realmente fazê-lo com o kubectl. Localize a instância ou a VM e a destrua.
# se você possuir acesso à maquina - desligue a força ou desconecte o cabo de rede. Estou falando sério!
Requisitos de Alta Disponibilidade
Estamos construindo um sistema que possa tolerar uma falha das seguintes:
Instância IRIS dentro de um contêiner/VM. Falha a nível do IRIS.
Falha no Pod/Contêiner.
Indisponibilidade temporária do nó de cluster individual. Um bom exemplo seria quando uma Zona de Disponibilidade fica temporariamente fora do ar.
Falha permanente do nó de cluster individual ou disco.
Basicamente os cenários que executamos na seção ˜Simule a falha".
Se alguma destas falhas ocorrer, o sistema deverá se recuperar sem que necessite de nenhum envolvimento humano e sem que ocorra nenhuma perda de dados.. Tecnicamente existem limites do que a persistência de dados garante. O IRIS por si só provê com base no Ciclo do Journal e no uso de transações em uma aplicação: https://docs.intersystems.com/irisforhealthlatest/csp/docbook/Doc.View.cls?KEY=GCDI_journal#GCDI_journal_writecycle De qualquer forma, estamos falando de menos de dois segundos de objetivo de ponto de recuperação (RPO).
Outros componentes do sistema (Serviço de APIs Kubernetes, base de dados etcd, serviço de Balanceamento de Carga, DNS e outros) estão fora do escopo e são gerenciados tipicamente pelo Serviço Gerenciado Kubernetes como o Azure AKS ou AWS EKS, então assumimos que eles já estão em alta disponibilidade.
Outra forma de se ver – somos responsáveis por lidar com falhas individuais de componentes e armazenamento, assumindo que o resto é tratado pelo provedor de infraestrutura/nuvem.
Arquitetura
Quando se trata de alta disponibilidade para o InterSystems IRIS, a recomendação tradicional é a utilização de Espelhamento. Utilizando o Espelhamento você terá duas instâncias ligadas do IRIS replicando de forma síncrona os dados. Cada nó mantém uma cópia completa da base de dados e, se o nó principal falhar, os usuários reconectam no nó Backup. Essencialmente, com a abordagem de uso do Espelhamento, o IRIS é responsável pela redundância tanto de computação quanto de armazenamento.
Com os servidores de espelhamento implantados em zonas de disponibilidade distintas o espelhamento provê a redundância necessária tanto para falhas de computação quanto para falhas de armazenamento e permite o excelente objetivo de tempo de recuperação (RTO - tempo necessário para que um sistema se recupere após uma falha) de apenas poucos segundos. Você pode encontrar o modelo de implantação para o IRIS Espelhado na Nuvem AWS aqui: https://community.intersystems.com/post/intersystems-iris-deployment%C2%A0guide-aws%C2%A0using-cloudformation-template
O lado menos bonito do espelhamento é a complexidade de configurá-lo, realizando procedimentos de backups e restore e lidando com a falta de replicação para configurações de segurança e arquivos locais que não os de bases de dados.
Orquestradores de contêineres como o Kubernetes (espere, estamos em 2021… exitem outros?!) proveem uma redundância computacional através da implantação de objetos, automaticamente reiniciando o Pod/Contêiner IRIS no caso de falha. É por isso que você vê apenas um nó IRIS executando no diagrama de arquitetura Kubernetes. Ao invés de manter um segundo nó de IRIS executando nós terceirizamos a disponibilidade de computação para o Kubernetes. O Kubernetes se certificará que o pod IRIS pode ser recriado no caso de falha do pod original por qualquer motivo.
Figura 2 Cenario de Failover
Tudo bem até agora… Se o nó do IRIS falhar, o Kubernetes apenas cria um novo. Dependendo do seu cluster, ele leva algo entre 10 a 90 segundos para trazer o IRIS de volta ao ar após uma falha de computação. É um passo atrás comparado com apenas alguns segundos no espelhamento mas, se é algo que você pode tolerar no caso de um evento indesejado, a recompensa é a grande redução da complexidade. Sem configuração de espelhamento e nem configurações de segurança e replicações de arquivos com que se preocupar.
Sinceramente, se você se logar em um contêiner, executando o IRIS no Kubernetes, você nem mesmo perceberá que está executando em um ambiente de alta disponibilidade. Tudo parece e se comporta como uma implantação de uma instância individual de IRIS.
Espere, e quanto ao armazenamento? Estamos lidando com um banco de dados … Seja qual for o cenário de falha que possamos imaginar, nosso sistema deverá cuidar da persistência dos dados também. O Espelhamento depende da computação, local no nó IRIS. Se o nó morre ou fica temporariamente indisponível – o armazenamento para o nó também o fica. É por isso que na configuração de espelhamento o IRIS cuida da replicação das bases de dados no nível do IRIS.
Precisamos de um armazenamento que possa não só preservar o estado da base de dados na reinicialização do contêiner mas também possa prover redundância em casos como a queda do nó ou de um segmento inteiro da rede (Zona de Disponibilidade). A apenas alguns anos atrás não existia uma resposta fácil para isso.Como você pode supor a partir do diagrama acima – temos uma baita resposta agora. É chamada de armazenamento distribuído de contêineres.
O armazenamento distribuído abstrai os volumes de hospedeiros subjacentes e os apresenta como um armazenamento conjunto disponível para todos os nós do cluster k8s. Nós utilizamos o Longhorn https://longhorn.io neste artigo; é grátis, de código aberto e bem fácil de instalar. Mas, você também pode verificar outros como o OpenEBS, Portworx e StorageOS que devem disponibilizar as mesmas funcionalidades. Rook Ceph é outro projeto de incubação CNCF a se considerar. No outro lado do espectro existem soluções de armazenamento de nível empresarial como o NetApp, PureStorage e outros.
Guia Passo a Passo
Na seção TL;DR nós instalamos tudo de uma vez. O Apêndice B lhe guiará através da instalação passo a passo e dos procedimentos de validação.
Armazenamento Kubernetes
Vamos voltar um pouco por um segundo e falar sobre contêineres e armazenamento em geral e como o IRIS se encaixa no cenário.
Por padrão todos os dados dentro do contêiner são efêmeros. Quando o contêiner morre, o dado desaparece. No Docker, você pode utilizar o conceito de volumes. Essencialmente isto permite que você exponha o diretório de seu SO hospedeiro para o contêiner.
docker run --detach
--publish 52773:52773
--volume /data/dur:/dur
--env ISC_DATA_DIRECTORY=/dur/iconfig
--name iris21 --init intersystems/iris:2020.3.0.221.0
No exemplo acima estamos iniciando o contêiner IRIS e fazendo com que o diretório local do hospedeiro ‘/data/dur’ fique acessível no ponto de montagem ‘/dur’ do contêiner. Desta forma, se o contêiner estiver armazenando qualquer coisa neste diretório, ela será preservada e disponível para utilização quando o próximo contêiner iniciar.
Do lado IRIS das coisas, podemos instruir o IRIS para armazenar todos os dados que devem sobreviver ao reinicio do contêiner em um diretório determinado especificando ISC_DATA_DIRECTORY. Durable SYS é o nome da funcionalidade do IRIS que você pode precisar dar uma olhada na documentação https://docs.intersystems.com/irisforhealthlatest/csp/docbook/Doc.View.cls?KEY=ADOCK#ADOCK_iris_durable_running
No Kubernetes a sintaxe é diferente mas os conceitos são os mesmos.
Aqui está a Implantação Kubernetes básica para IRIS.
apiVersion: apps/v1
kind: Deployment
metadata:
name: iris
spec:
selector:
matchLabels:
app: iris
strategy:
type: Recreate
replicas: 1
template:
metadata:
labels:
app: iris
spec:
containers:
- image: store/intersystems/iris-community:2020.4.0.524.0
name: iris
env:
- name: ISC_DATA_DIRECTORY
value: /external/iris
ports:
- containerPort: 52773
name: smp-http
volumeMounts:
- name: iris-external-sys
mountPath: /external
volumes:
- name: iris-external-sys
persistentVolumeClaim:
claimName: iris-pvc
Na especificação de implantação acima, a parte ‘volumes’ lista os volumes de armazenamento. Eles podem estar disponíveis fora do contêiner através do Requisição de Volume Persistente (PersistentVolumeClaim) como ‘iris-pvc’. O 'volumeMounts' expõe este volume dentro do contêiner. ‘iris-external-sys’ é o identificador que amarra a montagem do volume ao volume específico. Na verdade, podemos ter múltiplos volumes e este nome é utilizado apenas para distinguir um de outro. Você pode chamá-lo de ‘steve’ se quiser.
A variável de ambiente ISC_DATA_DIRECTORY, já familiar, instrui o IRIS a utilizar um ponto de montagem específico para armazenar todos os dados que precisam sobreviver ao reinício do contêiner.
Agora vamos dar uma olhada na Requisição de Volume Persistente iris-pvc.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: iris-pvc
spec:
storageClassName: longhorn
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
Bastante direto. Requisitando 10 gigabytes, montado como Read/Write em apenas um nó, utilizando a classe de armazenamento de ‘longhorn’.
Aquela storageClassName: longhorn é de fato crítica aqui.
Vamos olhar quais classes de armazenamento estão disponíveis no meu cluster AKS:
kubectl get StorageClass
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
azurefile kubernetes.io/azure-file Delete Immediate true 10d
azurefile-premium kubernetes.io/azure-file Delete Immediate true 10d
default (default) kubernetes.io/azure-disk Delete Immediate true 10d
longhorn driver.longhorn.io Delete Immediate true 10d
managed-premium kubernetes.io/azure-disk Delete Immediate true 10d
Existem poucas classes de armazenamento do Azure, instaladas por padrão e uma do Longhorn que instalamos como parte de nosso primeiro comando:
kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/master/deploy/longhorn.yaml
Se você comentar #storageClassName: longhorn na definição da Requisição de Volume Persistente, será utilizada a classe de armazenamento que estiver marcada como “default” que é o disco regular do Azure.
Para ilustrar porquê precisamos de armazenamento distribuído vamos repetir o experimento da “engenharia do caos” que descrevemos no início deste artigo sem o armazenamento longhorn. Os dois primeiros cenários (parar o IRIS e deletar o Pod) deveriam completar com sucesso e os sistemas deveriam se recuperar ao estado operacional. Ao tentar tanto drenar ou destruir o nó deveria deixar o sistema em estado de falha.
#drenar o nó a força
kubectl drain aks-agentpool-71521505-vmss000001 --delete-local-data --ignore-daemonsets
kubectl describe pods
...
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 57s (x9 over 2m41s) default-scheduler 0/3 nodes are available: 1 node(s) were unschedulable, 2 node(s) had volume node affinity conflict.
Essencialmente, o Kubernetes tentará reiniciar o pod IRIS pod no cluster mas, o nó onde ele iniciou originalmente não está disponível e os outros dois nós apresentam “conflito de afinidade de nó de volume”. Com este tipo de armazenamento o volume só está disponível no nó onde ele foi originalmente criado, visto que ele é basicamente amarrado ao disco disponível no nó hospedeiro.
Com o longhorn como classe de armazenamento, tanto o experimento “drenar a força” quanto o “destruir nó” funcionam com sucesso e o pod IRIS retorna a operação brevemente. Para conseguí-lo o Longhorn assume controle dos armazenamentos disponíveis dos 3 nós do cluster e replica os dados através deles. O Longhorn prontamente repara o armazenamento do cluster se um dos nós fica permanentemente indisponível. No nosso cenário “Destruir nó” o pod IRIS é reiniciado em outro nó rapidamente utilizando as replicas nos dois outros volumes remanescentes. Então, o AKS provisiona um novo nó para substituir o nó perdido e assim que ele está pronto, o Longhorn entra em ação e reconstrói os dados necessários no novo nó. Tudo é automático, sem seu envolvimento.
Figura 3 Longhorn reconstruindo a réplica do volume no nó substituído
Mais sobre implantação k8s
Vamos dar uma olhada em alguns outros aspectos de nossa implantação:
apiVersion: apps/v1
kind: Deployment
metadata:
name: iris
spec:
selector:
matchLabels:
app: iris
strategy:
type: Recreate
replicas: 1
template:
metadata:
labels:
app: iris
spec:
containers:
- image: store/intersystems/iris-community:2020.4.0.524.0
name: iris
env:
- name: ISC_DATA_DIRECTORY
value: /external/iris
- name: ISC_CPF_MERGE_FILE
value: /external/merge/merge.cpf
ports:
- containerPort: 52773
name: smp-http
volumeMounts:
- name: iris-external-sys
mountPath: /external
- name: cpf-merge
mountPath: /external/merge
livenessProbe:
initialDelaySeconds: 25
periodSeconds: 10
exec:
command:
- /bin/sh
- -c
- "iris qlist iris | grep running"
volumes:
- name: iris-external-sys
persistentVolumeClaim:
claimName: iris-pvc
- name: cpf-merge
configMap:
name: iris-cpf-merge
strategy: Recreate, replicas: 1 informa ao Kubernetes que em algum momento ele deve manter uma e exatamente uma instância de do pod IRIS executando. Isto é o que dá conta do nosso cenário “deletar pod”.
A seção livenessProbe garante que o IRIS está sempre ativo no contêiner e trata o cenário “IRIS está fora”. initialDelaySeconds garante algum tempo para que o IRIS inicie. Você pode querer aumentá-lo se o IRIS estiver levando um tempo considerável para iniciar em sua implementação.
CPF MERGE funcionalidade do IRIS que lhe permite modificar o conteúdo do arquivo de configuração iris.cpf durante a inicialização do contêiner. Veja https://docs.intersystems.com/irisforhealthlatest/csp/docbook/DocBook.UI.Page.cls?KEY=RACS_cpf#RACS_cpf_edit_merge para a documentação referente a ela. Neste exemplo estou utilizando o Kubernetes Config Map para gerenciar o conteúdo do arquivo mesclado: https://github.com/antonum/ha-iris-k8s/blob/main/iris-cpf-merge.yaml Aqui ajustamos os valores para os global buffers e gmheap, utilizados pela instância do IRIS, mais tudo que você pode encontrar no arquivo iris.cpf. Você pode até mesmo alterar a senha padrão do IRIS utilizando o campo `PasswordHash`no arquivo CPF Merge. Leia mais em: https://docs.intersystems.com/irisforhealthlatest/csp/docbook/Doc.View.cls?KEY=ADOCK#ADOCK_iris_images_password_auth
Além da Requisição de Volume Persistente https://github.com/antonum/ha-iris-k8s/blob/main/iris-pvc.yaml da implantação https://github.com/antonum/ha-iris-k8s/blob/main/iris-deployment.yaml e ConfigMap com o conteúdo do CPF Merge https://github.com/antonum/ha-iris-k8s/blob/main/iris-cpf-merge.yaml nossa implantação precisa de um serviço que exponha a implantação IRIS para a Internet pública: https://github.com/antonum/ha-iris-k8s/blob/main/iris-svc.yaml
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
iris-svc LoadBalancer 10.0.18.169 40.88.123.45 52773:31589/TCP 3d1h
kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 10d
O IP Externo do iris-svc pode ser utilizado para acessar o portal de administração do IRIS através de http://40.88.123.45:52773/csp/sys/%25CSP.Portal.Home.zen. A senha padrão é 'SYS'.
Backup/Restore e Dimensionamento do Armazenamento
Longhorn disponibiliza uma interface web para usuários para configurar e gerenciar volumes.
Identificar o pod, executar o componente de interface para usuários (longhorn-ui) e estabelecer um encaminhamento de portas com kubectl:
kubectl -n longhorn-system get pods
# note the longhorn-ui pod id.
kubectl port-forward longhorn-ui-df95bdf85-gpnjv 9000:8000 -n longhorn-system
A interface para usuários Longhorn ficará disponível em http://localhost:9000
Figura 4 Longhorn UI
Além da alta disponibilidade, a maioria das soluções de armazenamento para contêineres disponibilizam opções convenientes para backup, snapshots e restore. Os detalhes são específicos para cada implantação mas a convenção comum é de que o backup é associado ao VolumeSnapshot. Também é assim para o Longhorn. Dependendo da sua versão do Kubernetes e do seu provedor você também pode precisar instalar o volume snapshotter https://github.com/kubernetes-csi/external-snapshotter
`iris-volume-snapshot.yaml` é um exemplo de um snapshot de volume. Antes de utilizá-lo você deve configurar backups ou para um bucket S3 ou para um volume NFS no Longhorn. https://longhorn.io/docs/1.0.1/snapshots-and-backups/backup-and-restore/set-backup-target/
# Realizar um backup consistente do volume IRIS
kubectl apply -f iris-volume-snapshot.yaml
Para o IRIS é recomendado que você execute o External Freeze antes de realizar o backup/snapshot e então o Thaw depois. Veja os detalhes aqui: https://docs.intersystems.com/irisforhealthlatest/csp/documatic/%25CSP.Documatic.cls?LIBRARY=%25SYS&CLASSNAME=Backup.General#ExternalFreeze
Para aumentar o tamanho do volume IRIS - ajuste a requisição de armazenamento na requisição de volume persistente (arquivo `iris-pvc.yaml`), utilizado pelo IRIS.
...
resources:
requests:
storage: 10Gi #altere este valor para o necessário
Então, aplique novamente a especificação pvc. O Longhorn não consegue aplicar esta alteração enquanto o volume está conectado ao Pod em execução. Temporariamente altere o contador de réplicas para zero na implantação para que o tamanho do volume possa ser aumentado.
Alta Disponibilidade – Visão Geral
No início deste artigo nós definimos alguns critérios para alta disponibilidade. Aqui está como conseguimos alcançá-los com esta arquitetura:
Domínio de Falha
Mitigado automaticamente por
Instância IRIS no contêiner/VM. Falha no nível do IRIS.
Sonda Deployment Liveness reinicia o contêiner no caso do IRIS estar fora
Falha de Pod/Contêiner.
Implantação recria o Pod
Indisponibilidade temporária de um nó do cluster individual. Um bom exemplo seria uma Zona de Disponibilidade fora.
Implantação recria o pod em outro nó. O Longhorn torna os dados disponíveis em outro nó.
Falha permanente de um nó de cluster individual ou disco.
Mesmo do anteiror + k8s cluster autoscaler substituindo um nó danificado por um novo. O Longhorn reconstrói os dados no novo nó.
Zumbis e outras coisas a considerar
Se você estiver familiarizado em executar o IRIS em contêineres Docker, você já deve ter utilizado a flag `--init`.
docker run --rm -p 52773:52773 --init store/intersystems/iris-community:2020.4.0.524.0
O objetivo desta flag é previnir a formação de processos "zumbis". No Kubernetes, você pode tanto utilizar ‘shareProcessNamespace: true’ (considerações de segurança se aplicam) ou em seus próprios contêineres utilizar `tini`. Exemplo de Dockerfile com tini:
FROM iris-community:2020.4.0.524.0
...
# Add Tini
USER root
ENV TINI_VERSION v0.19.0
ADD https://github.com/krallin/tini/releases/download/${TINI_VERSION}/tini /tini
RUN chmod +x /tini
USER irisowner
ENTRYPOINT ["/tini", "--", "/iris-main"]
Desde 2021, todas as imagens de contêineres disponibilizadas pela InterSystems incluiria tini por padrão.
Você pode posteriormente diminuir o tempo de recuperação para os cenários “Drenar a força o nó/destruir nó” ajustando poucos parâmetros:
Política de Deleção de Pods do Longhorn https://longhorn.io/docs/1.1.0/references/settings/#pod-deletion-policy-when-node-is-down e despejo baseado em taint do kubernetes: https://kubernetes.io/docs/concepts/scheduling-eviction/taint-and-toleration/#taint-based-evictions
Disclaimer
Como funcionário InterSystems, Eu tenho que colocar isto aqui: O Longhorn é utilizado neste artigo como um exemplo de Armazenamento em Blocos Distribuído para Kubernetes. A InterSystems não valida e nem emite uma declaração de suporte oficial para soluções ou produtos de armazenamento individual. Você precisa testar e validar se qualquer solução específica de armazenamento atende a suas necessidades.
Solucões para armazenamento distribuído podem possuir características substancialmente distintas de performance., quando comparadas a armazenamento em nó local. Especialmente para operações de escrita, onde os dados devem ser escritos em múltiplas localidades antes de ser considerado em estado persistente. Certifique-se de testar suas cargas de trabalho e entender o comportamento específico, bem como as opções que seu driver para Interface de Armazenamento de Contêiner (CSI) oferece.
Basicamente, a InterSystems não valida e/ou endossa soluções específicas de armazenamento como o Longhorn da mesma forma que não valida marcas de HDs ou fabricantes de hardware para servidores. Eu pessoalmente achei o Longhorn fácil de se utilizar e seu time de desenvolvimento extremamente responsivo e útil na página do projeto no GitHub. https://github.com/longhorn/longhorn
Conclusão
O ecossistema Kubernetes evoluiu de forma significante nos últimos anos e, com a utilização de soluções de armazenamento em blocos distribuído, você pode agora construir uma configuração de Alta Disponibilidade que pode manter uma instância IRIS, nó de cluster e até mesmo falhas de Zonas de Disponibilidade.
Você pode terceirizar a alta disponibilidade de computação e armazenamento para componentes do Kubernetes, resultando em um sistema significativamente mais simples de se configurar e manter, comparando-se ao espelhamento tradicional do IRIS. Da mesma forma, esta configuração pode não lhe prover o mesmo RTO e nível de performance de armazenamento que uma configuração de Espelhamento.
Neste artigo criamos uma configuração IRIS de alta disponibilidade utilizando o Azure AKS como Kubernetes gerenciado e o sistema de armazenamento distribuído Longhorn. Você pode explorar múltiplas alternativas como AWS EKS, Google Kubernetes Engine para K8s gerenciados, StorageOS, Portworx e OpenEBS para armazenamento distribuído para contêiner ou mesmo soluções de armazenamento de nível empresarial como NetApp, PureStorage, Dell EMC e outras.
Apêndice A. Criando um Cluster Kubernetes na nuvem
Serviço Gerenciado Kubernetes de um dos provedores públicos de nuvem é uma forma fácil de criar um cluster k8s necessário para esta configuração.A configuração padrão do AKS da Azure é pronto para ser utilizado para a implantação descrita neste artigo.
Criar um novo cluster AKS com 3 nós. Deixe todo o resto padrão.
Figura 5 Criar um cluster AKS
Instale o kubectl em seu computador localmente: https://kubernetes.io/docs/tasks/tools/install-kubectl/
Registre seu cluster AKS com o kubectl local
Figura 6 Registre o cluster AKS com kubectl
Depois disto, você pode voltar para o início do artigoe instalar o longhorn e a implantação IRIS.
A instalação no AWS EKS é um pouco mais complicada. Você precisa se certificar que cada instância em seu grupo de nós tem o open-iscsi instalado.
sudo yum install iscsi-initiator-utils -y
Instalar o Longhorn no GKE necessita de um passo extra, descrito aqui: https://longhorn.io/docs/1.0.1/advanced-resources/os-distro-specific/csi-on-gke/
Apêndice B. Instalação Passo a Passo
Passo 1 – Cluster Kubernetes e kubectl
Você precisa um cluster k8s com 3 nós. Apêndice A descreve como conseguir um na Azure.
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-agentpool-29845772-vmss000000 Ready agent 10d v1.18.10
aks-agentpool-29845772-vmss000001 Ready agent 10d v1.18.10
aks-agentpool-29845772-vmss000002 Ready agent 10d v1.18.10
Passo 2 – Instalar o Longhorn
kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/master/deploy/longhorn.yaml
Certifique-se de que todos os pods no namespace ‘longhorn-system’ estão no estado de em execução. Isso pode levar alguns minutos.
$ kubectl get pods -n longhorn-system
NAME READY STATUS RESTARTS AGE
csi-attacher-74db7cf6d9-jgdxq 1/1 Running 0 10d
csi-attacher-74db7cf6d9-l99fs 1/1 Running 1 11d
...
longhorn-manager-flljf 1/1 Running 2 11d
longhorn-manager-x76n2 1/1 Running 1 11d
longhorn-ui-df95bdf85-gpnjv 1/1 Running 0 11d
Consulteo guia de instalação do Longhornpara detalhes e solução de problemas https://longhorn.io/docs/1.1.0/deploy/install/install-with-kubectl
Passo 3 – Faça um clone do repositório GitHub
$ git clone https://github.com/antonum/ha-iris-k8s.git
$ cd ha-iris-k8s
$ ls
LICENSE iris-deployment.yaml iris-volume-snapshot.yaml
README.md iris-pvc.yaml longhorn-aws-secret.yaml
iris-cpf-merge.yaml iris-svc.yaml tldr.yaml
Passo 4 – implemente e valide os componentes um a um
o arquivo tldr.yaml contém todos os componentes necessários para a implantação em um pacote. Aqui iremos instalá-los um a um e validar a configuração de cada um deles individualmente.
# Se você aplicou o tldr.yaml previamente, apague-o.
$ kubectl delete -f https://github.com/antonum/ha-iris-k8s/raw/main/tldr.yaml
# Criar a Requisição de Volume Persistente
$ kubectl apply -f iris-pvc.yaml
persistentvolumeclaim/iris-pvc created
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
iris-pvc Bound pvc-fbfaf5cf-7a75-4073-862e-09f8fd190e49 10Gi RWO longhorn 10s
# Criar o Mapa de Configuração
$ kubectl apply -f iris-cpf-merge.yaml
$ kubectl describe cm iris-cpf-merge
Name: iris-cpf-merge
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
merge.cpf:
----
[config]
globals=0,0,800,0,0,0
gmheap=256000
Events: <none>
# criar a implantação iris
$ kubectl apply -f iris-deployment.yaml
deployment.apps/iris created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
iris-65dcfd9f97-v2rwn 0/1 ContainerCreating 0 11s
# Anote o nome do pod. Você irá utilizá-lo para conectar ao pod no próximo comando
$ kubectl exec -it iris-65dcfd9f97-v2rwn -- bash
irisowner@iris-65dcfd9f97-v2rwn:~$ iris session iris
Node: iris-65dcfd9f97-v2rwn, Instance: IRIS
USER>w $zv
IRIS for UNIX (Ubuntu Server LTS for x86-64 Containers) 2020.4 (Build 524U) Thu Oct 22 2020 13:04:25 EDT
# h<enter> to exit IRIS shell
# exit<enter> to exit pod
# acesse os logs do contêiner IRIS
$ kubectl logs iris-65dcfd9f97-v2rwn
...
[INFO] ...started InterSystems IRIS instance IRIS
01/18/21-23:09:11:312 (1173) 0 [Utility.Event] Private webserver started on 52773
01/18/21-23:09:11:312 (1173) 0 [Utility.Event] Processing Shadows section (this system as shadow)
01/18/21-23:09:11:321 (1173) 0 [Utility.Event] Processing Monitor section
01/18/21-23:09:11:381 (1323) 0 [Utility.Event] Starting TASKMGR
01/18/21-23:09:11:392 (1324) 0 [Utility.Event] [SYSTEM MONITOR] System Monitor started in %SYS
01/18/21-23:09:11:399 (1173) 0 [Utility.Event] Shard license: 0
01/18/21-23:09:11:778 (1162) 0 [Database.SparseDBExpansion] Expanding capacity of sparse database /external/iris/mgr/iristemp/ by 10 MB.
# crie o serviço iris
$ kubectl apply -f iris-svc.yaml
service/iris-svc created
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
iris-svc LoadBalancer 10.0.214.236 20.62.241.89 52773:30128/TCP 15s
Passo 5 – Acesse o portal de administração
Finalmente – conecte-se ao portal de administração do IRIS, utilizando o IP externo do serviço: http://20.62.241.89:52773/csp/sys/%25CSP.Portal.Home.zen usuário _SYSTEM, senha SYS. Será solicitado que você altere no seu primeiro login.
Artigo
Gabriel Vellasques Tureck · Mar. 22, 2021
Olá comunidade,
Você sabia sobre OWASP e os dez principais riscos de segurança de aplicativos da Web para sua API da Web ou aplicativos da Web?
OWASP é uma fundação comunitária criada para nos ajudar a melhorar a segurança de aplicativos / APIs da web. O OWASP torna os aplicativos da web mais seguros por meio de seus projetos de software de código aberto liderados pela comunidade, centenas de capítulos em todo o mundo, dezenas de milhares de membros e hospedando conferências locais e globais.
Para resumir os principais procedimentos para tornar seu aplicativo da web / API da web mais seguro, o OWASP publicou as recomendações "Top 10 Web Application Security Risks" (fonte: https://owasp.org/www-project-top-ten/):
1- Injection.. Falhas de injeção, como injeção de SQL, NoSQL, OS e LDAP, ocorrem quando dados não confiáveis são enviados a um intérprete como parte de um comando ou consulta. Os dados hostis do invasor podem induzir o intérprete a executar comandos indesejados ou acessar dados sem a autorização adequada.2- Broken Authentication.. As funções de aplicativo relacionadas à autenticação e gerenciamento de sessão são frequentemente implementadas incorretamente, permitindo que os invasores comprometam senhas, chaves ou tokens de sessão ou explorem outras falhas de implementação para assumir as identidades de outros usuários temporária ou permanentemente.3- Sensitive Data Exposure. Muitos aplicativos da web e APIs não protegem adequadamente dados confidenciais, como finanças, saúde e PII. Os invasores podem roubar ou modificar esses dados fracamente protegidos para conduzir fraude de cartão de crédito, roubo de identidade ou outros crimes. Os dados confidenciais podem ser comprometidos sem proteção extra, como criptografia em repouso ou em trânsito, e requerem precauções especiais quando trocados com o navegador.4- XML External Entities (XXE). Muitos processadores XML mais antigos ou mal configurados avaliam referências de entidades externas em documentos XML. Entidades externas podem ser usadas para divulgar arquivos internos usando o manipulador de URI de arquivo, compartilhamentos de arquivos internos, varredura de porta interna, execução remota de código e ataques de negação de serviço.5- Broken Access Control. As restrições sobre o que os usuários autenticados têm permissão para fazer muitas vezes não são aplicadas de forma adequada. Os invasores podem explorar essas falhas para acessar funcionalidades e / ou dados não autorizados, como acessar contas de outros usuários, visualizar arquivos confidenciais, modificar dados de outros usuários, alterar direitos de acesso, etc.6- Security Misconfiguration. A configuração incorreta de segurança é o problema mais comum. Isso geralmente é o resultado de configurações padrão inseguras, configurações incompletas ou ad hoc, armazenamento em nuvem aberta, cabeçalhos HTTP configurados incorretamente e mensagens de erro detalhadas contendo informações confidenciais. Não apenas todos os sistemas operacionais, estruturas, bibliotecas e aplicativos devem ser configurados com segurança, mas também devem ser corrigidos / atualizados em tempo hábil.7- Cross-Site Scripting (XSS). As falhas de XSS ocorrem sempre que um aplicativo inclui dados não confiáveis em uma nova página da web sem validação ou escape adequado, ou atualiza uma página da web existente com dados fornecidos pelo usuário usando uma API do navegador que pode criar HTML ou JavaScript. O XSS permite que os invasores executem scripts no navegador da vítima, que podem sequestrar as sessões do usuário, desfigurar sites ou redirecionar o usuário para sites maliciosos.8- Insecure Deserialization. A desserialização insegura geralmente leva à execução remota de código. Mesmo que as falhas de desserialização não resultem na execução remota de código, elas podem ser usadas para realizar ataques, incluindo ataques de repetição, ataques de injeção e ataques de escalonamento de privilégios.9- Using Components with Known Vulnerabilities. Componentes, como bibliotecas, estruturas e outros módulos de software, são executados com os mesmos privilégios do aplicativo. Se um componente vulnerável for explorado, esse tipo de ataque pode facilitar a perda séria de dados ou o controle do servidor. Aplicativos e APIs que usam componentes com vulnerabilidades conhecidas podem minar as defesas do aplicativo e permitir vários ataques e impactos.10- Insufficient Logging & Monitoring. O registro e o monitoramento insuficientes, juntamente com a integração ausente ou ineficaz com a resposta a incidentes, permitem que os invasores ataquem ainda mais os sistemas, mantenham a persistência, se movam para mais sistemas e adulterem, extraiam ou destruam dados. A maioria dos estudos de violação mostra que o tempo para detectar uma violação é de mais de 200 dias, normalmente detectado por partes externas em vez de processos internos ou monitoramento.
Algumas técnicas podem ser usadas para implementar os dez primeiros OWASP, consulte a tabela:
Recursos de recomendação OWASP
Recursos
Injection
No SQL, use parâmetros de entrada especificados usando o “?” caractere ou variáveis de host de entrada (por exemplo,: var). Evite concatenar instruções SQL e argumentos de método de entrada.Use a API Sanitazer como https://developer.mozilla.org/en-US/docs/Web/API/HTML_Sanitizer_API
Broken Authentication
Crie senhas fortes, consulte o documento da Microsoft: https://support.microsoft.com/en-us/windows/create-and-use-strong-passwords-c5cebb49-8c53-4f5e-2bc4-fe357ca048eb
Não use senhas dentro do código-fonte, criptografe-o, use serviços de cofre ou serviços SSO.
Externalize suas senhas usando parâmetros do ambiente Docker / OS
Não permita ataques de força bruta usando gateways de API como IAM: https://docs.intersystems.com/components/csp/docbook/Doc.View.cls?KEY=CIAM1.5
Sensitive Data Exposure
Exposição de dados confidenciais Evite retornar dados de cartão de crédito, dados de saúde e outros dados confidenciais em sua API, se não for possível, criptografe os canais de mensagens e o armazenamento de dados confidenciais. Minimize a coleta de dados ao mínimo possível.
XXE
XXE Use% XMLAdaptor
Broken Access Control
Use ferramentas de gerenciamento de acesso como IAM: https://docs.intersystems.com/components/csp/docbook/Doc.View.cls?KEY=CIAM1.5
Security Misconfiguration
Atualize seu software periodicamente e execute o software Pentest em seu ambiente para realizar os procedimentos apropriados.
Siga o Guia de administração de segurança da intersystems: https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GCAS
XSS
Faça a sanitização / validação de entrada, consulte dicas OWASP: https://cheatsheetseries.owasp.org/cheatsheets/Input_Validation_Cheat_Sheet.html
Insecure deserialization
Crie hash para arquivos, crie pastas mais seguras sem permissão de execução para armazenar arquivos e validar extensões de arquivos
Using Components with Known Vulnerabilities
Na pilha da InterSystems o Apache Web Server é a ferramenta mais conhecida, portanto tome cuidado ao configurá-la para a produção, seguindo: https://www.tecmint.com/apache-security-tips/. Habilite o firewall do seu sistema operacional para ubuntu executar ufw enable (consulte: https://www.digitalocean.com/community/tutorials/how-to-set-up-a-firewall-with-ufw-on-ubuntu-18-04 )
Insufficient Logging & Monitoring
Use o Log Monitor (https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GCM_MONITOR)
Siga-o: https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=ALOG
Monitore usando SAM: https://docs.intersystems.com/sam/csp/docbook/DocBook.UI.Page.cls?KEY=ASAM
Você pode usar o software WAF em alinhamento com os dez principais OWASP, consulte: https://www.g2.com/categories/api-security ou use o IAM da InterSystems. Da lista G2, gosto do 42 crunch, que permite uma conta gratuita e você indica seu arquivo OpenAPI e ele é analisado para relatar recomendações, veja em https://42crunch.com/owasp-api-security-top-10/.
Artigo
Heloisa Paiva · Abr. 22
Há treze anos, obtive dois diplomas de graduação em engenharia elétrica e matemática, e logo em seguida comecei a trabalhar em tempo integral na InterSystems, sem usar nenhuma das duas. Uma das minhas experiências acadêmicas mais memoráveis e perturbadoras foi em Estatística II. Em uma prova, eu estava resolvendo um problema de intervalo de confiança moderadamente difícil. O tempo estava acabando, então (sendo um engenheiro) escrevi a integral definida na folha de prova, digitei-a na minha calculadora gráfica, escrevi uma seta com "calculadora" sobre ela e depois escrevi o resultado. Meu professor, carinhosamente conhecido como "Dean, Dean, a Máquina de Reprovar", me chamou ao seu escritório alguns dias depois. Ele não gostou nada do meu uso da calculadora gráfica. Achei isso irracional – afinal, era Estatística II, não Cálculo II, e eu fiz a parte de Estatística II corretamente... certo? Acontece que escrever "calculadora" sobre aquela seta me rendeu zero crédito na questão e uma risada do Dean; se eu tivesse omitido, teria tirado zero na prova. Eita.
Tenho repensado bastante nesse evento recentemente. A IA Generativa faz com que minha TI-89 Titanium, coberta de adesivos de estrelas por notas máximas nas aulas de matemática do ensino médio e modificada para rodar Tetris, pareça um tijolo de plástico superfaturado. Bem, era um tijolo de plástico superfaturado há 20 anos, mas ainda é hoje também.
My trusty old TI-89 Titanium
Riscos e Regras
Com o advento de ambientes de desenvolvimento integrado (IDEs) realmente bons e habilitados por IA, existe o potencial para que a IA faça o trabalho do desenvolvedor de software de nível inicial médio... certo? Se esse desenvolvedor de software de nível inicial estiver usando Python – ou alguma outra linguagem suficientemente popular na qual os modelos foram treinados – então sim. E se você se sentir confortável com o débito técnico de montanhas de código que podem ser lixo completo – ou pior ainda, majoritariamente bom com pequenos trechos de lixo escondidos – então sim. E se você tiver algum meio místico para equipar desenvolvedores de software de nível inicial em funções de principal/arquiteto sem exigir que eles escrevam nenhum código, então sim. Isso é muitas ressalvas, e precisamos de algumas regras para mitigar esses riscos.
Nota: estes riscos são independentes das preocupações com direitos autorais/propriedade intelectual que são de mão dupla: estamos infringindo código protegido por direitos autorais no conjunto de dados de treinamento ao usar a saída da GenAI? Estamos arriscando nossa própria propriedade intelectual ao enviá-la para a nuvem? Para este artigo, assumimos que ambos estão cobertos por nossa escolha de modelo/provedor de serviços, mas estas são grandes preocupações impulsionadoras no nível corporativo.
Regra nº 1: Escopo do Trabalho
Não use GenAI para fazer algo que você mesmo não conseguiria, além ou perto dos limites da sua compreensão e capacidade atuais. Voltando à ilustração original, se você está em Estatística II, pode usar GenAI para fazer Cálculo II – mas provavelmente não Estatística II, nem Estatística I e definitivamente não Teoria da Medida. Isso significa que, se você é um estagiário ou desenvolvedor de nível inicial, não deve deixar que ela faça nenhum do seu trabalho. Usar GenAI como uma busca no Google turbinada é totalmente aceitável, e usar um autocomplete inteligente pode ser OK, apenas não deixe que ela escreva código novo e do zero para você. Se você é um desenvolvedor sênior, use-a para fazer trabalho de desenvolvedor de nível inicial em tecnologias nas quais você tem proficiência de nível sênior; pense nisso como uma delegação semelhante e revise o código como se tivesse sido escrito por um desenvolvedor de nível inicial. Minha experiência de desenvolvimento de software assistido por IA tem sido com o Windsurf, que eu gosto nesse aspecto: consegui treiná-lo um pouco, dando-lhe regras e conselhos para lembrar, seguir e (como um desenvolvedor de nível inicial) ocasionalmente aplicar no contexto errado.
Regra nº 2: Atribuição
Se a GenAI escrever uma grande parte do código para você, certifique-se de que a mensagem de commit, o próprio código e qualquer documentação legível por humanos associada sejam muito claros sobre isso. Deixe óbvio: eu não escrevi isso, um computador escreveu. Isso é um serviço para aqueles que revisam seu código: eles devem tratá-lo como escrito por um desenvolvedor de nível inicial, não por você, e como parte da revisão devem questionar se a IA está fazendo coisas além da sua profundidade técnica (o que pode estar errado – e você não saberia). É um serviço para aqueles que olham seu código no futuro e tentam determinar se é lixo. E é um serviço para aqueles que tentam treinar futuros modelos de IA em seu código, para evitar o colapso e "defeitos irreversíveis nos modelos resultantes".
Regra nº 3: Modo de Aprendizagem e Reforço
Quando você está na faculdade cursando Estatística II, há algum valor no reforço das habilidades aprendidas em Cálculo II. Para ser honesto, esqueci a maior parte de ambos agora, por falta de uso. Talvez "Dean, Dean, a Máquina de Reprovar" estivesse certo afinal. Em situações em que seu objetivo principal é aprender coisas novas ou reforçar suas habilidades existentes, novas (ou de anos atrás!), fazer todo o trabalho sozinho é a melhor maneira de seguir. A prototipagem rápida é uma exceção (embora as Regras nº 1 e nº 2 ainda se apliquem!), mas mesmo no trabalho diário regular seria prejudicial tornar-se excessivamente dependente da GenAI para realizar tarefas de "desenvolvedor de nível inicial", pessoal ou organizacionalmente. Sempre precisaremos de desenvolvedores de nível inicial, porque sempre precisaremos de desenvolvedores principais e arquitetos, e o caminho entre os dois é uma função contínua. (Aí, eu me lembro de algumas coisas de matemática!)
Isso é algo que eu adoraria ver como um recurso de IDE: alternar para o "modo de aprendizado" onde a IA observa/orienta você em vez de fazer qualquer trabalho por você. Na ausência de alguma implementação personalizada em software, você também pode optar por usar a IA dessa maneira.
Regra nº 4: Reflexão
Não se perca no turbilhão de trabalho, entregas e reuniões. Reserve um tempo para refletir. Isso é importante em geral e importante no uso da GenAI especificamente.
Essa tecnologia está tornando minha vida melhor ou pior?
Está me tornando mais inteligente ou mais burro?
Estou produzindo mais valor ou apenas mais resultado?
Essa saída inclui dívida técnica incorrida por conveniência?
Estou aprendendo de forma mais eficaz ou esquecendo como aprender?
Como as soluções da IA se comparam às que tenho em mente? Ignoro algo que a IA presta atenção? A IA sistematicamente ignora coisas que são importantes para mim?
Estou me tornando como o ChatGPT, introduzindo sem alma e aleatoriamente listas com marcadores e texto em negrito nos documentos que escrevo? (Oh não!!)
Um Pensamento Final: GenAI e Desenvolvimento Baseado em InterSystems IRIS
Em um mundo onde os desenvolvedores esperam que a GenAI seja capaz de fazer o trabalho por eles – ou pelo menos torná-lo muito mais fácil – uma de duas coisas pode acontecer:
Tecnologias e linguagens dominantes (veja-se: Python) podem se tornar superdominantes, mesmo que não sejam as melhores para a tarefa em questão. Já que a GenAI é tão boa em Python, por que usar outra coisa?
Tecnologias e linguagens de nicho (veja: ObjectScript) podem se tornar mais palatáveis para os desenvolvedores. Aprender uma nova linguagem não é tão difícil se a GenAI puder ajudá-lo a começar rapidamente e fazer as coisas direito.
Minha esperança é que, à medida que fornecedores e líderes de desenvolvimento de software perceberem os riscos que descrevi, as ferramentas tendam a apoiar o último resultado – o que é uma oportunidade para a InterSystems. Sim, as pessoas podem simplesmente usar Python Embutido para tudo, mas nosso legado tecnológico e os pontos fortes da plataforma principal também podem se tornar mais palatáveis, e o ObjectScript pode receber o amor que merece.