Limpar filtro
Artigo
Daniel Noronha da Silva · Jun. 9, 2023
Pesquisando sobre InterSystems IRIS e como ela pode transformar o negócio de uma organização me deparei com uma possibilidade: Como uma grande empresa pode melhorar sua eficiência operacional e oferecer uma experiência de compra mais personalizada para seus clientes?
Digamos que uma grande empresa do setor de varejo possui uma grande quantidade de dados de vendas, estoque e preferências de clientes que precisam ser analisados para identificar padrões e esse grande volume de dados precisa ser gerenciado e processado em tempo real para criar uma experiência de compra mais personalizada para cada cliente. Nesse aspecto a tecnologia InterSystems IRIS cai como uma luva para atender aos requisitos dessa empresa.
O InterSystems IRIS foi projetado para trabalhar com cargas de trabalho em tempo real, o que é essencial para análise de dados em grande volumes em ambientes de rápidas mudanças. Com capacidade de processar transações em alta velocidade e em tempo real, a plataforma IRIS pode lidar com esse tipo de dados sem nenhum problema. Principalmente nos tempos de hoje com o advento de microserviços e infraestrutura inteligente, a plataforma InterSystems IRIS é altamente escalável e pode lidar com grandes volumes de transações em tempo real, isso significa que, a empresa pode expandir sua infraestrutura de TI para atender às suas necessidades crescentes sem comprometer o desempenho ou a disponibilidade do sistema.
Segurança e integridade dos dados, a InterSystems IRIS permite que a empresa integre facilmente dados de várias fontes, incluindo bancos de dados relacionais e não relacionais, arquivos de texto e dados estruturados e não estruturados, com isso a empresa pode acessar e analisar facilmente todos os seus dados independente de onde estejam armazenados. Também podemos aplicar machine learning, a plataforma IRIS possui recursos avançados de aprendizado de máquina permitindo que a empresa treine modelos de machine learning para análise preditiva e recomendações personalizadas. Com essas capacidades a empresa pode analisar os dados dos clientes para identificar padrões de comportamento e oferecer recomendações de produtos personalizados com base em seus históricos de compras e preferências.
A InterSystems IRIS pode ser aplicada e utilizadas pelas mais diversas áreas do mercado, mas nesse caso em específico, para uma grande varejista é uma solução perfeita para obter insights, coletando os dados de vendas e estoque em tempo real em suas lojas físicas e online, esses dados são enviados para a IRIS processar em real time. Também, a IRIS integra dados de várias fontes, com isso podemos ajustar a produção, o estoque e a oferta de produtos para atender à demanda dos clientes.
Artigo
Claudio Devecchi · Jun. 20, 2023
Neste artigo, vou compartilhar o tema que apresentamos no Global Summit 2023, na sessão Tech Exchange. Eu e @Rochael.Ribeiro.
Nesta oportunidade, abordamos os seguintes tópicos, os quais iremos explorar neste artigo:
Ferramentas Open Exchange para o desenvolvimento rápido de APIs
Open Api Specification (OAS)
Maneira Tradicional versus Desenvolvimento Rápido
API Composta (Interoperabilidade)
Abordagens Spec-First ou Api-First
Governança e Monitoramento de Api's
Demonstração (vídeo)
Ferramentas Open Exchange para o Desenvolvimento Rápido de APIs Rest
Como estamos falando de desenvolvimento rápido de APIs modernas (Rest / json) vamos utilizar duas ferramentas do Intersystems Open Exchange:
A primeira é um framework para desenvolvimento rápido de APIs a qual iremos detalhar neste artigo.
https://openexchange.intersystems.com/package/IRIS-apiPub
A segunda é para utilizarmos o Swagger como interface de visualização da especificação e documentação das APIs Rest desenvolvidas na plataforma IRIS, bem como a sua utilização/execução. A base para o seu funcionamento é o padrão Open Api specification (OAS), descrito a seguir:
https://openexchange.intersystems.com/package/iris-web-swagger-ui
O que é Open API Specification (OAS)?
É um padrão utilizado mundialmente para definir, documentar e consumir APIs. Na maioria dos casos, as APIs são desenhadas antes mesmo da sua implementação. Vamos falar mais sobre isso nos próximos tópicos.
Mas este padrão também serve para agilizar testes e chamadas das APIs em ferramentas (Rest Apis Clients) de mercado, como o Swagger, Postman, Insomnia, etc…
Forma tradicional de publicação de uma API usando o Intersystems IRIS
Imagine que queremos publicar uma API com base em um método IRIS já existente (figura abaixo).
No método tradicional:
1: Temos que pensar em como os consumidores irão chamá-la. Por exemplo: Qual path e verbo iremos utilizar e como iremos responder. Se em um objeto JSON ou como um plain/text.
2: Vamos ter que construir um novo método em uma classe %CSP.REST que irá manipular a chamada http e irá fazer uma chamada para este método.
3: Vamos manipular a resposta do método para a resposta http planejada para o usuário final.
4: Teremos que pensar em como iremos prover o código de sucesso e como iremos tratar as exceções.
5: Vamos mapear a rota para o nosso novo método.
6: Temos que pensar em como iremos prover a documentação da API para o usuário final. Iremos usar o Open Api Specification?
7: E se por exemplo tivermos um método com um payload de requisição ou resposta, o tempo de implementação de tudo irá aumentar, porque o payload também deverá ser documentado.
E como podemos ser mais rápidos?
Simplesmente marcando o método IRIS com o atributo [WebMethod], seja ele qual for, que o framework irá cuidar da sua publicação, utilizando-se do padrão OAS 3.x.
E por quê o padrão 3.x é tão importante?
Porque ele também documenta detalhadamente todas as propriedades dos payloads na entrada e saída.
Desta maneira, quaisquer ferramentas Rest Client de mercado podem instantaneamente se acoplar às APIs, como o Insomnia, Postman, Swagger, etc...
Utilizando o Swagger já iremos visualizar a nossa API (acima) e já podemos chamá-la.
Customização da API
Mas e se eu precisar customizar a minha API?
Por exemplo: Ao invés do nome do método eu quero que o path seja outro. E quero que os parâmetros de entrada estejam no path, não somente como um query param.
Definimos uma notação específica acima do método, onde podemos complementar as meta-informações que o método por si só não provê.
Neste exemplo estamos definindo um outro path para a nossa api e complementando as informações para o usuário final ter uma api mais amigável.
Mapa de projeção de método IRIS para API Rest
Este framework suporta inúmeros tipos de parâmetros.
Neste mapa podemos destacar os tipos complexos de parâmetros, ou seja, os objetos. Eles serão expostos automaticamente como um payload JSON e cada propriedade será devidamente documentada para o usuário final.
Interoperabilidade (Apis Compostas)
Suportando tipos complexos, é possível também expor métodos construídos para a Interoperabilidade.
É um cenário propício para a construção de APIs compostas, que se utilizam de orquestração de múltiplos componentes externos (outbounds).
Isso significa que os objetos ou mensagens utilizadas como request ou response serão automaticamente publicadas e interpretadas por ferramentas como o swagger.
E é uma forma excelente para testar componentes da interoperabilidade, pois geralmente um template do payload já é carregado para que o usuário saiba quais propriedades a API se utiliza.
Primeiro o desenvolvedor pode focar no teste, depois pode fazer o refinamento e customizar a exposição da API Rest.
Abordagem Spec-first ou Api-first
Outro conceito amplamente utilizado atualmente é ter a definição da API antes mesmo de sua implementação.
Com este framework é possível fazer a importação de uma especificação (OAS) para uma classe com a estrutura (spec) dos métodos já definidos, faltando apenas a sua implementação.
Governança e Monitoramento de Apis
Para a governança das APIs, é igualmente recomendada a utilização do IAM em conjunto com o apiPub.
Além de ter múltiplos plugins, o IAM pode se acoplar rapidamente às APIs através do padrão OAS.
O apiPub oferece um tracing adicional para as APIs que será demonstrado a seguir.
Demonstração
Download & Documentação
Intersystems Open Exchange: https://openexchange.intersystems.com/?search=apiPub
Documentação Completa: https://github.com/devecchijr/apiPub Muito bom Claudio! Esse é um recurso que com certeza facilita em muito a vida do desenvolvedor!
Parabéns. Obrigado Djeniffer! Fala @Claudio.Devecchi
O aplicativo é excelente e o artigo está muito bem detalhado! Isso facilita demais a vida de quem desenvolve e busca novas formas de criação. abracos Valeu pelo feedback meu caro @Henrique.GonçalvesDias !
Abraços
Anúncio
Danusa Calixto · Jun. 26, 2023
Olá Comunidade!
Os artigos publicados como tradução para ganhar a bonificação durante o período do concurso foram listados junto com os artigos concorrente. Porém, quero informá-los, de que eles não foram avalizados como artigos participantes e não participaram da votação. Eles foram apurados somente para o efeito da bonificação.
As publicações de traduções correspondentes ao informado acima foram:
Alterar o trace do Visualizador de Mensagens para JSON em vez de XML publicado por @Heloisa.Paiva
API para importar/exportar rotinas publicado por @Heloisa.Paiva
Melhores Templates publicado por @Heloisa.Paiva
Instalando Apache Server e HealthShare HealthConnect no Ubuntu Linux publicado por @Cristiano.Silva
Como obter informações de erro de resultados de compilação em massa de rotina/classe publicado por @Miqueias.Santos
Enviando mensagens para Kafka publicado por @Miqueias.Santos
Exemplo do FHIR e IntegratedML publicado por @Luana.Machado
Agradecemos a todos pela contribuição com as traduções publicadas. Continuem a avaliar e traduzir os artigos de outras comunidades para a comunidade em Português. Isso nos ajuda a manter a comunidade ativa e sempre atualizada.
Ótimo trabalho de vocês 😉
Anúncio
Danusa Calixto · Abr. 2
Olá Comunidade!
Animados com as novidades disponibilizadas na versão mais recente dos produtos InterSystems IRIS, InterSystems IRIS for Health, and HealthShare Health Connect ?
A versão 2025.1 dos produtos está cheia de novidades incluindo melhorias na tela de Configuração da Produção e no Editor DTL.
Saiba mais sobre a experiência aprimorada do usuário para a construção de integrações com os produtos InterSystems®. Aya Heshmat, Product Manager do HealthShare® Health Connect, explica como esses fluxos de trabalho são projetados para melhorar a navegação, fornecer filtragem mais inteligente, otimizar a edição avançada e permitir a integração perfeita do controle de origem.
Assista ao vídeo Building Integrations: A New User Experience e fique por dentro!
Compartilhe conosco nos comentários suas impressões e feedback! 😉
Artigo
Mark Bolinsky · Nov. 23, 2020
## Introdução
Recentemente, a InterSystems concluiu uma comparação de desempenho e escalabilidade da IRIS for Health 2020.1, cujo foco foi a interoperabilidade do HL7 versão 2. Este artigo descreve a taxa de transferência observada para diversas cargas de trabalho e também apresenta diretrizes de configuração geral e dimensionamento para sistemas nos quais a IRIS for Health é usada como um mecanismo de interoperabilidade para as mensagens do HL7v2.
A comparação simula cargas de trabalho parecidas com as de ambientes em produção. Os detalhes da simulação são descritos na seção Descrição e metodologia das cargas de trabalho. As cargas de trabalho testadas consistiram de cargas de Patient Administration (ADT) e Observation Result (ORU) do HL7v2 e incluíram transformações e novo roteamento.
A versão 2020.1 da IRIS for Health demonstrou uma taxa de transferência sustentada de mais de 2,3 bilhões de mensagens (entrada e saída) por dia com um servidor simples com processadores escaláveis Intel® Xeon® de 2ª geração e armazenamento Intel® Optane™ SSD DC P4800X Series. Os resultados mais que dobraram a escalabilidade em relação à comparação de taxa de transferência anterior do Ensemble 2017.1 HL7v2.
Durante os testes, a IRIS for Health foi configurada para preservar a ordem PEPS (primeiro a entrar, primeiro a sair) e para fazer a persistência completa das mensagens e filas para cada mensagem de entrada e saída. Ao fazer a persistência das filas e mensagens, a IRIS for Health proporciona proteção dos dados caso haja travamento do sistema, além de recursos completos de procura e reenvio de mensagens passadas.
Além disso, as diretrizes de configuração são abordadas nas seções abaixo, que ajudarão a escolher uma configuração e implantação adequadas para atender às exigências de desempenho e escalabilidade de suas cargas de trabalho.
Os resultados mostram que a IRIS for Health consegue atender a altíssimas taxas de transferência de mensagens em hardware de prateleira e, na maioria dos casos, permite que um único servidor pequeno forneça interoperabilidade de HL7 para toda a organização.
* * *
## Visão geral dos resultados
Foram usadas três cargas de trabalho para representar diferentes aspectos da atividade de interoperabilidade do HL7:
* **Carga de trabalho T1:** usa passagem simples de mensagens HL7, com uma mensagem de saída para cada mensagem de entrada. As mensagens são passadas diretamente do serviço empresarial do Ensemble (Ensemble Business Service) para a operação de negócios do Ensemble (Ensemble Business Operation), sem um mecanismo de roteamento. Nenhuma regra de roteamento foi usada, e nenhuma transformação foi executada. Foi criada uma instância de mensagens HL7 no banco de dados por mensagem de entrada.
* **Carga de trabalho T2:** usa um mecanismo de roteamento para alterar uma média de 4 segmentos da mensagem de entrada e roteá-la para uma única interface de saída (1 para 1 com uma transformação). Para cada mensagem de entrada, foi executada uma transformação de dados, e foram criados dois objetos de mensagem HL7 no banco de dados.
* **Carga de trabalho T4:** usa um mecanismo de roteamento para rotear separadamente mensagens modificadas para cada uma das quatro interfaces de saída. Em média, 4 segmentos da mensagem de entrada foram modificadas em cada transformação (1 entrada para 4 saídas com 4 transformações). Para cada mensagem de entrada, foram executadas quatro transformações de dados, foram enviadas quatro mensagens de saída, e foram criados cinco objetos de mensagem HL7 no banco de dados.
As três cargas de trabalha foram executadas em um sistema físico de 48 núcleos com dois processadores escaláveis Intel® Xeon® Gold 6252, com das unidades Intel® Optane™ SSD DC P4800X de 750 GB, com o Red Hat Enterprise Linux 8. Os dados são apresentados como o número de mensagens por segundo (e por hora) de entrada, o número por segundo (e por hora) de saída, bem como o total de mensagens (de entrada e de saída) em 10 horas por dia. Além disso, o uso de CPU é apresentado como medida dos recursos de sistema disponíveis para determinado nível de taxa de transferência.
### Resultados de escalabilidade
_Tabela 1: Resumo da taxa de transferência das quatro cargas de trabalho nesta configuração de hardware testada: _

*Carga de trabalho combinada, com 25% de T1, 25% de T2 e 50% de T4
* * *
## Descrição e metodologia das cargas de trabalho
As cargas de trabalho testadas incluíram mensagens de Patient Administration (ADT) e Observation Result (ORU) do HL7v2, com um tamanho médio de 1,2 KB e uma média de 14 segmentos. Cerca de 4 segmentos foram modificados pelas transformações (para cargas de trabalho T2 e T4). Os testes representam 48 a 128 interfaces de entrada de 48 a 128 interfaces de saída enviando e recebendo mensagens por TCP/IP.
Na carga de trabalho T1, foram usados quatro namespaces separados, cada um com 16 interfaces; na carga de trabalho T2, foram usados três namespaces, cada um com 16 interfaces; na carga de trabalho T4, foram usados quatro namespaces, cada um com 32 interfaces; e, na última "carga de trabalho combinada", foram usados três namespaces, com 16 interfaces para carga de trabalho T1, 16 para carga de trabalho T2 e 32 para carga de trabalho T4.
A escalabilidade foi mensurada aumentando-se gradualmente o tráfego em cada interface para descobrir a taxa de transferência mais alta com critérios de desempenho aceitável. Para que o desempenho seja aceitável, as mensagens devem ser processadas a uma taxa sustentada, sem filas, sem atrasos mensuráveis na entrada das mensagens, e o uso médio de CPU deve ficar abaixo de 80%.
Testes anteriores demonstraram que o tipo de mensagem HL7 usado não é significativo para o desempenho e a escalabilidade do Ensemble. Os fatores significativos são o número de mensagens de entrada, o tamanho das mensagens de entrada e saída, o número de novas mensagens criadas no mecanismo de roteamento e o número de segmentos modificados.
Além disso, testes anteriores demonstraram que o processamento de campos específicos de uma mensagem HL7 em uma transformação de dados não costuma impactar o desempenho de forma significativa. As transformações feitas nesses testes usaram atribuições bem simples para criar novas mensagens. É importante salientar que processamentos complexos (como o uso de consultas SQL extensivas em uma transformação de dados) podem fazer os resultados variarem.
Testes anteriores também indicaram que o processamento de regras não costuma ser significativo. Os conjuntos de regras de roteamento usados nos testes tiveram uma média de 32 regras, e todas eram simples. É importante salientar que conjuntos de regras extremamente grandes ou complexos podem fazer os resultados variarem.
### Hardware
#### Configuração do servidor
Os testes utilizaram um servidor com processadores escaláveis Intel® Xeon® Gold 6252 "_Cascade Lake_" de 2ª geração, com 48 núcleos de 2,1 GHz em um sistema com 2 soquetes, 24 núcleos por soquete com 192 GB de DR4-2933 DRAM e interface de rede Ethernet de 10 Gbits. Foi usado o sistema operacional Red Hat Enterprise Linux Server 8 para esse teste, com a IRIS for Health 2020.1
#### Configuração do disco
É feita a persistência completa no disco das mensagens que passam pela IRIS for Health. Nesse teste, duas unidades Intel® Optane™ SSD DC P4800X de 750 GB internas do sistema foram usadas, dividindo-se os bancos de dados em una unidade e os registros de log em outro. Além disso, para garantir uma comparação real, foi ativado o commit síncrono nos registros de log para forçar a durabilidade dos dados. Para a carga de trabalho T4 descrita anteriormente neste documento, cada mensagem HL7 de entrada gera aproximadamente 50 KB de dados, que podem ser divididos conforme indicado na tabela 2. Os diários de transações geralmente são mantidos na linha por menos tempo que os logs ou dados das mensagens, e isso deve ser levado em conta ao calcular o espaço em disco total necessário.
_Tabela 2: Requisitos de disco por mensagem HL7 de entrada para carga de trabalho T4 _
| Contribuinte | Requisito de dados |
| ------------------------------ | ------------------ |
| Dados do segmento | 4,5 KB |
| Objeto da mensagem HL7 | 2 KB |
| Cabeçalho da mensagem | 1 KB |
| Log de regra de encaminhamento | 0,5 KB |
| Diários de transações | 42 KB |
| Total | 50 KB |
Lembre-se de que a carga de trabalho T4 usa um mecanismo de roteamento para rotear separadamente mensagens modificadas para cada uma das quatro interfaces de saída. Em média, 4 segmentos da mensagem de entrada foram modificadas em cada transformação (1 entrada para 4 saídas com 4 transformações). Para cada mensagem de entrada, foram executadas quatro transformações de dados, foram enviadas quatro mensagens de saída e foram criados cinco objetos de mensagem HL7 no banco de dados.
Ao configurar sistemas para uso em produção, os requisitos reais devem ser calculados considerando-se os volumes de entrada diários, bem como o agendamento de limpeza de mensagens HL7 e a política de retenção de arquivos de registros de logs. Além disso, é necessário configurar no sistema um espaço adequado para registros de log, para evitar que os volumes de disco de registros de log fiquem cheios. Os arquivos de registros de log devem ficar em discos separados fisicamente dos arquivos de banco de dados, tanto por questões de desempenho quanto de confiabilidade.
## Conclusão
A taxa de transferência de mensagens HL7v2 da InterSystems IRIS for Health demonstrada nesses testes ilustra a enorme capacidade de taxa de transferência com uma configuração básica de servidor de prateleira com 2 soquetes para dar suporte a cargas de trabalho de mensagens bastante exigentes de qualquer organização. Além disso, a InterSystems está comprometida a aprimorar constantemente o desempenho e a escalabilidade a cada versão, além de aproveitar os benefícios das tecnologias mais recentes de servidor e nuvem.
O gráfico abaixo apresenta uma visão geral e um comparativo do aumento da taxa de transferência das comparações anteriores do Ensemble 2015.1 e Ensemble 2017.1 com processadores Intel® E5-2600 v3 (_Haswell_) e a comparação do Ensemble 2017.1 com processadores escaláveis Intel® Platinum Series (_Skylake_) de 1ª geração em relação aos resultados mais recentes com os processadores escaláveis Intel® Xeon® Gold Series (_Cascade Lake_) de 2ª geração executando a IRIS for Health 2020.1.
_Gráfico 1: Taxa de transferência de mensagens (em milhões) por 10 horas em um único servidor _

A InterSystems IRIS for Health continua aumentar a taxa de transferência de interoperabilidade a cada versão, além de oferecer flexibilidade quanto aos recursos de conectividade. Como o gráfico acima mostra, a taxa de transferência de mensagens aumentou significativamente e, com cargas de trabalho T2, dobrou em relação a 2017 e mais que triplicou em relação a 2015 na mesma janela de 10 horas e **sustentou mais de 2,3 bilhões** de taxas de mensagens em 24 horas.
Outro indicador importante dos avanços da IRIS for Health é a melhoria da taxa de transferência com cargas mais complexas T2 e T4, que incorporam transformações e regras de roteamento, ao contrário da operação única de passagem da carga de trabalho T1.
A InterSystems está disponível para conversar sobre soluções de acordo com as necessidades de interoperabilidade de sua organização.
Artigo
Guilherme Koerber · Mar. 26, 2021
Se você precisar escrever a Arquitetura de Dados de sua organização e mapear para o IRIS da InterSystems, considere o seguinte Diagrama de Arquitetura de Dados e referências à documentação da íris entre sistemas, consulte:
Mapeamento de arquitetura:
Base de dados SQL: https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=GSQL
Arquivos gerenciados: https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=AFL_mft e https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=SETEDIGuides
Corretor de IoT, Eventos e Sensores: https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=EMQTT
Mensagens: https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=EMQS
NoSQL: https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=GDOCDB
API e Web Services: https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=GREST, https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=GSOAP, https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=AFL_iam e https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=PAGE_interoperability
ETL: https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=SETAdapters, https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=EDTL, https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=EBPL e
Conectores EAI: https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=SETAdapters
Eventos XEP: https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=BJAVXEP, https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=BNETXEP,
Ingestão de Big Data: https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=BSPK
IA: https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=PAGE_text_analytics, https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=APMML, https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=PAGE_python_native, https://www.intersystems.com/br/resources/detail/machine-learning-made-easy-intersystems-integratedml/
Processos: https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=EBPL
Serviço Corporativo: https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=EESB e https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=AFL_iam
Em memória: https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GSCALE_ecp
Conteúdo: https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=GDOCDB
Textual: https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=AFL_textanalytics
Proteção: https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=SETSecurity, https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=TSQS_Applications, https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GCDI e https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GCAS
Inventário: https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=GSA_using_portal e https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GOBJ_xdata
Privacidade: https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=GCAS_encrypt
Ciclo da vida TI, Cópia de segurança e Restaurar: https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=GSA_using_portal, https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=GCDI_backup
Gerenciamento de acesso: https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=TSQS_Authentication, https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=TSQS_Authorization, https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=TSQS_Applications
Replicação e HA: https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=PAGE_high_availability
Monitoramento: https://docs.intersystems.com/sam/csp/docbook/DocBook.UI.Page.cls?KEY=ASAM e https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=PAGE_monitoring
Operação TI: https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=PAGE_platform_mgmt
Visualization: https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=PAGE_bi
Anúncio
Angelo Bruno Braga · Mar. 29, 2021
Olá Desenvolvedores!
Aqui estão os bônus tecnológicos para o concurso de programação InterSystems: Ferramentas de Desenvolvimento que irão lhe dar pontos extras na votação.
Uso de contêineres Docker - 2 pontos
A aplicação ganha o bônus 'Uso de contêiner Docker' se a mesma utiliza o InterSystems IRIS em um contêiner docker. Aqui você encontra o modelo mais simples para iniciar.
Implantação em Pacote ZPM - 2 pontos
Você ganhará este ponto de bônus se você criar e publicar o pacote ZPM(Gerenciador de Pacotes ObjectScript) para sua aplicação Full-Stack de forma que ele possa ser implantado com o seguinte comando
zpm "install o-nome-de-sua-solução-full-stack"
em um IRIS com o cliente ZPM instalado.
Documentação.Cliente ZPM.
Teste Unitário - 2 pontos
Aplicações que possuírem Teste Unitário para o código ObjectScript na plataforma de dados InterSystems ganhará este bônus.
Aprenda mais sobre Teste Unitário em ObjectScript na Documentação e na Comunidade de Desenvolvedores.
Demonstração Online de seu Projeto - 3 pontosColete 3 pontos de bônus a mais se você se você provisionar seu projeto para a nuvem como uma demonstração online. Você pode utilizar este modelo ou qualquer outra alternativa de implantação. Exemplo. Aprenda mais sobre no webinar de lançamento.
Análise de qualidade de código sem bugs - 2 pontos
Incluir a ação do Github de qualidade de código para controle estático de código e faça com que mostre 0 bugs para o seu código ObjectScript. Aprenda mais em nosso webinar de lançamento.
Artigo na Comunidade de Desenvolvedores - 2 pontos
Poste um artigo na Comunidade de Desenvolvedores que descrevam as funcionalidades de seu projeto. Ganhe 2 pontos para cada artigo publicado. Traduções para diferentes idiomas também valem.
Vídeo no YouTube - 3 pontos
Crie um vídeo no Youtube que demonstre seu produto em ação e ganhe 3 pontos de bônus para cada vídeo.
Esta lista de bônus é sujeita à alterações. Fiquem ligados !
Anúncio
Angelo Bruno Braga · Abr. 19, 2021
Olá Desenvolvedores,
Esta semana é a semana de votação para o Concurso de Programação Intersystems: Ferramentas de Desenvolvimento! Então, é a hora de dar o seu voto para as melhores soluções construídas com a plataforma de dados InterSystems IRIS.
🔥 Você decide: VOTE AQUI 🔥
Como votar e o que tem de novo ?
Todos os funcionários InterSystems employees podem votar tanto na nomeação dos Experts quanto na nomeação da Community.
Qualquer desenvolvedor pode votar em seu aplicativo – votos serão computados tanto na nomeação de Experts quanto da Community automaticamente (de acordo com o nível do Global Masters).
Membros da Comunidade de Desenvolvedores: Você pode selecionar 3 projetos: o 1°, 2° e 3° colocados de acordo com sua avaliação. É assim que funcionam os votos da Comunidade:
Quadro de Classificação da Comunidade:
Condições
Lugar
1°
2°
3°
Se você tiver um artigo publicado na Comunidade de Desenvolvedores e um app publicado no Open Exchange (OEX)
9
6
3
Se você tiver ao menos 1 artigo postado na Comunidade de Desenvolvedores ou 1 um app publicado no Open Exchange (OEX)
6
4
2
Se você tiver feito alguma contribuição válida para a Comunidade de Desenvolvedores (publicado um comentário/pergunta, etc.)
3
2
1
Para a nomeação dos Experts, níveis diferentes de experts poderão atribuir mais "pontos":
Quadro de Classificação dos Experts:
Nível
Colocação
1°
2°
3°
Nível VIP no GM, Moderadores, Gerentes de Produtos InterSystems
15
10
5
Nível Ambassador no Global Masters
12
8
4
Nível Expert no Global Masters
9
6
3
Nível Especialista no Global Masters
6
4
2
Nível Advocate no Global Masters ou Funcionários InterSystems
3
2
1
Assim que irá funcionar: Para aqueles que tem qualquer um dos níveis Experts acima, votos serão computados tanto para a nomeação de Experts quanto para a da Comunidade automaticamente.
Para fazer parte da votação, você precisa:
Logar no Open Exchange – As credenciais da Comunidade de Desenvolvedores funcionarão lá.
Faça qualquer contribuição válida para a Comunidade de Desenvolvedores – responda ou faça perguntas, escreva um artigo, publique um app no Open Exchange – e então, você estará apto a votar. Verifique esta postagem sobre as formas de colaborar com a Comunidade de Desenvolvedores.
Se você mudar de ideia, cancele sua escolha e dê seu voto para outra aplicação – você tem 7 dias para escolher !
Participantes do concurso podem corrigir bugs e desenvolver melhorias nas suas aplicações durente a semana de votação então, não perca a oportunidade !
➡️ Não se esqueçam de verificar as novas regras de votação para o concurso online InterSystems aqui.
Anúncio
Danusa Calixto · Ago. 19, 2022
Olá, membros da comunidade!
Estamos muito orgulhosos de anunciar que nossa comunidade de desenvolvedores InterSystems atingiu alguns marcos ENORMES:
📝 10,000 postagens publicadas
👥 11,000 membros registrados
👁 5,000,000 visualizações (it's five million!)
Gostaríamos de parabenizar você, nossos queridos membros e nós (administradores, gerentes de conteúdo e moderadores) por atingirmos 11 mil membros, 10 mil postagens e 5 milhões 🍋🍋🍋🍋🍋 de visualizações! Estamos muito orgulhosos de fazer parte desse sucesso, que foi criado exclusivamente por e graças a você!
Gostaríamos de agradecer a cada um de vocês por fazer parte do nosso grupo de pessoas que pensam da mesma forma! Obrigado por fazer perguntas e iniciar conversas! Por compartilhar seu conhecimento e seus sucessos! Por nos dar sugestões e nos fazer pensar e assim nos tornarmos melhores e mais úteis para você! Você está mantendo esta comunidade viva e próspera! Estamos muito felizes em tê-lo conosco! ❤️
E por fazer desta ocasião mais festiva...
O canal da Comunidade de Desenvolvedores do Discord alcançou 500 membros! 🎉
The Developer Community Discord channel reached 500 members! 🎉 Ainda temos muito trabalho pela frente nessa direção, mas estamos à altura do desafio. E esperamos que você também se junte a nós para obter informações e ideias ainda mais úteis. Junte-se aqui! >>
Obrigada novamente ! E vamos crescer juntos!
Artigo
Evgeny Shvarov · Out. 6, 2020
Olá, desenvolvedores!
Muitos de vocês publicam suas bibliotecas InterSystems ObjectScript no [Open Exchange](https://openexchange.intersystems.com/) e GitHub.
Mas o que você faz para facilitar o uso e a colaboração do seu projeto por desenvolvedores?
Neste artigo, quero apresentar uma maneira fácil de iniciar e contribuir com qualquer projeto ObjectScript apenas copiando um conjunto padrão de arquivos para o seu repositório.
Vamos lá!
Copie esses arquivos [deste repositório](https://github.com/intersystems-community/objectscript-docker-template) para o seu repositório:
[Dockerfile](https://github.com/intersystems-community/objectscript-docker-template/blob/master/Dockerfile)
[docker-compose.yml](https://github.com/intersystems-community/objectscript-docker-template/blob/master/docker-compose.yml)
[Installer.cls](https://github.com/intersystems-community/objectscript-docker-template/blob/master/Installer.cls)
[iris.script](https://github.com/intersystems-community/objectscript-docker-template/blob/master/iris.script)
[settings.json](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.vscode/settings.json "settings.json"){#9f423fcac90bf80939d78b509e9c2dd2-d165a4a3719c56158cd42a4899e791c99338ce73}
[.dockerignore](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.dockerignore ".dockerignore"){#f7c5b4068637e2def526f9bbc7200c4e-c292b730421792d809e51f096c25eb859f53b637}
[.gitattributes](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.gitattributes ".gitattributes"){#fc723d30b02a4cca7a534518111c1a66-051218936162e5338d54836895e0b651e57973e1}
[.gitignore](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.gitignore ".gitignore"){#a084b794bc0759e7a6b77810e01874f2-e6aff5167df2097c253736b40468e7b21e577eeb}
E você agora possui uma maneira padrão de lançar e colaborar com seu projeto. Abaixo está o longo artigo sobre como e por que isso funciona.
**OBS.:** Neste artigo, consideraremos projetos que podem ser executados no InterSystems IRIS 2019.1 e versões mais recentes.
**Escolhendo o ambiente de lançamento para projetos do InterSystems IRIS**
Normalmente, queremos que um desenvolvedor teste o projeto/biblioteca e tenha certeza de que será um exercício rápido e seguro.
Na minha humilde opinião, a abordagem ideal para lançar qualquer coisa nova de forma rápida e segura é através da utilização do contêiner Docker, que dá ao desenvolvedor uma garantia de que tudo o que ele/ela inicia, importa, compila e calcula é seguro para a máquina host e de que nenhum sistema ou código será destruído ou deteriorado. Se algo der errado, basta parar e remover o contêiner. Se a aplicação ocupa uma quantidade enorme de espaço em disco, você a limpa com o contêiner e seu espaço estará de volta. Se uma aplicação deteriora a configuração do banco de dados, você exclui apenas o contêiner com configuração deteriorada. É assim, simples e seguro.
O contêiner Docker oferece segurança e padronização.
A maneira mais simples de executar o contêiner Docker do InterSystems IRIS é executar uma [imagem do IRIS Community Edition](https://hub.docker.com/_/intersystems-iris-data-platform/plans/222f869e-567c-4928-b572-eb6a29706fbd?tab=instructions):
1. Instale o [Docker desktop](https://www.docker.com/products/docker-desktop)
2. Execute no terminal do sistema operacional o seguinte:
docker run --rm -p 52773:52773 --init --name my-iris store/intersystems/iris-community:2020.1.0.199.0
3. Em seguida, abra o Portal de Administração do IRIS em seu navegador host em:
4. Ou abra uma sessão no terminal:
docker exec -it my-iris iris session IRIS
5. Pare o contêiner IRIS quando não precisar mais dele:
docker stop my-iris
OK! Executamos o IRIS em um contêiner docker. Mas você deseja que um desenvolvedor instale seu código no IRIS e talvez faça algumas configurações. Isso é o que discutiremos a seguir.
**Importando arquivos ObjectScript**
O projeto InterSystems ObjectScript mais simples pode conter um conjunto de arquivos ObjectScript como classes, rotinas, macro e globais. Verifique o artigo sobre nomenclatura e estrutura de pastas proposta.
A questão é: como importar todo esse código para um contêiner IRIS?
Aqui é o momento em que o Dockerfile nos ajuda pois podemos usá-lo para pegar o contêiner IRIS padrão, importar todo o código de um repositório para o IRIS e fazer algumas configurações com o IRIS, se necessário. Precisamos adicionar um Dockerfile no repositório.
Vamos examinar o [Dockerfile](https://github.com/intersystems-community/objectscript-docker-template/blob/master/Dockerfile) do repositório de [modelos ObjectScript](https://github.com/intersystems-community/objectscript-docker-template):
ARG IMAGE=store/intersystems/irishealth:2019.3.0.308.0-community
ARG IMAGE=store/intersystems/iris-community:2019.3.0.309.0
ARG IMAGE=store/intersystems/iris-community:2019.4.0.379.0
ARG IMAGE=store/intersystems/iris-community:2020.1.0.199.0
FROM $IMAGE
USER root
WORKDIR /opt/irisapp
RUN chown ${ISC_PACKAGE_MGRUSER}:${ISC_PACKAGE_IRISGROUP} /opt/irisapp
USER irisowner
COPY Installer.cls .
COPY src src
COPY iris.script /tmp/iris.script # run iris and initial
RUN iris start IRIS \
&& iris session IRIS < /tmp/iris.script
As primeiras linhas ARG definem a variável $IMAGE - que usaremos então em FROM. Isso é adequado para testar/executar o código em diferentes versões do IRIS, trocando-os apenas pelo que é a última linha antes do FROM para alterar a variável $IMAGE.
Aqui temos:
ARG IMAGE=store/intersystems/iris-community:2020.1.0.199.0
FROM $IMAGE
Isso significa que estamos pegando o IRIS 2020 Community Edition versão 199.
Queremos importar o código do repositório - isso significa que precisamos copiar os arquivos de um repositório para um contêiner do docker. As linhas abaixo ajudam a fazer isso:
USER root
WORKDIR /opt/irisapp
RUN chown ${ISC_PACKAGE_MGRUSER}:${ISC_PACKAGE_IRISGROUP} /opt/irisapp
USER irisowner
COPY Installer.cls .
COPY src src
USER root - aqui, mudamos o usuário para root para criar uma pasta e copiar arquivos no docker.
WORKDIR /opt/irisapp - nesta linha configuramos o diretório de trabalho no qual copiaremos os arquivos.
RUN chown ${ISC_PACKAGE_MGRUSER}:${ISC_PACKAGE_IRISGROUP} /opt/irisapp - aqui, damos os direitos ao usuário e grupo irisowner que executam o IRIS.
USER irisowner - trocando usuário de root para irisowner
COPY Installer.cls . - copiando o [Installer.cls](https://github.com/intersystems-community/objectscript-docker-template/blob/master/Installer.cls) para a raiz do workdir. Não esqueça aqui do ponto.
COPY src src - copia os arquivos de origem da [pasta src no repo](https://github.com/intersystems-community/objectscript-docker-template/tree/master/src/) para a pasta src no workdir no docker.
No próximo bloco, executamos o script inicial, onde chamamos o instalador e o código ObjectScript:
COPY iris.script /tmp/iris.script # executar o iris e iniciar
RUN iris start IRIS \
&& iris session IRIS < /tmp/iris.script
COPY iris.script / - copiamos iris.script para o diretório raiz. Ele contém o ObjectScript que desejamos chamar para configurar o contêiner.
RUN iris start IRIS\ - inicia o IRIS
&& iris session IRIS < /tmp/iris.script - inicia o terminal IRIS e insere o ObjectScript inicial nele.
Ótimo! Temos o Dockerfile, que importa arquivos no docker. Mas nos deparamos com outros dois arquivos: installer.cls e iris.script. Vamos examiná-los.
[**Installer.cls**](https://github.com/intersystems-community/objectscript-docker-template/blob/master/Installer.cls)
Class App.Installer
{
XData setup
{
}
ClassMethod setup(ByRef pVars, pLogLevel As %Integer = 3, pInstaller As %Installer.Installer, pLogger As %Installer.AbstractLogger) As %Status [ CodeMode = objectgenerator, Internal ]
{
#; Deixe o documento XGL gerar código para este método.
Quit ##class(%Installer.Manifest).%Generate(%compiledclass, %code, "setup")
}
}
Francamente, não precisamos do Installer.cls para importar arquivos. Isso pode ser feito com uma linha. Mas frequentemente, além de importar o código, precisamos configurar a aplicação CSP, introduzir configurações de segurança, criar bancos de dados e namespaces.
Neste Installer.cls, criamos um novo banco de dados, namespace com o nome IRISAPP e criamos a aplicação /csp/irisapp padrão para este namespace.
Tudo isso realizamos no elemento :
<Namespace Name="${Namespace}" Code="${Namespace}" Data="${Namespace}" Create="yes" Ensemble="no">
<Configuration>
<Database Name="${Namespace}" Dir="/opt/${app}/data" Create="yes" Resource="%DB_${Namespace}"/>
<Import File="${SourceDir}" Flags="ck" Recurse="1"/>
</Configuration>
<CSPApplication Url="/csp/${app}" Directory="${cspdir}${app}" ServeFiles="1" Recurse="1" MatchRoles=":%DB_${Namespace}" AuthenticationMethods="32"
/>
</Namespace>
E importamos todos os arquivos do SourceDir com a tag Import:
<Import File="${SourceDir}" Flags="ck" Recurse="1"/>
SourceDir aqui é uma variável, que é definida para o diretório/pasta src atual:
<Default Name="SourceDir" Value="#{$system.Process.CurrentDirectory()}src"/>
Uma classe Installer.cls com essas configurações nos dá a confiança de que criamos um novo banco de dados IRISAPP limpo, no qual importamos código ObjectScript arbitrário da pasta src.
[iris.script](https://github.com/intersystems-community/objectscript-docker-template/blob/master/iris.script)
Aqui, você é bem-vindo para fornecer qualquer código de configuração ObjectScript inicial que deseja para iniciar seu contêiner IRIS.
Ex. Aqui carregamos e executamos o installer.cls e então criamos o UserPasswords sem expiração, apenas para evitar a primeira solicitação de alteração da senha, pois não precisamos desse prompt para o desenvolvimento.
; run installer to create namespace
do $SYSTEM.OBJ.Load("/opt/irisapp/Installer.cls", "ck")
set sc = ##class(App.Installer).setup() zn "%SYS"
Do ##class(Security.Users).UnExpireUserPasswords("*") ; call your initial methods here
halt
[docker-compose.yml](https://github.com/intersystems-community/objectscript-docker-template/blob/master/docker-compose.yml)
Por que precisamos de docker-compose.yml ? Não poderíamos simplesmente construir e executar a imagem apenas com Dockerfile? Sim, poderíamos. Mas docker-compose.yml simplifica a vida.
Normalmente, docker-compose.yml é usado para iniciar várias imagens docker conectadas a uma rede.
docker-compose.yml também pode ser usado para tornar a inicialização de uma imagem docker mais fácil quando lidamos com muitos parâmetros. Você pode usá-lo para passar parâmetros para o docker, como mapeamento de portas, volumes, parâmetros de conexão VSCode.
version: '3.6'
services:
iris:
build:
context: .
dockerfile: Dockerfile
restart: always
ports:
- 51773
- 52773
- 53773
volumes:
- ~/iris.key:/usr/irissys/mgr/iris.key
- ./:/irisdev/app
Aqui, declaramos o serviço iris, que usa o arquivo docker Dockerfile e expõe as seguintes portas do IRIS: 51773, 52773, 53773. Além disso, este serviço mapeia dois volumes: iris.key do diretório inicial da máquina host para a pasta IRIS onde é esperado, e ele mapeia a pasta raiz do código-fonte para a pasta /irisdev/app.
Docker-compose nos oferece o comando mais curto e unificado para construir e executar a imagem, quaisquer que sejam os parâmetros que você configurar no docker compose.
em qualquer caso, o comando para construir e lançar a imagem é:
$ docker-compose up -d
e para abrir o terminal IRIS:
$ docker-compose exec iris iris session iris
Node: 05a09e256d6b, Instance: IRIS
USER>
Além disso, docker-compose.yml ajuda a configurar a conexão para o plugin VSCode ObjectScript.
[.vscode/settings.json](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.vscode/settings.json)
A parte relacionada às configurações de conexão da extensão ObjectScript é esta:
{
"objectscript.conn" :{
"ns": "IRISAPP",
"active": true,
"docker-compose": {
"service": "iris",
"internalPort": 52773
}
}
}
Aqui vemos as configurações, que são diferentes das configurações padrão do plugin VSCode ObjectScript.
Aqui, dizemos que queremos nos conectar ao namespace IRISAPP (que criamos com Installer.cls):
"ns": "IRISAPP",
e há uma configuração docker-compose, que informa que, no arquivo docker-compose dentro do serviço "iris", o VSCode se conectará à porta, para a qual 52773 está mapeado:
"docker-compose": {
"service": "iris",
"internalPort": 52773
}
Se verificarmos o que temos para 52773, veremos que esta é a porta mapeada não definida para 52773:
ports:
- 51773
- 52773
- 53773
Isso significa que uma porta aleatória disponível em uma máquina host será obtida e o VSCode se conectará a este IRIS no docker via porta aleatória automaticamente.
**Este é um recurso muito útil, pois oferece a opção de executar qualquer quantidade de imagens do docker com IRIS em portas aleatórias e ter VSCode conectado a elas automaticamente.**
E quanto a outros arquivos?
Nos também temos:
[.dockerignore](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.dockerignore) - arquivo que você pode usar para filtrar os arquivos da máquina host que você não deseja que sejam copiados para a imagem docker que você construir. Normalmente .git e .DS_Store são linhas obrigatórias.
[.gitattributes](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.gitattributes) - atributos para git, que unificam terminações de linha para arquivos ObjectScript em fontes. Isso é muito útil se o repositório for colaborado por proprietários de Windows e Mac/Ubuntu.
[.gitignore](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.gitignore) - arquivos, os quais você não deseja que o git rastreie o histórico de alterações. Normalmente, alguns arquivos ocultos no nível do sistema operacional, como .DS_Store.
Ótimo!
Como tornar seu repositório executável em docker e amigável para colaboração?
1. Clone [este repositório](https://github.com/intersystems-community/objectscript-docker-template).
2. Copie todos esses arquivos:
[Dockerfile](https://github.com/intersystems-community/objectscript-docker-template/blob/master/Dockerfile)
[docker-compose.yml](https://github.com/intersystems-community/objectscript-docker-template/blob/master/docker-compose.yml)
[Installer.cls](https://github.com/intersystems-community/objectscript-docker-template/blob/master/Installer.cls)
[iris.script](https://github.com/intersystems-community/objectscript-docker-template/blob/master/iris.script)
[settings.json](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.vscode/settings.json "settings.json"){#9f423fcac90bf80939d78b509e9c2dd2-d165a4a3719c56158cd42a4899e791c99338ce73}
[.dockerignore](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.dockerignore ".dockerignore"){#f7c5b4068637e2def526f9bbc7200c4e-c292b730421792d809e51f096c25eb859f53b637}
[.gitattributes](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.gitattributes ".gitattributes"){#fc723d30b02a4cca7a534518111c1a66-051218936162e5338d54836895e0b651e57973e1}
[.gitignore](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.gitignore ".gitignore"){#a084b794bc0759e7a6b77810e01874f2-e6aff5167df2097c253736b40468e7b21e577eeb}
para o seu repositório.
Altere [esta linha no Dockerfile](https://github.com/intersystems-community/objectscript-docker-template/blob/10f4422c105d5c75111fde16a184a83f5ff86d06/Dockerfile#L15) para corresponder ao diretório com ObjectScript no repositório que você deseja importar para o IRIS (ou não altere se estiver na pasta /src).
É isso. E todos (e você também) terão seu código importado para o IRIS em um novo namespace IRISAPP.
**Como as pessoas irão iniciar o seu projeto**
o algoritmo para executar qualquer projeto ObjectScript no IRIS pode ser:
1. Clone o projeto Git localmente
2. Execute o projeto:
$ docker-compose up -d
$ docker-compose exec iris iris session iris
Node: 05a09e256d6b, Instance: IRIS
USER>zn "IRISAPP"
**Como qualquer desenvolvedor pode contribuir para o seu projeto **
1. Bifurque o repositório e clone o repositório git bifurcado localmente
2. Abra a pasta no VSCode (eles também precisam que as extensões [Docker](https://marketplace.visualstudio.com/items?itemName=ms-azuretools.vscode-docker) e [ObjectScript](https://marketplace.visualstudio.com/items?itemName=daimor.vscode-objectscript&ssr=false#review-details) estejam instaladas no VSCode)
3. Clique com o botão direito em docker-compose.yml->Reiniciar - [VSCode ObjectScript](https://openexchange.intersystems.com/package/VSCode-ObjectScript) irá conectar-se automaticamente e estará pronto para editar/compilar/depurar
4. Commit, Push e Pull as mudanças solicitadas em seu repositório
Aqui está um pequeno gif sobre como isso funciona:

É isso! Viva a programação!
Artigo
Mikhail Khomenko · Nov. 23, 2020
Imagine que você queira ver o que a tecnologia InterSystems pode oferecer em termos de análise de dados. Você estudou a teoria e agora quer um pouco de prática. Felizmente, a InterSystems oferece um projeto que contém alguns bons exemplos: Samples BI. Comece com o arquivo README, pulando qualquer coisa associada ao Docker, e vá direto para a instalação passo a passo. Inicie uma instância virtual, instale o IRIS lá, siga as instruções para instalar o Samples BI e, a seguir, impressione o chefe com belos gráficos e tabelas. Por enquanto, tudo bem.
Inevitavelmente, porém, você precisará fazer alterações.
Acontece que manter uma máquina virtual sozinha tem algumas desvantagens e é melhor mantê-la com um provedor em nuvem. A Amazon parece sólida e você cria uma conta no AWS (gratuita para iniciar), lê que usar a identidade do usuário root para tarefas diárias é ruim e cria um usuário IAM normal com permissões de administrador.
Clicando um pouco, você cria sua própria rede VPC, sub-redes e uma instância virtual EC2, e também adiciona um grupo de segurança para abrir a porta web IRIS (52773) e a porta ssh (22) para você. Repete a instalação do IRIS e Samples BI. Desta vez, usa o script Bash ou Python, se preferir. Mais uma vez, impressiona o chefe.
Mas o movimento DevOps onipresente leva você a começar a ler sobre infraestrutura como código e você deseja implementá-la. Você escolhe o Terraform, já que ele é bem conhecido de todos e sua abordagem é bastante universal - adequada com pequenos ajustes para vários provedores em nuvem. Você descreve a infraestrutura em linguagem HCL e traduz as etapas de instalação do IRIS e Samples BI para o Ansible. Em seguida, você cria mais um usuário IAM para permitir que o Terraform funcione. Executa tudo. Ganha um bônus no trabalho.
Gradualmente, você chega à conclusão de que, em nossa era de [microsserviços](https://martinfowler.com/articles/microservices.html), é uma pena não usar o Docker, especialmente porque a InterSystems lhe diz [como](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=ADOCK_iris). Você retorna ao guia de instalação do Samples BI e lê as linhas sobre o Docker, que não parecem complicadas:
$ docker pull intersystemsdc/iris-community:2019.4.0.383.0-zpm$ docker run --name irisce -d --publish 52773:52773 intersystemsdc/iris-community:2019.4.0.383.0-zpm$ docker exec -it irisce iris session irisUSER>zpmzpm: USER>install samples-bi
Depois de direcionar seu navegador para ttp://localhost:52773/csp/user/_DeepSee.UserPortal.Home.zen?$NAMESPACE=USER, você vai novamente ao chefe e tira um dia de folga por um bom trabalho.
Você então começa a entender que “docker run” é apenas o começo e você precisa usar pelo menos docker-compose. Não é um problema:
$ cat docker-compose.ymlversion: "3.7"services: irisce: container_name: irisce image: intersystemsdc/iris-community:2019.4.0.383.0-zpm ports: - 52773:52773$ docker rm -f irisce # We don’t need the previous container$ docker-compose up -d
Então, você instala o Docker e o docker-compose com o Ansible e, em seguida, apenas executa o contêiner, que fará o download de uma imagem se ainda não estiver presente na máquina. Em seguida, você instala Samples BI.
Você certamente gosta do Docker, porque é uma interface simples e legal para várias coisas do kernel. Você começa a usar o Docker em outro lugar e geralmente inicia mais de um contêiner. E descobre que muitas vezes os contêineres devem se comunicar entre si, o que leva à leitura sobre como gerenciar vários contêineres.
E você chega ao Kubernetes.
Uma opção para mudar rapidamente de docker-compose para Kubernetes é usar o [kompose](https://kompose.io/). Pessoalmente, prefiro simplesmente copiar os manifestos do Kubernetes dos manuais e, em seguida, editá-los, mas o kompose faz um bom trabalho ao concluir sua pequena tarefa:
$ kompose convert -f docker-compose.ymlINFO Kubernetes file "irisce-service.yaml" createdINFO Kubernetes file "irisce-deployment.yaml" created
Agora você tem os arquivos de implantação e serviço que podem ser enviados para algum cluster do Kubernetes. Você descobre que pode instalar um minikube, que permite executar um cluster Kubernetes de nó único e é exatamente o que você precisa neste estágio. Depois de um ou dois dias brincando com a sandbox do minikube, você está pronto para usar uma implantação real e ao vivo do Kubernetes em algum lugar da nuvem AWS.
Preparação
Então, vamos fazer isso juntos. Neste ponto, faremos algumas suposições:
Primeiro, presumimos que você tenha uma conta no AWS, [saiba seu ID](https://docs.aws.amazon.com/IAM/latest/UserGuide/console_account-alias.html) e não use credenciais de root. Você criou um usuário IAM (vamos chamá-lo de “my-user”) com [direitos de administrador](https://docs.aws.amazon.com/IAM/latest/UserGuide/getting-started_create-admin-group.html) e apenas acesso programático e armazenou suas credenciais. Você também criou outro usuário IAM, chamado “terraform”, com as mesmas permissões:

Em seu nome, o Terraform irá para sua conta no AWS e criará e excluirá os recursos necessários. Os amplos direitos de ambos os usuários são explicados pelo fato de que se trata de uma demonstração. Você salva as credenciais localmente para os dois usuários IAM:
$ cat ~/.aws/credentials[terraform]aws_access_key_id = ABCDEFGHIJKLMNOPQRSTaws_secret_access_key = ABCDEFGHIJKLMNOPQRSTUVWXYZ01234567890123[my-user]aws_access_key_id = TSRQPONMLKJIHGFEDCBAaws_secret_access_key = TSRQPONMLKJIHGFEDCBA01234567890123
Observação: não copie e cole as credenciais acima. Eles são fornecidos aqui como um exemplo e não existem mais. Edite o arquivo ~/.aws/credentials e introduza seus próprios registros.
Em segundo lugar, usaremos o ID do conta AWS fictícia (01234567890) para o artigo e a região AWS “eu-west-1.” Sinta-se à vontade para usar outra região.
Terceiro, presumimos que você esteja ciente de que o AWS não é gratuito e que você terá que pagar pelos recursos usados.
Em seguida, você instalou o utilitário AWS CLI para comunicação via linha de comando com o AWS. Você pode tentar usar o aws2, mas precisará definir especificamente o uso do aws2 em seu arquivo de configuração do kube, conforme descrito aqui.
Você também instalou o utilitário kubectl para comunicação via linha de comando com AWS Kubernetes.
E você instalou o utilitário kompose para docker-compose.yml para converter manifestos do Kubernetes.
Finalmente, você criou um repositório GitHub vazio e clonou-o em seu host. Vamos nos referir ao seu diretório raiz como . Neste repositório, vamos criar e preencher três diretórios: .github/workflows/, k8s/, e terraform/.
Observe que todo o código relevante é duplicado no repositório github-eks-samples-bi para simplificar a cópia e a colagem.
Vamos continuar.
Provisionamento AWS EKS
Já conhecemos o EKS no artigo Implementando uma aplicação web simples baseado em IRIS usando o Amazon EKS. Naquela época, criamos um cluster semiautomático. Ou seja, descrevemos o cluster em um arquivo e, em seguida, iniciamos manualmente o utilitário eksctl de uma máquina local, que criou o cluster de acordo com nossa descrição.
O eksctl foi desenvolvido para a criação de clusters EKS e é bom para uma implementação de prova de conceito, mas para o uso diário é melhor usar algo mais universal, como o Terraform. Um ótimo recurso, Introdução ao AWS EKS, explica a configuração do Terraform necessária para criar um cluster EKS. Uma ou duas horas gastas para conhecê-lo não será uma perda de tempo.
Você pode brincar com o Terraform localmente. Para fazer isso, você precisará de um binário (usaremos a versão mais recente para Linux no momento da redação do artigo, 0.12.20) e o usuário IAM “terraform” com direitos suficientes para o Terraform ir para o AWS. Crie o diretório /terraform/ para armazenar o código do Terraform:
$ mkdir /terraform$ cd /terraform
Você pode criar um ou mais arquivos .tf (eles são mesclados na inicialização). Basta copiar e colar os exemplos de código da Introdução ao AWS EKS e, em seguida, executar algo como:
$ export AWS_PROFILE=terraform$ export AWS_REGION=eu-west-1$ terraform init$ terraform plan -out eks.plan
Você pode encontrar alguns erros. Nesse caso, brinque um pouco com o modo de depuração, mas lembre-se de desligá-lo mais tarde:
$ export TF_LOG=debug$ terraform plan -out eks.plan$ unset TF_LOG
Esta experiência será útil, e muito provavelmente você terá um cluster EKS iniciado (use “terraform apply” para isso). Verifique no console do AWS:

Limpe-o quando você ficar entediado:
$ terraform destroy
Em seguida, vá para o próximo nível e comece a usar o módulo Terraform EKS, especialmente porque ele é baseado na mesma introdução ao EKS. No diretório examples/ você verá como usá-lo. Você também encontrará outros exemplos lá.
Simplificamos um pouco os exemplos. Este é o arquivo principal em que os módulos de criação de VPC e de criação de EKS são chamados:
$ cat /terraform/main.tfterraform { required_version = ">= 0.12.0" backend "s3" { bucket = "eks-github-actions-terraform" key = "terraform-dev.tfstate" region = "eu-west-1" dynamodb_table = "eks-github-actions-terraform-lock" }}
provider "kubernetes" { host = data.aws_eks_cluster.cluster.endpoint cluster_ca_certificate = base64decode(data.aws_eks_cluster.cluster.certificate_authority.0.data) token = data.aws_eks_cluster_auth.cluster.token load_config_file = false version = "1.10.0"}
locals { vpc_name = "dev-vpc" vpc_cidr = "10.42.0.0/16" private_subnets = ["10.42.1.0/24", "10.42.2.0/24"] public_subnets = ["10.42.11.0/24", "10.42.12.0/24"] cluster_name = "dev-cluster" cluster_version = "1.14" worker_group_name = "worker-group-1" instance_type = "t2.medium" asg_desired_capacity = 1}
data "aws_eks_cluster" "cluster" { name = module.eks.cluster_id}
data "aws_eks_cluster_auth" "cluster" { name = module.eks.cluster_id}
data "aws_availability_zones" "available" {}
module "vpc" { source = "git::https://github.com/terraform-aws-modules/terraform-aws-vpc?ref=master"
name = local.vpc_name cidr = local.vpc_cidr azs = data.aws_availability_zones.available.names private_subnets = local.private_subnets public_subnets = local.public_subnets enable_nat_gateway = true single_nat_gateway = true enable_dns_hostnames = true
tags = { "kubernetes.io/cluster/${local.cluster_name}" = "shared" }
public_subnet_tags = { "kubernetes.io/cluster/${local.cluster_name}" = "shared" "kubernetes.io/role/elb" = "1" }
private_subnet_tags = { "kubernetes.io/cluster/${local.cluster_name}" = "shared" "kubernetes.io/role/internal-elb" = "1" }}
module "eks" { source = "git::https://github.com/terraform-aws-modules/terraform-aws-eks?ref=master" cluster_name = local.cluster_name cluster_version = local.cluster_version vpc_id = module.vpc.vpc_id subnets = module.vpc.private_subnets write_kubeconfig = false
worker_groups = [ { name = local.worker_group_name instance_type = local.instance_type asg_desired_capacity = local.asg_desired_capacity } ]
map_accounts = var.map_accounts map_roles = var.map_roles map_users = var.map_users}
Vejamos um pouco mais de perto o bloco "_terraform_" em main.tf:
terraform { required_version = ">= 0.12.0" backend "s3" { bucket = "eks-github-actions-terraform" key = "terraform-dev.tfstate" region = "eu-west-1" dynamodb_table = "eks-github-actions-terraform-lock" }}
Aqui, indicamos que seguiremos a sintaxe não inferior ao Terraform 0.12 (muito mudou em comparação com as versões anteriores) e também que Terraform não deve armazenar seu estado localmente, mas sim remotamente, no S3 bucket.
É conveniente se o código do terraform possa ser atualizado de lugares diferentes por pessoas diferentes, o que significa que precisamos ser capazes de bloquear o estado de um usuário, então adicionamos um bloqueio usando uma tabela dynamodb. Leia mais sobre bloqueios na página State Locking (bloqueio de estado).
Como o nome do bucket deve ser único em toda o AWS, o nome “eks-github-actions-terraform” não funcionará para você. Pense por conta própria e certifique-se de que ele ainda não foi usado (se sim, você receberá um erro NoSuchBucket):
$ aws s3 ls s3://my-bucketAn error occurred (AllAccessDisabled) when calling the ListObjectsV2 operation: All access to this object has been disabled$ aws s3 ls s3://my-bucket-with-name-that-impossible-to-rememberAn error occurred (NoSuchBucket) when calling the ListObjectsV2 operation: The specified bucket does not exist
Tendo criado um nome, crie o bucket (usamos o usuário IAM “terraform” aqui. Ele tem direitos de administrador para que possa criar um bucket) e habilite o controle de versão para ele (o que lhe salvará em caso de um erro de configuração):
$ aws s3 mb s3://eks-github-actions-terraform --region eu-west-1make_bucket: eks-github-actions-terraform$ aws s3api put-bucket-versioning --bucket eks-github-actions-terraform --versioning-configuration Status=Enabled$ aws s3api get-bucket-versioning --bucket eks-github-actions-terraform{ "Status": "Enabled"}
Com o DynamoDB, ser único não é necessário, mas você precisa criar uma tabela primeiro:
$ aws dynamodb create-table \ --region eu-west-1 \ --table-name eks-github-actions-terraform-lock \ --attribute-definitions AttributeName=LockID,AttributeType=S \ --key-schema AttributeName=LockID,KeyType=HASH \ --provisioned-throughput ReadCapacityUnits=5,WriteCapacityUnits=5

Lembre-se de que, em caso de falha do Terraform, você pode precisar remover um bloqueio manualmente do console AWS. Mas tenha cuidado ao fazer isso.
Com relação aos blocos do módulo eks/vpc em main.tf, a forma de referenciar o módulo disponível no GitHub é simples:
git::https://github.com/terraform-aws-modules/terraform-aws-vpc?ref=master
Agora vamos dar uma olhada em nossos outros dois arquivos Terraform (variables.tf e outputs.tf). O primeiro contém nossas variáveis Terraform:
$ cat /terraform/variables.tfvariable "region" { default = "eu-west-1"}
variable "map_accounts" { description = "Additional AWS account numbers to add to the aws-auth configmap. See examples/basic/variables.tf for example format." type = list(string) default = []}
variable "map_roles" { description = "Additional IAM roles to add to the aws-auth configmap." type = list(object({ rolearn = string username = string groups = list(string) })) default = []}
variable "map_users" { description = "Additional IAM users to add to the aws-auth configmap." type = list(object({ userarn = string username = string groups = list(string) })) default = [ { userarn = "arn:aws:iam::01234567890:user/my-user" username = "my-user" groups = ["system:masters"] } ]}
A parte mais importante aqui é adicionar o usuário IAM “my-user” à variável map_users, mas você deve usar seu próprio ID de conta aqui no lugar de 01234567890.
O que isto faz? Quando você se comunica com o EKS por meio do cliente kubectl local, ele envia solicitações ao servidor da API Kubernetes, e cada solicitação passa por processos de autenticação e autorização para que o Kubernetes possa entender quem enviou a solicitação e o que elas podem fazer. Portanto, a versão EKS do Kubernetes pede ajuda ao AWS IAM com a autenticação do usuário. Se o usuário que enviou a solicitação estiver listado no AWS IAM (apontamos seu ARN aqui), a solicitação vai para a fase de autorização, que o EKS processa sozinho, mas de acordo com nossas configurações. Aqui, indicamos que o usuário IAM “my-user” é muito legal (grupo “system: masters”).
Por fim, o arquivo outputs.tf descreve o que o Terraform deve imprimir após concluir um job:
$ cat /terraform/outputs.tfoutput "cluster_endpoint" { description = "Endpoint for EKS control plane." value = module.eks.cluster_endpoint}
output "cluster_security_group_id" { description = "Security group ids attached to the cluster control plane." value = module.eks.cluster_security_group_id}
output "config_map_aws_auth" { description = "A kubernetes configuration to authenticate to this EKS cluster." value = module.eks.config_map_aws_auth}
Isso completa a descrição da parte do Terraform. Voltaremos em breve para ver como vamos iniciar esses arquivos.
Manifestos Kubernetes
Até agora, cuidamos de onde iniciar a aplicação. Agora vamos ver o que executar.
Lembre-se de que temos o docker-compose.yml (renomeamos o serviço e adicionamos alguns rótulos que o kompose usará em breve) no diretório /k8s/:
$ cat /k8s/docker-compose.ymlversion: "3.7"services: samples-bi: container_name: samples-bi image: intersystemsdc/iris-community:2019.4.0.383.0-zpm ports: - 52773:52773 labels: kompose.service.type: loadbalancer kompose.image-pull-policy: IfNotPresent
Execute o kompose e adicione o que está destacado abaixo. Exclua as anotações (para tornar as coisas mais inteligíveis):
$ kompose convert -f docker-compose.yml --replicas=1$ cat /k8s/samples-bi-deployment.yamlapiVersion: extensions/v1beta1kind: Deploymentmetadata: labels: io.kompose.service: samples-bi name: samples-bispec: replicas: 1 strategy: type: Recreate template: metadata: labels: io.kompose.service: samples-bi spec: containers: - image: intersystemsdc/iris-community:2019.4.0.383.0-zpm imagePullPolicy: IfNotPresent name: samples-bi ports: - containerPort: 52773 resources: {} lifecycle: postStart: exec: command: - /bin/bash - -c - | echo -e "write\nhalt" > test until iris session iris < test; do sleep 1; done echo -e "zpm\ninstall samples-bi\nquit\nhalt" > samples_bi_install iris session iris < samples_bi_install rm test samples_bi_install restartPolicy: Always
Usamos a estratégia de atualização de Recriar, o que significa que o pod será excluído primeiro e depois recriado. Isso é permitido para fins de demonstração e nos permite usar menos recursos.
Também adicionamos o postStart hook, que será disparado imediatamente após o início do pod. Esperamos até o IRIS iniciar e instalar o pacote samples-bi do repositório zpm padrão.
Agora adicionamos o serviço Kubernetes (também sem anotações):
$ cat /k8s/samples-bi-service.yamlapiVersion: v1kind: Servicemetadata: labels: io.kompose.service: samples-bi name: samples-bispec: ports: - name: "52773" port: 52773 targetPort: 52773 selector: io.kompose.service: samples-bi type: LoadBalancer
Sim, vamos implantar no namespace "padrão", que funcionará para a demonstração.
Ok, agora sabemos _onde_ e _o que_ queremos executar. Resta ver _como_.
O fluxo de trabalho do GitHub Actions
Em vez de fazer tudo do zero, criaremos um fluxo de trabalho semelhante ao descrito em [Implantando uma solução InterSystems IRIS no GKE usando GitHub Actions](https://community.intersystems.com/post/deploying-intersystems-iris-solution-gke-using-github-actions). Desta vez, não precisamos nos preocupar em construir um contêiner. As partes específicas do GKE são substituídas pelas específicas do EKS. As partes em negrito estão relacionadas ao recebimento da mensagem de commit e ao uso dela em etapas condicionais:
$ cat /.github/workflows/workflow.yamlname: Provision EKS cluster and deploy Samples BI thereon: push: branches: - master
# Environment variables.# ${{ secrets }} are taken from GitHub -> Settings -> Secrets# ${{ github.sha }} is the commit hashenv: AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }} AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }} AWS_REGION: ${{ secrets.AWS_REGION }} CLUSTER_NAME: dev-cluster DEPLOYMENT_NAME: samples-bi
jobs: eks-provisioner: # Inspired by: ## https://www.terraform.io/docs/github-actions/getting-started.html ## https://github.com/hashicorp/terraform-github-actions name: Provision EKS cluster runs-on: ubuntu-18.04 steps: - name: Checkout uses: actions/checkout@v2
- name: Get commit message run: | echo ::set-env name=commit_msg::$(git log --format=%B -n 1 ${{ github.event.after }})
- name: Show commit message run: echo $commit_msg
- name: Terraform init uses: hashicorp/terraform-github-actions@master with: tf_actions_version: 0.12.20 tf_actions_subcommand: 'init' tf_actions_working_dir: 'terraform'
- name: Terraform validate uses: hashicorp/terraform-github-actions@master with: tf_actions_version: 0.12.20 tf_actions_subcommand: 'validate' tf_actions_working_dir: 'terraform'
- name: Terraform plan if: "!contains(env.commit_msg, '[destroy eks]')" uses: hashicorp/terraform-github-actions@master with: tf_actions_version: 0.12.20 tf_actions_subcommand: 'plan' tf_actions_working_dir: 'terraform'
- name: Terraform plan for destroy if: "contains(env.commit_msg, '[destroy eks]')" uses: hashicorp/terraform-github-actions@master with: tf_actions_version: 0.12.20 tf_actions_subcommand: 'plan' args: '-destroy -out=./destroy-plan' tf_actions_working_dir: 'terraform'
- name: Terraform apply if: "!contains(env.commit_msg, '[destroy eks]')" uses: hashicorp/terraform-github-actions@master with: tf_actions_version: 0.12.20 tf_actions_subcommand: 'apply' tf_actions_working_dir: 'terraform'
- name: Terraform apply for destroy if: "contains(env.commit_msg, '[destroy eks]')" uses: hashicorp/terraform-github-actions@master with: tf_actions_version: 0.12.20 tf_actions_subcommand: 'apply' args: './destroy-plan' tf_actions_working_dir: 'terraform'
kubernetes-deploy: name: Deploy Kubernetes manifests to EKS needs: - eks-provisioner runs-on: ubuntu-18.04 steps: - name: Checkout uses: actions/checkout@v2
- name: Get commit message run: | echo ::set-env name=commit_msg::$(git log --format=%B -n 1 ${{ github.event.after }})
- name: Show commit message run: echo $commit_msg
- name: Configure AWS Credentials if: "!contains(env.commit_msg, '[destroy eks]')" uses: aws-actions/configure-aws-credentials@v1 with: aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }} aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }} aws-region: ${{ secrets.AWS_REGION }}
- name: Apply Kubernetes manifests if: "!contains(env.commit_msg, '[destroy eks]')" working-directory: ./k8s/ run: | aws eks update-kubeconfig --name ${CLUSTER_NAME} kubectl apply -f samples-bi-service.yaml kubectl apply -f samples-bi-deployment.yaml kubectl rollout status deployment/${DEPLOYMENT_NAME}
É claro que, precisamos definir as credenciais do usuário "terraform" (retirá-las do arquivo ~/.aws/credentials), permitindo que o GitHub use seus segredos:

Observe as partes destacadas do fluxo de trabalho. Elas nos permitirão destruir um cluster EKS empurrando uma mensagem de commit que contém a frase “[destroy eks]”. Observe que não executaremos "kubernetes apply" com essa mensagem de commit.
Execute um pipeline, mas primeiro crie um arquivo .gitignore:
$ cat /.gitignore.DS_Storeterraform/.terraform/terraform/*.planterraform/*.json$ cd $ git add .github/ k8s/ terraform/ .gitignore$ git commit -m "GitHub on EKS"$ git push
Monitore o processo de implantação na aba "Actions" da página do repositório GitHub. Aguarde a conclusão com sucesso.
Quando você executa um fluxo de trabalho pela primeira vez, leva cerca de 15 minutos na etapa “Terraform apply”, aproximadamente o mesmo tempo necessário para criar o cluster. Na próxima inicialização (se você não excluiu o cluster), o fluxo de trabalho será muito mais rápido. Você pode verificar isso:
$ cd $ git commit -m "Trigger" --allow-empty$ git push
É claro que seria bom verificar o que fizemos. Desta vez, você pode usar as credenciais do IAM “my-user” em seu computador:
$ export AWS_PROFILE=my-user$ export AWS_REGION=eu-west-1$ aws sts get-caller-identity$ aws eks update-kubeconfig --region=eu-west-1 --name=dev-cluster --alias=dev-cluster$ kubectl config current-contextdev-cluster
$ kubectl get nodesNAME STATUS ROLES AGE VERSIONip-10-42-1-125.eu-west-1.compute.internal Ready 6m20s v1.14.8-eks-b8860f
$ kubectl get poNAME READY STATUS RESTARTS AGEsamples-bi-756dddffdb-zd9nw 1/1 Running 0 6m16s
$ kubectl get svcNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEkubernetes ClusterIP 172.20.0.1 443/TCP 11msamples-bi LoadBalancer 172.20.33.235 a2c6f6733557511eab3c302618b2fae2-622862917.eu-west-1.elb.amazonaws.com 52773:31047/TCP 6m33s
Vá para _[http://a2c6f6733557511eab3c302618b2fae2-622862917.eu-west-1.elb.amazonaws.com:52773/csp/user/_DeepSee.UserPortal.Home.zen?$NAMESPACE=USER](http://a2c6f6733557511eab3c302618b2fae2-622862917.eu-west-1.elb.amazonaws.com:52773/csp/user/_DeepSee.UserPortal.Home.zen?%24NAMESPACE=USER) _(substitua o link pelo seu IP externo), então, digite “_system”, “SYS” e altere a senha padrão. Você deve ver vários painéis de Inteligência Empresarial (BI):

Clique na seta de cada um para um mergulho mais profundo:

Lembre-se, se você reiniciar um pod samples-bi, todas as suas alterações serão perdidas. Este é um comportamento intencional, pois esta é uma demonstração. Se você precisar de persistência, criei um exemplo no repositório github-gke-zpm-registry/k8s/statefulset.tpl.
Quando terminar, basta remover tudo que você criou:
$ git commit -m "Mr Proper [destroy eks]" --allow-empty$ git push
Conclusão
Neste artigo, substituímos o utilitário eksctl pelo Terraform para criar um cluster EKS. É um passo à frente para “codificar” toda a sua infraestrutura AWS.
Mostramos como você pode facilmente implantar uma aplicação de demonstração com git push usando GitHub Actions e Terraform.
Também adicionamos o kompose e um postStart hook de um pod à nossa caixa de ferramentas.
Não mostramos a ativação do TLS neste momento. Essa é uma tarefa que realizaremos em um futuro próximo.
Artigo
Mark Bolinsky · Dez. 14, 2020
O Google Cloud Platform (GCP) fornece um ambiente rico em recursos para Infraestrutura como um Serviço (IaaS) como uma oferta em nuvem totalmente capaz de oferecer suporte a todos os produtos da InterSystems, incluindo a mais recente plataforma de dados InterSystems IRIS . Deve-se ter cuidado, como com qualquer plataforma ou modelo de implantação, para garantir que todos os aspectos de um ambiente sejam considerados, como desempenho, disponibilidade, operações e procedimentos de gerenciamento. As especificidades de cada uma dessas áreas serão abordadas neste artigo.
A visão geral e os detalhes abaixo são fornecidos pelo Google e estão disponíveis aqui.
Visão geral
### Recursos do GCP
O GCP é composto por um conjunto de ativos físicos, como computadores e unidades de disco rígido, e também recursos virtuais, como máquinas virtuais (VMs), nos centros de dados do Google em todo o mundo. Cada centro de dados está em uma região do mundo. Cada região é uma coleção de zonas, isoladas de cada uma dentro da região. Cada zona é identificada por um nome que combina uma letra identificadora com o nome da região.
Essa distribuição de recursos tem várias vantagens, incluindo redundância em caso de falha e latência reduzida colocando recursos mais perto dos clientes. Essa distribuição também tem algumas regras quanto a como os recursos podem ser usados conjuntamente.
### Acesso aos recursos do GCP
Na computação em nuvem, o hardware físico e o software se tornam serviços. Esses serviços oferecem acesso aos recursos adjacentes. Ao implantar sua aplicação baseada em InterSytems IRIS no GCP, você combina esses serviços para obter a infraestrutura necessária e depois adiciona seu código para possibilitar a concretização dos cenários que deseja criar. Os detalhes dos recursos disponíveis estão disponíveis aqui.
### Projetos
Todos os recursos do GCP que você aloca e usa devem pertencer a um projeto. Um projeto é composto por configurações, permissões e outros metadados que descrevem suas aplicações. Os recursos em um único projeto podem funcionar juntos facilmente, por exemplo, comunicando-se por uma rede interna, sujeita a regras das regiões e zonas. Os recursos que cada projeto contêm permanecem separados por fronteiras de projetos. Você só pode interconectá-los por uma conexão de rede externa.
Interação com os serviços
O GCP oferece três formas básicas de interagir com os serviços e recursos.
#### Console
O Google Cloud Platform Console possui uma interface gráfica web do usuário que você pode usar para gerenciar os projetos e recursos do GCP. No GCP Console, você pode criar um novo projeto ou escolher um existente, e usar os recursos criados no contexto desse projeto. É possível criar diversos projetos, então você pode usá-los para segregar o trabalho da melhor maneira de acordo com suas necessidades. Por exemplo, você pode iniciar um novo projeto se quiser garantir que somente determinados membros da equipe consigam acessar recursos nesse projeto, enquanto todos os membros da equipe podem continuar acessando os recursos em outro projeto.
Interface de linha de comandos
Se você preferir trabalhar em uma janela de terminal, o Google Cloud SDK oferece a ferramenta de linha de comandos gcloud, que permite acesso aos comandos de que você precisa. A ferramenta gcloud pode ser usada para gerenciar o fluxo de trabalho de desenvolvimento e os recursos do GCP. Os detalhes de referências sobre o gcloud estão disponíveis aqui.
O GCP também oferece o Cloud Shell, um ambiente de shell interativo no navegador para o GCP. Você pode acessar o Cloud Shell pelo GCP Console. O Cloud Shell oferece:
Uma instância temporária de máquina virtual de mecanismo de computação.
Acesso de linha de comando à instância por um navegador.
Um editor de código integrado.
5 GB de armazenamento em disco persistente.
Google Cloud SDK e outras ferramentas pré-instalados.
Suporte às linguagens Java, Go, Python, Node.js, PHP, Ruby e .NET.
Funcionalidade de visualização da web.
Autorização integrada para acesso aos projetos e recursos no GCP Console.
Bibliotecas de cliente
O Cloud SDK inclui bibliotecas de cliente que permitem criar e gerenciar recursos com facilidade. As bibliotecas de cliente expõem APIs para dois propósitos principais:
As APIs de aplicações concedem acesso aos serviços. As APIs de aplicações são otimizadas para as linguagens compatíveis, como Node.js e Python. As bibliotecas foram desenvolvidas com metáforas de serviço, então você pode usar os serviços de modo mais natural e escrever menos código boilerplate. As bibliotecas também oferecem elementos auxiliares para autenticação e autorização. Os detalhes estão disponíveis aqui.
As APIs de administração oferecem funcionalidades de gerenciamento de recursos. Por exemplo, você pode usar as APIs de administração se quiser criar suas próprias ferramentas automatizadas.
Também é possível usar as bibliotecas de cliente da API do Google para acessar APIs de produtos, como Google Maps, Google Drive e YouTube. Os detalhes das bibliotecas de cliente do GCP estão disponíveis aqui.
Exemplos de arquitetura da InterSystems IRIS
Neste artigo, são fornecidos exemplos de implantações da InterSystems IRIS para GCP como ponto de partida para a implantação específica de sua aplicação. Eles podem ser usados como diretrizes para diversas possibilidades de implantação. Esta arquitetura de referência demonstra opções de implantação muito robustas, começando com implantações de pequeno porte até cargas de trabalho extremamente escaláveis para os requisitos de computação e dados.
Também são abordadas neste documento opções de alta disponibilidade e recuperação de desastres, junto com outras operações de sistema recomendadas. Espera-se que elas sejam modificadas pelos técnicos para se adequarem às práticas e políticas de segurança padrão da organização.
A InterSystems está disponível para conversar ou responder a perguntas sobre as implantações da InterSystems IRIS com GCP para sua aplicação específica.
* * *
Exemplos de arquitetura de referência
Os seguintes exemplos de arquitetura apresentam diversas configurações diferentes, com capacidade e funcionalidades cada vez maiores. Considere estes exemplos de implantação de pequeno porte / produção / produção de grande porte / produção com cluster fragmentado que mostram a progressão desde uma configuração pequena modesta para desenvolvimento até soluções extremamente escaláveis com alta disponibilidade entre zonas e recuperação de desastres multirregião. Além disso, é fornecido um exemplo de arquitetura usando as novas funcionalidades de fragmentação da InterSystems IRIS Data Plataform para cargas de trabalho híbridas com processamento de consulta SQL altamente paralelizado.
###
Configuração de implantação de pequeno porte
Neste exemplo, é usada uma configuração mínima para ilustrar um ambiente de desenvolvimento de pequeno porte que suporta até 10 desenvolvedores e 100 GB de dados. É fácil dar suporte a mais desenvolvedores e dados: basta alterar o tipo de instância da máquina virtual e aumentar o armazenamento dos discos persistentes conforme necessário.
Esta configuração é adequada para ambientes de desenvolvimento e para se familiarizar com a funcionalidade da InterSystems IRIS junto com construção de contêineres e orquestração do Docker, se desejar. Em geral, não se usam alta disponibilidade e espelhamento de bancos de dados em configurações de pequeno porte, mas essas funcionalidades podem ser adicionadas a qualquer momento, se for necessário prover alta disponibilidade.
Diagrama do exemplo de configuração de pequeno porte
O diagrama de exemplo abaixo na Figura 2.1.1-a ilustra a tabela de recursos na Figura 2.1.1-b. Os gateways incluídos são apenas exemplos e podem ser ajustados para se adequarem às práticas de rede padrão de sua organização.
Os seguintes recursos do projeto GCP VPC são provisionados com uma configuração mínima de pequeno porte. Podem ser adicionados ou removidos recursos do GCP conforme necessário.
Recursos do GCP para configuração de pequeno porte
Um exemplo de recursos do GCP para uma configuração de pequeno porte é fornecido na tabela abaixo.
É preciso considerar segurança de rede e regras de firewall adequadas para evitar o acesso não autorizado ao VPC. O Google desenvolveu melhores práticas de segurança de rede para dar os primeiros passos, disponíveis aqui.
Nota: as instâncias de máquina virtual precisam de um endereço IP público para estabelecerem conexão com os serviços do GCP. Embora esta prática possa suscitar preocupações, o Google recomenda usar regras de firewall para limitar o tráfego de entrada a essas instâncias de máquina virtual.
Caso sua política de segurança exija instâncias de máquina virtual verdadeiramente internas, você precisará configurar um proxy NAT manualmente em sua rede e uma rota correspondente para que as instâncias internas consigam estabelecer conexão com a Internet. É importante salientar que não é possível estabelecer conexão a uma instância de máquina virtual verdadeiramente interna diretamente usando-se SSH. Para estabelecer conexão a essas máquinas internas, você precisa configurar uma instância de bastion que tenha um endereço IP externo para usá-la como um túnel. É possível provisionar um host bastion para fornecer um ponto de entrada externo ao seu VPC.
Os detalhes dos hosts bastion estão disponíveis aqui.
Configuração de produção
Neste exemplo, temos uma configuração de maior porte como exemplo de configuração de produção que incorpora a funcionalidade de espelhamento de bancos de dados da InterSystems IRIS para fornecer alta disponibilidade e recuperação de desastres.
Está incluído nesta configuração um par de espelhos assíncronos dos servidores de banco de dados da InterSystems IRIS, divididos entre duas zonas dentro da região 1 para failover automático, e um terceiro membro espelho DR assíncrono na região 2 para recuperação de desastres no caso improvável de uma região GCP inteira ficar offline.
O servidor Arbiter e ICM da InterSystems é implantado em uma terceira zona separada para oferecer maior resiliência. O exemplo de arquitetura também inclui um conjunto de servidores web com balanceamento de carga opcionais para dar suporte a aplicações web. Esses servidores web com o InterSystems Gateway podem ser escaláveis de maneira independente, conforme necessário.
Diagrama do exemplo de configuração de produção
O diagrama de exemplo abaixo na Figura 2.2.1-a ilustra a tabela de recursos exibida na Figura 2.2.1-b. Os gateways incluídos são apenas exemplos e podem ser ajustados para se adequarem às práticas de rede padrão de sua organização.
Os seguintes recursos do GCP VPC Project são o mínimo recomendado para dar suporte a um cluster fragmentado. Podem ser adicionados ou removidos recursos do GCP conforme necessário.
Recursos do GCP configuração de produção
Um exemplo de recursos do GCP uma configuração de produção é fornecido nas tabelas abaixo.
Configuração de produção de grande porte
Neste exemplo, é fornecida uma configuração extremamente escalável expandindo-se a funcionalidade da InterSystems IRIS para fornecer servidores de aplicação usando-se o Enterprise Cache Protocol (ECP) da InterSystems para oferecer uma enorme escalabilidade horizontal de usuários. Neste exemplo, é incluído um nível ainda maior de disponibilidade, pois os clientes ECP preservam os detalhes de sessões mesmo caso haja failover da instância do banco de dados. São usadas diversas zonas GCP, com servidores de aplicação baseados em ECP e membros espelho de bancos de dados implantados em várias regiões. Esta configuração oferece suporte a dezenas de milhões de acessos ao banco de dados por segundo e a diversos terabytes de dados.
Diagrama do exemplo de configuração de produção de grande porte
O diagrama de exemplo na Figura 2.3.1-a ilustra a tabela de recursos na Figura 2.3.1-b. Os gateways incluídos são apenas exemplos e podem ser ajustados para se adequarem às práticas de rede padrão de sua organização.
Estão incluídos nesta configuração um par de espelhos de failover, quatro ou mais clientes ECP (servidores de aplicação) e um ou mais servidores web por servidor de aplicação. Os pares de espelhos de bancos de dados para failover são divididos entre duas zonas GCP diferentes na mesma região para proteção com domínio de falha, com o servidor Arbiter e ICM da InterSystems implantado em uma terceira zona para oferecer maior resiliência.
A recuperação de desastres se estende para uma segunda região e zona(s) GCP similar ao exemplo anterior. Podem ser usadas diversas regiões de recuperação de desastres com vários membros espelho DR assíncronos, se desejar.
Os seguintes recursos do GCP VPC Project são o mínimo recomendado para dar suporte a uma implantação em produção de grande escala. Podem ser adicionados ou removidos recursos do GCP conforme necessário.
Recursos do GCP para configuração de produção de grande porte
Um exemplo de recursos do GCP para uma configuração de produção de grande porte é fornecido nas tabelas abaixo.
Configuração de produção com cluster fragmentado da InterSystems IRIS
Neste exemplo, é fornecida uma configuração com escalabilidade horizontal para cargas de trabalho híbridas com SQL, incluindo-se os novos recursos de cluster fragmentado da InterSystems IRIS para fornecer uma enorme escalabilidade horizontal de consultas e tabelas SQL entre diversos sistemas. Os detalhes do cluster fragmentado da InterSystems IRIS e suas funcionalidades são abordados com mais detalhes posteriormente neste artigo.
Configuração de produção com cluster fragmentado da InterSystems IRIS
O diagrama de exemplo na Figura 2.4.1-a ilustra a tabela de recursos na Figura 2.4.1-b. Os gateways incluídos são apenas exemplos e podem ser ajustados para se adequarem às práticas de rede padrão de sua organização.
Estão incluídos nesta configuração quatro pares de espelhos como nós de dados. Cada um dos pares de espelhos de bancos de dados para failover é dividido entre duas zonas GCP diferentes na mesma região para proteção com domínio de falha, com o servidor Arbiter e ICM da InterSystems implantado em uma terceira zona para oferecer maior resiliência.
Esta configuração permite que todos os métodos de acesso ao banco de dados fiquem disponíveis a partir de qualquer nó de dados do cluster. Os dados das tabelas SQL grandes são particionados fisicamente em todos os nós de dados para permitir enorme paralelização de processamento de consultas e volume de dados. A combinação de todas essas funcionalidades permite o suporte a cargas de trabalho híbridas complexas, como consultas analíticas SQL de grande escala com ingestão simultânea de novos dados, tudo com uma única InterSystems IRIS Data Platform.
No diagrama acima e na coluna "tipo do recurso" na tabela abaixo, "Compute [Engine] (Computação [Mecanismo])" é um termo do GCP que representa uma instância de servidor GCP (virtual), conforme descrito com mais detalhes na seção 3.1 deste documento. Ele não representa nem sugere o uso de "nós de computação" na arquitetura de cluster descrita posteriormente neste artigo.
Os seguintes recursos do GCP VPC Project são o mínimo recomendado para dar suporte a um cluster fragmentado. Podem ser adicionados ou removidos recursos do GCP conforme necessário.
Recursos do GCP para configuração de produção com cluster fragmentado
Um exemplo de recursos do GCP para uma configuração de cluster fragmentado é fornecido na tabela abaixo.
* * *
Introdução aos conceitos de nuvem
O Google Cloud Platform (GCP) fornece um ambiente em nuvem repleto de recursos para infraestrutura como serviço (IaaS) totalmente capaz de dar suporte a todos os produtos da InterSystems, incluindo ao DevOps baseado em contêiner com a nova InterSystems IRIS Data Platform. Deve-se ter cuidado, assim como em qualquer plataforma ou modelo de implantação, para garantir que todos os aspectos de um ambiente sejam considerados, como desempenho, disponibilidade, operações de sistema, alta disponibilidade, recuperação de desastres, controles de segurança e outros procedimentos de gerenciamento. Este documento aborda os três principais componentes de todas as implantações em nuvem: Computação, Armazenamento e Rede.
Mecanismos de computação (máquinas virtuais)
No GCP, há diversas opções disponíveis para recursos de mecanismo de computação, com várias especificações de CPU e memória virtuais e das opções de armazenamento. Um item importante sobre o GCP: referências ao número de vCPUs em um determinado tipo de máquina é igual a um vCPU em um hyper-thread no host físico na camada do hypervisor.
Neste documento, os tipos de instância n1-standard* e n1-highmem* serão usados e estão amplamente disponíveis na maioria das regiões de implantação do GCP. Porém, o uso dos tipos de instância n1-ultramem* é uma excelente opção para conjuntos de dados muito grandes, pois são mantidas enormes quantidades de dados em cache na memória. As configurações padrão da instância, como a Política de disponibilidade da instância ou outros recursos avançados, são usadas, salvo indicação em contrário. Os detalhes dos vários tipos de máquina estão disponíveis aqui.
Armazenamento em disco
O tipo de armazenamento relacionado mais diretamente com os produtos da InterSystems são os tipos de disco persistente. Porém, o armazenamento local pode ser usado para altos níveis de desempenho, desde que as restrições de disponibilidade de dados sejam entendidas e atendidas. Existem várias outras opções, como armazenamento em nuvem (buckets). Porém, elas são mais específicas para os requisitos de cada aplicação, em vez de darem suporte à operação da InterSystems IRIS Data Platform.
Como vários outros provedores de nuvem, o GCP impõe limites da quantidade de armazenamento persistente que pode ser associado a um mecanismo de computação específico. Esses limites incluem o tamanho máximo de cada disco, o número de discos persistentes conectados a cada mecanismo de computação e a quantidade de IOPS por disco persistente com um limite geral de IOPS da instância específica do mecanismo de computação. Além disso, há limites de IOPS impostos por GB de espaço em disco. Então, às vezes é necessário provisionar mais capacidade de disco para alcançar a taxa de IOPS desejada.
Esses limites podem variar ao longo do tempo e devem ser confirmados com o Google conforme necessário.
Existem dois tipos de armazenamento persistente para volumes de disco: discos padrão persistentes e discos SSD persistentes. Os discos SSD persistentes são mais adequados para cargas de trabalho de produção que exigem um IOPS de baixa latência previsível e uma maior taxa de transferência. Os discos padrão persistentes são uma opção mais acessível para ambientes de desenvolvimento e teste ou para cargas de trabalho de arquivamento.
Os detalhes dos vários tipos de disco e limitações estão disponíveis aqui.
Rede do VPC
A rede Virtual Private Cloud (VPC) é recomendável para dar suporte aos diversos componentes da InterSystems IRIS Data Platform e também para fornecer controles de segurança de rede adequados, vários gateways, roteamento, atribuições de endereço IP interno, isolamento de interface de rede e controles de acesso. Um exemplo de VPC será detalhado nos exemplos apresentados neste documento.
Os detalhes de rede e firewall do VPC estão disponíveis aqui.
* * *
Visão geral do Virtual Private Cloud (VPC)
Os VPCs do GCP são um pouco diferentes dos de outros provedores de nuvem e oferecem maior simplicidade e flexibilidade. Uma comparação dos conceitos está disponível aqui.
São permitidos diversos VPCs por projeto do GCP (atualmente, 5 por projeto, no máximo), e existem duas opções para criar uma rede no VPC: modo automático e modo personalizado.
Os detalhes de cada tipo estão disponíveis aqui.
Na maioria das implantações em nuvem de grande porte, vários VPCs são provisionados para isolar os diversos tipos de gateways dos VPCs para aplicações e para aproveitar o emparelhamento de VPCs para comunicações de entrada e saída. Recomendamos consultar seu administrador de rede para verificar detalhes das subredes permitidas e qualquer regra de firewall de sua organização. O emparelhamento de VPCs não é abordado neste documento.
Nos exemplos fornecidos neste documento, um único VPC com três subredes será usado para fornecer isolamento de rede dos vários componentes e para se ter uma latência e largura de banda previsíveis, além de isolamento de segurança dos diversos componentes da InterSystems IRIS.
Definições de subrede e gateway de rede
São fornecidos dois gateways no exemplo deste documento para dar suporte a conectividade via Internet e VPN segura. Cada acesso de entrada precisa ter regras de firewall e roteamento corretas para fornecer segurança adequada à aplicação. Os detalhes de como usar rotas estão disponíveis aqui.
São usadas três subredes nos exemplos de arquitetura fornecidos, exclusivas para uso com a InterSystems IRIS Data Platform. O uso dessas subredes e interfaces de rede separadas permite maior flexibilidade dos controles de segurança e proteção da largura de banda, além do monitoramento de cada um dos três principais componentes acima. Os detalhes dos vários casos de uso estão disponíveis aqui.
Os detalhes da criação de instâncias de máquina virtual com várias interfaces de rede estão disponíveis aqui.
Subredes incluídas nestes exemplos:
Rede do Espaço do Usuáriopara consultas e usuários conectados de entrada
Rede Fragmentadapara comunicações interfragmentos entre os nós fragmentados
Rede de Espelhamentopara alta disponibilidade usando replicação assíncrona e failover automático de nós de dados individuais.
Nota:: o espelhamento síncrono de bancos de dados para failover só é recomendado entre diversas zonas com interconexões de baixa latência em uma única região GCP. Geralmente, a latência entre as regiões é alta demais para fornecer uma boa experiência do usuário, principalmente para implantações com altas taxas de atualização.
### Balanceadores de carga internos
A maioria dos servidores de nuvem IaaS não tem a capacidade de fornecer um endereço IP virtual (VIP), geralmente usado nos projetos com failover automático de bancos de dados. Para tratar esse problema, vários dos métodos de conectividade usados com mais frequência, especificamente clientes ECP e gateways web, são aprimorados na InterSystems IRIS para não depender da funcionalidade de VIP, tornando-os cientes do espelhamento e automáticos.
Métodos de conectividade como xDBC, sockets TCP-IP diretos ou outros protocolos de conexão direta exigem o uso de endereços tipo VIP. Para dar suporte a esses protocolos de entrada, a tecnologia de espelhamento de bancos de dados da InterSystems possibilita o failover automático para esses métodos de conectividade no GCP, usando uma página de status de verificação de integridade chamada <span class="Characteritalic" style="font-style:italic">mirror_status.cxw </span> para interagir com o balanceador de carga para conseguir funcionalidade parecida com a do VIP do balanceador de carga, encaminhando o tráfego somente para o membro espelho primário ativo e, portanto, fornecendo um projeto de alta disponibilidade completo e robusto no GCP.
Os detalhes de como usar um balanceador de carga para fornecer funcionalidade parecida com a do VIP estão disponíveis aqui.
Exemplo de topologia do VPC
Combinando todos os componentes, a ilustração da Figura 4.3-a abaixo demonstra o layout de um VPC com as seguintes características:
Usa várias zonas dentro de uma região para fornecer alta disponibilidade
Fornece duas regiões para recuperação de desastres
Usa subredes múltiplas para segregação da rede
Inclui gateways separados para conectividade via Internet e conectividade via VPN
Usa um balanceador de carga em nuvem para failover de IP para membros espelho
* * *
Visão geral do armazenamento persistente
Conforme abordado na introdução, recomenda-se o uso dos discos persistentes do GCP, especificamente os tipos de disco SSD persistente. Recomendam-se os discos SSD persistentes devido a taxas IOPS de leitura e gravação maiores, além da baixa latência necessária para cargas de trabalho de bancos de dados transacionais e analíticos. Podem ser usadas SSDs locais em determinadas circunstâncias, mas é importante salientar que os ganhos de desempenho das SSDs locais são obtidos ao custo de disponibilidade, durabilidade e flexibilidade.
Os detalhes de persistência de dados em SSDs locais estão disponíveis aqui para entender quando os dados de SSDs locais são preservados e quando não são.
LVM Striping
Como outros fornecedores de nuvem, o GCP impõe diversos limites no armazenamento, em termos de IOPS, espaço de armazenamento e número de dispositivos por instância de máquina virtual. Consulte a documentação do GCP para conferir os limites atuais aqui.
Com esses limites, o LVM stripping se torna necessário para maximizar o IOPS para além de um único dispositivo de disco para uma instância de banco de dados. No exemplo das instâncias de máquina virtual fornecido, recomendam-se os seguintes layouts de disco. Os limites de desempenho relativos aos discos de SSD persistentes estão disponíveis aqui.
Nota: atualmente, há um limite máximo de 16 discos persistentes por instância de máquina virtual, embora o GCP tenha informado que, atualmente, um aumento para 128 está em fase beta, o que será uma melhoria muito bem-vinda.
Com o LVM stripping, é possível espalhar cargas de trabalho de E/S aleatórias para mais dispositivos de disco e herdar filhas de discos. Veja abaixo um exemplo de como usar o LVM stripping com o Linux para o grupo de volumes do banco de dados. Este exemplo usa quatro discos em um LVM PE stripe com uma tamanho de extensão física (PE) de 4 MB. Também é possível usar tamanhos de PE maiores, se necessário.
Passo 1: Criar os discos padrão ou discos SSD persistentes conforme necessário
Etapa 2: O agendador de E/S é o NOOP para cada dispositivo de disco, usando-se "lsblk -do NAME,SCHED"
Etapa 3: Identificar os dispositivos de disco usando "lsblk -do KNAME,TYPE,SIZE,MODEL"
Etapa 4: Criar o grupo de volumes com novos dispositivos de disco
vgcreate s 4M
exemplo: vgcreate -s 4M vg_iris_db /dev/sd[h-k]
Etapa 4: Criar volume lógico
lvcreate n -L -i -I 4MB
exemplo: lvcreate -n lv_irisdb01 -L 1000G -i 4 -I 4M vg_iris_db
Etapa 5: Criar sistema de arquivo
mkfs.xfs K
exemplo: mkfs.xfs -K /dev/vg_iris_db/lv_irisdb01
Etapa 6: Montar sistema de arquivo
edit /etc/fstab com as seguintes entradas de montagem
/dev/mapper/vg_iris_db-lv_irisdb01 /vol-iris/db xfs defaults 0 0
mount /vol-iris/db
Usando a tabela acima, cada servidor da InterSystems IRIS terá a seguinte configuração com dois discos para SYS (sistema), quatro discos para DB (banco de dados), dois discos para registros de log primários e dois discos para registros de log alternativos.
Para escalabilidade, o LVM permite a expansão de dispositivos e volumes lógicos quando necessário sem interrupções. Consulte as melhores práticas de gerenciamento constante e expansão de volumes LVM na documentação do Linux.
Nota: a ativação de E/S assíncrona para o banco de dados e os arquivos de registros de log de imagem de gravação são altamente recomendáveis. Consulte os detalhes de ativação no Linux no seguinte artigo da comunidade: https://community.intersystems.com/post/lvm-pe-striping-maximize-hyper-converged-storage-throughput
* * *
Provisionamento
O InterSystems Cloud Manager (ICM) é uma novidade da InterSystems IRIS. O ICM realiza muitas tarefas e oferece diversas opções para provisionamento da InterSystems IRIS Data Platform. O ICM é fornecido como uma imagem do Docker que inclui tudo que é necessário para provisionar uma solução em nuvem do GCP robusta.
Atualmente, o ICM dá suporte ao provisionamento nas seguintes plataformas:
Google Cloud Platform (GCP)
Amazon Web Services, incluindo GovCloud (AWS / GovCloud)
Microsoft Azure Resource Manager, incluindo Government (ARM / MAG)
VMware vSphere (ESXi)
O ICM e o Docker podem ser executados em uma estação de trabalho desktop/notebook ou em um servidor de "provisionamento" simples, exclusivo e centralizado com um repositório centralizado.
A função do ICM no ciclo de vida da aplicação é Definir -> Provisionar -> Implantar -> Gerenciar
Os detalhes de instalação e uso do ICM com o Docker estão disponíveis aqui.
NOTA: o uso do ICM não é obrigatório para implantações em nuvem. O método tradicional de instalação e implantação com distribuições tarball é totalmente compatível e disponível. Porém, o ICM é recomendado para facilidade de provisionamento e gerenciamento em implantações em nuvem.
Monitoramento de contêiner
O ICM inclui um recurso de monitoramento básico usando Weave Scope para implantação baseada em contêiner. Ela não é implantada por padrão e precisa ser especificada no campo Monitor do arquivo de padrões.
Os detalhes de monitoramento, orquestração e agendamento com o ICM estão disponíveis aqui.
Uma visão geral e documentação do Weave Scope estão disponíveis aqui.
* * *
Alta disponibilidade
O espelhamento de bancos de dados da InterSystems proporciona o mais alto nível de disponibilidade em qualquer ambiente de nuvem. Existem opções para fornecer alguma resiliência de máquina virtual diretamente no nível da instância. Os detalhes das diversas políticas disponíveis no GCP estão disponíveis aqui.
As seções anteriores explicaram como um balanceador de carga em nuvem fornece failover automático de endereço IP para uma funcionalidade de IP Virtual (parecida com VIP) com espelhamento de bancos de dados. O balanceador de carga em nuvem usa a página de status de verificação de integridade <span class="Characteritalic" style="font-style:italic">mirror_status.cxw</span> mencionada anteriormente na seção Balanceadores de carga internos. Existem dois modos de espelhamento de bancos de dados: síncrono com failover automático e assíncrono. Neste exemplo, será abordado o espelhamento com failover síncrono. Os detalhes do espelhamento estão disponíveis aqui.
A configuração de espelhamento mais básica é um par de membros espelho de failover em uma configuração controlada pelo Arbiter. O Arbiter é colocado em uma terceira zona dentro da mesma região para proteção contra possíveis interrupções na zona que impactem tanto o Arbiter quanto um dos membros espelho.
Existem várias maneiras de configurar o espelhamento na configuração de rede. Neste exemplo, usaremos as subredes definidas anteriormente na seção Definições de subrede e gateway de rededeste documento. Serão fornecidos exemplos de esquemas de endereço IP em uma seção abaixo e, para o objetivo desta seção, somente as interfaces de rede e subredes designadas serão representadas.
* * *
Recuperação de desastres
O espelhamento de bancos de dados da InterSystems estende a funcionalidade de alta disponibilidade para também dar suporte à recuperação de desastres para outra região geográfica do GCP para proporcionar resiliência operacional no caso improvável de uma região GCP inteira ficar offline. Como uma aplicação conseguirá suportar essas interrupções depende da meta de tempo de recuperação (RTO) e das metas de ponto de recuperação (RPO). Elas fornecerão a estrutura inicial para a análise necessária para projetar um plano de recuperação de desastres adequado. Os seguintes links apresentam um guia para os itens que devem ser considerados ao criar um plano de recuperação de desastres para sua aplicação. https://cloud.google.com/solutions/designing-a-disaster-recovery-plan e https://cloud.google.com/solutions/disaster-recovery-cookbook
Espelhamento assíncrono de bancos de dados
O espelhamento de bancos de dados da InterSystems IRIS Data Platform fornece funcionalidades robustas para replicação assíncrona de dados entre zonas e regiões do GCP para ajudar a alcançar os objetivos de RTO e RPO de seu plano de recuperação de desastres. Os detalhes de membros espelho assíncronos estão disponíveis aqui.
Similar à seção anterior sobre alta disponibilidade, um balanceador de carga em nuvem fornece failover automático de endereço IP para uma funcionalidade de IP Virtual (parecida com IP virtual) para espelhamento assíncrono para recuperação de desastres também usando a mesma página de status de verificação de integridade <span class="Characteritalic" style="font-style:italic">mirror_status.cxw</span> mencionada anteriormente na seção Balanceadores de carga internos.
Neste exemplo, o espelhamento assíncrono de failover para recuperação de desastres será abordado junto com a introdução do serviço de Balanceamento de carga global do GCP para fornecer a sistemas upstream e estações de trabalho clientes um único endereço IP anycast, independentemente de em qual zona ou região sua implantação da InterSystems IRIS esteja operando.
Um dos avanços do GCP é o que o balancedador de carga é um recurso global definido por software e não está vinculado a uma região específica. Dessa forma, você terá o recurso exclusivo de usar um único serviço entre regiões, já que não é uma instância ou solução baseada em dispositivo. Os detalhes do Balanceamento Global de carga com IP anycast do GCP estão disponíveis aqui.
No exemplo acima, os endereços IP de todas as três instâncias da InterSystems IRIS recebem um Balanceador de carga global do GCP, e o tráfego será encaminhado somente para o membro espelho que for o espelho primário ativo, independentemente da zona ou região na qual está localizado.
* * *
Cluster fragmentado
A InterSystems IRIS inclui um amplo conjunto de funcionalidades para permitir escalabilidade de suas aplicações, que podem ser aplicadas de maneira independente ou conjunta, dependendo da natureza de sua carga de trabalho e dos desafios de desempenho específicos enfrentados. Uma dessas funcionalidades, a fragmentação, particiona os dados e o cache associado em diversos servidores, fornecendo escalabilidade flexível, barata e com bom desempenho para consultas e ingestão de dados, ao mesmo tempo em que maximiza o valor da infraestrutura por meio da utilização de recursos extremamente eficiente. Um cluster fragmentado da InterSystems IRIS pode proporcionar vantagens de desempenho significativas para diversas aplicações, mas especialmente para aquelas com cargas de trabalho que incluem um ou mais dos seguintes aspectos:
Ingestão de dados de alta velocidade ou alto volume, ou uma combinação das duas.
Conjuntos de dados relativamente grandes ou consultas que retornam grandes quantidades de dados, ou ambos.
Consultas complexas que realizam grandes quantidades de processamento de dados, como aquelas que buscam muitos dados no disco ou envolvem trabalho computacional significativo.
Cada um desses fatores tem suas próprias influências no ganho potencial obtido com a fragmentação, mas pode haver mais vantagens quando há uma combinação deles. Por exemplo, uma combinação dos três fatores (grandes quantidades de dados ingeridos rapidamente, grandes conjuntos de dados e consultas complexas que recuperam e processam muitos dados) faz muitas das cargas de trabalho analíticas da atualidade excelentes candidatas para a fragmentação.
Todas essas características estão relacionadas a dados, e a principal função da fragmentação da InterSystems IRIS é fornecer escalabilidade para grandes volumes de dados. Porém, um cluster fragmentado também pode incluir recursos para escalabilidade de volume de usuários, quando as cargas de trabalho que envolvem alguns ou todos esses fatores relacionados a dados também têm um altíssimo volume de consultas devido à grande quantidade de usuários. A fragmentação também pode ser combinada com escalabilidade vertical.
Visão geral operacional
O centro da arquitetura de fragmentação é o particionamento dos dados e do cache associado em vários sistemas. Um cluster fragmentado particiona fisicamente grandes tabelas de bancos de dados horizontalmente (ou seja, por linha) em diversas instâncias da InterSystems IRIS, chamadas denós de dados, enquanto permite às aplicações acessar de maneira transparente essas tabelas por qualquer nó e ainda ver todo o conjunto de dados como uma única união lógica. Essa arquitetura tem as seguintes vantagens:
Processamento paralelo: as consultas são executadas em paralelo nos nós de dados, e os resultados são unidos, combinados e retornados à aplicação como resultados de consulta completos pelo nó ao qual a aplicação está conectada, aumentando consideravelmente a velocidade de execução em diversos casos.
Cache particionado: cada nó de dados tem seu próprio cache, exclusivo para a partição fragmentada dos dados da tabela fragmentada que ele armazena, em vez de um único cache da instância atendendo a todo o conjunto de dados, o que reduz bastante o risco de sobrecarregar o cache e forçar leituras no disco que degradam o desempenho.
Carregamento paralelo: os dados podem ser carregados nos nós de dados em paralelo, reduzindo o cache e a contenção de disco entre a carga de trabalho de ingestão e a carga de trabalho de consulta, e aumentando o desempenho de ambas.
Os detalhes de cluster fragmentado da InterSystems IRIS estão disponíveis aqui.
Elementos de fragmentação e tipos de instância
Um cluster fragmentado consiste de pelo menos um nó de dados e, se necessário para requisitos específicos de desempenho ou carga de trabalho, uma quantidade opcional de nós computacionais. Esses dois tipos de nó oferecem blocos de construção simples com um modelo de escalabilidade simples, transparente e eficiente.
Nós de dados
Os nós de dados armazenam dados. No nível físico, os dados de tabelas fragmentadas[1] são espalhados em todos os nós de dados do cluster, e os dados de tabelas não fragmentadas são armazenados fisicamente somente no primeiro nó de dados. Essa diferença é transparente para os usuários, com uma única possível exceção: o primeiro nó pode ter um consumo de armazenamento um pouco maior que os outros, mas espera-se que essa diferença seja insignificante, já que os dados de tabelas fragmentadas costumam ser maiores que os dados de tabelas não fragmentadas em pelo menos uma ordem de grandeza.
Os dados de tabelas fragmentadas podem ser rebalanceados no cluster quando necessário, em geral após adicionar novos nós de dados. Essa ação moverá "buckets" de dados entre os nós para deixar a distribuição de dados aproximadamente igual.
No nível lógico, os dados de tabelas não fragmentadas e a junção de todos os dados das tabelas fragmentadas são visíveis de qualquer nó, então os clientes verão todo o conjunto de dados, independentemente de a qual nó estão conectados. Os metadados e o código também são compartilhados entre todos os nós de dados.
O diagrama básico da arquitetura de um cluster fragmentado consiste simplesmente dos nós de dados que parecem uniformes em todo o cluster. As aplicações cliente podem se conectar a qualquer nó e usarão os dados como se eles fossem locais.
[1] Por conveniência, o termo “dados das tabelas fragmentadas” é usado em todo o documento para representar os dados de “extensão” para qualquer modelo de dados com suporte a fragmentação e que estão marcados como fragmentados. Os termos “dados de tabelas não fragmentadas” e “dados não fragmentados” são usados para representar os dados que estão em uma extensão fragmentável não marcada desta forma ou para um modelo de dados que simplesmente não dá suporte a fragmentação ainda.
Nós de dados
Para cenários avançados em que é necessário ter baixas latências, possivelmente com uma chegada constante de dados, podem ser adicionados nós computacionais para fornecer uma camada de cache transparente para responder às consultas.
Os nós computacionais armazenam dados em cache. Cada nó computacional está associado a um nó de dados, para o qual ele armazena em cache os dados das tabelas fragmentadas correspondentes e, além disso, ele também armazena em cache dados das tabelas não fragmentadas conforme necessário para responder às consultas.
Como os nós computacionais não armazenam fisicamente dados e têm a função de dar suporte à execução de consultas, o perfil de hardware deles pode ser personalizado de acordo com essas necessidades, por exemplo, adicionando mais memória e CPI e mantendo o armazenamento no mínimo necessário. A ingestão é encaminhada para os nós de dados, seja por um driver (xDBC, Spark) ou implicitamente pelo código de gerenciamento de fragmentação quando o código da aplicação "crua" é executado em um nó computacional.
* * *
Ilustrações do cluster fragmentado
Existem várias combinações de implantação de um cluster fragmentado. Os seguintes diagramas de alto nível são fornecidos para ilustrar os modelos de implantação mais comuns. Esses diagramas não incluem os gateways e detalhes de rede e se concentram somente nos componentes do cluster fragmentado.
Cluster fragmentado básico
O diagrama abaixo é o cluster fragmentado mais simples, com quatro nós de dados implantados em uma única região e uma única zona. Um Balanceador de carga global do GCP é usado para distribuir as conexões de clientes para qualquer um dos nós do cluster fragmentado.
Neste modelo básico, não é fornecida resiliência ou alta disponibilidade além daquelas oferecidas pelo GCP para uma única máquina virtual e seu armazenamento SSD persistente. São recomendados dois adaptadores de interface de rede separados para fornecer tanto isolamento de segurança da rede para as conexões de entrada dos clientes quanto isolamento de largura de banda entre o tráfego dos clientes e as comunicações do cluster fragmentado.
Cluster fragmentado básico com alta disponibilidade
O diagrama abaixo é o cluster fragmentado mais simples, com quatro nós de dados espelhados implantados em uma única região dividindo o espelho de cada nó entre zonas. Um Balanceador de carga global do GCP é usado para distribuir as conexões de clientes para qualquer um dos nós do cluster fragmentado.
A alta disponibilidade é fornecida pelo uso do espelhamento de bancos de dados da InterSystems, que manterá um espelho replicado de maneira síncrona em uma zona secundária dentro da região.
São recomendados três adaptadores de interface de rede separados para fornecer isolamento de segurança da rede para as conexões de entrada dos clientes, isolamento de largura de banda entre o tráfego dos clientes e as comunicações do cluster fragmentado, e o tráfego do espelhamento síncrono entre os pares de nó.
Este modelo de implantação também agrega o Arbiter espelho conforme descrito em uma seção anterior deste documento.
Cluster fragmentado com nós computacionais separados
O seguinte diagrama expande o cluster fragmentado para simultaneidade maciça de usuários/consultas com nós computacionais separados e quatro nós de dados. O pool de servidores de Cloud Load Balancer contém somente os endereços dos nós computacionais. As atualizações e ingestões de dados continuarão a ser feitas diretamente nos nós de dados como antes para manter desempenho com latência baixíssima e evitar interferência e congestão de recursos entre as cargas de trabalho analíticas/de consultas e a ingestão de dados em tempo real.
Com este modelo, pode ser feito um ajuste fino da alocação de recursos para escalabilidade de computação/consultas e ingestão de maneira independente, permitindo um uso ideal de recursos quando necessário de forma "just-in-time" e mantendo uma solução simples e econômica, em vez de gastar recursos desnecessariamente só para escalabilidade de computação ou dados.
Os nós computacionais fazem um uso bem direto do grupo de escalabilidade automática do GCP (também chamado de Autoscaling) para permitir a inclusão ou exclusão automática de instâncias de um grupo de instâncias gerenciado com base em aumento ou diminuição da carga. A escalabilidade automática funciona pela inclusão de mais instâncias ao grupo quando há mais carga (aumento de escalabilidade) e pela exclusão de instâncias quando são necessárias menos instâncias (diminuição de escalabilidade).
Os detalhes de escalabilidade automática do GCP estão disponíveis aqui.
A escalabilidade automática ajuda as aplicações em nuvem a tratar de maneira simples o aumento no tráfego e reduz o custo quando a necessidade de recursos diminui. Basta definir a política de escalabilidade automática, e a ferramenta de escalabilidade automática atua com base na carga mensurada.
* * *
Operações de backup
Existem várias opções disponíveis para operações de backup. As três opções a seguir são viáveis para sua implantação do GCP com a InterSystems IRIS.
As duas primeiras opções detalhas abaixo incorporam um procedimento do tipo instantâneo (snapshot) que envolve a suspensão das gravações do banco de dados no disco antes de criar o snapshot e, em seguida, a retomada das atualizações assim que o snapshot for bem-sucedido.
As seguintes etapas de alto nível são realizadas para criar um backup limpo usando um dos métodos de snapshot:
Pausar gravações no banco de dados por meio da chamada de API de congelamento externo do banco de dados.
Criar snapshots dos discos de dados e do sistema operacional.
Retomar as gravações do banco de dados por meio da chamada da API de descongelamento externo.
Arquivos de instalação de backup para localização de backup
Os detalhes das APIs de congelamento/descongelamento externos estão disponíveis aqui.
Nota: não estão incluídos neste documento exemplos de script para backup. Porém, verifique periodicamente os exemplos publicados na InterSystems Developer Community. www.community.intersystems.com
A terceira opção é o backup on-line da InterSystems. Esta é uma opção básica para implantações de pequeno porte com um caso de uso e interface bem simples. No entanto, à medida que os bancos de dados aumentam de tamanho, os backups externos com tecnologia de snapshot são recomendados como uma melhor prática, com diversas vantagens, incluindo o backup de arquivos externos, tempos de restauração mais rápidos e uma visão corporativa de dados e ferramentas de gerenciamento.
Etapas adicionais, como verificações de integridade, podem ser adicionadas em intervalos periódicos para garantir um backup limpo e consistente.
Os pontos de decisão sobre qual opção usar dependem dos requisitos operacionais e políticas de sua organização. A InterSystems está disponível para discutir as várias opções com mais detalhes.
Backup de snapshot de disco persistente do GCP
As operações de backup podem ser arquivadas usando a API de linha de comando gcloud do GCP junto com os recursos das APIs de congelamento/descongelamento externos da InterSystems. Assim, é possível ter resiliência operacional 24/7 e a garantia de backups limpos regulares. Os detalhes de gerenciamento, criação e automação de snapshots dos discos persistentes do GCP estão disponíveis aqui.
Snapshots do Logical Volume Manager (LVM)
Como alternativa, muitas das ferramentas de backup de terceiros disponíveis no mercado podem ser usadas implementando agentes de backup individuais na própria VM e aproveitando backups em nível de arquivo em conjunto com snapshots do Logical Volume Manager (LVM).
Um dos principais benefícios desse modelo é ter a capacidade de fazer restaurações em nível de arquivo de VMs Windows ou Linux. Alguns pontos a serem observados com esta solução são: como o GCP e a maioria dos outros provedores em nuvem IaaS não fornecem mídia de fita, todos os repositórios de backup são baseados em disco para arquivamento de curto prazo e têm a capacidade de aproveitar o armazenamento de baixo custo do tipo blob ou bucket para retenção de longo prazo (LTR). É altamente recomendável usar este método para usar um produto de backup que suporte tecnologias de eliminação de duplicação e fazer o uso mais eficiente dos repositórios de backup baseados em disco.
Alguns exemplos desses produtos de backup com suporte à nuvem incluem, mas não se limitam a: Commvault, EMC Networker, HPE Data Protector e Veritas Netbackup.
Nota: a InterSystems não valida ou endossa um produto de backup em detrimento do outro. A responsabilidade de escolher um software de gerenciamento de backup é de cada cliente.
Backup on-line
Para implantações de pequeno porte, o recurso de backup on-line integrado também é uma opção viável. Este utilitário de backup on-line de banco de dados da InterSystems faz backup de dados em arquivos de banco de dados, capturando todos os blocos nos bancos de dados e depois gravando a saída em um arquivo sequencial. Este mecanismo de backup proprietário foi projetado para não causar tempo de inatividade aos usuários do sistema em produção. Os detalhes do backup on-line estão disponíveis aqui.
No GCP, após a conclusão do backup on-line, o arquivo de saída do backup e todos os outros arquivos em uso pelo sistema devem ser copiados para algum outro local de armazenamento fora da instância da máquina virtual. O armazenamento de bucket/objeto é uma boa opção.
Existem duas opções para usar um bucket de armazenamento do GCP.
Usar as APIs de script gcloud diretamente para copiar e manipular os arquivos de backup on-line recém-criados (e outros arquivos não relacionados ao banco de dados). Os detalhes estão disponíveis aqui.
Montar um bucket de armazenamento como um sistema de arquivo e usá-lo de maneira similar a um disco persistente, embora os buckets de armazenamento em nuvem sejam armazenamento de objetos.
Os detalhes de como montar um bucket de armazenamento em nuvem usando o Cloud Storage FUSE estão disponíveis aqui.
Artigo
Eduard Lebedyuk · Nov. 22, 2021
Todo mundo tem um ambiente de teste.
Algumas pessoas têm a sorte de ter um ambiente totalmente separado para executar a produção.
-- Desconhecido
.
Nesta série de artigos, gostaria de apresentar e discutir várias abordagens possíveis para o desenvolvimento de software com as tecnologias InterSystems e GitLab. Vou cobrir tópicos como:
* Git Básico
* Fluxo Git (processo de desenvolvimento)
* Instalação do GitLab
* Fluxo de Trabalho do GitLab
* GitLab CI/CD
* CI/CD com contêineres
Esta primeira parte trata do pilar do desenvolvimento de software moderno - sistema de controle de versão Git e vários fluxos Git.
## Git Básico
Embora o tópico principal que iremos discutir seja o desenvolvimento de software em geral e como o GitLab pode nos capacitar nesse esforço, o Git, ou melhor, os vários [conceitos de alto nível](https://en.wikipedia.org/wiki/Git#Characteristics) subjacentes no design do Git, são importantes para o melhor entendimento de conceitos posteriores.
Dito isso, o **Git** é um sistema de controle de versão, baseado nessas ideias (existem [muitas outras](en.wikipedia.org/wiki/Git#Characteristics), essas são as mais importantes):
* **Desenvolvimento não linear** significa que enquanto nosso software é lançado consequentemente da versão 1 para a 2 para a 3, sob a mesa a mudança da versão 1 para a 2 é feita em paralelo - vários desenvolvedores desenvolvem uma série de recursos/correções de bugs simultaneamente.
* **Desenvolvimento distribuído** significa que o desenvolvedor é independente de um servidor central ou de outros desenvolvedores e pode desenvolver facilmente em seu próprio ambiente.
* **Fusão** - as duas ideias anteriores nos levam à situação em que muitas versões diferentes da verdade existem simultaneamente e precisamos uni-las de volta em um estado completo.
Agora, não estou dizendo que Git inventou esses conceitos. Não. Em vez disso, o Git os tornou fáceis e populares e isso, juntamente com várias inovações relacionadas, ou seja, infraestrutura como código/conteinerização mudou o desenvolvimento de software.
### Termos básicos do Git
**Repositório** é um projeto que armazena dados e metainformações sobre os dados.
* O repositório "físico" é um diretório em um disco.
* O repositório armazena arquivos e diretórios.
* O repositório também armazena um histórico completo de alterações para cada arquivo.
O repositório pode ser armazenado:
* Localmente, em seu próprio computador
* Remotamente em um servidor remoto
Mas não há nenhuma diferença particular entre repositórios locais e remotos do ponto de vista do git.
**Commit** é um estado fixo do repositório. Obviamente, se cada commit armazenasse o estado completo do repositório, nosso repositório cresceria muito rapidamente. É por isso que um commit armazena um **diff** que é uma diferença entre o commit atual e seu **commit pai**.
Commits diferentes podem ter um número diferente de pais:
* 0 - o primeiro commit no repositório não tem pais.
* 1 - conforme o habitual - nosso commit mudou algo no repositório como era durante o commit pai
* 2 - quando temos dois estados diferentes do repositório, podemos uni-los em um novo estado. E esse estado e esse commit teriam 2 pais.
* >2 - pode acontecer quando unimos mais de 2 estados diferentes do repositório em um novo estado. Não seria particularmente relevante para nossa discussão, mas existe.
Agora, para um pai, cada commit diferente é chamado de **commit filho**. Cada commit pai pode ter qualquer número de commits filhos.
**Branch** é uma referência (ou ponteiro) para um commit. Veja como funciona:
Nesta imagem, podemos ver o repositório com dois commits (círculos cinza), o segundo é o head do branch master. Depois de adicionar mais commits, nosso repositório começa a ficar assim:

Esse é o caso mais simples. Um desenvolvedor trabalha em uma mudança de cada vez. No entanto, normalmente, existem muitos desenvolvedores trabalhando simultaneamente em diferentes recursos e precisamos de uma **árvore de commit** para mostrar o que está acontecendo em nosso repositório.
### Árvore de commit
Vamos começar do mesmo ponto de partida. Aqui está o repositório com dois commits:
Mas agora, dois desenvolvedores estão trabalhando ao mesmo tempo e para não interferir um no outro, eles trabalham em branches separados:

Depois de um tempo, eles precisam unir as alterações feitas e para isso eles criam uma **solicitação de mesclagem (merge)** (também chamada de **pull request**) - que é exatamente o que parece - é uma solicitação para unir dois estados diferentes do repositório (no nosso caso, queremos mesclar o develop branch no master branch) em um novo estado. Depois de ser devidamente revisado e aprovado, nosso repositório fica assim:
E o desenvolvimento continua:
### Resumo - Git Básico
Conceitos principais:
* **Git** é um sistema de controle de versão distribuído não linear.
* **Repositório** armazena dados e metainformações sobre os dados.
* **Commit** é um estado fixo do repositório.
* **Branch** é uma referência para um commit.
* **Solicitação de mesclagem** (também chamada de **pull request**) - é uma solicitação para unir dois estados diferentes do repositório em um novo estado.
Se você quiser ler mais sobre o Git, existem [livros disponíveis](https://git-scm.com/book/en/v2).
## Fluxos Git
Agora que o leitor está familiarizado com os termos e conceitos básicos do Git, vamos falar sobre como a parte do desenvolvimento do ciclo de vida do software pode ser gerenciada usando o Git. Existem várias práticas (chamadas de fluxos) que descrevem o processo de desenvolvimento usando Git, mas vamos falar sobre duas delas:
* Fluxo do GitHub
* Fluxo do GitLab
### Fluxo do GitHub
O fluxo do GitHub é tão fácil quanto parece. Aqui está:
1. Crie um branch (ramificação) do repositório.
2. Commit suas alterações para seu novo branch
3. Envie um pull request do seu branch com as alterações propostas para iniciar uma discussão.
4. Commit mais alterações em seu branch conforme necessário. Seu pull request será atualizado automaticamente.
5. Mescle o pull request assim que o branch estiver pronto para ser mesclado.
E existem várias regras que devemos seguir:
* master branch é sempre implantável (e funcionando!)
* Não há desenvolvimento indo diretamente para o master branch
* O desenvolvimento está acontecendo nos branches de recursos
* master == ambiente\** de produção\*
* Você precisa implantar na produção o mais rápido possível
* * Não confunda com "Produções Ensemble", aqui "Produção" significa SISTEMA EM PRODUÇÃO.
** Ambiente é um local configurado onde seu código é executado - pode ser um servidor, uma VM, até mesmo um contêiner.
Veja como funciona:
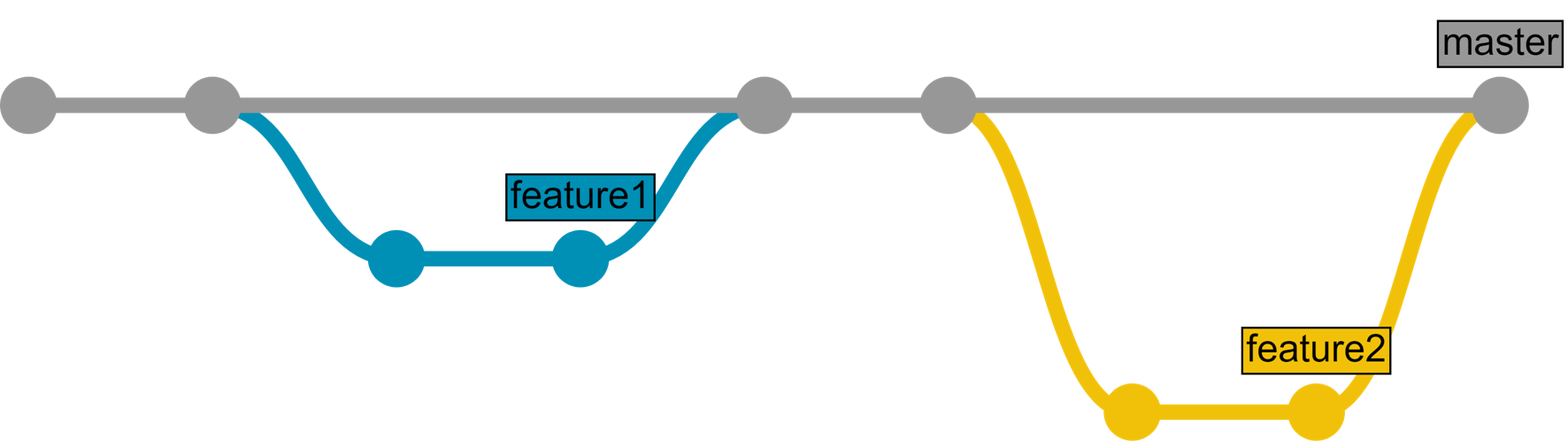
Você pode ler mais sobre o fluxo do GitHub [aqui](https://help.github.com/articles/github-flow/). Também há um [guia ilustrado](https://guides.github.com/introduction/flow/).
O fluxo do GitHub é bom para pequenos projetos e para testes se você está começando com os fluxos do Git. No entanto, o GitHub o usa, portanto, também pode ser viável em projetos grandes.
### Fluxo do GitLab
Se você não estiver pronto para implantar na produção imediatamente, o fluxo do GitLab oferece um fluxo do GitHub + ambientes. É assim que funciona - você desenvolve em branches de recursos, como acima, mescla (merge) no master, como acima, mas aqui está uma diferença: o master é igual apenas no ambiente de teste. Além disso, você tem "Branches de ambiente" que estão vinculados a vários outros ambientes que você possa ter.
Normalmente, existem três ambientes (você pode criar mais se precisar):
* Ambiente de teste == master branch
* Ambiente de pré-produção == preprod branch
* Ambiente de produção == prod branch
O código que chega em um dos branches do ambiente deve ser movido para o ambiente correspondente imediatamente, isso pode ser feito:
* Automaticamente (cobriremos isso nas partes 2 e 3)
* Parcialmente automático (igual ao automaticamente, exceto que um botão que autoriza a implantação deve ser pressionado)
* Manualmente
Todo o processo é assim:
1. O recurso é desenvolvido no branch de recursos.
2. O branch de recurso é revisado e mesclado no master branch.
3. Depois de um tempo (vários recursos mesclados), o master é mesclado com o preprod
4. Depois de um tempo (teste do usuário, etc.), o preprod é mesclado com o prod
5. Enquanto estávamos mesclando e testando, vários novos recursos foram desenvolvidos e mesclados no master, então vá para parte 3.
Veja como funciona:
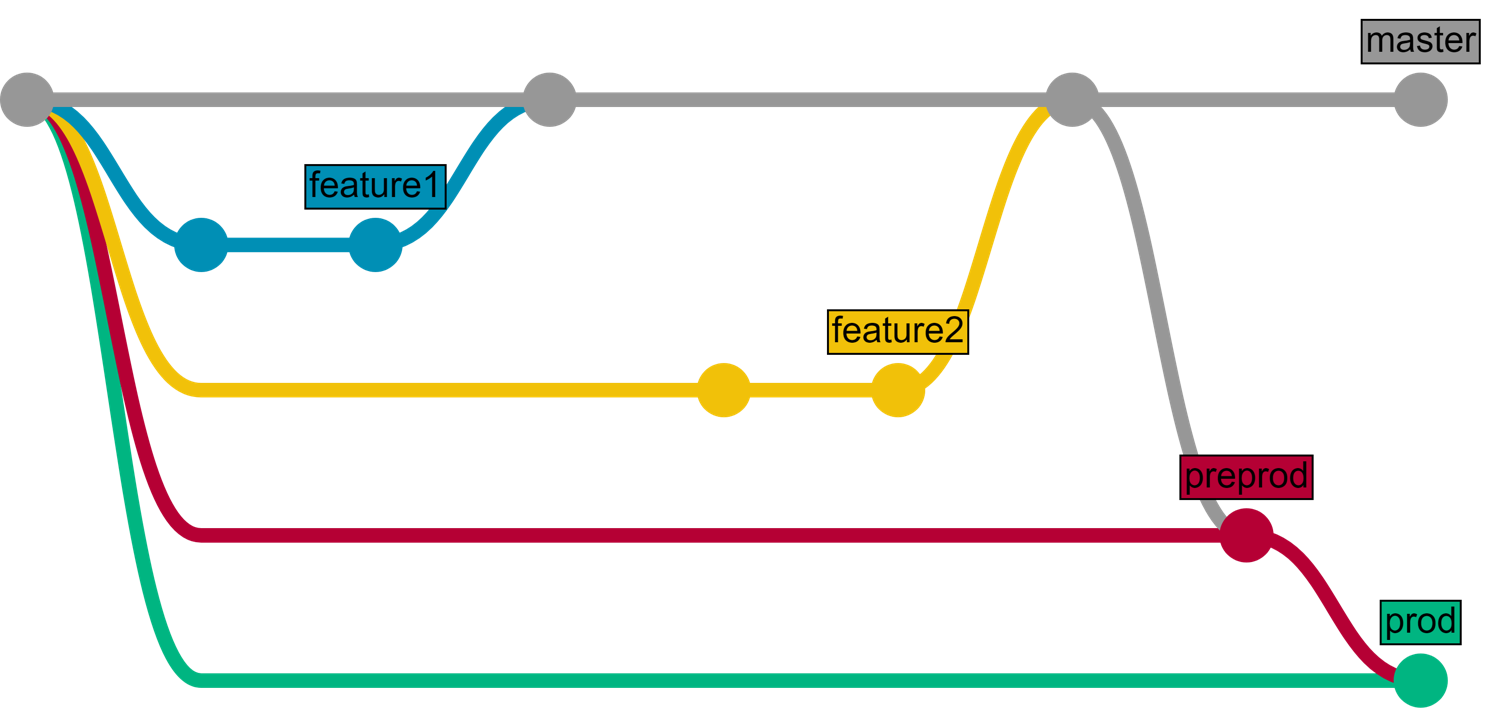
Você pode ler mais sobre o fluxo do GitLab [aqui](https://docs.gitlab.com/ce/workflow/gitlab_flow.html).
## Conclusão
* Git ****é um sistema de controle de versão distribuído não linear.
* O fluxo Git pode ser usado como uma diretriz para o ciclo de desenvolvimento de software; existem vários que você pode escolher.
## Links
* [Livro Git](git-scm.com/book/en/v2)
* [Fluxo do GitHub](help.github.com/articles/github-flow/)
* [Fluxo do GitLab](docs.gitlab.com/ce/workflow/gitlab_flow.html)
* [Fluxo Driessen](http://nvie.com/posts/a-successful-git-branching-model/) (fluxo mais abrangente, para comparação)
* [Código para este artigo](https://github.com/eduard93/GitGraph-samples)
## Questões para discussão
* Você usa um fluxo git? Qual?
* Quantos ambientes você tem para um projeto padrão?
## O que vem a seguir
Na próxima parte, iremos:
* Instalar o GitLab.
* Falar sobre alguns ajustes recomendados.
* Discutir o fluxo de trabalho do GitLab (não deve ser confundido com o fluxo do GitLab).
Fique ligado.
Anúncio
Jeff Fried · Mar. 29, 2021
Três novos conjuntos de versões de manutenção foram disponibilizados:
Caché 2018.1.5, Ensemble 2018.1.5 e HSAP 2018.1.5
InterSystems IRIS 2019.1.2, IRIS for Health 2019.1.2 e HealthShare Health Connect 2019.1.2
InterSystems IRIS 2020.1.1, IRIS for Health 2020.1.1 e HealthShare Health Connect 2020.1.1
Os kits para instalação e os contêineres podem ser baixados na página de Distribuição de Softwares do WRC.
Estas versões de manutenção contemplam várias atualizações distribuídas em um grande variedade de áreas. Para maiores informações a respeito das correções contidas nestes lançamentos, verifique a documentação para a versão em questão, onde podem ser encontrados as Notas do Lançamento, a Lista de Verificação da Atualização e uma Lista de Alterações do Lançamento, bem como a Referência de Classes e um conjunto completo de guias, referências, tutoriais e artigos. Toda a documentação está acessível através do site docs.intersystems.com.
Suporte para novas plataformas também foi adicionado a estes lançamentos. Em particular, foi adicionado suporte ao Ubuntu 20.04 LTS para todos os lançamentos, suporte para o IBM AIX 7.1 e ao 7.2 para Sistema p-64 foi adicionado para a versão 2019.1.2 (e já estava disponível para 2020.1), e suporte para Linux ARM64 foi adicionado à versão 2020.1.1. Para maiores detalhes verifique o documento Plataformas Suportadas de cada lançamento.
Os números que identificam os lançamentos podem ser encontrados na tabela abaixo:
Versão
Produto
Número Identificador do Lançamento
2018.1.5
Caché e Ensemble
2018.1.5.659.0
2018.1.5
Avaliação Caché
2018.1.5.659.0su
2018.1.5
HealthShare Health Connect (HSAP)
2018.1.5HS.9056.0
2019.1.2
InterSystems IRIS
2019.1.2.718.0
2019.1.2
IRIS for Health
2019.1.2.718.0
2019.1.2
HealthShare Health Connect
2019.1.2.718.0
2020.1.1
InterSystems IRIS
2020.1.1.408.0
2020.1.1
IRIS for Health
2020.1.1.408.0
2020.1.1
HealthShare Health Connect
2020.1.1.408.0
2020.1.1
InterSystems IRIS Community
2020.1.1.408.0
2020.1.1
IRIS for Health Community
2020.1.1.408.0
2020.1.1
IRIS Studio
2020.1.1.408.0
Anúncio
Angelo Bruno Braga · Dez. 29, 2021
Olá membros da Comunidade de Desenvolvedores,
Como podemos tornar nosso concurso de artigos técnicos ainda melhor? Queremos ouvir a opinião de todos vocês: tanto dos participantes quanto dos que não conseguiram participar .
Respondam por favor algumas questões e nos ajude a melhorar nosso concurso de artigos técnicos!
👉 Pesquisa de 1-min: Pesquisa do Concurso de Criação de Artigo Técnico InterSystems - Edição de Natal
Ou se preferir, deixe sua opinião nos comentários desta postagem!