Uso do KNIME com o IRIS
Olá,
Segundo a Wikipedia:
O KNIME é uma plataforma livre e de código aberto de análise de dados, construção de relatórios e integração de dados. O KNIME integra vários componentes para aprendizado de máquina e mineração de dados por meio de seu conceito de pipelining modular.
Uma interface gráfica de usuário e o uso de JDBC permitem a montagem de nós combinando diferentes fontes de dados, incluindo pré-processamento (ETL: Extract, transform, load), para modelagem, análise e visualização de dados sem necessidade (ou com necessidade mínima) de programação.
Podemos usar o KNIME com o IRIS através de uma conexão JDBC, e a partir daí consumir os dados das tabelas do IRIS.
Para o KNIME se conectar ao IRIS, precisamos seguir alguns poucos passos:
- Configuração do Driver JDBC do IRIS no KNIME;
- Configuração da conexão do KNIME ao IRIS;
- Consumo dos dados;
Vamos ver esses passos, que são bem simples de serem realizados.
Primeiro, baixe e instale o KNIME (https://www.knime.com/downloads). Uma vez instalado, execute-o e vá em Preferences->KNIME->Databases:
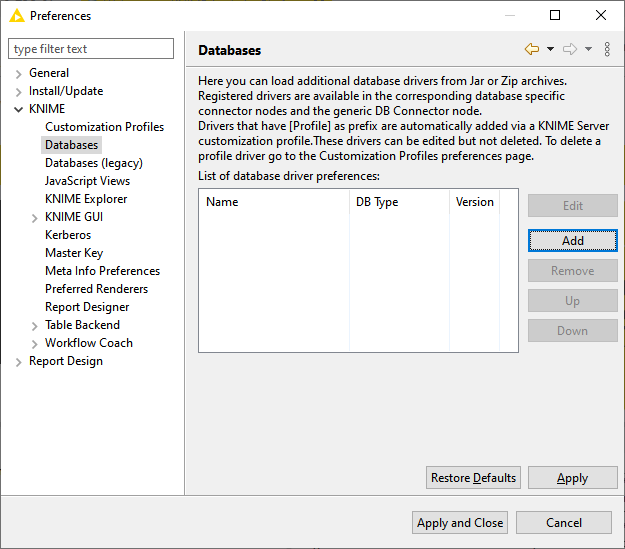
Fig 1. Tela do KNIME dos drivers JDBC reconhecidos
Clique em Add e preencha a tela com as informações de acesso ao driver JDBC do IRIS:
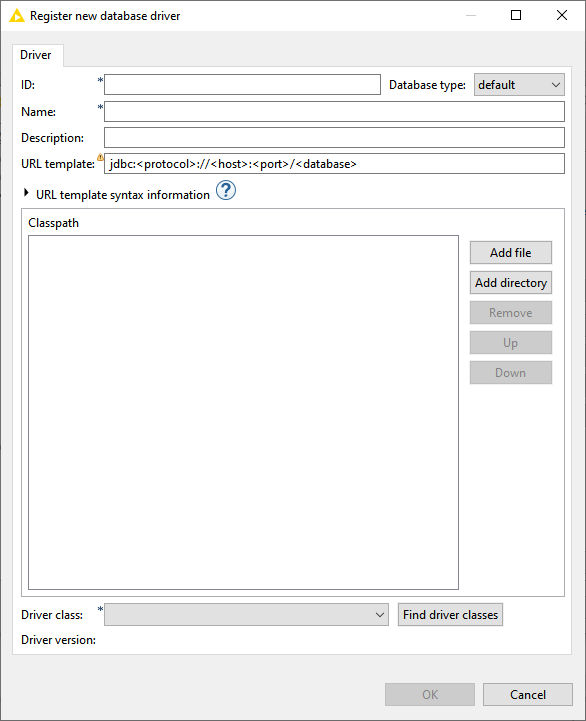
Fig 2. Tela de configuração do driver JDBC no KNIME
ID: Um identificador único no KNIME para o driver;
Database type: Tipo do banco de dados. Informe default;
Name e Description: Nome e descrição da conexão que está sendo criada;
URL template: URL de conexão ao IRIS via JDBC;
Classpath: Classe do JDBC do Iris – Ver na tela de configuração do KNIME abaixo;
Driver class: Classe do driver JDBC;
Preencha os dados conforme a tela abaixo (exemplo para o IRIS local no mesmo servidor que o KNIME);
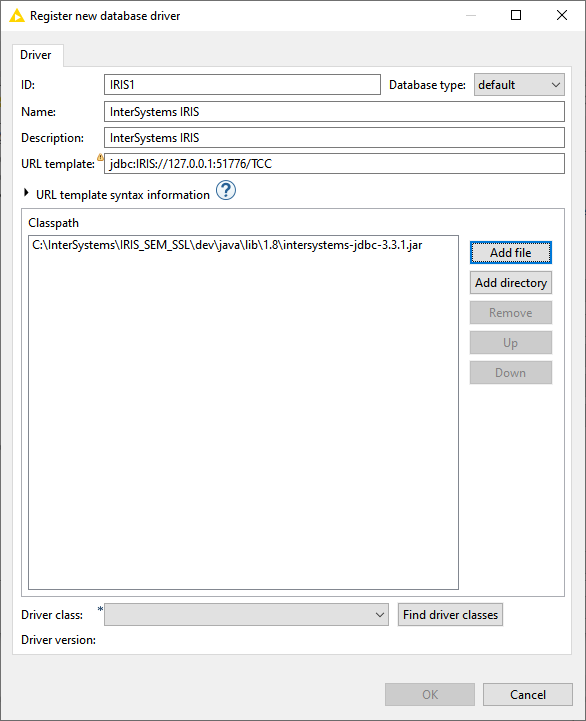
Fig 3. Tela com dados do driver JDBC do IRIS
Depois clique no botão “Find driver classes” para localizar a partir do arquivo jar do JDBC a classe associada:
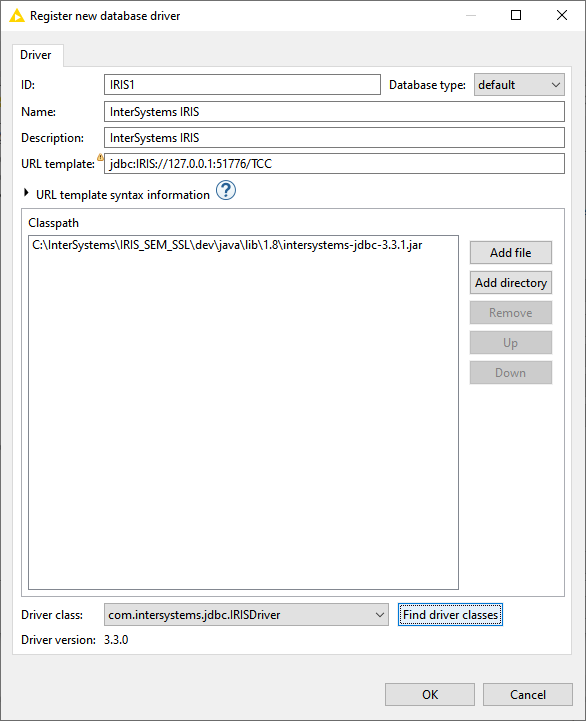
Fig. 4 – Driver Class localizado na configuração do KNIME
Clique em OK na tela dos dados e depois em Apply and Close na tela de Databases. Pronto. O KNIME já está configurado e conhecendo como acessar o IRIS. Agora vamos consumir os dados de uma tabela do IRIS. A URL que informamos aponta para o namespace TCC no servidor IRIS. Nele temos a tabela que iremos consumir:
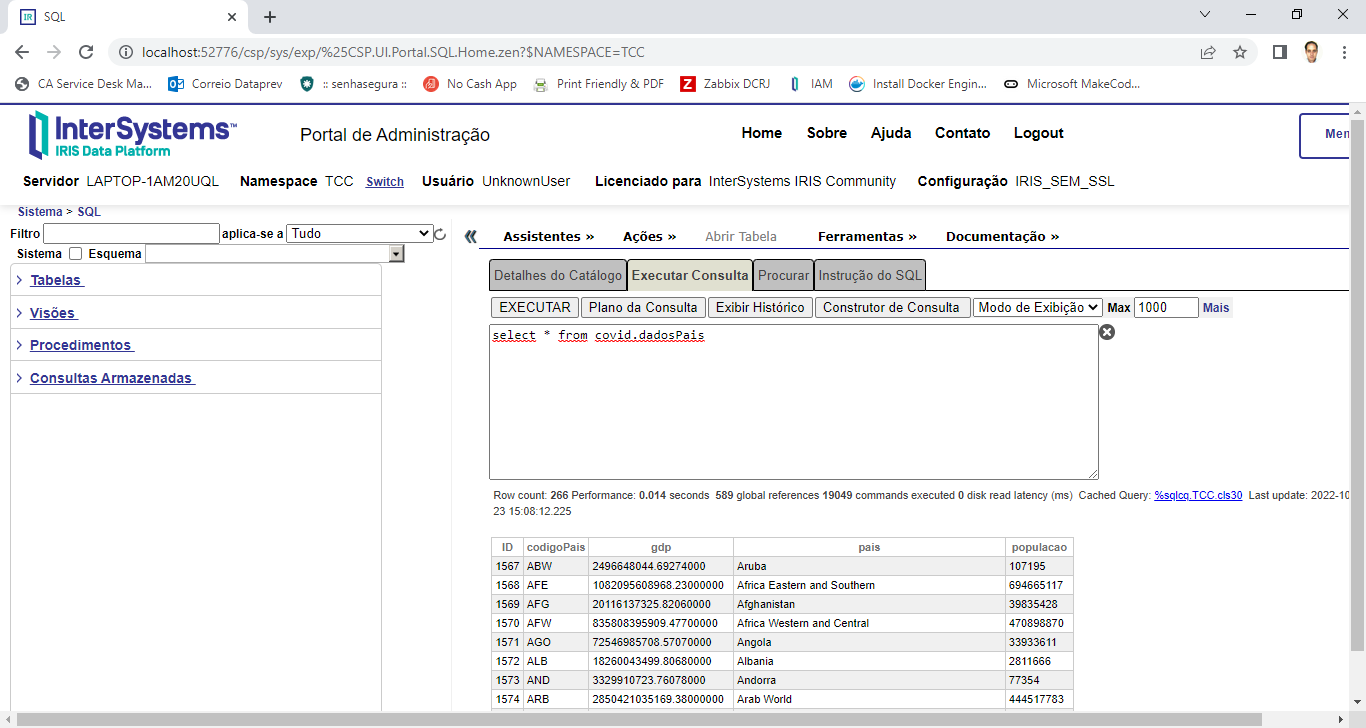
Fig. 5 – Tabela que iremos consumir do IRIS
Abra um novo Workflow em File->New->New KNIME Workflow:
Fig. 6 – Novo Workflow no KNIME
Clique em Next e Finish. Será apresentada a área onde os nodes do KNIME serão colocados e posteriormente configurados. Vamos começar colocando o node de conexão ao banco de dados. Clique na treeview da área de Node Repository em DB->Connection e arraste o node DB Connector para a área do workflow:
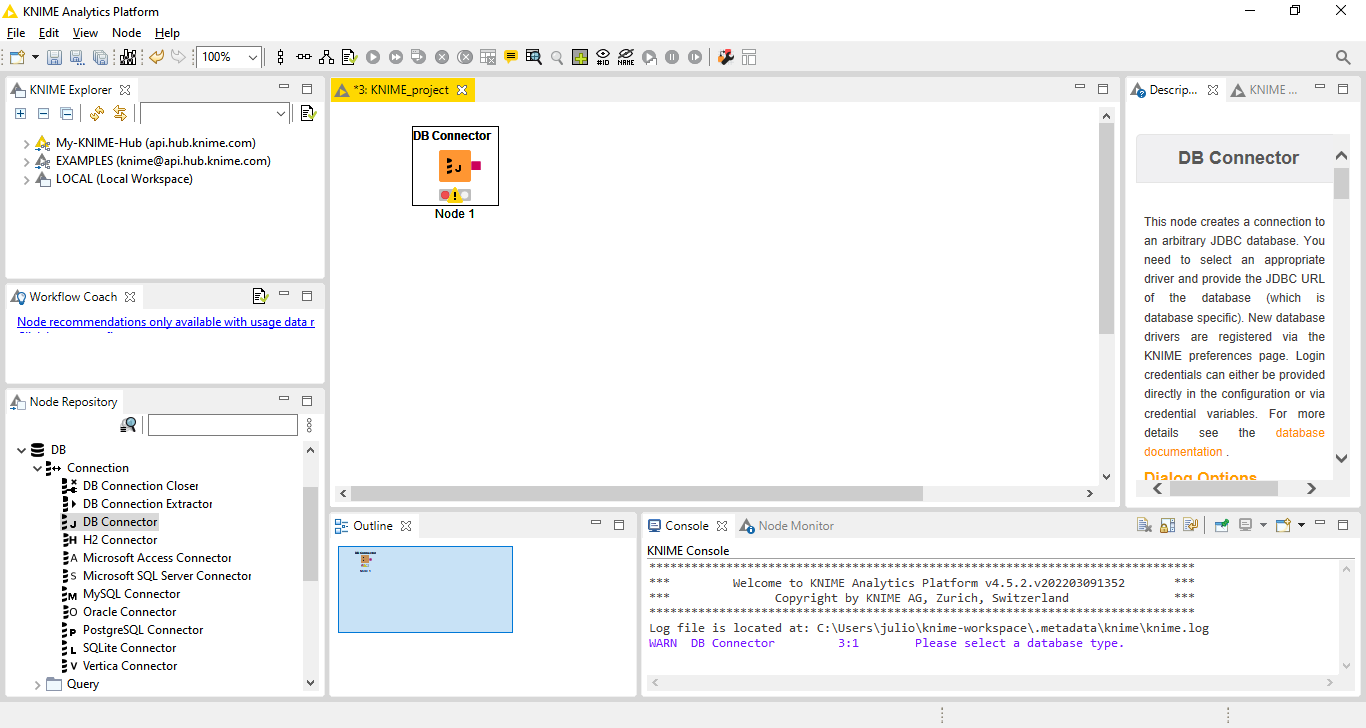
Fig. 7 – Workflow com o DB Connector
Clique sobre o DB Connector com o botão da direita e a seguir clique em Configure. Na tela apresentada selecione o Driver JDBC do IRIS que criamos anteriormente. Informe a autenticação Username & Password e informe o usuário e senha de acesso ao IRIS via JDBC. No nosso exemplo vamos utilizar o usuário _SYSTEM:
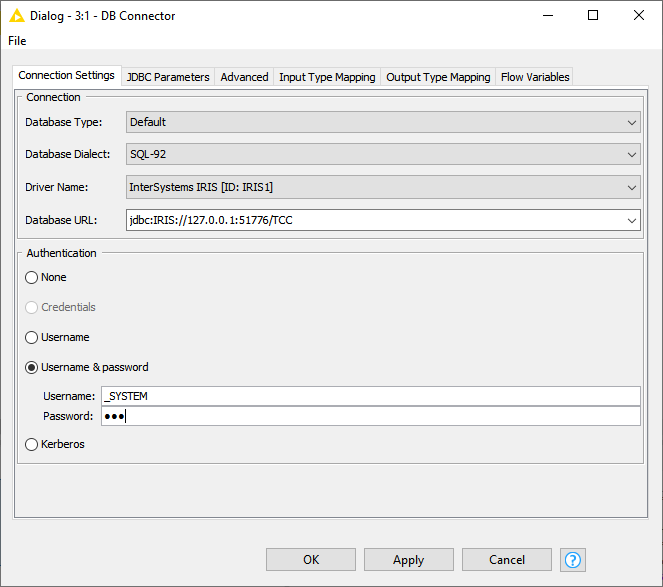
Fig. 8 – Configurando o DB Connector para acesso ao IRIS
Clique em Apply->OK ao término da configuração do DB Connector. Pronto, agora o nosso fluxo está apto a consumir dados do IRIS via JDBC. Clique novamente com o botão da direita sobre o DB Connector e a seguir clique em Execute. O KNIME vai conectar o nosso fluxo ao IRIS. Você verá que o sinal abaixo do node ficou verde informado que a conexão correu com sucesso.
Agora vamos consumir alguma informação do IRIS. Para isso vamos utilizar o node DB->Read/Write->DB Query Reader:
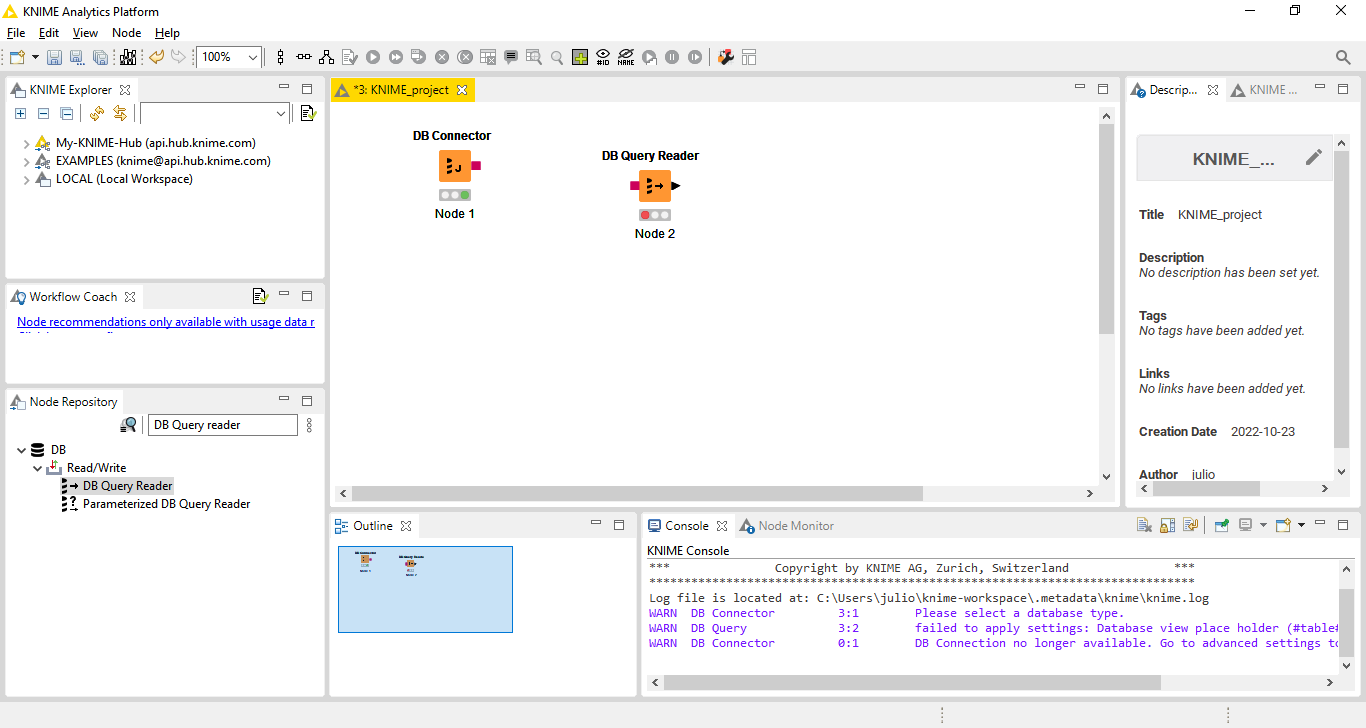
Fig. 9 – DB Query Reader no nosso fluxo
Após arrastar o node para o nosso fluxo vamos ligar o DB Connector a nosso novo node, informando que estes componentes formam um fluxo. Para isso clique na saída do DB Connector e arraste para a entrada do DB Query Reader. Uma conexão entre eles será criada:
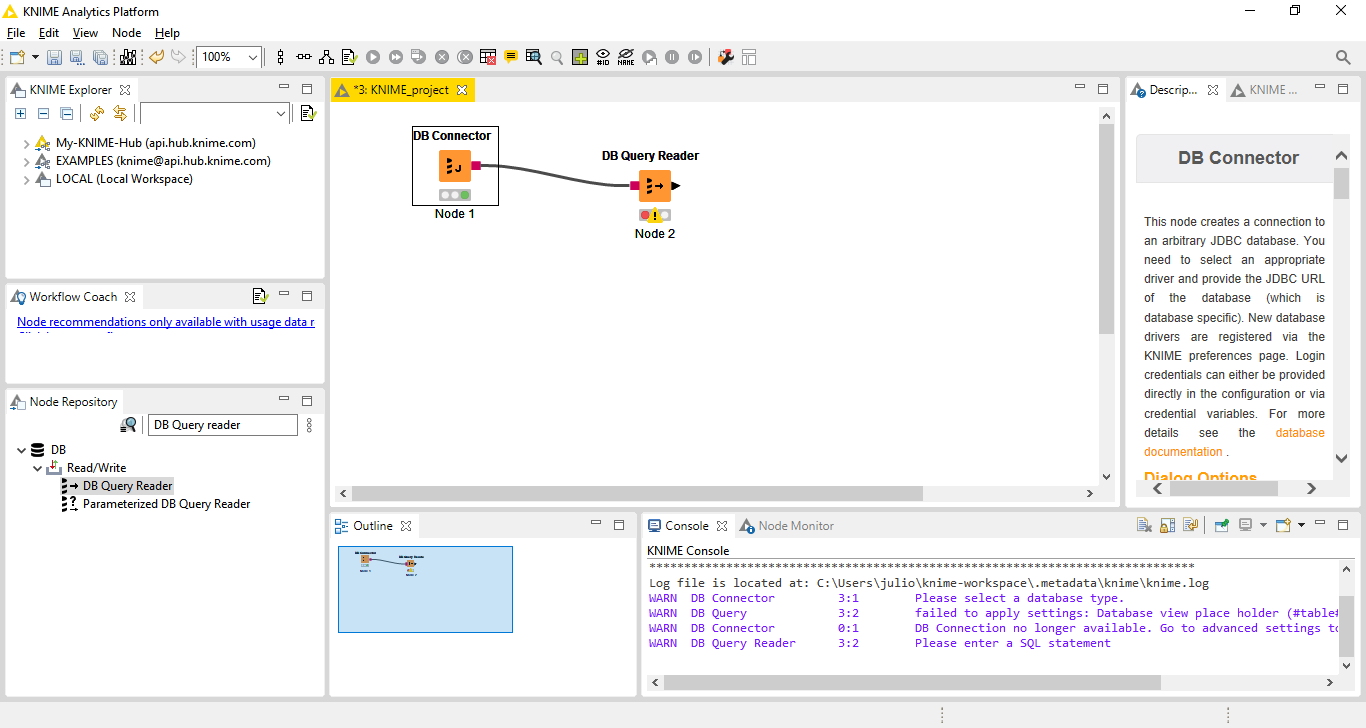
Fig. 10 – Nodes conectados
Agora vamos configurar o DB Query Reader para executar a query que desejamos. Para isso clique com o botão da direita sobre o node e a seguir em Configure. Uma tela será aberta para informar a query a ser executada:
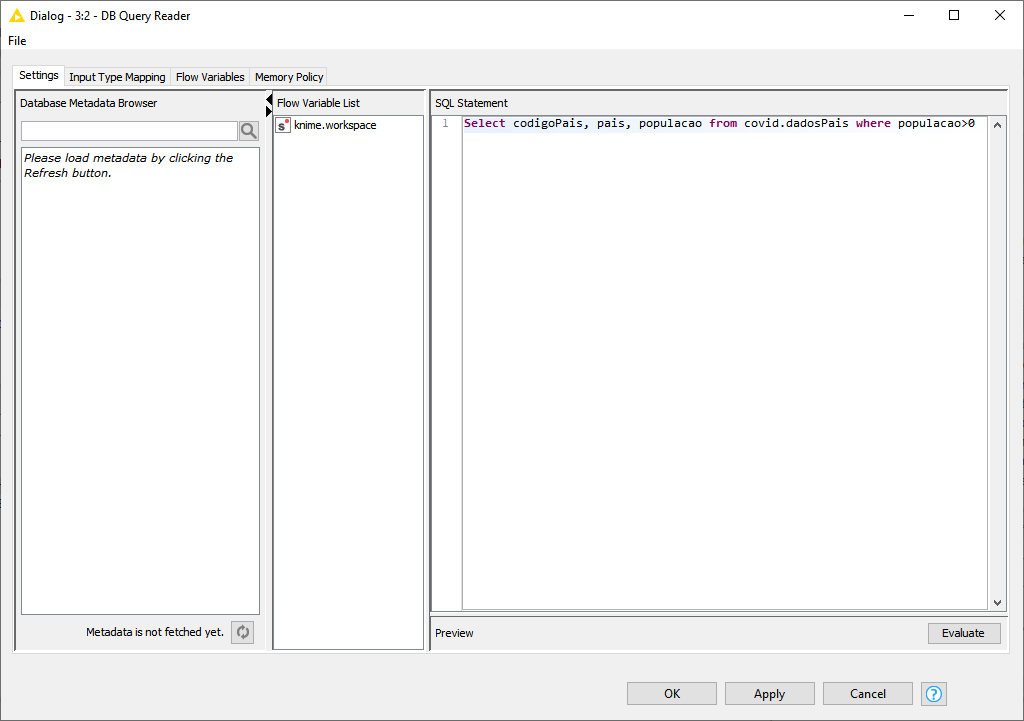
Fig. 11 – Codigo SQL que será executado pelo DB Query reader
Clique em Apply e OK para salvar nossa configuração. Pronto, o KNIME já pode ir no IRIS e recuperar informações de nossa tabela. Agora vamos salvar o que recuperamos em um arquivo texto, apenas para vermos o KNIME trabalhando. Para isso coloque o node CSV Writer para nosso fluxo. Ele fica no Node Repository em IO->Write->CSV Writer:
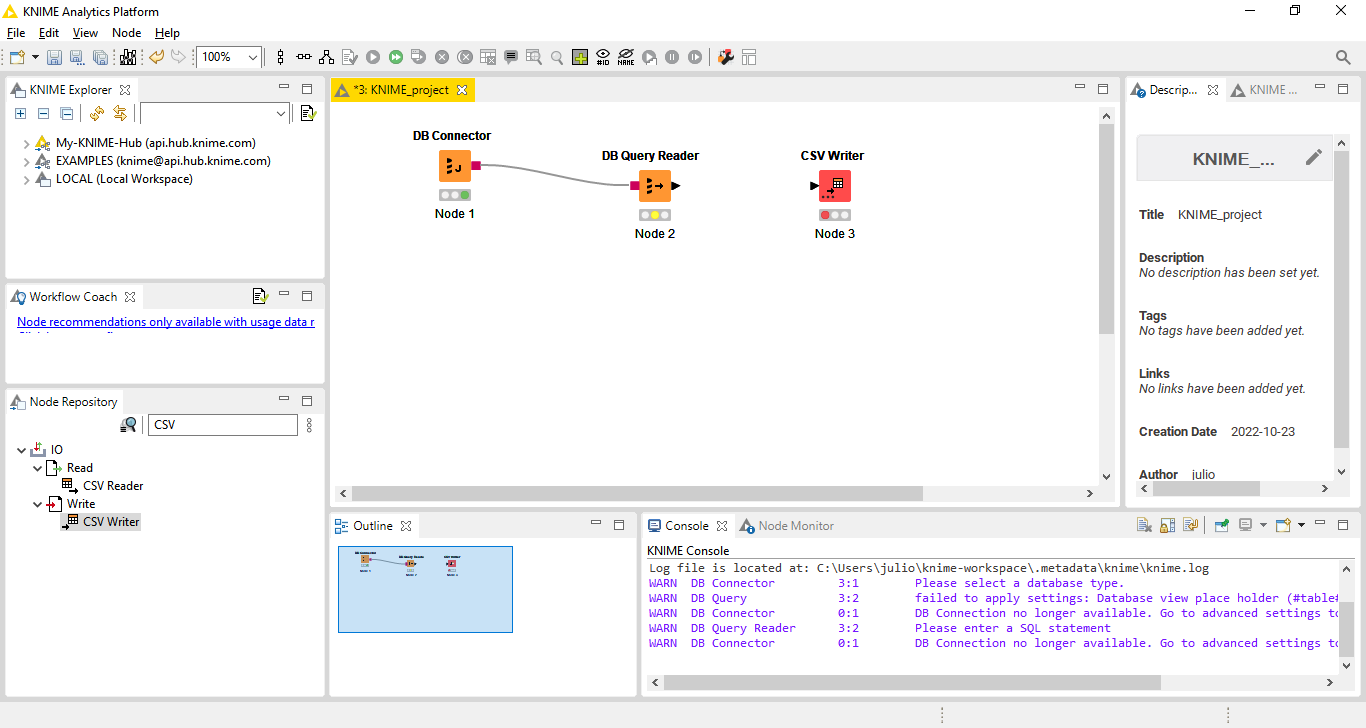
Fig. 12 – CSV Writer no nosso fluxo
Agora clicando com o botão da direita sobre o node do CSV Writer, clique em Configure e informe os dados solicitados. Aqui podemos informar o arquivo que será criado, o que fazer caso o arquivo exista, delimitadores e header do arquivo. Ao final clique em Apply->OK
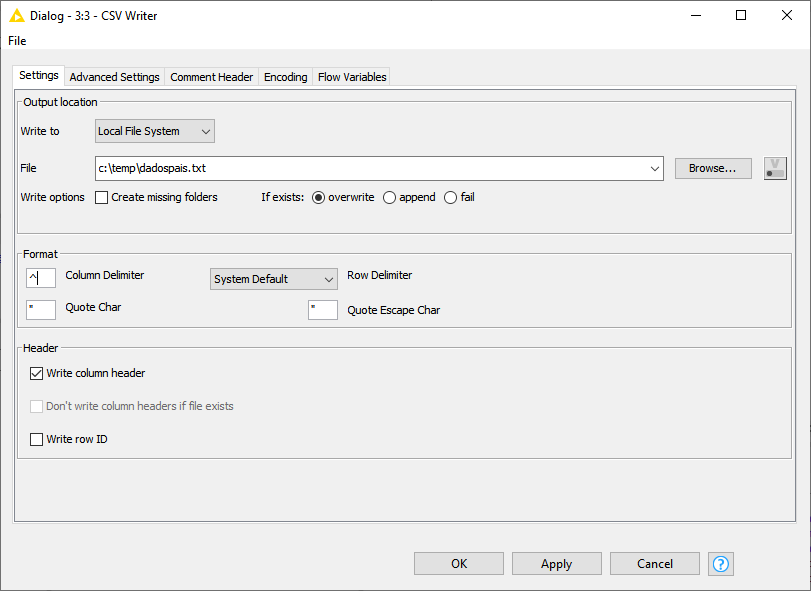
Fig. 13 – Tela de configuração do CSV Writer
Importante: Não esqueça de ligar a saída do DB Query Reader ao CSV Writer da mesma forma que fizemos com o DB Connector e o DB Query Reader (saída do node->arrastar para entrada do próximo node):
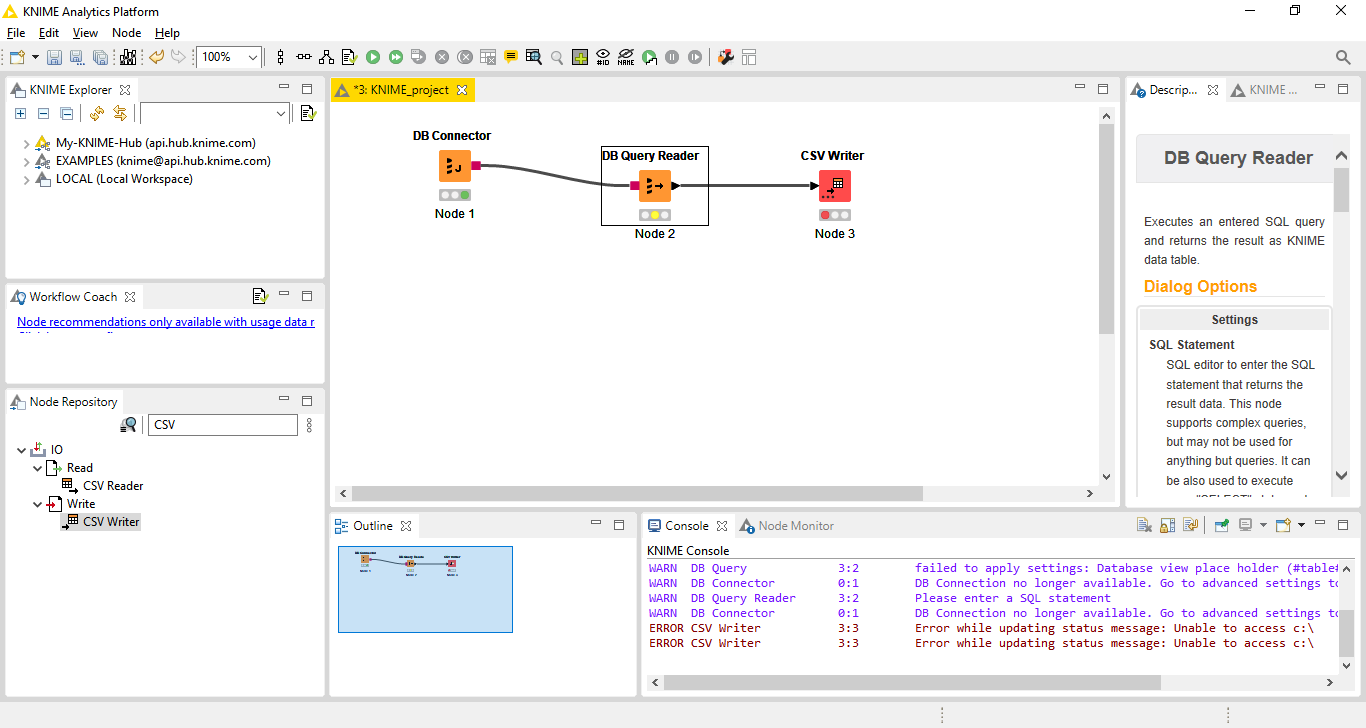
Fig. 14 – Todos os nodes conectados e configurados
Agora podemos executar nosso fluxo. Clique no botão de execução do fluxo e o arquivo será criado no diretório informado:

Fig. 15 – Execução do fluxo no KNIME
Agora navegando no nosso servidor, temos no diretório o arquivo criado com o resultado da query executada no IRIS
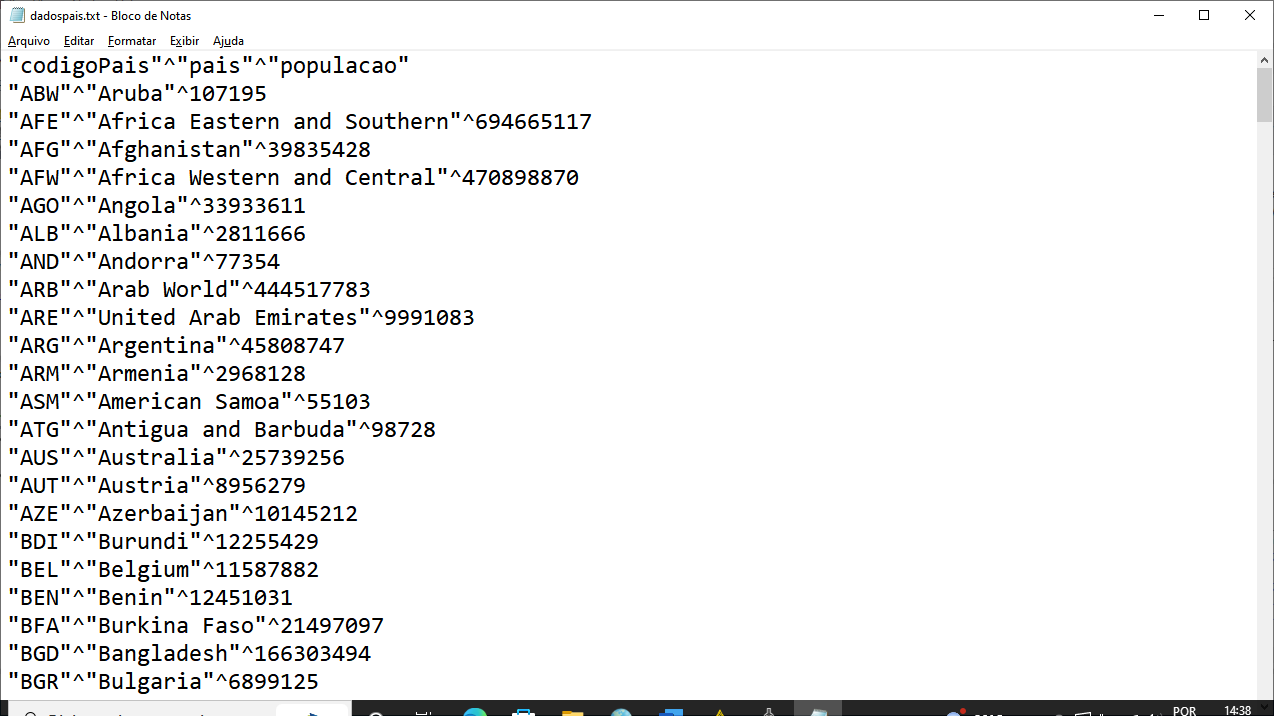
Fig. 16 – Arquivo com os dados retornados da Query executada
Podemos ir além, ligando outros nodes a saída da nossa query. Um exemplo é o node de Statistics. Vamos busca-lo no site do KNIME. Para isso abra seu navegador e na barra de endereços digite “KNIME Statistics node”. A primeira opção no Google é o Statistics – KNIME Hub. Abra a página e você terá acesso a este node:
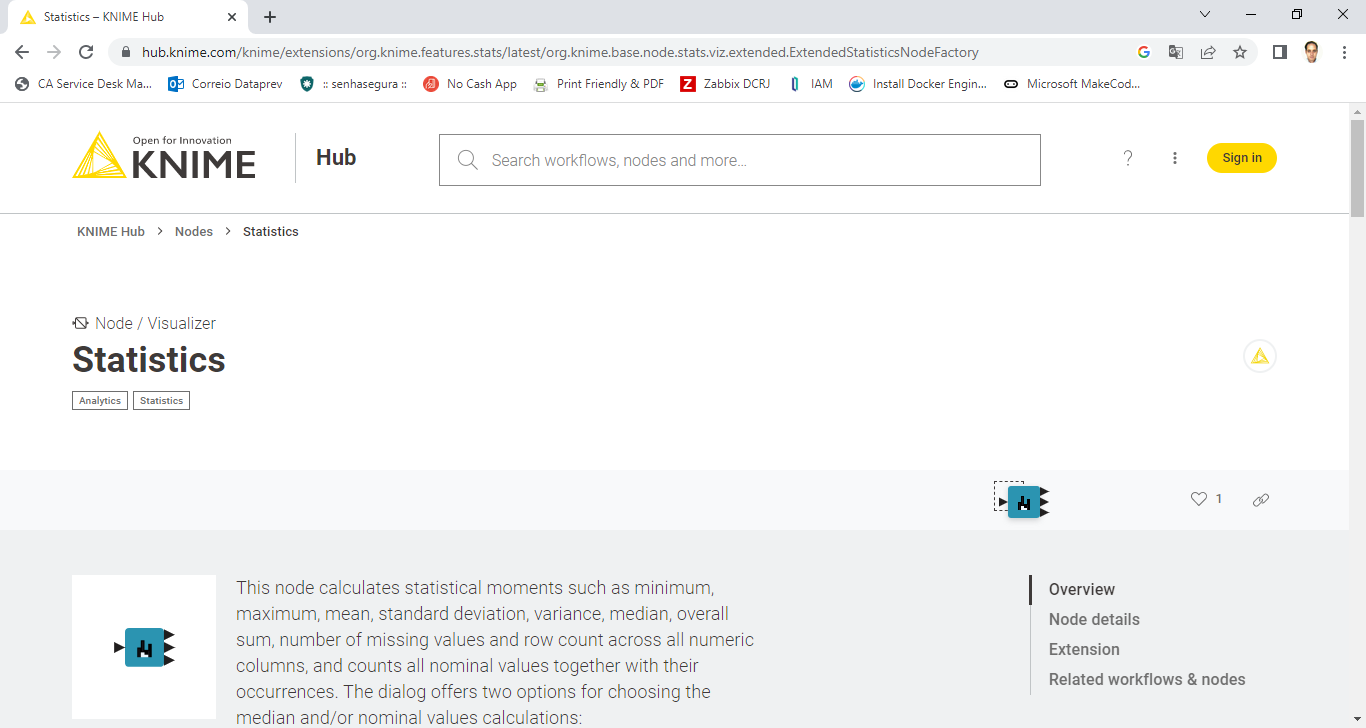
Fig. 17 – KNIME Statistics Node
Clique sobre a imagem do node e arraste para nosso fluxo. Ele será carregado no KNIME e incluído no nosso fluxo:
Fig. 18 – KNIME Statistics Node no nosso fluxo
Agora vamos ligar a saída do Query Reader ao node Statistics exatamente como fizemos com os anteriores: Clique na saída do node e arraste para a entrada do node seguinte:
Fig. 19 – Node Statistics ligado ao Fluxo
Pronto, agora temos o node Statistics também no nosso fluxo, utilizando o mesmo resultado que o nosso node CSV Writer. Clicando com o botão da direita no node Statistics, a seguir clique em Configure e vamos configurar o que queremos que aconteça:
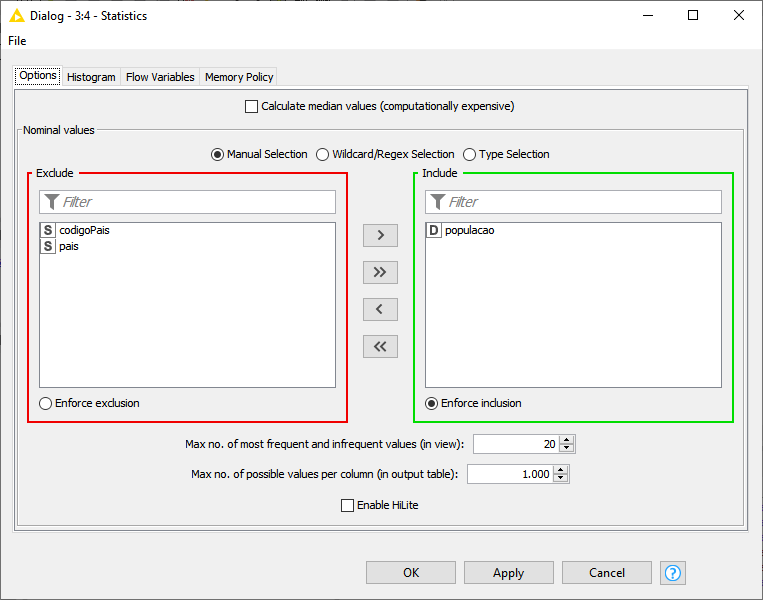
Fig. 20 – Tela de configuração do node Statistics
Vamos deixar na caixa Include apenas a coluna população. A seguir clique em Apply e OK. Clique no botão de execução do fluxo no KNIME e veja que o nosso node passou a ficar com o sinal verde. Clique com o botão da direita sobre ele e a seguir localize a opção Statistic Table no menu apresentado. Clique nesta opção e veja os dados do node baseado no que foi coletado de dados da query:

Fig. 21 – Dados do node Statistics
O KNIME tem diversos nodes para realizar uma série de tarefas. Podemos continuar a incluir novos nodes em nosso fluxo aproveitando os dados que já recolhemos. Podemos juntar dados de outras tabelas, visualizar as informações, exportar, importar dados e muito mais.
Podemos pegar dados de um sistema legado em IRIS, por exemplo, e fazer análises facilmente com o KNIME realizando o mapeamento das globais envolvidas, ou ainda em novos serviços já desenvolvidos utilizando classes, podemos agregar valor com uma simples conexão JDBC sem necessidade de nenhum tipo de refactoring dos dados, pois as classes do IRIS expõem as informações também como tabelas.
Com os recursos de Mirror podemos criar um servidor apartado com os dados para a geração de relatórios e estatísticas seja com KNIME, seja com outras ferramentas, de maneira rápida, segura e econômica.
Bons códigos.