Suporte a vetores, ou quase
Atualmente, há bastante conversa sobre o LLM, a IA etc. Os bancos de dados vetoriais fazem um pouco parte disso, e já há várias realizações diferentes para o suporte no mundo fora do IRIS.
Por que o vetor?
- Pesquisa de similaridade: os vetores permitem uma pesquisa de similaridade eficiente, como encontrar os itens ou documentos mais parecidos em um banco de dados. Bancos de dados relacionais tradicionais são projetados para pesquisas de correspondência exata, que não são adequadas para tarefas como pesquisa de similaridade em imagens ou texto.
- Flexibilidade: as representações vetoriais são versáteis e podem ser derivadas de vários tipos de dados, como texto (por embeddings, como Word2Vec e BERT), imagens (por modelos de aprendizado profundo) e muito mais.
- Pesquisas entre modalidades: os vetores permitem a pesquisa em várias modalidades de dados diferentes. Por exemplo, a partir da representação vetorial de uma imagem, é possível pesquisar imagens semelhantes ou textos relacionados em um banco de dados multimodal.
E vários outros motivos.
Então, para este concurso de python, decidi tentar implementar esse suporte. Infelizmente, não conseguir terminar a tempo, e explicarei abaixo porquê.
 Algumas coisas importantes precisam ser feitas para que fique completo
Algumas coisas importantes precisam ser feitas para que fique completo
- Aceitar e armazenar os dados vetorizados, com SQL, exemplo simples, (a quantidade de dimensões nesse exemplo é 3, sendo fixa por campo, e todos os vetores no campo precisam ter dimensões exatas)
create table items(embedding vector(3)); insert into items (embedding) values ('[1,2,3]'); insert into items (embedding) values ('[4,5,6]'); - Funções de similaridade, há diferentes algoritmos de similaridade, adequados para uma pesquisa simples em uma pequena quantidade de dados, sem usar índices
-- Euclidean distance select embedding, vector.l2_distance(embedding, '[9,8,7]') distance from items order by distance; -- Cosine similarity select embedding, vector.cosine_distance(embedding, '[9,8,7]') distance from items order by distance; -- Inner product select embedding, -vector.inner_product(embedding, '[9,8,7]') distance from items order by distance; - Índice personalizado, que ajuda com uma pesquisa mais rápida em uma grande quantidade de dados, os índices podem usar um algoritmo diferente e usar funções de distância diferentes das acimas, e algumas outras opções
- HNSW
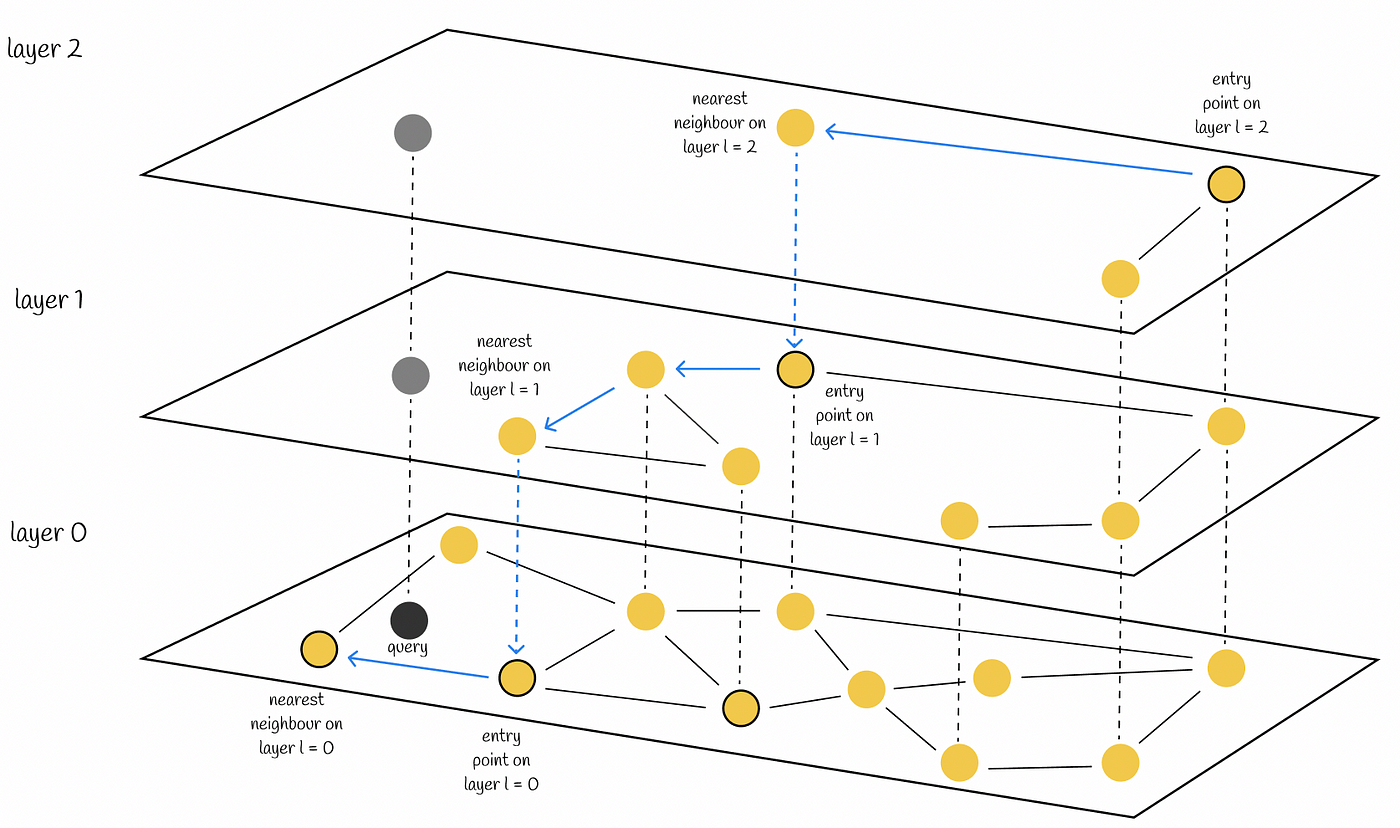
- Listas invertidas
.png)
- HNSW
- A pesquisa só usará as listas criadas, e seu algoritmo encontrará as informações solicitadas.
Insira vetores
O vetor deve ser um array de valores numéricos, que podem ser inteiros ou floats, bem como assinados ou não. No IRIS, podemos armazená-lo simplesmente como $listbuild, ele tem uma boa representação, já é compatível, só é preciso implementar a conversão de ODBC para lógica.
Em seguida, os valores podem ser inseridos como texto simples usando drivers externos, como ODBC/JDBC ou somente dentro do IRIS com ObjectScript
- SQL simples
insert into items (embedding) values ('[1,2,3]'); - Do ObjectScript
set rs = ##class(%SQL.Statement).%ExecDirect(, "insert into test.items (embedding) values ('[1,2,3]')")set rs = ##class(%SQL.Statement).%ExecDirect(, "insert into test.items (embedding) values (?)", $listbuild(2,3,4))
- Ou Embedded SQL
&sql(insert into test.items (embedding) values ('[1,2,3]'))set val = $listbuild(2,3,4) &sql(insert into test.items (embedding) values (:val))
Sempre será armazenado como $lb() e retornado em formato textual em ODBC
Em seguida, descobri que o JDBC usa Inserções Rápidas por padrão. Nesse caso, ele armazena os dados inseridos diretamente nos globais, então precisei desativá-lo manualmente
No DBeaver, selecione optfastSelect no campo FeatureOption
.png)
Cálculos
Os vetores são especialmente necessários para o suporte ao cálculo da distância entre dois vetores
Para o concurso, eu precisava usar o Embedded Python, e este é o problema: como operar com $lb no Embedded Python. Há um método ToList em %SYS.Class, mas ele não é integrado ao pacote Python do iris e precisa ser chamado com ObjectScript
ClassMethod l2DistancePy(v1 As dc.vector.type, v2 As dc.vector.type) As %Decimal(SCALE=10) [ Language = python, SqlName = l2_distance_py, SqlProc ]
{
import iris
import math
vector_type = iris.cls('dc.vector.type')
v1 = iris.cls('%SYS.Python').ToList(vector_type.Normalize(v1))
v2 = iris.cls('%SYS.Python').ToList(vector_type.Normalize(v2))
return math.sqrt(sum([(val1 - val2) ** 2 for val1, val2 in zip(v1, v2)]))
}
Não parece nada certo. Eu preferiria se $lb pudesse ser interpretado on the fly como lista no python ou nas funções builtin de lista to_list e from_list
Outro problema é quando tento testar essa função de diferentes maneiras. Usando o SQL do Embedded Python que utiliza a Função SQL escrita no Embedded Python, ele falha. Então, também precisei adicionar as funções do ObjectScript.
ModuleNotFoundError: No module named 'dc' SQL Function VECTOR.NORM_PY failed with error: SQLCODE=-400,%msg=ERROR #5002: ObjectScript error: <OBJECT DISPATCH>%0AmBm3l0tudf^%sqlcq.USER.cls37.1 *python object not found
Funções implementadas no momento para calcular a distância, em Python e ObjectScript
- Distância euclidiana
[SQL]_system@localhost:USER> select embedding, vector.l2_distance_py(embedding, '[9,8,7]') distance from items order by distance; +-----------+----------------------+ | embedding | distance | +-----------+----------------------+ | [4,5,6] | 5.91607978309961613 | | [1,2,3] | 10.77032961426900748 | +-----------+----------------------+ 2 rows in set Time: 0.011s [SQL]_system@localhost:USER> select embedding, vector.l2_distance(embedding, '[9,8,7]') distance from items order by distance; +-----------+----------------------+ | embedding | distance | +-----------+----------------------+ | [4,5,6] | 5.916079783099616045 | | [1,2,3] | 10.77032961426900807 | +-----------+----------------------+ 2 rows in set Time: 0.012s - Similaridade por cosseno
[SQL]_system@localhost:USER> select embedding, vector.cosine_distance(embedding, '[9,8,7]') distance from items order by distance; +-----------+---------------------+ | embedding | distance | +-----------+---------------------+ | [4,5,6] | .034536677566264152 | | [1,2,3] | .11734101007866331 | +-----------+---------------------+ 2 rows in set Time: 0.034s [SQL]_system@localhost:USER> select embedding, vector.cosine_distance_py(embedding, '[9,8,7]') distance from items order by distance; +-----------+-----------------------+ | embedding | distance | +-----------+-----------------------+ | [4,5,6] | .03453667756626421781 | | [1,2,3] | .1173410100786632659 | +-----------+-----------------------+ 2 rows in set Time: 0.025s - Produto interno
[SQL]_system@localhost:USER> select embedding, vector.inner_product_py(embedding, '[9,8,7]') distance from items order by distance; +-----------+----------+ | embedding | distance | +-----------+----------+ | [1,2,3] | 46 | | [4,5,6] | 118 | +-----------+----------+ 2 rows in set Time: 0.035s [SQL]_system@localhost:USER> select embedding, vector.inner_product(embedding, '[9,8,7]') distance from items order by distance; +-----------+----------+ | embedding | distance | +-----------+----------+ | [1,2,3] | 46 | | [4,5,6] | 118 | +-----------+----------+ 2 rows in set Time: 0.032s
Além disso, as funções matemáticas implementadas, ad, sub, div e mult. que a InterSystems aceita criam as próprias funções agregadas. Assim, seria possível somar todos os vetores ou encontrar a média. Mas, infelizmente, a InterSystems não oferece suporte ao uso do mesmo nome e precisa de um nome exclusivo (e esquema) para funcionar. No entanto, o resultado não numérico da função agregada não é compatível
Função vector_add simples, que retorna a soma de dois vetores
.png)
Quando usada como uma agregação, ela mostra 0, e o vetor esperado também
.png)
Crie um índice
Não consegui concluir essa parte devido a alguns obstáculos que tive durante a realização.
- A ausência de um $lb builtin para as conversões de listas em python e de volta quando o vetor no IRIS está armazenado em $lb, e toda a lógica da criação do índice deve estar em Python, é importante obter os dados de $lb e também definir de volta para os globais
- Falta de suporte a globais
- $Order no IRIS oferece suporte à direção, então pode ser usado em sentido inverso, enquanto a realização da ordem no Python Embedded não tem isso, então será necessário ler todas as chaves e revertê-las ou armazenar a ponta em algum lugar
- Tenho dúvidas devido à experiência ruim com as funções SQL do Python, chamadas a partir do Python, mencionadas acima
- Durante a criação do índice, esperava armazenar as distâncias no gráfico entre vetores, mas enfrentei um bug ao armazenar números float no global
Abri 11 issues com o Embedded Python que encontrei durante o trabalho, então a maior parte do tempo procurei alternativas para solucionar problemas. Com a ajuda do projeto iris-dollar-listde @Guillaume Rongier, consegui resolver alguns problemas.
Instalação
De qualquer maneira, ainda está disponível e pode ser instalado com IPM, até mesmo usado com funcionalidade limitada
zpm "install vector"Ou no modo de desenvolvimento com o docker-compose
git clone https://github.com/caretdev/iris-vector.git
cd iris-vector
docker-compose up -d