O teorema PACELC e o InterSystems IRIS
O teorema PACELC foi criado por Daniel Abadi (Universidade de Maryland, College Park) em 2010 como uma extensão do teorema CAP (criado por Eric Brewer - Consistência, Disponibilidade e Tolerância a Partições). Ambos auxiliam no projeto da arquitetura mais adequada para o funcionamento de plataformas de dados em ambientes distribuídos, considerando os aspectos de consistência versus disponibilidade. A diferença reside no fato de que o PACELC também permite a análise da melhor opção para ambientes não distribuídos, tornando-se o padrão ouro para a consideração de todos os cenários possíveis na definição da topologia e arquitetura de implantação.
O teorema CAP afirma que, em sistemas distribuídos, não é possível ter consistência, disponibilidade e tolerância a partições simultaneamente, exigindo a escolha de duas entre as três, conforme o diagrama a seguir.
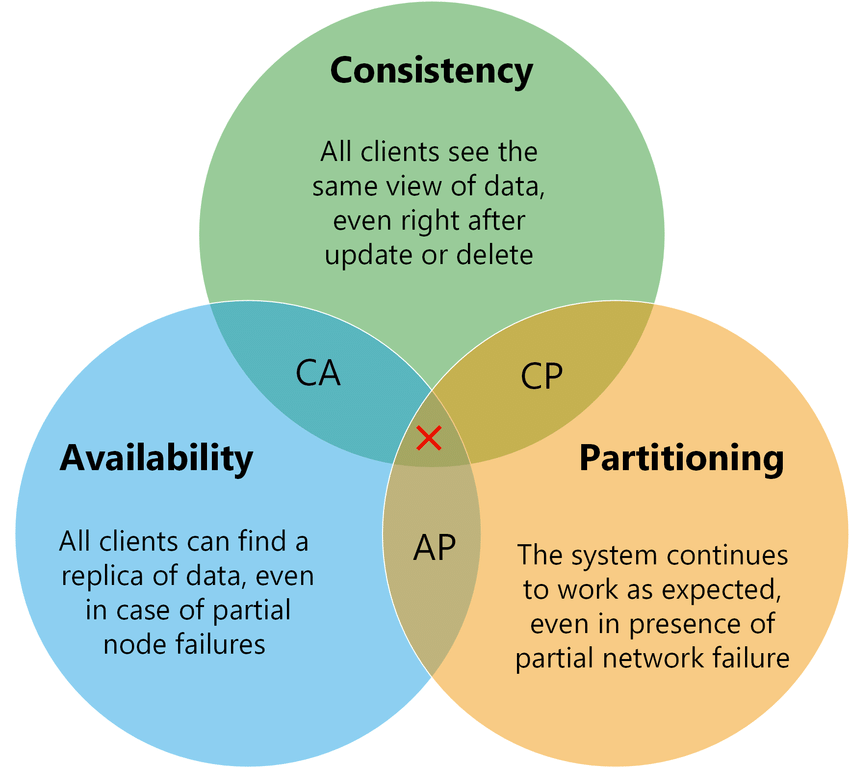
Fonte: https://medium.com/nerd-for-tech/understand-cap-theorem-751f0672890e
O PACELC, sendo uma extensão, confirma o CAP, mas adiciona o cenário não particionado (E - Else):
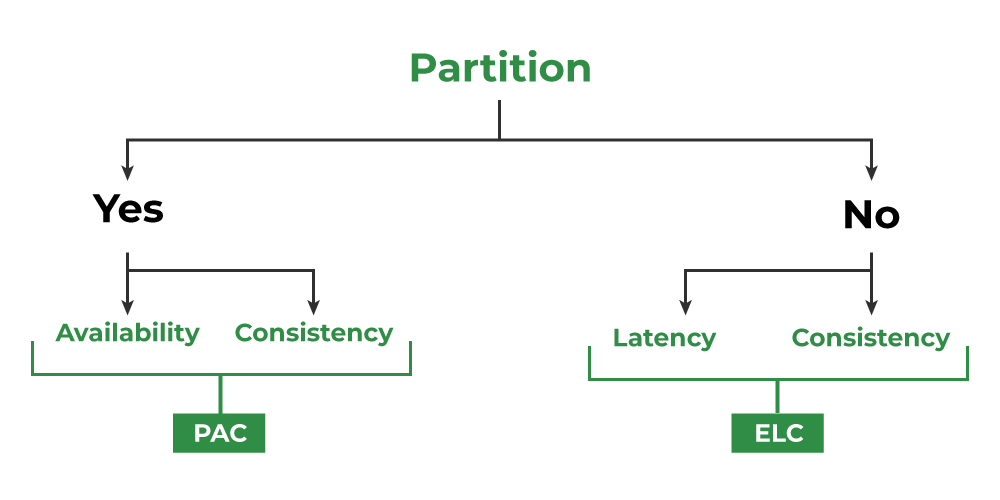
Source: https://www.geeksforgeeks.org/operating-systems/pacelc-theorem/
Componentes do InterSystems IRIS em suporte ao PACELC
O diagrama a seguir ilustra como os componentes da arquitetura InterSystems IRIS podem atender plenamente a qualquer uma das características do PACELC:
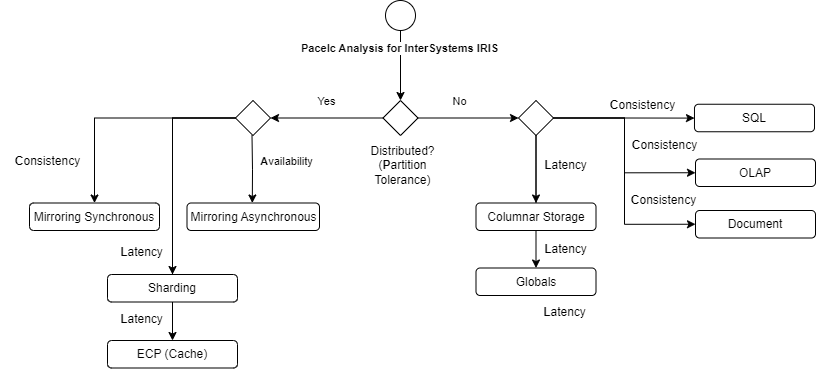
|
Classificação PACELC |
Arquitetura do IRIS |
Análise |
|
PC / EC |
Espelhamento (Mirroring) síncrono com SQL ou Documentos (Document DB) para transações e OLAP para análises. |
Grande consistência e latência média |
|
PC / EL |
Mirroring assíncrono com Globais para transacional e Columnar storage para latência |
Consistência média e ótima latência |
|
PL / EL |
Mirroring com ECP Sharding para grandes volumes de dados |
Boa consistência e boa latência (estratégia híbrida) |
Quando usar os recursos do IRIS resources para melhorar latência e disponibilidade
Alguns recursos no IRIS são usados para propósitos bem conhecidos:
- Mirror síncrono:
- Alta disponibilidade com consistência.
- Processamento distribuído com latência regular.
- Mirror assíncrono:
- Disaster recovery.
- Instância isolada para analítico e relatórios.
- Processamento distribuído com boa latência.
- ECP - Enterprise Cache processing:
- Processamento distribuído com boa latência.
- Alta disponibilidade com boa latência.
- Sharding:
- Processamento distribuído de dados para grandes volumes com boa latência.
- Boa latência para big data.
- Columnar Storage:
- Boa latência para dados desnormalizados.
- Boa latência para analítico, data lake e cenário de relatórios.
Estratégias de Tuning para melhorar latência
Além dos componentes arquitetônicos que melhoram significativamente a latência, mesmo em cenários de processamento distribuído, é possível aplicar diversas configurações de tuning:
- Otimização de memória (Shared Memory & Buffers)
- Buffers de Banco de Dados (Buffers Globais): Você deve alocar memória suficiente para manter os dados "quentes" (variáveis globais acessadas com frequência) na RAM.Em sistemas de 64 bits, esse valor deve ser o maior possível para evitar que o sistema acesse o disco.
- Buffers de Rotinas: Se o seu aplicativo executa rotinas ObjectScript ou rotinas legadas com grande volume de dados, aumente o cache de rotinas para evitar a sobrecarga de carregamento e compilação do código em tempo de execução.
- Huge pages (Linux): Sempre configure huge pages no nível do sistema operacional.Isso reduz a sobrecarga do kernel no gerenciamento de tabelas de páginas para grandes alocações de memória.
- Tuning de I/O (disco):
- Separação de Discos. Para obter melhores resultados:
- Use discos físicos separados (ou LUNs) para:
- WIJ (Write Image Journal): Requer alta taxa de transferência de dados em rajadas.
- Journal: Requerem gravações sequenciais de baixa latência.
- Bancos de Dados: Onde residem os arquivos .dat.
- Use discos físicos separados (ou LUNs) para:
- Arquitetura Global: O IRIS armazena dados em estruturas B-Tree. Globals grandes e com crescimento desordenado podem ficar fragmentados. Use o utilitário ^GBLOCKCOPY para compactar os globals e melhorar a localidade dos dados.
- Garanta o uso de discos SSD ou NVMe de alta velocidade.
- Otimize a alocação de blocos e o striping para volumes de banco de dados.
- Monitore e ajuste os parâmetros de alocação de cache de disco.
- Separação de Discos. Para obter melhores resultados:
- Configurações de Database Cache:
- Aumente o tamanho do cache principal para manter mais dados e índices na memória, reduzindo a necessidade de operações de E/S em disco.
- Monitore as taxas de acerto do cache e ajuste o tamanho dinamicamente, se necessário.
- Otimização de Query:
- Tuning de tabela: Execute regularmente o comando GATHER_TABLE_STATS (via Portal de Gerenciamento ou SQL). O otimizador de consultas do IRIS utiliza essas estatísticas para escolher entre uma varredura completa da tabela e um índice.
- Revise e reescreva consultas SQL lentas, garantindo que elas utilizem índices de forma eficiente.
- Use o Visualizador de Plano de Consulta do IRIS para identificar gargalos e forçar planos de execução ideais.
- Uso eficiente de índices:
- Crie índices compostos que correspondam às cláusulas WHERE e ORDER BY.
- Evite o uso excessivo de índices, que pode prejudicar o desempenho de gravação (inserção/atualização).
- Tuning de rede:
- Garanta uma rede de baixa latência e alta largura de banda, especialmente para conexões ECP e Sharding.
- Otimize os parâmetros TCP/IP do sistema operacional para o tráfego IRIS.
- Otimização de transações:
- Mantenha as transações curtas para liberar bloqueios mais rapidamente e aumentar a concorrência.
- Ajuste a frequência dos pontos de verificação do banco de dados para equilibrar a consistência e o desempenho de E/S.
- Sincronização de Thread e processos:
- Ajuste os parâmetros relacionados a tarefas e threads do IRIS para otimizar o paralelismo de acordo com o hardware do servidor.
- Tuning de Interoperabilidade (Productions):
- Para sistemas que atuam como um ESB (Enterprise Service Bus):
- Níveis de Log de Eventos: Em um ambiente de produção, evite o registro de eventos em nível "Debug". A gravação excessiva nos bancos de dados de gerenciamento (IRISSYS ou ENSLIB) pode degradar significativamente o desempenho do fluxo principal de mensagens.
- Tamanho do Pool: Ajuste o tamanho do pool de seus adaptadores. Se o pool for muito pequeno, as mensagens serão enfileiradas; se for muito grande, você poderá causar contenção de recursos ou sobrecarregar o sistema externo.
- Processamento Assíncrono: Use chamadas assíncronas em processos de negócios sempre que possível para evitar o bloqueio da execução enquanto aguarda sistemas externos lentos.
- Resumo dos parâmetros do iris.cpf para melhor latência:
|
Seção do CPF |
Parâmetro |
Valor sugerido (para o exemplo de 32GB RAM) |
Objetivo |
|
[config] |
globals |
16384 (16GB in 8K buffers) |
Reduzir IO |
|
[config] |
routines |
1024 (1GB) |
Acelere a execução do código |
|
[config] |
gmheap |
524288 (512MB) |
Estabilidade nas Productions |
|
[config] |
locksiz |
67108864 (64MB) |
Suporte a alta concorrência |
|
[config] |
wijsize |
1024 (1GB) |
Melhorar o desempenho de gravação |
Referências de documentação e de artigos
- High Availability Guide: https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GHA
- Scalability Guide: https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GSCALE
- Data integrity Guide: https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GCDI
- InterSystems IRIS Example Reference Architectures for Amazon Web Services (AWS): https://community.intersystems.com/post/intersystems-iris-example-reference-architectures-amazon-web-services-aws#:~:text=Large%20Production%20Configuration,massive%20horizontal%20scaling%20of%20users.
- InterSystems Data Platforms Capacity Planning and Performance Series Index: https://community.intersystems.com/post/intersystems-data-platforms-capacity-planning-and-performance-series-index
- Artigos do Robert Cemper: https://community.intersystems.com/user/69016/posts?filter=articles