Exemplo de análise de planejamento de capacidade da AWS
Com frequência, me pedem para avaliar dados de desempenho relacionados a aplicativos IRIS de clientes para entender se os recursos do sistema são sub ou superprovisionados.
Este exemplo recente é interessante, porque envolve um aplicativo que fez uma migração "lift and shift" de um grande aplicativo de banco de dados IRIS para a nuvem. AWS, no caso.
Um aprendizado importante é que, depois de migrar para a nuvem, os recursos podem ser dimensionados corretamente ao longo do tempo conforme necessário. Não é preciso comprar e provisionar infraestrutura local para o crescimento que você espera alcançar daqui a vários anos no futuro.
É necessário monitoramento contínuo. A taxa de transações do seu aplicativo mudará à medida que seu negócio e o próprio aplicativo ou o uso dele mudar. Isso alterará os requisitos de recursos do sistema. Planejadores também devem considerar picos sazonais na atividade. Claro, uma vantagem da nuvem é que os recursos podem ser aumentados ou reduzidos conforme necessário.
Para mais informações contextuais, há vários posts detalhados sobre AWS e IRIS na comunidade. Um bom ponto de partida é pesquisar "referência da AWS". Também adicionei alguns links úteis no final deste post.
Os serviços da AWS são como blocos de Lego: tamanhos e formatos diferentes podem ser combinados. Ignorei networking, segurança e preparação de uma VPC para este post. Foquei em dois dos componentes de blocos de Lego;
- Requisitos de computação.
- Requisitos de armazenamento.
Visão geral
O aplicativo é um sistema de informações de saúde usado em um grupo de hospitais movimentados. Os componentes da arquitetura em que estou focando aqui incluem dois servidores de bancos de dados em um cluster de tolerância a falhas de espelho da InterSystems.
Barra lateral: os espelhos estão em zonas de disponibilidade separadas para alta disponibilidade adicional.
Requisitos de computação
Tipos de instância EC2
O Amazon EC2 oferece uma ampla seleção de tipos de instância otimizados para diferentes casos de uso. Os tipos de instância compreendem combinações FIXAS variadas de CPU e memória, além de limites máximos fixos de capacidade de armazenamento e de networking. Cada tipo de instância inclui um ou mais tamanhos de instância.
Os atributos da instância EC2 que devem ser analisados com mais atenção incluem:
- Núcleos de vCPU e memória.
- Máximo de IOPS e taxa de transferência de IO.
Para aplicativos IRIS como esse com um grande servidor de banco de dados, dois tipos de instâncias EC2 são apropriadas:
- EC2 R5 e R6i estão na família de instâncias com memória otimizada e são adequadas para cargas de trabalho com uso intensivo da memória, como IRIS. Há 8 GB de memória por vCPU.
- EC2 M5 e M6i estão na família de instâncias de uso geral. Há 4 GB de memória por vCPU. Elas são mais usadas para servidores da Web, de impressão e de não produção.
Observação: nem todos os tipos de instâncias estão disponíveis em todas as regiões da AWS. As instâncias R5 foram usadas nesse caso porque a R6i lançada mais recentemente não estava disponível.
Planejamento de capacidade
Quando um sistema local existente está disponível, o planejamento da capacidade significa medir o uso atual de recursos, traduzindo isso para os recursos na nuvem pública e adicionando recursos para o crescimento previsto a curto prazo. Geralmente, se não há outros limites de recursos, os aplicativos do banco de dados do IRIS são escalados linearmente nos mesmos processadores. Por exemplo, imagine adicionar um novo hospital ao grupo. O aumento do uso do sistema (taxa de transações) em 20% exigiria 20% mais recursos de vCPU usando os mesmos tipos de processadores. É claro que isso não é garantido. Valide seus aplicativos.
Requisitos de vCPU
Antes da migração, a utilização da CPU chegava a quase 100% em períodos movimentados. O servidor no local tem 26 vCPUs. Uma boa regra geral é avaliar sistemas com um pico esperado de 80% de utilização da CPU. Isso permite picos temporários na atividade ou outras atividades incomuns. Confira abaixo um gráfico de exemplo para a utilização da CPU em um dia típico.
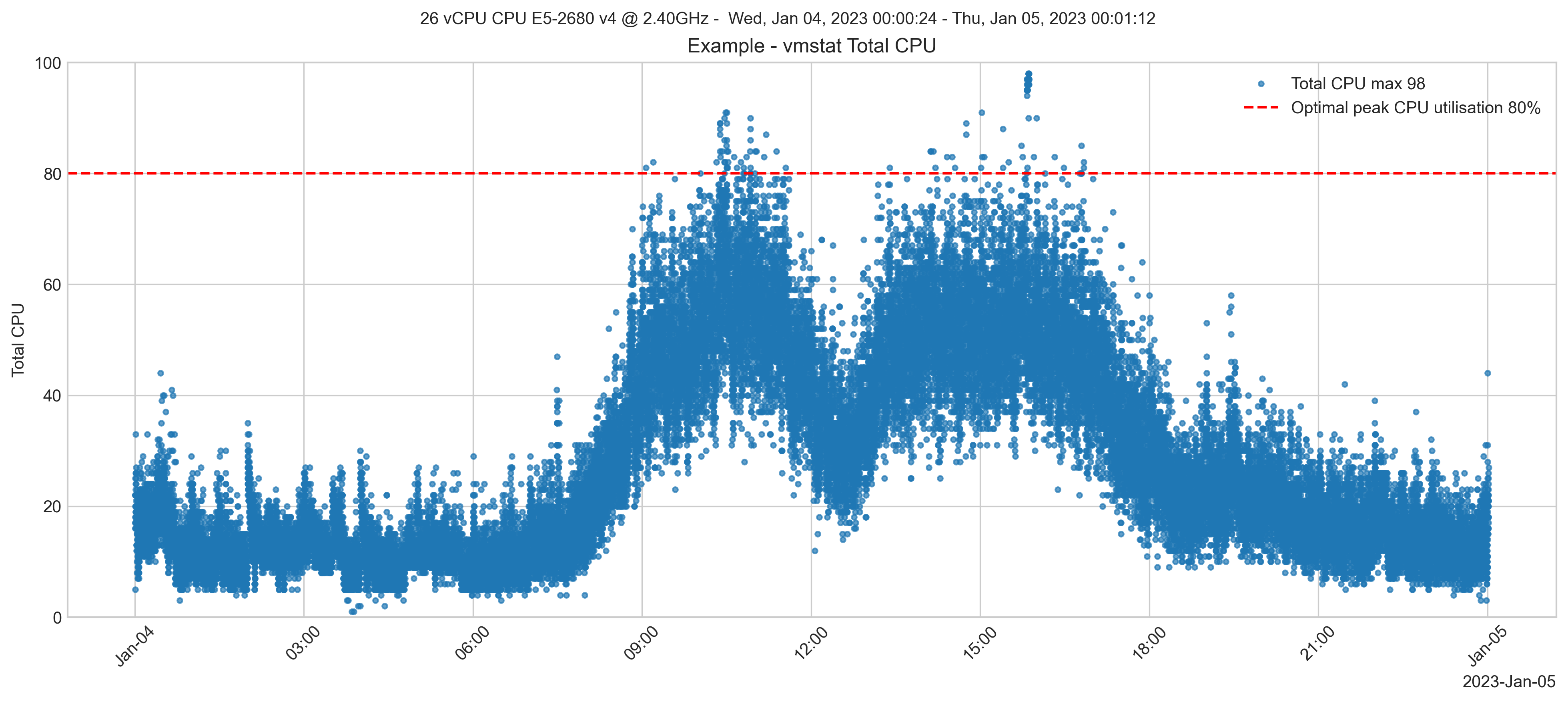
O monitoramento dos servidores locais exigiria o aumento para 30 núcleos de vCPUs, trazendo o pico geral de utilização para abaixo de 80%. O cliente esperava adicionar um crescimento de transações de 20% no curto prazo. Então, um buffer de 20% é adicionado aos cálculos, permitindo também uma capacidade de reserva adicional para o período de migração.
Um cálculo simples é que 30 núcleos + 20% de crescimento e buffer de migração equivale a 36 núcleos de vCPU necessários.
Dimensionamento para a nuvem
Lembre-se de que as instâncias EC2 da AWS em cada tipo de família têm tamanhos fixos de vCPU e memória e definem limites máximos de IOPS, armazenamento e taxa de transferência de rede.
Por exemplo, os tipos de instância disponíveis nas famílias R5 e R6i incluem:
- 16 vCPUs e memória de 128 GB
- 32 vCPUs e memória de 256 GB
- 48 vCPUs e memória de 384 GB
- 64 vCPUs e memória de 512 GB
- E assim por diante.
Regra geral: Uma maneira simplificada de dimensionar uma instância EC2 a partir de métricas locais conhecidas para a nuvem é arredondar os requisitos de vCPU locais recomendados para o próximo tamanho de instância EC2 disponível.
Ressalvas: Pode haver várias outras considerações. Por exemplo, diferenças nos tipos e nas velocidades dos processadores locais e do EC2, ou um armazenamento mais eficiente na nuvem do que em um sistema local antigo, podem significar que os requisitos de vCPU mudam. Por exemplo, é possível ter mais IO e fazer mais trabalho em menos tempo, aumentando o pico de utilização da vCPU. Os servidores locais podem ter um processador de CPU completo, incluindo hyper-threading, e as vCPUs das instâncias na nuvem serem um único hyper thread. Por outro lado, as instâncias EC2 são otimizadas para transferir parte do processamento para placas Nitro integradas. Assim, os principais núcleos de vCPU gastam mais ciclos processando as cargas de trabalho, melhorando o desempenho das instâncias. Porém, em resumo, a regra acima é um ótimo guia para começar. A vantagem da nuvem é que, com monitoramento contínuo, você pode planejar e mudar o tipo de instância para otimizar o desempenho e custo.
Por exemplo, para traduzir 30 ou 36 vCPUs locais em tipos de instância EC2 semelhantes:
- O r5.8xlarge tem 32 vCPUs, 256 GB de memória e um máximo de 30.000 IOPS.
- O r512xlarge tem 48 vCPUs, 384 GB de memória e um máximo de 40.000 IOPS
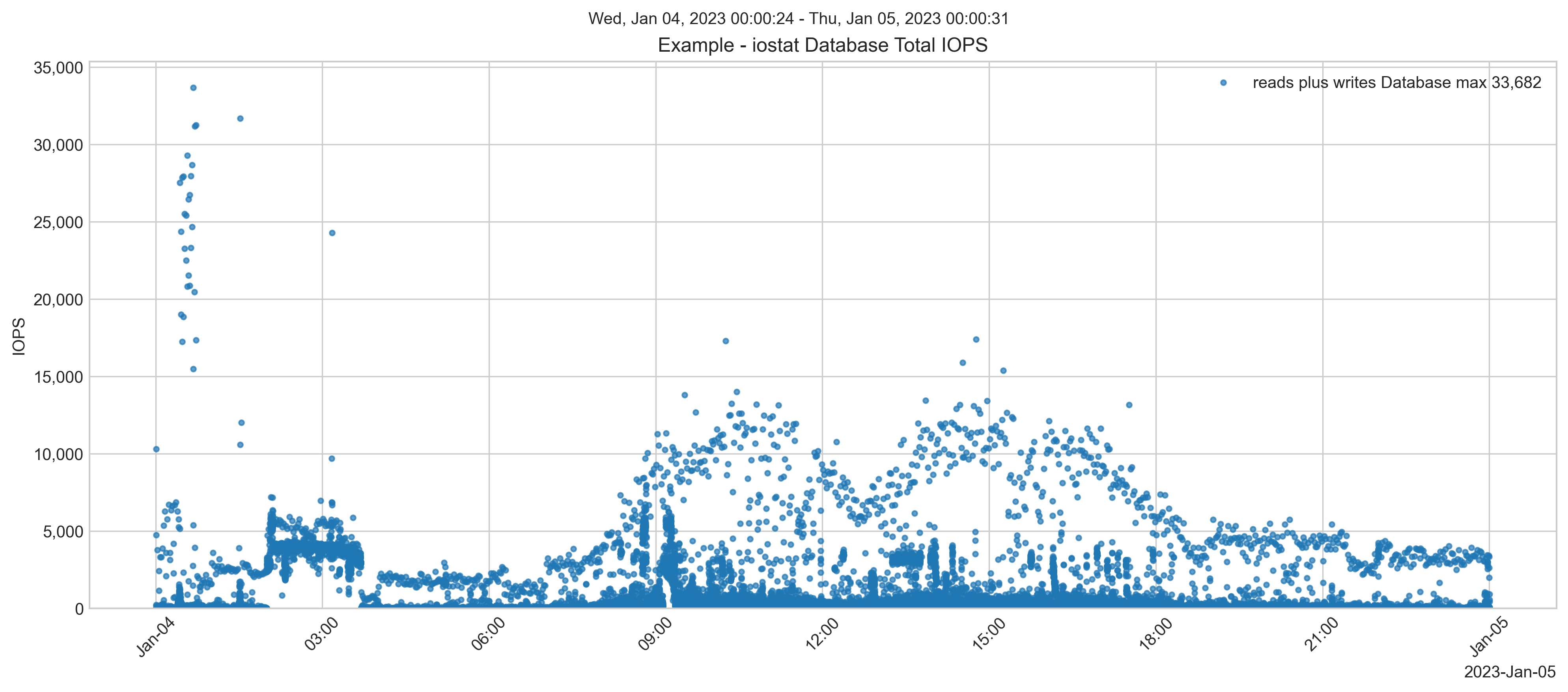
Observe o máximo de IOPS. Isso será importante mais tarde.
Resultados
Uma instância r512xlarge foi selecionada para os espelhos do banco de dados do IRIS para a migração.
Nas semanas seguintes à migração, o monitoramento mostrou que o tipo de instância de 48 vCPUs sustentou picos de quase 100% de utilização da vCPU. No entanto, em geral, o processamento chegou a aproximadamente 70%. Isso está bem dentro da faixa aceitável e, se os períodos de alta utilização forem atribuídos a um processo que pode ser otimizado, há bastante capacidade de reserva para considerar o dimensionamento para uma especificação inferior e um tipo de instância EC2 mais barato.
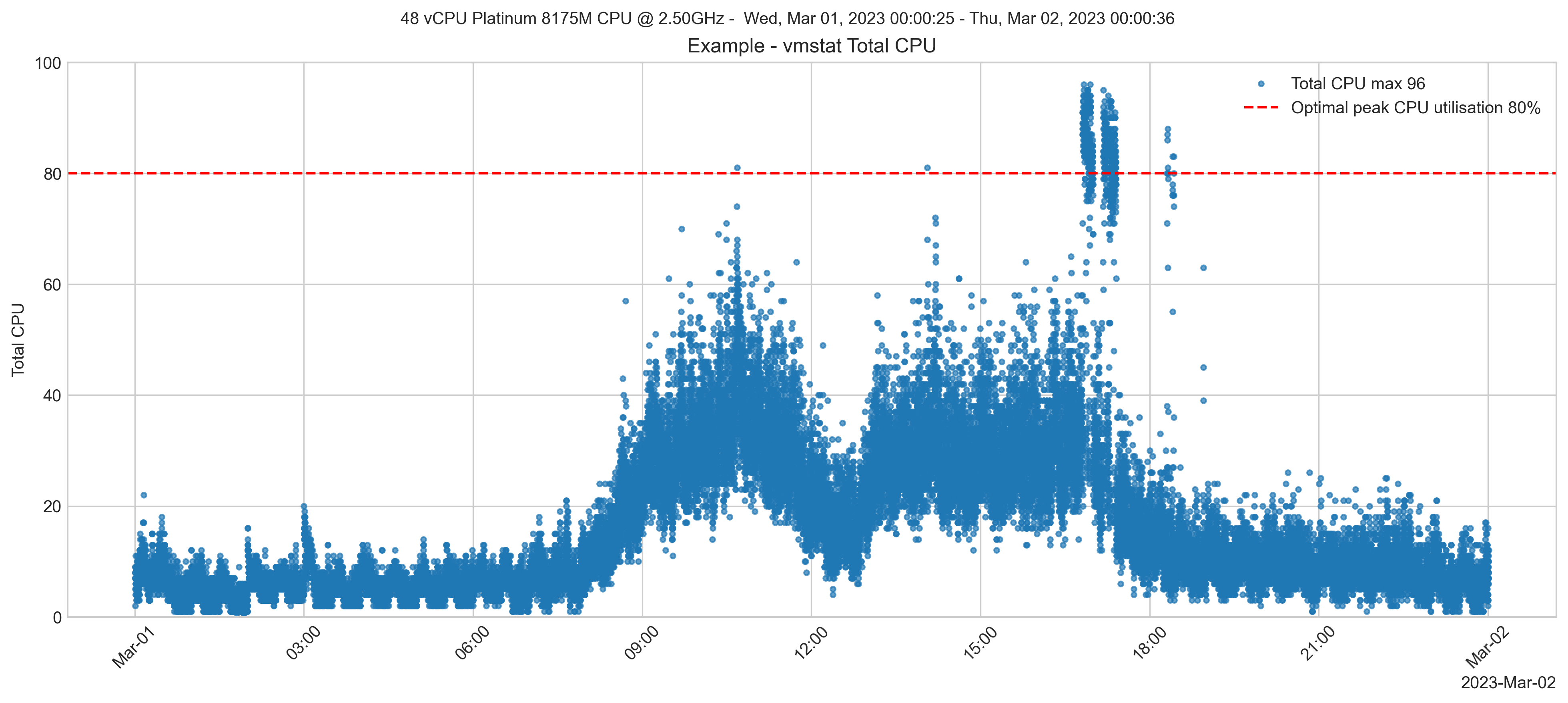
Um tempo depois, o tipo de instância permaneceu igual. Uma verificação do desempenho do sistema mostra que o pico de utilização da vCPU caiu para cerca de 50%. No entanto, ainda há picos temporários perto de 100%.
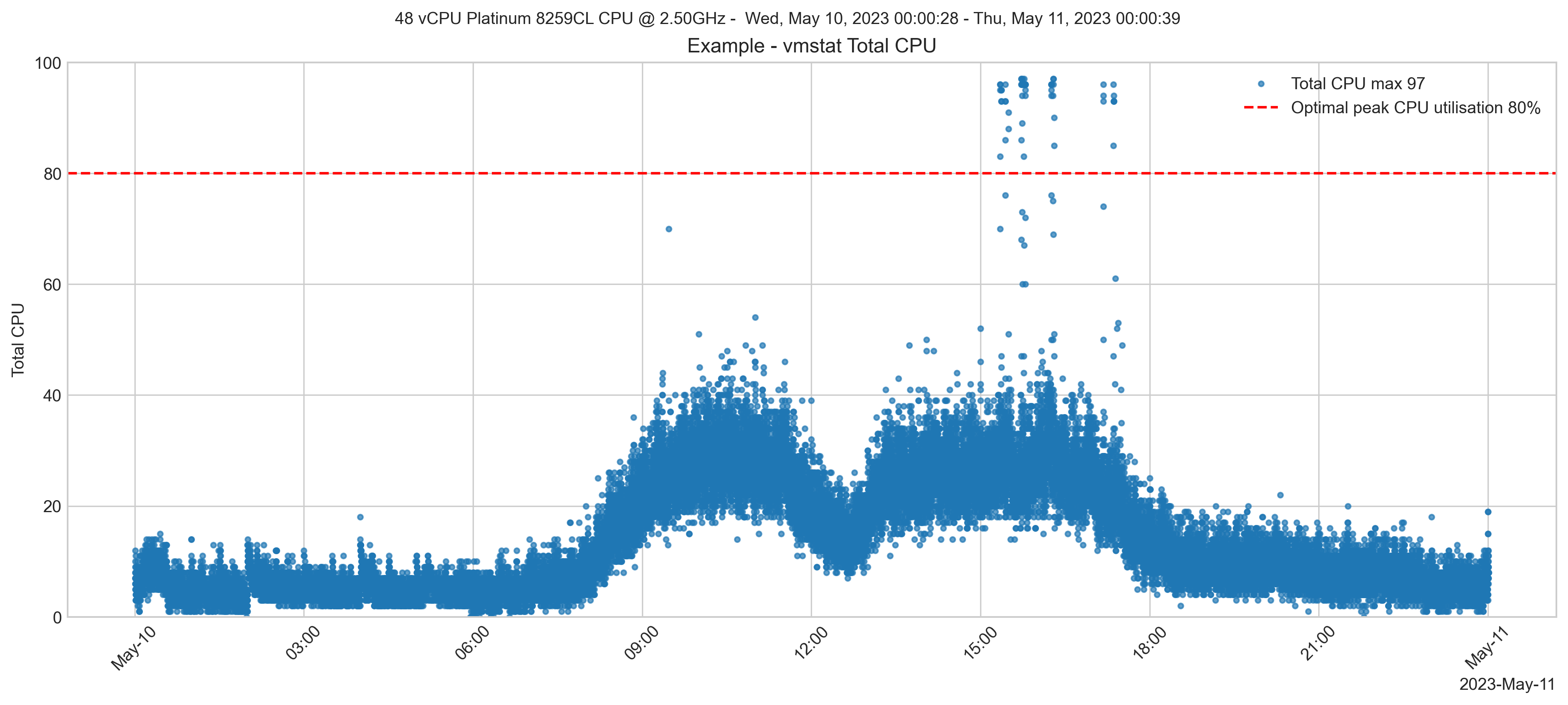
Recomendação
É necessário monitoramento contínuo. Com o monitoramento constante, o sistema pode ser dimensionado corretamente para alcançar o desempenho necessário e ter uma execução mais barata.
Os picos temporários na utilização da vCPU devem ser investigados. Por exemplo, um relatório ou uma tarefa em lote podem ser retirados do horário comercial, diminuindo o pico geral da vCPU e reduzindo qualquer impacto negativo nos usuários interativos do aplicativo.
Revise os requisitos de IOPS e taxa de transferência de armazenamento antes de mudar o tipo de instância. Não se esqueça que os tipos de instância têm limites máximos fixos de IOPS.
As instâncias podem ser dimensionadas usando o espelhamento de tolerância a falhas. Etapas simplificadas:
- Desligue o espelho de backup.
- Ligue o espelho de backup usando uma instância menor ou maior com configurações alteradas para montar o armazenamento do EBS e contar com uma menor pegada de memória (considere, por exemplo, hugepages do Linux e buffers globais do IRIS).
- Aguarde a atualização do espelho de backup.
- Aplique a tolerância a falhas ao espelho de backup para que se torne principal.
- Repita, redimensione o espelho restante, coloque-o online novamente e atualize.
Observação: durante a tolerância a falhas do espelho, haverá uma breve interrupção para todos os usuários, interfaces etc. No entanto, se forem usados servidores de aplicações ECP, poderá não haver nenhuma interrupção para os usuários. Os servidores de aplicações também podem fazer parte de uma solução de escalonamento automático.
Outras opções econômicas incluem executar o espelho de backup em uma instância menor. No entanto, há um risco significativo de desempenho reduzido (e usuários insatisfeitos) se uma tolerância a falhas ocorrer em momentos de pico de processamento.
Ressalvas: As vCPUs e memória das instâncias são fixas. Recomeçar com uma instância e pegada de memória menores implica em um cache de buffer global menor, o que pode aumentar a taxa de IOPS de leitura do banco de dados. Considere os requisitos de armazenamento antes de reduzir o tamanho da instância. Automatize e teste o dimensionamento para minimizar o risco de erro humano, especialmente se for uma ocorrência comum.
Requisitos de armazenamento
Um desempenho de IO de armazenamento previsível com baixa latência é essencial para fornecer escalabilidade e confiabilidade para seus aplicativos.
Tipos de armazenamento
O armazenamento do Amazon Elastic Block Store (EBS) é recomendado para a maioria dos aplicativos de banco de dados do IRIS com altas taxas de transações. O EBS oferece vários tipos de volumes que permitem otimizar o desempenho do armazenamento e o custo para uma ampla variedade de aplicativos. O armazenamento baseado em SSD é necessário para cargas de trabalho transacionais, como aplicativos que usam bancos de dados do IRIS.
Dos tipos de armazenamento SSD, os volumes gp3 são geralmente recomendados para bancos de dados do IRIS, porque equilibram o preço e o desempenho para aplicativos transacionais. No entanto, para casos excepcionais com taxas muito altas de IOPS ou de transferência, o io2 pode ser usado (geralmente por um custo mais alto). Há outras opções, como as soluções de armazenamento temporário anexado localmente e arrays virtuais de terceiros. Se você tiver requisitos que ultrapassam as capacidades do io2, fale com a InterSystems sobre suas necessidades.
O armazenamento acompanha limites e custos, por exemplo.
- Os volumes gp3 oferecem uma linha de base de medição de desempenho de 3.000 IOPS e 125 MiBps em qualquer tamanho de volume, com uma latência de milissegundos de um dígito 99% do tempo para o custo base da capacidade de GB de armazenamento. Os volumes gp3 podem ser escalonados para 16.000 IOPS e 1.000 MiBps de taxa de transferência por um custo adicional. O armazenamento é precificado por GB e com base no provisionamento de IOPS acima da linha de base de 3.000 IOPS.
- Os volumes io2 oferecem uma linha de base de medição de desempenho constante de até 500 IOPS/GB para um máximo de 64.000 IOPS com uma latência de milissegundos de um dígito 99% do tempo. O armazenamento é precificado por GB e com base no provisionamento de IOPS.
Lembre-se: as instâncias EC2 também têm limites de IOPS e taxa de transferência total do EBS. Por exemplo, o r5.8xlarge tem 32 vCPUs e um máximo de 30.000 IOPS. Nem todos os tipos de instâncias são otimizados para usar os volumes do EBS.
Planejamento de capacidade
Quando um sistema local existente está disponível, o planejamento da capacidade significa medir o uso atual de recursos, traduzindo isso para os recursos na nuvem pública e adicionando recursos para o crescimento previsto a curto prazo.
Os dois recursos essenciais que devem ser considerados:
- Capacidade de armazenamento. Quantos GB de armazenamento de banco de dados são necessários e qual é o crescimento esperado? Por exemplo, você sabe o crescimento médio histórico de banco de dados do seu sistema local para uma taxa de transações conhecida. Nesse caso, você pode calcular os tamanhos de banco de dados futuros com base em qualquer crescimento previsto da taxa de transações. Você também precisará considerar outros tipos de armazenamento, como diários.
- IOPS e taxa de transferência. Esse é o mais interessante e é abordado em detalhes abaixo.
Requisitos de banco de dados
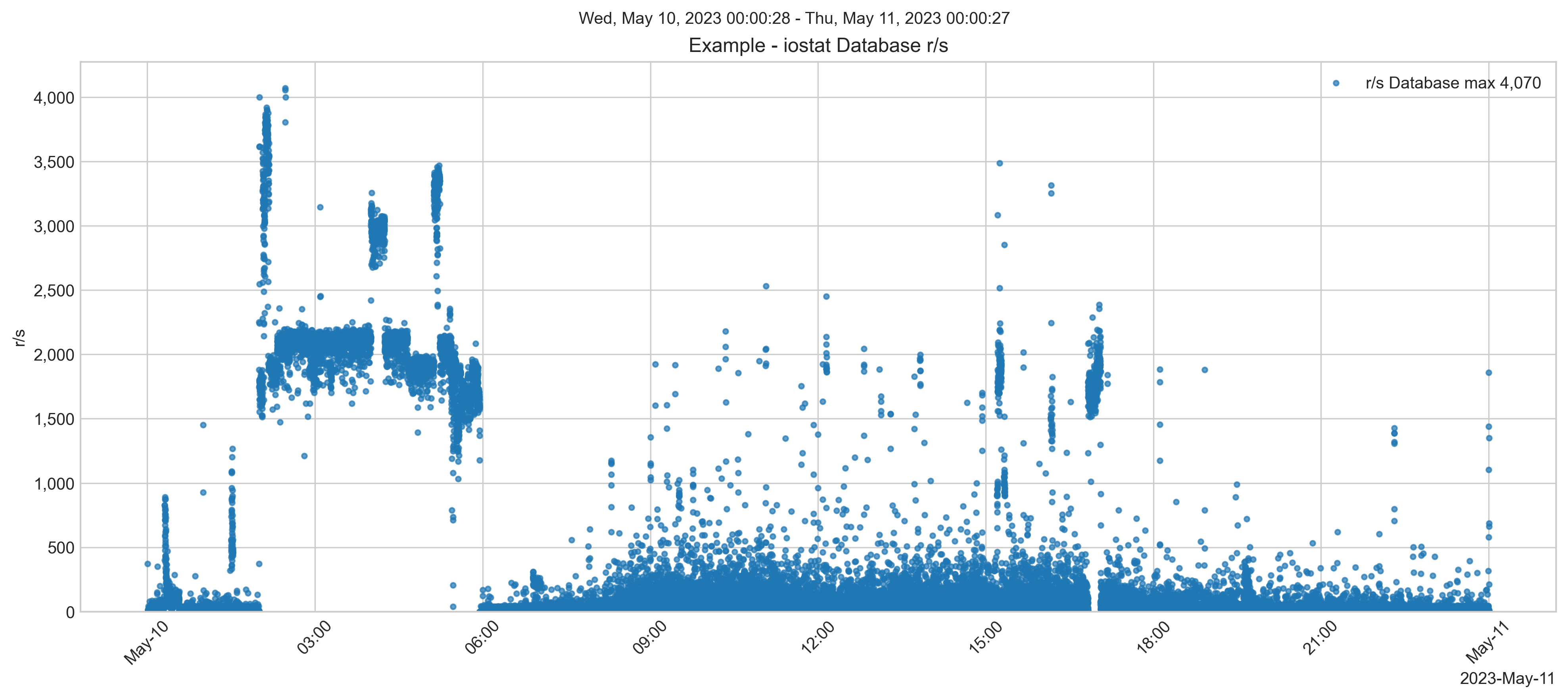
Antes da migração, as leituras de disco de banco de dados atingiam cerca de 8.000 IOPS.
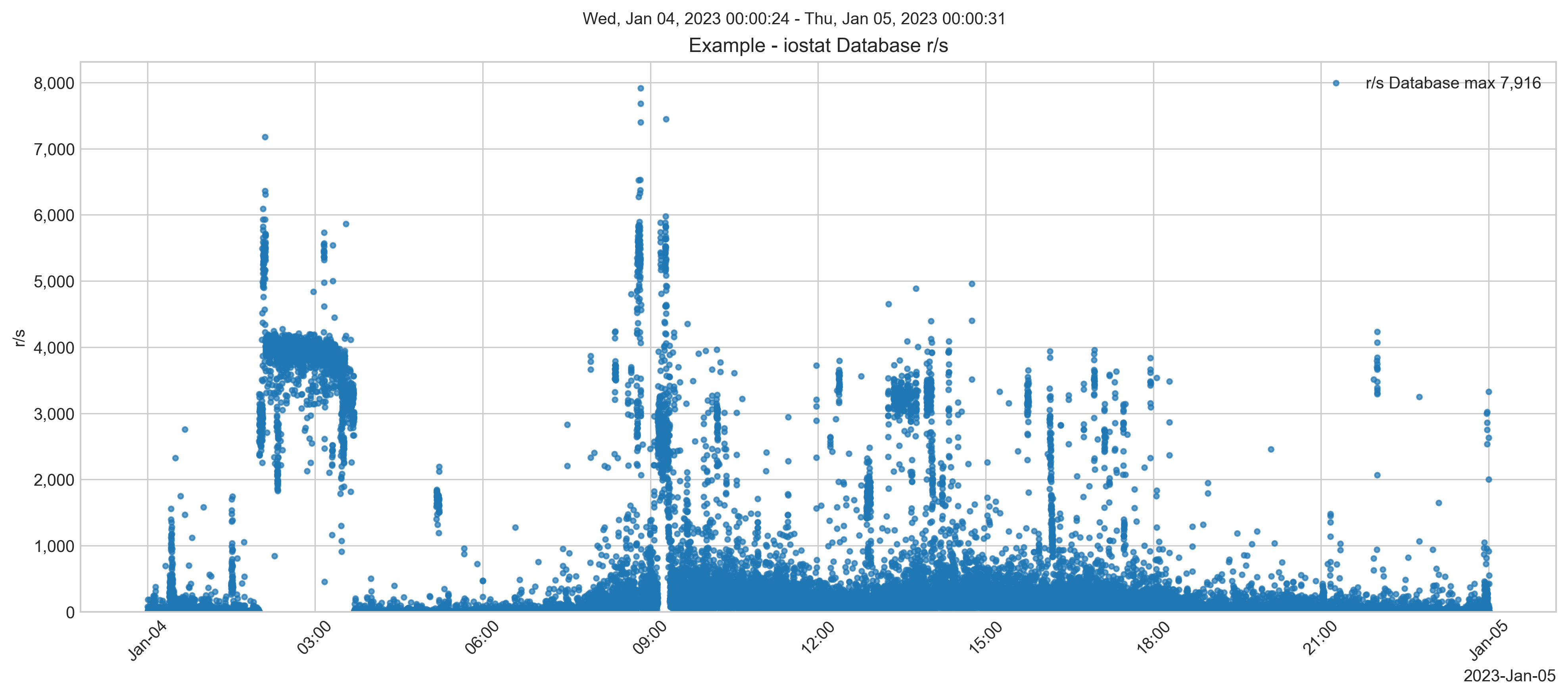
A taxa de IOPS de leitura e escrita ultrapassava 40.000 em alguns dias. Embora, durante o horário comercial, os picos sejam bem mais baixos.
A taxa de transferência total de leituras e escritas atingiu cerca de 600 MB/s.
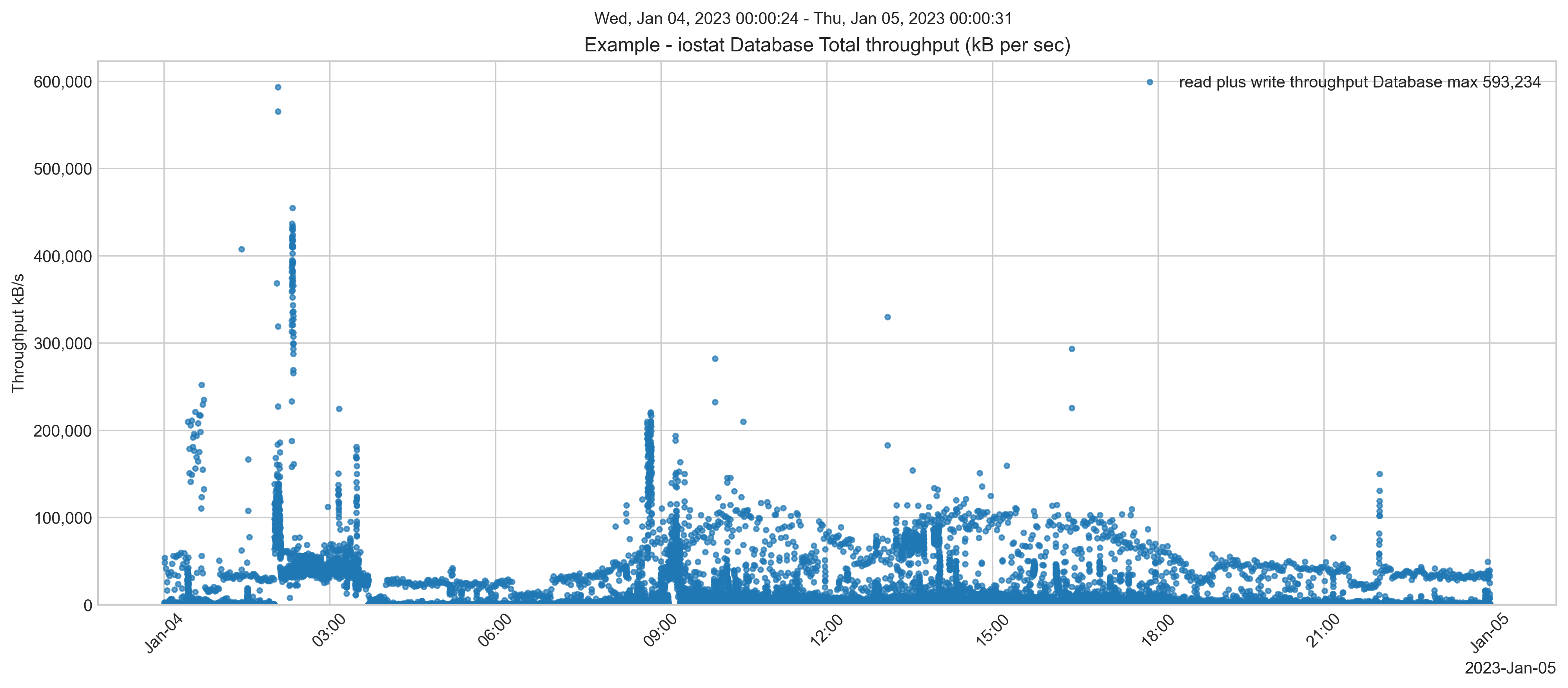
Lembre-se: as instâncias EC2 e os volumes do EBS têm limites de IOPS E taxa de transferência*. O limite que for atingido primeiro resultará na restrição desse recurso pela AWS, causando a degradação do desempenho e possivelmente afetando os usuários do seu sistema. Você precisa provisionar IOPS E taxa de transferência.
Dimensionamento para a nuvem
Os volumes gp3 são usados para equilibrar o preço e o desempenho. No entanto, nesse caso, o limite de 16.000 IOPS para um único volume gp3 foi excedido, e há a expectativa de que os requisitos aumentarão no futuro.
Para permitir o provisionamento de uma taxa IOPS mais alta do que o possível em um único volume gp3, é usada uma distribuição do LVM.
Para a migração, o banco de dados é implantado usando uma distribuição do LVM de quatro volumes gp3 com o seguinte:
- 8.000 IOPS provisionadas em cada volume (para um total de 32.000 IOPS).
- Taxa de transferência de 250 MB/s provisionada em cada volume (para um total de 1.000 MB/s).
O processo exato de planejamento de capacidade foi realizado para o Write Image Journal (WIJ) e os discos locais de diário de transações. O WIJ e os discos de diário foram provisionados em um único disco gp3 cada.
Para mais detalhes e um exemplo de como usar uma distribuição do LVM, veja: https://community.intersystems.com/post/using-lvm-stripe-increase-aws-ebs-iops-and-throughput
Regra geral: Se os seus requisitos ultrapassarem os limites de um único volume gp3, investigue a diferença de custo entre usar IOPS provisionadas do gp3 do LVM e do io2.
Ressalvas: Garanta que a instância EC2 não limite as taxas de IOPS ou de transferência.
Resultados
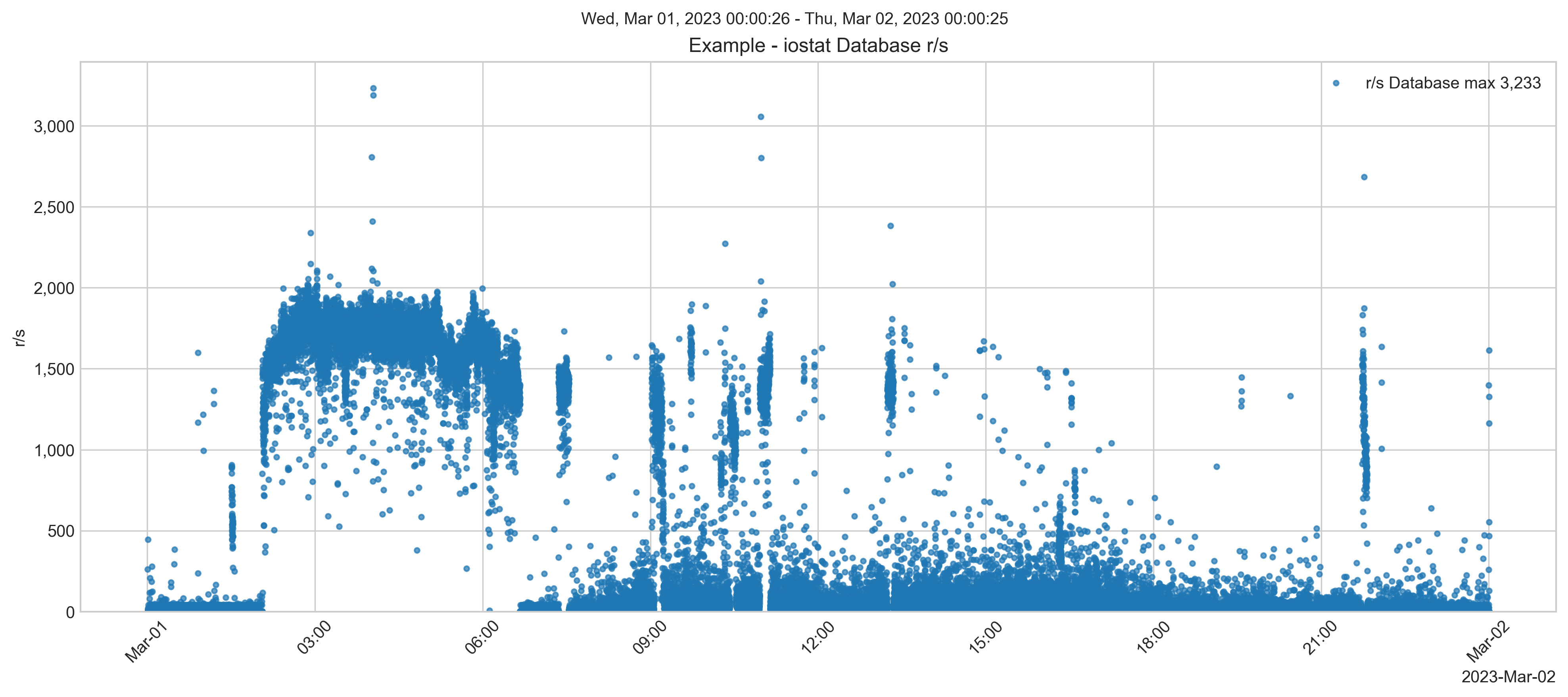
Nas semanas seguintes à migração, as IOPS de escrita de banco de dados atingiram cerca de 40.000 IOPS, semelhante a no local. No entanto, as IOPS de leitura de banco de dados foram muito mais baixas.
Uma menor taxa de IOPS de leitura é esperada devido à instância EC2 ter mais memória disponível para armazenar dados em cache nos buffers globais. Mais dados do conjunto de trabalho do aplicativo na memória significa que eles não precisam ser chamados de um armazenamento SSD muito mais lento. Lembre-se, acontecerá o oposto se você reduzir a pegada de memória.
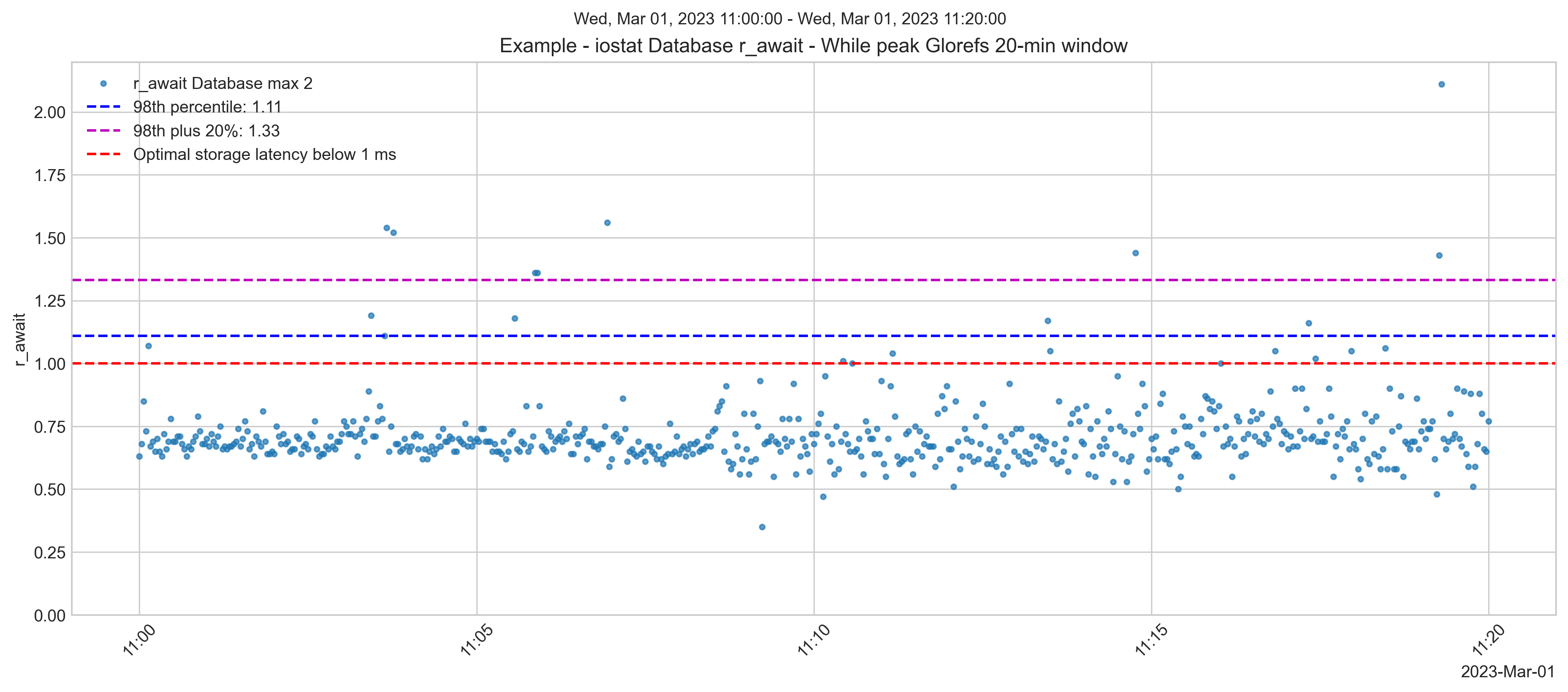
Durante os momentos de pico de processamento, o volume do banco de dados teve picos de latência acima de 1 ms. No entanto, os picos são temporários e não afetam a experiência do usuário. O desempenho do armazenamento é excelente.
Depois, uma verificação de desempenho do sistema mostra que, embora haja alguns picos, geralmente, a taxa de IOPS de leitura ainda é menor do que no local.
Recomendação
É necessário monitoramento contínuo. Com o monitoramento constante, o sistema pode ser dimensionado corretamente para alcançar o desempenho necessário e ter uma execução mais barata.
O processo de aplicação responsável pelos 20 minutos de alta IOPS de escrita de banco de dados durante a noite (gráfico não exibido) deve ser analisado para entender o que ele está fazendo. As escritas não são afetadas por grandes buffers globais e ainda estão na faixa de 30-40.000 IOPS. O processo poderia ser concluído com um menor provisionamento de IOPS. No entanto, haverá um impacto mensurável na latência de leitura do banco de dados se as escritas sobrecarregarem o caminho de IO, afetando negativamente os usuários interativos. A latência de leitura precisa ser monitorada atentamente se as leituras forem limitadas por um longo período.
O provisionamento de IOPS e taxa de transferência de disco do banco de dados pode ser ajustado pelas APIs da AWS ou interativamente pelo console da AWS. Como quatro volumes do EBS compõem o disco LVM, os atributos de IOPS e de taxa de transferência dos volumes do EBS precisam ser ajustados igualmente.
O WIJ e o diário também devem ser monitorados continuamente para entender se é possível fazer alguma alteração no provisionamento de IOPS e de taxa de transferência.
Observação: o volume do WIJ tem requisitos de alta taxa de transferência (não IOPS) devido ao tamanho do bloco de 256 kB. A taxa de IOPS do volume do WIJ pode estar abaixo da linha de base de 3.000 IOPS, mas a taxa de transferência está atualmente acima da linha de base de taxa de transferência de 125 MB/s. É provisionada uma taxa de transferência adicional no volume do WIJ.
Ressalvas: Diminuir o provisionamento de IOPS para limitar o período de altas escritas noturnas resultará em um ciclo mais longo do daemon de escrita (WIJ mais escritas aleatórias de banco de dados). Isso pode ser aceitável se as escritas forem concluídas em 30-40 segundos. No entanto, pode haver um grave impacto na latência de leitura e IOPS de leitura e, portanto, na experiência dos usuários interativos no sistema por 20 minutos ou mais. Prossiga com cautela.
Links úteis
- Os gráficos são criados com "yaspe" https://community.intersystems.com/post/yaspe-yet-another-system-performance-extractor
AWS
- Confira detalhes do Elastic Cloud Computing (EC2) da AWS aqui: https://aws.amazon.com/ec2/
- Confira detalhes do Elastic Block Store (EBS) da AWS aqui: https://aws.amazon.com/ebs/