Complementando o IRIS com MLflow para um pipeline de Treinamento Contínuo (CT)
Um pipeline de Treinamento Contínuo (CT) formaliza um modelo de Machine Learning (ML) desenvolvido por meio de experimentação de ciência de dados, utilizando os dados disponíveis em um determinado momento. Ele prepara o modelo para implantação, permitindo atualizações autônomas à medida que novos dados ficam disponíveis, além de oferecer monitoramento de desempenho robusto, registro de logs e recursos de registro de modelos para fins de auditoria.
O InterSystems IRIS já fornece quase todos os componentes necessários para suportar tal pipeline. No entanto, um elemento fundamental estava faltando: uma ferramenta padronizada para registro de modelos. Neste artigo, apresento esta abordagem, que combina os pontos fortes do IRIS com a plataforma de engenharia de IA de código aberto MLflow. Juntos, eles atuam como ferramentas complementares para a construção de um pipeline de Treinamento Contínuo (CT) eficaz.
A implementação neste repositório aproveita a configuração integrada do MLflow para armazenar explicadores SHAP, fornecendo explicações por trás das previsões feitas pelo modelo correspondente na época, incluindo modelos complexos de "caixa-preta", como Random Forest, XGBoost, Redes Neurais, etc.
Demo: https://youtu.be/qLdc4jhn83c
Componentes do Pipeline CT
A teoria por trás dos módulos deste pipeline CT é baseada no padrão da indústria para MLOps nível 1 definido pelo Google neste artigo, e a implementação de cada um de seus componentes aproveita os melhores recursos do IRIS e do MLflow, destacados em vermelho conforme visto na imagem abaixo:
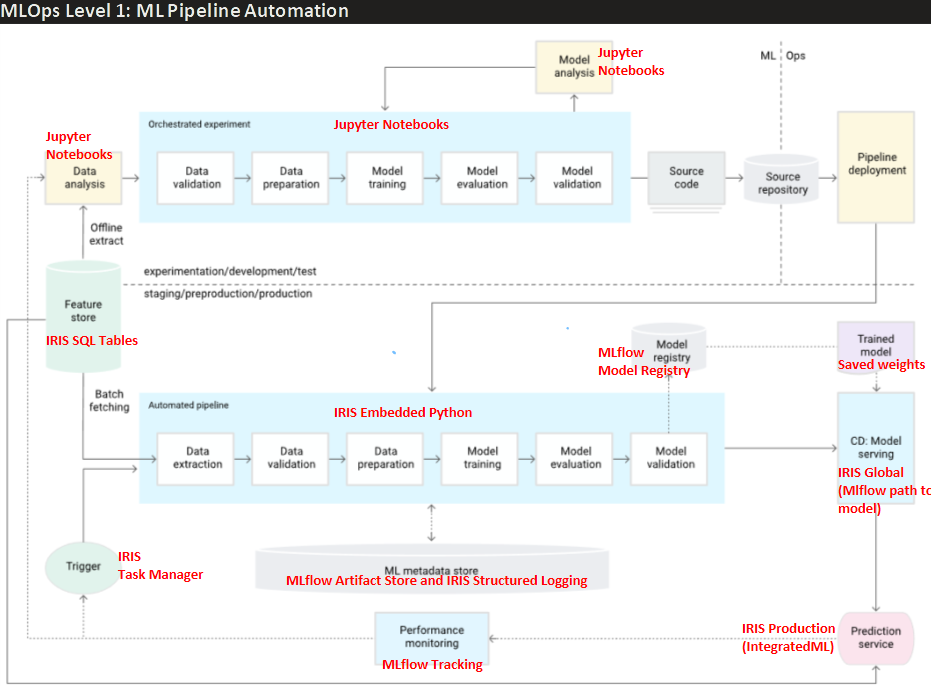
Para aqueles que são novos em pipelines CT, a imagem acima descreve como uma fase tradicional de experimentação de um projeto de Ciência de Dados (seção superior "experimentation/development/test"), geralmente feita em notebooks Jupyter, é transformada em uma implantação de nível de produção do modelo desenvolvido que permite o monitoramento contínuo do desempenho ao longo do tempo e o retreinamento automático sempre que o desempenho do modelo cair. Tudo isso com versionamento de modelo adequado e registro de logs para fins de auditoria.
Nos aprofundamos nos detalhes no README do repositório, mas para uma compreensão inicial de cada componente, definimos brevemente abaixo o que cada um faz e como isso se relaciona com a ferramenta IRIS/MLflow escolhida para esse propósito.
- Feature Store: É a única fonte de verdade para a obtenção dos dados e onde cada parâmetro constante ou definição relacionada aos próprios dados é definida, o que pode variar entre clientes e casos de uso (por exemplo, cada cliente pode definir a readmissão após 15, 30 ou qualquer outro número de dias. A chegada tardia a uma consulta pode ser considerada após 5, 10 ou qualquer outro número de minutos). As globals multidimensionais das Tabelas SQL do IRIS permitem o armazenamento de alta velocidade, e as propriedades computadas armazenadas facilitam a definição de propriedades personalizadas junto com os próprios dados brutos.
- Automated Pipeline: É a versão formalizada e claramente modularizada do "experimento orquestrado" que geralmente é feito em um jupyter notebook, preparado para ser executado toda vez que o modelo tiver que ser retreinado, se necessário. Ele contém todos os processos de dados e treinamento de modelo necessários para obter o modelo com o melhor desempenho geral. Nesta seção, é definida cada constante relacionada ao próprio modelo escolhido durante a fase de experimentação (previamente feita por cientistas de dados em notebooks jupyter, por exemplo, semente, tamanho do teste, K-folds para validação, etc.). Em nossa implementação, aproveitamos o embedded python para acessar facilmente as classes do IRIS diretamente, junto com todas as bibliotecas python padrão de Machine Learning necessárias (Pandas, scikit-learn, MLflow, etc.).
- Model Registry: Durante o treinamento, cada modelo treinado é registrado no backend de registro do MLflow, configurado automaticamente ao construir o projeto. Podemos, a qualquer momento, baixar modelos novamente de lá e consultar o desempenho de modelos anteriores.
- Trained Model: Embora o backend do MLflow tenha um Artifact Store onde os pesos de todos os modelos treinados são armazenados, este projeto adicionalmente salva os artefatos diretamente em um local persistente (volume Docker) para carregamento rápido quando necessário. Caso estes sejam excluídos, eles são baixados e salvos novamente no mesmo local a partir do MLflow Artifact Store.
- Model Serving: Este bloco é responsável por gerenciar o modelo que é servido para produção. Armazenamos o caminho para os artefatos do modelo a serem usados em produção em uma global do IRIS, que é o que é atualizado sempre que necessário. Neste repositório, promovemos diretamente o novo modelo se ele tiver um desempenho melhor que o anterior, mas em um cenário real isso pode exigir aprovação humana. Decidimos armazenar o caminho para o modelo em uma global e não o modelo em si, porque fazer isso implicaria tempo de processamento adicional para serialização e desserialização do objeto python, enquanto o texto é mais rápido e direto para ler de uma global independentemente das classes em todo o repositório, tornando-o fácil e rápido de ler em qualquer lugar.
- Prediction Service: É o serviço real que um cliente usaria para solicitar inferências no modelo atual definido em produção. No momento, este repositório usa um método embedded python para isso, mas este bloco pode ser potencialmente melhorado transformando o modelo para o formato PMML para tornar o serviço de produção executável usando Integrated ML para quaisquer modelos sklearn, ou qualquer modelo python como LightGBM usando os novos modelos personalizados do IntegratedML no IRIS 2026.1.
- Performance Monitoring: É qualquer tipo de monitoramento que possa ser implementado para acompanhar o desempenho do modelo atual em produção, junto com os anteriores, se necessário. Para isso, aproveitamos a interface do MLflow, onde podemos fazer gráficos personalizados com qualquer uma das variáveis registradas, data e hora, métricas de desempenho, tanto para cada modelo quanto para todos os modelos treinados historicamente.
- Trigger: É o que ativa a execução do Automated Pipeline. Pode ser o desvio de dados (data drift), degradação do modelo além de um certo limite, disponibilidade de uma certa quantidade de novos dados com rótulos suficientes ou um simples agendamento periódico. Neste projeto, comparamos diretamente com um limite definido da métrica R², portanto, toda vez que o desempenho cai abaixo do valor em MLpipeline.PerformanceMonitoring.R2THRESHOLD, executamos o pipeline automatizado. Para esta tarefa, outra abordagem válida seria usar o gerenciador de tarefas para agendar um método que observe o desempenho registrado durante o monitoramento de desempenho no rastreamento do MLflow e decida se deve retreinar um novo modelo.
A adição do MLflow permite o monitoramento histórico direto do desempenho dos modelos ao longo do tempo por meio de uma interface única, hospedada localmente em um container Docker. Ele permite que você armazene e acesse artefatos de todos os modelos treinados anteriormente, incluindo aqueles implantados em produção. Esses artefatos podem ser baixados sempre que necessário, juntamente com métricas de desempenho padrão e personalizadas e visualizações customizadas.
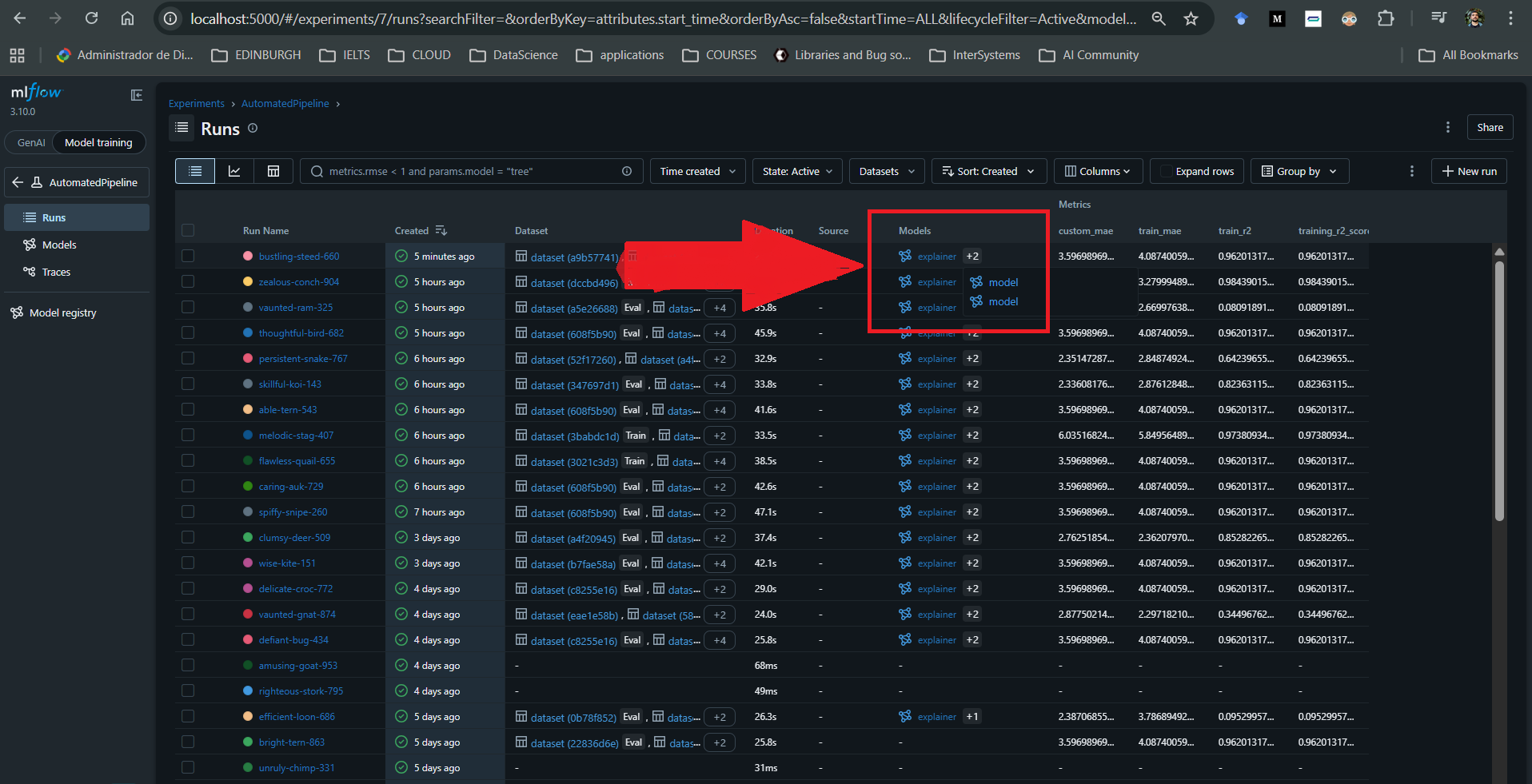
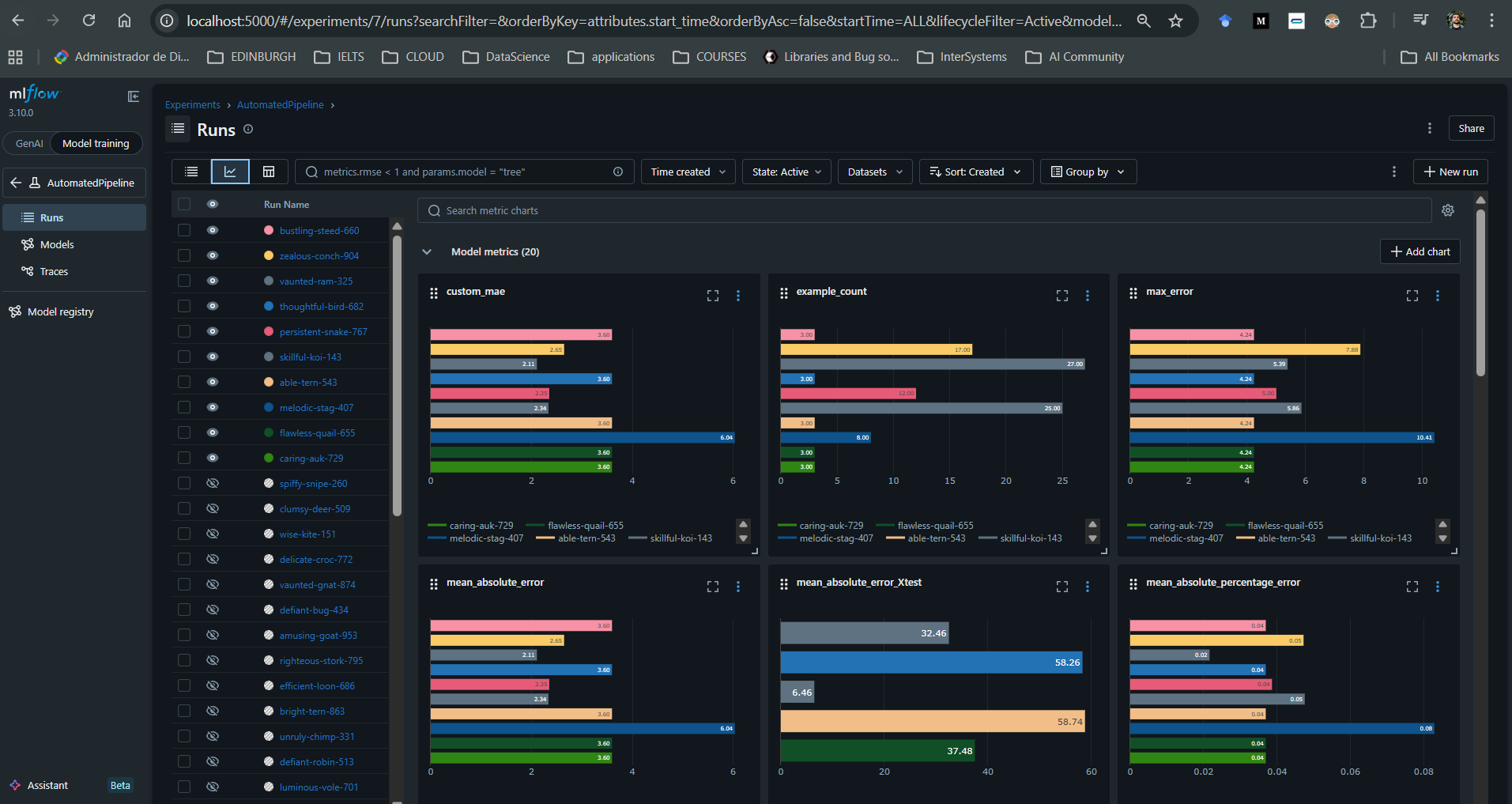
Para cada execução associada a um modelo, também é possível registrar artefatos adicionais, como explicadores SHAP, gráficos personalizados e métricas definidas pelo usuário.
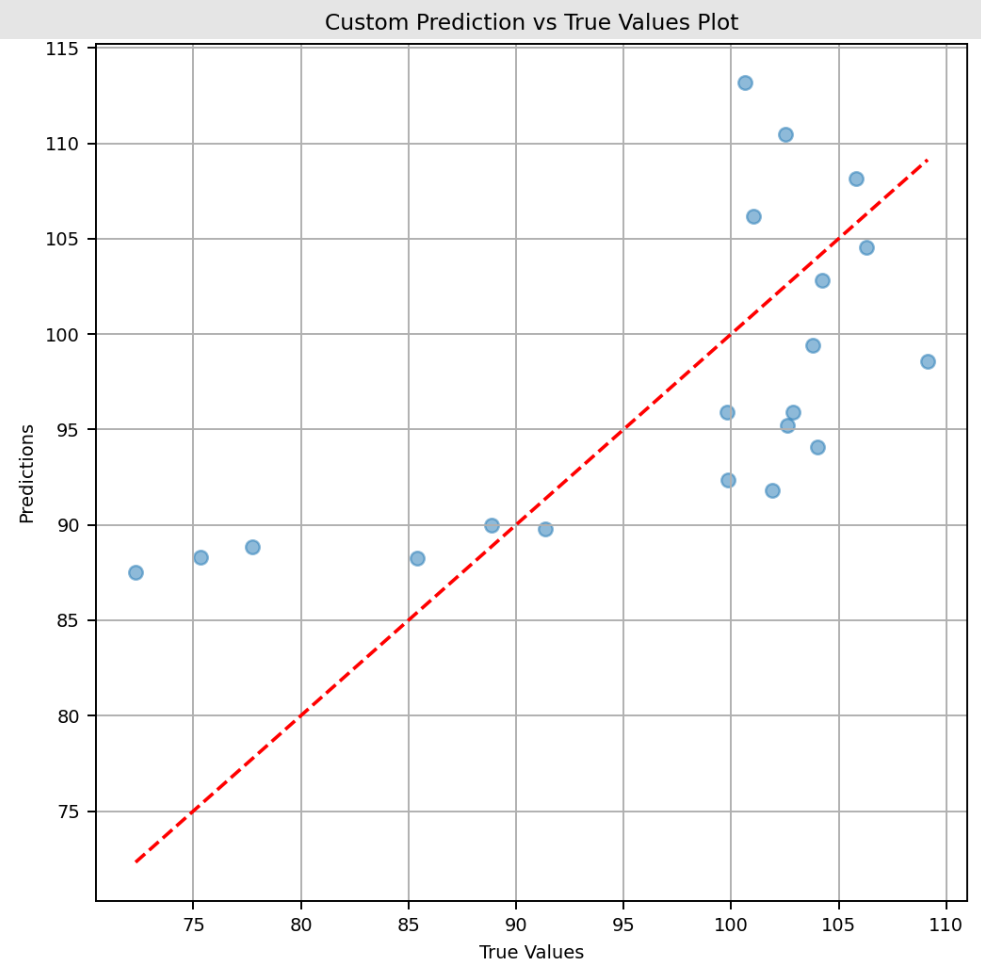
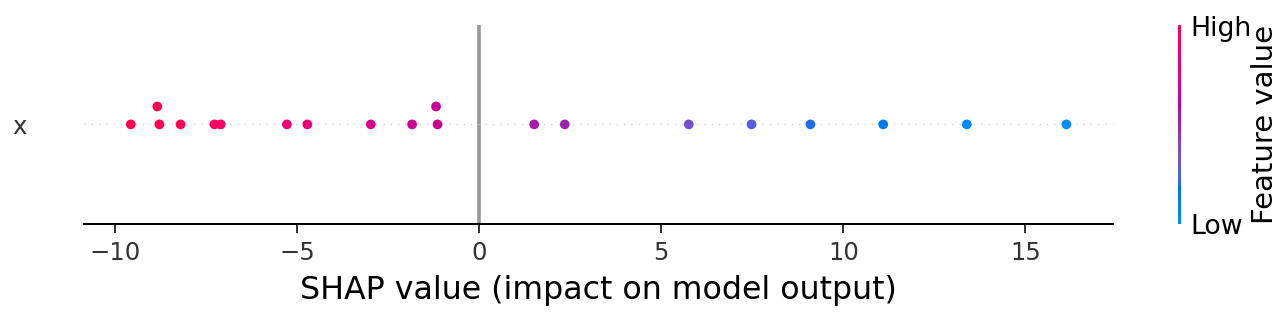
A implementação deste pipeline CT aproveita o Structured Logging para separar os logs deste pipeline dos demais do sistema, em um caminho persistente dentro do volume do container que hospeda o IRIS.
Trabalhos Futuros
- No futuro, este pipeline pode aproveitar o novo recurso lançado no IRIS 2026.1: IntegratedML Custom Models, para facilitar o serviço de predição por meio de comandos SQL, independentemente do modelo (suporte adicionado para LightGBM, NNs, XGBoost, etc.).
- No momento, o modelo é atualizado apenas automaticamente por meio de retreinamento com novos dados, mas os hiperparâmetros permanecem estáticos. Seguindo as instruções deste guia, este pipeline poderia ser melhorado introduzindo flexibilidade de hiperparâmetros e permitindo que o modelo seja reotimizado usando a estrutura de otimização de hiperparâmetros de código aberto Optuna.
- Neste projeto, quando o desempenho da predição cai abaixo de um limite predefinido, o modelo é retreinado e atualizado automaticamente. No entanto, em alguns casos, a aprovação humana deve ser necessária antes de fazer alterações em produção, o que é algo que deve ser considerado em um cenário da vida real.