Você já precisou alterar um IP ou porta antes de implantar uma interface em produção? Precisou remover itens de uma exportação? Ou modificar valores em uma tabela de lookup antes de implantar? Já quis desativar uma interface antes da implantação? Ou ainda adicionar um comentário, categoria ou configuração de alerta a uma interface antes de enviá-la para produção?
Se você já precisou fazer qualquer alteração em uma interface ou tabela de lookup antes de implantar em produção, então o Export Editor é para você!
O Export Editor é uma aplicação web Python/WSGI que fornece uma maneira de editar exportações antes de implantá-las em uma produção do IRIS/Health Connect.
Esta ferramenta permite que você:
- altere qualquer configuração em uma interface (seja um Business Service, Process ou Operation)
- modifique qualquer valor em uma tabela de lookup
- remova itens de uma exportação.
Exemplo de uso
Então, como usar o Export Editor? Acompanhe os passos a seguir para ver como você pode utilizar o Export Editor para migrar interfaces e tabelas de um ambiente de teste para um ambiente de produção, alterando os endereços IP configurados para apontar para um servidor de produção, ajustando as portas para as portas de produção, desativando as interfaces antes da implantação em produção e editando os dados das tabelas para os valores apropriados de produção.
Primeiro, você precisa gerar uma exportação a partir de uma Produção de Interoperabilidade, provavelmente do seu ambiente não produtivo.

Após adicionar todos os itens desejados à exportação (e remover quaisquer itens indesejados), salve o arquivo em um dos diretórios configurados para serem lidos pelo Export Editor.
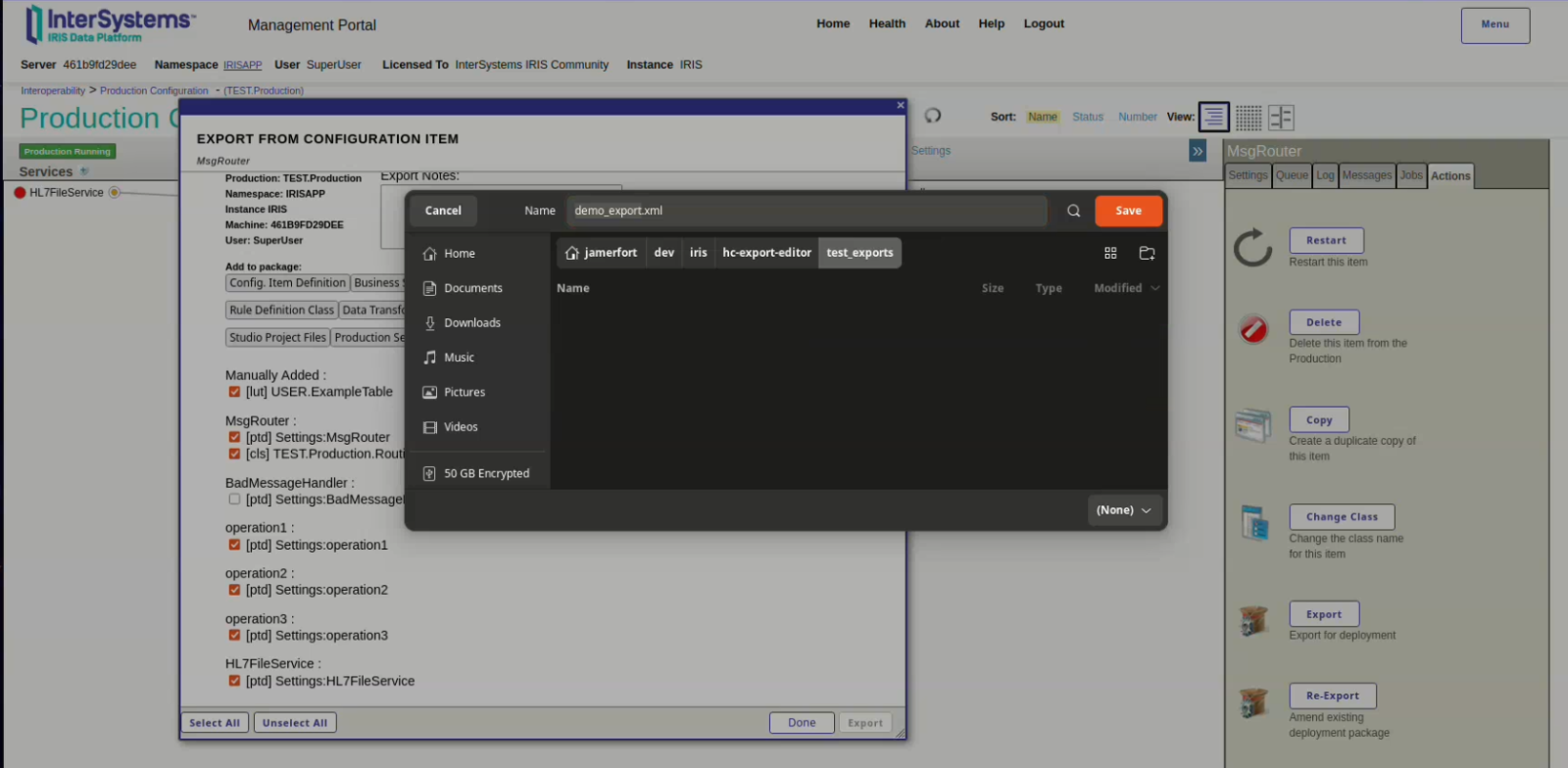
Agora, você deverá conseguir abrir a exportação no Export Editor.
.png)
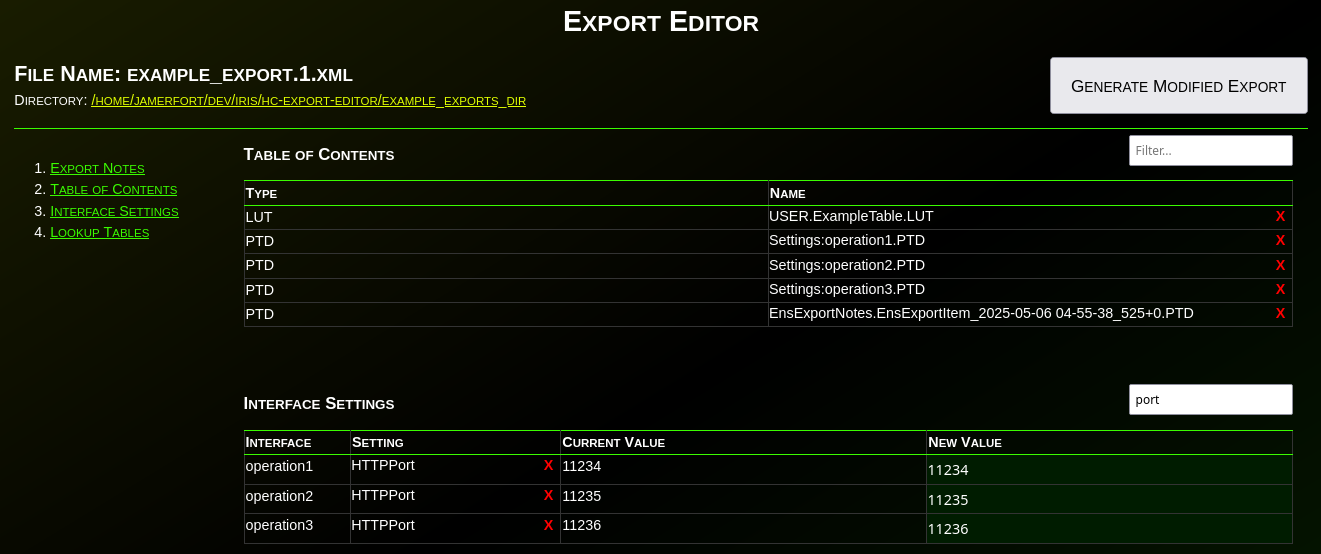
Após abrir a exportação, note que existem várias seções. Você pode ler sobre cada seção na documentação do projeto (veja o link abaixo). Por enquanto, vamos focar na seção "Interface Settings". Essa seção permite editar quaisquer propriedades de Services, Processes ou Operations incluídos na exportação. Por exemplo, podemos alterar a configuração FilePath do HL7FileService que exportamos de "/test-filesystem" para "/prod-filesystem".

Usando a caixa de filtro no canto superior direito da seção Interface Settings, podemos filtrar as configurações para mostrar apenas aquelas que contêm a palavra "server". Isso nos permite focar em configurações específicas de todas as interfaces de uma só vez. Vamos alterar os valores de "test-server" para "prod-server".
.png)
Da mesma forma, podemos usar o filtro para mostrar apenas as configurações de portas. Vamos alterar as portas para corresponder às portas de produção desejadas para essas operações (1111, 2222 e 3333 neste exemplo).
.png)
Vamos alterar todos os atributos "Enabled" das operações de "true" para "false":
.png)
Por fim, vamos modificar os valores da tabela "User.ExampleTable" para que façam referência a "prod" em vez de "test":

Agora, clique no botão "Generate Modified Export" (ou pressione "Enter" enquanto estiver em um dos campos editáveis) e salve a exportação modificada com o nome/local desejado. Lembre-se desse caminho, pois usaremos este arquivo para implantar nossas alterações em produção.
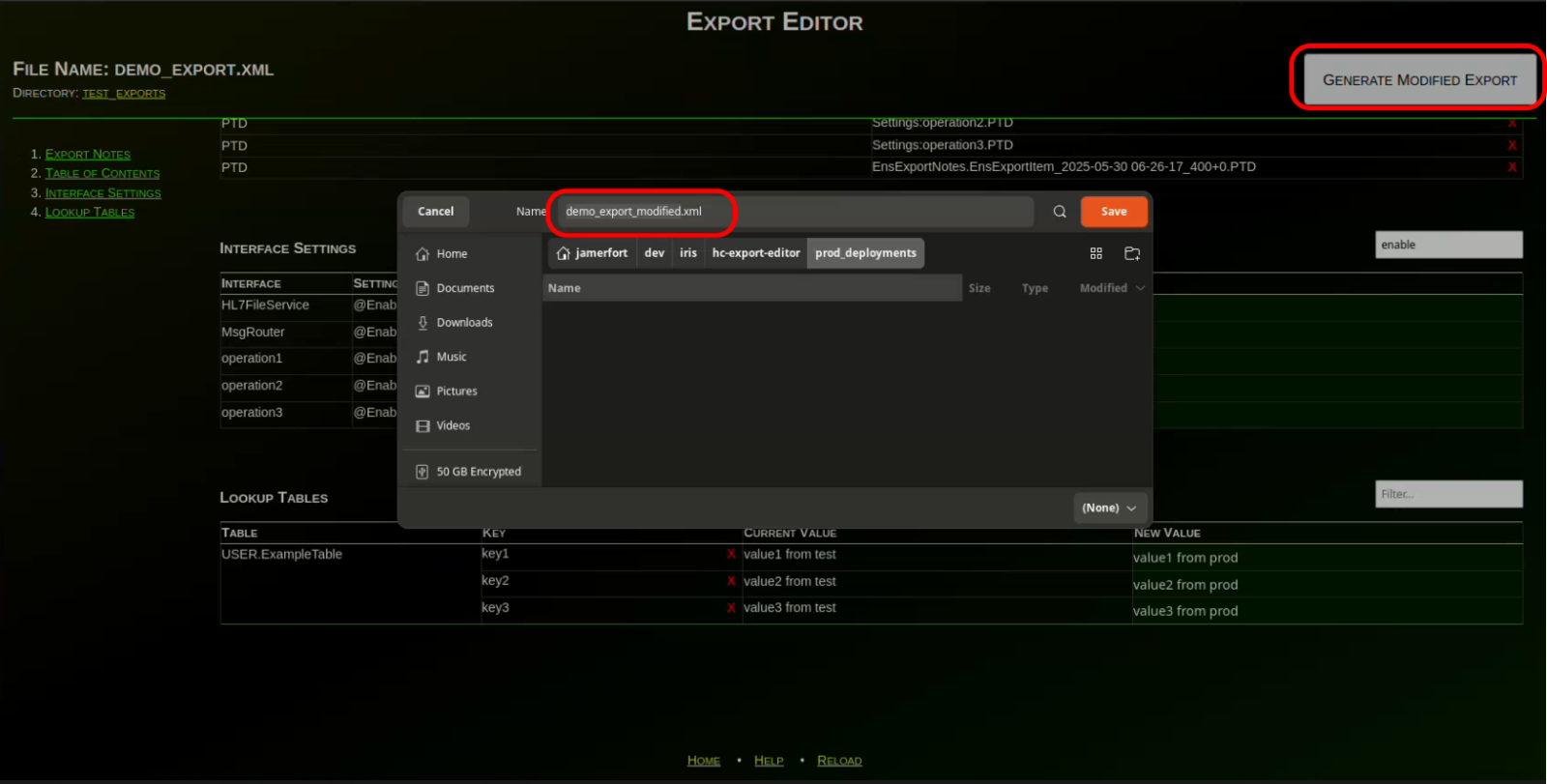
Agora, navegue até o seu ambiente de produção e abra "Interoperability > Manage > Deployment Changes > Deploy" para o seu namespace de produção:

Clique no botão "Open Local Deployment" no topo da página e selecione a exportação modificada que você salvou nos passos anteriores:

Verifique se a implantação inclui todos os itens desejados. Além disso, clique no botão "Select Target Production" no lado direito para selecionar o ambiente de produção desejado. Quando estiver pronto, clique no botão "Deploy" no topo para implantar em produção:

Você agora editou e implantou uma exportação com sucesso! Verifique se suas alterações foram aplicadas em produção (ou seja, se as operações foram desativadas e se os caminhos de arquivo, nomes de servidores, portas e valores das tabelas foram atualizados para os valores desejados).


Mais informações
Para mais informações sobre como instalar e usar o Export Editor, consulte o projeto hc-export-editor no Open Exchange.
 Open Exchange
Open Exchange