Limpar filtro
Anúncio
Angelo Bruno Braga · Nov. 29, 2021
Olá Desenvolvedores,
Esta semana é a semana de votação para o Concurso de Segurança InterSystems! Esta é a esperada hora de dar o seu voto para as melhores soluções construídas com a plataforma de dados InterSystems IRIS.
🔥 Você decide: VOTE AQUI 🔥
Como votar? Detalhes abaixo.
Nomeação de Especialistas:
Um júri experiente da InterSystems irá escolher os melhores aplicativos para indicar as premiações. Dêem as boas vindas aos nossos especialistas
⭐️ @Andreas.Dieckow, Gerente de Produtos Principal⭐️ @Robert.Kuszewski, Gerente de Produto⭐️ @Raj.Singh5479, Gerente de Produto⭐️ @Sean.Klingensmith, Desenvolvedor de Sistemas Sênior⭐️ @Wanqing.Chen, Desenvolvedor de Sistemas⭐️ @Pravin.Barton, Desenvolvedor⭐️ @Timothy.Leavitt, Gerente de Desenvolvimento⭐️ @Francois.LeFloch, Engenheiro de Soluções Sênior⭐️ @Marc.Mundt, Engenheiro de Vendas Sênior⭐️ @Eduard.Lebedyuk, Engenheiro de Vendas⭐️ @Alberto.Fuentes, Engenheiro de Vendas⭐️ @Guillaume.Rongier7183, Engenheiro de Vendas⭐️ @Evgeny.Shvarov, Gerente do Ecossistema para Desenvolvedores
Nomeação da Comunidade:
Para cada usuário a maior pontuação é selecionada de duas categorias abaixo:
Condições
Posição
1°
2°
3°
Se você possuir um artigo publicado na Comunidade de Desenvolvedores e um aplicativo publicado no Open Exchange (OEX)
9
6
3
Se você possuir ao menos 1 artigo publicado na Comunidade de Desenvolvedores ou 1 aplicativo publicado no OEX
6
4
2
Se você tiver feito qualquer contribuição válida na Comunidade de Desenvolvedores (publicado um comentário/pergunta, etc.)
3
2
1
Nível
Posição
1°
2°
3°
Global Masters VIP ou Gerentes de Produto da ISC
15
10
5
Nível Ambassador no GM
12
8
4
Nível Expert no GM ou Moderadores da Comunidade
9
6
3
Nível Specialist no GM
6
4
2
Nível Advocate no GM level ou funcionários InterSystems
3
2
1
Voto cego!
O número de votos para cada aplicativo serão ocultados de todos. Uma vez por dia iremos publicar o placar nos comentários da postagem original.
A ordem de exibição dos projetos na página do Concurso será a seguinte: serão exibidas primeiro as aplicações que foram enviadas primeiro, ou seja, serão exibidas no começo da lista as que forem enviadas mais cedo.
P.S. Não se esqueçam de se subscrever nesta postagem (clique no ícone do sino) para ser notificado dos novos comentários feitos a esta postagem..
Para participar da votação é necessário:
Se logar no Open Exchange – As credenciais da Comunidade de Desenvolvedores funcionarão.
Faça qualquer contribuição válida para a Comunidade de Desenvolvedores – responda ou crie perguntas, escreva um artigo, publique aplicações no Open Exchange – e você estará apto a votar. Verifique esta postagem sobre as formas de fazer contribuições válidas para a Comunidade de Desenvolvedores.
Se você mudar de ideia após votar, cancele sua escolha e dê seu voto para outra aplicação!
Apoie a aplicação que você gostar mais!
Nota: É permitido aos participantes do concurso corrigir os problemas e fazer melhorias em seus aplicativos durante a semana de votação então, não perca a oportunidade !
Anúncio
Angelo Bruno Braga · Jun. 27, 2022
Olá e sejam bem vindos ao 21º concurso de programação InterSystems!
🏆 Concurso Full Stack InterSystems 2022 🏆
Duração: de 27 de Junho a 17 de Julho de 2022
Em prêmios: US$10.000
O tópico
💡 Aplicações Full Stack 💡
Desenvolva uma solução Full Stack utilizando o InterSystems IRIS, InterSystems IRIS For Health ou o IRIS Cloud Service como backend. Entendemos como full stack um frontend web ou aplicação móvel que insira, atualize ou apague dados no InterSystems IRIS através de API REST, API Nativa, ODBC/JDBC ou Python Nativo.
O que mais?
Desta vez decidimos desafiar os desenvolvedores a utilizar suas habilidades para solucionar um dos desafios globais:1) Você receberá um bônus especial se sua aplicação puder solucionar problemas relacionados ao aquecimento global e mudanças climáticas. 2) Existirá outro bônus se você preparar e publicar no Open Exchange um conjunto de dados relacionado ao aquecimento global e mudanças climáticas.
Então! Estamos buscando suas contribuições inovativas para um mundo ainda mais sustentável. Aprimore sua habilidades digitais para desenvolver soluções para os problemas climáticos!
Requisitos Gerais:
Aplicações aceitas: Aplicações novas no Open Exchange ou aplicações existentes com uma melhoria considerável. Nosso time irá revisar todas as aplicações antes de aprová-las para o concurso.
A aplicação deverá funcionar tanto no IRIS Community Edition quanto no IRIS for Health Community Edition ou no IRIS Advanced Analytics Community
A aplicação deverá ser de Código Aberto e deverá ser publicada no GitHub.
O arquivo README da aplicação deverá ser escrito em Inglês, conter os passos para a instalação, e conter tanto um vídeo de demonstração e/ou descrição do funcionamento da aplicação.
Premiações do Concurso:
1. Nominação de Especialistas – um júri composto por nossos Especialistas irá determinar os ganhadores:
🥇 1° lugar - US$4.000
🥈 2° lugar - US$2.000
🥉 3° lugar - US$1.000
🌟 4-15° lugares - US$100
2. Ganhadores da Comunidade - dado às aplicações que ganharem a maior quantidade de votos no total:
🥇 1° lugar - US$1.000
🥈 2° lugar - US$750
🥉 3° lugar - US$500
✨ Distintivos do Global Masters incluídos para todos os ganhadores!
Se vários participantes tiverem a mesma quantidade de votos, todos serão considerados ganhadores e a premiação será então dividida entre eles.
Prazos Importantes:
🛠 Desenvolvimento da aplicação e fase de inscrição:
27 de Junho de 2022 (01:00 BRT): Início do concurso.
10 de Julho de 2022 (00:59 BRT): Prazo final para submissões.
✅ Período de votação:
11 de Julho de 2022 (01:00 BRT): Início da votação.
17 de Julho de 2022 (00:59 BRT): Término da votação.
Nota: Os desenvolvedores participantes podem incluir melhorias em seus aplicativos durante todo o período de registro e também no de votação
Quem pode participar?
Qualquer membro da Comunidade de Desenvolvedores, exceto funcionários da InterSystems (contratados da ISC são permitidos). Crie já sua conta!
👥 Desenvolvedores podem criar times para criar uma aplicação colaborativa. São permitidos de 2 até 5 desenvolvedores por time.
Não se esqueçam de divulgar os membros de seu time no README de sua aplicação – Usem os perfis da Comunidade de Desenvolvedores.
Recursos Auxiliares:
✓ Exemplos InterSystems IRIS Docker aplicáveis para uma aplicações Full Stack:
Exemplo IRIS Full Stack
Exemplo básico de InterSystems IRIS Docker
Exemplo de API REST IRIS
Exemplo de API Nativa
Exemplos de IntegratedML
Exemplo de IRIS Analytics
isc-ipm-js
isc-perf-ui
isc-json
isc-rest
isc-codetidy
✓ Cursos Online:
Implementando Aplicações RESTful
✓ Vídeos:
Design e desenvolvimento com API REST
API REST 5 minutos
Aplicativos Web Orientados a Dados
✓ Para iniciantes com a plataforma de dados InterSystems IRIS:
Crie uma aplicação servidor com InterSystems IRIS
Caminho de aprendizagem para iniciantes
✓ Para iniciantes no Gerenciador de Pacotes ObjectScript (ZPM):
Como construir, Testar e Publicar pacotes ZPM com Aplicação REST para InterSystems IRIS
Desenvolvimento orientado a Package First com InterSystems IRIS e ZPM
✓ Como enviar seu projeto para o concurso:
Como publicar uma aplicação no Open Exchange
Como enviar uma aplicação para o Concurso
Precisa de ajuda?
Junte-se ao canal do concurso no servidor Discord da InterSystems ou converse conosco nos comentários desta postagem.
Estamos ansiosos para ver seus projetos! Boa sorte 👍
Participando deste concurso você concorda com os termos de competição definidos aqui. Leiam por favor os termos cuidadosamente antes de prosseguir.
Anúncio
Rochael Ribeiro · Ago. 5, 2022
No setor financeiro, a InterSystems é responsável por 15% do processamento de todas as ações negociadas no mundo e tem 11 dos 20 maiores bancos globais como clientes, representando mais de 7 milhões de licenças em operação. No País, a empresa que atende Banco do Brasil, Caixa Econômica e Icatu, entre outros, será uma das maiores patrocinadoras do Febraban Tech, onde vai falar sobre interoperabilidade, Smart Data Fabric e tudo o que está fazendo para ajudar o mercado. Quer saber mais? Acesse agora e confira: https://lnkd.in/dvYuS48N#InterSystemsBrasil #Finanças #FebrabanTech #DataFabric#Interoperabilidade #Bancos #Seguradoras
Anúncio
Angelo Bruno Braga · Out. 6, 2022
Olá Comunidade,
Junte-se a nós para um Encontro de Desenvolvedores InterSystems durante o TechCrunch Disrupt 2022!
Estaremos nos reunindo na quarta-feira, 19 de outubro, no Bartlett Hall, localizado na 242 O'Farrell St. (a poucos quarteirões do Moscone Center), das 18h às 20h30 PT, onde os palestrantes discutirão como os desenvolvedores pode trazer o código para os dados, não os dados para o código com Embedded Python e ML Integrado no InterSystems IRIS.
Alimentos e bebidas serão servidos acompanhados de discussões.
Agenda:
👉 "Visão Geral da InterSystems, Recursos para Desenvolvedores e Programa de Startup" por @Dean.Andrews2971, Head de Relações com Desenvolvedores, InterSystems
👉 "Nenhum Aplicativo Python com Latência Próximo aos Dados" por @Raj.Singh5479, Gerente de Produto - Experiência do Desenvolvedor, InterSystems
👉 "Aprendizado de Máquina sem uma equipe de ciência de dados: AutoML rápido e fácil no InterSystems IRIS" por @Akshat.Vora, Desenvolvedor de Sistemas Sênior, InterSystems
>> Inscreva-se aqui <<
Espero ver você lá!
Anúncio
Angelo Bruno Braga · Dez. 8, 2022
Olá desenvolvedores,
Divirtam-se assistindo o novo vídeo no InterSystems Developers YouTube:
⏯ InterSystems IRIS Cloud SQL @ Global Summit 2022
Aprenda a implantar um mecanismo InterSystems IRIS SQL totalmente gerenciado, escalável e seguro na nuvem em menos de um minuto. Mostraremos como começar a trabalhar rapidamente por meio do InterSystems Cloud Portal — importe seus esquemas e dados e conecte-se facilmente usando os drivers de cliente JDBC, ADO.NET, DB-API e ODBC da InterSystems.
Apresentadores:
🗣 Richard Guidice, Engenheiro de Nuvem Sênior, InterSystems🗣 @Steven.LeBlanc, Especialista de Produto, InterSystems
Aproveite e fique ligado!👍
Anúncio
Angelo Bruno Braga · jan 16, 2023
Olá Desenvolvedores,
Gostaríamos de convidá-lo a participar de nosso próximo concurso, dedicado à criação de ferramentas úteis para facilitar a vida de seus colegas desenvolvedores:
🏆 Concurso InterSystems: Ferramentas para Desenvolvedores 🏆
Envie um aplicativo que ajude a desenvolver mais rapidamente, contribua com código mais qualitativo e ajude no teste, implantação, suporte ou monitoramento de sua solução com o InterSystems IRIS.
Duração: de 23 de Janeiro a 12 de Fevereiro de 2023
Total em prêmios: US$13.500
O tópico
💡 InterSystems IRIS Ferramentas para Desenvolvedores 💡
Neste concurso, esperamos aplicativos que melhorem a experiência do desenvolvedor com o IRIS, ajudem a desenvolver mais rapidamente, contribuam com código mais qualitativo, ajudem a testar, implantar, oferecer suporte ou monitorar sua solução com o InterSystems IRIS.
Requisitos Gerais:
Aplicativos aceitos: novos para aplicativos Open Exchange ou existentes, mas com uma melhoria significativa. Nossa equipe analisará todas as inscrições antes de aprová-los para o concurso.
O aplicativo deve funcionar no InterSystems IRIS Community Edition.
Tipos de aplicativos que correspondem: estruturas de interface do usuário, IDE, gerenciamento de banco de dados, monitoramento, ferramentas de implantação, etc.
O aplicativo deve ser um aplicativo de código aberto e publicado no GitHub.
O arquivo README para o aplicativo deve estar em inglês, conter as etapas de instalação e conter a demonstração em vídeo ou/e uma descrição de como o aplicativo funciona.
Prêmios
1. Nominação de Especialistas - um júri especialmente selecionado determinará os vencedores:
🥇 1º lugar - US$5.000
🥈 2º lugar - US$3.000
🥉 3º lugar - US$1.500
🏅 4tº lugar - US$750
🏅 5º lugar - US$500
🌟 6-10º lugares - US$100
2. Ganhadores da Comunidade - ao aplicativo que receberá mais votos no total:
🥇 1º lugar - US$750
🥈 2º lugar - US$500
🥉 3º lugar - US$250
Se vários participantes obtiverem a mesma quantidade de votos, todos são considerados vencedores e o prêmio em dinheiro é dividido entre os vencedores.
Prazos Importantes
🛠 Fase de desenvolvimento e inscrição do aplicativo:
23 de Janeiro de 2023 (02:00 BRT): Início do concurso
5 de Fevereiro de 2023 (01:59 BRT): Prazo final para envio.
✅ Voting period:
6 de Fevereiro de 2023 (02:00 BRT): Início da votação
12 de Fevereiro de 2023 (01:59 BRT): Fim da votação
Nota: Os desenvolvedores podem melhorar seus aplicativos durante todo o período de registro e votação
Quem pode participar
Qualquer membro da comunidade de desenvolvedores, exceto funcionários da InterSystems.Crie uma conta!
👥 Os desenvolvedores podem se unir para criar um aplicativo colaborativo. Permitido de 2 a 5 desenvolvedores em uma equipe.
Não se esqueça de destacar os membros da sua equipe no README do seu aplicativo - perfis de usuário da Comunidade de Desenvolvedores
Recursos útei
✓ Aplicações de examplo:
iris-rad-studio - RAD para Interface com Usuário
cmPurgeBackup - Ferramenta de Backup
errors-global-analytics - Visualização de erros
objectscript-openapi-definition - gerador de Open API
Test Coverage Tool - ajudante de cobertura de teste
and many more
✓ Modelos que sugerimos para começar:
iris-dev-template
rest-api-contest-template
native-api-contest-template
iris-fhir-template
iris-fullstack-template
iris-interoperability-template
iris-analytics-template
✓ Para iniciantes no IRIS:
Build a Server-Side Application with InterSystems IRIS
Learning Path for beginners
✓ Para iniciantes no ObjectScript Package Manager (ZPM):
How to Build, Test and Publish ZPM Package with REST Application for InterSystems IRIS
Package First Development Approach with InterSystems IRIS and ZPM
✓ Como enviar seu projeto para o concurso:
Como publicar uma aplicação no Open Exchange
Como enviar uma aplicação para o Concurso
Precisa de Ajuda?
Junte-se ao canal do concurso no servidor Discord da InterSystems ou fale conosco no comentário deste post.
Mal podemos esperar para ver seus projetos! Boa sorte 👍
Ao participar deste concurso, você concorda com os termos de competição definidos aqui. Por favor, leia-os atentamente antes de prosseguir.
Artigo
Danusa Calixto · Fev. 3, 2023
Olá Comunidade,
Alguns de vocês passaram na Certificação Oficial da InterSystems e gostariam de obter uma marca verde bacana no avatar do seu perfil
e todos os seus certificados em seu perfil DC para que outras pessoas saibam que você sabe... você sabe o que queremos dizer
Portanto, para adicionar a certificação ao seu perfil na DC, você precisa seguir 3 etapas fáceis:
1️⃣ Vá até o seu perfil na comunidade
2️⃣ Vá até a seção Certificação Intersystems
3️⃣ Clique no botão Carregar minha certificação
e é isso!
O sistema enviará a solicitação para Credly com seu e-mail DC. Se sua certificação estiver vinculada ao mesmo e-mail, seus certificados serão carregados automaticamente:
Caso contrário, siga as etapas detalhadas descritas na página:
E pronto. Agora todo mundo sabe que você sabe...
Parabéns por adicionar a Certificação e por realmente ter passado nela. Bom trabalho!
Anúncio
Rochael Ribeiro · Mar. 15, 2023
Boa tarde,
Estamos com uma vaga aberta para São Paulo, de Sales Engineer, presencial.
Quem tiver interesse, favor verificar os requisitos da vaga em A InterSystems está contratando!
Este também é o link para aplicar para a vaga!!!!!!
Venha trabalhar conosco!!!!!!!
Artigo
Heloisa Paiva · Dez. 24, 2024
Oi Comunidade!
Nós sabemos que pode ser frustrante receber muitos emails (e nós definitivamente não queremos adicionar no seu lote), então aqui está como você pode definir notificações por email para o portal InterSystems Ideas.
Por padrão, todos os usuários registrados são inscritos em todas as categorias de ideias. Para mudar isso, entre no seu perfil do Portal de Ideias, selecione "Edit Profile", e então clique dentro do item "Weekly summary email", clique em "categories to highlight" e escolha o que você tem interesse.
Também tem algumas coisas que você deve saber:
1. Quando você cria uma ideia ou vota numa ideia existente, você automaticamente se inscreve para mudanças de status e comentários relacionados àquela ideia.
2. Você pode se inscrever/desinscrever de notificações relacionadas a uma ideia especifica clicando no botão "Subscribed" no topo direito da tela.
Se você apoia uma ideia, mas não quer receber notificações, por favor não cancele seu voto para se desinscrever, use o botão "Subscribed".
3. Para ver as ideias que você se inscreveu, use o filtro "My subscriptions" no menu principal do Portal de Ideias. Esse filtro estará disponível após o login.
Ali, você pode gerenciar suas inscrições a cada ideia
4. Se você não quer notificações do Portal de Ideias, envie uma mensagem privada a @Vadim.Aniskin .
Aguardando suas novas ideias, comentários e votos no InterSystems Ideas!
Artigo
Heloisa Paiva · Dez. 26, 2024
Oi Desenvolvedores!
Nós temos certeza que você quer que suas ideias do Ideas Portal sejam implementadas, então aqui estão alguns passos que você pode seguir para atrair atenção a elas.
Para promover sua ideia, você pode:
1. Criar uma publicação na Comunidaed de Desenvolvedores sobre a sua ideia, convidando usuários a votaram por ela no Portal de Ideias. Por exemplo, @Heloisa.Paiva escreveu um artigo "About the idea of Using Python Class Definition Syntax to create IRIS classes" mencionando "use Python Class Definition Syntax to create IRIS classes" do @Sylvain.Guilbaud.
2. Requisite a criação de uma enquete no Portal de Ideias dedicada à implementação da ideia. @Guillaume.Rongier7183 requisitou uma enquete do tipo sobre a ideia "Dark version of InterSystems Community".
Para requisitar uma enquete, escreva uma mensagem direta a @Vadim.Aniskin.
3. Responda a comentários sobre a sua ideia no Portal de Ideias e na Comunidade de Desenvolvedores.
Esses três passos vão atrair atenção a sua ideia e melhorar as chances de sua implementação.
Boa sorte e continue mandando ideias!
Artigo
Heloisa Paiva · Fev. 7
Atualizado 01/04/25
Olá Comunidade,
Vocês podem desbloquear todo o potencial do InterSystems IRIS — e ajudar sua equipe a se integrar — com a gama completa de recursos de aprendizado da InterSystems oferecidos online e presencialmente, para todas as funções em sua organização. Desenvolvedores, administradores de sistema, analistas de dados e integradores podem rapidamente se atualizar.
Recursos de Integração para Cada Função
Desenvolvedores
Programa de Aprendizado Online: Introdução ao InterSystems IRIS para Codificadores (21h)
Treinamento em Sala de Aula: Desenvolvimento com Objetos InterSystems e SQL (5 dias)
Administradores de Sistema
Trilha de Aprendizagem: Noções Básicas de Gerenciamento do InterSystems IRIS (10h)
Treinamento em Sala de Aula: Gerenciando Servidores InterSystems (5 dias)
Analistas de Dados
Vídeo: Introdução à Análise com InterSystems (6m)
Trilha de Aprendizagem para cada ferramenta:
Analisando Dados com o InterSystems IRIS BI
Apresentando Dados Visualmente com Relatórios InterSystems (1h 15m)
Construindo Modelos de Dados Usando o Adaptive Analytics (2h 15m)
Curso em Sala de Aula: Usando o InterSystems Embedded Analytics (5 dias)
Integradores
Programa de Aprendizagem: Introdução ao InterSystems IRIS for Health para Integradores (14h)
Treinamento em Sala de Aula: Desenvolvimento de Integrações de Sistemas e Construção e Gerenciamento de Integrações HL7 (5 dias cada)
Implementadores
Trilha de Aprendizagem: Implementação do InterSystems IRIS em Container e na Nuvem (3h)
Programa de Aprendizagem: Iniciando com InterSystems IRIS para Implementadores (26h)
Gerentes de Projeto
Assista a vídeos de visão geral do produto.
Leia histórias de sucesso para se inspirar — veja como outros estão usando os produtos InterSystems!
Outros Recursos dos Serviços de Aprendizagem
💻 Aprendizado Online: Registre-se gratuitamente em learning.intersystems.com para acessar cursos, vídeos e exercícios individuais. Você também pode concluir trilhas de aprendizado baseadas em tarefas ou programas baseados em funções para avançar em sua carreira.
👩🏫 Treinamento em Sala de Aula: Verifique o cronograma de treinamento em sala de aula ao vivo, presencial ou virtual, ou solicite um curso privado para sua equipe. Encontre detalhes em classroom.intersystems.com.
📘 Documentação do InterSystems IRIS: Materiais de referência abrangentes, guias e artigos explicativos. Explore a documentação.
📧 Suporte: Para suporte técnico, envie um e-mail para support@intersystems.com.
Oportunidades de Certificação
Depois que você e os membros da sua equipe tiverem obtido treinamento e experiência suficientes, ganhem o certificado de acordo com sua função!
Aprenda com a Comunidade
💬Participe do aprendizado na Comunidade de Desenvolvedores: Converse com outros desenvolvedores, poste perguntas, leia artigos e fique atualizado com os últimos anúncios. Veja este post para dicas sobre como aprender na Comunidade de Desenvolvedores.
Com esses recursos de aprendizado, sua equipe estará bem equipada para maximizar os recursos do InterSystems IRIS, impulsionando o crescimento e o sucesso de sua organização. Para obter assistência adicional, poste perguntas aqui ou pergunte ao seu Engenheiro de Vendas dedicado.
Artigo
Heloisa Paiva · Abr. 7
Eu decidi escrever isso antes que o tempo apagasse minha memória.É uma história muito pessoal como parceiro, como competidor, como funcionário,como cliente e, finalmente, como um observador externo da InterSystems.
Após uma graduação super rápida na Universidade Técnica de Viena,alguns anos de desenvolvimento para uma máquina virtual na SIEMENS,alguma experiência hardcore em networking e desenvolvimento de núcleo de SO na OLIVETTI, eu entrei na Digital Equipment (DEC) em 1978 como engenheiro de suporte e vendas do seu novíssimo DSM-11.
O núcleo do DSM-11 - o módulo Global - foi escrito por Terry Ragon.Eu tive a oportunidade de conhecê-lo durante o treinamento de lançamento em Maynard, MA.A InterSystems era relativamente nova após sua fundação.
O núcleo do DSM-11 - o módulo Global - foi escrito por Terry Ragon.Eu tive a oportunidade de conhecê-lo durante o treinamento de lançamento em Maynard, MA.A InterSystems era relativamente nova após sua fundação.Foi um período desafiador para entender toda a tecnologia de hardware (para mim) nova e todos os detalhes daquele grande bolo de sistema operacional, banco de dados e interpretador.Era fascinante. Foi ótimo ver como eu podia vencer qualquer benchmark contraBDs relacionais tradicionais.Como fornecedor do motor principal, eu via a InterSystems como um Parceiro.
Embora baseado na minha experiência em virtualização, eu simplesmente não consegui resistir a modificar e ajustar drivers e módulos de disco para transformar o DSM-11 em um "Produto em Camadas" [um Aplicativo] rodando com quase o mesmodesempenho sobre o RSX-11M.
Você pode imaginar que a DEC não ficou muito satisfeita com essa experiência.Especialmente porque pouco tempo depois, eles iniciaram o mesmo exercício no VMS.O resultado foi ruim e não atraente para os clientes naquela época.A DEC simplesmente não conseguiu entender a joia que tinha em suas mãos.Mais tarde, sob a orientação da InterSystems, essa lacuna foi fechada.
Mas um dos meus clientes me convidou para escrever seu próprio SO "tipo DSM"diretamente em um VAX puro, sem nenhuma parte do VMS.Com que frequência você ouviu falar de uma oportunidade de engenharia como essa?Foi um daqueles gatilhos de "IMPOSSÍVEL - NÃO PODE SER FEITO" que encontrei durante minha vida.Éramos 2 engenheiros experientes dedicados ao projeto:Compramos um VAX-750 em 1981, começamos a ler o manual do processadore depois de passar da página 35 começamos a digitar no console.Realista:- Havia um projeto além dos limites do PDP- Já suportando máquinas sem disco via Ethernet,- Eu criei os bootloaders, meu próprio protocolo sobre Ethernet,meu próprio formato de hardware no disco, que mais ninguém conseguia ler.
.....
Um esforço enorme. Mas depois de apenas 18 meses estava prontoe pudemos executar a primeira instalação em um cliente.Esta foi a época em que a InterSystems se tornou uma Concorrente.Uma concorrente muito remota, já que não havia sobreposição no mercado.Observávamos um ao outro com desconfiança de uma grande distância.
Foi um sucesso comercial para a empresa.Para mim, tornou-se muito trabalho de rotina com o MicroVAX como máquina principal.Correção de bugs e um novo lançamento de vez em quando não eram um desafio real.
Alguns anos depois, a DEC me ofereceu uma nova "MISSÃO IMPOSSÍVEL" e eu aceitei.Era um desafio tecnológico - mas longe do antigo DSM que havia saídodo meu escopo. E se converteu em um desafio organizacional e de gestão.Então eu vendi minha "Alma de Engenheiro" para subir na gestão internacional da DEC.Mas isso me tornou consciente da mentalidade de "Qualidade" e "Cliente em primeiro lugar".
Quando a Compaq comprou a DEC, as estruturas de gestão locais foram destruídas.Buscando novas oportunidades, fui contatado por um headhunter.Grande surpresa: seu cliente era a InterSystems:
Em poucas semanas, entrei como Funcionário e me senti em casa imediatamente.Agora percebi o que havia perdido por muito tempo - Trabalho Criativo -e o que eu havia vendido por apenas alguns trocados a mais.
Eu tinha acabado de entrar quando os objetos se tornaram invisíveis na partição local.O Caché Studio era novo em folha. E duas décadas de desenvolvimento tinham se passado.Mas as estruturas básicas eram as mesmas que eu havia construído na minha própria variante.E de suma importância para mim: "Qualidade em primeiro lugar" + "Dedicação ao Cliente".
Passei 12 anos muito emocionantes na InterSystems vendo muitas funcionalidades novassurgirem e algumas menos atraentes desaparecerem.Mas nunca foi um trabalho de rotina. Todo dia um desafio diferente para enfrentar.
Estou especialmente orgulhoso de nunca ter perdido nenhum benchmark contra outros BDs:Coroado por vencer o Oracle Spatial por um fator significativo.
Após minha aposentadoria, há 9 anos, passei para o papel deCliente da InterSystems. Essa experiência completa a imagem.Um prazer muito pessoal para mim é esta Comunidade de Desenvolvedores da qual participei em 2017.Agora me vejo no papel de Observador da InterSystems. Entendam,eu já havia proposto isso em 2005. Mas era muito cedo para ser aceito.
Minha dedicação a Clientes + Qualidade permanece intacta e minha mensagem para meus engenheiros de suporte na DEC ainda é válida para mim:
o cliente sempre tem razão - ele tem o problema
nossos produtos podem ter um bug - então encontre-o
a descrição dos nossos produtos pode estar errada - explique melhor
não assuma que o cliente tem seu conhecimento técnico - explique em detalhes
nós não entendemos qual é o bug - pergunte duas vezes e tente escutar mais profundamente
Esses também são os 5 princípios que aplico quando faço minhas revisões no OEXe isso faz a qualidade de um pacote OEX.
Agora, em 2023, tornei-me um Observador crítico e tenho minhas surpresas,tenho alguns déjà-vus reconhecendo ideias antigas vestidas de novo. Meus aplausospara novidades são filtrados. Algumas são ótimas, outras menos convincentes.
Eu sempre tento transmitir minha experiência pessoal àqueles que a pedem.E às vezes tento lembrar os colaboradores de que seus artigos oupacotes são um serviço aos outros membros e merecem Qualidade.
Espero que não tenha sido entediante para você.
Artigo
Heloisa Paiva · Maio 15
Como todos sabemos, a InterSystems é uma ótima empresa.
Seus produtos podem ser tão úteis quanto complexos.
No entanto, nosso orgulho às vezes nos impede de admitir que talvez não entendamos alguns conceitos ou produtos que a InterSystems nos oferece.
Hoje estamos começando uma série de artigos explicando como alguns dos intrincados produtos da InterSystems funcionam, obviamente de forma simples e clara.
Neste ensaio, irei esclarecer o que é Machine Learning e como tirar proveito dele... porque desta vez, VOCÊ VAI SABER com certeza do que estou falando.
O que (diabos) é Machine Learning?
Machine Learning é um ramo da inteligência artificial que se concentra no desenvolvimento de algoritmos e modelos que permitem aos computadores aprender a realizar tarefas específicas com base em dados, sem serem explicitamente programados para cada tarefa. Em vez de seguir instruções específicas, as máquinas aprendem por meio da experiência, identificando padrões em dados e fazendo previsões ou tomando decisões com base neles.
O processo envolve alimentar algoritmos com conjuntos de dados (chamados conjuntos de treinamento) para fazê-los aprender e melhorar seu desempenho ao longo do tempo. Esses algoritmos podem ser projetados para realizar uma ampla gama de tarefas, incluindo reconhecimento de imagem, processamento de linguagem natural, previsão de tendências financeiras, diagnóstico médico e muito mais.
Em resumo, Machine Learning permite que os computadores aprendam com dados e melhorem com a experiência, possibilitando que realizem tarefas complexas sem programação explícita para cada situação de forma autônoma...
É uma definição encantadora. No entanto, imagino que você precise de um exemplo, então aqui vai:
Bem, imagine que todos os dias você anota em algum lugar a hora do nascer e do pôr do sol. Se alguém lhe perguntasse se o sol nasceria no dia seguinte, o que você diria? Tudo o que você notou foi apenas a hora do nascer e do pôr do sol...
Observando seus dados, você concluiria que, com 100% de probabilidade, o sol nascerá amanhã. No entanto, você não pode ignorar o fato de que existe uma chance de que, devido a uma catástrofe natural, você não consiga ver o sol nascendo no dia seguinte. É por isso que você deveria dizer que a probabilidade de testemunhar um nascer do sol no dia seguinte é, na verdade, de 99,99%.
Considerando sua experiência pessoal, você pode fornecer uma resposta que corresponda aos seus dados. Machine Learning é a mesma coisa, só que feita por um computador.
Observe a tabela abaixo:
A
B
1
2
2
4
3
6
4
8
Como as colunas A e B se relacionam?
A resposta é fácil, o valor de B é o dobro de A. B=A*2, é um padrão.
Agora, examine a outra tabela:
A
B
1
5
2
7
3
9
4
11
Esta é um pouco mais complicada... Se você ainda não descobriu o padrão, é B=(A*2) +3.
Um humano, por exemplo, consegue deduzir a fórmula, o que significa que quanto mais dados você tem, mais fácil é adivinhar o padrão por trás desse mistério.
Então, Machine Learning usa a mesma lógica para revelar o padrão oculto nos dados.
Como começar?
Primeiro, você precisará de um computador. Sim, já que este artigo é sobre Machine Learning, ter apenas um caderno e um lápis não será suficiente.
Segundo, você precisará de uma instância do IRIS Community. Você pode baixar uma imagem Docker e executar seu teste aqui. Observe que ele deve ter ML integrado, por exemplo, a versão mais recente do InterSystems IRIS Community:
docker pull intersystems/iris-ml-community:latest-em
ou
docker pull intersystems/iris-community:latest
Se você precisar de outra plataforma, verifique https://hub.docker.com/r/intersystems/iris-ml-community/tags ou https://hub.docker.com/r/intersystems/iris-community/tags.
Então, crie um container a partir desta imagem e execute-o:
docker run --name iris-ml -d --publish 1972:1972 --publish 52773:52773 intersystems/iris-m
Se você é da "velha guarda", pode baixar uma versão gratuita para avaliação. No entanto, é importante ter uma conta InterSystems. Confira em https://login.intersystems.com/login/SSO.UI.Register.cls.
Depois, solicite uma cópia de avaliação em https://evaluation.intersystems.com/Eval/.
Instale e execute sua instância.
Agora, acesse o portal IRIS:http://localhost:52773/csp/user/EnsPortal.ProductionConfig.zen
Usuário: Superuser
Senha: SYS
Observação: Você pode ser solicitado a alterar a senha na primeira vez. Não se preocupe, apenas crie uma senha que você possa lembrar facilmente.
Abra a "Machine learning configuration" para revisar as versões que você instalou.
Neste ponto, você pode ver as configurações de provedor de ML instaladas.
Terra, "água" e fogo... qual o melhor?
Todos são bons. O importante é como treinar seu dragão, quer dizer... seus dados.
Explore mais informações sobre os modelos existentes:
AutoML: AutoML é um sistema de Machine Learning automatizado desenvolvido pela InterSystems e hospedado dentro da plataforma de dados InterSystems IRIS®. Ele é projetado para construir modelos preditivos precisos rapidamente usando seus dados. Ele automatiza vários componentes chave do processo de aprendizado de máquina.
Clique no link abaixo para ver mais informações: https://docs.intersystems.com/iris20241/csp/docbook/Doc.View.cls?KEY=GAUTOML_Intro
H2O: É um modelo de Machine Learning de código aberto. O provedor H2O não oferece suporte à criação de modelos de séries temporais.
Siga o link abaixo para descobrir mais: https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GIML_Configuration_Providers#GIML_Configuration_Providers_H2O
PMML: (Predictive Modelling Markup Language). É um padrão baseado em XML que expressa modelos analíticos. Ele oferece uma maneira para que aplicativos definam modelos estatísticos e de mineração de dados para que possam ser facilmente reutilizados e compartilhados. Confira o link abaixo para mais informações:https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=APMML
Qual é o primeiro passo?
Assim como no exemplo do pôr do sol e do nascer do sol, precisamos de alguns dados para treinar nosso modelo
É essencial conhecer o objetivo dos dados e os valores que devem ser previstos. Também é fundamental ter dados claros, sem duplicatas. Você também deve descobrir qual é o conjunto mínimo de dados. Eu vou usar o provedor AutoML porque é da Intersystems, ha-ha 😉
Existem alguns tipos de algoritmos:
Árvores de decisão: Primeiro, a informação é classificada, depois a próxima pergunta é aplicada para avaliar a probabilidade. Exemplo: Vai chover amanhã? Verifique se o céu está nublado (muito ou pouco) ou limpo. Se estiver muito nublado, verifique a umidade. Depois disso, verifique a temperatura... Se estiver muito nublado, com alta umidade e baixa temperatura, então choverá amanhã.
Florestas aleatórias: É um conjunto de árvores de decisão, cada uma das quais "vota" em uma classe. A maioria dos votos define o modelo selecionado.
Redes neurais: Isso não significa que Skynet está chegando... No entanto, é muito complicado de explicar em poucas palavras. A ideia geral é "copiar" a função dos neurônios humanos. Isso significa que cada dado de entrada é analisado por um "neurônio", que, por sua vez, fornece os dados de entrada para o próximo "neurônio" analisar os dados de saída.
Se você deseja brincar com redes neurais usando Python, pode criar uma e verificar como funciona. Por favor, dê uma olhada em https://colab.research.google.com/drive/1XJ-Lph5auvoK1M4kcHZvkikOqZlmbytI?usp=sharing.
Através do link acima, você pode executar uma rotina em Python, com a ajuda da biblioteca TensorFlow. Para obter o padrão das tabelas A e B, faça o seguinte:
import tensorflow as tf
import numpy as np
tableA = np.array([1, 2, 3, 4, 5, 6, 7], dtype=float)
tableB = np.array([5, 7, 9, 11, 13, 15, 17], dtype=float)
hidden1 = tf.keras.layers.Dense(units=3, input_shape=[1])
hidden2 = tf.keras.layers.Dense(units=3)
exit = tf.keras.layers.Dense(units=1)
model = tf.keras.Sequential([hidden1, hidden2, exit])
model.compile(
optimizer=tf.keras.optimizers.Adam(0.1),
loss='mean_squared_error'
)
print("Start training...")
history = model.fit(tableA, tableB, epochs=1000, verbose=False)
print("Model trained!")
import matplotlib.pyplot as plt
plt.xlabel("# Epoch")
plt.ylabel("Loss magnitud")
plt.plot(history.history["loss"])
print("Doing a predicction!")
result = model.predict([100])
print("The result is " + str(result) )
print("Internal variables of the model")
print(hidden1.get_weights())
print(hidden2.get_weights())
print(exit.get_weights())
O código acima utiliza os valores de A e B para criar um modelo para comparar e descobrir a relação entre ambos os valores.
Quando a predição é feita, ela retorna o valor correto; neste exemplo, a predição é 203.
Como isso funciona no IRIS?
Machine Learning no IRIS é chamado de "integratedML". Ele foi implementado desde o InterSystems IRIS 2023.2 como um Recurso Experimental, o que significa que não é suportado para ambientes de produção. No entanto, o recurso é bem testado e a InterSystems acredita que ele pode agregar valor significativo aos clientes. Você pode encontrar mais informações na documentação Using integratedML.
Mesmo assim, como esta é uma lição de ML para iniciantes, explicarei como operá-lo da maneira mais simples possível.
Observação: Estou utilizando um Docker com uma imagem de containers.intersystems.com/iris-ml-community
docker pull containers.intersystems.com/iris-ml-community
Você pode baixar a imagem do IRIS e os exemplos de https://github.com/KurroLopez/iris-mll-fordummies.
📣DICA: Pode abrir o terminal Docker com o seguinte comando:
docker-compose exec iris iris session iris
Estúdio da Universidade Sleepland
A Universidade Sleepland conduziu uma extensa pesquisa sobre insônia, realizando milhares de entrevistas e construindo um banco de dados com vários parâmetros de pacientes com e sem insônia.
Os dados coletados incluem o seguinte:
Gênero (masculino/feminino)
Idade (A idade da pessoa em anos)
Ocupação (A ocupação ou profissão da pessoa)
Duração do Sono (O número de horas que a pessoa dorme por dia)
Qualidade do Sono (Uma avaliação subjetiva da qualidade do sono, variando de 1 a 10)
Nível de Atividade Física (O número de minutos que a pessoa se dedica à atividade física diariamente)
Nível de Estresse (Uma avaliação subjetiva do nível de estresse experimentado pela pessoa, variando de 1 a 10)
Categoria de IMC (A categoria de IMC da pessoa: 1 Abaixo do Peso, Normal, Acima do Peso)
Sistólica (Pressão arterial sistólica)
Diastólica (Pressão arterial diastólica)
Frequência Cardíaca (A frequência cardíaca em repouso da pessoa em BPM)
Passos Diários (O número de passos que a pessoa dá por dia)
Distúrbio do Sono (Nenhum, Insônia, Apneia do Sono)
Para a primeira amostra, eu criei uma classe (St.MLL.insomniaBase) com as colunas mencionadas acima:
Class St.MLL.insonmniaBase Extends %Persistent
{
/// Gender of patient (male/female)
Property Gender As %String;
/// The age of the person in years
Property Age As %Integer;
/// The occupation or profession of the person
Property Occupation As %String;
/// The number of hours the person sleeps per day
Property SleepDuration As %Numeric(SCALE = 2);
/// A subjective rating of the quality of sleep, ranging from 1 to 10
Property QualitySleep As %Integer;
/// The number of minutes the person engages in physical activity daily
Property PhysicalActivityLevel As %Integer;
/// A subjective rating of the stress level experienced by the person, ranging from 1 to 10
Property StressLevel As %Integer;
/// The BMI category of the person: Underweight, Normal, Overweight
Property BMICategory As %String;
/// Systolic blood pressure
Property Systolic As %Integer;
/// Diastolic blood pressure
Property Diastolic As %Integer;
/// The resting heart rate of the person in BPM
Property HeartRate As %Integer;
/// The number of steps the person takes per day
Property DailySteps As %Integer;
/// None, Insomnia, Sleep Apnea
Property SleepDisorder As %String;
}
Então, eu construí algumas classes que estendem de insomniaBase chamadas insomnia01, insomniaValidate01 e insomniaTest01. Isso me permitiu ter as mesmas colunas para cada tabela.
Eventualmente, precisaremos popular nossas tabelas com valores de exemplo, então eu projetei um método de classe para esse propósito.
Class St.MLL.insomnia01 Extends St.MLL.insomniaBase
{
/// Populate values
ClassMethod Populate() As %Status
{
write "Init populate "_$CLASSNAME(),!
&sql(TRUNCATE TABLE St_MLL.insomnia01)
……
write $CLASSNAME()_" populated",!
Return $$$OK
}
📣DICA: Para abrir o terminal, digite o seguinte comando:
docker-compose exec iris iris session iris
Usando o terminal, chame o método Populate desta classe.
Do ##class(St.MLL.insomnia01).Populate()
Se fizermos tudo certo, teremos uma tabela com os valores para treinar nosso ML.
Também precisamos criar uma nova tabela para validação. É fácil porque você só precisará de uma parte dos dados fornecidos para o treinamento. Neste caso, serão 50% dos itens.
Por favor, execute a seguinte frase no terminal.
Do ##class(St.MLL.insomniaValidate01).Populate()
Finalmente, prepararemos alguns dados de teste para ver os resultados do nosso treinamento.
Do ##class(St.MLL.insomniaTest01).Populate()
Treine, treine e treine... você se tornará mais forte.
Agora, temos todos os dados necessários para treinar nosso modelo. Como fazer isso?
Você precisará apenas de 4 instruções simples:
CREATE MODEL
TRAIN MODEL
VALIDATE MODEL
SELECT PREDICT
Criação do modelo
CREATE MODEL cria os metadados do modelo de Machine Learning, especificando o nome do modelo, o campo alvo a ser previsto e o conjunto de dados que fornecerá o campo alvo.
Em nossa amostra, temos alguns parâmetros para avaliar distúrbios do sono, então projetaremos os seguintes modelos:
insomnia01SleepModel:Por gênero, idade, duração do sono e qualidade do sono.
Verifica se a idade e os hábitos de sono afetam algum tipo de distúrbio do sono.
insomnia01BMIModel: Por gênero, idade, ocupação e categoria de IMC.
Examina se idade, ocupação e IMC afetam algum tipo de distúrbio do sono.
insomnia01AllModel: Todos os fatores.
Inspeciona se todos os fatores afetam algum tipo de distúrbio do sono.
Vamos criar todos esses modelos agora.
Usando o gerenciamento SQL no portal IRIS, digite a seguinte frase:
CREATE MODEL insomnia01AllModel PREDICTING (SleepDisorder) From St_MLL.insomnia01
Neste ponto, nosso modelo sabe qual coluna prever.
Você pode verificar o que foi criado e o que a coluna de previsão contém com a seguinte frase:
SELECT * FROM INFORMATION_SCHEMA.ML_MODELS
Certifique-se de que o nome da coluna de previsão e as próprias colunas estejam corretos.
No entanto, também queremos adicionar diferentes tipos de modelos, pois desejamos prever distúrbios do sono de acordo com outros fatores, não todos os campos
Neste caso, vamos usar a cláusula "WITH" para especificar as colunas que devem ser usadas como parâmetros para fazer a previsão.
Para utilizar a cláusula "WITH", devemos indicar o nome das colunas e seu tipo.
CREATE MODEL insomnia01SleepModel PREDICTING (SleepDisorder) WITH(Gender varchar, Age integer, SleepDuration numeric, QualitySleep integer) FROM St_MLL.insomnia01
CREATE MODEL insomnia01BMIModel PREDICTING (SleepDisorder) WITH(Gender varchar, Age integer, Occupation varchar, BMICategory varchar) FROM St_MLL.insomnia01
Certifique-se de que todos esses modelos foram criados com sucesso.
Treinando o modelo
O comando TRAIN MODEL executa o mecanismo AutoML e especifica os dados que serão usados para o treinamento. A sintaxe FROM é genérica e permite que o mesmo modelo seja treinado várias vezes em diferentes conjuntos de dados. Por exemplo, você pode treinar uma tabela com dados da Universidade Sleepland ou da Universidade Napcity. A coisa mais importante, porém, é ter o modelo de dados com os mesmos campos, mesmo nome e mesmo tipo.
O mecanismo AutoML executa automaticamente todas as tarefas necessárias de aprendizado de máquina. Ele identifica recursos candidatos relevantes a partir dos dados selecionados, avalia tipos de modelos viáveis com base nos dados e na definição do problema e define hiperparâmetros para criar um ou mais modelos viáveis.
Como nosso modelo tem 50 registros, isso é suficiente para tal treinamento.
TRAIN MODEL insomnia01AllModel FROM St_MLL.insomnia01
Faça o mesmo com os outros modelos.
TRAIN MODEL insomnia01SleepModel FROM St_MLL.insomnia01
TRAIN MODEL insomnia01BMIModel FROM St_MLL.insomnia01
Você pode descobrir se seu modelo foi treinado corretamente com a seguinte frase:
SELECT * FROM INFORMATION_SCHEMA.ML_TRAINED_MODELS
É necessário validar o modelo e o treinamento com o comando VALIDATE MODEL.
Validando o modelo
Nesta etapa, precisamos confirmar se o modelo foi treinado corretamente. Portanto, devemos executar o comando VALIDATE MODEL.
📣Lembre-se: Antes de popular a classe, valide-a com 50% dos dados da fonte de dados de treinamento.
VALIDATE MODEL retorna métricas simples para modelos de regressão, classificação e séries temporais com base no conjunto de testes fornecido.
Verifique o que foi validado com a seguinte frase:
VALIDATE MODEL insomnia01AllModel From St_MLL.insomniaValidate01
Repita com os outros modelos.
VALIDATE MODEL insomnia01SleepModel FROM St_MLL.insomniaValidate01
VALIDATE MODEL insomnia01BMIModel FROM St_MLL.insomniaValidate01
Consumindo o modelo
Agora, vamos consumir este modelo e verificar se o modelo aprendeu com precisão como produzir o valor do Resultado.
Com a ajuda da frase “SELECT PREDICT”, vamos prever qual será o valor do Resultado. Para isso, usaremos a tabela test1 populada anteriormente.
SELECT *, PREDICT(insomnia01AllModel) FROM St_MLL.insomniaTest01
O resultado parece estranho depois de utilizar 50% dos dados explorados para treinar o modelo... Por que uma enfermeira de 29 anos foi diagnosticada com "insônia", enquanto o modelo previu "apneia do sono"? (veja o ID 54).
Devemos examinar outros modelos (insomnia01SleepModel e insomnia01BMIModel), criados com colunas diferentes, mas não se preocupe! Eu mostrarei as colunas usadas para projetá-los.
SELECT Gender, Age, SleepDuration, QualitySleep, SleepDisorder, PREDICT(insomnia01SleepModel) As SleepDisorderPrediction FROM St_MLL.insomniaTest01
Você pode ver novamente que uma mulher de 29 anos foi diagnosticada com "insônia", enquanto a previsão indica "apneia do sono".
Ok, você está certo! Também precisamos saber qual porcentagem da previsão foi aplicada a este valor final.
Como podemos saber a porcentagem de uma previsão?
Para descobrir a porcentagem da previsão, devemos usar o comando “PROBABILITY”.
Este comando retorna um valor entre 0 e 1. No entanto, não é a probabilidade de previsão, é a probabilidade de obter o valor que você deseja verificar.
Este é um bom exemplo:
SELECT *, PREDICT(insomnia01AllModel) As SleepDisorderPrediction, PROBABILITY(insomnia01AllModel FOR 'Insomnia') as ProbabilityPrediction FROM St_MLL.insomniaTest01
É a probabilidade de obter "Insônia" como um distúrbio do sono.
Nossa enfermeira, uma mulher de 29 anos, diagnosticada com "Insônia" tem 49,71% de chance de ter Insônia. Ainda assim, a previsão é "Apneia do Sono"...
Por quê? A probabilidade é a mesma para outros modelos?
SELECT Gender, Age, SleepDuration, QualitySleep, SleepDisorder, PREDICT(insomnia01SleepModel) As SleepDisorderPrediction, PROBABILITY(insomnia01SleepModel FOR 'Insomnia') as ProbabilityInsomnia,
PROBABILITY(insomnia01SleepModel FOR 'Sleep Apnea') as ProbabilityApnea
FROM St_MLL.insomniaTest01
Finalmente, está um pouco mais claro agora. De acordo com os dados (sexo, idade, qualidade do sono e duração do sono), a probabilidade de ter insônia é de apenas 34,63%, enquanto a chance de ter apneia do sono é de 64,18%.
Uau... Isso é muito interessante! Ainda assim, estávamos explorando apenas uma pequena porção de dados inseridos diretamente em uma tabela com um método de classe... Como podemos carregar um arquivo enorme com dados?
Por favor, aguarde o próximo artigo!, ele está chegando em breve.
Artigo
Julio Esquerdo · Jun. 7
Olá,
Neste artigo vamos ver o uso do python como linguagem de programação no InterSystems Iris. Para tal vamos usar como referência a versão Community 2025.1 que está disponível para ser baixada em https://download.intersystems.com mediante o login no ambiente. Para maiores informações sobre o download e instalação do Iris veja o link da comunidade https://community.intersystems.com/post/how-download-and-install-intersystems-iris
Uma vez instalado o íris agora precisamos ter o python disponível no nosso ambiente. Temos vários tutoriais explicando a instalação e configuração do python no Iris. Uma boa fonte de referência é o link da documentação oficial da InterSystems em https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=AFL_epython
Uma vez instalado e configurado o python no Iris podemos fazer um primeiro teste: abrir o shell do python via terminal do Iris. Para isso vamos abrir uma janela de terminal do Iris e executar o comando Do $$SYSTEM.Python.Shell():
Fig. 1 – Tela do shell python no Iris
Se você estiver com seu ambiente configurado corretamente você verá a tela acima. A partir daí podemos então executar comandos, como por exemplo, ver a versão do python. Para isso vamos usar o módulo sys:
Fig. 2 – Tela do shell python no Iris
Pronto. Temos o Iris e o python prontos para trabalhar. Agora podemos criar, por exemplo, uma classe Iris e nela programar alguns métodos utilizando python. Vamos ver um exemplo:
Class Demo.Pessoa Extends %Persistent{Property nome As %String;Method MeuNome() [ Language = objectscript ]{ write ..nome}Method MeuNomePython() [ Language = python ]{ print(self.nome)}}
A classe acima te uma propriedade (nome) e dois métodos, um em objectscript e outro em python, apenas para comparação. Chamando estes métodos temos o resultado na tela abaixo:
Fig. 3 – Chamada de método no Iris
Veja então que podemos ter na mesma classe métodos codificados em objectscript e em python. E de um deles podemos chamar o outro. Veja o exemplo a seguir. Vamos criar um novo método GetChave e do método MeuNomePython vamos fazer uma chamada e recuperar a informação:
Method MeuNomePython() [ Language = python ]{ chave=self.GetChave() print(self.nome) print(chave)}Method GetChave() As %Integer [ Language = objectscript ]{ Return $Get(^Chave)}
Vamos criar uma global com o valor que desejamos que seja recuperado:
Fig. 4 – Criação de global no Iris
Pronto. Com a global criada vamos agora chamar o nosso método:
Fig. 5 – Chamada de método no Iris
Veja que agora nosso método em python faz uma chamada a outro método, este codificado em objectscript. O inverso também é válido.
Python tem diversas bibliotecas úteis, como por exemplo:
iris – Permite interação com o banco de dados e ambiente Iris
matplot – Visualização de dados e criação de gráficos
numpy - Provê suporte a arrays e estrutura de dados
scikit-learn – Permite criar e implementar models de aprendizado de máquina
pandas – É utilizada para manipulação e análise de dados
Uma outra funcionalidade presente no Iris com python é a possibilidade de acessar dados via SQL, ou seja, podemos ter os dados armazenados em tabelas no Iris e código em python consumindo estes dados. Vamos ver um exemplo de código que lê uma tabela Iris e gera um arquivo XLS utilizando a biblioteca iris e pandas:
ClassMethod tabela() As %Status [ Language = python ]{ import iris import pandas as pd rs = iris.sql.exec("select * from demo.alunos") df = rs.dataframe() # Salvar o DataFrame como um arquivo XLS caminho_arquivo = 'c:\\temp\\dados.xlsx' df.to_excel(caminho_arquivo, index=False) return True}
Como visto, utilizamos no código as bibliotecas iris e pandas. Então criamos um recordset (rs) com o comando SQL desejado e depois disso um dataframe pandas (df) a partir deste recordset. A partir do dataframe exportamos os dados da tabela para um arquivo Excel no caminho especificado (df.to_excel). Veja que com pouquíssimas linhas montamos um código extremamente útil. Aqui o uso das bibliotecas python foi fundamental. Elas já nos forneceram o suporte ao dataframe (pandas) e a partir daí a sua manipulação (to_excel). Executando nosso código temos então a tabela excel gerada a partir dos dados da tabela:
Fig. 6 – Chamada de método no Iris
Fig. 7 – Planilha gerada pelo método
Python tem diversas bibliotecas prontas para uso, com diversas funcionalidades, assim como muito código em comunidades que podem ser utilizados nas aplicações.
Uma delas, que mencionamos acima, é a scikit-learn, que permite o uso de diversos mecanismos de regressão, permitindo a criação de métodos de predição baseado em informações, como por exemplo, uma regressão linear. Podemos ver um exemplo de código de regressão abaixo:
ClassMethod CalcularRegressaoLinear() As %String [ Language = python ]{ import iris import json
import pandas as pd from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_absolute_error import numpy as np import matplotlib import matplotlib.pyplot as plt matplotlib.use("Agg") rs = iris.sql.exec("select venda as x, temperatura as y from estat.fabrica") df = rs.dataframe() print(df) # Reformatando x1 para uma matriz 2D exigida pelo scikit-learn X = df[['x']] y = df['y'] # Inicializa e ajusta o modelo de regressão linear model = LinearRegression() model.fit(X, y) # Extrai os coeficientes da regressão coeficiente_angular = model.coef_[0] intercepto = model.intercept_ r_quadrado = model.score(X, y) # Calcula Y_pred baseado no X Y_pred = model.predict(X) # Calcula MAE MAE = mean_absolute_error(y, Y_pred) # Previsão para a linha de regressão x_pred = np.linspace(df['x'].min(), df['x'].max(), 100).reshape(-1, 1) y_pred = model.predict(x_pred) # Geração do gráfico de regressão plt.figure(figsize=(8, 6)) plt.scatter(df['x'], df['y'], color='blue', label='Dados Originais') plt.plot(df['x'], df['y'], color='black', label='Linha dos Dados Originais') plt.scatter(df['x'], Y_pred, color='green', label='Dados Previstos') plt.plot(x_pred, y_pred, color='red', label='Linha da Regressão') plt.scatter(0, intercepto, color="purple", zorder=5, label="Ponto do intercepto") plt.title('Regressão Linear') plt.xlabel('X') plt.ylabel('Y') plt.legend() plt.grid(True) # Salvando o gráfico como imagem caminho_arquivo = 'c:\\temp\\RegressaoLinear.png' plt.savefig(caminho_arquivo, dpi=300, bbox_inches='tight') plt.close() # Formata os resultados em JSON resultado = { 'coeficiente_angular': coeficiente_angular, 'intercepto': intercepto, 'r_quadrado': r_quadrado, 'MAE': MAE } return json.dumps(resultado)}
O código lê uma tabela em Iris via SQL, cria um dataframe pandas baseado nos dados da tabela e calcula uma regressão linear, gerando um gráfico com a reta da regressão, além de trazer indicadores da regressão. Tudo isso a partir da biblioteca scikit-learn.
O artigo da comunidade https://pt.community.intersystems.com/post/usando-o-python-no-intersystems-iris-%E2%80%93-calculando-uma-regress%C3%A3o-linear-simples traz mais informações sobre o uso do scikit-learn para calcular regressão linear.
O Iris também permite o armazenamento dados vetoriais, o que abre inúmeras possibilidades. A biblioteca langchain_iris traz mecanismos que auxiliam no armazenamento e recuperação de informações em base de dados vetoriais.
O código a seguir pega um arquivo PDF e gera uma base de dados vetorial com os embeddings gerados para futura recuperação de dados:
ClassMethod Ingest(collectionName As %String, filePath As %String) As %String [ Language = python ]{ import json from langchain_iris import IRISVector from langchain_openai import OpenAIEmbeddings from langchain_community.document_loaders import PyPDFLoader try: apiKey = <chatgpt_api_key> loader = PyPDFLoader(filePath) splits = loader.load_and_split() vectorstore = IRISVector.from_documents( documents=splits, embedding=OpenAIEmbeddings(openai_api_key=apiKey), dimension=1536, collection_name=collectionName, ) return json.dumps({"status": True}) except Exception as err: return json.dumps({"error": str(err)})}
Ao ler o arquivo PDF, o mesmo é “quebrado” em pedaços (splits) e esses pedaços são armazenados na forma de embeddings no Iris. Embeddings são vetores que representam aquele split.
Fig. 8 – Tabela com coluna do tipo vetor no Iris
Uma vez feita a ingestão do arquivo podemos agora recuperar informações e passar para a LLM gerar um texto de retorno baseado em uma pergunta formulada. A pergunta é convertida em vetores e é feita a busca no banco de dados. Os dados recuperados são então enviados a LLM que formata uma resposta. No exemplo usamos o ChatGPT:
Fig.9 – Chamada de método no Iris
Abaixo o código da busca realizada:
ClassMethod Retrieve(collectionName As %String, question As %String, sessionId As %String = "") [ Language = python ]{ import json import iris from langchain_iris import IRISVector from langchain_community.chat_message_histories import ChatMessageHistory from langchain_core.chat_history import BaseChatMessageHistory from langchain_core.runnables.history import RunnableWithMessageHistory from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain.chains import create_history_aware_retriever from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder from langchain.chains import create_retrieval_chain from langchain.chains.combine_documents import create_stuff_documents_chain
try: apiKey = <chatgpt_api_key> model = "gpt-3.5-turbo" llm = ChatOpenAI(model= model, temperature=0, api_key=apiKey) embeddings = OpenAIEmbeddings(openai_api_key=apiKey) vectorstore = IRISVector( embedding_function=OpenAIEmbeddings(openai_api_key=apiKey), dimension=1536, collection_name=collectionName, ) retriever = vectorstore.as_retriever() contextualize_q_system_prompt = """Dado um histórico de bate-papo e a última pergunta do usuário \ que pode fazer referência ao contexto no histórico do bate-papo, formule uma pergunta independente \ que pode ser entendido sem o histórico de bate-papo. NÃO responda à pergunta, \ apenas reformule-o se necessário e devolva-o como está.""" contextualize_q_prompt = ChatPromptTemplate.from_messages( [ ("system", contextualize_q_system_prompt), MessagesPlaceholder("chat_history"), ("human", "{input}"), ] ) history_aware_retriever = create_history_aware_retriever( llm, retriever, contextualize_q_prompt ) qa_system_prompt = """ Você é um assistente inteligente que responde perguntas com base em dados recuperados de uma base. Dependendo da natureza dos dados, você deve escolher o melhor formato de resposta: 1. **Texto:** Se os dados contêm principalmente informações descritivas ou narrativas, responda em formato de texto. 2. **Tabela:** Se os dados contêm informações estruturadas (ex: listas, valores, métricas, comparações diretas), responda em formato HTML com o seguinte estilo: - Bordas de 1px sólidas e de cor #dddddd. - O cabeçalho deve ter um fundo cinza escuro (#2C3E50) e texto em branco. - As células devem ter padding de 8px. - As linhas pares devem ter um fundo cinza claro (#f9f9f9). - As linhas devem mudar de cor ao passar o mouse sobre elas, usando a cor #f1f1f1. - O texto nas células deve estar centralizado. 3. **Lista:** Se os dados contêm informações estruturadas (ex: listas, valores, métricas, comparações diretas), responda em formato HTML com o seguinte estilo: - Bordas de 1px sólidas e de cor #dddddd. - O cabeçalho deve ter um fundo cinza escuro (#2C3E50) e texto em branco. - As células devem ter padding de 8px. - As linhas pares devem ter um fundo cinza claro (#f9f9f9). - As linhas devem mudar de cor ao passar o mouse sobre elas, usando a cor #f1f1f1. - O texto nas células deve estar centralizado. 4. **Gráfico:** Se os dados contêm informações que são mais bem visualizadas em um gráfico (ex: tendências, distribuições, comparações entre categorias), gere um gráfico apropriado. Inclua um título, rótulos de eixo e uma legenda quando necessário. Responda utilizando um link do quickchart.io. Contexto: {context} Pergunta: {input} """ qa_prompt = ChatPromptTemplate.from_messages( [ ("system", qa_system_prompt), MessagesPlaceholder("chat_history"), ("human", "{input}"), ] ) question_answer_chain = create_stuff_documents_chain(llm, qa_prompt) rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain) def get_session_history(sessionId: str) -> BaseChatMessageHistory: rs = iris.sql.exec("SELECT * FROM (SELECT TOP 5 pergunta, resposta, ID FROM Vector.ChatHistory WHERE sessionId = ? ORDER BY ID DESC) SUB ORDER BY ID ASC", sessionId) history = ChatMessageHistory() for row in rs: history.add_user_message(row[0]) history.add_ai_message(row[1]) return history def save_session_history(sessionId: str, pergunta: str, resposta: str): iris.sql.exec("INSERT INTO Vector.ChatHistory (sessionId, pergunta, resposta) VALUES (?, ?, ?) ", sessionId, pergunta, resposta) conversational_rag_chain = RunnableWithMessageHistory( rag_chain, get_session_history, input_messages_key="input", history_messages_key="chat_history", output_messages_key="answer", ) ai_msg_1 = conversational_rag_chain.invoke( {"input": question, "chat_history": get_session_history(sessionId).messages}, config={ "configurable": {"session_id": sessionId} }, ) save_session_history(sessionId, question, str(ai_msg_1['answer'])) return str(ai_msg_1['answer']) except Exception as err: return str(err)}
Aqui neste código entram vários aspectos que devem ser considerados neste tipo de código como o contexto da conversa, o prompt da LLM, embeddings e pesquisa vetorial.
E podemos ainda ter uma interface para realizar as chamadasao método, o que dá uma aparência mais sofisticada para a consulta. No exemplo temos uma página web acessando uma api REST que chama o método de consulta:
Fig. 10 – Tela de aplicação web chamando API REST no Iris
Estes são exemplos de uso do python no Iris. Mas o universo de bibliotecas disponíveis é muito maior. Podemos utilizar bibliotecas de reconhecimento de imagem, OCR, biometria, estatística e muito mais.
Artigo
Evgeny Shvarov · Nov. 9, 2020
Olá Comunidade!
Como você sabe, temos o nosso marketplace para soluções e ferramentas das Plataformas de Dados InterSystems, o [InterSystems Open Exchange](http://openexchange.intersystems.com)!
Mas como publicar sua aplicação no OE?
Antes de começar, deixe-me responder a algumas perguntas básicas.
**Quem pode publicar?**
Basicamente, todo mundo. Você pode entrar no Open Exchange com a sua conta do InterSystems Developer Community ou da Central de Suporte (WRC).
**O que é uma aplicação?**
Uma aplicação Open Exchange é uma solução, ferramenta, adaptador de interoperabilidade e interfaces, desenvolvidas usando qualquer produto das Plataformas de Dados InterSystems: Caché, Ensemble, HealthShare, InterSystems IRIS ou InterSystems IRIS for Health.
Ou esta ferramenta ou solução deve ajudar no desenvolvimento, testes, implantação ou gerenciamento de soluções nas Plataformas de Dados InterSystems.
**O que é uma aplicação para Open Exchange?**
Na verdade, é o nome, descrição e o conjunto de links para as entradas da aplicação: página de download, documentação, repositório de código (se houver), licença, etc.
Deixe-me ilustrar o processo com um exemplo pessoal.
**Enviando uma aplicação para o Open Exchange**
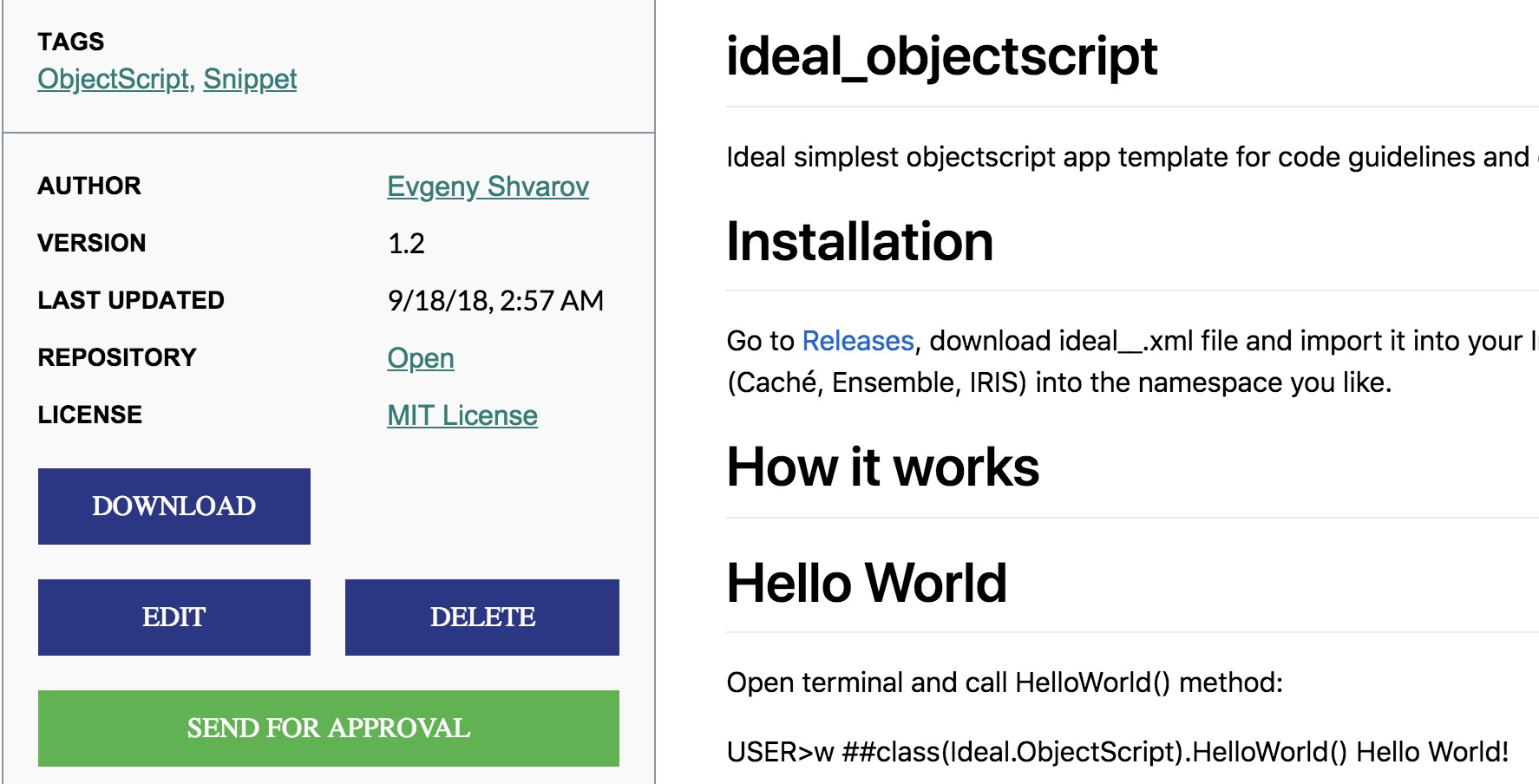
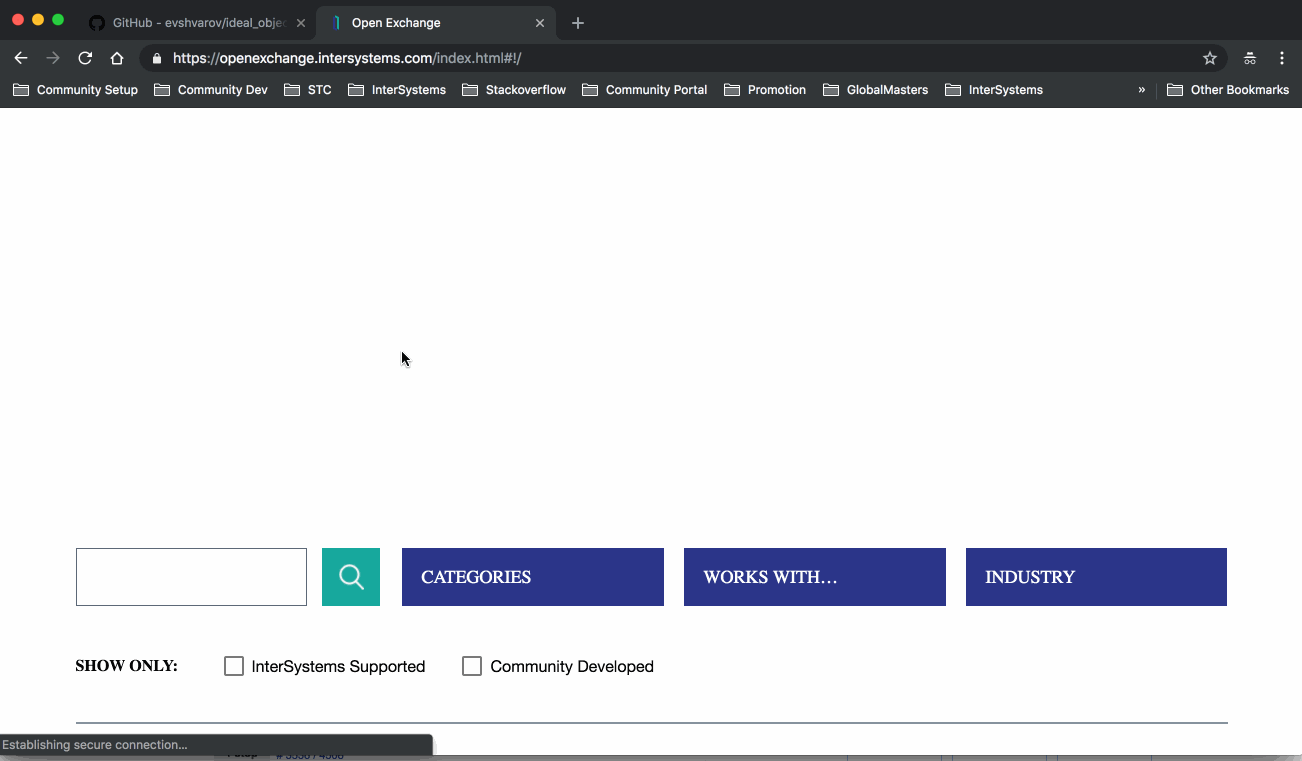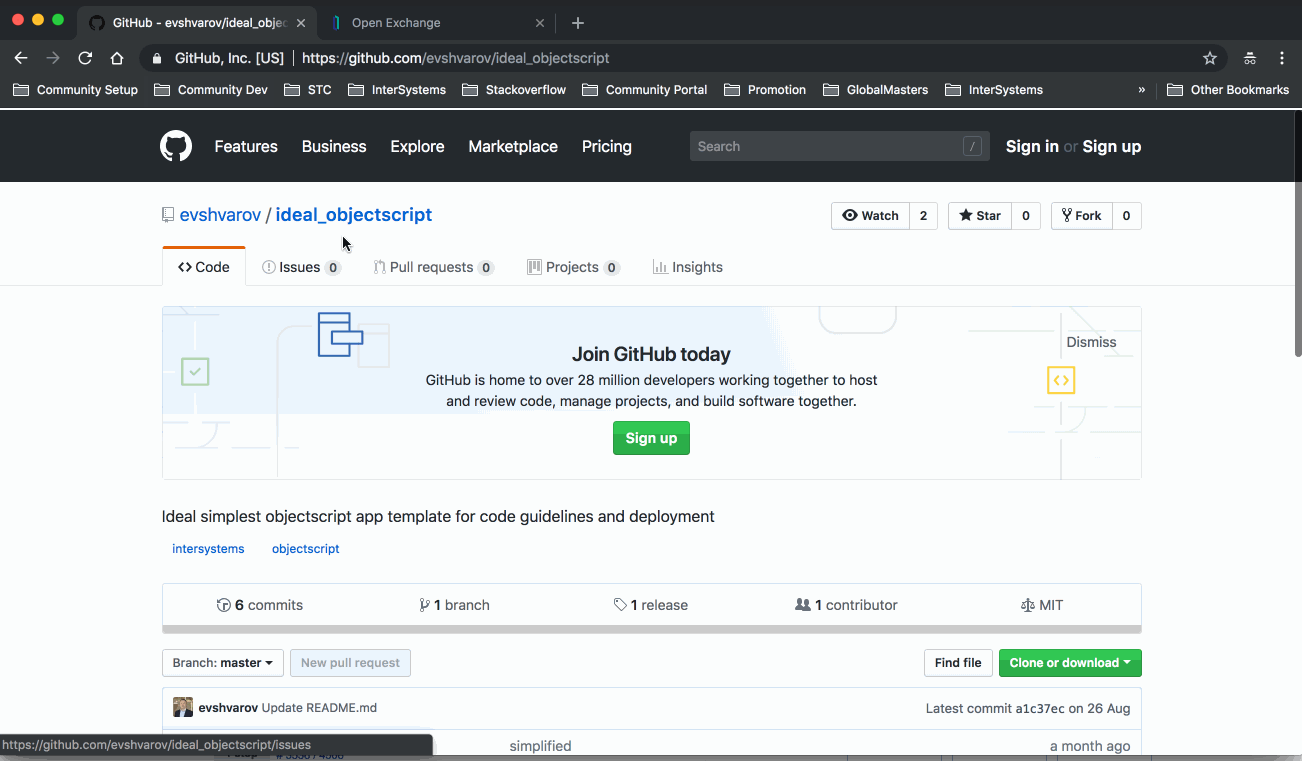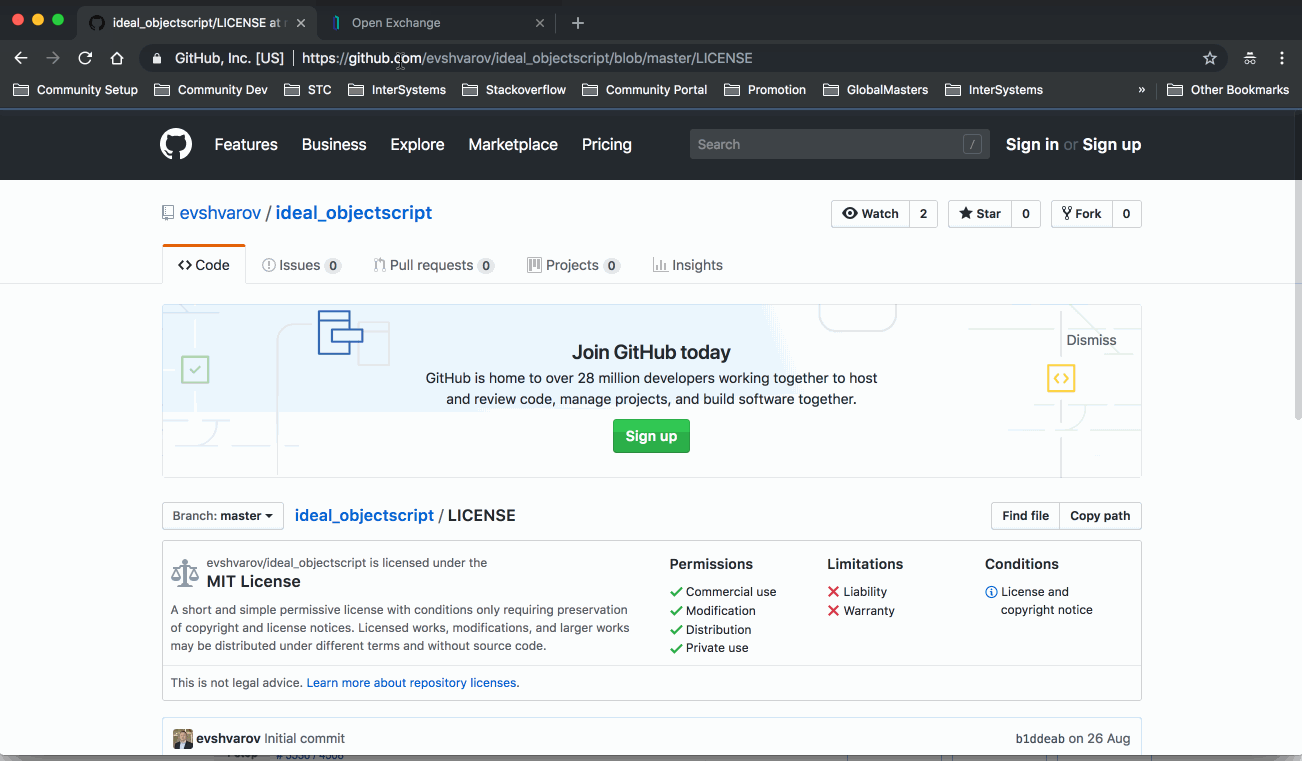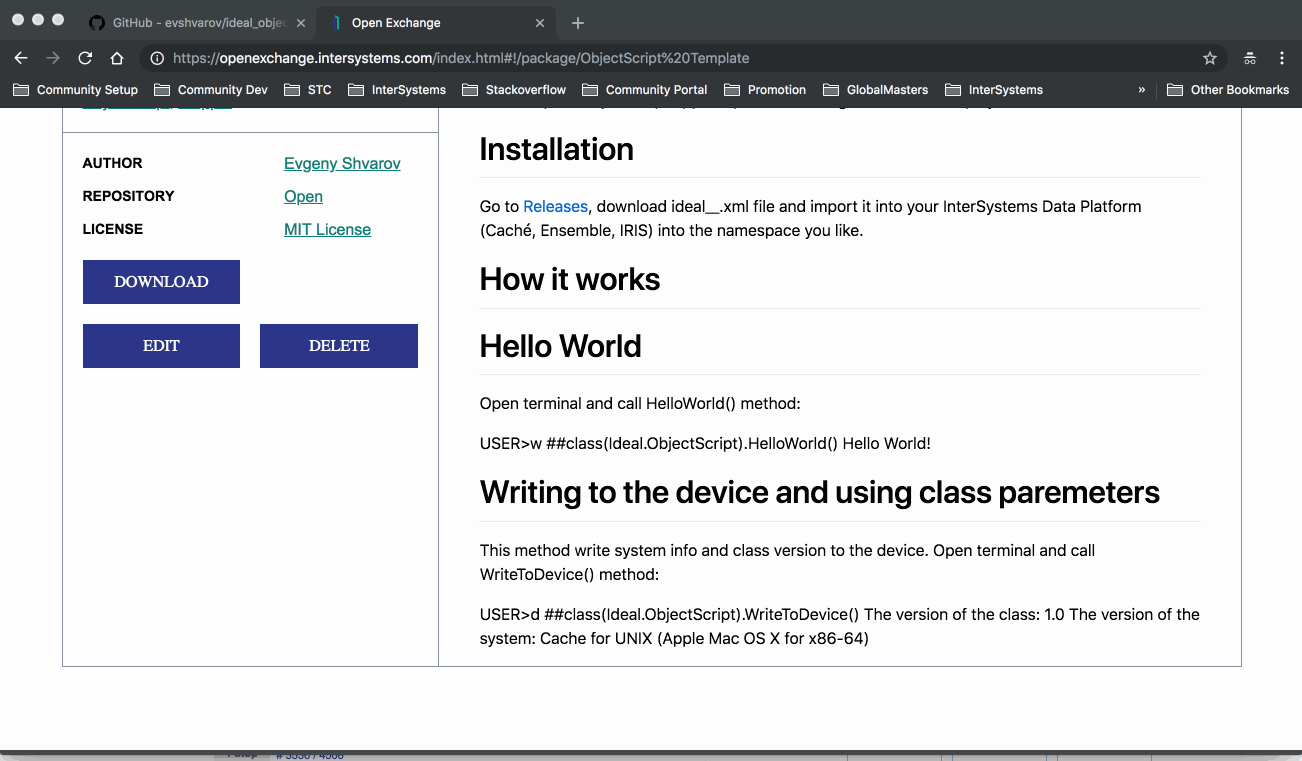
Para ilustrar o procedimento, desenvolvi uma aplicação fantástica em ObjectScript para o InterSystems IRIS e quero compartilhá-la com o Developer Community: Ideal ObjectScript.
Ela demonstra o uso ideal das diretrizes de codificação do ObjectScript para vários casos de uso com ObjectScript.
Existem campos obrigatórios que devem ser apresentados em todas as aplicações no Open Exchange.
1. Nome - um nome único no Open Exchange para a aplicação
2. Descrição - descrição da aplicação. O campo suporta markdown.
3. URL do Produto - o link para uma página de download da sua aplicação.
4. Licença - o link para a página que exibe a licença da sua aplicação.
5. Plataformas de Dados InterSystems - conjunto de Plataformas de Dados InterSystems que sua aplicação se destina.
Todos os demais campos são opcionais.
Então, vamos enviar a minha aplicação.
Eu tenho o **nome**: Ideal ObjectScript
**Descrição**: O Ideal ObjectScript demonstra o uso ideal das diretrizes de codificação do InterSystems ObjectScript para vários casos de uso com ObjectScript.
**URL do Produto**: https://github.com/evshvarov/ideal_objectscript/releases/tag/1.0 - o link para a versão 1.0 da aplicação na seção de lançamentos do GitHub.
**URL da Licença**: https://github.com/evshvarov/ideal_objectscript/blob/1.0/LICENSE - o link para o arquivo da LICENÇA da aplicação.
**Plataformas de Dados InterSystems:** E a aplicação suporta InterSystems IRIS, Caché e Ensemble - esta é a lista de produtos InterSystems com os quais eu mesmo testei a aplicação.
Com isso, estamos prontos para enviar a aplicação.
**Versão da aplicação**
Depois de clicar em Enviar para aprovação, você precisa fornecer a versão da aplicação e as notas da versão. Usamos o [Semver](http://semver.org/) para controle de versão. As notas de lançamento serão publicadas na seção de notícias do Open Exchange, Redes Sociais DC e histórico de versão da aplicação.
Depois disso, a aplicação entra no fluxo de trabalho de aprovação que resulta com a aprovação automática no OpEx ou com algumas recomendações de como corrigir as descrições e links da aplicação.
Inserir
**Parâmetros adicionais**

**URL da Imagem**
Coloque uma URL para o ícone de imagem de sua aplicação que será exibida em um bloco. Você pode omitir isso e o ícone do OpEx será mostrado.
**URL do GitHub**
Coloque o link para o repositório no GitHub de sua aplicação se você o tiver. Temos a integração com o GitHub no Open Exchange, portanto, se você inserir o link para o repositório de sua aplicação, o Open Exchange mostrará a descrição no GitHub automaticamente (tudo o que está listado no Readme.md). Ex. veja como a página do Ideal ObjectScript [é exibida no Open Exchange.](https://openexchange.intersystems.com/index.html#!/package/Ideal%20ObjectScript)
**URL do Artigo da Comunidade**
É claro que você pode falar sobre a sua aplicação no Developer Community com um bom artigo, então coloque a URL dele aqui!
Como você pode ver o procedimento é muito simples! Estou ansioso para ver suas aplicações para a Plataformas de Dados InterSystems no Open Exchange!
Mantenha-se informado!